R 语言环境下用ARIMA模型做时间序列预测
- 格式:docx
- 大小:171.37 KB
- 文档页数:8

时间序列分析R语言代码时间序列分析是统计学中的一个重要分支,主要用于研究随时间变化的数据。
它可以帮助我们了解数据的趋势、周期性和季节性等特征,从而为预测和决策提供依据。
R语言是一种功能强大的统计分析工具,提供了丰富的时间序列分析函数和包,以下是一个简单的时间序列分析R语言代码示例。
首先,我们需要加载需要用到的包,如`ggplot2`和`forecast`。
```Rlibrary(ggplot2)library(forecast)```接下来,我们可以导入时间序列数据,并将其转换为时间序列对象。
假设我们有一个名为`data.csv`的数据文件,其中包含每个月份的销售额数据。
```Rdata <- read.csv("data.csv")ts_data <- ts(data$Sales, start = c(2000, 1), frequency = 12) ```通过绘制时间序列图,我们可以直观地观察数据的趋势和季节性。
```Rggplot(data, aes(x = Month, y = Sales)) +geom_line( +xlab("Month") +ylab("Sales") +theme_minimal``````R```接下来,我们可以通过绘制分解后的趋势、季节性和随机成分图来进一步研究数据的特征。
```Rtheme_minimal```我们还可以使用自回归移动平均模型(ARIMA)对时间序列数据进行建模和预测。
首先,我们需要估计ARIMA模型的参数。
```Rarima_model <- auto.arima(ts_data)```通过`auto.arima(`函数,R会自动选择最佳的ARIMA模型。
然后,我们可以使用这个模型来进行预测。
假设我们希望对未来12个月的销售额进行预测。
```Rforecast_data <- forecast(arima_model, h = 12)```最后,我们可以绘制预测结果和置信区间的图表。
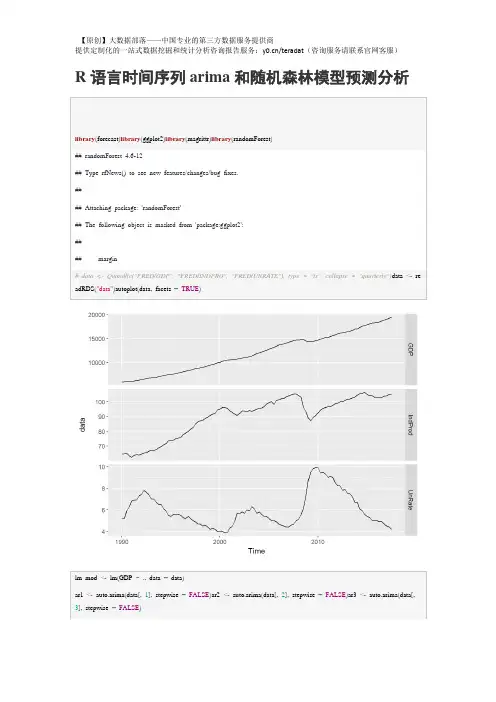

R语言时间序列有关各种函数总结R语言是一种强大的统计分析和数据可视化工具,提供了许多时间序列分析的函数和方法。
下面是一些重要的时间序列分析函数的总结:1. ts(函数:用于创建时间序列对象。
可以指定时间序列的起始时间、结束时间、时间间隔等。
例如,创建从1990年1月到1999年12月的月度时间序列对象可以使用以下代码:```Rts_data <- ts(data, start=c(1990, 1), end=c(1999, 12), frequency=12)``````R```3. stl(函数:基于季节性-趋势-随机性分解的局部回归方法,用于进行季节调整。
该函数可以根据时间序列的特性自动选择适当的分解模型。
以下是使用stl(函数进行季节调整的示例:```Rseasonally_adjusted <- stl(ts_data, s.window="periodic")```4. forecast(函数:用于时间序列的预测。
可以根据历史数据拟合不同的模型,例如ARIMA模型、指数平滑模型等,并生成未来一段时间的预测结果。
以下是使用forecast(函数生成未来12个月的预测结果的示例:```Rforecast_result <- forecast(ts_data, h=12)```5. autocorrelation(函数:用于计算时间序列的自相关系数。
自相关系数可以帮助我们了解时间序列的固定模式和周期性。
以下是计算时间序列的自相关系数的示例:```Racf_result <- autocorrelation(ts_data)```6. arima(函数:用于建立自回归移动平均模型(ARIMA)来拟合时间序列。
ARIMA模型是一种常用的时间序列预测模型,可以预测时间序列的未来值。
以下是使用arima(函数拟合ARIMA模型的示例:```Rarima_model <- arima(ts_data, order=c(p, d, q))```7. ets(函数:用于指数平滑时间序列模型的拟合和预测。

