编译原理词法分析--A__状态转换图-直接转向法-伪代码描述
- 格式:doc
- 大小:29.00 KB
- 文档页数:2

编译原理内容介绍编译原理是计算机科学中的一个重要领域,它研究的是如何将高级编程语言转换成计算机硬件能够直接执行的机器语言的过程。
在计算机科学中,编译原理是一个基础性的领域,涉及到计算机语言、计算机组成原理、最优化技术、算法分析等众多方面知识。
编译原理的研究旨在提高编程效率、代码可读性、运行效率和可移植性等方面,因此具有非常重要的意义。
编译原理主要包括以下几个方面的内容:1. 词法分析词法分析是将高级编程语言中的字符流转换为一系列有意义的词法符号的过程。
词法符号包括关键字、标识符、运算符、分界符等,它们是编程语言的基本组成部分。
词法分析器通常使用有限状态自动机来实现,可以通过正则表达式来定义词法规则。
2. 语法分析语法分析是将词法符号流转换为一个语法树的过程。
语法树是将编程语言的语法结构形式化的一种工具,它能够帮助编译器理解程序的结构和语义,为后续的中间代码的生成和优化提供便利。
语法分析器通常使用上下文无关文法来描述编程语言的语法规则,可以使用递归下降分析、LL分析器、LR分析器等算法来实现。
3. 语义分析语义分析是分析和检查程序的语义正确性的过程,它通常包括类型检查、变量声明的作用域和生命周期、函数调用和参数传递等方面的分析。
语义分析是编译器实现的关键步骤之一,它可以为代码生成和优化提供更准确的信息。
4. 中间代码生成中间代码生成是将语法树转换为具有一定格式的中间代码的过程,中间代码通常是一种类似于汇编语言的低级程序表示形式,它能够方便地被不同的目标平台所接受和执行。
中间代码的生成通常是由语法分析和语义分析过程直接实现,也可以采用优化算法对生成的中间代码进行优化。
5. 代码优化代码优化是对生成的中间代码进行优化的过程,它旨在提高代码的执行效率、减少代码大小和消除不必要的指令等。
代码优化是编译器设计的重要方面,这是因为优化好的代码可以使程序的性能和效率得到显著提升,在实际应用中具有非常重要的意义。

1.编译程序编译程序是一种翻译程序,它将高级语言所写的源程序翻译成等价的机器语言或汇编语言的目标程序。
2.词法分析(Lexical analysis或Scanning)和词法分析程序(Lexical analyzer 或Scanner)词法分析阶段是编译过程的第一个阶段。
这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
词法分析程序实现这个任务。
词法分析程序可以使用lex等工具自动生成。
3.语法分析(Syntax analysis或Parsing)和语法分析程序(Parser)语法分析是编译过程的一个逻辑阶段。
语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等.语法分析程序判断源程序在结构上是否正确.源程序的结构由上下文无关文法描述.4.语义分析(Syntax analysis)及中间代码生成语义分析是编译过程的一个逻辑阶段. 语义分析的任务是对结构上正确的源程序进行上下文有关性质的审查, 进行类型审查.例如一个C程序片断:int arr[2],b;b = arr * 10;源程序的结构是正确的.语义分析将审查类型并报告错误:不能在表达式中使用一个数组变量,赋值语句的右端和左端的类型不匹配.语义分析时,根据语句的含义,可对它进行翻译,用另一种语言形式(比源语言更接近于目标语言的一种中间代码或直接用目标语言)来描述这种语义。
5.代码优化代码优化的任务是对前阶段产生的中间代码进行等价变换或改造,以期获得更为高效的,即省时间和空间的代码。
6.目标代码生成目标代码的生成的任务是将中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码。
7.遍8.前端(Front-end)和后端(Back end)有时,常常把编译的过程分为前端(front end)和后端(back end),前端由那样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。


