神经网络报告仿真设计报告
- 格式:doc
- 大小:966.00 KB
- 文档页数:9

神经网络实验报告神经网络实验报告引言:神经网络是一种模仿人脑神经元网络结构和功能的计算模型,它通过学习和训练来实现模式识别、分类和预测等任务。
本次实验旨在探索神经网络的基本原理和应用,并通过实践验证其效果。
一、神经网络的基本原理1.1 神经元模型神经元是神经网络的基本单元,它接收来自其他神经元的输入信号,并通过激活函数进行处理后输出。
我们采用的是Sigmoid函数作为激活函数,它能够将输入信号映射到0到1之间的值。
1.2 神经网络结构神经网络由输入层、隐藏层和输出层组成。
输入层接收外部输入的数据,隐藏层用于处理和提取特征,输出层给出最终的预测结果。
隐藏层的数量和每层神经元的数量是根据具体问题而定的。
1.3 反向传播算法反向传播算法是神经网络中最常用的训练算法,它通过计算误差和调整权重来不断优化网络的预测能力。
具体而言,它首先进行前向传播计算得到预测结果,然后计算误差,并通过链式法则将误差反向传播到每个神经元,最后根据误差调整权重。
二、实验设计2.1 数据集选择本次实验选择了一个手写数字识别的数据集,其中包含了大量的手写数字图片和对应的标签。
这个数据集是一个经典的机器学习数据集,可以用来评估神经网络的分类能力。
2.2 神经网络参数设置为了探究神经网络的性能和泛化能力,我们设置了不同的参数组合进行实验。
主要包括隐藏层数量、每层神经元数量、学习率和训练轮数等。
2.3 实验步骤首先,我们将数据集进行预处理,包括数据归一化和标签编码等。
然后,将数据集划分为训练集和测试集,用于训练和评估网络的性能。
接下来,根据不同的参数组合构建神经网络,并使用反向传播算法进行训练。
最后,通过测试集评估网络的分类准确率和损失函数值。
三、实验结果与分析3.1 参数优化我们通过对不同参数组合的实验进行比较,找到了在手写数字识别任务上表现最好的参数组合。
具体而言,我们发现增加隐藏层数量和神经元数量可以提高网络的分类准确率,但同时也会增加训练时间。

一、实验背景随着人工智能技术的飞速发展,神经网络作为一种强大的机器学习模型,在各个领域得到了广泛应用。
为了更好地理解神经网络的原理和应用,我们进行了一系列的实训实验。
本报告将详细记录实验过程、结果和分析。
二、实验目的1. 理解神经网络的原理和结构。
2. 掌握神经网络的训练和测试方法。
3. 分析不同神经网络模型在特定任务上的性能差异。
三、实验内容1. 实验一:BP神经网络(1)实验目的:掌握BP神经网络的原理和实现方法,并在手写数字识别任务上应用。
(2)实验内容:- 使用Python编程实现BP神经网络。
- 使用MNIST数据集进行手写数字识别。
- 分析不同学习率、隐层神经元个数对网络性能的影响。
(3)实验结果:- 在MNIST数据集上,网络在训练集上的准确率达到98%以上。
- 通过调整学习率和隐层神经元个数,可以进一步提高网络性能。
2. 实验二:卷积神经网络(CNN)(1)实验目的:掌握CNN的原理和实现方法,并在图像分类任务上应用。
(2)实验内容:- 使用Python编程实现CNN。
- 使用CIFAR-10数据集进行图像分类。
- 分析不同卷积核大小、池化层大小对网络性能的影响。
(3)实验结果:- 在CIFAR-10数据集上,网络在训练集上的准确率达到80%以上。
- 通过调整卷积核大小和池化层大小,可以进一步提高网络性能。
3. 实验三:循环神经网络(RNN)(1)实验目的:掌握RNN的原理和实现方法,并在时间序列预测任务上应用。
(2)实验内容:- 使用Python编程实现RNN。
- 使用Stock数据集进行时间序列预测。
- 分析不同隐层神经元个数、学习率对网络性能的影响。
(3)实验结果:- 在Stock数据集上,网络在训练集上的预测准确率达到80%以上。
- 通过调整隐层神经元个数和学习率,可以进一步提高网络性能。
四、实验分析1. BP神经网络:BP神经网络是一种前向传播和反向传播相结合的神经网络,适用于回归和分类问题。

一、实验目的与要求1. 掌握神经网络的原理和基本结构;2. 学会使用Python实现神经网络模型;3. 利用神经网络对手写字符进行识别。
二、实验内容与方法1. 实验背景随着深度学习技术的不断发展,神经网络在各个领域得到了广泛应用。
在手写字符识别领域,神经网络具有较好的识别效果。
本实验旨在通过实现神经网络模型,对手写字符进行识别。
2. 神经网络原理神经网络是一种模拟人脑神经元结构的计算模型,由多个神经元组成。
每个神经元接收来自前一个神经元的输入,通过激活函数处理后,输出给下一个神经元。
神经网络通过学习大量样本,能够自动提取特征并进行分类。
