【原创】R语言时变参数VAR随机模型数据分析报告论文(代码数据)
- 格式:docx
- 大小:98.10 KB
- 文档页数:4

R语言回归模型项目分析报告论文摘要本文旨在介绍并分析一个使用R语言实现的回归模型项目。
该项目主要探究了自变量与因变量之间的关系,并利用R语言的回归模型进行了预测和估计。
本文将首先介绍项目背景和数据来源,接着阐述模型的构建和实现过程,最后对结果进行深入分析和讨论。
一、项目背景和数据来源本项目的目的是探究自变量X1、X2、X3等与因变量Y之间的关系。
为了实现这一目标,我们收集了来自某一领域的实际数据,数据涵盖了多个年份和多个地区的情况。
数据来源主要是公开可用的数据库和相关文献。
在数据处理过程中,我们对缺失值、异常值和重复值进行了适当处理,以保证数据的质量和可靠性。
二、模型构建和实现过程1、数据预处理在构建回归模型之前,我们对数据进行预处理。
我们检查并处理缺失值,采用插值或删除的方法进行处理;我们检测并处理异常值,以防止其对回归模型产生负面影响;我们进行数据规范化,将不同尺度的变量转化为同一尺度,以便于回归分析。
2、回归模型构建在数据预处理之后,我们利用R语言的线性回归函数lm()构建回归模型。
我们将自变量X1、X2、X3等引入模型中,然后通过交叉验证选择最佳的模型参数。
我们还使用了R-squared、调整R-squared、残差标准误差等指标对模型性能进行评价。
3、模型实现细节在构建回归模型的过程中,我们采用了逐步回归法(stepwise regression),以优化模型的性能。
逐步回归法是一种回归分析的优化算法,它通过逐步添加或删除自变量来寻找最佳的模型。
我们还使用了R语言的arima()函数进行时间序列分析,以探究时间序列数据的规律性。
三、结果深入分析和讨论1、结果展示通过R语言的回归模型分析,我们得到了因变量Y与自变量X1、X2、X3等之间的关系。
我们通过表格和图形的方式展示了回归分析的结果,其中包括模型的系数、标准误差、t值、p值等指标。
我们还提供了模型的预测值与实际值之间的比较图,以便于评估模型的性能。

R语言破产模型分析报告1、引言对保险人而言,资产和负债是影响保险人稳定经营至关重要的因素。
资产和负债的差额称为盈余,简记作:U(t)=A(t)−L(t),t>0其中A(t)表示时刻t的资产,L(t)表示时刻t的负债,t=0时刻的盈余被称为初始盈余,简记为u,即U(0)=u。
对这个初步的理论模型进行简化并根据实际情况设置一些假定情况,会得出很多不同的盈余过程模型,最经典的有古典盈余过程模型:U(t)=u+ct−S(t);u≥0,c>0这是一个以u为初值,以时间t为指标集的随机过程。
其中{S(t),t>0}称为总理赔过程,满足:S(t)={X1+X2+⋯XN(t),N(t)>00 ,N(t)=0N(t)表示[0,t]内的总理赔次数,Xi表示[0,t]内第i次理赔的金额。
根据这个古典盈余过程模型可以引出破产模型,在这个盈余过程模型中,一方面有连续不断的保费收入并以速度c进行积累,另一方面则是不断会有理赔需要支付,因此这是一个不断跳跃变化的过程。
从保险人的角度来看,当然希望ct−S(t)恒大于0,否则就有可能出现U(t)<0的情况,这种情况可以定义为理论意义上的破产。
从研究保险人破产角度出发,可以把这个盈余过程模型看做一个特殊的破产模型。
2、相关概念概述2.1、指数分布随机变量的密度函数为:f(x;λ)={λe −λx,x≥00 ,x<0则称随机变量服从指数分布。
2.2、泊松分布泊松过程中,第k次随机事件与第k+1次随机事件出现的时间间隔服从指数分布。
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。
如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数等等。
泊松分布的概率质量函数为:P(X=k)=e−λλk k!泊松分布的参数λ是单位时间内随机事件的平均发生率。
两个独立且服从泊松分布的随机变量,其和仍然服从泊松分布。

R语言向量误差修正模型(VECM)是一种用于多变量时间序列建模的方法,它可以帮助我们理解变量之间的长期和短期关系。
在本文中,我将深入探讨VECM模型的系数解读,并结合个人观点和理解,为您解析这一主题。
1. VECM模型简介VECM模型是向量自回归模型(VAR)的扩展,它在处理非平稳时间序列数据时具有很高的适用性。
与VAR模型不同的是,VECM模型考虑了变量之间的协整关系,从而可以分离长期均衡关系和短期动态调整过程。
2. VECM模型系数解读在VECM模型中,系数的解读非常重要。
我们需要关注模型的截距项和趋势项,它们代表了长期均衡关系的影响。
我们需要关注误差修正项的系数,它代表了模型中的短期调整过程。
通过这些系数的解读,我们可以更好地理解变量之间的动态关系。
3. 长期均衡关系解读当我们在VECM模型中发现存在协整关系时,我们可以通过截距项和趋势项来解读长期均衡关系。
截距项代表了长期均衡关系的水平,而趋势项则代表了长期均衡关系的变化趋势。
通过对这些系数的解读,我们可以揭示变量之间的长期关系。
4. 短期动态调整解读除了长期均衡关系,VECM模型还可以帮助我们理解变量之间的短期动态调整过程。
误差修正项的系数代表了短期动态调整的速度和方向,通过对这些系数的解读,我们可以了解变量之间的短期动态关系。
5. 个人观点和理解在我看来,VECM模型的系数解读是非常重要的。
通过深入理解模型系数的含义,我们可以更好地把握多变量时间序列数据的动态特性,从而做出更准确的预测和分析。
我认为在解读系数时,需要结合实际问题的背景和领域知识,以便更好地理解变量之间的关系。
总结与回顾通过本文的阐述,我们对VECM模型的系数解读有了更深入的理解。
从长期均衡关系到短期动态调整,每个系数都承载着丰富的信息,帮助我们理解变量之间的复杂关系。
在实际应用中,我们需要综合运用VECM模型的系数解读和领域知识,从而做出准确的预测和分析。
通过本文的讨论,相信您已经对r语言向量误差修正模型系数解读有了更深入的了解。

R语言arima模型时间序列分析报告(附代码数据)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了R语言arima模型时间序列分析报告library(openxlsx)data=read.xlsx("hs300.xlsx")XXX收盘价(元)`date=data$日期date=as.Date(as.numeric(date),origin="1899-12-30")#1998-07-05#绘制时间序列图plot(date,timeseries)timeseriesdiff<-diff(timeseries,differences=1)plot(date[-1],timeseriesdiff)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#我们可以通过键入下面的代码来得到时间序列(数据存于“timeseries”)的一阶差分,并画出差分序列的图:#时间序列分析之ARIMA模型预测#从一阶差分的图中可以看出,数据仍是不平稳的。
我们继续差分。
【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#二次差分(上面)后的时间序列在均值和方差上确实看起来像是平稳的,随着时间推移,时间序列的水平和方差大致保持不变。
因此,看起来我们需要对data进行两次差分以得到平稳序列。
#第二步,找到合适的ARIMA模型#如果你的时间序列是平稳的,或者你通过做n次差分转化为一个平稳时间序列,接下来就是要选择合适的ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的p值和q值。
为了得到这些,通常需要检查[平稳时间序列的(自)相关图和偏相关图。
#我们使用R中的“acf()”和“pacf”函数来分别(自)相关图和偏相关图。

本文是我们通过时间序列和ARIMA模型预测拖拉机销售的制造案例研究示例的延续。
您可以在以下链接中找到以前的部分:第1部分:时间序列建模和预测简介第2部分:在预测之前将时间序列分解为解密模式和趋势第3部分:ARIMA预测模型简介在本部分中,我们将使用图表和图表通过ARIMA预测PowerHorse拖拉机的拖拉机销售情况。
我们将使用前一篇文章中学到的ARIMA建模概念作为我们的案例研究示例。
但在我们开始分析之前,让我们快速讨论一下预测:诺查丹玛斯的麻烦人类对未来和ARIMA的痴迷 - 由Roopam撰写人类对自己的未来痴迷- 以至于他们更多地担心自己的未来而不是享受现在。
这正是为什么恐怖分子,占卜者和算命者总是高需求的原因。
Michel de Nostredame(又名Nostradamus)是一位生活在16世纪的法国占卜者。
在他的着作Les Propheties (The Prophecies)中,他对重要事件进行了预测,直到时间结束。
诺查丹玛斯的追随者认为,他的预测对于包括世界大战和世界末日在内的重大事件都是不可挽回的准确。
