A律压缩与解压缩基本原理及实现程序
- 格式:doc
- 大小:44.50 KB
- 文档页数:4

压缩软件原理压缩软件是一种常见的计算机应用程序,它可以将文件或文件夹进行压缩,从而减小其占用的存储空间。
在网络传输和存储文件时,压缩软件能够提高效率,减少传输时间和存储成本。
那么,压缩软件是如何实现文件压缩的呢?其原理是什么呢?首先,压缩软件利用了数据的重复性原理。
在文件中,往往会存在大量的重复数据,例如相同的文字、图片或者代码片段。
压缩软件通过对文件进行扫描分析,找出其中的重复数据,并将其进行压缩存储。
这样一来,文件中的重复数据只需存储一次,就可以在解压缩时还原出原始文件,从而实现了对文件的压缩。
其次,压缩软件利用了数据的统计原理。
在文件中,某些数据出现的频率可能会比较高,而另一些数据则可能出现的较少。
压缩软件可以通过统计分析文件中不同数据的出现频率,然后采用不同的编码方式对数据进行压缩。
对于出现频率较高的数据,采用较短的编码;而对于出现频率较低的数据,采用较长的编码。
这样一来,可以有效地减小文件的存储空间。
此外,压缩软件还利用了数据的模式识别原理。
在文件中,某些数据可能会呈现出一定的规律或者模式,例如连续的0或者1,或者特定的数据序列。
压缩软件可以通过对文件进行模式识别,找出其中的规律和模式,并对其进行压缩存储。
这样一来,可以进一步减小文件的存储空间。
总的来说,压缩软件通过利用数据的重复性、统计规律和模式识别原理,实现了对文件的压缩。
在实际应用中,不同的压缩算法和压缩方法会对文件的压缩效果产生影响。
因此,选择合适的压缩软件和压缩算法,可以更好地实现文件的高效压缩和解压缩。
除了文件压缩,压缩软件还可以对文件进行加密和保护,以及对压缩包进行分卷和合并等操作。
因此,压缩软件在日常生活和工作中具有广泛的应用价值,对提高工作效率和节省存储空间都具有积极的作用。
综上所述,压缩软件通过利用数据的重复性、统计规律和模式识别原理,实现了对文件的高效压缩。
在实际应用中,选择合适的压缩软件和压缩算法,可以更好地实现文件的压缩和解压缩,提高工作效率和节省存储空间。

计算机应用基础数据压缩和解压缩的原理与方法数据压缩和解压缩在计算机应用中扮演着重要的角色,它可以有效地减少数据的存储空间和网络传输所需的带宽。
本文将介绍数据压缩和解压缩的原理与方法。
一、数据压缩的原理数据压缩的基本原理是通过消除冗余信息来减少数据的存储空间和传输带宽。
下面将介绍几种常见的数据压缩原理。
1.1 无损压缩无损压缩是指在数据压缩的过程中不会丢失原始数据的任何信息。
其中最常用的无损压缩算法是哈夫曼编码和LZW编码。
1.1.1 哈夫曼编码哈夫曼编码是一种变长编码,根据字符出现的频率来构建编码表。
频率较高的字符使用较短的编码,频率较低的字符使用较长的编码。
在压缩的过程中,将原始数据替换为对应的编码,从而减少数据的大小。
1.1.2 LZW编码LZW编码是一种字典编码,将一系列连续的字符序列映射为短的编码。
在压缩的过程中,使用一个字典来存储已经出现的字符序列及其对应的编码。
当遇到新的字符序列时,将其添加到字典中,并输出其对应的编码。
1.2 有损压缩有损压缩是指在压缩的过程中会有一定程度上的信息丢失。
有损压缩常用于图像、音频和视频等多媒体数据的压缩。
其中最常用的有损压缩算法是JPEG和MP3。
1.2.1 JPEGJPEG是一种常用的图像压缩格式,它通过舍弃图像中的一些高频信息来减少数据的大小。
在压缩的过程中,JPEG将图像分为不同的8x8像素块,并对每个块进行离散余弦变换(DCT),然后对DCT系数进行量化,并使用熵编码进行进一步压缩。
1.2.2 MP3MP3是一种常用的音频压缩格式,它通过删除音频中的一些听觉上不明显的信息来减少数据的大小。
在压缩的过程中,MP3首先对音频进行傅里叶变换,并将频谱分割为不同的子带。
然后对每个子带进行量化,并使用熵编码进行进一步压缩。
二、数据解压缩的原理数据解压缩的过程是数据压缩的逆过程,它可以将压缩后的数据恢复为原始的数据。
解压缩的原理和压缩的原理相对应,下面将介绍几种常见的数据解压缩原理。
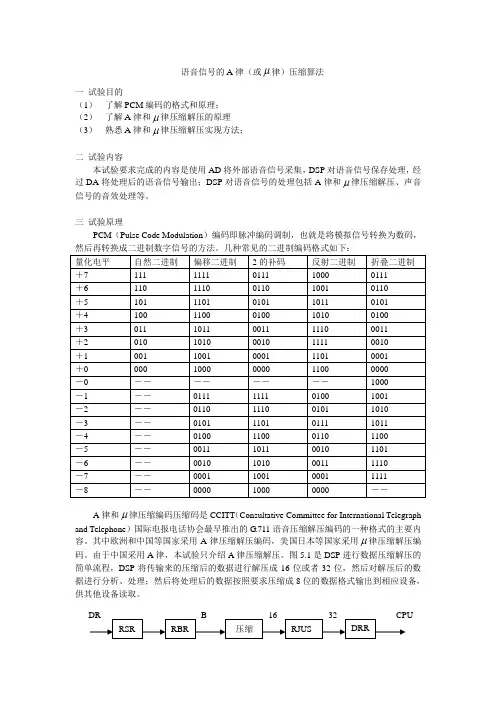
语音信号的A律(或μ律)压缩算法一试验目的(1)了解PCM编码的格式和原理;(2)了解A律和μ律压缩解压的原理(3)熟悉A律和μ律压缩解压实现方法;二试验内容本试验要求完成的内容是使用AD将外部语音信号采集,DSP对语音信号保存处理,经过DA将处理后的语音信号输出;DSP对语音信号的处理包括A律和μ律压缩解压、声音信号的音效处理等。
