spss如何做交叉表分析
- 格式:doc
- 大小:17.00 KB
- 文档页数:2
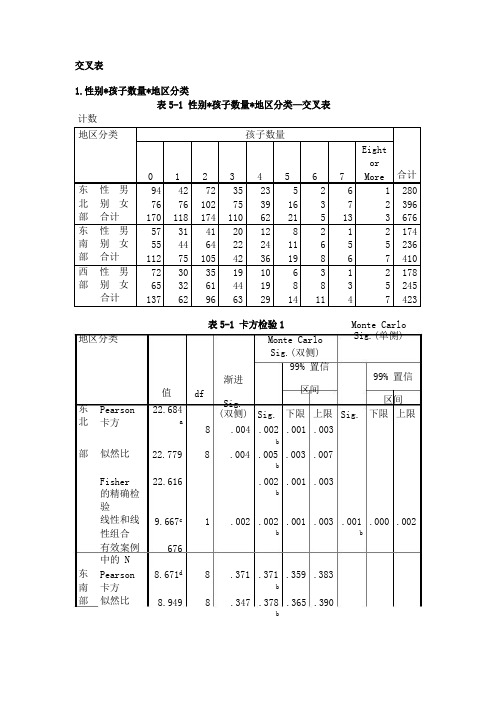
计数 交叉表1.性别*孩子数量*地区分类表 5-1 性别*孩子数量*地区分类—交叉表地区分类表 5-1 卡方检验 1Monte Carlo Sig.(双侧)Monte Carlo Sig.(单侧)东 北Pearson 卡方值 df 22.684a99% 置信99% 置信渐进区间区间 Sig.(双侧) Sig. 下限 上限 Sig. 下限 上限8 .004 .002 .001 .003b部 似然比 22.779 8 .004 .005 .003 .007bFisher 的精确检 验线性和线 22.616 .002 .001 .003b9.667c 1 .002 .002 .001 .003 .001 .000 .002性组合 bb东 南 有效案例 中的 N Pearson 卡方 6768.671d 8 .371 .371 .359 .383 b部 似然比8.9498 .347 .378 .365 .390b地区分类孩子数量合计1234567 EightorMore 东 性 男 北 别 女 部 合计 94 76 170 42 76 118 72 102 174 35 75 110 23 39 62 5 16 21 2 3 5 6 7 13 1 2 3 280 396 676 东 性 男 南 别 女 部 合计 57 55 112 31 44 75 41 64 105 20 22 42 12 24 36 8 11 19 2 6 8 1 5 6 2 5 7 174 236 410 西 性 男 部 别 女合计72 65 137 30 32 62 35 61 96 19 44 63 10 19 296 8 143 8 111 3 42 5 7 178 245 423结果分析:从上述数据可看到,在东北部,东南部,西部三个地区中,Pearson卡方检验中,渐进Sig.(双侧)值分别是0.04<0.05,0.371>0.05,0.054>0.05,所以三个地区不同性别拥有的孩子数量没有显著差异;在三个地区被调查的人当中,没有孩子和两个孩子的人最多,其次是一个或者三个孩子的,四个孩子的也占了一部分,而五个孩子及以上的人相当少。

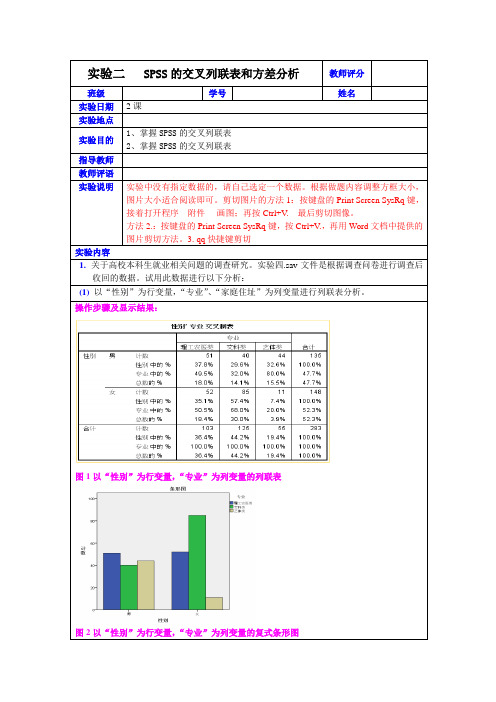
图1以“性别”为行变量,“专业”为列变量的列联表
图2以“性别”为行变量,“专业”为列变量的复式条形图
图4以“性别”为行变量,“家庭住址”为列变量的列联
图1以“性别”为行变量,“家庭住址”为列变量的复式条形图图1以“性别”为行变量,“家庭住址”为列变量的卡方分布
图1以“是否签约”为行变量,“就业形势看法”为列变量的交叉列联表图2以“是否签约”为行变量,“就业形势看法”为列变量的卡方检验
图3 以“是否签约”为行变量,“就业形势看法”为列变量的复式条形图图4 以“是否签约”为行变量,“预期薪酬”为列变量的交叉列联表
图6 以“是否签约”为行变量,“预期薪酬”为列变量的复式条形图
图7 以“是否签约”为行变量,“理想就业单位”为列变量的交叉列联表
图10 以“是否签约”为行变量,“培养模式契合”为列变量的列联表
图12 以“是否签约”为行变量,“培养模式契合”为列变量的复式条形图
图14 以“是否签约”为行变量,“在校努力与最终就业”为列变量的卡方检验图15 以“是否签约”为行变量,“在校努力与最终就业”为列变量的复式条形图图16 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的列联表
图18 以“是否签约”为行变量,“所学专业与就业应该怎样”为列变量的复式条形图
(3)使用方差分析的方法探索不同性别在性别、形象、英语水平、计算机水平、毕业高校、专业背景、资格证书、社会实践经历、在校成绩这些因素对就业的影响方面的看法是否显著不同。
操作步骤及显示结果:。


17. 交叉表与多选题(一)基本理论分类变量包括无序分类变量、有序分类变量、多选题变量集。
对于分类变量的描述统计,主要是对分类变量各水平值分别进行频数和比例计算,再进步计算所需的一些相对频数指标。