例如,在他的书中的一个预言中,他后来成为他最受争议和最受欢迎的预言之一,他写了以下内容:“饥饿凶猛的野兽将越过河流战场的大部分将对抗希斯特。
当一个德国的孩子什么都没有观察时,把一个伟大的人画进一个铁笼子里。
“他的追随者声称赫斯特暗指阿道夫希特勒诺查丹玛斯拼错了希特勒的名字。
诺查丹玛斯预言的一个显着特点是,他从未将这些事件标记到任何日期或时间段。
诺查丹玛斯的批评者认为他的书中充满了神秘的专业人士(如上所述),他的追随者试图强调适合他的写作。
为了劝阻批评者,他的一个狂热的追随者(基于他的写作)预测了1999年7月世界末日的月份和年份 - 相当戏剧化,不是吗?好吧当然,1999年那个月没有发生任何惊天动地的事情,否则你就不会读这篇文章。
然而,诺查丹玛斯将继续成为讨论的话题,因为人类对预测未来充满了痴迷。

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
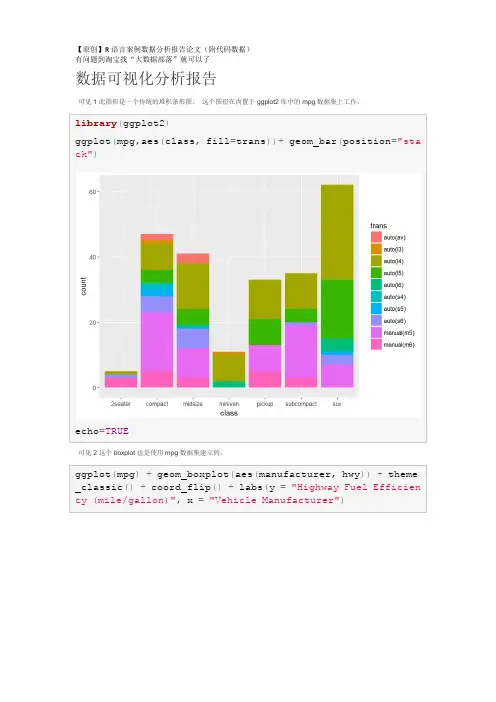
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogR语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)数据分析报告随着lme4软件包的改进,使用广义线性混合模型(GLMM)和线性混合模型(LMM)的工作变得越来越容易。
当我们发现自己在工作中越来越多地使用这些模型时,我们(作者)开发了一套工具,用于简化和加快与的merMod对象进行交互的常见任务lme4。
该软件包提供了那些工具。
安装# development versionlibrary(devtools)install_github("jknowles/merTools")# CRAN version -- coming sooninstall.packages("merTools")咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogRshiny的应用程序和演示演示此应用程序功能的最简单方法是使用捆绑的Shiny应用程序,该应用程序会在此处启动许多指标以帮助探索模型。
去做这个:devtools::install_github("jknowles/merTools")library(merTools)m1 <- lmer(y ~ service + lectage + studage + (1|d) + (1|s), data=InstEval)shinyMer(m1, simData = InstEval[1:100, ]) # just try the first 100 rows of data在第一个选项卡上,该功能提供了用户选择的数据的预测间隔,这些预测间隔是使用predictInterval包中的功能计算得出的。
通过从固定效应和随机效应项的模拟分布中进行采咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog样,并将这些模拟估计值组合起来,可以为每个观测值生成预测分布,从而快速计算出预测间隔。

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogR语言进行数值模拟:模拟泊松回归模型数据分析报告来源:大数据部落| 有问题百度一下“”就可以了模拟回归模型的数据验证回归模型的首选方法是模拟来自它们的数据,并查看模拟数据是否捕获原始数据的相关特征。
感兴趣的基本特征是平均值。
我喜欢这种方法,因为它可以扩展到广义线性模型(logistic,Poisson,gamma,...)和其他回归模型,比如t -regression。
您的标准回归模型假设存在将预测变量与结果相关联的真实/固定参数。
但是,当我们执行回归时,我们只估计这些参数。
因此,回归软件返回表示系数不确定性的标准误差。
我将用一个例子来证明我的意思。
示范我将使用泊松回归来证明这一点。
我模拟了两个预测变量,使用50的小样本。
n <- 50set.seed(18050518) xc的系数为0.5 ,xb的系数为1 。
我对预测进行取幂,并使用该rpois()函数生成泊松分布结果。
# Exponentiate prediction and pass to rpois()summary(dat)咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogxc xb yMin. :-2.903259Min. :0.00Min. :0.001st Qu.:-0.6487421st Qu.:0.001st Qu.:1.00Median :-0.011887 Median :0.00Median :2.00Mean : 0.006109 Mean :0.38Mean :2.023rd Qu.: 0.8085873rd Qu.:1.003rd Qu.:3.00Max. : 2.513353Max. :1.00Max. :7.00接下来是运行模型。
Call:glm(formula = y ~ xc + xb, family = poisson, data = dat)Deviance Residuals:Min 1Q Median 3Q Max-1.9065-0.9850-0.13550.5616 2.4264Coefficients:Estimate Std. Error z value Pr(>|z|)(Intercept) 0.208390.15826 1.3170.188xc 0.461660.09284 4.9736.61e-07 ***xb 0.809540.20045 4.0395.38e-05 ***---Signif. codes:0‘***’ 0.001‘**’ 0.01‘*’ 0.05‘.’ 0.1‘ ’ 1 (Dispersion parameter for poisson family taken to be 1)Null deviance:91.087on 49degrees of freedomResidual deviance:52.552on 47degrees of freedom AIC:161.84 Number of Fisher Scoring iterations:5咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog估计的系数与人口模型相距不太远,.21代表截距而不是0,.46而不是.5,而0.81而不是1。

R语言VAR模型的不同类型的脉冲响应分析原文链接:/?p=9384目录模型与数据估算值预测误差脉冲响应识别问题正交脉冲响应结构脉冲反应广义脉冲响应参考文献脉冲响应分析是采用向量自回归模型的计量经济学分析中的重要一步。
它们的主要目的是描述模型变量对一个或多个变量的冲击的演化。
因此使它们成为评估经济时非常有用的工具。
这篇文章介绍了VAR文献中常用的脉冲响应函数的概念和解释。
模型与数据为了说明脉冲响应函数的概念,使用了Lütkepohl(2007)的示例。
可以从教科书的网站上下载所需的数据集。
它包含从1960年1季度到1982年4季度按季度和季节性调整的时间序列,这些序列是西德的固定投资,可支配收入和数十亿德国马克的消费支出。
# 下载数据data <- read.table("e1.dat", skip = 6, header = TRUE)# 仅使用前76个观测值,因此有73个观测值# 取一阶差分后,留给估计的VAR(2)模型。
data <- data[1:76, ]# 转换为时间序列对象data <- ts(data, start = c(1960, 1), frequency = 4)# 取对数和差值data <- diff(log(data))# 绘图数据plot(data, main = "Dataset E1 from Lütkepohl (2007)")此数据用于估计具有常数项的VAR(2)模型。
估算值可以使用vars软件包估算VAR模型:# 查看摘要统计信息summary(model)代码的结果应与Lütkepohl(2007)的3.2.3节中的结果相同。
预测误差脉冲响应由于VAR模型中的所有变量都相互依赖,因此单独的系数估计仅提供有关反应的有限信息。
为了更好地了解模型的动态行为,使用了_脉冲响应_(IR)。

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogR语言求风险价值VaR Value at Risk 数据分析报告来源:风险价值是衡量与投资组合相关的风险水平的统计方法。
风险价值在指定的时间范围内和给定的置信水平下测量最大损失量。
首先,它的英文值是价值的风险性,缩写一般是风险价值而不是无功,后者通常是指方差是方差。
在风险价值出现以前,风险一般是用方差衡量的。
方差虽然可以很好的表达风险资产在一段时间里的变化的激烈程度,但并不直观。
假如我说『我的股票去年方差是400』,一般投资者很难理解这个数字的含义。
