OraGiST - How to Make User-Defined Indexing Become Usable and Useful
- 格式:pdf
- 大小:82.41 KB
- 文档页数:10

Oracle⾃定义异常处理--第⼀种⽅式:使⽤raise_application_error抛出⾃定义异常declarei number:=-1;beginif i=-1thenraise_application_error(-20000,'参数值不能为负'); --抛出⾃定义异常end if;exceptionwhen others thendbms_output.put_line('err_code:'||sqlcode||';err_msg:'||sqlerrm); --进⾏异常处理raise; --继续抛出该异常end;--第⼆种⽅式,使⽤ exception 进⾏异常的定义declarei number:=-1;my_err exception; --⾃定义异常PRAGMA EXCEPTION_INIT(my_err, -01476); --初始化异常(我理解就是将该异常绑定到某个错误代码上)beginif i=-1thenraise my_err; --抛出⾃定义异常end if;exceptionwhen my_err then--捕捉⾃定义异常dbms_output.put_line('err_code:'||sqlcode||';err_msg:'||sqlerrm); --异常处理raise; --继续抛出这个⾃定义异常when others then--捕捉其它异常dbms_output.put_line('err_code:'||sqlcode||';err_msg:'||sqlerrm); --异常处理raise; --继续抛出异常end;EXCEPTIONWHEN l_exit THEN var_o_message := var_o_message; OPEN user_cusor FOR'SELECT '''|| var_o_message ||''' AS VAR_O_MESSAGE FROM DUAL WHERE ROWNUM=1';WHEN OTHERS THEN var_o_message := var_o_message || SQLERRM(SQLCODE) || dbms_utility.format_error_backtrace(); OPEN user_cusor FOR'SELECT '''|| var_o_message ||''' AS VAR_O_MESSAGE FROM DUAL WHERE ROWNUM=1';END;第⼀种⽅式⾃定义异常的代码范围为:-20000到-20300第⼆种⽅式的好处是,可以将⾃定义异常绑定到某上具体的预定义错误代码上,如ORA-01476: divisor is equal to zero这样我们就可以捕捉⾃定义异常⽽不需要⽤ others 进⾏捕捉了.但也不是所有的预定义异常都可以绑定,这个需要使⽤的时候⾃⼰多试试Oracle内置函数SQLCODE和SQLERRM是特别⽤在OTHERS处理器中,分别⽤来返回Oracle的错误代码和错误消息。

Oracle 命令Array Oracle用户管理:创建一个用户:create user 用户名identified by 密码(密码必须以字母开头)给用户修给密码:password 用户名修改用户密码:alter user 用户名identified by 新密码删除用户:drop user 用户名[cascade]授权用户登录dba:grant conn(connect) to 用户名授予用户查询emp表权限:grant select on emp to 用户名授予用户修改emp表权限:grant update on emp to 用户名授予用户修改/删除/查修权限:grant all on emp to 用户名收回用户对emp表的权限:revoke select/update on emp from 用户名希望xiaoming用户可以把查询权限授予别的用户:grant select on scott.emp to xiaoming with grant option;(如果收回xiaoming对emp查询的权限,那么xiaoming授予用户也会受到诛连) 用户锁定:指定用户用户登录最多可以输入密码的次数。
例子:指定scott这个用户最多尝试3次登录,锁定时间为2天。
创建profile文件:create profile lock_account limit failed_login_attempts 3 password_lock_time 2;alter user scott profile lock_account;给用户解锁:alter user 用户名account unlock;终止口令:create profile myprofile limit password_life_time 10 password_grace_time 2;alter user 用户名profile myprofile;口令历史:如果希望用户在修改密码时不能用以前的密码。

如果你管理的Oracle数据库下某些应用项目有大量的修改删除操作,数据索引是需要周期性的重建的。
它不仅可以提高查询性能,还能增加索引表空间空闲空间大小。
在ORACLE里大量删除记录后,表和索引里占用的数据块空间并没有释放。
重建索引可以释放已删除记录索引占用的数据块空间。
转移数据,重命名的方法可以重新组织表里的数据。
下面是可以按ORACLE用户名生成重建索引的SQL脚本:SET ECHO OFF;SET FEEDBACK OFF;SET VERIFY OFF;SET PAGESIZE 0;SET TERMOUT ON;SET HEADING OFF;ACCEPT username CHAR PROMPT 'Enter the index username: ';spool /oracle/rebuild_&username.sql;SELECT'REM +-----------------------------------------------+' || chr(10) ||'REM | INDEX NAME : ' || owner || '.' || segment_name|| lpad('|', 33 - (length(owner) + length(segment_name)) )|| chr(10) ||'REM | BYTES : ' || bytes|| lpad ('|', 34-(length(bytes)) ) || chr(10) ||'REM | EXTENTS : ' || extents|| lpad ('|', 34-(length(extents)) ) || chr(10) ||'REM +-----------------------------------------------+' || chr(10) ||'ALTER INDEX ' || owner || '.' || segment_name || chr(10) ||'REBUILD ' || chr(10) ||'TABLESPACE ' || tablespace_name || chr(10) ||'STORAGE ( ' || chr(10) ||' INITIAL ' || initial_extent || chr(10) ||' NEXT ' || next_extent || chr(10) ||' MINEXTENTS ' || min_extents || chr(10) ||' MAXEXTENTS ' || max_extents || chr(10) ||' PCTINCREASE ' || pct_increase || chr(10) ||');' || chr(10) || chr(10)FROM dba_segmentsWHERE segment_type = 'INDEX'AND owner='&username'ORDER BY owner, bytes DESC;spool off;如果你用的是WINDOWS系统,想改变输出文件的存放目录,修改spool后面的路径成:spool c:oraclerebuild_&username.sql;如果你只想对大于max_bytes的索引重建索引,可以修改上面的SQL语句:在AND owner='&username' 后面加个限制条件AND bytes> &max_bytes 如果你想修改索引的存储参数,在重建索引rebuild_&username.sql里改也可以。


Oracle用户自定义异常注意:普通的查询语句不会出现异常,只有使用into对变量进行赋值的时候才会发生异常1 --系统变量: notfound --> if sql%notfund then 如果这个表达式为真,则(增删改)出错2 --,先自定义一个异常:no_result exception3 -- if sql%nofund then4 --excetpion5 --when no_result then6 --dbms……用户自定义异常写在:declare里,如:1 set serveroutput on2 declare3 no_result exception; --自定义异常4 v_ssid student_test.sid%type;1 begin2 update student_test set sex='男' where sid=1000002; --没有异常,报(自定义异常)插入为空的错误3 if SQL%NOTFOUND then4 RAISE no_result;5 end if;6 exception7 when no_result then8 dbms_output.put_line('修改有误!');9 when dup_val_on_index then10 dbms_output.put_line('系统异常,违反主键约束');11 end;如果修改语句修改为空,系统不会报错,但会直接进入用户自己定义的no_result异常里,if SQL%NOTFOUND thenRAISE no_result;end if;SQL%NOTFOUND是检查更新语句是否更新成功,如果更新失败,则notfound语句为真,则使用raise语句跳转到no_result异常执行。
(dup_val_on_index)异常是系统异常,如果使用插入语句并且违反主键唯一性约束,则执行dup_val_on_index异常。
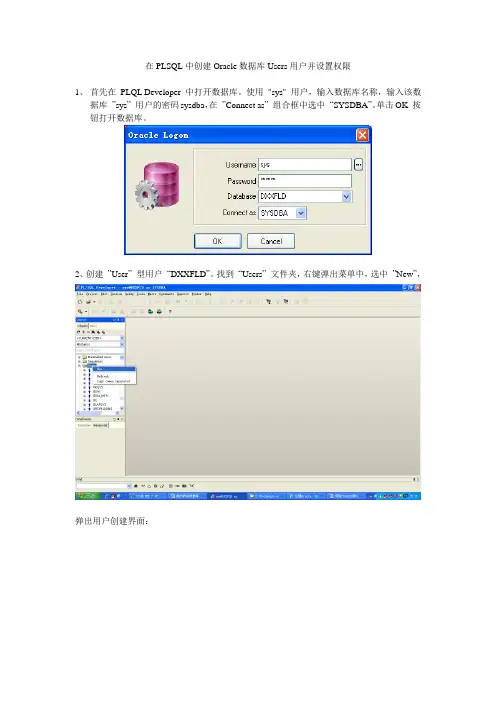
在PLSQL中创建Oracle数据库Users用户并设置权限
1、首先在PLQL Developer 中打开数据库。
使用"sys" 用户,输入数据库名称,输入该数
据库”sys”用户的密码sysdba,在”Connect as”组合框中选中“SYSDBA”。
单击OK 按钮打开数据库。
2、创建”User”型用户“DXXFLD”。
找到“Users”文件夹,右键弹出菜单中,选中”New”,
弹出用户创建界面:
在其中输入要添加的用户名”DXXFLD”,并作其他设置如下:
户名连接到数据库。
然后通过“Quotas”选项卡设置用户权限:将“Tablespace”中选中“User”, 勾选“Unlimited”复选项(这个一定要选中啊,不然创建表的时候会提示没有表空间的访问权限
的)。
最后单击”Apply”按钮使各项设置起作用。
2、使用新创建的用户创建表。
在”Tables”文件夹上右键单击,选中弹出菜单中“New”选
项
在之后弹出属性页下,做如下设置:
然后再设置字段名等其他属性就和直接用“System”或“Sys”等表空间创建表一样了。
要说明的是使用自定义”Users”创建的表,其在PLSQL 中“Users“->”Tables”目录下才
可见。

oracle shell oracle sql语句-回复【Oracle Shell Oracle SQL语句】是指在Oracle数据库环境下使用Oracle SQL语句的命令行工具。
它通过命令行输入SQL语句来操作和查询数据库,具有灵活性和高效性。
本文将详细介绍Oracle Shell Oracle SQL语句的使用方法和一些常用语句示例。
第一步:安装和配置Oracle Shell1. 下载Oracle数据库软件,并按照官方文档进行安装。
2. 配置环境变量。
在Linux/Unix系统中,可以在".bash_profile"文件中添加以下内容:export ORACLE_HOME=/path/to/oracleexport PATH=ORACLE_HOME/bin:PATH3. 重新加载.bash_profile文件,使环境变量生效。
source ~/.bash_profile第二步:连接Oracle数据库1. 打开终端,输入以下命令登录到Oracle数据库:sqlplus 用户名/密码2. 如果成功登录,将显示“Connected to Oracle...”的信息,说明连接成功。
第三步:执行SQL语句在Oracle Shell中,可以执行各种SQL语句来操作和查询数据库。
