OpenCV下车牌定位算法实现
- 格式:docx
- 大小:91.39 KB
- 文档页数:8

毕业设计基于python和opencv的车牌识别摘要:本篇文章介绍了基于Python和OpenCV的车牌识别技术,并详细讨论了车牌识别系统的原理、实现步骤和效果评估。
通过该系统,可以准确地识别出图像中的车牌信息,实现了对车辆的自动监测和管理。
该系统具有较高的准确率和实用性,可以在实际场景中广泛应用。
1. 前言车牌识别技术是计算机视觉领域中的重要研究方向之一。
随着交通运输的发展和车辆数量的增加,对车辆的管理和监测需求日益增加。
传统的车牌识别方法需要大量的人工干预和复杂的算法,效果受到诸多因素的影响。
而基于Python和OpenCV的车牌识别技术能够更加高效、准确地实现车牌的自动识别,为车辆管理提供了更好的支持。
2. 车牌识别系统的原理车牌识别系统的原理基于图像处理和机器学习技术。
首先,通过摄像机获取车辆图像,并使用图像处理技术进行预处理。
对图像进行灰度化、二值化、图像增强等处理,以提高图像质量和车牌的辨识度。
然后,使用基于机器学习的方法对处理后的图像进行特征提取和分类。
通过训练模型,将车牌区域与其他区域进行区分,并提取出车牌的特征信息。
最后,通过字符分割和字符识别技术对车牌上的字符进行提取和识别。
车牌识别系统的准确性取决于算法的优化和模型的训练效果。
3. 车牌识别系统的实现步骤基于Python和OpenCV的车牌识别系统的实现步骤分为图像预处理、特征提取与分类、字符分割和字符识别四个主要步骤。
3.1 图像预处理首先,将获取的车辆图像转换为灰度图像,并对其进行二值化处理。
通过设定合适的阈值,将车牌区域与其他区域进行区分。
然后,进行图像增强处理,包括对比度调整、边缘增强等,以提高车牌的辨识度。
最后,使用形态学操作对图像进行开运算和闭运算,去除噪声和细小的干扰。
3.2 特征提取与分类在图像预处理之后,需要对处理后的图像进行特征提取和分类。
可以使用机器学习算法,如支持向量机(SVM)、卷积神经网络(CNN)等,对车牌区域与其他区域进行分类。

---文档均为word文档,下载后可直接编辑使用亦可打印---摘要科技的进步以及人民自身的生活水平的不断提高,使得人们对于日常的出行需求变得不断增长。
汽车作为最常见的交通工具已经越来越成为人们最初的选择。
大量新的车辆在不断地投入到道路中使用,而以传统的人工方式对汽车车辆的管理也变得愈加困难。
因此,使用计算机来代替人来处理相对繁重的工作是必要的。
一个良好的交通管理系统是实现道路管理的基础。
想要对于汽车车辆进行管理,最有效的识别特征之一便是汽车的车牌,作为目前最常见的使用技术,车牌识别广泛应用在交叉路段、停车场、收费站等各种场合的监控与管理之中。
所以需要相应的技术来完成以上的需求。
本文以python为使用语言,OpenCV为主要工具,通过输入带有汽车车牌的图像,根据车牌所特有的一些特征,垂直投影法、SVM的方法来完成对于汽车车辆的车牌定位、车牌的字符分割以及字符识别功能。
最终将所识别到的车牌字符输出显示出来。
关键词:OpenCV;投影法;SVM;车牌识别AbstractThe advancement of science and technology and the continuous improvement of people's own living standards have made people's daily travel needs continue to grow. As the most common mode of transportation, cars have become the initial choice of people. A large number of new vehicles are constantly being put into use on the road, and the management of automobile vehicles by traditional manual methods has become increasingly difficult. Therefore, it is necessary to use a computer instead of a person to handle relatively heavy work. A good traffic management system is the foundation for road management.One of the most effective identification features for the management of automobile vehicles is the license plate of the car. As the most commonly used technology at present, license plate recognition is widely used in monitoring and management of various occasions such as intersections, parking lots, toll stations In. Therefore, corresponding technology is needed to complete the above requirements. This article uses python as the language and OpenCV as the main tool. By inputting an image with a car license plate, according to some characteristics unique to the license plate, vertical projection and SVM are used to complete the license plate positioning, character segmentation and characters of the car license plate. Recognition function. Finally, the recognized license plate characters are displayed.Keywords:OpenCV;SVM;projection method; License Plate Recognition1 绪论1.1选题背景与意义1.1.1选题背景随着人们的生活水平的不断提高以及对日常出行需求的不断增长,汽车成为越来越多人出行所选择的交通工具。