假如开个方变成标准方差,加上单位,说『我的股票去年标准方差是20万』,这意味着『我的股票去年平均涨跌20万』,就相对好理解一些。
而且很多时候我们并不关心平均起伏,而是“最大的损失”,而风险价值是摩根大通那一批发明的指标,我可以说“我的股票去年99%的风险值是30万“意味着我的股票去年的99%的亏损不到30万。
作为一般投资者,可能会知道他们是否有风险。
历史模拟方法这里本文将介绍使用历史模拟方法计算单个股票的风险价值的方法。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog简而言之,这种方法是:获取一段时期(通常为501天)的收益率数据,并采取特定的分位数,衡量该风险的价值。
在ř中,我们将以沪深300指数为例进行计算。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog尽管芒格(美国投资家,沃伦·巴菲特的黄金搭档)认为风险价值(Value at Risk)是有史以来最蠢的衡量指标。
但是VAR的广泛应用代表着监管机构正式开始运用概率性思维衡量金融机构的风险,而不是用单纯地采用静态的会计数据.VAR的测度能力还很原始,但仍代表了思维进步的趋势。
实验目的1. 用R生成服从某些具体已知分布的随机变量二、实验内容在R中各种概率函数都有统一的形式,即一套统一的前缀+分布函名: d表示密度函数(density );p 表示分布函数(生成相应分布的累积概率密度函数);q表示分位数函数,能够返回特定分布的分位( quantile );r表示随机函数,生成特定分布的随机数( random)。
R中的各种概率统计分布汉文名称英文名称R対应的乳字附加参数B分布beta beta shapely shape2, nep二项式分布binomial binom size, prob柯阿分布Cauchy cauchy location, scale忖方分布匚hi-squared chisq elf# nep指数分布exponential exp rateF分布F f dfl f dfl, nepGamma(¥)分布gamma gamma shape, scale几何分布geometric geom prob超几何分布hypergeometric hyper m, n, k对数币态分布log-normml Inorm meanlog, sdlogLogistic 分布logistic logis Io匚ation, scale血二项式分布negative binomial rib inom size, prob正态分布normal norm mean, sd泊松分布Poisson pois lambdaWilcoxon signed rank signrank nt分布Student's t t df# nep|均匀分布uniform unif min f max韦伯分布Weibull weibull shape, scale怯和分布Wilcoxon wilcox m# n1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x) > u}若u~u (0,1),贝U F-(u)和X的分布一样Example 1如果X~Exp (1)(服从参数为 u~u(0,1),则 X=-logU~Exp(1) 则可以解出x=-log(1-u)Exp from Uniform通过随机数生成产生的分布与本身的指数分布结果相一致R代码如下:nsim = 10A 4U = runif(nsim) X = -log(U)Y = rexp(nsim) X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8)) curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8)) curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
# 数据处理思路## 1.原始数据为4组时间序列;##读取软件包library("fGarch")library("quantmod")library(ghyp)library(copula)##设置工作目录##读取数据data=read.csv("Data.csv")head(data)## Pound Jpan Usd Eur## 1 -0.016689192 -0.006422036 -0.004161304 0.001084608## 2 0.000000000 0.005993930 0.000000000 -0.034008741## 3 0.000000000 -0.006850273 0.008322209 -0.013969242## 4 0.012517495 0.010275005 0.000000000 -0.001120290## 5 0.012513888 -0.007277877 0.020798548 -0.011676878## 6 -0.008342191 0.002140679 0.012474350 0.007202157data=na.omit(data)# 2.对每组数据进行基本检验(自回归,异方差,自相关,稳定性,正态性)然后进行G ARCH(1,1)建模,得到四个边缘分布;##自编函数进行基本检验testfun=function(yield){##绘制时序图ts.plot(yield)##基本统计量summary(yield)sd(yield)var(yield)## /*偏度、峰度*/n<-length(yield)m <-mean(yield)s <-sd(yield)g1 <-n/((n-1)*(n-2))*sum((yield-m)^3)/s^3g2 <-((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((yield-m)^4)/s^4-(3*(n-1)^2)/((n-2)*(n-3)))##偏度g1##峰度g2## /*作图*/hist(yield,freq = F)lines(density(yield))##QQ图(正态性)qqnorm(yield)qqline(yield)library(tseries)## /*JB检验*/(检验正态性)print(jarque.bera.test(yield))## /*自相关性检验*/print(Box.test(yield,type="Ljung-Box" ) )# 然后用自相关图检查序列的平稳性,,最后发现一阶差分后的序列是平稳的##检验自相关偏相关系数acf(yield)pacf(yield)# 下面对平稳性序列建立模型 ,偏相关系数在滞后1期后很快地趋向于0,所以取p=1 ,自相关系数图形具有拖尾性,所以初步判断为ar(1)模型## /*单位根检验*/ 稳定性检验print(adf.test(yield))print(pp.test(yield))## /* ARCH-LM检验结果*/ 异方差检验library(FinTS)print(ArchTest(yield, lags=12, demean =FALSE) )## 建立/*GARCH*/模型library(fGarch);library(rugarch)## /*GARCH(1,1)-norm*/garch_norm<-garchFit(yield~garch(1, 1),trace=FALSE)garch_normspec<-ugarchspec(variance.model=list(garchOrder=c(1,1)),mean.model=list(armaOrder=c(0,0)))fit <-ugarchfit(spec = spec, data = yield)fit}##对每一组数据进行分析yield=data[,1] testfun(yield)#### Jarque Bera Test#### data: yield## X-squared = 614.62, df = 2, p-value < 2.2e-16 ###### Box-Ljung test#### data: yield## X-squared = 0.51149, df = 1, p-value = 0.4745## Warning in adf.test(yield): p-value smaller than printed p-value #### Augmented Dickey-Fuller Test#### data: yield## Dickey-Fuller = -13.844, Lag order = 13, p-value = 0.01## alternative hypothesis: stationary## Warning in pp.test(yield): p-value smaller than printed p-value #### Phillips-Perron