r语言arima函数用法一、介绍ARIMA(Autoregressive Integrated Moving Average)模型是一种常用的时间序列分析方法,它可以用来预测未来的数据趋势。
在R 语言中,arima函数是实现ARIMA模型的主要函数之一。
二、语法arima(x, order = c(p, d, q), seasonal = c(P, D, Q), ...)参数说明:x:时间序列数据order:一个长度为3的向量,分别表示AR、差分和MA的阶数seasonal:一个长度为4的向量,分别表示季节性AR、季节性差分和季节性MA的阶数以及周期...:其他可选参数三、使用方法1. 导入数据首先需要导入时间序列数据,可以使用read.csv等函数将csv文件导入为data.frame格式,再使用ts函数将其转换为时间序列格式。
2. 确定模型阶数确定ARIMA模型的阶数是非常重要的。
可以通过绘制自相关图ACF 和偏自相关图PACF来辅助判断。
如果ACF在滞后p处截尾,而PACF在滞后q处截尾,则可以考虑使用ARIMA(p,d,q)模型。
3. 拟合模型使用arima函数拟合ARIMA模型,并将结果保存在一个对象中。
例如:model <- arima(x, order = c(p, d, q), seasonal = c(P, D, Q))其中x是时间序列数据,p、d、q和P、D、Q分别表示ARIMA模型的阶数和周期。
4. 模型诊断拟合模型后,需要对其进行诊断。
可以使用checkresiduals函数检查残差是否符合正态分布和白噪声等假设。
如果残差不符合假设,则需要重新调整模型。
5. 预测未来值使用forecast函数可以预测未来的时间序列值。
例如:forecast(model, h = n)其中h表示预测的步数,n表示时间序列数据的长度。
四、示例以下是一个简单的ARIMA模型示例:1. 导入数据data <- read.csv("data.csv")ts_data <- ts(data$y, start = c(2010, 1), frequency = 12)2. 确定模型阶数acf(ts_data)pacf(ts_data)由自相关图和偏自相关图可以看出,ACF在1处截尾,而PACF在2处截尾,因此可以使用ARIMA(1,0,2)模型。

R语言arima模型时间序列分析报告(附代码数据)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了R语言arima模型时间序列分析报告library(openxlsx)data=read.xlsx("hs300.xlsx")XXX收盘价(元)`date=data$日期date=as.Date(as.numeric(date),origin="1899-12-30")#1998-07-05#绘制时间序列图plot(date,timeseries)timeseriesdiff<-diff(timeseries,differences=1)plot(date[-1],timeseriesdiff)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#我们可以通过键入下面的代码来得到时间序列(数据存于“timeseries”)的一阶差分,并画出差分序列的图:#时间序列分析之ARIMA模型预测#从一阶差分的图中可以看出,数据仍是不平稳的。
我们继续差分。
【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#二次差分(上面)后的时间序列在均值和方差上确实看起来像是平稳的,随着时间推移,时间序列的水平和方差大致保持不变。
因此,看起来我们需要对data进行两次差分以得到平稳序列。
#第二步,找到合适的ARIMA模型#如果你的时间序列是平稳的,或者你通过做n次差分转化为一个平稳时间序列,接下来就是要选择合适的ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的p值和q值。
为了得到这些,通常需要检查[平稳时间序列的(自)相关图和偏相关图。
#我们使用R中的“acf()”和“pacf”函数来分别(自)相关图和偏相关图。

基于ARIMA模型的时间序列预测分析时间序列预测分析是经济学和金融领域的重要应用之一,也是数据分析领域中非常基础的操作。
