ORACLE 体系结构详解
- 格式:doc
- 大小:268.00 KB
- 文档页数:22
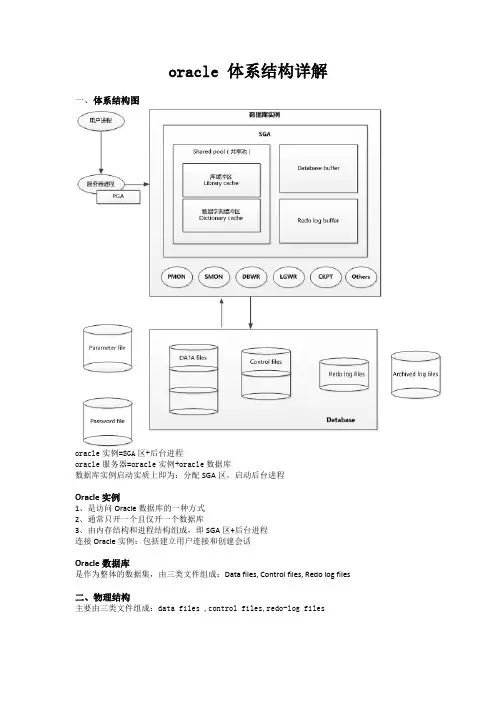
oracle 体系结构详解一、体系结构图oracle实例=SGA区+后台进程oracle服务器=oracle实例+oracle数据库数据库实例启动实质上即为:分配SGA区,启动后台进程Oracle 实例1、是访问Oracle 数据库的一种方式2、通常只开一个且仅开一个数据库3、由内存结构和进程结构组成,即SGA区+后台进程连接Oracle实例:包括建立用户连接和创建会话Oracle数据库是作为整体的数据集,由三类文件组成:Data files, Control files, Redo log files二、物理结构主要由三类文件组成:data files ,control files,redo-log files1.data files:数据文件,存放基本表信息(即表中数据等)、索引信息(系统内建有索引表)、回退信息(主要为数据的rollback)、临时信息(如有orderby 等操作时系统有临时信息)、系统引导信息(如数据字典等)2、control files:控制文件(二进制的)。
存放库物理结构、库名、库创建日期、序列号(存有同步信息);控制文件至少有两个一摸一样的,用做备份用参数Controlfiles=/../../文件名1,/../../文件名2;指定3、redo log files:回退日志文件,存放修改前后的信息,主要用于数据的恢复,一个数据库至少有两个redo log files文件,以便可以循环记录信息注:三类文件都有序列号,必须同步才能使用,且已Control files中的序列号为准,其他的必须与其保持一致除了上面三类文件还有:Parameter file(参数文件),Password file(口令文件),Archived log files(归档文件)等参数文件:有二进制、文本两种,用于设定参数的值。
二进制参数文件可以及时更改,即时生效;文本参数文件需重启口令文件:可用orapwd.exe 建口令文件。

Oracle数据库体系结构⼀、oracle数据库体系结构基本组成:Oracle server:⼀般情况下是⼀个instance和⼀个database组成⼀般:1个instance只能对应⼀个数据库。
特殊:1个数据库可以有多个instance(RAC)⼀台服务器上同时可装多套版本的数据库软件,每个数据库软件可建多个数据库,但是每个数据库只对应⼀个instance,也可以理解成每个数据库只有⼀个SID 。
利⽤DBCA建出的每个库都是相对独⽴的,在同⼀服务器上如果创建多库必须将环境变量的参数⽂件做区分,并且在对实例切换时需如下操作:connect ⽤户名/密码@实例的服务名1.1 oracle服务器和实例1.1.1实例由内存区和后台进程组成①内存区:数据库⾼速缓存、重做⽇志缓存、共享池、流池以及其它可选内存区(如Java池),这些池也称为数据库的内存结构②后台进程:包括系统监控进程(SMON)、进程监控(PMON)、数据库写进程(DBWR)、⽇志写进程(LGWR)、检验点进程(CKPT)、其它进程(SMON,如归档进程、RECO进程等)③注:要访问数据库必须先启动实例,实例启动时先分配内存区,然后再启动后台进程,后台进程执⾏库数据的输⼊、输出以及监控其它Oracle进程。
在数据库启动过程中有五个进程是必须启动的,它们是系统监控进程(SMON)、进程监控(PMON)、数据库写进程(DBWR)、⽇志写进程(LGWR)、检验点进程(CKPT),否则实例⽆法创建。
1.1.2服务器Oracle服务器由数据库实例和数据⽂件组成,也就是我们常说的数据库管理系统。
数据库服务器除了维护实例和数据库⽂件之外,还在⽤户建⽴与服务器的连接时启动服务器进程并分配PGA1.2 oracle数据库逻辑结构表空间:据库的基本逻辑结构,是⼀系列数据⽂件的集合;段:不同类型数据在数据库中占⽤的空间,有许多区组合⽽成;区:由连续的块组成,⽬的是为数据⼀次性预留⼀个较⼤的空间,oracle为存储空间进⾏分配回收都是以区为单位的;块:最⼩的存储单位,在创建数据库时指定,不能修改。

Oracle数据库体系结构一.Oracle数据库体系结构1.实例:一组用于管理数据库文件的内存结构,实例对应着数据库;RAC/CDB CDB:CDB为数据库容器,PDB插拔数据库。