一、单分类变量的统计描述1. 频数分布分类变量的分析,首先要了解:各类别的样本数(频数),以及占总样本量的百分比;对有序分类变量,还需要了解:累积频数、累积百分比。
2. 集中/离散趋势观察原始频数,或者使用众数。
对于分类变量,集中/离散趋势是一体的。
3. 相对频数指标(1)比(Riatio)两个有关指标之比A/B, 用来反映相对的大小关系,例如,月销售额/销售人数;(2)构成比用于描述事物内部各构成部分所占的比重,例如,百分比、累积百分比;(3)率(Rate)率是具有时间概念或速度、强度意义的指标,表示某个时期内某事件发生的频率或强度,例如速率、频率、费率、发病率等。
二、多分类变量的联合描述列联表。
例如,r×c二维列联表:(1)共n个样本;(2)按两种属性A、B,属性A有r个水平值:A1, …, A r; 属性B有c个水平值:B1, …, B c. 属性A=A i,属性B=B j的样本数为n ij.(3)n i. = “属性A=A i”的合计数,n.j = “属性B=B j”的合计数。
注:多分类变量对应高维列联表。
三、多选题的统计描述多选题是调查问卷的常见题型,因为多选题是回答同一个大问题,所以不能割裂开来单独分析,需要做汇总处理。
1. 应答人数(Count)选择各题项的人数,原始频数;2. 应答人数百分比选择该项的人数占总人数的百分比,可以反映该选项在人群中的受欢迎程度;3. 应答人次(Response)选择各选项的总人次,1个受访者选择2个选项,即2人次;4. 应答次数百分比在做出的所有选择中,选择该项的人次占总人次数的比例。
(二)SPSS实现有某调查问卷的数据文件(部分):变量属性:一、单分类变量的描述——频率变量“s4”表示学历:问题1:描述受访者的学历分布情况【分析】——【描述统计】——【频率】,将“学历”选入【变量】框,点【确定】得到S4. 学历频率百分比有效百分比累积百分比有效初中/技校或以下 154 13.4 13.4 13.4 高中/中专 313 27.3 27.3 40.7 大专331 28.9 28.9 69.6 本科 292 25.5 25.5 95.0 硕士或以上 57 5.0 5.0 100.0合计1147100.0100.0注:详细操作见第15篇《频率图表》。

spss卡方检验SPSS卡方检验SPSS(统计软件包 for the Social Sciences)是一种功能强大的统计软件,在社会科学、商业智能和市场调研等领域得到广泛应用。
其中,卡方检验是SPSS中常用的统计方法之一。
本文将介绍SPSS 中使用卡方检验进行数据分析的基本步骤、原理和注意事项。
一、卡方检验的基本概念卡方检验,又称为卡方拟合优度检验,用于比较观察样本与理论预期分布之间的差异。
它基于卡方统计量,可以用于分析分类数据的关联性和独立性。
卡方检验的结果可以帮助研究人员判断观察数据与理论模型之间的差异程度以及独立性。
二、SPSS中进行卡方检验的步骤1. 收集数据并导入到SPSS中。
2. 在SPSS中选择“分析”菜单,点击“描述统计”下的“交叉表”。
3. 在交叉表对话框中,选择需要比较的两个变量。
4. 点击“统计”按钮,选择“卡方”选项。
5. 点击“继续”按钮,然后点击“OK”按钮生成交叉表结果。
三、SPSS卡方检验的原理SPSS中的卡方检验基于卡方统计量,该统计量用于衡量观察值与理论期望值之间的差异。
卡方统计量的计算公式如下:\\[ X^2 = \\sum \\frac{(O-E)^2}{E} \\]其中,O表示观察值,E表示理论期望值。
卡方统计量服从自由度为(k-1) × (m-1)的卡方分布,其中k表示列数,m表示行数。
通过计算卡方统计量,可以得到卡方值和P值。
如果P值小于设定的显著性水平(通常为0.05),则认为观察值与理论期望值存在显著差异,拒绝原假设。
四、卡方检验的应用场景卡方检验通常用于以下几种情况:1. 检验分类变量之间的关联性。
例如,研究某一地区的居民性别与吸烟习惯之间的关系。
2. 检验分类变量与某一特定属性的关联性。
例如,研究某个产品的用户满意度与不同年龄段之间的关系。
3. 检验分类变量的分布是否服从某一特定的理论分布。
例如,研究某一地区的选民支持率是否符合某个政党的预期。