Unit Root Test#### data: yield## Dickey-Fuller Z(alpha) = -2511.3, Truncation lag parameter = 9, ## p-value = 0.01## alternative hypothesis: stationary###### ARCH LM-test; Null hypothesis: no ARCH effects#### data: yield## Chi-squared = 137.66, df = 12, p-value < 2.2e-16## Loading required package: parallel#### Attaching package: 'rugarch'## The following object is masked from 'package:stats': #### sigma#### *---------------------------------*## * GARCH Model Fit *## *---------------------------------*#### Conditional Variance Dynamics## -----------------------------------## GARCH Model : sGARCH(1,1)## Mean Model : ARFIMA(0,0,0)## Distribution : norm#### Optimal Parameters## ------------------------------------## Estimate Std. Error t value Pr(>|t|)## mu -0.000306 0.000404 -0.7566 0.44929## omega 0.000005 0.000004 1.3070 0.19123## alpha1 0.026957 0.005041 5.3478 0.00000## beta1 0.963989 0.002210 436.1868 0.00000#### Robust Standard Errors:## Estimate Std. Error t value Pr(>|t|)## mu -0.000306 0.000430 -0.71164 0.47669## omega 0.000005 0.000025 0.18945 0.84974## alpha1 0.026957 0.031215 0.86359 0.38782## beta1 0.963989 0.005525 174.47964 0.00000#### LogLikelihood : 6477.686#### Information Criteria## ------------------------------------#### Akaike -4.8275## Bayes -4.8187## Shibata -4.8275## Hannan-Quinn -4.8243#### Weighted Ljung-Box Test on Standardized Residuals## ------------------------------------## statistic p-value## Lag[1] 0.00832 0.9273## Lag[2*(p+q)+(p+q)-1][2] 1.48204 0.3652## Lag[4*(p+q)+(p+q)-1][5] 4.83395 0.1668## d.o.f=0## H0 : No serial correlation#### Weighted Ljung-Box Test on Standardized Squared Residuals ## ------------------------------------## statistic p-value## Lag[1] 6.92 0.008522## Lag[2*(p+q)+(p+q)-1][5] 8.11 0.027672## Lag[4*(p+q)+(p+q)-1][9] 11.59 0.022506## d.o.f=2#### Weighted ARCH LM Tests## ------------------------------------## Statistic Shape Scale P-Value## ARCH Lag[3] 0.2937 0.500 2.000 0.5878## ARCH Lag[5] 2.0334 1.440 1.667 0.4639## ARCH Lag[7] 5.6010 2.315 1.543 0.1704#### Nyblom stability test## ------------------------------------## Joint Statistic: 4.4761## Individual Statistics:## mu 0.32013## omega 0.76021## alpha1 0.09171## beta1 0.23634#### Asymptotic Critical Values (10% 5% 1%)## Joint Statistic: 1.07 1.24 1.6 ## Individual Statistic: 0.35 0.47 0.75 #### Sign Bias Test## ------------------------------------## t-value prob sig ## Sign Bias 2.0286 0.04260 ** ## Negative Sign Bias 2.5388 0.01118 ** ## Positive Sign Bias 0.2935 0.76914 ## Joint Effect 6.9989 0.07193 * ###### Adjusted Pearson Goodness-of-Fit Test: ## ------------------------------------## group statistic p-value(g-1)## 1 20 105.7 4.951e-14## 2 30 216.2 1.590e-30## 3 40 284.3 5.053e-39## 4 50 404.9 1.711e-57###### Elapsed time : 0.784045yield=data[,2]testfun(yield)#### Jarque Bera Test#### data: yield## X-squared = 622.46, df = 2, p-value < 2.2e-16 ###### Box-Ljung test#### data: yield## X-squared = 8.6698, df = 1, p-value = 0.003235## Warning in adf.test(yield): p-value smaller than printed p-value #### Augmented Dickey-Fuller Test#### data: yield## Dickey-Fuller = -13.404, Lag order = 13, p-value = 0.01## alternative hypothesis: stationary## Warning in pp.test(yield): p-value smaller than printed p-value#### Phillips-Perron Unit Root Test#### data: yield## Dickey-Fuller Z(alpha) = -2799.7, Truncation lag parameter = 9, ## p-value = 0.01## alternative hypothesis: stationary###### ARCH LM-test; Null hypothesis: no ARCH effects#### data: yield## Chi-squared = 200.84, df = 12, p-value < 2.2e-16#### *---------------------------------*## * GARCH Model Fit *## *---------------------------------*#### Conditional Variance Dynamics## -----------------------------------## GARCH Model : sGARCH(1,1)## Mean Model : ARFIMA(0,0,0)## Distribution : norm#### Optimal Parameters## ------------------------------------## Estimate Std. Error t