在ORACLE 12C之前,实例与数据库是一对一或多对一关系(RAC),即一个实例只能与一个数据库相关联,数据库可以被多个实例所加载。
而实例与数据库不可能是一对多的关系。
当进入ORACLE 12C后,实例与数据库可以是一对多的关系。
RAC:允许多个Oracle数据库实例在多台服务器上共享同一个数据库存储空间,并通过集群来保证高可用性和容错性。
简单来说,RAC就是将多个数据库实例连接起来,形成一个“集群”。
2.ShardingSphere:中间件,不同的数据库对应不同的实例,中间有一个中间件,使用者连接中间件;数据库中间件可以简化对读写分离以及分库分表的操作,并隐藏底层实现细节,可以像操作单库单表那样操作多库多表。
常见的中间件有MyCat,Mysql-Proxy,DRDS,Atlas,Zebra二.Orcal数据库体系结构:Orcal服务器=数据库+实例1.实例是暂时的,它只不过是一组逻辑划分的内存结构和进程结构,它会随着数据的关闭而消失数据库它就是一堆物理文件(控制文件、数据文件、日志文件等等)它呢是永久存在的数据库和实例是一对一的,这种结构我们一般称为单实例体系结构;既然有一对一,那就会有一对多,在复杂的分布式结构中,一个数据库可以对多个实例,多个实例之间可以通过网络来进行数据的一个交互或着交换2.PGA:程序全局区,为单独的服务器进程存储私有数据的内存区域(SAG属于公共资源,PAG是私有的)3.SGA:系统全局区,所有用户都可以访问的共享内存区域启动Oracle数据库时,系统先在内存内规划一个固定区域,用来储存用户需要的数据,以及Oracle运行时必备的系统信息4.后台进程结构,此处只罗列必须启动的5个后台进程系统监控器SMON:负载检查数据库一致性,有必要会在数据库打开时启动数据库恢复进程监视器PMON:负责一个Orcal数据库进程失败时清理资源,会定期唤醒或者被其他主动事务主动唤醒数据库写进程DBWR:负责将更改的数据从“数据库高速缓冲区”写入“数据文件”日志写进程LGWR:负载把日志数据写到练级日志文件检查点进程SKPT:负责检查点操作,主要检查数据库状态一致性和记录系统变更时间5.三个文件1)控制文件:存储数据库结构,一个控制文件只属于一个数据库,包含数据文件日志文件信息及相关状态归档信息,2)数据文件:存储数据,xxx.dbf文件存储着系统数据,数据字典数据,索引数据及用户存储的数据3)日志文件:存储与事务有关的重做日志三.逻辑存储结构1.块是Oracle用来管理存储的最小单元,也是最小的逻辑存储结构2.区是Oracle数据库分配空间的最小单位3.段由多个区组成,这些区可以是连续的,也可以是不连续的4.表空间是Oracle数据库的最大逻辑划分区域,通常用来存放数据表、索引、回滚段等数据对象。


简述oracle体系结构
Oracle体系结构
Oracle是一种支持分布式数据库管理系统,其体系结构主要包
括E-R图,表和索引,存储过程和视图, SQL,PL/SQL程序和组件,等等。
1. E-R图
E-R图是一种关系数据库管理系统的基本模型,其中实体表示客观事物,关系表示实体之间的联系。
E-R图可以被用来描述实体和它们之间的关系,以及实体的属性和它们之间的关系。
2.表和索引
表是由一系列列组成的逻辑结构,它们包含每行和每列的数据。
索引是一种特别的表,可以被用来提高表的搜索速度和性能。
3.存储过程和视图
存储过程是一种特定类型的程序,它们可以被用来完成某些操作,比如查询和更新。
视图是一种准备好的查询,它们可以被用来返回数据库中的数据。
4.SQL,PL/SQL程序和组件
SQL(Structured Query Language)是一种用于在数据库中执行查询和更新操作的语言,是一种面向关系型数据库的核心语言。
PL/SQL是一种可以嵌入SQL语句的程序设计语言,用来定义复杂的
查询,更新和实现回调函数。
组件是一种模块化的程序,用来构建更复杂的系统。


oracle第⼀篇:oracle12c体系结构1、oracle12c的体系结构:内存(逻辑)结构:SGA可以分为数据缓冲区、⽇志缓冲区、共享池、⼤型池、JAVA池、流池。
数据缓冲区(data buffer cache):oracle读取数据的缓存区,执⾏数据的临时存储空间以及修改未提交时,未写⼊磁盘的脏数据。