下面是一些常用的SQL语句示例:1. 创建表CREATE TABLE 表名(列名数据类型,列名数据类型,...);例如,创建一个名为"employees"的表:CREATE TABLE employees (employee_id NUMBER,first_name VARCHAR2(50),last_name VARCHAR2(50),hire_date DATE);2. 插入数据INSERT INTO 表名(列名1, 列名2, ...) VALUES (值1, 值2, ...);例如,向"employees"表中插入数据:INSERT INTO employees (employee_id, first_name, last_name, hire_date)VALUES (1, 'John', 'Doe', TO_DATE('2022-01-01', 'YYYY-MM-DD'));3. 查询数据SELECT 列名1, 列名2, ... FROM 表名WHERE 条件;例如,查询"employees"表中所有员工的姓名和入职日期:SELECT first_name, last_name, hire_dateFROM employees;4. 更新数据UPDATE 表名SET 列名1 = 值1, 列名2 = 值2 WHERE 条件;例如,将"employees"表中员工ID为1的姓名更新为"Jane":UPDATE employees SET first_name = 'Jane' WHERE employee_id = 1;5. 删除数据DELETE FROM 表名WHERE 条件;例如,从"employees"表中删除姓名为"Jane"的员工:DELETE FROM employees WHERE first_name = 'Jane';6. 创建索引CREATE INDEX 索引名ON 表名(列名);例如,为"employees"表的"employee_id"列创建索引:CREATE INDEX emp_id_idx ON employees (employee_id);第四步:退出Oracle Shell在使用完Oracle Shell后,可以输入以下命令退出:EXIT;总结:本文介绍了使用Oracle Shell执行Oracle SQL语句的基本步骤和常用语句示例。

oracle手工建库方法1、建立口令文件,用于sys用户远程登录的认证(remote_login_passwordfile=exclusive),位置$ORACLE_HOME/dbs/orapwSID.创建命令:orapwd[oracle@work dbs]$orapwd file=orapwprod password=oracle entries=5force=yremote_login_passwordfile1)none拒绝sys用户从远程连接2)exclusive sys用户可以从远程连接3)share多个库可以共享口令文件SQL>ALTER SYSTEM SET remote_login_passwordfile=NONE SCOPE=SPFILE【拒绝远程登录】2、创建init parameter文件[oracle@oracle dbs]$more initdw.ora|grep-v'^#'|grep-v'^$'>initlx02.ora建立目录[oracle@oracle dbs]$mkdir-p$ORACLE_BASE/admin/lx02/bdump[oracle@oracle dbs]$mkdir-p$ORACLE_BASE/admin/lx02/cdump[oracle@oracle dbs]$mkdir-p$ORACLE_BASE/admin/lx02/udump[oracle@oracle dbs]$mkdir-p$ORACLE_BASE/oradata/lx02【存放控制文件的位置】修改初始化文件[oracle@oracle dbs]$vi initlx02.oradb_name=lx02sga_target=300Mdb_block_size=8192pga_aggregate_target=30Mdb_cache_size=80Mshared_pool_size=60Mparallel_threads_per_cpu=4optimizer_mode=choosestar_transformation_enabled=truedb_file_multiblock_read_count=16query_rewrite_enabled=truequery_rewrite_integrity=trustedbackground_dump_dest=$ORACLE_BASE/admin/lx02/bdumpuser_dump_dest=$ORACLE_BASE/admin/lx02/udumpcore_dump_dest=$ORACLE_BASE/admin/lx02/cdumpcontrol_files=$ORACLE_BASE/oradata/lx02/control01.ctlundo_management=autoundo_tablespace=rtbs3、建立建库脚本1、库名2、表空间及数据文件的位置和大小3、redo日志文件的位置和大小4、字符集(1)建库脚本:vi cr_db.sqlCREATE DATABASE annyUSER SYS IDENTIFIED BY oracleUSER SYSTEM IDENTIFIED BY oracleLOGFILE GROUP1('/u01/app/oracle/oradata/anny/redo01.log')SIZE100M,GROUP2('/u01/app/oracle/oradata/anny/redo02.log')SIZE100M,GROUP3('/u01/app/oracle/oradata/anny/redo03.log')SIZE100MMAXLOGFILES10MAXLOGMEMBERS5MAXLOGHISTORY1MAXDATAFILES100MAXINSTANCES1CHARACTER SET zhs16gbkNATIONAL CHARACTER SET AL16UTF16DATAFILE'/u01/app/oracle/oradata/anny/system01.dbf'SIZE325M REUSEEXTENT MANAGEMENT LOCAL(启动本地管理空闲区)SYSAUX DATAFILE'/u01/app/oracle/oradata/anny/sysaux01.dbf'SIZE325M REUSEDEFAULT TEMPORARY TABLESPACE tempTEMPFILE'/u01/app/oracle/oradata/anny/temp01.dbf'SIZE20M REUSEUNDO TABLESPACE rtbs【这个名字要和初始化文件的一致】DATAFILE'/u01/app/oracle/oradata/anny/rtbs01.dbf'SIZE200M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;【根据自己的实际需求更改】告警日志信息:create tablespace SYSTEM datafile'$ORACLE_BASE/oradata/test/system01.dbf'size400mdefault storage(initial10K next10K)onlineSat Aug2000:26:342011Completed:create tablespace SYSTEM datafile'$ORACLE_BASE/oradata/test/system01.dbf'size 400mdefault storage(initial10K next10K)EXTENT MANAGEMENT DICTIONARY onlineSat Aug2000:26:342011create rollback segment SYSTEM tablespace SYSTEMstorage(initial50K next50K)Completed:create rollback segment SYSTEM tablespace SYSTEMstorage(initial50K next50K)Sat Aug2000:26:492011Thread1advanced to log sequence2Current log#2seq#2mem#0:/u01/app/oracle/oradata/test/redo02a.logSat Aug2000:26:502011CREATE UNDO TABLESPACE RTBS DATAFILE'$ORACLE_BASE/oradata/test/rtbs01.dbf'size100m Sat Aug2000:26:512011Successfully onlined Undo Tablespace1.Completed:CREATE UNDO TABLESPACE RTBS DATAFILE'$ORACLE_BASE/oradata/test/rtbs01.dbf'size100mSat Aug2000:26:512011create tablespace SYSAUX datafile'$ORACLE_BASE/oradata/test/sysaux01.dbf'size100m EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO onlineCompleted:create tablespace SYSAUX datafile'$ORACLE_BASE/oradata/test/sysaux01.dbf'size 100mEXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO onlineSat Aug2000:26:542011CREATE TEMPORARY TABLESPACE TEMP TEMPFILE'$ORACLE_BASE/oradata/test/temp01.dbf' size100mCompleted:CREATE TEMPORARY TABLESPACE TEMP TEMPFILE'$ORACLE_BASE/oradata/test/temp01.dbf'size100mSat Aug2000:26:552011ALTER DATABASE DEFAULT TEMPORARY TABLESPACE TEMPCompleted:ALTER DATABASE DEFAULT TEMPORARY TABLESPACE TEMPSat Aug2000:26:552011ALTER DATABASE DEFAULT TABLESPACE SYSTEMCompleted:ALTER DATABASE DEFAULT TABLESPACE SYSTEMSat Aug2000:27:012011SMON:enabling tx recoverySat Aug2000:27:022011Threshold validation cannot be done before catproc is loaded.replication_dependency_tracking turned off(no async multimaster replication found)Starting background process QMNCQMNC started with pid=13,OS id=6485Sat Aug2000:27:032011Completed:create database testuser sys identified by**user system identified by*datafile'$ORACLE_BASE/oradata/test/system01.dbf' size400msysaux datafile'$ORACLE_BASE/oradata/test/sysaux01.dbf'size100mundo tablespace rtbs datafile'$ORACLE_BASE/oradata/test/rtbs01.dbf'size100mdefault temporary tablespace temp tempfile'$ORACLE_BASE/oradata/test/temp01.dbf'size100m logfilegroup1'$ORACLE_BASE/oradata/test/redo01a.log'size10m,group2'$ORACLE_BASE/oradata/test/redo02a.log'size10m,group3'$ORACLE_BASE/oradata/test/redo03a.log'size10mcharacter set zhs16gbk(2)export ORACLE_SID=lx02(3)启动数据库到nomount状态,startup nomount(4)启动告警日志tail-f/$ORACLE_BASE/admin/lx02/bdump(5)运行建库脚本:@/export/home/oracle/cr_db.sql4、建立数据字典创建数据字典脚本:vi cr_dict.sql@$ORACLE_HOME/rdbms/admin/catalog.sql@$ORACLE_HOME/rdbms/admin/catproc.sqlconn system/oracle@$ORACLE_HOME/sqlplus/admin/pupbld.sql执行数据字典脚本:@/export/home/oracle/cr_dict.sql5、创建users表空间,作为普通用户的默认表空间SQL>select tablespace_name from dba_tablespaces;【如果执行不成功,说明上一步有问题】TABLESPACE_NAME------------------------------SYSTEMRTBSSYSAUXTEMP4rows selected.08:08:27SQL>col file_name for a5008:08:37SQL>select file_id,file_name,tablespace_name from dba_data_files;FILE_ID FILE_NAME