三试验原理PCM(Pulse Code Modulation)编码即脉冲编码调制,也就是将模拟信号转换为数码,A律和μ律压缩编码压缩码是CCITT(Consultative Committee for International Telegraph and Telephone)国际电报电话协会最早推出的G.711语音压缩解压编码的一种格式的主要内容。
其中欧洲和中国等国家采用A律压缩解压编码,美国日本等国家采用μ律压缩解压编码。
由于中国采用A律,本试验只介绍A律压缩解压。
图5.1是DSP进行数据压缩解压的简单流程,DSP将传输来的压缩后的数据进行解压成16位或者32位,然后对解压后的数据进行分析、处理;然后将处理后的数据按照要求压缩成8位的数据格式输出到相应设备,供其他设备读取。
图5.1图5.2是DSP 将数据解压的值,DSP 将压缩的8位数据解压成16位的DSP 通用数据格式,其中高12位为解压后的数据,低4位补0。
DSP 将解压后的数据放在缓冲串口的发送寄存器中,只要运行发送指令,缓冲串口就会将数据发送出去。
对接受数据的解压缓冲串口有一样的操作。
图5.2 A 律数据解压图DSP 内部的缓冲串口(MCBSPS )带有硬件实现的A 律和 律压缩解压,用户只需要在相应寄存器中设置就可以了。
所有与缓冲串口相关的寄存器和引脚如图5.4所示,图5.4中有13个需要设置的寄存器,分别为RSR 、XSR 、RBR 、DRR 、DXR 、SPCR 、RCR 、XCR 、SRGR 、PCR 、MCR 、RCER 、XCER 等。

A律压缩与解压缩基本原理及实现程序在A律压缩中,输入的原始数据通常是模拟信号,例如语音波形。
该算法将模拟信号进行量化和编码,以减小数据的大小。
下面将详细介绍A律压缩与解压缩的基本原理及实现程序。
1.压缩原理:A律压缩的第一步是将模拟信号进行量化。
量化是将连续的模拟信号转换为离散的数字信号的过程。
在A律压缩中,采用非线性量化方法。
具体而言,采用的是一种对数变换,将较小的信号幅度量化为较大的值,而较大的信号幅度量化为较小的值。
这样可以减少较小振幅信号的量化误差,提高信号的动态范围。
A律压缩的第二步是对量化后的信号进行编码。
通常采用的编码方式是将每个量化的值映射成对应的编码值。
在A律压缩中,采用的是8位编码,将量化值映射到一个8位的二进制码字。
这样可以进一步减小数据的大小。
2.解压缩原理:A律解压缩的第一步是将编码后的数据解码成量化值。
根据编码表,将每个编码值解码为对应的量化值。
这样可以恢复出压缩前的模拟信号。
A律解压缩的第二步是将量化值反量化为模拟信号。
根据A律的量化特性,采用合适的反量化函数,将量化值恢复为原始的模拟信号。
一般而言,反量化函数是原量化函数的逆函数。
3.示例程序:压缩程序:```import numpy as np#定义量化函数def quantize(signal, max_amp):quantized = np.sign(signal) * np.log(1 + max_amp * np.abs(signal)) / np.log(1 + max_amp)return quantized#定义编码函数def encode(quantized):encoded = np.round((quantized + 1) * 127.5)return encoded.astype(np.uint8)#输入原始信号signal = np.random.random(1000) * 2 - 1#设置最大振幅max_amp = 1.0#量化quantized = quantize(signal, max_amp)#编码encoded = encode(quantized)#输出压缩后的数据print(encoded)```解压缩程序:```#定义解码函数def decode(encoded):quantized = encoded / 127.5 - 1return quantized#定义反量化函数def dequantize(quantized, max_amp):signal = np.sign(quantized) * (1 / max_amp) * ((1 + max_amp) ** np.abs(quantized) - 1)return signal#解码decoded = decode(encoded)#反量化reconstructed = dequantize(decoded, max_amp)#输出解压缩后的数据print(reconstructed)```以上是A律压缩与解压缩的基本原理及示例程序。