在实际的运用中,为了准确预测未来的数据趋势,我们必须有一种可靠的方法来对现有的时间序列数据进行建模和预测。
ARIMA模型,作为时间序列模型中的一个经典算法,可以解决这个问题。
ARIMA模型全称为自回归移动平均模型(Autoregressive Integrated Moving Average),是一种基于时间序列的统计分析方法,可以用于对非周期性、平稳时间序列样本的拟合与分析,以及预测其未来表现。
ARIMA模型的应用广泛,包括经济学、金融、气象、医学等领域,是时间序列预测中最常用的模型之一。
ARIMA模型的建立,需要对时间序列数据做许多处理和检验工作。
首先,我们需要检查所处理的时间序列数据是否符合ARIMA模型的假设:平稳性,即时间序列数据在不同时间段内的方差和均值都应该相等。
如果时间序列数据不符合平稳性假设,我们需要进行差分操作,将非平稳时间序列转化为平稳时间序列。
同时,根据检验结果,选择合适的阶数并确定ARIMA模型的系数。
阶数包括自回归阶数、差分阶数、移动平均阶数等,不同阶数的选择会影响ARIMA模型的预测效果。
ARIMA模型的预测目的是预测未来一段时间内的时间序列数据。
在进行模型预测时,我们需要确定预测的区间长度,根据之前的数据,计算需要预测的时间序列数据点所在的时间段内的均值和方差,并依照ARIMA模型的计算公式进行预测。
ARIMA模型在时间序列预测中的应用,已经非常成熟。
但是,ARIMA模型也有一些缺陷。
第一,ARIMA模型对于数据的通常要求非常苛刻,需要平稳且线性的时间序列数据;第二,ARIMA模型仅适用于描述非周期性时间序列数据,对于周期性和复杂时间序列数据,ARIMA模型效果欠佳。
因此,在实际预测中,我们需要针对数据的特点选择不同的方法和模型进行分析,以得到更加准确的预测结果。

⽤R做时间序列分析之ARIMA模型预测昨天刚刚把导⼊数据弄好,今天迫不及待试试怎么做预测,⽹上找的帖⼦跟着弄的。
第⼀步.对原始数据进⾏分析⼀.ARIMA预测时间序列指数平滑法对于预测来说是⾮常有帮助的,⽽且它对时间序列上⾯连续的值之间相关性没有要求。
但是,如果你想使⽤指数平滑法计算出预测区间,那么预测误差必须是不相关的,⽽且必须是服从零均值、⽅差不变的正态分布。
即使指数平滑法对时间序列连续数值之间相关性没有要求,在某种情况下,我们可以通过考虑数据之间的相关性来创建更好的预测模型。
⾃回归移动平均模型( ARIMA)包含⼀个确定(explicit)的统计模型⽤于处理时间序列的不规则部分,它也允许不规则部分可以⾃相关。
⼆.确定数据的差分ARIMA 模型为平稳时间序列定义的。
因此,如果你从⼀个⾮平稳的时间序列开始,⾸先你就需要做时间序列差分直到你得到⼀个平稳时间序列。
如果你必须对时间序列做 d 阶差分才能得到⼀个平稳序列,那么你就使⽤ARIMA(p,d,q)模型,其中 d 是差分的阶数。
我们以每年⼥⼈裙⼦边缘的直径做成的时间序列数据为例。
从 1866 年到 1911 年在平均值上是不平稳的。
随着时间增加,数值变化很⼤。
下⾯是.dat数据:下⾯进⼊预测。
先导⼊数据:> skirts <- scan("/tsdldata/roberts/skirts.dat",skip=5) #导⼊在线数据,并跳过前5⾏Read 46 items #R控制台显⽰内容,表⽰共读取46⾏数据> skirts<- ts(skirts,start = c(1866)) #设定时间1866开始> plot.ts(skirts) #画出图我们可以通过键⼊下⾯的代码来得到时间序列(数据存于“skirtsts”)的⼀阶差分,并画出差分序列的图: > skirtsdiff<-diff(skirts,differences=1) #⼀阶差分> plot.ts(skirtsdiff) #画图从⼀阶差分的图中可以看出,数据仍是不平稳的。

r语言时间序列拟合在R语言中,我们可以使用`arima`函数来拟合时间序列。
将时间序列数据读取到一个向量或数据框中。
假设我们有一个名为`tsdata`的向量,表示一个时间序列。
然后,我们可以使用`arima`函数来拟合时间序列。
`arima`函数的基本语法如下:```Rfit <- arima(tsdata, order = c(p, d, q))```其中,`tsdata`是时间序列数据,`order`参数指定自回归阶数p、积分阶数d和移动平均阶数q。