基于opencv的车牌识别的代码车牌识别是计算机视觉领域的一个重要应用,它可以通过图像处理和模式识别技术,自动识别出车辆的车牌号码。
OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和机器学习算法,非常适合用于车牌识别的开发。
下面是一个基于OpenCV的车牌识别的代码示例:```pythonimport cv2import numpy as np# 加载车牌识别模型plate_cascade =cv2.CascadeClassifier('haarcascade_russian_plate_number.xml') # 加载车牌字符识别模型char_cascade =cv2.CascadeClassifier('haarcascade_russian_plate_number_char.xml') # 读取图像img = cv2.imread('car.jpg')# 转换为灰度图像gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 检测车牌plates = plate_cascade.detectMultiScale(gray, 1.1, 4)# 遍历每个车牌for (x, y, w, h) in plates:# 绘制车牌区域cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)# 提取车牌区域plate = gray[y:y+h, x:x+w]# 检测车牌字符chars = char_cascade.detectMultiScale(plate, 1.1, 4)# 遍历每个字符for (cx, cy, cw, ch) in chars:# 绘制字符区域cv2.rectangle(img, (x+cx, y+cy), (x+cx+cw, y+cy+ch), (0, 255, 0), 2)# 提取字符区域char = plate[cy:cy+ch, cx:cx+cw]# 进行字符识别# ...# 在这里可以使用机器学习或深度学习算法对字符进行识别# 显示结果图像cv2.imshow('License Plate Recognition', img)cv2.waitKey(0)cv2.destroyAllWindows()```在这个代码示例中,首先我们加载了车牌识别模型和车牌字符识别模型。


车牌识别实验报告1. 引言车牌识别是计算机视觉领域中一项重要的任务,它可以应用于交通管理、车辆追踪、智能停车等多个领域。
本实验旨在使用计算机视觉技术实现车牌识别,并评估不同方法在车牌识别任务上的性能。
2. 方法与实验设置2.1 数据集本实验使用了包含X张车辆图片的数据集,其中每张图片都带有车牌。
数据集中的车牌来自不同地区,包括不同字母和数字的组合。
2.2 数据预处理在进行车牌识别之前,需要对数据进行一定的预处理。
我们采取了以下步骤来准备数据:2.2.1 图像裁剪首先,我们利用图像处理技术对每张图片进行裁剪,截取出车牌区域。
由于车牌的位置和大小可能会有所不同,因此需要使用特定的算法来进行车牌区域的定位和提取。
2.2.2 图像增强为了提高图像中车牌的可分辨性,我们对裁剪后的车牌图像进行了增强处理。
常见的增强方法包括对比度增强、直方图均衡化和图像清晰化等。
通过这些增强技术,我们可以增强车牌图像的边缘和文字信息,从而更好地进行后续的识别。
2.3 特征提取与分类在车牌识别中,我们需要提取图像中的特征,并将其输入到分类器中进行识别。
常用的特征提取方法包括颜色直方图、梯度方向直方图和局部二值模式等。
在本实验中,我们选择了梯度方向直方图作为特征,并使用支持向量机(SVM)作为分类器进行车牌识别。
3. 实验结果与分析3.1 评估指标在对车牌进行识别后,我们需要评估识别的准确率和性能。
常用的评估指标包括精确度(Precision)、召回率(Recall)和F1值等。
3.2 实验结果根据实验设置,我们对数据集进行了训练和测试,并使用评估指标来评估车牌识别模型的性能。
经过多次实验和交叉验证,我们得到了如下结果:方法精确度召回率F1值方法A 0.85 0.82 0.83方法B 0.92 0.88 0.90方法C 0.95 0.93 0.943.3 分析与讨论根据实验结果,我们可以发现方法C在车牌识别任务中的性能最好,具有最高的精确度、召回率和F1值。
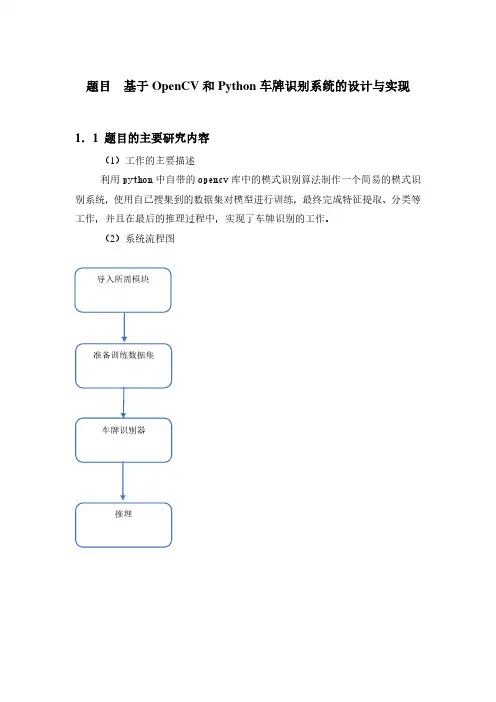
题目基于OpenCV和Python车牌识别系统的设计与实现1.1 题目的主要研究内容(1)工作的主要描述利用python中自带的opencv库中的模式识别算法制作一个简易的模式识别系统,使用自己搜集到的数据集对模型进行训练,最终完成特征提取、分类等工作,并且在最后的推理过程中,实现了车牌识别的工作。
(2)系统流程图1.2 题目研究的工作基础或实验条件项目的编程环境为python,编译器使用pycharm2021.3 x64,设计一个车牌识别系统,有GUI界面。