主要作⽤是提⾼数据的查询速度和减少磁盘的I/O操作;⽇志缓冲区(redo log buffer cache):在执⾏sql语句之前,需要计算出sql执⾏语句的改变向量,并将该向量以⽇志的形式临时存储在该内存区域,然后再去数据缓冲区进⾏数据的更改。
共享池(share pool):共享池分为库缓存、数据字典缓存、sql查询和pl/sql函数结果查询缓存;共享池的⼤⼩9i版本之后就可以直接调整⼤⼩。
库缓存:⽤于临时存储近期已经分过的代码,再次使⽤时就不需要对该代码进⾏分析,直接调⽤。
提⾼语法的执⾏效率。
数据字典缓存:⽤于对近期调⽤的数据字典进⾏缓存,并且数据字典缓存的分配是在库缓存之后的,所以只要库缓存没问题,数据字典缓存也就没问题。
sql查询和pl/sql函数结果查询缓存:当同⼀会话或者多个不同的会话执⾏多次,就会将该查询的结果存储在内存中,当下⼀次查询时直接去调⽤该查询的结果。
在运⽤该执⾏结果之前缓存机制会⾃动的检查查询中的表等对象是否发⽣了变化。
如果变化就会重新查询,使⽤重新查询得到的结果。
⼤型池(large pool):可选择型的内存区域,主要⽤于共享服务器进程的使⽤。
如果未分配再⽤⼑该内存时会在共享池中进⾏分配。
JAVA池(java pool):在运⾏java过程时才使⽤到java池,它作⽤于java对象所需要的堆空间。
但是实际java的实际运⾏还是在数据缓存区。
流池(stream pool):⽤于在redo log中获取⽇志向量,并重新构造执⾏语句,在远程数据库执⾏。
⽽在redo log中提取更改的进程以及应⽤更改的进程将⽤到内存,该内存即是流池。


Oracle数据库体系结构小结——参考文献:Concepts双语版Oracle数据库体系结构分为四大体系结构,即:Oracle网格体系结构、应用体系结构、物理数据库结构、逻辑数据库结构;一、 Oracle网格体系结构:Oracle是第一个为企业网格计算而设计的数据库。
在网格体系中所有资源被统一储备、随需分配。
回顾网格的相关内容:1、网格将相似的IT资源整体地看做一个池。
2、网格中管理的IT资源包括:基础设施:组成数据存储、软件运行环境的硬件和软件;应用:定义业务过程(business process)的程序逻辑(program logic)和流程(flow);信息:蕴含于各种数据中用于指导业务的数据的内在含义;3、网格中的两个独特核心理念:虚拟化和资源供给;虚拟化,就是将各类独立的资源视为一个池,经过抽象后提供给资源消费者。
这意味着打破了资源提供者与资源消费者之间的硬性联系(也就是说没有明确规定哪一块资源就是某个消费者独有的)。
资源供给,就是当消费者通过虚拟层请求资料时,网格在幕后找出满足需求的资源,并分配给消费者。
注:基础设施、应用、信息三种资源的虚拟化与资源供给的具体方法各不相同,但思路是相通的。
并且通过网格供给三种资源给用户带来的益处也各不相同,但都具备商质量、低造价、及灵活的特点。
将基础设施资源视为一个池并随需分配,提高了资源利用水平,减少了冗余资源,节约了软硬件购买资金。
数据库服务器的网格特性:1、基础设施网格:A、服务能力虚拟化:Oracle实时应用集群(RAC Oracle Real Application Clusters)可以使一个数据库运行在网格中多个集群节点上,即把多个计算机的处理能力作为池。
Oracle是目前唯一不需要将数据分区再分布处理就能利用多个计算机提供的处理能力的数据库。
B、存储能力虚拟化。
Oracle数据库10g的自动存储管理功能(ASM,Automatic Storage Management)在数据库存储硬件之间建立了一个虚拟层,多个磁盘可以被视为一个磁盘组,而且磁盘可以在保持数据库联机的状态下动态地添加或先移除。

Oracle数据库的体系结构介绍Oracle数据库是目前世界领先的企业级关系数据库管理系统,其卓越的性能、可靠性以及安全性被广泛地应用于企业级应用系统中。
本文将详细介绍Oracle数据库的体系结构,帮助读者更好地了解Oracle数据库。
一、概述Oracle数据库的体系结构分为三层:物理层、逻辑层和视图层。
物理层描述了数据在物理介质上的存储方式和管理方式;逻辑层主要由Oracle数据库的核心服务组成,该层体现了Oracle数据库的最核心功能;视图层则提供给应用程序用户和管理员使用,是Oracle数据库的最外层。
二、物理层Oracle数据库的物理层包括数据文件、控制文件和重做日志文件。
