使用SPSS进行数据探索性分析的步骤
- 格式:docx
- 大小:37.32 KB
- 文档页数:3
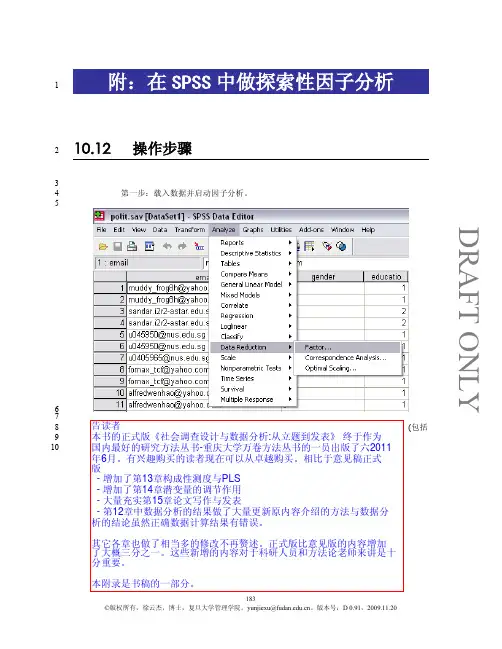
DRAFT ONLY附:在SPSS 中做探索性因子分析110.12操作步骤23 第一步:载入数据并启动因子分析。
4567 第二步:选择因子所对应的测度项。
在这个研究中,我们选择对应于七个变量(包括8 自变量、因变量、与控制变量) 的测度项。
910告读者丗本书的正式版丆《社会调查设计与数据分析:从立题到发表》丆 终于作为国内最好的研究方法丛书-重庆大学万卷方法丛书的一员出版了乮六2011年6月乯。
有兴趣购买的读者现在可以从卓越购买。
相比于意见稿丆正式版丗- 增加了第13章丆构成性测度与PLS•C - 增加了第14章丆潜变量的调节作用 - 大量充实第15章丆论文写作与发表- 第12章中数据分析的结果做了大量更新丆原内容介绍的方法与数据分析的结论虽然正确丆数据计算结果有错误。
其它各章也做了相当多的修改丆不再赘述。
正式版比意见版的内容增加了大概三分之一。
这些新增的内容对于科研人员和方法论老师来讲是十分重要。
本附录是书稿的一部分。
DRAFT ONLY12第三步:设定因子求解办法为主成分分析法。
使用相关系数矩阵,并设定主要因子的34特征根大于1。
5678第四步:设计因子旋转方法为“Varimax”。
然后在“Factor Analysis”窗口中按“ok”开始计算。
910DRAFT ONLY1210.13主成分分析的结果34 对应于27个测度项,主成分分析法一共产生了27个因子。
这是可以产生的因子个数5 的上限。
“Total ”列报告了每一个因子所对应的特征值。
“% of Variance ”表示这个特征6 值在所有特征值和中的比例。
“Extraction Sums of Squared Loadings ”这一列反映了特征根7 大于1的因子。
在这个例子中,我们顺利地得到了7个因子。
相应地,在用碎石坡法对因8 子进行目测时,我们得到的结果是一致的。
请读者参看本章中的相应图例。
值得一提的9 是,第八个因子的特征根为0.967,十分接近1。

使用SPSS进行探索式因素分析的教程探索性因素分析是一种统计方法,用于确定一组变量之间的潜在结构。
SPSS是一种常用于数据分析的软件工具,它提供了强大的因素分析功能。
以下是一个使用SPSS进行探索性因素分析的简单教程,该教程可以帮助您了解如何使用SPSS来执行因素分析并对结果进行解释。
步骤1:导入数据步骤2:准备数据确保您的数据符合因素分析的前提条件。
确定您要进行因素分析的变量是否具有线性关系,并进行必要的数据转换(例如,对数转换)以满足这个条件。
步骤3:执行因素分析在SPSS的“分析”菜单下,选择“数据准备”和“因子”。
在弹出的对话框中,选择您要进行因素分析的变量并将其移动到“因子”框中。
选择“萃取方法”(如主成分分析或最大似然估计)并指定要提取的因素的数量。
您还可以选择执行因子旋转以获得更简单和解释性更强的因子结构。
步骤4:解读结果SPSS将生成一个因素分析的输出报告,其中包含多个表格和图形。
以下是一些常见的解读步骤:-总体解释:观察“总体解释”表,了解因子数量和提取方法的解释力度。
查看“因素”的特征值,了解提取的因子解释的总方差比例。
-因子负荷:查看“因子负荷”表,该表显示了原始变量与提取的因子之间的相关性。
较高的因子负荷表示原始变量与特定因子之间的较强关联。
-因子旋转:如果您选择了因子旋转,则查看“旋转因子载荷矩阵”表,该表显示了旋转后的因子负荷。
查看这些旋转后的因子负荷以确定是否存在更简单的因子结构。
-因子得分:根据选定的因子分析方法,可以生成每个观测值的因子得分。
这些得分表示了每个观测值在每个因子上的得分情况,可以用于后续的分析和解释。
步骤5:解释因子根据因子负荷和因子名称,解释每个因子代表的潜在结构。
结合领域知识和因子负荷,您可以确定每个因子是否与特定概念或潜在维度相关联。
步骤6:结果报告根据您的研究目的和需要,将因子分析的结果写入报告中。
确保清楚地描述因子数量、命名以及每个因子代表的结构或概念。

最新SPSS数据分析的主要步骤资料最新的SPSS数据分析主要步骤资料是指在使用SPSS进行数据分析时的一系列指导和建议。
下面是一个超过1200字的详细解释。
步骤1:定义研究目的和问题在进行数据分析之前,首先需要明确研究的目的和问题是什么。
这有助于确定所需的数据类型、变量和分析方法等。
例如,研究目的可能是探索数据中的关联性、预测一些变量的值,或者比较不同组别之间的差异。
步骤2:数据准备和清洗在进行数据分析之前,必须对数据进行准备和清洗。
这包括删除缺失数据、处理异常值和离群值、转换数据类型等。
同时,还需要检查数据是否满足分析的前提条件,如正态分布、线性关系等。
步骤3:描述性统计分析描述性统计是对数据集的基本特征进行总结和展示的过程。
它包括计算变量的均值、标准差、频数和百分比等。
通过描述性统计分析,可以了解数据的分布情况、中心趋势和离散程度等。
步骤4:探索性数据分析在进行更深入的统计分析之前,建议进行一些探索性数据分析。