根据实际情况,需要根据自己的数据选择合适的阶数。
一种常见的方法是使用自相关图ACF和偏自相关图PACF来确定阶数。
可以使用`acf`和`pacf`函数来绘制这两个图形。
接下来,我们可以使用拟合模型对未来的观测值进行预测。
使用`forecast`函数可以根据已有的观测值和拟合模型预测未来的观测值。
下面是一个完整的例子:```R# 读取时间序列数据tsdata <- c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)# 拟合时间序列fit <- arima(tsdata, order = c(1, 0, 0))# 绘制自相关图acf(tsdata)# 绘制偏自相关图pacf(tsdata)# 预测未来观测值forecast_values <- forecast(fit, h = 5) # h表示预测的步长# 输出预测结果print(forecast_values)```这将输出拟合模型的参数估计和预测的未来观测值。

一、概述ARIMA模型(自回归移动平均模型)是一种时间序列分析模型,用于预测和分析时间序列数据的趋势和季节性变动。
在ARIMA模型中,残差检验是非常重要的,用来验证模型的拟合效果和预测精度。
本文将使用R语言来进行ARIMA模型的残差检验,以期验证模型的有效性和稳健性。
二、ARIMA模型简介ARIMA模型是由自回归(AR)和移动平均(MA)两部分组成的,其中AR部分用来刻画时间序列数据的自相关性,MA部分用来刻画时间序列数据的移动平均性,而I部分则用来描述时间序列数据的差分性。
在R语言中,我们可以使用arima函数来构建ARIMA模型,其基本形式为:```model <- arima(data, order=c(p, d, q))```其中,data为时间序列数据,p为自回归项数量,d为差分阶数,q 为移动平均项数量。
三、残差检验方法残差检验是用来验证模型的拟合效果和预测精度的重要手段,通常包括自相关性检验、正态性检验和异方差性检验三个方面。
1. 自相关性检验自相关性检验用来验证模型的残差是否存在自相关性,常用的方法有Ljung-Box检验和Durbin-Watson检验。
在R语言中,我们可以使用acf函数和Box.test函数来进行自相关性检验。
2. 正态性检验正态性检验用来验证模型的残差是否符合正态分布,常用的方法有QQ图和Shapiro-Wilk检验。
在R语言中,我们可以使用qqnorm 函数和qqline函数来进行QQ图的绘制,使用shapiro.test函数来进行Shapiro-Wilk检验。
3. 异方差性检验异方差性检验用来验证模型的残差是否存在异方差性,常用的方法有Breusch-Pagan检验和White检验。
在R语言中,我们可以使用bptest函数和ncvTest函数来进行异方差性检验。
四、使用R语言进行ARIMA模型残差检验下面我们将使用R语言来演示如何进行ARIMA模型的残差检验。

r语言arima函数参数R语言中的arima函数是用于拟合自回归移动平均模型(ARIMA)的函数。
ARIMA模型是一种常用的时间序列分析方法,用于预测未来的观测值。
arima函数有多个参数,下面将逐个介绍这些参数的含义和用法。
## 参数1: xx是一个时间序列向量或者一个包含时间序列的矩阵。
它是我们要拟合ARIMA模型的数据。
## 参数2: orderorder是一个长度为3的向量,表示ARIMA模型中自回归(p)、差分(d)和移动平均(q)部分的阶数。
order=c(1,1,0)表示拟合一个一阶差分自回归移动平均模型。
## 参数3: seasonalseasonal是一个长度为4的向量,表示季节性部分的阶数。
seasonal=c(0,1,1,4)表示在每个季度进行一次一阶差分操作,并且使用一个一阶差分移动平均过程。
## 参数4: include.meaninclude.mean是一个逻辑值,表示是否在ARIMA模型中包含均值项。
默认情况下,include.mean为TRUE,即包含均值项。
## 参数5: methodmethod是用于估计ARIMA模型参数的方法。
常见的方法有“CSS-ML”(条件最大似然估计)和“CSS”(条件和平方误差)。
默认情况下,method为“CSS-ML”。