17. 交叉表与多选题(一)基本理论分类变量包括无序分类变量、有序分类变量、多选题变量集。
对于分类变量的描述统计,主要是对分类变量各水平值分别进行频数和比例计算,再进步计算所需的一些相对频数指标。
一、单分类变量的统计描述1. 频数分布分类变量的分析,首先要了解:各类别的样本数(频数),以及占总样本量的百分比;对有序分类变量,还需要了解:累积频数、累积百分比。
2. 集中/离散趋势观察原始频数,或者使用众数。
对于分类变量,集中/离散趋势是一体的。
3. 相对频数指标(1)比(Riatio)两个有关指标之比A/B, 用来反映相对的大小关系,例如,月销售额/销售人数;(2)构成比用于描述事物内部各构成部分所占的比重,例如,百分比、累积百分比;(3)率(Rate)率是具有时间概念或速度、强度意义的指标,表示某个时期内某事件发生的频率或强度,例如速率、频率、费率、发病率等。
二、多分类变量的联合描述列联表。
例如,r×c二维列联表:(1)共n个样本;(2)按两种属性A、B,属性A有r个水平值:A1, …, A r; 属性B有c个水平值:B1, …, B c. 属性A=A i,属性B=B j的样本数为n ij.(3)n i. = “属性A=A i”的合计数,n.j = “属性B=B j”的合计数。
注:多分类变量对应高维列联表。
三、多选题的统计描述多选题是调查问卷的常见题型,因为多选题是回答同一个大问题,所以不能割裂开来单独分析,需要做汇总处理。
1. 应答人数(Count)选择各题项的人数,原始频数;2. 应答人数百分比选择该项的人数占总人数的百分比,可以反映该选项在人群中的受欢迎程度;3. 应答人次(Response)选择各选项的总人次,1个受访者选择2个选项,即2人次;4. 应答次数百分比在做出的所有选择中,选择该项的人次占总人次数的比例。
(二)SPSS实现有某调查问卷的数据文件(部分):变量属性:一、单分类变量的描述——频率变量“s4”表示学历:问题1:描述受访者的学历分布情况【分析】——【描述统计】——【频率】,将“学历”选入【变量】框,点【确定】得到S4. 学历频率百分比有效百分比累积百分比有效初中/技校或以下 154 13.4 13.4 13.4 高中/中专 313 27.3 27.3 40.7 大专33128.928.969.6本科 292 25.5 25.5 95.0 硕士或以上 57 5.0 5.0 100.0合计1147100.0100.0注:详细操作见第15篇《频率图表》。
SPSS-多重响应-频率和交叉表案例分析(问卷调查分析)2011-09-29 16:35马上要国庆了,公司待遇不错,一口气放10天假,真是太高兴了,已经买了飞机票,飞机票贵的一滚,来回居然要2000多,伤不起啊!!在10.1休假前,希望跟大家讨论一下SPSS-多重响应--频率和交叉表分析,希望大家能够多提点提点在云南电信网上营业厅做了一个关于“客户不使用电信3g业务的原因有哪些的问卷调查,问题所示:这份问卷调查总更有35人参与,样本容量偏少,其中1:选择 A :3G资费过高的有 14人2:选择 B: 网络覆盖率低,信号不稳定的 15人3:选择 C:买手机太麻烦的 15人4:选择 D: 换手机号麻烦 15人5:选择 E: 3G功能用处不大 9人6:选择F: 朋友使用后,觉得不好 10人第一步:我们将 A , B, C , D , E ,F,六个答案选项分别做为一个单独的变量,分别赋值为“0”和“1”,0代表没有被选中,“1”代表被选中,这个就是所谓的“二分法”在SPSS中进行数据编码后,如下所示:点击“分析-多重响应---定义变量集---进入如下所示页面:根据如上图所示,填写变量集名称,标签,以及在”二分法” 计算值选项中填入“1”再点击”添加“ 添加成后,点击”关闭“按钮再点击”分析-多重响应--频率分析----分析结果如下所示:上图结果很直观,结果,我就不分析了百分比=N/总计 =14/78=17.9%个案百分比=N/参与人数(有效人数)=14/33=42.4% 下面来进行“交叉表”分析,如下所示:从上图可知:多重响应交叉表中有“行,列,层”三个选框1:我们将“变量集" 移入”行“列表框内,将”客户类型“移入”列框内,层选框可以不选,有需要时再选,层选项框是用来分层进行统计分析的(我进行了分层,如上图所示)比如:我想计算每一个答案有多少被选中,有多少没有选中,可以采用分层,分为“选中”和“未选中”两个层次“客户类型”是指来进行“问卷调查”人的分类,分为“3g老客户”“3g一般客户” "很少用3g客户“”不用3g客户“等类型,点击“选项”进入如下所示页面:点击确定,可以得到如下结果:因为我们上图选中的“列”所以,计算的是列单元格百分比,也进行了分层处理,分为“没有选中”和“选中”两个层次。