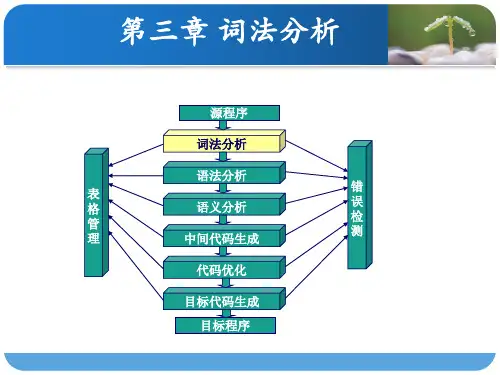
第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N⇒ND⇒N3⇒ND3⇒N23⇒D23⇒123N⇒ND⇒NDD⇒DDD⇒1DD⇒12D⇒123N⇒ND⇒N1⇒ND1⇒N01⇒D01⇒301N⇒ND⇒NDD⇒DDD⇒3DD⇒30D⇒301N⇒ND⇒N1⇒ND1⇒N31⇒ND31⇒N431⇒ND431⇒N5431⇒D5431⇒75431N⇒ND⇒NDD⇒NDDD⇒NDDDD⇒DDDDD⇒7DDDD⇒75DDD⇒754DD⇒7543D⇒75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S⇒iSeS⇒iiSesS⇒iS⇒iiSeS所以该文法是二义性文法。

实验一:词法分析一、实验目的:1、通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
2、编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本关键字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)二、实验预习提示1、词法分析器的功能和输出格式词法分析器的功能是输入源程序,输出单词符号。
词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
本实验中,采用的是一类符号一种别码的方式。
2、单词的BNF表示<标识符>-> <字母><字母数字串><字母数字串>-><字母><字母数字串>|<数字><字母数字串>|<下划线><字母数字串>|ε<无符号整数>-> <数字><数字串><数字串>-> <数字><数字串> |ε<加法运算符>-> +<减法运算符>->-<大于关系运算符>->><大于等于关系运算符>-> >=3、“超前搜索”方法词法分析时,常常会用到超前搜索方法。
如当前待分析字符串为“a>+”,当前字符为’>’,此时,分析器到底是将其分析为大于关系运算符还是大于等于关系运算符呢?显然,只有知道下一个字符是什么才能下结论。
于是分析器读入下一个字符’+’,这时可知应将’>’解释为大于运算符。
但此时,超前读了一个字符’+’,所以要回退一个字符,词法分析器才能正常运行。
在分析标识符,无符号整数等时也有类似情况。

编译原理的基本知识编译原理是计算机科学中非常重要的一门学科,它研究的是计算机程序的编写、编译和执行过程。
作为一名程序员,了解编译原理的基本知识非常重要,因为只有了解了编译原理的基本知识,我们才能够更好地编写高效、安全、可靠的程序。
在本文中,我们将介绍编译原理的基本知识,包括编译的过程、词法分析、语法分析、语义分析、优化和代码生成等方面。
一、编译的过程编译的过程可以分为四个阶段,分别是预处理、词法分析、语法分析和代码生成。
预处理的主要作用是对源代码进行一些替换和重定向。
例如,预处理器可以把代码中的宏定义替换成它所代表的部分,还可以把头文件的内容加入到源文件中。
预处理的结果是一个新的源文件,这个新的源文件中已经包含了所有的宏定义和头文件。
词法分析的作用是将源代码分解成一个个的词法单元,也就是经过语法分析器处理后表示意义的最小元素。
词法分析器会识别出特定的记号,例如变量名、关键字、运算符等等。
词法分析器的输出是一系列的词法单元。
语法分析的作用是判断所生成的词法单元是否符合语法规则,如果不符合语法规则,就会产生一个语法错误。
语法分析器会使用语法规则进行语法检查,同时生成一个语法树。
语法树是一个树形结构,它反映了程序中各个语法单位之间的层次关系。
语义分析的主要作用是判断程序是否符合语义规则。
例如,一个整型变量不能赋值为字符串类型。
语义分析器会使用语义规则进行语义检查,同时生成一个中间代码。
优化的作用是对中间代码进行优化,使得程序的执行效率更高、占用的空间更小。
通常,优化器会从减少代码行数、减小代码路径长度、减少内存读写次数等方面进行优化。
代码生成的主要作用是将中间代码转换成目标代码。
目标代码可以是汇编代码、机器代码等。
代码生成器会使用一种转换过程,将中间代码翻译成目标代码。
通常,这个过程会在多个阶段进行,包括指令选择、寄存器分配、代码调整等。
二、词法分析词法分析是编译器的第一个阶段。
它的作用是将源代码分解成一个个的词法单元,也就是经过语法分析器处理后表示意义的最小元素。