## 参数6: optim.controloptim.control是一个控制优化算法的参数。
可以通过optim.control 函数设置参数的值,例如控制迭代次数、收敛容限等。
## 参数7: kappakappa是一个正则化参数,用于减小模型中的过拟合。
默认情况下,kappa为0。
## 参数8: xregxreg是一个可选的外部回归变量矩阵。
如果提供了xreg,则ARIMA模型中会包含这些外部回归变量。
## 参数9: testtest是一个逻辑值,表示是否进行残差诊断检验。
默认情况下,test为FALSE,即不进行残差诊断检验。

本文是我们通过时间序列和ARIMA模型预测拖拉机销售的制造案例研究示例的延续。
您可以在以下链接中找到以前的部分:第1部分:时间序列建模和预测简介第2部分:在预测之前将时间序列分解为解密模式和趋势第3部分:ARIMA预测模型简介在本部分中,我们将使用图表和图表通过ARIMA预测PowerHorse拖拉机的拖拉机销售情况。
我们将使用前一篇文章中学到的ARIMA建模概念作为我们的案例研究示例。
但在我们开始分析之前,让我们快速讨论一下预测:诺查丹玛斯的麻烦人类对未来和ARIMA的痴迷 - 由Roopam撰写人类对自己的未来痴迷- 以至于他们更多地担心自己的未来而不是享受现在。
这正是为什么恐怖分子,占卜者和算命者总是高需求的原因。
Michel de Nostredame(又名Nostradamus)是一位生活在16世纪的法国占卜者。
在他的着作Les Propheties (The Prophecies)中,他对重要事件进行了预测,直到时间结束。
诺查丹玛斯的追随者认为,他的预测对于包括世界大战和世界末日在内的重大事件都是不可挽回的准确。
例如,在他的书中的一个预言中,他后来成为他最受争议和最受欢迎的预言之一,他写了以下内容:“饥饿凶猛的野兽将越过河流战场的大部分将对抗希斯特。
当一个德国的孩子什么都没有观察时,把一个伟大的人画进一个铁笼子里。
“他的追随者声称赫斯特暗指阿道夫希特勒诺查丹玛斯拼错了希特勒的名字。
诺查丹玛斯预言的一个显着特点是,他从未将这些事件标记到任何日期或时间段。
诺查丹玛斯的批评者认为他的书中充满了神秘的专业人士(如上所述),他的追随者试图强调适合他的写作。
为了劝阻批评者,他的一个狂热的追随者(基于他的写作)预测了1999年7月世界末日的月份和年份 - 相当戏剧化,不是吗?好吧当然,1999年那个月没有发生任何惊天动地的事情,否则你就不会读这篇文章。
然而,诺查丹玛斯将继续成为讨论的话题,因为人类对预测未来充满了痴迷。
基于ARIMA模型的时间序列预测时间序列预测是一种重要的预测方法,它在许多领域中都有广泛的应用,包括经济学、金融学、气象学、交通规划等。
基于ARIMA模型的时间序列预测是一种经典方法,它能够通过对历史数据的分析和模型拟合来预测未来的趋势和变化。
本文将介绍ARIMA模型的基本原理及其在时间序列预测中的应用,并通过一个实例来说明其有效性和局限性。
ARIMA模型是自回归移动平均自回归模型(Autoregressive Integrated Moving Average Model)的简称,它是一种常用于时间序列分析和预测的统计模型。
ARIMA模型基于以下几个假设:首先,时间序列数据应该是平稳的,即其均值和方差在不同时刻上保持不变;其次,时间序列数据之间存在一定程度上的相关性;最后,在建立ARIMA 模型之前需要对原始数据进行差分操作以消除非平稳性。
ARIMA模型包括三个部分:自回归(Autoregressive, AR)部分、差分(Integrated, I)部分和移动平均(Moving Average, MA)部分。
自回归部分表示当前时刻值与过去时刻值之间的线性关系,差分部分表示对原始数据进行差分操作以达到平稳性,移动平均部分表示当前时刻值与过去时刻的误差之间的线性关系。
这三个部分的组合构成了ARIMA模型。
在ARIMA模型中,参数的选择是非常重要的。
选择合适的参数可以提高模型的拟合度和预测准确度。
常用方法包括自相关函数(ACF)和偏自相关函数(PACF)图,以及信息准则(AIC、BIC等)来选择最佳参数。
ARIMA模型在时间序列预测中具有广泛应用。
例如,在经济学中,ARIMA模型可以用来预测股票价格、通货膨胀率等经济指标;在气象学中,ARIMA模型可以用来预测温度、降雨量等气象数据;在交通规划中,ARIMA模型可以用来预测交通流量、拥堵情况等。