3. 实验方法本实验采用Python编程语言,使用TensorFlow框架实现神经网络模型。
具体步骤如下:(1)数据预处理:从公开数据集中获取手写字符数据,对数据进行归一化处理,并将其分为训练集和测试集。
(2)构建神经网络模型:设计网络结构,包括输入层、隐藏层和输出层。
输入层用于接收输入数据,隐藏层用于提取特征,输出层用于输出分类结果。
(3)训练神经网络:使用训练集对神经网络进行训练,调整网络参数,使模型能够准确识别手写字符。
(4)测试神经网络:使用测试集对训练好的神经网络进行测试,评估模型的识别效果。
三、实验步骤与过程1. 数据预处理(1)从公开数据集中获取手写字符数据,如MNIST数据集;(2)对数据进行归一化处理,将像素值缩放到[0, 1]区间;(3)将数据分为训练集和测试集,比例约为8:2。
2. 构建神经网络模型(1)输入层:输入层节点数与数据维度相同,本实验中为28×28=784;(2)隐藏层:设计一个隐藏层,节点数为128;(3)输出层:输出层节点数为10,对应10个类别。
3. 训练神经网络(1)定义损失函数:均方误差(MSE);(2)选择优化算法:随机梯度下降(SGD);(3)设置学习率:0.001;(4)训练次数:10000;(5)在训练过程中,每100次迭代输出一次训练损失和准确率。

《认知科学与类脑计算》课程实验报告实验名称:基本操作与前馈神经网络姓名:学号:框架选择:MindSpore √PyTorch 日期:一、实验内容1.1前馈神经网络解决回归、二分类、多分类任务实验内容:首先根据要求生成回归、二分类数据集以及下载MNIST手写数据集。
然后搭建前馈神经网络模型对上述数据进行训练并测试,解决问题。
最后打印实验预测结果,绘制loss曲线。
前馈神经网络用到了一些算法和概念:①神经元(Neurons):前馈神经网络由神经元构成,每个神经元是一个计算单元,接受输入并产生输出。
每个神经元都有一个相关的权重(weight)和一个偏置(bias)。
②权重和偏置(Weights and Biases):每个神经元都与前一层的所有神经元相连,每个连接都有一个相关的权重,用于调整输入信号的重要性。
此外,每个神经元都有一个偏置,用于调整神经元的激活阈值。
③激活函数(Activation Function):激活函数定义了神经元的输出如何计算。
它通常是非线性的,允许神经网络学习非线性关系。
④前馈传播(Feedforward Propagation):前馈神经网络的计算是通过前馈传播进行的。
数据从输入层经过隐藏层逐层传播,最终到达输出层。
每个神经元将其输入与相关权重相乘,加上偏置,并通过激活函数进行转换,然后传递给下一层。
⑤损失函数(Loss Function):损失函数用于度量模型的输出与真实标签之间的差异。
训练过程的目标是最小化损失函数。
⑥反向传播(Backpropagation):反向传播是通过梯度下降优化权重和偏置的过程。
首先,通过前馈传播计算损失,然后通过反向传播计算损失相对于每个权重和偏置的梯度。
梯度信息用于更新权重和偏置,以减小损失。
1.2在多分类实验的基础上使用至少三种不同的激活函数这里的多分类实验具体指MNIST手写数据集的识别。
在实验中我考虑使用了ReLu、tanh和sigmoid三个函数进行对比实验。
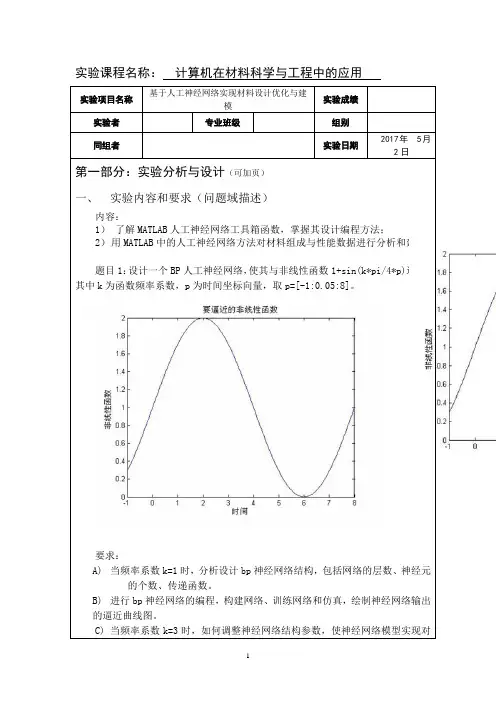
实验课程名称:计算机在材料科学与工程中的应用2)用MATLAB中的人工神经网络方法对材料组成与性能数据进行分析和建模。
题目1:设计一个BP人工神经网络,使其与非线性函数1+sin(k*pi/4*p)逼近,其中k为函数频率系数,p为时间坐标向量,取p=[-1:0.05:8]。
要求:A)当频率系数k=1时,分析设计bp神经网络结构,包括网络的层数、的个数、传递函数。
B)进行bp神经网络的编程,构建网络、训练网络和仿真,绘制神经网络输出的逼近曲线图。
计算机实现过程:① 初始化:对所有连接权和阈值赋以随机任意小值;)0;,...,1;,...,1;,...,2()()(1====-t p j p i m k t t w k k k i k ij ,,θ② 从N 组输入输出样本中取一组样本:x (1)=[x1,…, xp1]T, d (1) =[d1,…,dpm ]T, 把输入信息 x (1) =[x1,…, xp1]T 输入BP 网络中 ③ 正向传播:计算各层节点的输出),...,1,...,2(k ki p i m k y ==;分析:产生副作用,训练后网络输出结果拟合精度不够。
分析:训练曲线达不到,由于初始值不定,误差进入梯度误差局部最小曲面。