其中,数据文件用于存储数据表、索引和其他对象的数据;控制文件则记录了数据库的结构信息和操作日志,是维护数据库一致性和恢复数据的关键元素;重做日志文件用于记录正在进行的操作和已经完成的操作,以便在系统崩溃或停机时进行恢复。
三、逻辑层Oracle数据库的逻辑层包括多个服务组件,如SQL解析器、优化器、缓存池、锁管理器、存储管理器等。
其中,SQL解析器用于解析SQL语句,将其转换成可执行的优化器,并进行语法和语义检查;优化器则负责分析并优化SQL执行计划,以提高查询效率;缓存池用于存储查询结果和表空间等数据对象,提高查询响应速度;锁管理器则负责管理并发访问,防止数据冲突,保证数据库的一致性和稳定性。
四、视图层Oracle数据库的视图层提供了多种视图和接口,包括SQL*Plus、SQL Developer、Toad等。
其中,SQL*Plus是Oracle自带的命令行工具,提供简单的SQL语句执行和结果输出;SQL Developer是Oracle 提供的图形化界面工具,提供更为便捷的数据库管理和开发支持;Toad则是第三方软件,提供了更为强大和灵活的数据库管理和开发支持。
五、总结Oracle数据库作为目前世界领先的企业级关系数据库管理系统,其体系结构设计合理,层次清晰,提供了完备的物理、逻辑和视图三层管理机制,为企业级应用系统提供了高效、可靠、稳定的运行环境和数据服务。
oracle体系结构简介一、物理存储结构1、数据文件存放数据库数据,以dbf为扩展名。
将数据放在多个数据文件中,再将数据文件分放在不同的硬盘中,可以提高存取速度。
数据文件由数据块构成,块大小由数据库创建时确定。
2、重做日志文件,以rdo为扩展名。
含对数据库所做的更改记录,这样万一出现故障可以启用数据恢复。
一个数据库至少需要两个重做日志文件。
重做日志在日志文件中以循环的方式工作。
有归档日志模式和非归档日志模式。
3、控制文件,以ctl或ctrl为扩展名。
控制文件维护数据库的全局物理结构,记录数据库中所有文件的控制信息,每个数据库至少要有一个控制文件,建议用户使用两个或更多控制文件,并存放在不同的磁盘上。
Oracle系统通过控制文件保持数据库的完整性,以及决定恢复数据时使用哪些重做日志。
4、参数文件,以ora为扩展名。
在一个数据库启动时,每个参数都有一个默认值,而参数文件中的设置值被用来更改默认值,参数值极大影响了oracle如何去执行其不同的任务。
参数文件包括以下几种:<1>、初始化参数文件。
当创建一个数据库时,oracle创建了一个默认的init.ora文件,如果不修改任何参数,oracle将用所有的缺省值来启动数据库,通常根据实际的应用修改参数设置以提高性能。
<2>、配置参数文件。
一般被命名为config.ora,它被用于特定实例的信息。
这个文件是一个由init.ora文件调用或激活的文本文件,init.ora中包含一个ifile参数以设置config.ora文件的位置。
既然一个数据库可以有一个或多个实例与之关联,那么配置文件中每一个参数对于不同的实例配置可能不同,当然,如果和数据库关联的实例只有一个,所有信息都保存在文件init.ora中,那么config.ora文件就不是必需的了。
<3>、服务器参数文件(spfile)。
它被设计为一个服务器端的参数文件,可以被认为是在oracle数据库服务器执行的机器上被管理的初始化参数的仓库。
Oracle体系结构详解(上)一、oracle数据库的整体架构由上图可知,oracle数据库由实例和数据库组成。
二、数据库存储结构:2.1数据库存储结构Oracle数据库有物理结构和逻辑结构。
数据库的物理结构是数据库中的操作系统文件的集合。
数据库的物理结构由数据文件、控制文件和重做日志文件组成。
数据文件:数据文件是数据的存储仓库。
联机重做日志文件:联机重做日志文件包含对数据库所做的更改记录,在发生故障时能够恢复数据。
重做日志按时间顺序存储应用于数据库的一连串的变更向量。
其中仅包含重建(重做)所有已完成工作的最少限度信息。
如果数据文件受损,则可以将这些变更向量应用于数据文件备份来重做工作,将它恢复到发生故障的那一刻前的状态。
重做日志文件包含联机重做日志文件(对于连续的数据库操作时必须的)和归档日志文件(对于数据库操作是可选的,但对于时间点恢复是必须的)。