第一章:编译过程的六个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成解释程序:把某种语言的源程序转换成等价的另一种语言程序——目标语言程序,然后再执行目标程序。
解释方式是接受某高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这句的执行结果,然后再接受下一句。
编译程序:就是指这样一种程序,通过它能够将用高级语言编写的源程序转换成与之在逻辑上等价的低级语言形式的目标程序(机器语言程序或汇编语言程序)。
解释程序和编译程序的根本区别:是否生成目标代码第三章:Chomsky对文法中的规则施加不同限制,将文法和语言分为四大类:0型文法(PSG)◊ 0型语言或短语结构语言文法G的每个产生式α→β中:若α∈V*VNV*, β∈(VN∪VT)* ,则G是0型文法,即短语结构文法。
1型文法(CSG)◊ 1型语言或上下文有关语言在0型文法的基础上:若产生式集合中所有|α|≤|β|,除S→ε(空串)外,则G是1型文法,即:上下文有关文法另一种定义:文法G的每一个产生式具有下列形式:αAδ→αβδ,其中α、δ∈V*,A∈VN,β∈V+;2型文法(CFG)◊ 2型语言或上下文无关语言文法G的每个产生式A→α,若A∈VN ,α∈(VN∪VT)*,则G是2型法,即:上下文无关文法。
3型文法(RG)◊ 3型语言或正则(正规)语言若A、B∈VN,a∈VT或ε,右线性文法:若产生式为A→aB或A→a左线性文法:若产生式为A→Ba或A→a都是3型文法(即:正规文法)最左(最右)推导在推导的任何一步α⇒β,其中α、β是句型,都是对α中的最左(右)非终结符进行替换规范推导:即最右推导。
规范句型:由规范推导所得的句型。
句子的二义性(这里的二义性是指语法结构上的。
)文法G[S]的一个句子如果能找到两种不同的最左推导(或最右推导),或者存在两棵不同的语法树,则称这个句子是二义性的。
文法的二义性一个文法如果包含二义性的句子,则这个文法是二义文法,否则是无二义文法。