TABLESPACE_NAME------------------------------------------------------------------------------------------1/u01/app/oracle/oradata/lx02/system01.dbf SYSTEM2/u01/app/oracle/oradata/lx02/rtbs01.dbf RTBS3/u01/app/oracle/oradata/lx02/sysaux01.dbf SYSAUXSQL>create tablespace users2datafile'/u01/app/oracle/oradata/lx02/user01.dbf'size100m;【创建表空间】Tablespace created.select*from database_properties;【查看数据库的属性】SQL>alter database default tablespace users;【修改users的默认表空间】Database altered.08:10:45SQL>select file_id,file_name,tablespace_name from dba_data_files;【查看数据文件】FILE_ID FILE_NAME TABLESPACE_NAME------------------------------------------------------------------------------------------1/u01/app/oracle/oradata/lx02/system01.dbf SYSTEM2/u01/app/oracle/oradata/lx02/rtbs01.dbf RTBS3/u01/app/oracle/oradata/lx02/sysaux01.dbf SYSAUX4/u01/app/oracle/oradata/lx02/user01.dbf USERSSQL>select file_name,file_id,tablespace_name from dba_temp_files;【查看临时表空间,临时表不和数据文件放在一起】FILE_NAME FILE_ID TABLESPACE_NAME----------------------------------------------------------------------------------------------------------------------------------/u01/app/oracle/oradata/anny/temp01.dbf1TEMPselect username,default_tablespace,temporary_tablespace from dba_users;【查看用户的默认表空间】USERNAME DEFAULT_TABLESP TEMPORARY_TABLESPACE------------------------------------------------------------------------------------------------------------------------OUTLN SYSTEM TEMPSYS SYSTEM TEMPSYSTEM SYSTEM TEMPSCOTT USERS TEMPTOM USERS TEMPDBSNMP SYSAUX TEMPTSMSYS USERS TEMPDIP USERS TEMP4rows selected.6、添加scott案例SQL>@$ORACLE_HOME/rdbms/admin/utlsampl.sql【运行该脚本就可以使用系统模板】Disconnected from Oracle Database10g Enterprise Edition Release10.2.0.1.0-Production With the Partitioning,OLAP and Data Mining options到此,完成手工建库~~。

刚创建的用户怎样才能成功创建一个表当一个用户刚被创建时是不具备任何权限的,因此要在该用户模式下创建表,需授予CREATE SESSION、CREATE TABLE、以及UNLIMITED TABLESPACE(或分配配额)权限,因为:当用户要连接到数据库时必须拥有CREATE SESSION权限当用户要创建表时必须拥有CREATE TABLE权限,同时用户还需要在表空间中拥有配额或者被授予UNLIMITED TABLESPACE。
现在我们来做一个测试:1)、创建用户TEST,密码为passwd_1:SQL> CREATE USER testIDENTIFIED BY passwd_I1用户已创建2)当用TEST连接数据库时:SQL> conn test/passwd_1ERROR:ORA-01045: user TEST lacks CREATE SESSION privilege; logon denied警告: 您不再连接到 ORACLE。
//因为缺少CREATE SESSION的权限,登陆失败。
3)利用SYS给TEST授予CREATE SESSION权限:SQL> grant create session to test;授权成功。
4)SQL> conn test/passwd_1已连接。
5)在test的方案中创建表exam1:SQL> create table exam1(student_id int,paper_id int);create table exam1ERROR 位于第 1 行:ORA-01031: 权限不足//因为未给TEST用户授予create table 权限,因此不能够创建表exam1. 6) 给TEST用户授予CRETE TABLE 权限SQL> grant create table to test;授权成功。
7)SQL> create table exam1(student_id int,paper_id int);create table exam1ERROR 位于第 1 行:ORA-01950: 表空间'SYSTEM'中无权限//因为在创建用户时没有指定表空间,因此默认的表空间是SYSTEM表空间,而TEST用户还需要在表空间SYSTEM中既没有拥有配额又没有被授予UNLIMITED TABLESPACE权限,因此对于这种情况有两种解决办法://在SYSTEM表空间中,给用户TEST分配15M的使用空间SQL> create table exam1(student_id int,paper_id int);表已创建第二种方法:SQL> grant unlimited tablespace to test(在system中授权)授权成功。
Oracle数据库操作中,假如在原始表TB_HXL_USER上新增字段remark01,默认值为'A',但是由于该表的数据量比较大,直接在原表上新增字段,执行的时间特别长,最后还报出了undo空间不足的问题。
而且在新增字段的过程中,其他用户还不能访问该表,出现的等待事件是library cache lock。
下面试着通过在线重定义的方法新增字段,能够避免undo空间不足以及其他用户不能访问该表的情况。
1.使用如下SQL获取原始表的DDL设置分隔符号以及去掉表DDL中的storage属性:1.begin2.3.Dbms_Metadata.Set_Transform_Param(Dbms_Metadata.Session_Transform,4.5.'SQLTERMINATOR',6.7.True);8.9.Dbms_Metadata.Set_Transform_Param(Dbms_Metadata.Session_Transform,10.11.'STORAGE',12.13.False);14.15.end;提取表,索引,约束以及权限的语句。
1.Select Dbms_Metadata.Get_Ddl(Object_Type => 'TABLE', Name => 'TB_HXL_USER') ||2.3.Dbms_Metadata.Get_Dependent_Ddl(Object_Type => 'INDEX',4.5.Base_Object_Name => 'TB_HXL_USER') ||6.7.Dbms_Metadata.Get_Dependent_Ddl(Object_Type => 'CONSTRAINT',8.9.Base_Object_Name => 'TB_HXL_USER') ||10.11.Dbms_Metadata.Get_Dependent_Ddl('OBJECT_GRANT', 'TB_HXL_USER', 'HXL')12.13.From Dual2.将步骤1 SQL中的表名TB_HXL_USER 替换为TB_HXL_USER_MID 创建中间表3.中间表新增字段 remark011.alter table TB_HXL_USER_MID add remark01 varchar2(10) default 'A';4.检查能否进行重定义,过程执行成功即说明可以重定义1.Begin2.3.Dbms_Redefinition.Can_Redef_Table(USER, 'TB_HXL_USER');4.5.End;5.开始重定义表注意:如原始表有未提交的事物,该过程会一直在等待,等待事件为enq: TX - row lock contention。

oracle create user语句摘要:1.Oracle 创建用户的基本语法2.Oracle 创建用户的步骤3.Oracle 创建用户的注意事项正文:一、Oracle 创建用户的基本语法Oracle 数据库创建用户的基本语法如下:```CREATE USER [USERNAME] IDENTIFIED BY [PASSWORD]PROFILE [PROFILE_NAME]```- USERNAME:要创建的用户名- PASSWORD:用户的密码- PROFILE_NAME:可选项,指定用户所属的角色二、Oracle 创建用户的步骤1.打开Oracle SQL*Plus 或使用其他工具连接到Oracle 数据库。
2.输入以下命令,创建用户:```CREATE USER example_user IDENTIFIED BY example_password PROFILE default_role```3.如果要创建多个用户,可以使用以下命令:```CREATE USER example_user1 IDENTIFIED BY example_password1 CREATE USER example_user2 IDENTIFIED BY example_password2 ```三、Oracle 创建用户的注意事项1.用户名和密码必须符合Oracle 的命名规则,例如,用户名长度应在1 到30 个字符之间,密码长度应在8 到20 个字符之间。
2.在创建用户时,可以指定用户所属的角色。
如果不指定,则用户将默认属于"DEFAULT"角色。
3.在创建用户后,可以使用"ALTER USER"命令对用户进行修改,例如更改用户名、密码或角色等。
oraclegrant授权语句--select * from dba_users; 查询数据库中的所有⽤户 --alter user TEST_SELECT account lock; 锁住⽤户 --alter user TEST_SELECT account unlock; 给⽤户解锁 --create user xujin identified by xujin; 建⽴⽤户 --grant create tablespace to xujin; 授权 --grant select on tabel1 to xujin; 授权查询 --grant update on table1 to xujin; --grant execute on procedure1 to xujin 授权存储过程 --grant update on table1 to xujin with grant option; 授权更新权限转移给xujin⽤户,许进⽤户可以继续授权; --收回权限 --revoke select on table1 from xujin1; 收回查询select表的权限; --revoke all on table1 from xujin; /*grant connect to xujin; revoke connect from xujin grant select on xezf.cfg_alarm to xujin; revoke select on xezf.cfg_alarm from xujin;*/ --select table_name,privilege from dba_tab_privs where grantee='xujin' 查询⼀个⽤户拥有的对象权限 --select * from dba_sys_privs where grantee='xujin' 查询⼀个⽤户拥有的系统权限 --select * from session_privs --当前会话有效的系统权限 --⾓⾊ --create role xujin1;--建⽴xujin1⾓⾊ --grant insert on xezf.cfg_alarm to xujin1; 将插⼊表的信息 --revoke insert on xezf.cfg_alarm from xujin1; 收回xujin1⾓⾊的权限 --grant xujin1 to xujin ; 将⾓⾊的权限授权给xujin; -- create role xujin2; --grant xujin1 to xujin2; 将⾓⾊xujin1授权给xujin2; --alter user xujin default xujin1,xujin2; 修改⽤户默认⾓⾊ -- DROP ROLE xujin1;删除⾓⾊1; --select * from role_sys_privs where role=xujin1; --查看许进1⾓⾊下有什么系统权限; --select granted_role,admin_option from role_role_privs where role='xujin2'; --查看xujin1⾓⾊下⾯有什么⾓⾊权限 --select * from role_sys_privs where role='xujin2'; --select table_name,privilege from role_tab_privs where role='xujin1'; --select * from dba_role_privs where grantee='xujin' --查看⽤户下⾯有多少个⾓⾊;。