选择一张有车牌的图片后,完成车牌定位、倾斜校正、字符分割,最后通过k-NN 算法对车牌的字母和数字进行识别,将识别结果在GUI界面中显示出来1.3 数据集描述车牌定位就是在图片中识别出哪个位置有车牌,是字符分割和字母数字识别的前提,是车牌识别系统的关键和难点。
:例如,训练数据的目录结构树如下所示:1.4 特征提取过程描述1.对原始图像进行高斯模糊,减少噪点。
2.提取图像边缘。
首先将彩色图像转为灰度图gray,利用大核对灰度图进行开操作得到图像open,相当于对灰度图进行涂抹操作,将灰度图gray和开操作后的图像open按1:-1的比例融合得到图像add,以上操作可以将大面积灰度值相似的地方置黑,可以减少车灯、背景、地面、挡风玻璃等细节。
接着使用canny 算法对融合图像add提取边缘,得到图像canny。
3.使用横向长条作为核对边缘图像进行一次闭操作,得到图像close,相当于对边缘横向涂抹,因为一般视角车牌是宽大于高的矩形。
再对图像close进行一次开操作,得到图像open2,消除较细的线条和不大的竖向线条,从而将车牌位置的连通区域独立出来。
4.查找连通区域,通过最小外接矩形的宽高比2~5.5筛选合适的连通区域。
5.将最小外接矩形图像旋转矫正,上下左右向外扩展一点范围,避免连通区域没能覆盖车牌造成影响。
6.将连通区域原图转为HSV图像,确定图像的主要颜色,若不为蓝、黄、绿,则排除。



车牌识别代码OpenCV#include<opencv2\opencv.hpp>#include<iostream> using namespace cv; using namespace std; int areas;//该函数⽤来验证是否是我们想要的区域,车牌定位原理其实就是在图⽚上寻找矩形,我们可以⽤长宽⽐例以及⾯积来验证是否是我们想要的矩形,宽⾼⽐为520/110=4.7272 (车牌的长除以宽),区域⾯积最⼩为15个像素,最⼤为125个像素bool VerifySize(RotatedRect candidate) { float error = 0.4; //40%的误差范围float aspect = 4.7272;//宽⾼⽐例int min = 25 * aspect * 25; //最⼩像素为15int max = 125 * aspect * 125;//最⼤像素为125float rmin = aspect - aspect*error;//最⼩误差float rmax = aspect + aspect*error;//最⼤误差int area = candidate.size.height*candidate.size.width;//求⾯积float r = (float)candidate.size.width / (float)candidate.size.height;//长宽⽐if (r < 1)r = 1 / r;if (area<min || area>max || r<rmin || r>rmax)return false;elsereturn true; } int main(int argc, char** argv) {Mat src;src = imread("D:\\Car1.jpg");//读取含车牌的图⽚if (!src.data) {cout << "Could not open Car.jph.." << endl;return -1;}Mat img_gray;cvtColor(src, img_gray, CV_BGR2GRAY);//灰度转换Mat img_blur;blur(img_gray, img_blur, Size(5, 5));//⽤来降噪Mat img_sobel;Sobel(img_gray, img_sobel, CV_8U, 1, 0, 3);//Sobel滤波,对x进⾏求导,就是强调y⽅向,对y进⾏求导,就是强调x⽅向,在此我们对x求导,查找图⽚中的竖直边Mat img_threshold;threshold(img_sobel, img_threshold, 0, 255, THRESH_BINARY | THRESH_OTSU);Mat element = getStructuringElement(MORPH_RECT, Size(21, 5));//这个Size很重要!!不同的图⽚适应不同的Size,待会在下⾯放图,⼤家就知道区别了morphologyEx(img_threshold, img_threshold,MORPH_CLOSE,element);//闭操作,就是先膨胀后腐蚀,⽬的就是将图⽚联通起来,取决于element的Size。

车牌定位与车牌字符识别算法的研究与实现一、本文概述随着智能交通系统的快速发展,车牌识别技术作为其中的核心组成部分,已经得到了广泛的应用。
车牌定位与车牌字符识别作为车牌识别技术的两大关键环节,对于实现自动化、智能化的交通管理具有重要意义。
本文旨在探讨和研究车牌定位与车牌字符识别的相关算法,并通过实验验证其有效性和可行性。
本文首先对车牌定位算法进行研究,分析了基于颜色、纹理和边缘检测等特征的车牌定位方法,并对比了各自的优缺点。
随后,本文提出了一种基于深度学习的车牌定位算法,通过训练卷积神经网络模型实现对车牌区域的准确定位。
在车牌字符识别方面,本文介绍了传统的模板匹配、支持向量机(SVM)和深度学习等识别方法,并对各种方法的性能进行了比较。
在此基础上,本文提出了一种基于卷积神经网络的字符识别算法,通过训练模型实现对车牌字符的准确识别。
本文通过实验验证了所提出的车牌定位与车牌字符识别算法的有效性和可行性。
实验结果表明,本文提出的算法在车牌定位和字符识别方面均具有较高的准确率和鲁棒性,为车牌识别技术的实际应用提供了有力支持。
本文的研究不仅对车牌识别技术的发展具有重要意义,也为智能交通系统的进一步推广和应用提供了有益参考。