这包括绘制直方图、散点图、箱线图等图表,以了解变量之间的关系和趋势。
通过可视化数据,可以帮助我们发现隐藏在数据中的模式和趋势,为进一步的分析提供指导。
步骤5:应用统计方法在进行数据分析的核心阶段,要根据研究目的和问题选择适当的统计方法。
SPSS提供了各种常见的统计方法,如相关分析、回归分析、方差分析、T检验等。
根据研究的具体情况,选择合适的方法进行分析,并根据结果进行解释和推断。
步骤6:解释和报告结果数据分析的结果需要进行解释和报告,以便他人了解研究的发现和结论。
建议使用清晰简洁的方式来解释结果,并使用图表和表格等可视化工具来提供支持。
同时,还需要注意结果的可靠性和有效性,并根据实际情况提出进一步的建议和探索。
步骤7:验证和验证结果在分析结果之后,建议对结果进行验证和验证。
这可以通过重复分析、使用其他统计方法、进行敏感性分析等来实现。
通过验证和验证结果,可以提高分析的可靠性,并确保结论的正确性和准确性。

spss数据分析简单操作流程1.打开SPSS软件。
Open the SPSS software.2.在数据编辑器中导入你的数据集。
Import your dataset into the data editor.3.检查数据是否被正确导入。
Check if the data has been imported correctly.4.在变量视图中检查数据变量。
Check the data variables in the variable view.5.在数据视图中查看数据记录。
View the data records in the data view.6.进行数据清洗,处理缺失值和异常值。
Clean the data, handle missing and outlier values.7.进行描述性统计分析,了解数据的基本特征。
Conduct descriptive statistical analysis to understand the basic characteristics of the data.8.选择合适的分析方法,比如t检验、方差分析等。
Select appropriate analysis methods, such as t-tests, ANOVA, etc.9.运行所选的分析方法。
Run the selected analysis methods.10.解释分析结果,得出结论。
Interpret the analysis results and draw conclusions.11.导出分析结果为表格或图表。
Export the analysis results as tables or charts.12.保存分析的数据和结果。
Save the analyzed data and results.。

如何使用SPSS作数据分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学领域的数据分析。
本文将介绍如何使用SPSS进行数据分析的基本步骤和常用功能。
一、数据导入与清洗在使用SPSS进行数据分析之前,首先需要将数据导入软件,并对数据进行清洗,确保数据的准确性和完整性。
以下是数据导入与清洗的步骤:1. 打开SPSS软件,并创建一个新的数据文件。
2. 选择导入数据的方式,可以是从Excel、csv等格式导入,也可以手动输入数据。
3. 导入数据后,检查数据是否包含缺失值或异常值。
可以使用SPSS的数据清洗工具进行处理,比如删除缺失值或替代为合适的值。
4. 检查数据的变量类型,确保每个变量的类型正确,比如分类变量、连续变量等。
5. 对需要的变量进行重命名,并添加变量标签,便于后续分析的理解和解释。
二、数据描述统计分析数据描述统计是对数据的基本特征进行概括和描述的分析方法。
SPSS提供了丰富的数据描述统计功能,如均值、标准差、频数分布等。
以下是数据描述统计分析的步骤:1. 运行SPSS软件,打开已经导入并清洗好的数据文件。
2. 选择"统计"菜单下的"描述统计"选项。
3. 在弹出的对话框中,选择需要进行描述统计分析的变量,并选择所需的统计指标,如均值、标准差等。
4. 点击"确定"进行计算,SPSS将输出所选变量的描述统计结果,包括均值、标准差、中位数等。
三、相关性分析相关性分析用于衡量两个或多个变量之间的相关程度,常用于探究变量之间的关系。
SPSS提供了多种相关性分析方法,如皮尔逊相关系数、斯皮尔曼相关系数等。
以下是相关性分析的步骤:1. 打开已导入的数据文件。
2. 选择"分析"菜单下的"相关"选项。
3. 在弹出的对话框中,选择需要进行相关性分析的变量,并选择所需的相关系数方法。

SPSS探索性因子分析的过程探索性因子分析(Exploratory Factor Analysis,EFA)是一种统计方法,旨在帮助研究者理解和解释大量变量之间的关系。
它可以用于数据降维、信度分析和测量模型构建等多种研究目的。
以下是SPSS中进行探索性因子分析的详细步骤:1.数据准备:-打开SPSS软件,并导入数据文件。