分析:训练曲线达到要求分析:训练曲线未达到目标,需要调整神经网络结构参数分析:达到目标,且连续运行多次,均达到要求,此神经元数目达到要求分析:当神经元数目过大,达到过拟合,对训练以外的数据精确度不够,泛化能力减弱当频率一定且其他参数条件不变时,隐含层神经元数增大时,得到的曲线与原始的非线性函数曲线更加接近,说明BP网络对非线性函数的逼近效果比较好。
将数据转置,随机选择5组数据为预测样本数据,其他图:。

1 BP 神经网络简介图1 BP 神经网络结构图BP(Back Propagation)神经网络是目前人工神经网络中研究最深入、应用最为广泛的一种模型,其结构如图l 所示。
图中,x 、z 是网络的输入、输出向量,每一神经元用一个节点表示,网络由输入层、隐层和输出层节点组成,隐层可以是一层,也可以是多层(图中是单隐层),前层至后层节点之间通过权系数相联结。
BP 神经网络学习时,输入信号从输入层经隐层传向输出层(正向传播),若输出层得到期望的输出,则学习算法结束:否则,转至反向传播。
反向传播就是将误差信号(样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层神经元的权值,使误差信号减小。
以下是各层权值的具体过程(即BP 学习算法):定义网络的输出误差 22111()()22l k k k E d O d o ==-=-∑,将其依次展开至隐层和输入层,在使误差不断减小的原则下,应使权值的调整量与误差的负梯度成正比,即:jk jkEw w ∂∆∝-∂ ,0,1,2,;j m =1,2,k l =ij ijEv v ∂∆∝-∂ ,1,2,;i n =1,2,j m =经推导可得到各层权值调整的计算公式,写成向量的形式为:()o T T W Y ηδ∆= , ()y T T V X ηδ∆=式中,12(,,,)T n X x x x =为输入向量,12(,,,)T m Y y y y =为隐层输出向量,12(,,,)T l O o o o =为输出向量,12(,,,)T l d d d d =为期望输出,而[]jk m l W w ⨯=和[]ij n m V v ⨯=分别是隐层到输出层和输入层到隐层的权值矩阵。
BP 网络的学习训练过程如下:(1) 初始化网络,对网络参数及各权系数进行赋值,其中权系数应取随机数; (2) 输入训练样本,计算各层的预报值,并与真实值相比较,得出网络的输出误差;(3) 依据误差反向传播规则,调整隐层之间以及隐层与输入层之间的权系zx数;(4) 重复步骤(2)和(3),直至预测误差满足条件或训练次数达到规定次数。

人工智能实验报告在当今科技飞速发展的时代,人工智能(AI)已经成为了最具创新性和影响力的领域之一。
为了更深入地了解人工智能的工作原理和应用潜力,我进行了一系列的实验。
本次实验的目的是探索人工智能在不同任务中的表现和能力,以及分析其优势和局限性。
实验主要集中在图像识别、自然语言处理和智能决策三个方面。
在图像识别实验中,我使用了一个预训练的卷积神经网络模型。
首先,准备了大量的图像数据集,包括各种物体、场景和人物。
然后,将这些图像输入到模型中,观察模型对图像中内容的识别和分类能力。
结果发现,模型在常见物体的识别上表现出色,例如能够准确地识别出猫、狗、汽车等。
然而,对于一些复杂的、少见的或者具有模糊特征的图像,模型的识别准确率有所下降。
这表明模型虽然具有强大的学习能力,但仍然存在一定的局限性,可能需要更多的训练数据和更复杂的模型结构来提高其泛化能力。
自然语言处理实验则侧重于文本分类和情感分析。
我采用了一种基于循环神经网络(RNN)的模型。
通过收集大量的文本数据,包括新闻、评论、小说等,对模型进行训练。
在测试阶段,输入一些新的文本,让模型判断其所属的类别(如科技、娱乐、体育等)和情感倾向(积极、消极、中性)。
实验结果显示,模型在一些常见的、结构清晰的文本上能够做出较为准确的判断,但对于一些语义模糊、多义性较强的文本,模型的判断容易出现偏差。
这提示我们自然语言的复杂性和多义性给人工智能的理解带来了巨大的挑战,需要更深入的语言模型和语义理解技术来解决。
智能决策实验主要是模拟了一个简单的博弈场景。
通过设计一个基于强化学习的智能体,让其在与环境的交互中学习最优的决策策略。
经过多次训练和迭代,智能体逐渐学会了在不同情况下做出相对合理的决策。
但在面对一些极端情况或者未曾遇到过的场景时,智能体的决策效果并不理想。
这说明智能决策系统在应对不确定性和新颖情况时,还需要进一步的改进和优化。
通过这些实验,我对人工智能有了更深刻的认识。

一、实验背景随着人工智能技术的快速发展,神经网络作为一种重要的机器学习算法,已经在图像识别、自然语言处理、推荐系统等领域取得了显著的成果。
为了更好地理解和掌握神经网络的基本原理和应用,我们进行了为期一周的神经网络实训实验。