查看系统的redo log的信息SQL> select group#,sequence#,bytes,members,status from v$log;GROUP# SEQUENCE# BYTES MEMBERS STATUS---------- ---------- ---------- ---------- ----------------1 22 524288001 INACTIVE2 23 524288001 CURRENT3 21 524288001 INACTIVESQL> select member from v$logfile;MEMBER/u01/app/oracle/oradata/hnzk/redo03.log/u01/app/oracle/oradata/hnzk/redo02.log/u01/app/oracle/oradata/hnzk/redo01.log控制文件:控制文件包含维护和验证数据库完整性的必要的信息。
Oracle体系结构Oracle核心竞争力可扩充性:Oracle系统有能力承担增长的工作符合,并且相应的扩充系统资源利用情况。
可靠性:无论出现系统资源崩溃,电源断电还是系统故障的时候,我们都可以对Oracle进行配置。
以保证检索用户数据事务处理的时候,不受到影响。
可管理性:数据库管理员可以微调Oracle使用内存的方式,以及Oracle向磁盘写入数据的频率。
并且管理可以调整,数据库为连接到数据库的用户分配操作系统进程的方式。
Oracle总体结构分为三个部分第一部分:系统全局区(SGA)第二部分:程序全局区和后台进程第三部分:Oracle的文件如果从功能上划分的话:存储结构:由这些文件就构成了Oracle的物理存储结构。
内存结构:使用内存最多的是SGA,也是影响数据库系统性能最大的一个参数。
进程结构:前台进程服务进程和用户进程,是根据实际需要而运行的,并在需要结束后立刻结束。
后台进程是指Oracle数据库启动后自动启动的几个操作系统进程。
存储结构包括物理结构和逻辑结构,既独立又相互联系的。
物理结构:是和操作系统平台有关的。
逻辑结构:逻辑存储结构是和操作系统平台无关的。
_______________________________________________________________________________这个图是两种存储结构中的对应关系表空间包括系统表空间和用户表空间。
表空间也是最大的逻辑单位。
块是最小的一个逻辑单位。
逻辑结构的表空间对应着物理结构的数据文件,也就是创建表空间的时候要给它指定数据文件,但是一个表空间可以对应多个数据文件。
表空间的大小也就是他包含的数据文件大小的总和。
数据文件呢同时又对应着操作系统中的数据块,数据文件也是以数据块的形式,存在于操作系统中。
逻辑结构中的块也对应着操作系统的数据块。
——————————————————————————————————————— 物理存储结构Oracle的物理存储结构,也就是Oracle的数据库文件数据库文件又分为主要文件和其他文件主要文件:首先来看数据文件:就是物理存储Oracle数据库数据的文件有一下特点:◆每一个数据文件,只与一个数据库相关联。
Oracle体系结构就是围绕这张图展开的,要想深入了解oracle,就必须把这张图搞明白。
如图:一、基本组成:Oracle server:一般情况下是一个instance和一个database组成1个instance只能对应一个数据库。
特殊:1个数据库可以有多个instance(rac)一台服务器上同时可装多套版本的数据库软件,每个数据库软件可建多个数据库,但是每个数据库只对应一个instance,也可以理解成每个数据库只有一个SID 。
利用DBCA建出的每个库都是相对独立的,在同一服务器上如果创建多库必须将环境变量的参数文件做区分,并且在对实例切换时需如下操作:connect 用户名/密码@实例的服务名Oracle Instance:是由内存(SGA)和后台进程(backupground Process)组成通过instance来访问database一个实例只能打开一个数据库Oracle database:数据文件(Data files):数据文件永远存储数据库的数据,包括数据字典、用户数据(表、索引、簇)、undo数据等重做日志(Redo log):“先记后写”重做日志用于记录数据库的变化,当进行例程恢复或介质恢复时需要使用重做日志执行DDL或DML操作时,事物变化会被写到重做日志缓冲区,而在特定的时刻LGWR会将重做日志缓冲区中的内容写入重做日志。