-确保数据变量符合连续性或有序性测量标准。
如果存在分类变量,需要进行变量转换,如使用哑变量编码。
2.确定分析目的和因变量:-确定研究目的,明确是否要进行因子分析以及预期得到的结果。
-选择用于分析的变量,这些变量应当在理论上与研究目的相关,并且在实践中已经得到应用。
3.进行初始的探索性因子分析:-在「分析」菜单中选择「数据降维」,然后选择「因子」。
-从左侧的变量列表中选择需要进行因子分析的变量,将其添加到右侧的「因子分析」框中。
-在「提取」选项卡中,选择提取的因子数量。
通常,可以通过解释方差方法选择大于1的特征根值,或者根据理论确定因子数量。
-点击「列表」按钮,查看提取出的因子信息,包括特征根值、解释方差和因子载荷。
根据因子载荷大小判断变量与因子之间的关系。
4.进行旋转:-在「提取」选项卡中,点击「旋转」按钮。
- 在旋转选项卡中,选择旋转方法。
常用的旋转方法包括方差最大化(Varimax)、直角旋转(Orthogonal rotation)和斜交旋转(Oblique rotation)。
-点击「列表」按钮,查看旋转后的因子载荷。
选择合适的旋转结果,以使因子载荷更加清晰和解释性更好。
5.进行因子得分估计:-在主对话框中,点击「因子得分」选项卡。
-选择要估计的因子得分的方法。
可选择「最大似然估计」或「预测指标法」。
-点击「存储因子得分」复选框,以将因子得分保存到数据文件中。
-点击「OK」按钮进行分析。
6.结果解读:-分析结果包括提取的因子信息、旋转后的因子载荷、因子得分和信度分析等。
-根据因子载荷和理论知识,解释每个因子代表的潜在构念。

使用SPSS进行市场调查数据分析的步骤第一章:准备调查数据市场调查数据的准备是进行数据分析的首要步骤。
在这一章节中,我们将讨论如何准备和收集市场调查数据,以便能够进行后续的分析。
1.1 确定调查目的和设计在进行市场调查之前,我们需要明确调查的目的和设计。
这包括确定调查的研究问题、调查对象、调查方式以及样本规模等。
只有明确了调查目的和设计,我们才能有针对性地收集和准备数据。
1.2 收集数据市场调查数据可以通过不同的方式收集,例如问卷调查、个人访谈、焦点小组讨论等。
在收集数据时,我们需要注意确保数据的可靠性和有效性。
因此,在设计问卷或进行访谈时,要保证问题的清晰明确,避免引导性问题和双重否定等。
1.3 数据录入和清洗收集到的市场调查数据需要进行录入和清洗。
数据录入可以通过手动输入或扫描问卷等方式进行。
在录入过程中,要检查数据的准确性,确保没有错误的输入。
清洗数据是指检查和处理数据中的不一致、缺失或异常值等问题,以便后续的分析能够得到可靠的结果。
第二章:数据探索与描述在进行数据分析之前,我们需要对数据进行探索和描述,以了解数据的特征和分布情况。
这有助于为后续的分析提供参考和依据。
2.1 描述性统计描述性统计是对数据进行总体和特征描述的统计方法。
我们可以计算数据的均值、中位数、方差、标准差等指标,来描述数据的集中趋势和离散程度。
此外,还可通过绘制直方图、箱线图等图表来展示数据的分布情况。
2.2 数据相关性分析在市场调查中,数据之间可能存在相关性。
为了了解变量之间的关系,我们可以使用相关系数进行分析。
通过计算相关系数,我们可以判断两个变量之间的线性相关程度,并绘制散点图来展示其关系。
2.3 分组分析市场调查数据通常包含多个变量,我们可以通过分组分析来探究变量之间的差异性。
比如,我们可以将样本分为不同的年龄组或性别组,分析不同群体在某个变量上的差异。
第三章:假设检验在市场调查数据分析中,经常需要进行假设检验来验证研究假设的成立。

SPSS探索性因素分析之具体步骤探讨探索性因素分析之具体步骤探讨文/哈工程大学应用心理学系曹国兴这主要针对的是预试问卷而言,也就是说在初试问卷经过了语义分析,专家讨论论证之后最终得出的问卷。
以下的经验是根据我编制职业承诺问卷的基础上总结而来,错误之处希望同行指教。
首先要说的是关于样本数量的问题。
按照统计学标准而言,一般样本数应为题目数的5-10倍。
由于我的题目为50,故样本至少为250个。
前期我计划发放样本数为6倍也就是300份,由于样本流失及废卷的原因,最终回收到有效问卷为256份,有效率为85.33%。
当然这是无法避免的。
下面我主要谈一下进行探索性分析的具体步骤:第一:比较明确的一步就是做一下关于各个项目的鉴别度(区分度)的分析。
在这个条件下会删除一部分不适合的题目。
删除程序为SPSS下的Analyze→Scale→ReliabilityAnalysis。
比较保险的的是从比较小的鉴别度一步一步删除,每次删一些较低的题目就看一下科隆巴赫系数的大小,直到满意为止。
当然也可以直接将低于0.3的题目删除。
注意的是删除的应为那些删除后科隆巴赫系数值提高的题目,如果删除后科隆巴赫系数值降低,这就需要重新考虑了。
结合语义分析取舍。
第二:在这种情况下一般而言,进行问卷设计之前所有的题目究竟是属于哪一个维度或者有几个维度应该有一定的假设,此时应该如下操作:(1)首先是反向题目的更改。
这方面需要注意的就是每次关闭文件的时候注意不要保存或者你将反向题目更改后的文件保存下来,一定要注明,因为如果你忘记了,就会混淆到底反向题目有没有修改过。