二、实验目的1. 理解神经网络的基本原理和结构;2. 掌握神经网络训练和推理的基本方法;3. 通过实际操作,加深对神经网络的理解和应用。
三、实验内容1. 神经网络基本原理在实验过程中,我们首先学习了神经网络的基本原理,包括神经元结构、激活函数、损失函数等。
通过学习,我们了解到神经网络是一种模拟人脑神经元结构的计算模型,通过学习大量样本数据,实现对未知数据的分类、回归等任务。
2. 神经网络结构设计我们学习了神经网络的结构设计,包括输入层、隐含层和输出层。
输入层负责接收原始数据,隐含层负责对数据进行特征提取和抽象,输出层负责输出最终结果。
在实验中,我们尝试设计了不同层级的神经网络结构,并对比分析了其性能。
3. 神经网络训练方法神经网络训练方法主要包括反向传播算法和梯度下降算法。
在实验中,我们使用了反向传播算法对神经网络进行训练,并对比了不同学习率、批量大小等参数对训练效果的影响。
4. 神经网络推理方法神经网络推理方法主要包括前向传播和后向传播。
在前向传播过程中,将输入数据通过神经网络进行处理,得到输出结果;在后向传播过程中,根据输出结果和实际标签,计算损失函数,并更新网络参数。
在实验中,我们实现了神经网络推理过程,并对比分析了不同激活函数对推理结果的影响。
5. 实验案例分析为了加深对神经网络的理解,我们选择了MNIST手写数字识别数据集进行实验。
通过设计不同的神经网络结构,使用反向传播算法进行训练,最终实现了对手写数字的识别。
四、实验结果与分析1. 不同神经网络结构对性能的影响在实验中,我们尝试了不同层级的神经网络结构,包括单层神经网络、多层神经网络等。
结果表明,多层神经网络在性能上优于单层神经网络,尤其是在复杂任务中,多层神经网络具有更好的表现。

一、实验背景随着深度学习技术的快速发展,卷积神经网络(Convolutional Neural Network,CNN)在图像识别、图像处理等领域取得了显著的成果。
本实验旨在通过设计和实现一个简单的卷积神经网络模型,对图像进行分类识别,并分析其性能。
二、实验目的1. 理解卷积神经网络的基本原理和结构。
2. 掌握卷积神经网络在图像分类任务中的应用。
3. 分析卷积神经网络的性能,并优化模型参数。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 深度学习框架:TensorFlow4. 数据集:CIFAR-10四、实验步骤1. 数据预处理- 加载CIFAR-10数据集,并将其分为训练集、验证集和测试集。
- 对图像进行归一化处理,将像素值缩放到[0, 1]区间。
2. 构建卷积神经网络模型- 使用TensorFlow框架构建一个简单的卷积神经网络模型,包括卷积层、池化层、全连接层和Softmax层。
- 设置模型的超参数,如学习率、批大小等。
3. 训练模型- 使用训练集对模型进行训练,并使用验证集监控模型的性能。
- 调整超参数,如学习率、批大小等,以优化模型性能。
- 使用测试集评估模型的性能,计算准确率、召回率等指标。
5. 可视化模型结构- 使用TensorBoard可视化模型结构,分析模型的学习过程。
五、实验结果与分析1. 模型结构- 本实验构建的卷积神经网络模型包括3个卷积层、3个池化层、2个全连接层和1个Softmax层。
- 卷积层使用ReLU激活函数,池化层使用最大池化操作。
- 全连接层使用Softmax激活函数,输出模型的预测结果。
2. 训练过程- 在训练过程中,模型的准确率逐渐提高,最终在测试集上达到了较好的性能。
- 模型的训练过程如下:```Epoch 1/1060000/60000 [==============================] - 44s 739us/step - loss: 2.2851 - accuracy: 0.4213Epoch 2/1060000/60000 [==============================] - 43s 721us/step - loss: 2.0843 - accuracy: 0.5317...Epoch 10/1060000/60000 [==============================] - 43s 719us/step - loss: 1.4213 - accuracy: 0.8167```- 在测试集上,模型的准确率为81.67%,召回率为80.83%。

BP⼈⼯神经⽹络试验报告⼀学号:北京⼯商⼤学⼈⼯神经⽹络实验报告实验⼀基于BP算法的XX及Matlab实现院(系)专业学⽣姓名成绩指导教师2011年10⽉⼀、实验⽬的:1、熟悉MATLAB 中神经⽹络⼯具箱的使⽤⽅法;2、了解BP 神经⽹络各种优化算法的原理;3、掌握BP 神经⽹络各种优化算法的特点;4、掌握使⽤BP 神经⽹络各种优化算法解决实际问题的⽅法。