控制文件(Control file)控制文件用于记录和维护数据库的物理结构,并且每个Oracle数据库至少要包含一个控制文件。
归档日志(Archive log):是非活动(Inactive)重做日志的备份。
口令文件(Password file):用于验证特权用户(具有SYSDBA、SYSOPER权限的特殊数据库用户)参数文件(Parameter file):用于定义启动实例所需要的初始化参数,包括文本参数文件(pfile)和服务器参数文件(spfile)(二进制文件放入裸设备,引入spfile)User and Server process :在执行sql语句时产生的进程,每一个连接,oracle server创建一个session,产生一个server process,在client发起一个connection时就产生了一个user process。
Oracle体系结构一、物理结构二、逻辑结构三、内存结构四、数据库实例与进程五、数据字典一、Oracle 的物理结构Oracle 数据库文件包括数据文件、日志文件、控制文件、配置文件数据文件(1)用来存储数据库中的全部数据,如数据库表中的数据和索引数据。
通常为后缀名为.dbf格式的文件。
(2) 每个Oracle 可以有一个或多个数据文件,一个数据文件只能属于一个数据库。
(3) 每个数据文件又由若干物理块组成;(4) 一个或多个数据文件组成表空间;日志文件(重做日志文件)(1)用于记录数据库所做的全部变更(如增加、删除、修改),以便在系统发生故障时,用它对数据库进行恢复。
名字通常为Log*.dbf格式。
控制文件(1)用于打开和存取数据库。
(2)是较小的二进制文件,记录了数据库的物理结构,如:数据库名、数据库的数据文件和日志文件的名字和位置等信息。
(3)名字通常为Ctr*.ctl格式,如CtrlCIMS.ctl。
(4)控制文件中的内容只能够由Oracle本身来修改。
(5)每个数据库必须至少拥有一个控制文件。
一个数据库也可有多个控制文件,但是一个控制文件只能属于一个数据库。
配置文件:(1)是一个ASCII文本文件,记录Oracle 数据库运行时的一些重要参数。
(2)名字通常为initsid*.ora格式,如:initCIMS.ora,(3)SID相当于它所控制的数据库的标识符。
(4)每个Oracle数据库和实例都有它自己惟一的init.ora 文件。
二、Oracle 的逻辑结构逻辑结构描述了数据库从逻辑上如何来存储数据块中的数据。
包括表空间、段、区、数据块和模式对象。
逻辑结构支配一个数据库如何使用系统的物理空间,模式对象及其之间的关系则描述关系数据库之间的设计。
一个数据块从逻辑上是由一个或多个表空间组成,表空间是数据块中物理编组的数据仓库,每个表空间由段构成,段由一组区组成,一个区由连续的数据块组成。
ORACLE 体系结构(Architecture of ORACLE)第一部分:ORACLE8i体系结构第一章. 概要在本章里你可以了解以下内容1、理解ORACLE 实例的组成2、理解ORACLE 数据库的组成3、理解ORACLE内存结构的组成4、理解后台进程的作用与分工5、理解数据库的物理文件与对应的逻辑结构6、理解ORACLE的整体构架第二章. 理解ORACLE实例2.1 ORACLE SERVERORACLE是一个可移植的数据库——它在相关的每一个平台上都可以使用,即所谓的跨平台特性。
在不同的操作系统上也略有差别,如在UNIX/LINUX上,ORACLE是多个进程实现的,每一个主要函数都是一个进程;而在Windows上,则是一个单一进程,但是在该进程中包含多个线程。
但是从整体构架上来看,ORACLE在不同的平台上是一样的,如内存结构、后台进程、数据的存储。
一个运行着的ORACLE数据库就可以看成是一个ORACLE SERVER,该SERVER由数据库(Database)和实例(Instance)组成,在一般的情况下一个ORACLE SERVER包含一个实例和一个与之对应的数据库,但是在特殊情况下,如8i的OPS,9i的RAC,一个SERVER中一个数据库可以对应多个实例。
一系列物理文件(数据文件,控制文件,联机日志等)的集合或与之对应的逻辑结构(表空间,段等)被称为数据库,简单的说,就是一系列与磁盘有关系的物理文件的组成。
ORACLE内存结构和后台进程被成为数据库的实例,一个实例最多只能安装(Mount)和打开(Open)在一个数据库上,负责数据库的相应操作并与用户交互。