然而,ARIMA模型也存在一些局限性。
首先,在时间序列数据中可能存在非线性关系或季节性变化,在这种情况下使用ARIMA模型可能无法达到理想效果;其次,在实际应用中,时间序列数据可能受到外部因素(如变化、自然灾害等)的影响,这些因素无法通过ARIMA模型来捕捉;最后,ARIMA模型的预测结果可能受到数据长度和质量的影响,因此在使用ARIMA模型进行预测时需要谨慎选择和处理数据。
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测原⽂链接:/?p=12272使⽤ARIMA模型,您可以使⽤序列过去的值预测时间序列。
在本⽂中,我们从头开始构建了⼀个最佳ARIMA模型,并将其扩展到Seasonal ARIMA(SARIMA)和SARIMAX模型。
1.时间序列预测简介时间序列是在定期的时间间隔内记录度量的序列。
根据频率,时间序列可以是每年(例如:年度预算),每季度(例如:⽀出),每周(例如:销售数量),每天(例如天⽓),每⼩时(例如:股票价格),分钟(例如:来电提⽰中的呼⼊电话),甚⾄是⼏秒钟(例如:⽹络流量)。
为什么要预测?因为预测时间序列(如需求和销售)通常具有巨⼤的商业价值。
在⼤多数制造公司中,它驱动基本的业务计划,采购和⽣产活动。
预测中的任何错误都会在整个供应链或与此相关的任何业务环境中蔓延。
因此,准确地进⾏预测很重要,以节省成本,这对于成功⾄关重要。
不仅在制造业中,时间序列预测背后的技术和概念还适⽤于任何业务。
现在,预测时间序列可以⼤致分为两种类型。
如果仅使⽤时间序列的先前值来预测其未来值,则称为单变量时间序列预测单变量时间序列预测。
多变量时间序列预测。
如果您使⽤序列以外的其他预测变量(也称为外⽣变量)进⾏预测,则称为多变量时间序列预测这篇⽂章重点介绍⼀种称为ARIMA建模的特殊类型的预测⽅法。
ARIMA是⼀种预测算法,其基于以下思想:时间序列的过去值中的信息可以单独⽤于预测未来值。
2. ARIMA模型简介那么ARIMA模型到底是什么?ARIMA是⼀类模型,可以根据⾃⾝的过去值(即⾃⾝的滞后和滞后的预测误差)“解释”给定的时间序列,因此可以使⽤⽅程式预测未来价值。
任何具有模式且不是随机⽩噪声的“⾮季节性”时间序列都可以使⽤ARIMA模型进⾏建模。
ARIMA模型的特征在于3个项:p,d,qp是AR项q是MA项d是使时间序列平稳所需的差分数如果时间序列具有季节性模式,则需要添加季节性条件,该时间序列将变成SARIMA(“季节性ARIMA”的缩写)。
r语言arima函数用法一、概述Arima函数是R语言中用于时间序列分析的一个功能强大的函数。
它可以用来估计和预测时间序列数据,包括季节性和趋势性成分。
本文主要介绍Arima函数的用法,包括参数设置、模型识别、模型估计、模型检验和预测等方面。
二、参数设置Arima函数的参数包括x、order、seasonal和include.mean。
其中,x表示输入的时间序列数据,通常为一个向量或矩阵;order指定AR、差分和MA的阶数,格式为c(p, d, q),其中p代表AR阶数,d代表差分阶数,q代表MA阶数;seasonal指定季节性的阶数,格式为c(P, D, Q, m),其中P代表季节AR阶数,D 代表季节差分阶数,Q代表季节MA阶数,m代表季节周期;include.mean指定是否包括常数项,默认为TRUE。
三、模型识别在使用Arima函数之前,首先需要对时间序列数据进行模型识别。
模型识别主要包括确定AR和MA的阶数以及季节性的阶数。
常用的方法包括自相关函数ACF和偏自相关函数PACF的观察,以及模型选择准则AIC和BIC的比较。
•自相关函数ACF:用来检测时间序列数据的自相关性。
如果ACF在k阶后截尾,则说明可以考虑AR(k)模型。
•偏自相关函数PACF:用来检测时间序列数据的偏自相关性。
如果PACF在k 阶后截尾,则说明可以考虑MA(k)模型。
•模型选择准则AIC和BIC:用来比较不同模型的拟合程度。
AIC和BIC值越小,模型的拟合程度越好。
四、模型估计模型估计是指根据已有的时间序列数据,估计ARIMA模型的参数。
在估计过程中,需要设置初始值,然后通过迭代方法求解模型的参数估计值。
在R语言中,使用Arima函数可以很方便地进行模型估计。
五、模型检验模型检验是指对估计得到的模型参数进行检验,判断模型是否合理。