value Pr(>|t|)## mu -0.000378 0.000162 -2.32606 0.020015## omega 0.000001 0.000003 0.29829 0.765484## alpha1 0.073454 0.054146 1.35659 0.174911## beta1 0.918489 0.053787 17.07655 0.000000#### Robust Standard Errors:## Estimate Std. Error t value Pr(>|t|)## mu -0.000378 0.004551 -0.083040 0.93382## omega 0.000001 0.000224 0.004403 0.99649## alpha1 0.073454 3.609132 0.020352 0.98376## beta1 0.918489 3.598937 0.255211 0.79856#### LogLikelihood : 8875.036#### Information Criteria## ------------------------------------#### Akaike -6.6152## Bayes -6.6064## Shibata -6.6152## Hannan-Quinn -6.6121#### Weighted Ljung-Box Test on Standardized Residuals## ------------------------------------## statistic p-value## Lag[1] 1.670 0.1963## Lag[2*(p+q)+(p+q)-1][2] 2.129 0.2422## Lag[4*(p+q)+(p+q)-1][5] 3.179 0.3754## d.o.f=0## H0 : No serial correlation#### Weighted Ljung-Box Test on Standardized Squared Residuals ## ------------------------------------## statistic p-value## Lag[1] 1.365 0.2427## Lag[2*(p+q)+(p+q)-1][5] 1.781 0.6711## Lag[4*(p+q)+(p+q)-1][9] 2.051 0.8988## d.o.f=2#### Weighted ARCH LM Tests## ------------------------------------## Statistic Shape Scale P-Value## ARCH Lag[3] 0.5947 0.500 2.000 0.4406## ARCH Lag[5] 0.7150 1.440 1.667 0.8189## ARCH Lag[7] 0.8194 2.315 1.543 0.9411#### Nyblom stability test## ------------------------------------## Joint Statistic: 83.8698## Individual Statistics:## mu 0.1258## omega 8.1451## alpha1 0.1628## beta1 0.2932#### Asymptotic Critical Values (10% 5% 1%) ## Joint Statistic: 1.07 1.24 1.6 ## Individual Statistic: 0.35 0.47 0.75 #### Sign Bias Test## ------------------------------------## t-value prob sig## Sign Bias 0.8300 0.4066## Negative Sign Bias 0.0096 0.9923## Positive Sign Bias 0.8500 0.3954## Joint Effect 3.9034 0.2721###### Adjusted Pearson Goodness-of-Fit Test: ## ------------------------------------## group statistic p-value(g-1)## 1 20 134.1 2.473e-19## 2 30 178.1 2.286e-23## 3 40 156.3 5.577e-16## 4 50 207.4 2.232e-21###### Elapsed time : 0.686039yield=data[,3]testfun(yield)#### Jarque Bera Test#### data: yield## X-squared = 1139.4, df = 2, p-value < 2.2e-16 ###### Box-Ljung test#### data: yield## X-squared = 1.7147, df = 1, p-value = 0.1904## Warning in adf.test(yield): p-value smaller than printed p-value #### Augmented Dickey-Fuller Test#### data: yield## Dickey-Fuller = -13.046, Lag order = 13, p-value = 0.01## alternative hypothesis: stationary## Warning in pp.test(yield): p-value smaller than printed p-value#### Phillips-Perron Unit Root Test#### data: yield## Dickey-Fuller Z(alpha) = -2592.1, Truncation lag parameter = 9, ## p-value = 0.01## alternative hypothesis: stationary###### ARCH LM-test; Null hypothesis: no ARCH effects#### data: yield## Chi-squared = 186.82, df = 12, p-value < 2.2e-16#### *---------------------------------*## * GARCH Model Fit *## *---------------------------------*#### Conditional Variance Dynamics## -----------------------------------## GARCH Model : sGARCH(1,1)## Mean Model : ARFIMA(0,0,0)## Distribution : norm#### Optimal Parameters## ------------------------------------## Estimate Std. Error t value Pr(>|t|)## mu -0.000280 0.000409 -0.68501 0.493340## omega 0.000003 0.000002 2.04640 0.040717## alpha1 0.040733 0.004312 9.44690 0.000000## beta1 0.953784 0.004676 203.97687 0.000000#### Robust Standard Errors:## Estimate Std. Error t value Pr(>|t|)## mu -0.000280 0.000392 -0.71474 0.47477## omega 0.000003 0.000004 0.93251 0.35107## alpha1 0.040733 0.004957 8.21679 0.00000## beta1 0.953784 0.006562 145.34066 0.00000#### LogLikelihood : 6305.272#### Information Criteria## ------------------------------------#### Akaike -4.6989## Bayes -4.6901## Shibata -4.6989## Hannan-Quinn -4.6958#### Weighted Ljung-Box Test on Standardized Residuals## ------------------------------------## statistic p-value## Lag[1] 1.487 0.2227## Lag[2*(p+q)+(p+q)-1][2] 2.793 