⼆、实验内容:1 案例背景1.1 BP 神经⽹络概述BP 神经⽹络是⼀种多层前馈神经⽹络,该⽹络的主要特点是信号前向传递,误差反向传播。
在前向传递中,输⼊信号从输⼊层经隐含层逐层处理,直⾄输出层。
每⼀层的神经元状态只影响下⼀层神经元状态。
如果输出层得不到期望输出,则转⼊反向传播,根据预测误差调整⽹络权值和阈值,从⽽使BP 神经⽹络预测输出不断逼近期望输出。
BP 神经⽹络的拓扑结构如图1.1所⽰。
图1.1 BP 神经⽹络拓扑结构图图1.1中1x ,2x , ……n x 是BP 神经⽹络的输⼊值1y ,2y , ……n y 是BP 神经的预测值,ij ω和jk ω为BP 神经⽹络权值。
从图1.1可以看出,BP 神经⽹络可以看成⼀个⾮线性函数,⽹络输⼊值和预测值分别为该函数的⾃变量和因变量。
当输⼊节点数为n ,输出节点数为m 时,BP 神经⽹络就表达了从n 个⾃变量到m 个因变量的函数映射关系。
BP 神经⽹络预测前⾸先要训练⽹络,通过训练使⽹络具有联想记忆和预测能⼒。
BP 神经⽹络的训练过程包括以下⼏个步骤。
步骤1:⽹络初始化。
根据系统输⼊输出序列()y x ,确定⽹络输⼊层节点数n 、隐含层节点数l ,输出层节点数m ,初始化输⼊层、隐含层和输出层神经元之间的连接权值ij ω和式中, l 为隐含层节点数; f 为隐含层激励函数,该函数有多种表达形式,本章所选函数为:步骤3:输出层输出计算。
根据隐含层输出H ,连接权值jk ω和阈值b ,计算BP 神经⽹络预测输出O 。

一、实验目的本次实验旨在了解神经网络的基本原理,掌握神经网络的构建、训练和测试方法,并通过实验验证神经网络在实际问题中的应用效果。
二、实验内容1. 神经网络基本原理(1)神经元模型:神经元是神经网络的基本单元,它通过接收输入信号、计算加权求和、应用激活函数等方式输出信号。
(2)前向传播:在神经网络中,输入信号通过神经元逐层传递,每层神经元将前一层输出的信号作为输入,并计算输出。
(3)反向传播:在训练过程中,神经网络通过反向传播算法不断调整各层神经元的权重和偏置,以最小化预测值与真实值之间的误差。
2. 神经网络构建(1)确定网络结构:根据实际问题选择合适的网络结构,包括输入层、隐含层和输出层的神经元个数。
(2)初始化参数:随机初始化各层神经元的权重和偏置。
3. 神经网络训练(1)选择损失函数:常用的损失函数有均方误差(MSE)和交叉熵(CE)等。
(2)选择优化算法:常用的优化算法有梯度下降、Adam、SGD等。
(3)训练过程:将训练数据分为训练集和验证集,通过反向传播算法不断调整网络参数,使预测值与真实值之间的误差最小化。
4. 神经网络测试(1)选择测试集:从未参与训练的数据中选取一部分作为测试集。
(2)测试过程:将测试数据输入网络,计算预测值与真实值之间的误差,评估网络性能。
三、实验步骤1. 数据准备:收集实验所需数据,并进行预处理。
2. 神经网络构建:根据实际问题确定网络结构,初始化参数。
3. 神经网络训练:选择损失函数和优化算法,对网络进行训练。
4. 神经网络测试:将测试数据输入网络,计算预测值与真实值之间的误差,评估网络性能。
四、实验结果与分析1. 实验结果(1)损失函数曲线:观察损失函数随训练轮数的变化趋势,分析网络训练效果。
(2)测试集误差:计算测试集的预测误差,评估网络性能。
2. 结果分析(1)损失函数曲线:从损失函数曲线可以看出,随着训练轮数的增加,损失函数逐渐减小,说明网络训练效果较好。
《神经网络》课程学习总结报告李浩程柏林一、工作说明:程柏林和李浩讲授的内容是“双向异联想网络(BAM)”。
其中,1.程柏林完成的工作有:双向异联想网络(BAM)基本概念、网络结构及工作原理、学习规则等基本理论的介绍,以及用BAM网络实现对字符的识别程序仿真和介绍。
程序附后。
2.李浩完成的工作有双向异联想网络(BAM)应用举例、双向异联想网络(BAM)仿真及其说明、问题的讨论及解答。
程序附后。
二、未解决的问题:用外积和法设计的权矩阵,不能保证p对模式全部正确的联想。
若对记忆模式对加以限制(即要求p个记忆模式X k是两两正交的),则用外积和法设计的BAM网具有较好的联想能力。
在难以保证要识别的样本(或记忆模式)是正交的情况下,如何求权矩阵,并保证具有较好的联想能力?这个问题在用BAM网络实现对字符的识别程序仿真中得到体现。
我们做过尝试,用伪逆法求权矩阵,虽然能对未加干扰的字符全部进行识别,但对加有噪声的字符识别效果很差。
至于采用改变结构和其他算法的方法来求权矩阵,将是下一步要做的工作。
三、建议1.关于本课程的学习:我们认为教员的这种教学方式比较好,避免了为考试而学的观念,更多地考虑到学生学习的自主性,调动了学生的学习兴趣和积极性,并且培养了学生之间的协作精神。