常用的检验方法包括残差自相关图、残差正态性检验、白噪声检验等。
•残差自相关图:用来检测模型残差序列的自相关性。
基于时间序列分析的ARIMA模型分析及预测ARIMA(Autoregressive Integrated Moving Average)模型是一种常用于时间序列分析和预测的经典模型。
它结合了自回归(AR)、差分(I)和移动平均(MA)这三种方法,可以较好地处理非平稳时间序列数据。
ARIMA模型的基本思想是根据时间序列数据的自相关(AR)和趋势性(MA)来预测未来的值。
它的建模过程包括确定模型的阶数、参数估计和模型诊断。
首先,ARIMA模型的阶数由p、d和q这三个参数决定。
其中,p代表自回归阶数,d代表差分阶数,q代表移动平均阶数。
p和q决定了时间序列的自相关和移动平均相关的程度,而d决定了时间序列是否平稳。
确定这些参数可以通过观察ACF(自相关函数)和PACF(偏自相关函数)图来进行。
接下来,参数估计是ARIMA模型中关键的一步。
常用的估计方法有最小二乘法(OLS)和最大似然估计法(MLE)。
最小二乘法适用于平稳时间序列,最大似然估计法适用于非平稳时间序列。
完成参数估计后,还需要进行模型诊断。
模型诊断主要是通过残差序列来判断模型是否拟合良好。
通常,残差序列应满足如下条件:残差序列应是白噪声序列,即残差之间应该没有相关性;残差序列的均值应接近于零,方差应保持不变。
最后,通过使用ARIMA模型预测未来的值。
根据模型对未来的预测,我们可以得到未来一段时间内的时间序列预测结果。
ARIMA模型的优点是可以对非平稳时间序列进行建模和预测。
它几乎可以应用于任何时间序列数据,如股票价格、气温、销售量等。
然而,ARIMA模型也有一些限制。
首先,ARIMA模型假设时间序列的结构是稳定的,但实际上很多时间序列数据都是非稳定的。
其次,ARIMA 模型对数据的准确性和完整性有较高的要求,如果数据中存在缺失值或异常值,建模的准确性会受到影响。
总结来说,ARIMA模型是一种经典的时间序列分析和预测方法。
它能够处理非平稳时间序列数据,并且可以通过确定阶数、参数估计和模型诊断来进行预测。
如何使用R语言进行时间序列分析与预测标题:使用R语言进行时间序列分析与预测导言:时间序列分析是一种用于研究随时间变化的数据模式和趋势的方法。
它在许多领域中都有广泛的应用,包括经济学、金融学、气象学等。
R语言是一种功能强大的统计分析软件,它提供了许多用于时间序列分析和预测的函数和包。
本文将介绍如何使用R语言进行时间序列分析和预测的步骤和方法。
一、准备数据1. 收集时间序列数据:首先需要收集相关的时间序列数据,例如每天的销售量、股票价格等。
这些数据可以通过调查、采样或从公开数据源中获取。
2. 数据清洗:对收集到的数据进行清洗,包括去除异常值、缺失值和重复值等。
确保数据的完整性和准确性。
3. 建立时间索引:将数据转换为时间序列对象,并建立时间索引。
R语言中常用的时间序列对象包括ts、xts和zoo等。
二、时间序列分析1. 可视化分析:使用R语言中的绘图函数,如plot()和ggplot2包,将时间序列数据可视化。
可以观察数据的趋势、季节性和周期性。
2. 平稳性检验:检验时间序列数据是否平稳,即均值、方差和自协方差不随时间变化。
常用的平稳性检验方法有ADF检验和KPSS检验。
3. 建立模型:根据时间序列数据的特点选择合适的模型。
常用的时间序列模型包括ARIMA模型、指数平滑模型和ARCH/GARCH模型等。
4. 模型识别:对建立的模型进行参数估计,并进行模型识别。
使用R语言中的函数,如auto.arima()和ets(),自动选择最佳的模型。
5. 模型诊断:对建立的模型进行诊断,检验模型的拟合优度。
常用的模型诊断方法有残差分析、Ljung-Box检验和AIC准则等。
三、时间序列预测1. 预测模型:基于建立的时间序列模型,使用R语言中的forecast包,预测未来一段时间内的数值。
可以使用函数,如forecast()和predict(),进行预测。
2. 模型评估:对时间序列预测结果进行评估。
使用预测准确度指标,如均方根误差(RMSE)和平均绝对百分误差(MAPE),评估预测模型的准确性。
arima模型的r方 r语言
ARIMA模型的R方在R语言中可以通过"forecast"包的"()"函数来计算。