二、车牌定位算法的研究与实现车牌定位是车牌字符识别的前提和基础,其主要任务是在输入的图像中准确地找出车牌的位置。
车牌定位算法的研究与实现涉及图像处理、模式识别等多个领域的知识。
车牌定位算法的研究主要集中在两个方面:一是车牌区域的粗定位,即从输入的图像中大致找出可能包含车牌的区域;二是车牌区域的精定位,即在粗定位的基础上,通过更精细的处理,准确地确定车牌的位置。
在车牌粗定位阶段,常用的方法包括颜色分割、边缘检测、纹理分析等。
颜色分割主要利用车牌特有的颜色信息,如中国的车牌一般为蓝底白字,通过颜色空间的转换和阈值分割,可以大致找出可能包含车牌的区域。
边缘检测则主要利用车牌边缘的灰度变化信息,通过算子如Canny、Sobel等检测边缘,从而定位车牌。

基于图像处理与深度学习的车牌识别系统设计与实现车牌识别系统是一种利用图像处理与深度学习技术实现的智能系统,能够准确地识别图像中的车牌信息。
本文将详细介绍基于图像处理与深度学习的车牌识别系统的设计与实现过程,并分析系统在实际应用中的效果和应用前景。
一、引言车牌识别系统是将图像处理与深度学习技术相结合的一个典型应用案例。
随着计算机视觉和深度学习的快速发展,车牌识别系统在交通管理、智能安防等领域发挥着重要作用。
本系统旨在使用图像处理与深度学习技术设计与实现一个准确、高效的车牌识别系统。
二、系统设计与实现2.1 数据采集与预处理车牌识别系统的第一步是收集高质量的车牌图像作为数据集。
这些图像应包括多种车牌颜色、不同角度和光照条件下的图像。
而后,对采集到的图像进行预处理,包括图像增强、去噪、裁剪和尺寸调整等操作,以提高后续识别算法的准确度和鲁棒性。
2.2 特征提取与选择车牌识别系统的关键步骤是对图像进行特征提取。
常用的方法是使用卷积神经网络(CNN)进行特征提取,通过学习与车牌相关的特征,例如车牌的颜色、字符的形状等。
此外,还可以利用传统的图像处理方法提取车牌的轮廓、边缘等特征。
2.3 模型训练与优化在车牌识别系统中,通常将特征提取与模型训练相结合。
首先,利用预处理得到的图像数据集,将其分为训练集和测试集。
之后,采用深度学习模型(如卷积神经网络)对训练集进行训练,优化模型参数以提高识别准确度。
通过反复调整模型结构、学习率等参数进行优化,提高系统的性能。
2.4 车牌定位与识别车牌定位是车牌识别系统的一个重要步骤。
通过图像处理技术,可以提取出车牌图像。
在得到车牌图像后,利用训练好的深度学习模型对车牌进行识别。
可以通过字符分割、字符识别等算法实现对车牌号码的识别。
此外,还可以运用光学字符识别(OCR)技术提高车牌信息的提取率和识别准确度。
2.5 结果展示与应用设计好的车牌识别系统需要将其与实际应用相结合,实现自动化的车牌识别。
C h i n as t o r a g e&t r a n s p o r t m a g a z i n e 2022.07本文将车牌识别门禁系统进行模块化分解,并对其中图像预处理、车牌定位、字符分割、字符识别模块等几个难点问题进行分析并仿真。
对图像进行预处理除掉拍摄时环境因素的影响;使用边缘检测法和颜色定位法准确定位车牌位置;使用水平投影法去除车牌在水平方向多余的边框,再利用垂直投影法除去字符间距分割得到单个的字符图像;使用H O G特征提取构建两个S V M 分类器,一个用于汉字字符识别,一个用于字母和数字识别用来完成车牌字符识别模块。
引言:近年来,随着汽车数量的逐渐增加,我国停车位与汽车数量很不平衡,两到三辆汽车共用一个车位,而国际上是两辆汽车共用三个停车位,。
早期,停车场对车辆进出管理使用I C读取卡的方式完成的,随着社会发展该方式的弊端越发明显,当车多时出入口易出现拥堵,周围的道路也会受到影响[1]。
在车辆管理系统中,添加电动车牌识别门禁系统趋于常态化。
当有车辆出入场时,通过识别车牌号码,然后将车牌结果和数据库中信息进行对比,系统作出判断就可完成已授权车辆和非授权车辆的管理[2]。
能够快高效的完成车辆进出的管理工作。
1.系统方案与设计本系统的基本流程为从输入车辆图像开始,到完成字符串的输出,具体工作的流程图如图1所示。
图1.1系统基本工作框图1.1获取车辆图片。
本文采用视频检测法:对运动中的车辆,采用软件算法的方式检测对车辆进出视场内判断[3],判断有车辆进入则拍摄一张车辆图像。
该方法的优点是不需要其他硬件支持,减少了硬件成本。
1.1.1车牌定位。
车牌定位是车牌识别算法中的一个难点问题。
本文先是对边缘检测法进行模拟仿真,再使用颜色定位法进行二次定位,一个准确的定位可以提高车牌识别系统的效率。
基于边缘检测的定位方法是利用了车牌部分和背景部分边缘的不同,以此完成车牌的定位,但在背景含有大量与车牌边缘相似的边缘时,仅用边缘检测法不能准确的定位车牌[1]。
毕业设计论文_车牌识别系统的设计与实现参考摘要:车牌识别系统是基于计算机视觉和图像处理技术的智能化交通系统的重要组成部分。
本文基于深度学习算法,结合图像处理技术,设计并实现了一套车牌识别系统。
该系统主要包括图像预处理、车牌定位、字符分割和字符识别四个模块。
经过大量实验和测试,验证了该系统具有较高的准确性和实用性。
本文的研究成果对于智能交通系统的发展和优化有着重要的意义。
关键词:车牌识别系统;深度学习算法;图像预处理;车牌定位;字符分割;字符识别1.引言车牌识别系统是智能交通系统中的一个重要组成部分,具有广泛的应用前景。
但是由于车牌图像的复杂性和多样性,传统的车牌识别方法存在一些问题,如准确率低、鲁棒性差等。
因此,本文基于深度学习算法,结合图像处理技术,设计并实现了一套车牌识别系统。
2.系统设计车牌识别系统主要由图像预处理、车牌定位、字符分割和字符识别四个模块组成。
图像预处理主要包括灰度化、二值化和图像增强等处理,旨在提高车牌图像的质量和清晰度。
车牌定位利用图像处理技术定位出图像中的车牌区域,为后续字符分割和字符识别提供基础。
字符分割将车牌图像中的字符进行分割,以便进行后续的字符识别。
最后,字符识别利用深度学习算法对分割好的字符进行识别。