另外对于第二阶段的学习,我们的感觉是:除了自己要讲授的内容外,其他学生所讲的内容自己学习得不好,不知其他学生的感觉如何?所以如何让一个人不仅对自己所讲的内容搞熟以外,对其他人讲的内容也要达到这个效果,这将是教员和学员实施这种教学方法下一步要考虑的问题之一。
建议:运用神经网络解决与所学专业如信号处理,模式识别等问题非常多,但从某些参考文献上看,涉及理论的较多,而从应用(具体地说用程序仿真实现的过程)上介绍较少,这就留给教员和学员(尤其是学员)一个探讨的领域,能否先由教员选择一些具体问题供学员参考,结合个人兴趣,分组实施。
2.对自己或他人的建议为了要讲好自己要讲的内容,所花费在这方面的时间就多些,并且对自己要讲的内容研究得透彻一些,如果把同样的时间和钻研的精神用在所有内容的学习上,我们想任何一门课程都应该学得更好一些。
神经网络控制大作业-南航-智能控制-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII南京航空航天大学研究生实验报告实验名称:神经网络控制器设计姓名:学号:专业:201 年月日一、题目要求考虑如下某水下航行器的水下直航运动非线性模型:()||a m m v k v v u y v++==其中v R ∈为水下航行器的前进速度, u R ∈为水下航行器的推进器推力,y R ∈为水下航行器的输出,航行器本体质量、附加质量以及非线性运动阻尼系数分别为100,15,10a m m k ===。
作业具体要求:1、设计神经网络控制器,对期望角度进行跟踪。
2、分析神经网络层数和神经元个数对控制性能的影响。
3、分析系统在神经网络控制和PID 控制作用下的抗干扰能力(加噪声干扰、加参数不确定)、抗非线性能力(加死区和饱和特性)、抗时滞的能力(对时滞大小加以改变)。
二、神经网络控制器的设计1.构建系统的PID 控制模型在Simulink 环境下搭建水下航行器的PID 仿真模型,如下图1所示:图1 水下航行器的PID 控制系统其中,PID控制器的参数设置为:K p=800,K i=100,K d=10。
需要注意的一点是,经过signal to workspace模块提取出的数据的Save format为Array格式。
2.BP神经网络控制器的训练首先将提取出的训练数据变为标准的训练数据形式,标准的训练数据分为输入和目标输出两部分。
经过signal to workspace模块提取出的数据为一个训练数据个数乘以输入(或输出)个数的矩阵,因此分别将x、u转置后就得到标准训练数据x’,u’。
然后,新建m文件,编写神经网络控制器设计程序:%----------------------------------------------------------------p=x'; %inputt=u'; %inputnet=newff(p,t,3,{'tansig','purelin'},'trainlm');net.trainparam.epochs=2500;net.trainparam.goal=0.00001;net=train(net,x',u'); %train networkgensim(net,-1); %generate simulink block%----------------------------------------------------------------上述m文件建立了如下图所示的神经网络,包含输入层、1个隐含层和输出层,各层神经元节点分别为 1、 3 和1。
智能控制仿真实验实验一模糊控制系统的仿真实验实验二 BP神经网络的仿真实验实验三遗传算法仿真实验实验四智能控制实际工程处理(选做)实验一模糊控制系统的仿真实验实验目的:现有被控对象一:G(s)=1/(s2+2s+1)被控对象二:G(s)=K /【(T1s+1)(T2s+1) 】试设计一个模糊控制系统来实现对它的控制,并完成以下任务实验任务一:请根据以上的数据重新仿真一下,看Ke的变化对系统性能的影响是否如此?然后仍以G(s)=1/(s2+2s+1) 为被控对象,按照同样的方法仿真并分析Kc、Ku的变化对系统性能的影响。
1.相同参数不同控制器解模方法下的图形BISECTORMOMSOMLOM2.不同参数相同解模方法下的图形(解模方法均为BISECTOR)(1)Ke的影响(Kc=5,Ku=8)Ke=1(2)Kc的影响(Ke=9,Ku=8)Kc=1(3)Ku的影响(Ke=9,Kc=5)Ku=1小结:由以上图形分析可得,不同的解模方法输出的结果不同,经比较BISECTOR 的解模方法更加合适。
参数Kc、Ku不变时,随着Ke的减小,上升时间将增大;Ke、Ku不变时,随着Kc的减小超调变大;Ke、Kc不变时随着Ku的减小,输出越来越低于1。