程序如下所示:#include "stdio.h"int main() //验证方法{int m,n;int compress(int input);int decompress(int input);m=compress(-16); //输出m=129,因为符号位的关系10000001n=decompress(m); //输出n=-16,解压缩printf("%d\n",m);printf("%d\n",n);return 0;}//压缩函数int compress(int input){int i,inputtemp,seg,flag,offset;if(input<0) //获取最高位的符号位{flag = 1;inputtemp=-1*(input);}else{flag = 0;inputtemp = input;}inputtemp=(inputtemp>>4) & 0x7ff; //获取原始数据的除符号外的高位if(inputtemp < 16){return ((flag<<7) | inputtemp);}for(i=0;i<=6;i++){if(inputtemp < (1<<(5+i))){seg=(i+1); //段落码offset=(inputtemp-(1<<(5+i-1)))/(1<<i); //段内码return ((flag<<7) | (seg<<4) | offset); //压缩值}}return 0;}//解压缩函数int decompress(int input){int i,flag,seg,offset,temp;flag=input>>7; //获取最高位的符号位seg=(input>>4) & 0x0007; //段落码offset=input & 0x000f; //段内码if(seg == 0){temp=offset;}else{i=(seg-1);temp=(offset*(1<<i)+(1<<(5+i-1)));}if(flag==0)return (temp << 4);elsereturn ((-1)*(temp << 4));}。

计算机数据压缩算法的原理和实现计算机数据压缩算法是一种通过对数据进行编码和压缩以减少存储空间和传输带宽需求的技术。
本文将介绍常见的数据压缩算法以及它们的原理和实现方式。
一、无损压缩算法无损压缩算法是指压缩后的数据可以完全恢复为原始数据。
常见的无损压缩算法包括:1. 霍夫曼编码霍夫曼编码是一种用于无损数据压缩的变长编码方法。
它利用出现频率较高的字符用较少的比特表示,而较少出现的字符用较多的比特表示,从而实现数据的高效压缩。
2. LZ77/LZ78LZ77和LZ78是两种基于字典的压缩算法。
它们利用了数据中的重复模式,并通过引用先前出现的数据来实现压缩。
LZ77是一种基于滑动窗口的压缩算法,它将数据分为窗口和缓冲区,在窗口中查找重复的子串,并用指针来表示。
LZ78是LZ77的改进版,它使用了字典来存储出现过的子串,并用索引来表示。
3. 阿尔米达-雷德-华诺编码(Arithmetic coding)阿尔米达-雷德-华诺编码是一种用于无损数据压缩的算法,它将整个数据流映射为一个介于0到1之间的实数,并根据数据的概率分布来进行编码。
它可以实现更高的压缩比例和更精细的概率建模。
二、有损压缩算法有损压缩算法是指压缩后的数据无法完全恢复为原始数据,但经过压缩后的数据仍然可以满足特定的应用需求。
常见的有损压缩算法包括:1. JPEGJPEG是广泛应用于图像压缩的有损压缩算法。
它利用了人眼对颜色和细节的敏感度有限性,并通过去除不可察觉的细节和冗余数据来实现高压缩比。
JPEG压缩算法包括离散余弦变换(DCT)和量化两个主要步骤。
2. MP3MP3是广泛应用于音频压缩的有损压缩算法。
MP3算法利用了人耳对音频的感知特性,并通过去除听不到或难以察觉的音频信号来实现高效的压缩。
MP3压缩算法主要包括声音分析、频域处理和编码三个步骤。
三、压缩算法的实现压缩算法的实现可以通过编程语言以及相应的算法实现。
以下是一些常见的编程语言和库用于实现压缩算法:1. C/C++C/C++语言提供了丰富的库和算法,可以实现各种压缩算法。

学会使用文件压缩软件压缩和解压缩文件在日常工作和学习中,我们经常需要使用文件压缩软件来压缩和解压缩文件。
文件压缩软件可以将大文件压缩成较小的文件,从而节省存储空间,便于传输和共享。