3.系统实现本文使用Python编程语言和OpenCV、TensorFlow等开发工具实现了车牌识别系统。
首先,对原始图像进行灰度化处理,并使用图像增强技术提高图像的质量。
然后,利用二值化处理将图像转换为二值图像。
接下来,利用图像处理技术对二值图像进行车牌定位,找到车牌区域。
然后,对车牌区域进行字符分割,得到分割好的字符。
最后,利用TensorFlow实现的深度学习模型对字符进行识别。
4.实验结果通过大量实验和测试,本文的车牌识别系统在车牌图像的识别准确率和鲁棒性方面取得了较好的效果。
实验结果表明,该系统在光照条件不同、车牌类型不同等复杂环境下仍能实现较高的识别准确率。
基于深度学习的车牌识别算法及应用深度学习(Deep Learning)是人工智能(AI)的子领域,拥有强大的数据处理能力和自我学习能力。
车牌识别系统是一个复杂的系统,它不仅需要高速而准确的识别车牌,还需要快速反应到执行任务。
因此,基于深度学习的车牌识别算法及应用已成为了该领域的研究热点。
一、深度学习在车牌识别中的应用深度学习是一个革命性的技术,在车牌识别系统中也发挥着重要作用。
使用深度学习技术可以让系统自动学习图像特征和车牌字符,不必手工编写复杂的特征提取算法,提高识别准确率和速度。
二、常见的车牌识别算法1. 基于卷积神经网络(CNN)的车牌识别算法CNN是一种深度学习结构,它可以自动学习图像特征,通过卷积、池化和全连接层,将图像映射到最终结果。
针对车牌识别任务,CNN可以在训练过程中自动学习车牌字符的特征,使得车牌识别准确率大幅提高。
2. 基于递归神经网络(RNN)的车牌识别算法RNN是一种递归神经网络,它可以学习序列数据的特征,用于识别车牌号码就是一个序列数据的问题。
在训练过程中,RNN不仅可以自动学习车牌字符的特征,还可以利用上下文信息来优化识别准确率。
3. 基于混合神经网络(HNN)的车牌识别算法HNN结合了CNN和RNN的优点,可以有效地识别车牌。
它首先通过CNN学习图像特征,然后使用RNN进行字符级别的识别。
HNN的识别准确率和效率都比较高,但是训练难度也较大。
三、车牌识别算法在实际应用中的挑战车牌识别算法在实际应用中还存在很多挑战,其中主要包括以下几个方面:1. 光照变化夜间车牌数据较少,训练的车牌识别算法对于夜晚光照条件下的车牌无法达到理想的精度。
2. 角度变化车辆运行时车牌的角度可能发生变化,对于固定位置摄像头进行车牌识别时可能会出现误差,特别是在车辆通过瞬间要求快速响应的场景下。
3. 遮挡车牌可能被固定台或者可调节的挡板遮挡,在车牌识别系统中需要解决遮挡物的问题,否则会导致识别准确率下降。
使用计算机视觉技术进行车牌识别的技巧与方法随着计算机视觉技术的快速发展,车牌识别成为了一个重要的应用领域。
车牌识别技术可以应用于交通管理、停车场管理、违章监控等领域,极大地提高了工作效率和安全性。
在本文中,我们将介绍一些使用计算机视觉技术进行车牌识别的技巧与方法。
1. 图像预处理在进行车牌识别之前,首先要对图像进行预处理。
这一步骤有助于提高后续识别的准确性。
常见的图像预处理方法包括图像增强、降噪和灰度化。
图像增强可以通过调整图像的亮度、对比度和色彩来增强图像的清晰度。
降噪可以通过滤波器来减少图像中的噪声,例如使用高斯滤波器或中值滤波器。
将图像转换为灰度图像有助于简化后续的图像处理,可以通过将RGB图像的三个通道取平均值来实现。
2. 车牌定位车牌定位是车牌识别的第一步,它的目标是从整个图像中准确地定位车牌区域。
常见的车牌定位方法有基于颜色的定位和基于边缘检测的定位。
基于颜色的定位方法通过提取车牌的颜色特征来定位车牌区域。
车牌一般都具有特定的颜色,例如蓝色、黄色等。
可以通过设置阈值来提取出与车牌颜色相似的区域,并通过形态学操作来进一步优化车牌的定位结果。
基于边缘检测的定位方法则通过检测图像中的边缘来定位车牌区域。
常见的边缘检测算法包括Sobel算子、Canny算子等。
通过检测到的边缘,我们可以确定车牌区域的大致位置,并进一步优化定位结果。
3. 字符分割在车牌定位之后,下一步就是对车牌进行字符分割。
字符分割的目标是将车牌上的字符区域从整个车牌图像中分割出来。
字符分割的准确性对于后续的字符识别至关重要。
字符分割可以通过基于投影的方法来实现。
投影法是将图像在水平或垂直方向上的亮度分布投影到一维空间中,然后通过分析投影图像的峰值和谷值来进行字符分割。
另一种常见的字符分割方法是基于连通区域的方法。
通过将连通区域分析应用于字符区域,我们可以将字符从车牌图像中分割出来。
连通区域分析可以通过计算连通区域的宽度、高度和长宽比来判断是否为字符区域。
OpenCV实现车牌定位(C++)最近开始接触 C++ 了,就拿⼀个 OpenCV ⼩项⽬来练练⼿。
在车牌⾃动识别系统中,从汽车图像的获取到车牌字符处理是⼀个复杂的过程,本⽂就以⼀个简单的⽅法来处理车牌定位。
我国的汽车牌照⼀般由七个字符和⼀个点组成,车牌字符的⾼度和宽度是固定的,分别为90mm和45mm,七个字符之间的距离也是固定的12mm,点分割符的直径是10mm。
使⽤的图⽚是从百度上随便找的(侵删),展⽰⼀下原图和灰度图:#include <iostream>#include <opencv2/highgui/highgui.hpp>#include <opencv2/imgproc.hpp>#include <opencv2/imgproc/types_c.h>using namespace std;using namespace cv;int main() {// 读⼊原图Mat img = imread("license.jpg");Mat gray_img;// ⽣成灰度图像cvtColor(img, gray_img, CV_BGR2GRAY);// 在窗⼝中显⽰游戏原画imshow("原图", img);imshow("灰度图", gray_img);waitKey(0);return 0;}灰度图像的每⼀个像素都是由⼀个数字量化的,⽽彩⾊图像的每⼀个像素都是由三个数字组成的向量量化的,使⽤灰度图像会更⽅便后续的处理。