实例与数据库的关系如下图所示:图一ORACLE SERVER2.2 ORACLE内存结构(Memory structure)2.2.1 内存结构的组成Oracle内存结构主要可以分共享内存区与非共享内存区,共享内存区主要包含SGA(System Global Area),非共享内存区主要由PGA(Program Global Area)组成,可以用如下图形表示。
图二ORACLE MEMOERY STRUCTRUE2.2.2全局共享区System Global Area(SGA)System Global Area 是一块巨大的共享内存区域,他被看做是Oracle 数据库的一个大缓冲池,这里的数据可以被ORACLE的各个进程共用。
其大小可以通过如下语句查看:SQL> select * from v$sga;NAME V ALUE-------------------- ---------Fixed Size 39816V ariable Size 259812784Database Buffers 1.049E+09Redo Buffers 327680更详细的信息可以参考V$sgastat、V$buffer_pool主要包括以下几个部分:2.2.2.1共享池(Shared pool)共享池是SGA中最关键的内存片段,特别是在性能和可伸缩性上。
一个太小的共享池会扼杀性能,使系统停止,太大的共享池也会有同样的效果,将会消耗大量的CPU来管理这个共享池。
不正确的使用共享池只会带来灾难。
共享池主要又可以分为以下两个部分:1、SQL语句缓冲(Library Cache)当一个用户提交一个SQL语句,Oracle会将这句SQL进行分析(parse),这个过程类似于编译,会耗费相对较多的时间。
在分析完这个SQL,Oracle会把他的分析结果给保存在Shared pool的Library Cache中,当数据库第二次执行该SQL时,Oracle自动跳过这个分析过程,从而减少了系统运行的时间。
这也是为什么第一次运行的SQL 比第二次运行的SQL 要慢一点的原因。
下面举例说明parse的时间SQL>StartupSQL> select count(*) from usertable;COUNT(*)----------243Elapsed: 00:00:00.08这是在Share_pool 和Data buffer 都没有数据缓冲区的情况下所用的时间SQL> alter system flush SHARED_POOL;System altered.清空Share_pool,保留Data bufferSQL> select count(*) from usertable;COUNT(*)-----------------243Elapsed: 00:00:00.02SQL> select count(*) from usertable;COUNT(*)----------------243Elapsed: 00:00:00.00从两句SQL 的时间差上可以看出该SQL 的Parse 时间约为00:00:00.02对于保存在共享池中的SQL语句,可以从V$Sqltext、v$Sqlarea中查询到,对于编程者来说,要尽量提高语句的重用率,减少语句的分析时间。
一个设计的差的应用程序可以毁掉整个数据库的Share pool,提高SQL语句的重用率必须先养成良好的变成习惯,尽量使用Bind变量。
2、数据字典缓冲区(Data Dictionary Cache)显而易见,数据字典缓冲区是ORACLE特地为数据字典准备的一块缓冲池,供ORACLE 内部使用,没有什么可以说的。
2.2.2.2块缓冲区高速缓存(Database Buffer Cache)这些缓冲是对应所有数据文件中的一些被使用到的数据块。
让他们能够在内存中进行操作。
在这个级别里没有系统文件,,户数据文件,临时数据文件,回滚段文件之分。
也就是任何文件的数据块都有可能被缓冲。
数据库的任何修改都在该缓冲里完成,并由DBWR进程将修改后的数据写入磁盘。
这个缓冲区的块基本上在两个不同的列表中管理。
一个是块的“脏”表(Dirty List),需要用数据库块的书写器(DBWR)来写入,另外一个是不脏的块的列表(LRU List),一般的情况下,是使用最近最少使用(Least Recently Used,LRU)算法来管理。
块缓冲区高速缓存又可以细分为以下三个部分(Default pool,Keep pool,Recycle pool)。