本文将介绍如何学会使用文件压缩软件来压缩和解压缩文件,并且按类划分为三个章节:文件压缩的原理和常用的文件压缩软件、压缩文件的操作步骤、以及解压缩文件的操作步骤。
第一章:文件压缩的原理和常用的文件压缩软件文件压缩的原理是通过减少冗余数据和使用压缩算法将文件转化为更小的格式,从而实现节省存储空间和传输带宽的目的。
常用的文件压缩算法有ZIP、RAR、7ZIP等。
这些压缩算法都采用了不同的压缩策略和算法来实现文件压缩,其中RAR和7ZIP通常压缩效率更高。
除了以上提到的文件压缩算法外,还有一些常用的文件压缩软件。
其中最常见的是WinRAR和7-Zip,它们提供了简单易用的图形界面和丰富的功能。
另外,还有一些开源的文件压缩软件,比如PeaZip和Bandizip等,它们也提供了类似的功能,并且完全免费。
第二章:压缩文件的操作步骤在使用文件压缩软件进行压缩文件之前,我们需要先安装相应的文件压缩软件。
以WinRAR为例,以下是压缩文件的基本操作步骤:1. 打开WinRAR软件,点击菜单栏中的“添加”按钮。
2. 在弹出的窗口中,选择要压缩的文件或文件夹,并点击“确定”按钮。
3. 在新的窗口中,可以设置压缩文件的名称、保存路径和压缩格式等选项。
4. 点击“确定”按钮开始压缩文件,等待压缩完成。
如果需要进一步设置压缩参数,可以在WinRAR的设置界面中进行配置。
例如,可以设置文件压缩的级别、密码、文件分卷等选项。
同时,还可以选择是否创建自解压文件,方便接收者在没有安装文件压缩软件的情况下解压缩文件。
第三章:解压缩文件的操作步骤解压缩文件与压缩文件类似,同样需要使用文件压缩软件来操作。
以下是解压缩文件的基本操作步骤:1. 打开安装好的文件压缩软件,点击菜单栏中的“打开”按钮。

语音信号压缩(A律)绪论语言是人们最重要的交流工具,语音信号处理是语音学和数字信号处理相结合的交叉学科,同时又与心理声学、语言学、模式识别和人工智能等学科相联系。
既依赖这些学科的发展,又可以促进这些学科的进步。
近年来,随着多媒体信息技术和网络技术的高速发展,数字语音压缩技术的应用领域越来越广泛,尤其在可视电话、IP网络电话、数字蜂窝移动通信、综合业务数字网、公共交换电话网和话音存储转发系统等领域中,需要在保证语音一定质量的前提下尽可能降低其编码比特率,便于在有限的传输带宽内让出更多的信道用于传送图像、文档、计算机文件和其他数据流。
本文通过研究A律压缩算法的应用,来实现语音信号的压缩。
近年来,DSP技术在我国也得到了迅速的发展,不论是在科学技术研究,还是在产品的开发等方面,在数字信号处理中,其应用越来越广泛,并取得了丰硕的成果。
数字滤波占有极其重要的地位。
一个完备的语音信号处理系统不但要具备语音信号的采集和回放功能,而且更重要的是要能完成复杂的语音信号分析和处理处理算法,通常这些算法运算量大,而且又要满足实时或准时的快速高效处理要求,因此需采用高速DSP芯片,另外,在要求系统满足较好的通用性的同时,针对不同的应用和不断出现的新的处理方法,还要使系统便于功能的改进和扩展。
为此,我们以PC机为主机,以TMS320C50为信号处理核心设计了该系统,TMS320C50是美国Texas Instrument 公司的16位定点DSP产品,它包括改进的哈佛结构,高性能CPU,片内存储器,在外围接口以及一套高效的泄编指令集,计算速度可达40Mips且性能价格比较好。
1 语音信号压缩(A律)课程设计的目的及设计任务1.1课程设计的目的本设计的目的在于通过使用DSP的程序设计完成对语音信号的压缩,既可以通过软件实现,也可以通过硬件实现。
进行程序的设计,并在CCS软件环境下进行调试,同时也加深学生对数字信号处理器的常用指标和设计过程的理解。

A律压缩与解压缩算法实验原理:在进行A律压缩时,对于采样到的12位数据,默认其最高位为符号位,压缩时要保持最高位即符号位不变,原数据的后11位要压缩成7位。
这7位码由3位段落码和4位段内码组成。
具体的压缩变换后的数据根据后11位数据大小决定。
具体的编译码表如表5.2所示。
压缩后的数据的最高第7位)表示符号,量阶分别为1、1、2、4、8、16、32、64,由压缩后数据的第6位到第4位决定,第3位到第0位是段内码。
压缩后的数据有一定的失真。
有些数据不能表示出,只能取最近该数据的压缩值。