0.1596## Lag[4*(p+q)+(p+q)-1][5] 4.167 0.2340## d.o.f=0## H0 : No serial correlation#### Weighted Ljung-Box Test on Standardized Squared Residuals ## ------------------------------------## statistic p-value## Lag[1] 0.2218 0.6377## Lag[2*(p+q)+(p+q)-1][5] 0.6245 0.9369## Lag[4*(p+q)+(p+q)-1][9] 1.2158 0.9755## d.o.f=2#### Weighted ARCH LM Tests## ------------------------------------## Statistic Shape Scale P-Value## ARCH Lag[3] 0.003795 0.500 2.000 0.9509## ARCH Lag[5] 0.558535 1.440 1.667 0.8662## ARCH Lag[7] 0.860015 2.315 1.543 0.9352#### Nyblom stability test## ------------------------------------## Joint Statistic: 11.858## Individual Statistics:## mu 0.04612## omega 1.68786## alpha1 0.21234## beta1 0.13921#### Asymptotic Critical Values (10% 5% 1%) ## Joint Statistic: 1.07 1.24 1.6 ## Individual Statistic: 0.35 0.47 0.75 #### Sign Bias Test## ------------------------------------## t-value prob sig## Sign Bias 0.50882 0.6109## Negative Sign Bias 0.02904 0.9768## Positive Sign Bias 0.95615 0.3391## Joint Effect 3.23974 0.3561###### Adjusted Pearson Goodness-of-Fit Test: ## ------------------------------------## group statistic p-value(g-1)## 1 20 224.4 4.516e-37## 2 30 414.9 7.179e-70## 3 40 530.3 1.819e-87## 4 50 669.5 7.785e-110###### Elapsed time : 0.5700321yield=data[,4]testfun(yield)#### Jarque Bera Test#### data: yield## X-squared = 265.7, df = 2, p-value < 2.2e-16###### Box-Ljung test#### data: yield## X-squared = 12.253, df = 1, p-value = 0.0004644## Warning in adf.test(yield): p-value smaller than printed p-value #### Augmented Dickey-Fuller Test#### data: yield## Dickey-Fuller = -13.616, Lag order = 13, p-value = 0.01## alternative hypothesis: stationary## Warning in pp.test(yield): p-value smaller than printed p-value#### Phillips-Perron Unit Root Test#### data: yield## Dickey-Fuller Z(alpha) = -2410.8, Truncation lag parameter = 9, ## p-value = 0.01## alternative hypothesis: stationary###### ARCH LM-test; Null hypothesis: no ARCH effects#### data: yield## Chi-squared = 146.83, df = 12, p-value < 2.2e-16#### *---------------------------------*## * GARCH Model Fit *## *---------------------------------*#### Conditional Variance Dynamics## -----------------------------------## GARCH Model : sGARCH(1,1)## Mean Model : ARFIMA(0,0,0)## Distribution : norm#### Optimal Parameters## ------------------------------------## Estimate Std. Error t value Pr(>|t|)## mu -0.000575 0.000300 -1.9151 0.055481## omega 0.000005 0.000002 2.4374 0.014795## alpha1 0.047347 0.004708 10.0571 0.000000## beta1 0.934878 0.006087 153.5890 0.000000#### Robust Standard Errors:## Estimate Std. Error t value Pr(>|t|)## mu -0.000575 0.000334 -1.72194 0.085081## omega 0.000005 0.000006 0.89757 0.369417## alpha1 0.047347 0.012544 3.77441 0.000160## beta1 0.934878 0.010121 92.36867 0.000000#### LogLikelihood : 7255.899#### Information Criteria## ------------------------------------#### Akaike -5.4078## Bayes -5.3990## Shibata -5.4078## Hannan-Quinn -5.4046#### Weighted Ljung-Box Test on Standardized Residuals## ------------------------------------## statistic p-value## Lag[1] 10.02 0.001547## Lag[2*(p+q)+(p+q)-1][2] 10.18 0.001714## Lag[4*(p+q)+(p+q)-1][5] 11.34 0.004141## d.o.f=0## H0 : No serial correlation#### Weighted Ljung-Box Test on Standardized Squared Residuals ## ------------------------------------## statistic p-value## Lag[1] 3.952 0.04683## Lag[2*(p+q)+(p+q)-1][5] 5.939 0.09297## Lag[4*(p+q)+(p+q)-1][9] 6.833 0.21355## d.o.f=2#### Weighted ARCH LM Tests## ------------------------------------## Statistic Shape Scale P-Value## ARCH Lag[3] 2.321 0.500 2.000 0.1276## ARCH Lag[5] 3.069 1.440 1.667 0.2799## ARCH Lag[7] 3.210 2.315 1.543 0.4749#### Nyblom stability test## ------------------------------------## Joint Statistic: 1.5527## Individual Statistics:## mu 1.0709## omega 0.1964## alpha1 0.1429## beta1 0.1513#### Asymptotic Critical Values (10% 5% 1%)## Joint Statistic: 1.07 1.24 1.6## Individual Statistic: 0.35 0.47 0.75#### Sign Bias Test## ------------------------------------## t-value prob sig## Sign Bias 1.2545 0.2098## Negative Sign Bias 0.9650 0.3346## Positive Sign Bias 0.6906 0.4899## Joint Effect 4.1751 0.2432###### Adjusted Pearson Goodness-of-Fit Test:## ------------------------------------## group statistic p-value(g-1)## 1 20 30.35 0.04752## 2 30 33.06 0.27549## 3 40 42.38 0.32717## 4 50 53.61 0.30205###### Elapsed time : 0.742043# 3.