如果不是人为设置初始化参数(Init.ora),ORACLE将默认为Default pool。
由于操作系统寻址能力的限制,不通过特殊设置,在32位的系统上,块缓冲区高速缓存最大可以达到1.7G,在64位系统上,块缓冲区高速缓存最大可以达到10G。
2.2.2.3重做日志缓冲区(Redo log buffer)重做日志文件的缓冲区,对数据库的任何修改都按顺序被记录在该缓冲,然后由LGWR 进程将它写入磁盘。
这些修改信息可能是DML语句,如(Insert,Update,Delete),或DDL语句,如(Create,Alter,Drop等)。
重做日志缓冲区的存在是因为内存到内存的操作比较内存到硬盘的速度快很多,所以重作日志缓冲区可以加快数据库的操作速度,但是考虑的数据库的一致性与可恢复性,数据在重做日志缓冲区中的滞留时间不会很长。
所以重作日志缓冲区一般都很小,大于3M之后的重作日志缓冲区已经没有太大的实际意义。
2.2.2.4 Java程序缓冲区(Java Pool)Java 的程序区,Oracle 8I 以后,Oracle 在内核中加入了对Java的支持。
该程序缓冲区就是为Java 程序保留的。
如果不用Java程序没有必要改变该缓冲区的默认大小。
2.2.2.5大池(Large Pool)大池的得名不是因为大,而是因为它用来分配大块的内存,处理比共享池更大的内存,在8.0开始引入。
下面对象使用大池:1、MTS——在SGA的Large Pool中分配UGA2、语句的并行查询(Parallel Executeion of Statements)——允许进程间消息缓冲区的分配,用来协调并行查询服务器3、备份(Backup)——用于RMAN磁盘I/O缓存2.2.3程序共享区Program Global Area(PGA)Program Global Area(PGA)是用来保存与用户进程相关的内存段,PGA总是由进程或线程在本地分配,其它进程与线程无法访问。
User Global Area(UGA)实际上是会话的状态,它是会话必须始终能够得到的内存。
对于专用服务器进程,UGA在PGA中分配。
对于多线程进程,UGA在Large pool中分配。
PGA/UGA一般保存了用户的变量、权限、堆栈、排序(Sort)空间等信息。
影响PGA/UGA 最大的也就是Sort信息,由初始化参数sort_area_size决定,由于Sort信息分配在UGA中,所以在共享服务器中能更好的利用内存。
2.3 后台进程(Background process)后台进程是Oracle的程序,用来管理数据库的读写,恢复和监视等工作。
Server Process 主要是通过他和user process进行联系和沟通,并由他和user process进行数据的交换。
在Unix机器上,Oracle后台进程相对于操作系统进程,也就是说,一个Oracle后台进程将启动一个操作系统进程;在Windows机器上,Oracle后台进程相对于操作系统线程,打开任务管理器,我们只能看到一个ORACLE.EXE的进程,但是通过另外的工具,就可以看到包含在这里进程中的线程。
后台进程与其它结构的关系如图所示:图三ORACLE BACKGROUP PROCESS在Unix上可以通过如下方法查看后台进程:ps –ef | grep ora_# ps -ef | grep ora_ | grep XCLUA Toracle 29431 1 0 Sep 02 ? 2:02 ora_dbwr_SIDoracle 29444 1 0 Sep 02 ? 0:03 ora_ckpt_SIDoracle 29448 1 0 Sep 02 ? 2:42 ora_smon_SIDoracle 29442 1 0 Sep 02 ? 3:25 ora_lgwr_SIDoracle 29427 1 0 Sep 02 ? 0:01 ora_pmon_SIDOracle系统有5 个基本进程他们是DBWR(数据文件写入进程)LGWR(日志文件写入进程)SMON(系统监护进程)PMON(用户进程监护进程)CKPT(检查点进程,同步数据文件, 日志文件,控制文件)2.3.1 数据写进程DBWR将修改过的数据缓冲区的数据写入对应数据文件维护系统内的空缓冲区这里指出几个容易错误的概念:·当一个更新提交后,DBWR把数据写到磁盘并返回给用户提交完成。