(2)也就是重点阶段。
顾名思义探索性因子分析就好比你是一个探险家在探索一块未知的领域,你不知道去哪一个方向才是正确的,也许你走了很长的路却与你所期望的目的地相反。
为避免在进行探索性因子分析的时候做无用功,我采用了如下的方法:在最大变异法和极大相等法两种正交旋转下分别对题目进行讨论。

一、统计报告l 在线分析处理报告Analyze→Reports→OLAP Cubesl 个案摘要报告Analyze→Reports→Summarize Casesl 行形式摘要报告Analyze→Reports→Report Summaries in Rowsl 列形式摘要报告Analyze→Reports→Report Summaries in Columns二、描述性统计分析1.频数分析Analyze→Descriptive Statistic→Frequencies(1)频度分布表(2)变量描述统计量的计算(3)显示频度的图形2.基本描述统计量Analyze→Descriptive Statistic→Descriptivesl 集中趋势(Central T endency)的统计量l 离散趋势(Dispersion)的统计量l 分布形态(Distribution)的统计量3.探索性分析Analyze→Descriptive Statistic→Explorel 茎叶图l 箱图l 正态分布检验Q-Q概率图l 方差齐性检验的散点-分层图4.交叉列联表分析Analyze→Descriptive Statistic→Crosstabs三、两总体均值比较l 单样本T检验Analyze→Compare Means→One-Sample T T estl 独立样本T检验Analyze→Compare Means→Independen t-Samples T T est l 配对样本T检验Analyze→Compare Means→Paired-Samples T T est四、方差分析l 单因素方差分析Analyze→Compare Means→One-way ANOV Al 多因素方差分析Analyze→General Linear Model→Univariatel 协方差分析Analyze→General Linear Model→Univariateu 假设检验的步骤1.提出原假设和备择假设对每个假设检验问题,一般可同时提出两个相反的假设:●原假设原假设又称零假设,是正待检验的假设,记为H0●备择假设备择假设是拒绝原假设后可供选择的假设,记为H1 。

SPSS探索性因子分析的过程SPSS探索性因子分析(Exploratory Factor Analysis,EFA)是一种统计方法,旨在通过将大量的观测变量分解为较小的、相互关联的潜在因子,来帮助研究者理解潜在的数据结构和模式。
本文将介绍SPSS中进行探索性因子分析的过程,包括数据准备、模型设定、因子提取和解释因子。
一、数据准备在进行探索性因子分析之前,需要确保数据准备工作已经完成。
这包括了数据的清洗、缺失值的处理和变量的选择等。
清洗数据:删除不适用的或异常的数据,确保数据的一致性和可靠性。
处理缺失值:根据缺失数据的性质和缺失的模式,选择适当的处理方法,如删除带有缺失值的观测、替换缺失值(如均值填充)等。
选择变量:根据研究目的和理论基础,选择合适的变量进行因子分析。
二、模型设定在SPSS中,打开要进行因子分析的数据集,选择"数据"菜单下的"概要统计",然后选择"因子"。
选择因子旋转方法:因子旋转是为了使提取出的因子更易解释和理解。
常用的旋转方法有正交旋转(如Varimax旋转)和斜交旋转(如Oblimin旋转)等。
在进行因子旋转时,可以根据理论和实际情况选择适当的旋转方法。
三、因子提取在SPSS的因子分析过程中,需要进行因子提取来确定潜在因子的数量。
选择因子数:在进行因子提取时,需要预设潜在因子的数量。
根据Kaiser准则和Scree图等指标,确定因子的个数。
Kaiser准则建议保留特征值大于1的因子,Scree图则可通过图形分析法确定因子数。
执行因子分析:根据前面设定的方法和参数,执行因子分析。
根据提取出的因子载荷矩阵进行因子解释。
因子载荷矩阵反映了每个观测变量与每个因子之间的关系。
载荷值表示观测变量与因子之间的相关性,值越大表示相关性越大。
四、解释因子根据因子载荷矩阵来解释因子。
通过观察载荷矩阵,找出与每个因子高相关的观测变量(载荷值绝对值大于0.4),根据这些观测变量来解释因子的含义。
SPSS中对问卷数据进行探索因子分析的详细操作与结果解读——【杏花开生物医药统计】一、什么是探索因子分析探索因子分析主要用于对问卷数据进行统计分析。
通常我们在做问卷分析的时候,如果我们设计的题项没有明确的维度划分,而我们又需要了解这些题项的维度,这时我们就需要对这题项进行探索因子分析,通过在SPSS中进行探索因子分析,得到题项的维度,从而达到降维或者其他的目的。
二、因子分析与主成分分析的区别:主成分分析是将原始数据中最主要的成分放大,体现出来。