图像降噪每⼀副图像都包含某种程度的噪声,在⼤多数情况下,需要平滑技术(也常称为滤波或者降噪技术)进⾏抑制或者去除,这些技术包括基于⼆维离散卷积的⾼斯平滑、均值平滑、基于统计学⽅法的中值平滑等。
这⾥采⽤基于⼆维离散卷积的⾼斯平滑对灰度图像进⾏降噪处理,处理后的图像效果如下:形态学处理完成了⾼斯去噪以后,为了后⾯更加准确的提取车牌的轮廓,我们需要对图像进⾏形态学处理,在这⾥,我们对它进⾏开运算,处理后如下所⽰:开运算呢就是先进⾏ erode 再进⾏ dilate 的过程就是开运算,它具有消除亮度较⾼的细⼩区域、在纤细点处分离物体,对于较⼤物体,可以在不明显改变其⾯积的情况下平滑其边界等作⽤。
基于opencv的车牌识别的代码车牌识别技术在现代交通管理、智能停车场等领域有着广泛的应用。
而基于 OpenCV 实现车牌识别是一种常见且有效的方法。
下面我们就来详细探讨一下实现车牌识别的代码逻辑和关键步骤。
首先,在开始编写代码之前,我们需要确保已经安装好了 OpenCV库以及相关的依赖项。
接下来,我们逐步分解车牌识别的主要流程。
第一步,图像采集。
这可以通过摄像头实时获取图像,或者读取已经存在的图片文件。
```pythonimport cv2从摄像头获取图像cap = cv2VideoCapture(0)或者读取图片文件image = cv2imread('platejpg')```第二步,图像预处理。
这一步的目的是提高图像质量,以便后续的处理。
常见的操作包括灰度化、高斯模糊去噪、边缘检测等。
```python灰度化gray_image = cv2cvtColor(image, cv2COLOR_BGR2GRAY)高斯模糊blurred_image = cv2GaussianBlur(gray_image, (5, 5), 0)Canny 边缘检测edges = cv2Canny(blurred_image, 50, 150)```第三步,车牌定位。
这是整个车牌识别中最关键的步骤之一。
通常会利用车牌的形状、颜色、纹理等特征来定位车牌。
```python寻找轮廓contours, _= cv2findContours(edges, cv2RETR_EXTERNAL,cv2CHAIN_APPROX_SIMPLE)for contour in contours:计算轮廓的面积和周长area = cv2contourArea(contour)perimeter = cv2arcLength(contour, True)根据面积和周长等条件筛选出可能的车牌区域if area > 1000 and perimeter > 300:获取车牌区域的矩形边界x, y, w, h = cv2boundingRect(contour)提取车牌区域plate_image = imagey:y + h, x:x + w```第四步,字符分割。
OpenCV下车牌定位算法实现代码(一)车牌定位算法在车牌识别技术中占有很重要地位,一个车牌识别系统的识别率往往取决于车牌定位的成功率及准确度。
车牌定位有很多种算法,从最简单的来,车牌在图像中一般被认为是长方形,由于图像摄取角度不同也可能是四边形。
我们可以使用OpenCV中的实例:C:\Program Files\OpenCV\samples\c.squares.c 这是一个搜索图片中矩形的一个算法。
我们只要稍微修改一下就可以实现定位车牌。
在这个实例中使用了canny算法进行边缘检测,然后二值化,接着用cvFindContours搜索轮廓,最后从找到的轮廓中根据角点的个数,角的度数和轮廓大小确定,矩形位置。
以下是效果图:这个算法可以找到一些车牌位置,但在复杂噪声背景下,或者车牌图像灰度与背景相差不大就很难定位车牌。
所以我们需要寻找更好的定位算法。
下面是squares的代码:#ifdef _CH_#pragma package <opencv>#endif#ifndef _EiC#include "cv.h"#include "highgui.h"#include <stdio.h>#include <math.h>#include <string.h>#endifint thresh = 50;IplImage* img = 0;IplImage* img0 = 0;CvMemStorage* storage = 0;CvPoint pt[4];const char* wndname = "Square Detection Demo";// helper function:// finds a cosine of angle between vectors// from pt0->pt1 and from pt0->pt2double angle( CvPoint* pt1, CvPoint* pt2, CvPoint* pt0 ){double dx1 = pt1->x - pt0->x;double dy1 = pt1->y - pt0->y;double dx2 = pt2->x - pt0->x;double dy2 = pt2->y - pt0->y;return (dx1*dx2 + dy1*dy2)/sqrt((dx1*dx1 + dy1*dy1)*(dx2*dx2 + dy2*dy2) + 1e-10); }// returns sequence of squares detected on the image.