这个函数会自动选择最佳的ARIMA模型,并返回模型的参数和拟合优度。
首先,你需要安装并加载"forecast"包。
你可以使用以下代码来安装和加载这个包:
```r
("forecast")
library(forecast)
```
然后,你可以使用"()"函数来拟合ARIMA模型,并返回模型的参数和拟合优度。
以下是一个示例代码:
```r
假设你的时间序列数据存储在变量"data"中
()函数会自动选择最佳的ARIMA模型
fit <- (data)
输出模型的参数和拟合优度
summary(fit)
```
在输出结果中,你可以找到模型的R方值。
R方是评价模型拟合优度的指标之一,其值应该在0到1之间,越接近1表示模型拟合效果越好。
如果R
方为负数,则说明模型的拟合效果很差或者是数据存在异常值或离群点。
需要注意的是,R方只是评价模型拟合优度的指标之一,还有其他指标可以用来评估模型的性能,如预测误差、MAE、MSE等。
因此,在评估模型时,需要综合考虑多个指标。
R 语言环境下使用ARIMA模型做时间序列预测
1.序列平稳性检验
通过趋势线、自相关(ACF)与偏自相关(PACF)图、假设检验和因素分解等方法确定序列平稳性,识别周期性,从而为选择适当的模型提供依据。
1.1绘制趋势线
图1 序列趋势线图
从图1很难判断出序列的平稳性。
1.2绘制自相关和偏自相关图
图2 序列的自相关和偏自相关图
从图2可以看出,ACF拖尾,PACF1步截尾(p=1),说明该现金流时间序列可能是平稳性时间序列。
1.3 ADF、PP和KPSS 检验平稳性
图3 ADF、PP和KPSS检验结果
通过ADF检验,说明该现金流时间序列是平稳性时间序列(p-value for ADF test <0.02,拒绝零假设).pp test和kpss test 结果中的警告信息说明这两种检验在这里不可用。
但是这些检验没有充分考虑趋势、周期和季节性等因素。
下面对该序列进行趋势、季节性和不确定性因素分解来进一步确认序列的平稳性。
1.4 趋势、季节性和不确定性因素分解
R 提供了两种方法来分解时间序列中的趋势、季节性和不确定性因素。
第一种是使用简单的对称过滤法,把相应时期内经趋势调整后的观察值进行平均,通过decompose()函数实现,如图4。
第二种方法更为精确,它通过平滑增大规模后的观察值来寻找趋势、季节和不确定因素,利用stl()函数实现。
如图5。
图4 decompose()函数分解法
图5 stl()函数分解法
两种方法得到的结果非常相似。
从上图可以看出,该现金流时间序列没有很明显的长期趋势。
但是有明显的季节性或周期性趋势,经分解后的不确定因素明显减少。
综上平稳性分析检验,我们选用包含季节性因素的S-ARIMA模型来预测现金流时间序列。
2.S-ARIMA模型
2.1 建立SARIMA模型
在R 软件包中包含auto.arima()、expand.grid() 等函数,针对p,d,q 众多的可能取值,可以通过expand.grid()建立所有的可能参数组合,用for()条件函数代入相应的arima()模型,把结果储存在BIC当中。
其中,BIC根据AIC
是拟合原序列的最佳模型。
指标来计算。
结果显示,SARIMA(0,1,1)(1,1,0)
12
拟合结果如下图6所示:
图6 SARIMA(0,1,1)(1,1,0)12模型拟合结果
结果表明,ma 和sar 的系数为负数并且影响非常显著。
2.2 模型有效性检验
R 提供了tsdiag()函数来检验模型的有效性。
检验结果如下图7:
图7 tsdiag()函数检验结果
图中第二行的ACF 检验说明残差没有明显的自相关性。
第三行的Ljung-Box 测试显示所有的P-value>0.1,说明残差为白噪声。
模型合格。
3.预测未来现金流
模通过以上模型的建立与检验,我们建立了SARIMA(0,1,1)(1,1,0)
12
型来预测未来现金流。
预测结果如图8所示:
图8 模型对未来若干年现金流的预测结果
下面进行预测值与真实值的对比,如图9所示:
图9 预测值与真实值对比图(图中,蓝色代表预测值;红色代表真实值)
从图9可以看出,模型对六个月内的预测值相对准确,但是从2009年4月份开始,预测值与真实值之间出现明显偏差,说明该模型适合短期内预测。
而从长期来看,由于影响现金流的不确定性因素增加,模型的预测能力下降。