利用得到的四组边缘分布,测度两两之间的相关性后,选择合适的Copula函数,建立四元Copula函数,并检验拟合程度;y2<-datahead(y2)## Pound Jpan Usd Eur## 1 -0.016689192 -0.006422036 -0.004161304 0.001084608## 2 0.000000000 0.005993930 0.000000000 -0.034008741## 3 0.000000000 -0.006850273 0.008322209 -0.013969242## 4 0.012517495 0.010275005 0.000000000 -0.001120290## 5 0.012513888 -0.007277877 0.020798548 -0.011676878## 6 -0.008342191 0.002140679 0.012474350 0.007202157# 2D distribution of yields:cdf<-pobs(y2)# 测度两两之间的相关性plot(cdf)# 建立四元Copula函数t.cop<-tCopula(dim=4, param=0.5, df=2, df.fixed=TRUE)fit<-fitCopula(data=cdf, copula=t.cop)# 检验拟合程度summary(fit)## $method## [1] "maximum pseudo-likelihood"#### $loglik## [1] -839.8142#### $convergence## [1] 0#### $coefficients## Estimate Std. Error z value Pr(>|z|)## rho.1 0.004473614 0.009902117 0.4517837 0.6514248#### attr(,"class")## [1] "summary.fitCopula"# 4.利用四元Copula函数,用Monte Carlo方法进行VaR的估计;# Monte-Carlo & VaR:N0<-10000points_cop<-rCopula(copula=fit@copula, N0)plot(points_cop, cex=0.2)y=data[,1]y1=data[,2]y_cop<-quantile(y, points_cop)y1_cop<-quantile(y1, points_cop)gammas <-seq(0,1,0.001)var <-var(y)*gammas^2 +var(y1)*(1-gammas)^2 +2*cov(y, y1)*gammas*(1-gammas)optimal <-(var(y1) -cov(y, y1))/(var(y) +var(y1) -2*cov(y, y1)) optimal## [1] 0.1595596prt_y2<-optimal*y_cop+(1-optimal)*y1_cop#VaR的估计quantile(prt_y2, 0.05)## 5%## -0.01896628# 要求:完整的代码,每一步检验和建模的图表和结果以及分析;# # Getting stock prices for Boeing & Airbus and calculating yields: ## getSymbols("BA", from="2014-01-01", to="2016-10-19")# p<-as.numeric(Ad(BA))# l<-length(p)# y<-p[2:l]/p[1:(l-1)]-1# getSymbols("AIR",from="2014-01-01", to="2016-10-19")# p1<-as.numeric(Ad(AIR))# y1<-diff(p1)/head(p1,-1)# # Creating an optimal portfolio:## gammas <- seq(0,1,0.001)# var <- var(y)*gammas^2 + var(y1)*(1-gammas)^2 + 2*cov(y, y1)*gammas* (1-gammas)# optimal <- (var(y1) - cov(y, y1))/(var(y) + var(y1) - 2*cov(y, y1)) # optimal# prt<-optimal*y+(1-optimal)*y1# y2<-cbind(y,y1)# head(y2)# # 2D distribution of yields:## cdf<-pobs(y2)# plot(cdf)# # Initializing copula:## t.cop<-tCopula(dim=2, param=0.5, df=2, df.fixed=TRUE)# fit<-fitCopula(data=cdf, copula=t.cop)# summary(fit)# # Monte-Carlo & VaR:## N0<-10000# points_cop<-rCopula(copula=fit@copula, N0)# plot(points_cop, cex=0.2)# y_cop<-quantile(y, points_cop)# y1_cop<-quantile(y1, points_cop)# prt_y2<-optimal*y_cop+(1-optimal)*y1_cop# quantile(prt_y2, 0.05)。
r语言数据分析案例R语言是一种强大的统计分析工具,广泛应用于数据科学领域。
它提供了丰富的包和函数,使得数据分析变得简单高效。
以下是一个使用R语言进行数据分析的案例,展示了从数据导入、处理、分析到可视化的完整流程。
首先,我们需要安装并加载必要的R包。
在这个案例中,我们将使用`dplyr`进行数据处理,`ggplot2`用于数据可视化,以及`readr`来读取数据文件。
```rinstall.packages("dplyr")install.packages("ggplot2")install.packages("readr")library(dplyr)library(ggplot2)library(readr)```接下来,我们导入数据。
假设我们有一个名为`data.csv`的CSV文件,其中包含了我们分析所需的数据。
```rdata <- read_csv("data.csv")```数据导入后,我们通常需要进行数据清洗和预处理。
这可能包括处理缺失值、异常值、数据类型转换等。
```rdata <- data %>%filter(!is.na(value)) %>% # 移除含有缺失值的行mutate(value = as.numeric(value)) # 确保value列为数值类型```在数据清洗后,我们可能需要进行一些探索性数据分析(EDA),以了解数据的分布和特征。
```rsummary(data)```接下来,我们可以进行更深入的数据分析。
例如,如果我们想要分析某个变量与另一个变量之间的关系,我们可以使用相关性分析。
```rcor(data$variable1, data$variable2)```为了可视化数据,我们可以使用`ggplot2`包来创建图表。
例如,如果我们想要绘制一个散点图来展示两个变量之间的关系,我们可以这样做:```rggplot(data, aes(x = variable1, y = variable2)) +geom_point() +theme_minimal()```此外,我们还可以创建更复杂的图表,如箱线图、直方图等,以进一步探索数据。
R语⾔时变向量⾃回归(TV-VAR)模型分析时间序列和可视化原⽂链接:/?p=22350在⼼理学研究中,个⼈主体的模型正变得越来越流⾏。
原因之⼀是很难从⼈之间的数据推断出个⼈过程。