oracle,创建⽤户,授予⽤户各种权限;ORA-01939错误;ORA-01950错误;。
...3个默认的⽤户:sys orcl [as sysdba]system orclscott tiger创建⽤户:create user gis /*⽤户名*/ identified by gis /*密码*/ ;PRIVILEGE:权限系统权限:grant(revoke) create session to(from) gis;grant(revoke) create table to(from) gis;grant(revoke) unlimited tablespace to(from) gis;grant create seesion to public; #将权限授予所有⽤户。
select * from user_sys_privs; 查看当前⽤户的系统权限。
对象权限:grant(revoke) select on mytable to(from) gis;grant(revoke) all on mytable to(from) gis;select * from user_tab_privs; #查看当前⽤户的表的对象权限:对象权限可以控制到列(只能插⼊和更新控制到列):select * from user_col_privs; #查看当前⽤户的列的对象权限:1) grant update(name) on mytable to sagittys; #在gis⽤户上将mytable表的name列更新权限给sagittys⽤户update gis.mytable set name='laowang' where id=1;commit;2) grant insert(id) on mytable to sagittys;insert into gis.mytable(id) values(7);GRANTEE OWNER TABLE_NAME GRANTOR PRIVILEGE GRA HIE----- ------------------------------ ------------------------------ --GIS SAGITTYS SA SAGITTYS FLASHBACK NO NOGIS SAGITTYS SA SAGITTYS DEBUG NO NOGIS SAGITTYS SA SAGITTYS QUERY REWRITE NO NOGIS SAGITTYS SA SAGITTYS ON COMMIT REFRESH NO NOGIS SAGITTYS SA SAGITTYS REFERENCES NO NOGIS SAGITTYS SA SAGITTYS UPDATE #更新 NO NOGIS SAGITTYS SA SAGITTYS SELECT #查询 NO NOGIS SAGITTYS SA SAGITTYS INSERT #插⼊ NO NOGIS SAGITTYS SA SAGITTYS INDEX #索引 NO NOGIS SAGITTYS SA SAGITTYS DELETE #删除 NO NOGIS SAGITTYS SA SAGITTYS ALTER #修改 NO NO(在CMD中默认宽度到头了则不会规则的显⽰,此时将宽度设为400,set linesize 400,就ok了)语⾔分类:1、 DLL,数据定义语⾔CREATE,CREATE TABLE abc(a varchar(10),b char(10));ALTER,ALTER TABLE abc ADD c NUMBER; 加⼀个c的字段,数据符为NUMBER。
Oracle 权限设置一、权限分类:系统权限:系统规定用户使用数据库的权限。
(系统权限是对用户而言)。
实体权限:某种权限用户对其它用户的表或视图的存取权限。
(是针对表或视图而言的)。
二、系统权限管理:1、系统权限分类:DBA: 拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构。
RESOURCE:拥有Resource权限的用户只可以创建实体,不可以创建数据库结构。
CONNECT:拥有Connect权限的用户只可以登录Oracle,不可以创建实体,不可以创建数据库结构。
对于普通用户:授予connect, resource权限。
对于DBA管理用户:授予connect,resource, dba权限。
2、系统权限授权命令:[系统权限只能由DBA用户授出:sys, system(最开始只能是这两个用户)]授权命令:SQL> grant connect, resource, dba to 用户名1 [,用户名2]...;[普通用户通过授权可以具有与system相同的用户权限,但永远不能达到与sys用户相同的权限,system 用户的权限也可以被回收。
]例:SQL> connect system/managerSQL> Create user user50 identified by user50;SQL> grant connect, resource to user50;查询用户拥有哪里权限:SQL> select * from dba_role_privs;SQL> select * from dba_sys_privs;SQL> select * from role_sys_privs;删除用户:SQL> drop user 用户名 cascade; //加上cascade则将用户连同其创建的东西全部删除3、系统权限传递:增加WITH ADMIN OPTION选项,则得到的权限可以传递。
Oracle新建⽤户、⾓⾊,授权,建表空间的sql语句oracle数据库的权限系统分为系统权限与对象权限。
系统权限( database system privilege )可以让⽤户执⾏特定的命令集。
例如,create table权限允许⽤户创建表,grant any privilege 权限允许⽤户授予任何系统权限。
对象权限( database object privilege )可以让⽤户能够对各个对象进⾏某些操作。
例如delete权限允许⽤户删除表或视图的⾏,select权限允许⽤户通过select从表、视图、序列(sequences)或快照(snapshots)中查询信息。
每个oracle⽤户都有⼀个名字和⼝令,并拥有⼀些由其创建的表、视图和其他资源。
oracle⾓⾊(role)就是⼀组权限(privilege)(或者是每个⽤户根据其状态和条件所需的访问类型)。
⽤户可以给⾓⾊授予或赋予指定的权限,然后将⾓⾊赋给相应的⽤户。
⼀个⽤户也可以直接给其他⽤户授权。
Oracle创建⽤户的语法:Oracle创建⽤户(密码验证⽤户),可以采⽤CREATE USER命令。
CREATE USER username IDENTIFIED BY passwordOR IDENTIFIED EXETERNALLYOR IDENTIFIED GLOBALLY AS ‘CN=user'[DEFAULT TABLESPACE tablespace][TEMPORARY TABLESPACE temptablespace][QUOTA [integer K[M] ] [UNLIMITED] ] ON tablespace[,QUOTA [integer K[M] ] [UNLIMITED] ] ON tablespace[PROFILES profile_name][PASSWORD EXPIRE][ACCOUNT LOCK or ACCOUNT UNLOCK]其中,CREATE USER username:⽤户名,⼀般为字母数字型和“#”及“_”符号。
OraGiST-How to Make User-Defined Indexing BecomeUsable and UsefulCarsten Kleiner,Udo W.LipeckUniversit¨a t HannoverInstitut f¨u r InformationssystemeFG DatenbanksystemeWelfengarten130167Hannover{ck|ul}@dbs.uni-hannover.deAbstract:In this article we present a concept for simplification of user-defined in-dexing for user-defined data types in object-relational database systems.The conceptis based on a detailed analysis of user-defined indexing in ORDBS on one hand,andfeatures of generalized search trees(GiST)as an extensible indexing framework onthe other hand.It defines a minimal interface to be implemented in order to use GiSTwithin ORDBS;this greatly simplifies the process of implementing user-defined in-dexes.The effectiveness of the approach is illustrated by performance experimentscarried out on a prototypical implementation of our concept.For the experiments wehave used new specialized spatial data types,that store spatial as well as thematic infor-mation within a single attribute.These data types facilitate advanced spatial analysisoperators.The experiments show great performance improvements on these opera-tors by using multidimensional user-defined index structures based on R-trees whencompared to system-provided indexes.Keywords:object-relational databases,user-defined indexing,data cartridge,user-defined datatype,advanced spatial analysis operators1Introduction1.1MotivationIn recent years object-relational database systems(ORDBS)have advanced past research prototypes and are becoming commercially available.One of the key advantages over tra-ditional relational databases is the possibility to use user-defined datatypes(UDTs).It is a very important feature in many advanced applications,because adequate modeling of non-standard domains requires such types.This can be inferred from the increased popularity of object-oriented modeling which implicitly facilitates the use of arbitrary datatypes. Also in the spirit of object-oriented modeling these new UDTs will have specific functions operating on them,usually called methods in object-oriented technology.The most impor-tant of these methods from a database perspective are methods that can be used in queries to select objects from tables or join objects from different tables.These methods are also called operators in object-relational terminology.In commercial settings