而因子分析是寻找一个新的隐藏因子,他能包含或包括原本数据中的一个或几个,而并不是其中主要成分的放大。
三、因子分析在SPSS中的实例操作与分析1.准备案例数据我们搜集了一份问卷数据,该问卷设计了调查自我效能的相关题项43题,这里并没有预先的维度划分,就需要进行探索因子分析,找出中43个题项的维度划分。
(图1)2.SPSS中的操作步骤①点击“分析”-“降维”-“因子分析”,在弹出的“因子分析”对话框中,将需要进行划分的43题项全部选入右侧“变量”框中。
(图2)(图3)②进行因子分析的参数设置,先点击右侧“描述”,勾选下面的“KMO和巴特利特球形度检验”。
这个是一前提检验,检验这些数据是否适合进行因子分析。
(图4)③再点击右侧的“旋转”按钮设置,在“方法”一栏里勾选“最大方差法”。
(图5)④最后点击右侧“选项”按钮设置,在系数显著栏里,勾选“按大小排序”和“排除小系数”,并将系数设置为0.5。
这里的意思就是只显示载荷大于0.5的,小于0.5的为排除项,不显示。
(图6)⑤点击下面“确定”进行计算,得到结果。
(图7)由上图表可以看出:KMO=0.937,大于0.7,说明这些数据十分适合做因子分析。
(图8)由总方差的解释这张表可以看出,基于特征值大于1时候的累积%为69.693%,大于60%,说明当前探索出来的8个维度,能够较好代表这整个数据。
(图9)最后通过旋转后的成分矩阵表来看具体划分,横向看,22和30不属于任何维度,那么就属于无效题项,应当删除,纵向看,维度8下面只有31题一题,那么这样的题项和维度也属于无效,当删除。
SPSS基本统计分析(⼆):探索分析1、主要功能:
此分析⽅法可检查数据是否有错误,对样本分布特征以及样本分布规律作初步了解。
剔除奇异值和错误数据。
探索性分析过程将提供在分组和不分组的情况下常⽤的统计量和图形。
2. SPSS操作
2.1操作步骤
对30名10岁少⼉(15男15⼥)的⾝⾼(cm)进⾏探索性分析。
注意:录⼊数据时,对不同分组需要定义新的组值,这⾥,0代表男孩,1代表⼥孩。
点击统计,出现如下对话框:
点击图,出现如下对话框:
点击选项,出现如下对话框:
2.2输出结果
(1)个案处理摘要:由表中可以看出不同性别的有效个案数、缺失个案数和总计个案数。
(2)下表中包含了所有的描述性统计指标。
(3)M估计量:给出的是4种集中趋势的稳健估计量,表格下⽅还给出了不同⽅法计算估计量的加权常量。
当数据中存在极端值或异常值时,M估计量是很好的均值和中位数的替代者,能够更好的反映数据的集中程度。
在描述统计中,如果均值和中位数与M估计量的差距很⼤,说明数据中存在异常值。
(4)百分位数
(5)正态性检验
给出了KS和SW两种正态检验⽅法的结果,P值均⼤于0.05,因此认为数据服从正态分布。
(6)⽅差齐性检验
表格所⽰为莱⽂⽅差齐性检验的结果,并列举了计算莱⽂统计量的4种算法,由结果得,P值均⼤于0.05,认为不同性别的⾝⾼⽅差是齐性的。
(7)箱图与极端值
由箱图可以看出,编号为24的⼥孩⾝⾼在箱图外,属于离群点。
极值表格中输出的是每个变量的5个最⼤值和5个最⼩值。
现要对长途进修者对教导技巧资本和应用情形进行懂得,设计一个李克特量表,如下图所示:一.因子剖析的界说在实际研讨进程中,往往须要对所反应事物.现象从多个角度进行不雅测.是以研讨者往往设计出多个不雅测变量,从多个变量收集大量数据以便进行剖析查找纪律.多变量大样本固然会为我们的科学研讨供给丰硕的信息,但却增长了数据收集和处理的难度.更重要的是很多变量之间消失必定的相干关系,导致了信息的重叠现象,从而增长了问题剖析的庞杂性.因子剖析是将实际生涯中浩瀚相干.重叠的信息进行归并和分解,将原始的多个变量和指标变成较少的几个分解变量和分解指标,以利于剖析剖断.用较少的分解指标剖析消失于各变量中的各类信息,而各分解指标之间彼此是不相干的,代表各类信息的分解指标成为因子.因子剖析就是用少数几个因子来描写很多指标之间的接洽,以较少几个因子反响原材料的大部分信息的统计办法.二.数学模子iZ 为第i 个变量的尺度化分数;(尺度分是一种由原始分推导出来的相对地位量数,它是用来解释原始分在所属的那批分数中的相对地位的.)mF 为配合因子;m 为所有变量配合因子的数量;iU 为变量i Z 的独一身分;α为因子负荷.(也叫因子载荷,统计意义就是第i个变量与第m个公共因子的相im干系数,它反应了第i个变量在第m个公共因子上的相对重要性也就是第m个配合因子对第i个变量的解释程度.)α不是很大就是很小,如许每个变量因子剖析的幻想情形,在于个体因子负荷im才干与较少的配合因子产生亲密接洽关系,假如想要以起码的配合身分数来解释变量间的关系程度,则i U彼此间不克不及有接洽关系消失.所谓的因子负荷就是因子构造华夏始变量与因子剖析时抽掏出配合因子的相干,α就是第i个原有变量和第m个因子即在各个因子变量不相干的情形下,因子负荷imα绝对变量间的相干系数,也就是i Z在第m个配合因子变量上的相对重要性,是以,im值越大则公共因子和原有变量关系越强.在因子剖析中有两个重要指针:一为“配合性”,二为“特点值”.