SPSS问卷分析篇之非参数检验——交叉表分析SPSS问卷分析篇之非参数检验——交叉表分析标签:SPSS 调查问卷销售渠道-------------------------------------------------------->【概念】均值检验、方差检验都是针对综述变量并涉及总体的的统计参数,但在数据分析的过程中,有很多类别数据或顺序数据,对这些数据的分析主要是应用频数及分布特征来分析,这类分析统称为非参数统计分析。
非参数检验是对非参数统计分析的显著性进行检验,与参数检验相比,对数据分布、数据测量尺度没有特别要求,计算较为简单,特别适用于类别测量或顺序变量的统计分析。
对于一个调查样本,通常会利用分组变量,将调查样本划分为若干个相互独立的子样本,通过统计各子样本的调查结果,发现各子样本的差别或联系,应用多个独立样本的非参数检验,判断这些差别或联系的显著性,进而判断分组变量是否有统计意义。
如在市场调查中,用个人资料对调查样本进行分组,并分析这些分组在不同问题上是否存在差异,此时就需要使用非参数检验的方法(多样本非参数检验)。
在调查问卷分析中,经常要用到多个分组变量进行交叉统计分析,并对分析结果的显著性进行检验,此时可用SPSS菜单crosstable功能的卡方检验。
【案例】假设我们已经取得某调查问卷数据,其中包含字段:购买休闲服地点(步行街、街道服装店、百货店、综合购物广场、综合超市、服装批发市场、其他);性别(男、女);现在我们想知道性别在购物地点的选择上有没有差异。
1、SPSS——analysis——描述统计——crosstable2、统计量中选择“卡方”检验3、结果此图的上半部分:频数分析表,指出男性和女性分别在不同的购物地点的频数,大概可以看出男性和女性各自不同的消费习惯;下半部分:卡方检验,pearson chi假设行和列变量相互独立,即假设男性和女性在选择购物地点时没有差别,现在现住小于0.05,原假设不正确,所以,男性和女性在选择购物地点时有显著差异,这可以指导我们在开拓新的铺面时,准确把握顾客和选择合适的地点。
交叉表分析主要用来检验两个变量之间是否存在关系,或者说是否独立,其零假设为两个变量之间没有关系。
我们在实际的工作中,经常用交叉表来分析比例是否相等。
比如我们来分析一下,不同的性别对不同的报纸的选择有什么不同,就是要用交叉表分析了,下面是具体的方法。
方法/步骤
在spss中打开数据,然后依次打开:analyze--descriptive--crosstabs,打开交叉表对话框
将性别放到行列表,将对读物的选择变量放到列,这样就构成了一个交叉表
接下来我们要设置输出的结果,点击statistics,打开一个新的对话框
勾选chi-square(卡方检验),勾选phi and cramer's V(衡量交互分析中两个变量关系强度的指标),点击continue,回到交叉表对话框
点击cells,设置cell中要展示的数据
在这里勾选observed(各单元格的观测次数),勾选row(行单元格的百分比),点击continue,回到交叉表对话框
点击ok按钮,输出检验结果
先看到的第一个表格就是交叉表,性别为行、选择的读物为列
卡方检验结果:我们主要是看pearson卡方检验,sig值小于0.05,因此我们认为不同的性别的人对周末读物的选择有显著的差别
最后一个表格,输出的是phi值和V值,两个都是代表两个变量之间的关系的紧密度的,数值小于0.1说明关系不紧密,即性别与周末读物的选择没有明显的关系,这个结论和上面的卡方检验有出入,所以我们需要进一步进行两两比较。