these new fea-tures will only be used,if they achieve a performance comparable to standard datatypes and functions in traditional relational databases.Since UDTs can be defined arbitrarily by the user,it is impossible for the ORDBS vendor to provide efficient support of all such operators in selection and/or join queries.Conse-quently they provide extensible indexing and query optimization features.The author of the UDT has to implement these features using domain-specific knowledge.The complete package of UDT,operators,indexing and query optimization is also called a cartridge(or, depending on the particular vendor,extender or data blade),since it can be plugged into the database server similar to cartridges in hardware.The enhanced database server then efficiently supports UDTs transparent to the end-user.A big obstacle,however,is that the implementation of user-defined indexing is pretty complex and time-consuming.Moreover as it is,it has to be carried out completely from scratch for every UDT that requires efficient query support.In order to overcome this and make user-defined indexing more usable,a generic indexing framework such as gener-alized search trees(GiST;[HNP95])should be used.This has the advantage of already providing most of the required functionality for several different index structures.These structures can easily be specialized to obtain a specific index for a particular datatype. Therefore it would be desirable to have an easy to use tool that combines a particular UDT from an ORDBS with a concrete extension of an index framework automatically and leaves only the(very few as will be shown in this article)type and operator specific implementation parts to the user.In this article we willfirst investigate what the type and operator specific details of such a definition under some reasonable assumptions are.The result is a concept for greatly simplifying the usage of an indexing framework in ORDBS. We will then present the design of a prototypical implementation of such a tool,called OraGiST,which facilitates the use of GiST as user-defined index structures in the ORDBS Oracle9i.The tool which was developed in our group does as much work as possible automatically,leaving the programmer with just very few tasks1to be solved,before being able to use GiST inside Oracle.While OraGiST is specifically designed for Oracle,similar extensions for other ORDBS based on the previous concept would also be possible.The effectiveness of this approach is illustrated by some sample results from spatial data. In advanced applications one would like to combine spatial selection criteria with other thematic attributes in a single operator.Queries such as select all cities in a given query window where the population density is higher than a given value and the percentage of male inhabitants is more than55percent could be answered efficiently by such complex operators.We will show that using high-dimensional R-tree-like GiST extensions devel-oped by using OraGiST is more efficient than working with classical indexes.It is even more efficient than using the DBMS provided spatial indexes on the spatial component.1.2Related WorkThe concept of object-relational database systems(ORDBS)has been described in[SM96] and[SB99].Most commercial DBMS that were relational can be called object-relational to a certain degree today.Probably the most commonly used systems are Oracle9i and IBM DB2.In the open-source area e.g.PostgreSQL is also object-relational;it is based on the oldest ORDBS Postgres(cf.[SR86]).Requirements specific to user-defined indexing in ORDBS are explained in[SB99].A good overview of advanced spatial applications can be found in[RSV01].In particular indexing in spatial databases is reviewed in[GG98].RSS-Trees were introduced in detail in[KL00].The introduction of user-defined types in ORDBS requires easily extensible indexes in order to facilitate efficient querying of UDTs.Therefore generic index struc-tures such as generalized search trees have to be used.A similar idea to ours has been described in[RKS99]for the CONCERT DBS.It allows indexing based on concepts but is more focused on spatio-temporal data and is restricted in the indexes to be used since it requires a hierarchical partitioning of space.The basic insight that only very few features are actually specific to a data type in indexing is also used in our approach.More advanced research on query optimization for user-defined types is described in[Hel98].Another im-plementation for advanced index structures was presented in[BDS00].It is written in Java and focuses on main memory index structures.When Java has become more efficient and systems even more powerful in terms of main memory this will probably also be a very interesting approach.The combination of an extensible indexing framework with a com-mercial ORDBS has to the best of our knowledge never been researched before.Also the idea of using higher-dimensional indexing for advanced spatial analysis has never been an-alyzed in such detail.Finally no experimental results on the efficiency of real user-defined indexing in ORDBS have been reported yet.2Current SituationGeneralized search trees(GiST;[HNP95])are search trees that combine and implement the common features of tree-based access methods such as insertion and searching but still allow to adjust the classical operations to a particular data type and indexing structure. This is achieved by an implementation using certain extensible methods in the general algorithms that have to be implemented by the user for the particular data type and indexing structure by object-oriented specialization later;these methods are consistent,penalty, pickSplit,union and optionally compress and decompress.Due to space constraints details on GiST are omitted;they can be found in the full version of this paper([KL02]).Afile-based implementation of generalized search trees called libgist has been made available under .It is written in