所为配合性,也称变量配合度或者公共方差,就是每个变量在每个配合因子的负荷量的平方总和(一横列中所有因子负荷的的平方和),也就是个体变量可以被配合因子解释的变异量百分比,这个值是个体变量与配合因子间多元相干的平方.从配合性的大小可以断定这个原始变量与配合因子间的关系程度.假如大部分变量的配合度都高于0.8,则解释提掏出的配合因子已经根本反应了各原始变量80%以上的信息,仅有较少的信息丧掉,因子剖析后果较好.而各变量的独一身分就是1减掉落该变量配合性的值,就是原有变量不克不及被因子变量所能解释的部分.所谓特点值,是每个变量在某一配合因子的因子负荷的平方总和(一向行所有因子负荷的平方和),在因子剖析的的配合因子抽取中,特点值最大的配合因子会最先被抽取,其次是次大者,最后抽取的配合因子的特点值会最小,平日会接近于0.将每个配合因子的特点值除以总题数,为此配合因子可以解释的变异量,因子剖析的目标之一,即在身分构造的简略化,愿望以起码的配合因子能对总变异量做最大的解释,因而抽取的身分越少越好,但抽取的因子的累积变异量越大越好.三.SPSS中实现进程(一)录入数据(二)因子剖析“剖析”|“降维”|“因子剖析”选项卡,打开如图所示“因子剖析”对话框.从原变量量表中选择须要进行因子剖析的变量,然后单击箭头按钮将选中的变量选入“变量”列表中.“变量列表”的变量为要进行因子剖析的的目标变量,变量在区间或比率级别应当是定量变量.分类数据(如:性别等)不合适因子剖析.2.“描写按钮”:重要设定对原始变量的根本描写并对原始变量进行相干性剖析.选中“原始剖析成果”复选框,暗示因子剖析未转轴前之配合性.特点值.变异数百分等到累积百分比,这是一个中央成果,对主成分剖析来说,这些值是要进行剖析变量的相干或协方差矩阵的对角元素.KMO与Bartlett球形度磨练用来磨练适不合适用来做因子剖析.KMO磨练,磨练变量间的偏相干是否很小;巴特利特球形磨练,磨练相干阵是否是单位阵.KMO值越接近1越合适做因子剖析,巴特利特磨练的原假设设为相干矩阵为单位阵,假如Sig值谢绝原假设暗示变量间消失相干关系,是以合适做因子剖析.“抽取”按钮:重要设定提取公共因子的办法和公共因子的个数.办法:主成分剖析法.SPSS默认办法.该办法假定原变量是因子变量的线性组合,第一主成分有最大的方差,后续成分可解释的方差越来越少.这是应用最多的因子提取办法.剖析:相干性矩阵.暗示以相干性矩阵作为提取公共因子的根据,当剖析中应用不合的尺度测量变量时比较合适.输出:未扭转的因子解.显示未扭转时因子负荷量.特点值及配合性.碎石图.暗示输出与每个因子相接洽关系的特点值的图,该图用于肯定应保持的因子个数,平日该图显示大因子的峻峭斜率和残剩因子平缓的尾部之间明显的中止.按特点值大小分列,有助于肯定保存若干个因子.抽取:基于特点值.暗示抽取特点值超出指定值的所有因子,在“特点值大于”输入框中指定值,一般为1.4.扭转:用于设定因子扭转的办法.扭转的目标是为了简化构造,以帮忙解释因子SPSS默认不扭转.办法:最大方差法:是一种正交扭转办法,他使得对每个因子有高负载的变量的数量达到最小,并简化了因子的解释.输出:扭转解.该复选框只有在选择里扭转办法之后才干选择,对于正交扭转会显示已扭转的模式矩阵和因子变换矩阵.5.得分:用于对因子得分进行设置,即盘算因子得分.取默认值,单击持续按钮.6.选项:用于设定对变量缺掉值的处理和系数显示的格局.缺掉值:按列表消除个案.去除所有含缺掉值的个案后再进行剖析.系数显示格局:按大小分列.载荷系数按照数值的大小分列,并组成矩阵,使得在统一因子上具有较高载荷的变量的分列在一路,便于得到结论.(三)成果剖析1.KMO及Bartlett’磨练当KMO值愈大时,暗示变量间的配合因子愈多,愈合适进行因子剖析,根据专家不雅点,假如KMO的值小于0.5时,较不宜进行因子剖析,此处的KMO值为0.695,暗示合适因子剖析.此外Bartkett’s球形磨练的原假设为相干系数矩阵为单位阵,Sig值为0.000小于明显程度0.05,是以谢绝虚无假设,解释变量之间消失相干关系,合适做因子剖析.(Bartkett’s球形磨练的2 为234.438,自由度为45,达到明显,代表母群体的相干矩阵间有配合因子消失,合适进行因子剖析.)2.配合性,显示因子间的配合性成果.在主成分剖析中,有若干个原始变量便有若干个成分,所以配合性会等于1,没有独一身分.所以本成果中央一栏显示初试配合性都为1,则暗示抽取办法为主成分剖析法,最右一栏为题项的配合性.从该表可以得到,因子剖析的变量配合度都异常高,标明变量中的大部分信息均可以或许被因子所提取,解释因子剖析的成果是有用的. 3.整体解释的变异数--------扭转之前的数据.该表给出了因子进献率的成果,表中左侧部分为初始特点值,中央为提取主因子成果,右侧为扭转后的主因子成果.“合计”指因子的特点值,“方差的%”暗示该因子的特点值占总特点值百分比,“累积%”÷10=63.579%.个中自有前三个因子的特点值大于1,并且前三个因子的特点值之和占总特点值的89.366%,是以提取前三个因子作为主因子列于右边,这也是因子剖析时所抽出的公共因子数.因为特点值是由大到小分列,所以第一个公同因子的解释变异量平日是最大者,其次是第二个1.547,再是第三个1.032.