Cross table analysis is mainly used to test the existence of a relationship between two variables, or is independent, the null hypothesis for it doesn't matter between the two variables. We are in actual work,/post/496.html often with cross table to analyze whether equal proportion. For example, we analyze, choose different gender on different newspapers have what different, is to use cross table analysis, the following are the specific method.
Methods / procedures
Open the data in SPSS, then in turn: analyze--descriptive--crosstabs, cross table dialog box opens The sex on the list, select variables on the readings on the column, so as to form a cross table
Next we are going to set the output results, click statistics, open a new dialog
Check the chi-square (chi square test),/post/484.html check the phi and cramer's V (a measure of interaction analysis of two variables relationship strength index), click continue, back cross table dialog box
If you click cells, you want to display the data set cell
If you check the observed here (we each cell observation times), check the row (percentage cell), click continue,/post/331.html back cross table dialog box
If you click the OK button, we output test results
The first table we first see is cross table, sex, selection of books for the column
New results of chi square test: we mainly see Pearson chi square test, SIG value of less than 0.05, so we think different gender have significant differences on the weekend just reading
We present the last table,/post/118.html the output is the phi value and V value, two are representative of the relationship between the two variables tightness,/post/635.html a value of less than 0.1 show the relationship is not close, namely, gender and weekend reading choice is not obvious, and chi square this conclusion and the above test, so we need a further two two.。