C++and provides the general tree along with several extensions for most of the trees proposed in the litera-ture such as B-Tree,R∗-Tree and SS-Tree.Its completion was reported in[Kor99].Since it operates on indexfiles,it cannot be used directly in conjunction with a commercial OR-DBS,where indexfiles should be under control of the DBS as well,e.g.for transactionalcorrectness reasons.Moreover the interfaces need to be linked together in order to use a GiST specialization as an index inside the ORDBS.In addition ORDBS users want to use the given and other GiST-based index structures for their own user-defined types.This requires a mapping of database types and operators to GiST objects and predicates.In order to implement extensible user-defined indexing-for example in Oracle9i-cer-tain methods have to be programmed:IndexCreate,IndexInsert,IndexDrop,IndexStart, IndexFetch,IndexClose,IndexAlter and IndexUpdate.These are later automatically in-voked by the database server when executing regular SQL commands using the UDTs. Again due to space constraints details are omitted here,but can be found in the full version of the paper.User-defined data types in ORDBS need data type specific query optimization to be able to use them efficiently.In Oracle this is implemented by providing special interfaces for extensible optimization.Functions defined in these interfaces are called automatically by the database server,if an implementation of the interface for the particular data type is registered with the server.This way extensible optimization is as directly integrated into the database server as possible for arbitrary data types.The interfaces of the extensible optimizer are described in detail in system documentation.3Concept of OraGiSTIn order to connect thefile-based implementation of generalized search trees with the in-dexing interface of the ORDBS we havefirstly analyzed which components of the mapping between a generic index and an ORDBS are generic themselves and which are dependent on the particular data type in question.Consequently,the implementation of a connector component between ORDBS and generic index consists of two main parts.We have called our prototypical implementation OraGiST,since it operates based on libgist and Or-acle9i.An overview of the architecture of OraGiST is given infigure1.As explained before,the tool OraGiST mainly consists of two components.Thefirst component(called OraGiST library)is independent of the particular data type,user and GiST extension.It provides functionality for calling the appropriate generic index methods inside functions of the ORDBS extensible indexing interface(cf.section2)on the one hand.Also it facilitates storing of index information of afile-based tree index structure inside an ORDBS on the other hand.These are the upper two associations infigure1. The second component(OraGiST toolbox infigure1)is dependent on the data type and thus index structure specialization.Consequently,it cannot work completely without pro-grammer interaction.It can rather be a support tool providing the user with method proto-types,and taking over all generic tasks of this part of the user-defined index development process.In particular,only four methods have to be implemented for the particular data type by the database programmer.Firstly,it has to be defined which GiST specialization is to be used for a particular ORDBS user-defined data type2.This is done by implement-Oracle ORDBS libgist libraryOraGiST Figure 1:Architecture and Functionality of OraGiSTing the method getExtension .Secondly,the mapping of database operators to index structure methods implementing the desired predicate has to be declared by implement-ing the method getQuery by the developer.The implementation of these two methods typically consist of only a single line returning a pointer to the particular object required.Also the mapping between ORDBS data type and index structure entry has to be imple-mented.Since often not the exact objects but rather approximations are inserted into an index,this method is called approximate (cf.MBRs in spatial indexing).More gener-ally speaking this method implements the compress method of the original GiST concept.This method is the only one that may incur considerable programming work,since it must implement the mapping of a database object to an index object;in the case of spatial data in Oracle 9i ,for instance,the rather complex definition of the database geometry type has to be investigated in C to compute the MBR of the object.Finally,results from an index lookup may not be results to the original query,if the index entries are approximations of the original objects.For spatial data e.g.not all objects whose MBR intersect a given object do intersect the object themselves;thus usually the so-called filter-and-refine strategy of query execution is used for spatial queries.This is reflected in OraGiST by means of a method needFilter .It has to return true ,if results from the index scan still have to be tested,before the query result is determined,and false else.For the programmer this is only one additional line of code in the current version of OraGiST ,since as testing method the functional implementation of the opera-tor which is required by the ORDBS anyway may be used.If such testing is required,after registering the index with OraGiST ,the toolbox will automatically take care,that results of an index scan are additionally filtered by the functional implementation of the operatorCREATE TYPE twoIntegerGeometry AS OBJECT(geom OGCGeometry,theme1INTEGER,theme2INTEGER,--type-specific methods);Figure2:Data type definition for combining spatial and thematic informationin the ORDBS.As stated earlier based on this concept,we have developed a prototypical implementation of a connector between GiST implementation libgist and Oracle9i as ORDBS.This simplifies user-defined indexing to such a degree that it is really usable with acceptable implementation effort.If