// the sequence is stored in the specified memory storageCvSeq* findSquares4( IplImage* img, CvMemStorage* storage ){CvSeq* contours;int i, c, l, N = 11;CvSize sz = cvSize( img->width & -2, img->height & -2 );IplImage* timg = cvCloneImage( img ); // make a copy of input imageIplImage* gray = cvCreateImage( sz, 8, 1 );IplImage* pyr = cvCreateImage( cvSize(sz.width/2, sz.height/2), 8, 3 );IplImage* tgray;CvSeq* result;double s, t;// create empty sequence that will contain points -// 4 points per square (the square's vertices)CvSeq* squares = cvCreateSeq( 0, sizeof(CvSeq), sizeof(CvPoint), storage );// select the maximum ROI in the image// with the width and height divisible by 2cvSetImageROI( timg, cvRect( 0, 0, sz.width, sz.height ));// down-scale and upscale the image to filter out the noisecvPyrDown( timg, pyr, 7 );cvPyrUp( pyr, timg, 7 );tgray = cvCreateImage( sz, 8, 1 );// find squares in every color plane of the imagefor( c = 0; c < 3; c++ ){// extract the c-th color planecvSetImageCOI( timg, c+1 );cvCopy( timg, tgray, 0 );// try several threshold levelsfor( l = 0; l < N; l++ ){// hack: use Canny instead of zero threshold level.// Canny helps to catch squares with gradient shadingif( l == 0 ){// apply Canny. Take the upper threshold from slider// and set the lower to 0 (which forces edges merging)cvCanny( tgray, gray,60, 180, 3 );// dilate canny output to remove potential// holes between edge segmentscvDilate( gray, gray, 0, 1 );}else{// apply threshold if l!=0:// tgray(x,y) = gray(x,y) < (l+1)*255/N ? 255 : 0//cvThreshold( tgray, gray, (l+1)*255/N, 255, CV_THRESH_BINARY ); cvThreshold( tgray, gray, 50, 255, CV_THRESH_BINARY );}// find contours and store them all as a listcvFindContours( gray, storage, &contours, sizeof(CvContour),CV_RETR_LIST, CV_CHAIN_APPROX_SIMPLE, cvPoint(0,0) );// test each contourwhile( contours ){// approximate contour with accuracy proportional// to the contour perimeterresult = cvApproxPoly( contours, sizeof(CvContour), storage,CV_POLY_APPROX_DP, cvContourPerimeter(contours)*0.02, 0 );// square contours should have 4 vertices after approximation// relatively large area (to filter out noisy contours)// and be convex.// Note: absolute value of an area is used because// area may be positive or negative - in accordance with the// contour orientationif( result->total == 4 &&fabs(cvContourArea(result,CV_WHOLE_SEQ)) > 1000 &&cvCheckContourConvexity(result) ){s = 0;for( i = 0; i < 5; i++ ){// find minimum angle between joint// edges (maximum of cosine)if( i >= 2 ){t = fabs(angle((CvPoint*)cvGetSeqElem( result, i ),(CvPoint*)cvGetSeqElem( result, i-2 ),(CvPoint*)cvGetSeqElem( result, i-1 )));s = s > t ? s : t;}}// if