另⼀个原因是,由于移动设备⽆处不在,从个⼈获得的时间序列变得越来越多。
所谓的个⼈模型建模的主要⽬标是挖掘潜在的内部⼼理现象变化。
考虑到这⼀⽬标,许多研究⼈员已经着⼿分析个⼈时间序列中的多变量依赖关系。
对于这种依赖关系,最简单和最流⾏的模型是⼀阶向量⾃回归(VAR)模型,其中当前时间点的每个变量都是由前⼀个时间点的所有变量(包括其本⾝)预测的(线性函数)。
标准VAR模型的⼀个关键假设是其参数不随时间变化。
然⽽,⼈们往往对这种随时间的变化感兴趣。
例如,⼈们可能对参数的变化与其他变量的关系感兴趣,例如⼀个⼈的环境变化。
可能是⼀份新的⼯作,季节,或全球⼤流⾏病的影响。
在探索性设计中,⼈们可以研究某些⼲预措施(如药物治疗或治疗)对症状之间的相互作⽤有哪些影响。
在这篇博⽂中,我⾮常简要地介绍了如何⽤核平滑法估计时变VAR模型。
这种⽅法是基于参数可以随时间平滑变化的假设,这意味着参数不能从⼀个值 "跳 "到另⼀个值。
然后,我重点介绍如何估计和分析这种类型的时变VAR模型。
通过核平滑估计时变模型核平滑法的核⼼思想如下。
我们在整个时间序列的持续时间内选择间隔相等的时间点,然后在每个时间点估计 "局部 "模型。
所有的局部模型加在⼀起就构成了时变模型。
对于 "局部 "模型,我们的意思是,这些模型主要是基于接近研究时间点的时间点。
这是通过在参数估计过程中对观测值进⾏相应的加权来实现的。
这个想法在下图中对⼀个数据集进⾏了说明。
这⾥我们只说明在t=3时对局部模型的估计。
我们在左边的⾯板上看到这个时间序列的10个时间点。
红⾊的⼀列w\_t\_e=3表⽰我们在t=3时估计局部模型可能使⽤的⼀组权重:接近t=3的时间点的数据得到最⾼的权重,⽽更远的时间点得到越来越⼩的权重。
向量自回归var模型案例附数据向量自回归VAR模型案例附数据向量自回归(Vector Autoregression, VAR)模型是一种广泛应用于多元时间序列分析的建模方法。
这种模型将每个内生变量作为其自身滞后值和所有其他内生变量的滞后值的线性函数进行描述。
VAR模型具有简单、灵活和易于推广的优点,因此在宏观经济分析、金融数据分析等领域得到了广泛应用。
以下是一个基于R语言对VAR模型进行估计和预测的案例示例,数据来自于加拿大的一些宏观经济变量:数据说明:变量包括加拿大的实际GDP(rgdp)、GDP平减指数(deflator)、实际进口量(im)和实际出口量(ex),时间范围为1981年第1季度到2001年第2季度,共81个观测值。
```r# 导入数据canadata <- read.table("canadata.txt", header = TRUE)str(canadata)# 对数据取对数并构造时间序列对象y <- log(canadata[, 2:5])z <- ts(y, start = c(1981, 1), frequency = 4)# 估计VAR模型library(vars)var.model <- VAR(z, p = 2, type = "const")summary(var.model)# 预测fcast <- predict(var.model, n.ahead = 8)# 数据可视化plot(fcast$fcst[, 1], type = 'l', ylim = range(z[, 1], fcast$fcst[, 1]), xlab = "Time", ylab = "rgdp", main = "Canadian GDP Forecast")lines(z[, 1], col = "blue")```。
R语言中混合线性模型的实现以及参数解析一、概述混合线性模型(Mixed Linear Model, MLM)指的是在一个线性模型中,将随机变量(random variable)和拟合变量(fitted variable)施加简化概率模型的方法,是推理统计技术的一种重要方法。
它将观察数据分成固定相关部分(直接反映来自不随环境变化的潜在变量)和随机相关部分(显示数据之间的随机错误关系)。
R 语言中实现混合线性模型的函数有lme(和lmer(。
二、R中实现混合线性模型1、lme(函数lme(函数的基本格式为:lme(formula, data, random = NULL, method = c("ML", "REML"),correlation = NULL, weights, na.action, control)其中formula是模型建模的公式,data是数据,random是自变量的随机公式,method 指定最大似然估计或者 REML 估计, correlation 指定空间自变量Y共享的相关性结构, weights 是权重, na.action 指定缺失值的处理方法, control 是控制参数。
2、lmer(函数lmer(函数的基本格式为:lmer(formula, data, REML = FALSE, control = lmerControl(, na.action = na.fail,weights = NULL, start=NULL,correlation=NULL,verbose=FALSE)其中formula是模型建模的公式,data是数据,REML是最大似然法或者REML估计,control是控制参数,na.action 是缺失值的处理方法,weights是权重,start是初始值,correlation是空间自变量Y共享的相关性结构,verbose是输出更多的信息。
咨询QQ:3025393450
有问题百度搜索“”就可以了
欢迎登陆官网:/datablog
R语言时变参数VAR随机模型数据分析报告
来源:大数据部落
摘要
时变参数VAR随机模型是一种新的计量经济学方法,用于在具有随机波动率和相关状态转移的时变参数向量自回归(VAR)的大模型空间中执行随机模型规范搜索(SMSS)。
这是由于过度拟合的关注以及这些高度参数化模型中通常不精确的推断所致。
对于每个VAR系数,这种新方法自动确定它是恒定的还是随时间变化的。
此外,它可用于将不受限制的时变参数VAR收缩到固定VAR因此,提供了一种简单的方法(概率地)在时变参数模型中施加平稳性。
我们通过局部应用证明了该方法的有效性,我们在非常低的利率期间调查结构性冲击对政府支出对美国税收和国内生产总值(GDP)的动态影响。
引言
向量自回归(VAR)广泛用于宏观经济学中的建模和预测。
特别是,VAR已被用于理解宏观经济变量之间的相互作用,通常通过估计脉冲响应函数来表征各种结构性冲击对关键经济变量的影响。
状态空间模型
咨询QQ:3025393450
有问题百度搜索“”就可以了
欢迎登陆官网:/datablog
允许时间序列模型中的时变系数的流行方法是通过状态空间规范。
具体而言,假设ÿ 是Ñ 对因变量的观测的×1向量,X 是Ñ ×上解释变量的观测矩阵,β是状
态的×1向量。
然后可以将通用状态空间模型编写为(1)
(2)
这种一般的状态空间框架涵盖了宏观经济学中广泛使用的各种时变参数(TVP)回归模型,并已成为分析宏观经济数据的标准框架。
然而,最近的研究引起了人们的担忧,过度拟合可能是这些高度参数化模型的问题。
此外,这些高维模型通常给出不精确的估计,使任何形式的推理更加困难。
受这些问题的影响,研究人员可能希望有一个更简约的规范,以减少过度参数化的潜在问题,同时保持状态空间框架的灵活性,允许系数的时间变化。
例如,人们可能希望拥有一个具有时不变系数的默认模型,但是当有强有力的时间变化证据时,这些系数中的每一个都可以转换为随时间变化的。
通过这种方式,人们可以保持简洁的规范,从而实现更精确的估计,同时最大限度地降低模型错误指定的风险。
结果
我们实施了Gibbs采样器,以获得VECM模型中参数的25,000个后抽取。
BKK采用类似的“标准化”系列的方法,只影响先前的规范,只要在后验计算中适当考虑转换即可。
或者,可以使用原始系列并使用训练样本来指定先验,虽然这在操作上更加复杂。
值得注意的是,我们在SMSS和TVP-SVECM规范中应用了相同的标准化。
我们的算法实现也使用了三个广义Gibbs步骤算法的稳定性,通过跟踪所有抽样变量的低效率因素和复制模拟运行多次验证。
SMSS产生的IRF与对角线转换协方差的比较,具有完全转换协方差的SMSS和基准TVP-SVECM在2000Q1的支出减少1%之后的20个季度。
咨询QQ:3025393450
有问题百度搜索“”就可以了
欢迎登陆官网:/datablog
2000年第一季度的税收(虚线)和支出(实线)对1%的支出冲击的中位数冲动响应。
结束语
时变VAR广泛用于通过估计脉冲响应函数来研究结构冲击对关键经济变量的动态影响。
然而,由于这些模型是高度参数化的,因此推断通常是不精确的,并且通常难以得出结论。
在本文中,我们提出了一种新方法,允许数据决定VAR中的参数是时变的还是时不变的,从而允许模型在系数的时间变化很小时自动切换
咨询QQ:3025393450
有问题百度搜索“”就可以了
欢迎登陆官网:/datablog
到更简约的规范。
通过在状态方程的方差之前引入Tobit,计算许多指标的任务被大大简化。
还有问题吗?请在下面留言!。