one of the predefined GiST extensions is to be used as index only the small OraGiST toolbox classes have to be implemented.But even if a new GiST extension is required as index development time is greatly reduced.This is due to the extensibility features of GiST which facilitate simple definition of new index structures as long as they can be expressed in the GiST framework.We will illustrate that user-defined indexing is also very useful for UDTs by presenting performance experiments of using such indexes for advanced spatial analysis operators in the next section.4Case Study:Advanced Spatial Analysis4.1Data Types and OperatorsSpatial index structures have been researched in great detail in the past.Operators sup-ported by most of these indexes are spatial selections such as overlap or window queries. Some also support spatial join or nearest neighbor mon for all these queries is that they only use the spatial information of objects for determining the query results. Recent spatial applications on the other hand tend to use queries that combine spatial and thematical information infinding the desired objects.One could e.g.be interested in all counties in a given window where the median rent is below a given value.Or using even more thematic information,one could ask for all those counties where,in addition, the population is higher than anotherfixed value.For these queries traditional spatial indexes are only partly helpful,since they only support the spatial selection part of the queries.Especially in cases where the stronger restrictions are on the thematic attributes (e.g.a very low threshold value for median rent)the spatial index does not help at all. Since in many cases it is difficult or impossible to predict which queries will be used on a given table3,it would be desirable to have a combined index that supports spatial-thematic queries of different selectivities equally well,regardless of the particular query parameters.Consequently we suggest to define user-defined data types in ORDBS which combine spa-tial and thematic attributes in a single type4.A sample definition for twoIntegerGeo-metry combining a spatial and two numerical thematic attributes is given infigure2. We use a type OGCGeometry as an implementation of the OpenGIS Consortium simple features specification here.Operators on these newly defined types can be conjunctions of spatial operators and operators on the types of the thematic attributes.In the sequel we will investigate the frequently used operator twoBetweenOverlap on the aforementioned type,which is a conjunction of spatial overlap operator and between operator on the the-matic attributes.Since twoIntegerGeometry combines information from orthogonal domains in a single type,it is straightforward to use higher dimensional spatial indexes for the newly introduced operator.In particular,we obtain a four-dimensional domain for twoIntegerGeometry.4.2Performance EvaluationAn extensive performance evaluation for different datatypes can be found in the full ver-sion.If we use one thematic attribute in addition to the spatial attribute and thus use type integerGeometry and operator betweenOverlap,we obtain the results depicted infigure3.Indexing options compared in this work are user-defined three-dimensional versions of R*-and RSS-Tree([KL00]),as well as Oracle spatial indexes on the spatial component of such objects5.For the latter indexes the thematic attribute has to be checked separately in order to compute a correct query result.Figure3shows that this separate processing incurs a big overhead and thus leads to a pretty bad er-defined indexes perform much better with the R*-tree outperforming the RSS-tree by a small mar-gin.The unstable performance of the predefined indexes is due to them only considering the spatial component.Consequently,when the stronger restriction in the query parame-ters is on the spatial component they perform better,but worse if the stronger restriction is on the thematic attribute.Figure3clearly shows the usefulness of user-defined indexing, since only by using it,an efficient and predictable query performance can be achieved for the user-defined type considered.Since the built-in indexes already performed bad on integerGeometry we do not con-sider them an alternative6for the more complex type twoIntegerGeometry.Figure4 illustrates the performance of different user-defined indexes on queries using the operator twoBetweenOverlap.In particular the variants of the user-defined RSS-tree for dif-ferent dimensionalities are compared;also the four-dimensional R*-tree can be compared with the RSS-tree.Thefigure clearly shows the benefits of using a multidimensional in-dex structure as compared to a lower dimensional one,since,at least for low to medium dimensional data,the more dimensions are indexed the better the performance is.Also,0102030405060708002468101214r e s p o n s e t i m e selectivity in %Oracle R-Tree User-Def-3D-RSS-Tree User-Def-3D-R*-Tree Oracle QuadtreeFigure 3:Performance Evaluation on 2D spatial data plus one thematic dimensiondifferent from the indexes on integerGeometry ,this time the full-dimensional RSS-tree is faster than the R*-tree for small selectivities.Consequently it is difficult to say which of the two variants should be preferred in real applications.But,since both perform almost equally well,the RSS-tree has the advantage of a faster index creation time due to its simpler,namely linear,insertion algorithm.More details can be found in the full version.Nevertheless we can already conclude that the performance gain from using a more appropriate index for a particular data type illustrates,that an easily adaptable in-dexing framework is required.Only by doing so one can obtain optimal performance with acceptable effort for each of the many possible UDTs.5Conclusion and Future Work5.1ConclusionIn this article we have presented a concept on how to integrate a flexible extensible index-ing framework into recent commercial