例如,数据125,压缩后的值为00111111,意义如下:程序如下所示:#include "stdio.h"int main() //验证方法{int m,n;int compress(int input);int decompress(int input);m=compress(-16); //输出m=129,因为符号位的关系10000001n=decompress(m); //输出n=-16,解压缩printf("%d\n",m);printf("%d\n",n);return 0;}//压缩函数int compress(int input){int i,inputtemp,seg,flag,offset;if(input<0) //获取最高位的符号位{flag = 1;inputtemp=-1*(input);}else{flag = 0;inputtemp = input;}inputtemp=(inputtemp>>4) & 0x7ff; //获取原始数据的除符号外的高位if(inputtemp < 16){return ((flag<<7) | inputtemp);}for(i=0;i<=6;i++){if(inputtemp < (1<<(5+i))){seg=(i+1); //段落码 offset=(inputtemp-(1<<(5+i-1)))/(1<<i); //段内码 return ((flag<<7) | (seg<<4) | offset); //压缩值}}return 0;}//解压缩函数int decompress(int input){int i,flag,seg,offset,temp;flag=input>>7; //获取最高位的符号位seg=(input>>4) & 0x0007; //段落码offset=input & 0x000f; //段内码if(seg == 0){temp=offset;}else{i=(seg-1);temp=(offset*(1<<i)+(1<<(5+i-1)));}if(flag==0)return (temp << 4);elsereturn ((-1)*(temp << 4)); }。

压缩与解压缩篇章一:压缩的概念与原理(300字左右)在计算机科学和信息技术领域中,压缩指的是将一个或多个文件或数据流转化为更紧凑的格式的过程。
压缩的目的是减小文件或数据流的大小,从而提高其存储效率和传输速度。
压缩的原理可以简单地概括为两个步骤:冗余消除和编码。
冗余消除是指通过消除文件或数据流中的冗余部分来减小大小。
冗余指的是文件或数据中出现的重复或不必要的信息。
编码是指将源文件或流转换为更紧凑的表示形式,以减少存储和传输所需的比特数。
压缩可以分为两种类型:有损压缩和无损压缩。
有损压缩是指在压缩过程中会有一定的数据丢失,但是可以获得更高的压缩比。
无损压缩是指压缩过程中不会丢失任何信息,但是压缩比相对较低。
篇章二:压缩算法的应用(350字左右)压缩算法在实际应用中有着广泛的用途。
以下是几个常见的应用场景:1. 文件压缩:通过对文件进行压缩,可以减小文件的大小,从而节省存储空间和提高传输速度。
常见的文件压缩格式包括ZIP、RAR和7-Zip等。
2. 音频压缩:音频文件通常占用较大的存储空间,而音频压缩可以将音频文件的大小减小到可接受的范围内。
著名的音频压缩格式包括MP3、AAC和FLAC等。
3. 图片压缩:图片文件也常常过大,通过对图片进行压缩可以将其大小减小,同时保持较高的图像质量。
JPEG和PNG是常见的图片压缩格式。
4. 视频压缩:视频文件通常非常庞大,通过对视频进行压缩可以减小文件的大小,方便存储和传输。
常见的视频压缩格式包括MPEG、AVI 和MP4等。
篇章三:解压缩工具与技术(350字左右)解压缩是压缩的逆过程,即将压缩后的文件或数据流恢复到原始的格式和大小。
解压缩通常使用专门的解压缩工具来实现。
常见的解压缩工具包括WinRAR、WinZIP和7-Zip等。
这些工具可以处理各种常见的压缩格式,并提供简单易用的界面。
此外,解压缩还有一些专用的技术和算法。
其中最常见的是哈夫曼编码,它通过将频率较高的字符用较短的编码表示,从而实现较高的压缩比。

文件压缩与解压文件压缩与解压是计算机领域中常见的操作,通过对文件进行压缩可以减小文件的大小,方便传输和存储,同时也可以提升系统的性能。
而解压则是将压缩的文件恢复到原始状态的过程。
本文将介绍文件压缩与解压的原理、常用工具以及使用技巧。
一、文件压缩的原理文件压缩的原理主要是通过消除或者替换文件中的冗余信息来减小文件的体积。
常用的文件压缩算法包括无损压缩和有损压缩两种。
1. 无损压缩无损压缩是指在压缩过程中不丢失任何信息的压缩方法。