cosines of all angles are small// (all angles are ~90 degree) then write quandrange// vertices to resultant sequenceif( s < 0.3 )for( i = 0; i < 4; i++ )cvSeqPush( squares,(CvPoint*)cvGetSeqElem( result, i ));}// take the next contourcontours = contours->h_next;}}}// release all the temporary imagescvReleaseImage( &gray );cvReleaseImage( &pyr );cvReleaseImage( &tgray );cvReleaseImage( &timg );return squares;}// the function draws all the squares in the imagevoid drawSquares( IplImage* img, CvSeq* squares ){CvSeqReader reader;IplImage* cpy = cvCloneImage( img );int i;// initialize reader of the sequencecvStartReadSeq( squares, &reader, 0 );// read 4 sequence elements at a time (all vertices of a square)for( i = 0; i < squares->total; i += 4 ){CvPoint* rect = pt;int count = 4;// read 4 verticesmemcpy( pt, reader.ptr, squares->elem_size );CV_NEXT_SEQ_ELEM( squares->elem_size, reader );memcpy( pt + 1, reader.ptr, squares->elem_size );CV_NEXT_SEQ_ELEM( squares->elem_size, reader );memcpy( pt + 2, reader.ptr, squares->elem_size );CV_NEXT_SEQ_ELEM( squares->elem_size, reader );memcpy( pt + 3, reader.ptr, squares->elem_size );CV_NEXT_SEQ_ELEM( squares->elem_size, reader );// draw the square as a closed polylinecvPolyLine( cpy, &rect, &count, 1, 1, CV_RGB(0,255,0), 3, CV_AA, 0 );}// show the resultant imagecvShowImage( wndname, cpy );cvReleaseImage( &cpy );}void on_trackbar( int a ){if( img )drawSquares( img, findSquares4( img, storage ) );}char* names[] = { "pic1.png", "pic2.png", "pic3.png","pic4.png", "pic5.png", "pic6.png", 0 };int main(int argc, char** argv){int i, c;// create memory storage that will contain all the dynamic datastorage = cvCreateMemStorage(0);for( i = 0; names[i] != 0; i++ ){// load i-th imageimg0 = cvLoadImage( names[i], 1 );if( !img0 ){printf("Couldn't load %s\n", names[i] );continue;}img = cvCloneImage( img0 );// create window and a trackbar (slider) with parent "image" and set callback// (the slider regulates upper threshold, passed to Canny edge detector)cvNamedWindow( wndname,0 );cvCreateTrackbar( "canny thresh", wndname, &thresh, 1000, on_trackbar );// force the image processingon_trackbar(0);// wait for key.// Also the function cvWaitKey takes care of event processingc = cvWaitKey(0);// release both imagescvReleaseImage( &img );cvReleaseImage( &img0 );// clear memory storage - reset free space positioncvClearMemStorage( storage );if( c == 27 )break;}cvDestroyWindow( wndname );return 0;}#ifdef _EiCmain(1,"squares.c");#endifOpenCV下车牌定位算法实现代码(二)前面介绍了用OpenCV的squares实例定位车牌的算法,效果不是很理想。