ORDBS.The need for this integration was moti-vated by the new features of ORDBS,namely the possibility to use user-defined data types.Since these types also have type-specific operators,type-specific indexes will be required in order to process user-defined operators efficiently.The concept of integrating generalized search trees into an ORDBS was then applied to specialized spatial data types to prove its feasibility and also its effectiveness.In particular,spatial data enriched with one or two thematic attributes was used as data type.Operators on these types answer queries such as retrieve all objects that lie in a given area where the median rent is below a given threshold value .These operators are very frequent in advanced spatial analysis and therefore need index assistance.0102030405060708005101520r e s p o n s e t i m e selectivity in %User-Def-4D-RSS-Tree User-Def-4D-R*-Tree User-Def-3D-RSS-Tree User-Def-2D-RSS-TreeFigure 4:Performance Evaluation on 2D spatial data plus two thematic dimensions (standard query)Our experiments showed that viewing the objects as elements of a three-(for one the-matic attribute)or four-dimensional (for two thematic attributes)space and using spatial indexes extended to three or four dimensions shows best query performance.Overall the experiments showed the huge performance gain achieved by using user-defined indexing as compared to using system-provided indexes.The concept of OraGiST uses object-oriented techniques to simplify the development in two ways:firstly,if an existing index structure is used only the implementation of the interface defined by OraGiST is required.If on the other hand a different index is desired,its development is supported by using an extensible indexing framework such that only a new spezilization has to be developed.5.2Future WorkThe concept has so far only been implemented in a prototype fashion.Firstly the imple-mentation is currently restricted to GiST and Oracle 9i .An extension to other indexing frameworks and more importantly other ORDBS should be evaluated.Also the very good performance results shown previously only hold for rather simple objects.If we consider complex polygons in the spatial component,we currently obtain good results only for very small selectivities.These results could probably become better,if the OraGiST concept is extended to allow for a direct implementation of the refine step during two step query processing in the connector class.Currently the functional implementation (fallback)of an operator inside the DBS is used for refinement.Our concept and prototype implementation should be tested with different,especially more complex,user-defined data types and operators.We expect the results to be even more impressive with such types,since no system-provided indexing is available at all.Also,tests with different operators on the given types,especially different spatial operators,could give an interesting overview of overall performance.Moreover to provide a com-plete data cartridgefine tuning of user-defined indexing by implementing user-defined cost and selectivity estimation is also missing so far.Conceptually we think,that an extensi-ble framework-like approach could greatly simplify implementation for a particular UDT, similar to user-defined indexing.To be able to use such techniques a parametrized ap-proach to cost and selectivity estimation in ORDBS has to be developed.In particular the processing of data type specific join queries could benefit significantly from optimized query execution,both by indexing and by cost and selectivity estimation.Research on data type specific joins in ORDBS is currently only in its early stages.Bibliography[BDS00]J.van den Bercken,J.P.Dittrich,and B.Seeger.javax.XXL:A Prototype for a Library of Query Processing Algorithms.In:Proceedings of the2000ACM SIGMOD InternationalConference on Management of Data,Dallas,May16-18,2000.ACM Press.[GG98]V olker Gaede and Oliver G¨u nther.Multidimensional Access Methods.ACM Computing Surveys,30(2):170–231,June1998.[Hel98]Joseph M.Hellerstein.Optimization Techniques for Queries with Expensive Methods.ACM Transactions on Database Systems,23(2):113–157,June1998.[HNP95]J.M.Hellerstein,J.F.Naughton,and A.Pfeffer.Generalized Search Trees for Database Systems.In:Proceedings of the21th International Conference on Very Large Data Bases,Zurich,Sept.11-15,1995.Morgan Kaufmann Publishers.[KL00]Carsten Kleiner and Udo W.Lipeck.Efficient Index Structures for Spatio-Temporal Ob-jects.In:Eleventh International Workshop on Database and Expert Systems Applications(DEXA2000;4-8September2000,Greenwich,UK).IEEE Computer Society Press. [KL02]Carsten Kleiner and Udo W.Lipeck.OraGiST-How to Make User-Defined Indexing Become Usable and Useful.Technical Report DBS01-2002,Institut f¨u r Informationssys-teme,Universit¨a t Hannover,September2002.[Kor99]Marcel Kornacker.High-Performance Extensible Indexing.In:Proceedings of the25th International Conference on Very Large Data Bases,Edinburgh,Sept7-10,1999.MorganKaufmann Publishers.[RKS99]Lukas Relly,Alexander Kuckelberg,and Hans-J¨o rg Schek.A Framework of a Generic In-dex for Spatio-Temporal Data in CONCERT.In:Spatio-Temporal Database Management–Int.Workshop STDBM’99,Edinburgh,Sept.10-11,1999.Springer-Verlag.[RSV01]Philippe Rigaux,Michel Scholl,and Agnes V oisard.Spatial Databases:With Application to GIS.Morgan Kaufmann Publishers,2001.[SB99]Michael Stonebraker and Paul Brown.Object-Relational DBMSs–Tracking the Next Great Wave(Second Edition).The Morgan Kaufmann Series in Data Management Sys-tems.Morgan Kaufmann Publishers,2nd edition,1999.[SM96]Michael Stonebraker and Dorothy Moore.Object-Relational DBMSs–The Next Great Wave–First Edition.The Morgan Kaufmann Series in Data Management Systems.Mor-gan Kaufmann Publishers,1st edition,1996.[SR86]Michael Stonebraker and Lawrence A.Rowe.The Design of POSTGRES.In:Proceed-ings of the1986ACM SIGMOD International Conference on Management of Data.ACMPress.。