常见的无损压缩算法有LZW(Lempel-Ziv-Welch)、DEFLATE等。
其中,DEFLATE算法被广泛应用于各种文件格式的压缩中,如ZIP压缩包。
2. 有损压缩与无损压缩不同,有损压缩是指在压缩的过程中会丢失一定的信息。
这种压缩方法常用于图像、音频和视频等多媒体文件的压缩。
著名的有损压缩算法有JPEG、MP3和H.264等。
二、常用的文件压缩与解压工具文件压缩与解压的工具有很多,下面将介绍几种常用的工具及其特点。
1. WinRARWinRAR是一款功能强大且广泛使用的文件压缩工具,它支持多种文件格式的压缩和解压,包括RAR、ZIP、7Z等。
WinRAR具有压缩率高、操作简便等特点,适用于Windows操作系统。
2. 7-Zip7-Zip是一款自由软件,支持Windows、Linux等多个操作系统,具有高压缩率、支持多种压缩格式的特点。
7-Zip主要支持7z、ZIP、RAR等格式的压缩和解压。
3. macOS内置的压缩与解压工具对于使用macOS的用户,系统内置了压缩与解压工具。
用户只需在Finder中对文件或文件夹进行右键点击,选择压缩选项即可生成压缩文件。
解压缩同样简单,只需双击压缩文件即可完成解压过程。
三、文件压缩与解压的使用技巧除了选择适用的压缩工具外,文件压缩与解压的使用技巧也能提升效率和便捷性。
下面介绍几个常用的技巧。
1. 创建压缩文件夹通过将多个文件或文件夹放入一个压缩文件夹中,可以方便地对多个文件进行批量压缩。
PCM技术概述数字交换系统可以直接处理,传送和交换数字信息,与模拟交换系统相比,抗干扰性强,易于时分多路复用,便于加密,适于信号处理和控制,便于引入远端集线器,易于集成容量大阻塞低的数字交换网络,并有利于实现数字交换与数字传输的直接联接,构成综合数字网(IDN),为向ISDN过渡奠定基础。
然而,目前的通信网仍然以模拟为主,用户终端多为模拟话机。
因而来自用户线的话音要进入数字交换机,需先在用户接口电路进行模数转换,将模拟话音编码成数字话音。
话音信号的数字化方法很多,常用的有脉冲编码调制(PCM),增量调制(DM),线性预测编码(LPC),以及某些改进的方案,如插值PCM(DPCM),自适应插值PCM(ADPCM),与自适应DM(ADM)等。
在程控数字交换机系统中,除个别的应用外,基本采用PCM数字化方法。
PCM历史形成脉冲编码调制的概念是1937年,由法国工程师Alec Reeres 最早出来的。
1946年美国Bell实验室实现了第一台PCM数字电话终端机。
1962年,晶体管PCM终端机大量应用于市话网中局间中继线,使市话电缆传输电话路数扩大24-30倍。
70年代后期,超大规模集成电路的PCM编、解码器的出现,使光纤通信、数字微波通信、卫星通信获得了更广泛的应用。
PCM应用原理PCM主要包括抽样,量化,与编码三种功能单元。
首先,模拟话音经防混叠低通滤波得到限带(300-3400HZ)的话路信号,将其抽样变成脉冲调幅(PAM)信号。
根据抽样定理,只要抽样频率fs不低于模拟信号最高频率fm的2倍,即fs>=2fm,则在接收端能够恢复出原模拟信号。
CCITT建议规定fs=8KHZ。
然后将幅度连续的抽样信号用四舍五入的方法量化为有限个采值的量化信号,再经编码,变换成二进制代码。
对于电话,CCITT G.711,712建议每抽样值编为8位码,这样共有256个量化级,因而每路模拟话音相应的数字话音相应的数字话音标准数码率为64kb/s.在PCM设备中,各路编码信号,先经时分多路复用,合成的码流再通过信道(或线路)传送到接收端。
数据结构中的压缩与解压缩算法在数据结构中,压缩与解压缩算法扮演着重要的角色。
它们可以显著减少数据存储和传输所需的空间和时间。
压缩算法使用各种技术来减少数据的大小,而解压缩算法则将压缩的数据还原到其原始状态。
本文将介绍几种常用的压缩与解压缩算法,并讨论它们的原理和应用。
一、哈夫曼编码哈夫曼编码是一种基于变长编码的压缩算法。
它通过根据输入数据中字符的频率来构建一棵哈夫曼树,并生成一个独特的编码表。
在哈夫曼编码中,频率较高的字符用较短的编码表示,而频率较低的字符用较长的编码表示。
这种编码方式可以大大减少数据的大小,并且可以在解压缩时快速还原原始数据。
二、LZW压缩LZW(Lempel-Ziv-Welch)压缩算法是一种基于字典的压缩算法。
它通过在压缩和解压缩过程中动态构建和更新字典,将输入数据中的字符串替换为对应的索引。
LZW压缩算法能够在保持数据质量的同时实现很高的压缩比。
它被广泛应用于图像、音频和视频等多媒体数据的压缩。