第三章3.1 对于词法分析器的要求1.词法词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。
词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序。
2.程序语言的单词符号:关键字、标识符、常数、运算符、界符。
3.输出的单词符号的表示形式:(单词种别,单词自身的值)Eg:while (i>=j) i--;输出单词符号:< while, - >< (, - >< id, 指向i的符号表项的指针><>=, - >< id, 指向j的符号表项的指针>< ), - >< id, 指向i的符号表项的指针>< --, - >< ;, - >4.词法分析器作为一个独立子程序:结构简洁、清晰和条理化,有利于集中考虑词法分析一些枝节问题。
5.词法分析器3.2 词法分析器的设计1.词法分析器2.输入、预处理:输入串放在输入缓冲区中。
预处理子程序:剔除无用的空白、跳格、回车和换行等编辑性字符;区分标号区、捻接续行和给出句末符等扫描缓冲区(指向开始位置,向前搜索确定终点)3.单词符号的识别、超前搜索:(1)基本字识别Eg:DO99K=1,10 DO 99 K = 1,10IF(5.EQ.M)GOTO55 IF (5.EQ.M) GOTO 55DO99K=1.10IF(5)=55需要超前搜索才能确定哪些是基本字(2)标识符(3)常数(4)算符和界符4.状态转换图(有限方向图)<1>结点代表状态<2>状态之间用箭弧连结,箭弧上的标记(字符)代表射出结状态下可能出现的输入字符或字符类。
<3>一个状态转换图可用于识别(或接受)一定的字符串。
5.语法分析的状态转换图6.状态转换图的实现思想:每个状态结对应一小段程序。
编译原理词法分析和语法分析报告+代码(C语言版)-CAL-FENGHAI.-(YICAI)-Company One1信息工程学院实验报告(2010 ~2011 学年度第一学期)姓名:柳冠天学号:2081908318班级:083词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
(2)运算符和界符: = + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:表2.1 各种单词符号对应的种别码2.3 词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
1.编译程序的工作一般分为词法分析、语法分析、语义分析与中间代码生成、优化和目标代码生成五个阶段。
2.和各阶段都有关的是:表格管理和出错处理。
3. 遍:编译程序具体实现时,往往将编译程序组织成若干遍。
1.程序语言是由语法和语义两方面定义的。
2.上下文无关文法的定义:四个组成部分:一组终结符号、一组非终结符号、一个开始符号、一组产生式。
2.文法G产生的句子的全体是该文法描述的语言。
3.什么是句型?什么是句子?什么是语言?假定G是一个文法,S是它的开始符号。
如果S α,则称α是一个句型。
仅含终结符的句型是一个句子。
文法G所产生的句子的全体是一个语言。
6.乔姆斯基把文法分成4种类型,即0型文法、1型文法、2型文法和3型文法。
0型文法也称为短语文法。
1型文法也称为上下文有关文法。
2型文法也称为上下文无关文法。
3型文法也称为正规文法。
与程序语言语法有关的文法是上下文无关文法1.词法分析器的任务是什么?词法分析的任务是输入源程序,对构成源程序的字符串进行扫描和分解,识别出一个个的单词2.使用状态转换图是设计词法分析程序的一种好途径,在状态转换图中,结点代表状态,用圆圈表示。
状态转换图是识别(或接受)一定的字符串。
3.确定的有限自动机(DFA)、非确定有限自动机(NFA)。
五元式:有限状态集合、有穷字母表、转换函数、唯一的初始状态、终止状态集合。
4.设有确定的有限自动机DFA M = ({0,1,2,3},{a,b},δ,0,{3}),其中δ为: δ(0,a)=1 δ(0,b)=2δ(1,a)=3 δ(1,b)=2δ(2,a)=1 δ(2,b)=3δ(3,a)=3 δ(3,b)=3请画出状态转换矩阵和状态转化图。
5.设计一个DFA,要求能够识别∑={0,1}上能被5整除的二进制数1.语法分析器的功能2.自上而下语法分析方法会遇到的主要问题是回溯和左递归。
3.把一个文法改造成任何非终结符的所有候选式首符集两两不相交的方法是提取公共左因子。
编译原理词法分析--A__状态转换图-直接转向法-伪代码描述int code, value;strToken := ““;GetChar(); //将下一字符读入ch中, 搜索指示器前移一个字符位置GetBC(); //检查ch中的字符是否为空白,若是调用GetChar直至读入非空白字符if (IsLetter())//判断ch中的字符是否为字母beginwhile (IsLetter() or IsDigit())beginConcat(); //将ch中的字符连接到strToken之后GetChar();EndRetract(); //将搜索指示器回退一个字符位置, 将ch置为空code = Reserve(); //对strToken中的字符串查找保留字表,若是,返回编码;否则返回0 if (code = 0)beginvalue := InsertId(strToken); //将strT oken中的标识符插入符号表,返回指针return ($ID, value);endelsereturn (code, -);endelse if (IsDigit())//判断ch中的字符是否为数字beginwhile (IsDigit))beginConcat();GetChar();EndRetract();Value := InsertToken(); //将strToken中的标识符插入常数表,返回指针return ($INT, value);endelse if (ch = ‘=’)return ($ASSIGN, -);else if (ch = ‘+’)return ($PLUS, -);else if (ch = ‘*’)beginGetChar();if (ch = ‘*’) return ($POWER,-);Retract(); return ($STAR,-);endelse if (ch = ‘;’)return ($SEMICOLON, -);else if (ch = ‘(’)return ($LPAR, -);else if (ch = ‘)’)return ($RPAR, -); else if (ch = ‘{’)return ($LBRACE, -); else if (ch = ‘}’ )return ($RBRACE, -); else ProcError(); //错误处理。
int code, value;
strToken := ““;
GetChar(); //将下一字符读入ch中, 搜索指示器前移一个字符位置
GetBC(); //检查ch中的字符是否为空白,若是调用GetChar直至读入非空白字符if (IsLetter())//判断ch中的字符是否为字母
begin
while (IsLetter() or IsDigit())
begin
Concat(); //将ch中的字符连接到strToken之后
GetChar();
End
Retract(); //将搜索指示器回退一个字符位置, 将ch置为空
code = Reserve(); //对strToken中的字符串查找保留字表,若是,返回编码;否则返回0 if (code = 0)
begin
value := InsertId(strToken); //将strToken中的标识符插入符号表,返回指针
return ($ID, value);
end
else
return (code, -);
end
else if (IsDigit())//判断ch中的字符是否为数字
begin
while (IsDigit))
begin
Concat();
GetChar();
End
Retract();
Value := InsertToken(); //将strToken中的标识符插入常数表,返回指针
return ($INT, value);
end
else if (ch = ‘=’)return ($ASSIGN, -);
else if (ch = ‘+’)return ($PLUS, -);
else if (ch = ‘*’)
begin
GetChar();
if (ch = ‘*’) return ($POWER,-);
Retract(); return ($STAR,-);
end
else if (ch = ‘;’)return ($SEMICOLON, -);
else if (ch = ‘(’)return ($LPAR, -);
else if (ch = ‘)’)return ($RPAR, -); else if (ch = ‘{’)return ($LBRACE, -); else if (ch = ‘}’ )return ($RBRACE, -); else ProcError(); //错误处理。