可知Ke=9、Kc=5、Ku=8更为合适。
实验任务二:仍使用以上设计的模糊控制器,被控对象为: G(s)=K /【(T 1s+1)(T 2s+1)】 ,被控对象的参数有以下四组: 第一组参数: G(s)=20/【(1.2s+1)(4s+1)】 第二组参数: (s)=20/【(0.4s+1)(4s+1)】 第三组参数: G(s)=20/【(2s+1)(4s+1)】 第四组参数: G(s)=20/【(2s+1)(8s+1)】请根据由任务一得到的Ke 、Kc 、Ku 的变化对系统性能影响的规律,选择第一组参数作为被控对象参数,调试出适合该系统的最佳的Ke 、Kc 、Ku 和反模糊化方法;并在你调出的最佳的Ke 、Kc 、Ku 状态下,将对象参数分别变成第二、三、四组的参数,仿真出结果,并分析fuzzy controller 的适应能力。
研究生(人工智能)报告题目:人工智能实验报告学号姓名专业电磁场与微波技术指导教师院(系、所)华中科技大学研究生院制1问题二利用一阶谓词逻辑求解猴子摘香蕉问题:房内有一个猴子,一个箱子,天花板上挂了一串香蕉,其位置如图所示,猴子为了拿到香蕉,它必须把箱子搬到香蕉下面,然后再爬到箱子上。
请定义必要的谓词,列出问题的初始化状态(即下图所示状态),目标状态(猴子拿到了香蕉,站在箱子上,箱子位于位置b)。
图1 猴子香蕉问题解:⏹定义描述环境状态的谓词。
AT(x,w):x在t处,个体域:xϵ{monkey},wϵ{a,b,c,box};HOLD(x,t):x手中拿着t,个体域:tϵ{box,banana};EMPTY(x):x手中是空的;ON(t,y):t在y处,个体域:yϵ{b,c,ceiling};CLEAR(y):y上是空的;BOX(u):u是箱子,个体域:uϵ{box};BANANA(v):v是香蕉,个体域:vϵ{banana};⏹使用谓词、连结词、量词来表示环境状态。
问题的初始状态可表示为:S o:A T(monkey,a)˄EMPTY(monkey)˄ON(box,c)˄ON(banana,ceiling)˄CLEAR(b)˄BOX(box)˄BANANA(banana)要达到的目标状态为:S g:AT(monkey,box)˄HOLD(monkey,banana)˄ON(box,b)˄CLEAR(ceiling)˄CLEAR(c)˄BOX(box)˄BANANA(banana)⏹从初始状态到目标状态的转化, 猴子需要完成一系列操作, 定义操作类谓词表示其动作。
WALK(m,n):猴子从m走到n处,个体域:m,nϵ{a,b,c};CARRY(s,r):猴子在r处拿到s,个体域:rϵ{c,ceiling},sϵ{box,banana};CLIMB(u,b):猴子在b处爬上u;这3个操作也可分别用条件和动作来表示。
神经网络实验报告一、实验目的和任务1、掌握产生实验数据的方法;2、掌握“时钟”的使用方法,记录程序运行时间;3、掌握评估神经网络学习效果的指标方法;4、模拟神经元模型,理解其工作原理;5、模拟感知机网络,用hebbu规则和BP算法训练神经网络,用实验数据测试两种算法学习效果的差异;6、构建两层自组织映射(SOM)神经网络、两层ART神经网络或两层hopfield神经网络,并进行测试分析,比较不同网络的差异。
二、实验工具和方法借助软件MATLAB(R2009a)及其神经网络工具箱Neural Network Toolbox V ersion 6.0.2进行实验的仿真和测试。
三、实验过程1、实验数据的产生:假设噪声数据服从均值为0,方差为1的正态分布。
首先在变量论域产生100个随机数,并利用函数表达式分别计算其相应函数值,最后分别叠加噪声数据,得到与变量对应的100个实验数据。
(1)函数数据的产生:使用MA TLAB生成均匀随机数的函数rand(m,n),可生成在m行n列的在(0,1)之间符合均匀分布的随机数。
x0=rand(1,100);x=100*x0;如此可生成在变量论域(0,100)之间的100个符合均匀分布的随机数。
假如用来生成实验数据的函数为2sin=+,输入:y x xy1=x.^2+sin(x)即可得到所需的函数数据。
(2)噪声数据的产生由于噪声数据服从均值为0,方差为1的正态分布,使用MATLAB函数randn(m,n),可生成在m行n列的在(0,1)之间符合要求的随机数。
y2=randn(1,100)(3)生成实验数据将实验数据和噪声数据叠加:y=y1+y22、“时钟”的使用方法在编写MATLAB代码的时候,经常需要获知代码执行的实际时间,这就这程序中用到即使函数。
MATLAB里提供了cputime,tic/toc,etime三种方法。