三、Run-Length编码Run-Length编码是一种简单但有效的压缩算法。
它通过将连续重复的字符或数据序列替换为一个标记和一个计数值来实现压缩。
例如,连续出现的字符 "AAAABBBCCD" 可以被编码为 "4A3B2C1D"。
Run-Length编码在处理包含大量连续重复数据的情况下非常有效,但对于非重复数据的压缩效果有限。
四、Burrows-Wheeler变换Burrows-Wheeler变换是一种用于数据压缩的重排和重新排列技术。
它通过对输入数据进行循环右移和排序,生成一个新的字符串。
然后,通过记录原始字符串的最后一个字符在排序后的字符串中的位置,以及排序后的字符串中的每个字符前一个字符的索引,可以实现数据的压缩。
解压缩时,通过逆向操作将压缩后的数据还原为原始数据。
以上介绍了几种常用的压缩与解压缩算法,它们在数据结构中起着重要的作用。
A律压缩律压缩、扩张仿真1.1 课题原理A律是ITU-T(国际电联电信标准局)CCITT G.712定义的关于脉冲编码的一种压缩/解压缩算法。
世界上大部分国家采用A律压缩算法。
A律是PCM非均匀量化中的一种对数压扩形式,脉冲编码调制PCM是对一个时间连续的模拟信号先抽样,再对样值幅度量化,编码的过程其中量化,就是把经过抽样得到的瞬时值将其幅度离散,即用一组规定的电平,把瞬时抽样值用最接近的电平值来表示,通常是用二进制表示。
而量化中会出现误差,即量化后的信号和抽样信号的差值,量化误差在接收端表现为噪声,称为量化噪声。
量化级数越多误差越小,相应的二进制码位数越多,要求传输速率越高,频带越宽。
为使量化噪声尽可能小而所需码位数又不太多,通常采用非均匀量化的方法进行量化。
非均匀量化根据幅度的不同区间来确定量化间隔,幅度小的区间量化间隔取得小,幅度大的区间量化间隔取得大。
令量化器过载电压为1,相当于把输入信号进行归一化,那么A律对数压缩定义为:当0 <= x <= 1/A时,f(x)=(Ax)/(1+lnA)当1/A <= x <= 1时,f(x)=(1+lnAx)/(1+lnA)在现行的国际标准中A=87.6,此时信号很小时(即小信号时),从上式可以看到信号被放大了16倍,这相当于与A压缩率与无压缩特性比较,对于小信号的情况,量化间隔比均匀量化时减小了16倍,因此,量化误差大大降低;而对于大信号的情况例如x=1,量化间隔比均匀量化时增大了5.47倍,量化误差增大了。
这样实际上就实现了“压大补小”的效果。
A律十三折线用折线实现压扩特性,它既不同于均匀量化的直线,又不同于对数压扩特性的光滑曲线。
虽然总的来说用折线作压扩持性是非均匀量化,但它既有非均匀(不同折线有不同斜率)量化,又有均匀量化(在同一折线的小范围内)。
有两种常用的数字压扩技术,一种是13折线A律压扩,它的特性近似A=87.6的A 律压扩特性。
对数压缩方法a律和μ律
对数压缩方法是一种信号处理技术,常用于音频编码和数字通
信系统中。
其中,a律(A-law)和μ律(Mu-law)是两种常见的
对数压缩方法。
首先,让我们来谈谈a律。
a律是一种非线性的对数压缩方法,主要用于欧洲的数字通信系统。
在a律编码中,输入信号的动态范
围被压缩,以便更有效地表示和传输信号。
a律编码使用一个非线
性的转换函数,将输入信号映射到一个更小的范围内。
这种非线性
压缩可以更好地保留信号的动态范围,尤其在低幅度信号的处理上
效果更为明显。
a律编码通常用于电话系统中,其压缩特性能够更
好地适应人耳的特性,提高了信噪比和动态范围。
接下来,我们来看看μ律。
μ律是另一种非线性的对数压缩
方法,主要用于北美和日本的数字通信系统。
μ律编码也使用非线
性的转换函数,将输入信号进行压缩以便更有效地表示和传输。
与
a律相似,μ律编码也能更好地保留信号的动态范围,特别是在低
幅度信号的处理上效果更为显著。
μ律编码在音频编码和数字通信
系统中得到广泛应用,尤其在存储和传输音频数据时,能够有效地
减少数据量并保持音质。
总的来说,a律和μ律都是非线性的对数压缩方法,它们在不同的地区和应用中得到了广泛的应用。
它们能够有效地压缩信号的动态范围,提高传输效率和保持音频质量。
选择使用哪种方法取决于具体的应用需求和所处地区的标准。
希望这些信息能够帮助你更好地理解对数压缩方法a律和μ律。
解压缩原理解压缩,顾名思义就是将压缩过的文件或文件夹进行还原,使其恢复到原来的大小和格式。
在计算机领域中,压缩和解压缩是非常常见的操作,它们可以有效地减小文件的大小,提高存储和传输效率。
而解压缩原理则是指解压缩操作的工作原理和过程。