扭转后的特点值为 4.389,3.137,1,411,解释变异量为43.885%,31.372%,14.108%,累积的解释变异量为43.885%,75.257%,89.366%.扭转后的特点值不合于转轴前的特点值.4.碎石图.特点值的碎石图.平日该图显示大因子的峻峭斜率和残剩因子平缓的尾部,之间有明显的中止.一般取主因子在异常峻峭的斜率上,而处在平缓斜率上的因子对变异的解释异常小.可以从此碎石图中看出,从第三个身分今后,坡线甚为平展,因而可以保存3个身分较为合适.5.成分矩阵:给出了未扭转的因子载荷.从该表中可以得到应用主成分剖析办法提取的三个因子的载荷量,个中因子负荷量小于0.1的未被显示,因子为了便利解释因子寄义,须要进行因子扭转.6.扭转成份矩阵:给出了扭转后的因子载荷值,个中扭转办法采取的是Kaiser尺度化的正交扭转法.经由过程因子扭转,各个因子有了比较明白的寄义.从图中可以看出:a1,a8,a6,a5,a4位因子1,a10,a9,a7为因子2,a3,a2为因子3.题项在其所属的因子层面次序是按照因子负荷量的高下分列的.7.成份转换矩阵:六.成果解释根据因子的特点值和扭转后的因子矩阵,采取了主成分剖析法抽掏出3个因子作为配合因子,并应用因子扭转办法中的最大方差法,按照从大到小的次序进行分列,使得变量与因子的关系豁然清楚明了,对其做如下表所示的因子剖析摘要表.。
正态分布及spss中的检验方法1.基本理论正态分布:又称高斯分布或上帝分布,分布形态,呈现最好和最坏的较少,较多的集中在一般如果是图形展示类似钟形。
一般问卷数据可以采用中心极限定理:在收集数据时只要收集的数据,次数足够大,数据将会趋向于正态分布,因此一般认为问卷数据满足近似正态分布。
正态性检验方法:K-S和S-W较严格和准确,但因为对数据的要求较为严格。
图形法p-p和q-q图,还有描述统计分析的偏度和峰度,非参数检验的单样本K-S检验。
图1探索方法勾选2.描述统计探索分析方法探索性分析方法的操作第一步:将数据导入spss软件后,点击分析、描述统计、探索。
图2探索性操作第一步第二步、进入图中对话框后,点击图,勾选直方图和含检验的正态性图,点击继续、确定。
图3探索性第二步然后正态性检验的结果就出来了(在正态检验中重要的是正态性检验表中的结果)。
图4探索性检验结果展示将结果粘贴复制到Excel表格中,后将整理好的结果粘贴复制到Word文档进行,由于p<0.05,表明本次数据不满足正态分布。
图5探索结果整理3.p-p图操作步骤第一步、将数据导入spss软件中,p-p图操作:点击分析、描述统计、p-p 图。
图6p-p操作步骤第一步进入图中框中后,将变量放入对应的对话框中点击确定。
图7p-p图勾选情况然后p-p图结果就出来了(根据图中点是否均匀的分布在对角线上,来判断是否满足近似正态)。
图8p-p图结果展示将p-p图结果放入Word文档中进行分析,从图中可以看出,点均分布在对角线附近,表明数据满足正态分布。
图9p-p结果整理4.Q-Q图操作步骤Q-Q图操作第一步:首先将数据导入spss中,点击分析、描述统计、Q-Q图。
图10Q-Q图操作步骤一第二步、进入图中对话框后,将对应变量放入对应框中,点击确定。
图11Q-Q图勾选情况然后Q-Q图结果就出来了(根据图中点是否均匀的分布在对角线上,来判断是否满足近似正态)。
手把手教你怎么用SPSS分析数据SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学和商业领域。
本文将手把手教您如何使用SPSS分析数据,并提供一些实用的技巧和注意事项。
第一步:导入数据首先,打开SPSS软件并新建一个数据文件。
选择“文件”菜单中的“打开”选项,找到要导入的数据文件,如Excel或CSV文件。
选择正确的导入选项,确保数据被正确地导入SPSS。
导入数据后,您可以在数据视图中看到数据的表格形式。
第二步:检查数据在分析之前,您需要检查导入的数据,确保数据被正确导入且没有缺失值或异常数据。
您可以查看数据的统计特征,例如平均值、标准差、最小值和最大值。
此外,您还可以使用图表检查变量的分布情况。
第三步:数据清洗在分析之前,您可能需要对数据进行清洗。
这可能包括删除缺失值、处理异常值或填补缺失数据。
SPSS提供了一些功能来处理这些问题。
您可以使用“数据”菜单中的“选择”选项来创建一个子样本,仅包含没有缺失值的数据。
此外,还可以使用“变量”菜单中的“转换”选项来创建变量的复制品,并对这些副本进行值的修复。
第四步:描述性统计描述性统计是对数据进行初步分析的重要步骤。
它可以提供关于数据集的重要信息,如平均值、中位数、标准差和百分位数。
您可以使用“分析”菜单中的“描述统计”选项来计算描述性统计量。
选择要计算的变量并运行分析,将得到包含描述性统计结果的输出。
第五步:数据分析一旦清洗和描述性统计完成,您就可以进行更多复杂的分析。
SPSS提供了各种分析选项,包括t检验、方差分析、回归分析、聚类分析等。
选择适当的统计方法,并设置所需的参数,然后运行分析。
结果将显示在输出窗口中,您可以查看统计结果、显著性值以及图表。