(1)cputime方法返回MATLAB启动以来的CPU时间,可以在程序代码执行前保存当时的CPU时间,然后在程序代码执行结束后用cputime减去之前保存的数值,就可以获取程序实际运行的时间。
人工神经网络仿真设计作业
班级
学号
姓名
自动化学院
一、目标
对非线性函数进行拟合。
(在MATLAB R2014a版本下调试通过)
二、采用网络
采用RBF网络。
三、RBF网络学习过程
RBF网络结构:
在RBF网络之前训练,需要给出输入向量X和目标向量y,训练的目的是要求得第一层和第二层之间的权值W1、阀值B1,和第二层与第三层之间的权值W2、阀值B2。
整个网络的训练分为两步,第一步是无监督的学习,求W1、B1。
第二步是有监督的学习求W2、B2。
网络会从0个神经元开始训练,通过检查输出误差使网络自动增加神经元。
每次循环使用,重复过程直到误差达到要求。
因此RBF网络具有结构自适应确定,输出与初始权值无关的特征。
流程图
四、结果分析
被拟合函数为:
F = 10+x1.^2-8*sin(2*pi*x1)+x2.^2-4*cos(2*pi*x2);
其中x为:
x1、x2为[-1.5:0.1:1.5]区间上的随机400位数字RBF神经网络的调用语句为:
net = newrb(P,T,GOAL,SPREAD,MN,DF) P为输入向量,T为目标向量,GOAL为圴方误差,默认为0,SPREAD为径向基函数的分布密度,默认为1,MN为神经元的最大数目,DF为两次显示之间所
添加的神经元神经元数目。
下面分别对SPREAD,MN,DF取不同值测试。
SPREAD=0.5、MN=200
图1 NEWRB, neurons = 200, MSE = 1.65238e-07
图2 SPREAD=0.5、MN=200时仿真结果
●SPREAD=0.5、MN=400
图3 NEWRB, neurons = 400, MSE = 9.47768e-13
图4 SPREAD=0.5、MN=400时仿真结果
●SPREAD=1、MN=200
图5 NEWRB, neurons = 200, MSE = 1.17356e-07
图6 SPREAD=1、MN=200时仿真结果
SPREAD=1、MN=400
图7 NEWRB, neurons = 400, MSE = 1.60702e-08
图8 SPREAD=1、MN=400时仿真结果
●SPREAD=2、MN=400
图9 NEWRB, neurons = 400, MSE = 0.332281
图10 SPREAD=2、MN=400时仿真结果
●对泛化能力的测试
训练时,x的取值范围为[-1.5:0.1:1.5]
测试时,x取[-2:0.1:2]
图11 泛化能力测试
可以看出,网络的泛化能力稍差,尤其对于取值边界部分,误差较大。
五、参数分析
●SPREAD参数
在测试中,对RBF网络的SPREAD参数和MN参数分别取不同的数值组合,得到了上述结果。
SPREAD参数叫做扩展速度,其默认值为1。
SPREAD越大,函数拟合越平滑,但是逼近误差会变大,需要的隐藏神经元也越多,计算也越大。
SPREAD越小,函数的逼近会越精确,但是逼近过程会不平滑,网络的性能差,会出现过适应现象。
所以具体操作的时候要对不同的SPREAD值进行尝试,SPREAD即要大到使得神经元产生响应的输入范围能够覆盖足够大的区域,同时也不能太大,而使各个神经元都具有重叠的输入向量响应区域。
在本次测试中,可以看出SPREAD=0.5时,误差达到最小, MSE = 9.47768e-13 SPREAD=1时,MSE = 1.60702e-08,虽然误差稍大,但逼近过程会更加平滑。
SPREAD=2时,MSE = 0.332281,误差急剧变大,从图像中也可看出,图像拟合效果较差。
●MN参数
MN参数为隐层神经元个数,MN越大对数据的拟合越精确,在本例中,对数据拟合最好的情况MN=400,即输入数据X的数量。
权值w与阈值b
在网络运行后,在命令行窗口输入
net.IW{1}
ans =
0.0422 0.0020
-1.4445 1.3746
0.1840 -1.4981
1.2000 1.1240
…
权值为400*2的矩阵,不一一列出具体数字;
net.b{1}
ans =
0.8326
0.8326
0.8326
…
阈值为400*1的矩阵,不一一列出具体数字。
六、小结
RBF网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度。
在本次实验中,利用MATLAB构建RBF网络函数对一个非线性函数进行拟合,通过测试不同参数,选择最佳的一组参数得到所需要的网络。
同时分析了不同参数对网络性能的影响,并通过图像更直观地表现参数对模型的影响情况。