本文将对解压缩原理进行详细介绍,希望能够对您有所帮助。
首先,我们需要了解压缩的原理。
在计算机中,压缩是通过一些算法和技术来减小文件的大小,常见的压缩算法有LZ77、LZ78、哈夫曼编码等。
这些算法可以通过消除文件中的冗余信息或者利用更高效的编码方式来实现文件的压缩。
在压缩过程中,文件会被重新编码,使其变得更加紧凑和高效。
接下来,我们来看一下解压缩的原理。
解压缩就是将压缩过的文件还原到原来的大小和格式。
在解压缩过程中,计算机会根据压缩时使用的算法和技术,将文件重新解码并恢复到原来的状态。
这个过程需要计算机进行一系列的操作,包括解码、还原和重建文件结构等步骤。
在实际的解压缩过程中,计算机会首先读取压缩文件的头部信息,获取文件的压缩算法和压缩前的大小等信息。
然后,计算机会根据这些信息来进行解压缩操作,将文件逐步还原到原来的状态。
在这个过程中,计算机需要进行解码和重建文件结构等操作,以确保文件能够完整地恢复。
除了以上提到的基本原理之外,解压缩的过程还涉及到一些具体的技术和算法。
例如,对于不同的压缩格式,解压缩的方法和过程也会有所不同。
在实际应用中,我们通常会使用一些专门的解压缩软件来进行解压缩操作,这些软件会根据文件的格式和算法来进行相应的解压缩处理,使得解压缩操作更加方便和高效。
总的来说,解压缩原理是基于压缩算法和技术实现的,它通过一系列的解码和重建操作,将压缩过的文件还原到原来的状态。
在实际应用中,我们可以通过一些专门的解压缩软件来进行解压缩操作,以提高效率和便利性。
希望本文对您理解解压缩原理有所帮助,谢谢阅读!。
A律压缩与解压缩算法
实验原理:
在进行A律压缩时,对于采样到的12位数据,默认其最高位为符号位,压缩时要保持最高位即符号位不变,原数据的后11位要压缩成7位。
这7位码由3位段落码和4位段内码组成。
具体的压缩变换后的数据根据后11位数据大小决定。
具体的编译码表如表5.2所示。
压缩后的数据的最高第7位)表示符号,量阶分别为1、1、2、4、8、16、32、64,由压缩后数据的第6位到第4位决定,第3位到第0位是段内码。
压缩后的数据有一定的失真。
有些数据不能表示出,只能取最近该数据的压缩值。
例如,数据125,压缩后的值为00111111,意义如下:
程序如下所示:
#include "stdio.h"
int main() //验证方法
{
int m,n;
int compress(int input);
int decompress(int input);
m=compress(-16); //输出m=129,因为符号位的关系10000001
n=decompress(m); //输出n=-16,解压缩
printf("%d\n",m);
printf("%d\n",n);
return 0;
}
//压缩函数
int compress(int input)
{
int i,inputtemp,seg,flag,offset;
if(input<0) //获取最高位的符号位
{
flag = 1;
inputtemp=-1*(input);
}
else
{
flag = 0;
inputtemp = input;
}
inputtemp=(inputtemp>>4) & 0x7ff; //获取原始数据的除符号外的高位
if(inputtemp < 16)
{
return ((flag<<7) | inputtemp);
}
for(i=0;i<=6;i++)
{
if(inputtemp < (1<<(5+i)))
{
seg=(i+1); //段落码 offset=(inputtemp-(1<<(5+i-1)))/(1<<i); //段内码 return ((flag<<7) | (seg<<4) | offset); //压缩值}
}
return 0;
}
//解压缩函数
int decompress(int input)
{
int i,flag,seg,offset,temp;
flag=input>>7; //获取最高位的符号位
seg=(input>>4) & 0x0007; //段落码
offset=input & 0x000f; //段内码
if(seg == 0)
{
temp=offset;
}
else
{
i=(seg-1);
temp=(offset*(1<<i)+(1<<(5+i-1)));
}
if(flag==0)
return (temp << 4);
else
return ((-1)*(temp << 4)); }。