第六步:结果解释结果解释是分析的最后一步。
根据分析的目的和使用的统计方法,您需要解释和报告结果。
确保以简洁明了的方式解释统计结果,并使用图表和图形来展示数据。
使用SPSS进行数据探索性分析的步骤数据探索性分析是研究者在进行数据分析之前的一项重要工作。
它可以帮助研究者了解数据的基本特征、发现数据中的规律和异常情况,并为后续的数据分析提供参考。
SPSS是一款常用的统计软件,它提供了丰富的功能和工具,方便研究者进行数据探索性分析。
下面将介绍使用SPSS进行数据探索性分析的步骤。
1. 导入数据在SPSS中,首先需要将待分析的数据导入软件中。
可以通过点击菜单栏中的"文件"-"打开"来选择数据文件,或者直接将数据文件拖入SPSS的工作区。
导入数据后,SPSS会自动将数据显示在数据视图中。
2. 查看数据在导入数据后,可以通过查看数据视图来了解数据的整体情况。
数据视图显示了数据表格,每一列代表一个变量,每一行代表一个观察值。
可以通过滚动条或者快捷键来浏览数据。
同时,还可以通过点击菜单栏中的"数据"-"描述统计"-"频数"来查看每个变量的频数分布情况。
3. 处理缺失值在数据分析过程中,经常会遇到缺失值的情况。
缺失值可能对后续的数据分析产生影响,因此需要对缺失值进行处理。
SPSS提供了多种处理缺失值的方法,如删除含有缺失值的观察值、替换缺失值等。
可以通过点击菜单栏中的"数据"-"选择"-"筛选"来选择处理缺失值的方法。
4. 描述性统计分析描述性统计分析是数据探索性分析的重要部分,它可以帮助研究者了解数据的基本特征。
在SPSS中,可以通过点击菜单栏中的"分析"-"描述统计"-"统计量"来进行描述性统计分析。
在弹出的对话框中,选择需要进行描述性统计分析的变量,并选择需要计算的统计量,如均值、标准差、最小值、最大值等。
点击确定后,SPSS会自动计算并显示结果。
使用SPSS进行数据探索性分析的步骤
数据探索性分析是研究者在进行数据分析之前的一项重要工作。
它可以帮助研究者了解数据的基本特征、发现数据中的规律和异常情况,并为后续的数据分析提供参考。
SPSS是一款常用的统计软件,它提供了丰富的功能和工具,方便研究者进行数据探索性分析。
下面将介绍使用SPSS进行数据探索性分析的步骤。
1. 导入数据
在SPSS中,首先需要将待分析的数据导入软件中。
可以通过点击菜单栏中的"文件"-"打开"来选择数据文件,或者直接将数据文件拖入SPSS的工作区。
导入数据后,SPSS会自动将数据显示在数据视图中。
2. 查看数据
在导入数据后,可以通过查看数据视图来了解数据的整体情况。
数据视图显示了数据表格,每一列代表一个变量,每一行代表一个观察值。
可以通过滚动条或者快捷键来浏览数据。
同时,还可以通过点击菜单栏中的"数据"-"描述统计"-"频数"来查看每个变量的频数分布情况。
3. 处理缺失值
在数据分析过程中,经常会遇到缺失值的情况。
缺失值可能对后续的数据分析产生影响,因此需要对缺失值进行处理。
SPSS提供了多种处理缺失值的方法,如删除含有缺失值的观察值、替换缺失值等。
可以通过点击菜单栏中的"数据"-"选择"-"筛选"来选择处理缺失值的方法。
4. 描述性统计分析
描述性统计分析是数据探索性分析的重要部分,它可以帮助研究者了解数据的基本特征。
在SPSS中,可以通过点击菜单栏中的"分析"-"描述统计"-"统计量"来进行描述性统计分析。
在弹出的对话框中,选择需要进行描述性统计分析的变量,并
选择需要计算的统计量,如均值、标准差、最小值、最大值等。
点击确定后,SPSS会自动计算并显示结果。
5. 绘制图表
图表是数据探索性分析的重要工具,可以直观地展示数据的分布情况和趋势变化。
在SPSS中,可以通过点击菜单栏中的"图形"-"图表"来绘制各种类型的图表,如柱状图、折线图、散点图等。
在绘制图表时,需要选择需要展示的变量和图表类型,并进行相应的设置。
6. 相关性分析
相关性分析可以帮助研究者了解变量之间的相关关系。
在SPSS中,可以通过点击菜单栏中的"分析"-"相关"-"双变量"来进行相关性分析。
在弹出的对话框中,选择需要进行相关性分析的变量,并选择需要计算的相关系数。
点击确定后,SPSS会自动计算并显示结果。
7. 因素分析
因素分析是一种常用的数据降维方法,可以帮助研究者提取出数据中的主要因素。
在SPSS中,可以通过点击菜单栏中的"分析"-"数据降维"-"因子"来进行因素分析。
在弹出的对话框中,选择需要进行因素分析的变量,并进行相应的设置。
点击确定后,SPSS会自动进行因素分析,并显示结果。
8. 聚类分析
聚类分析可以帮助研究者将数据样本划分为若干个相似的群组。
在SPSS中,可以通过点击菜单栏中的"分析"-"分类"-"聚类"来进行聚类分析。
在弹出的对话框中,选择需要进行聚类分析的变量,并进行相应的设置。
点击确定后,SPSS会自动进行聚类分析,并显示结果。
以上是使用SPSS进行数据探索性分析的一般步骤。
在实际操作中,根据具体的研究目的和数据特点,可能还需要进行其他分析方法和技术的应用。
通过数据探索性分析,研究者可以更好地了解数据,为后续的数据分析和建模提供基础。