JAVA数据库基本操作增删改查(精)
- 格式:doc
- 大小:15.50 KB
- 文档页数:3

jparepository接口方法JpaRepository接口方法是Spring Data JPA提供的一种数据访问层的接口,它提供了一系列的方法用于对数据库进行基本的增删改查操作。
在本文中,我们将详细介绍JpaRepository接口的各种方法及其使用。
1. findAll()方法:该方法用于查询数据库中的所有数据,并返回一个包含所有数据的List集合。
它可以用于获取数据库中的所有记录。
2. findById()方法:该方法用于根据给定的ID查询数据库中的数据,并返回一个Optional类型的对象。
Optional是Java 8引入的一个容器对象,用于处理可能为空的值,通过该方法可以根据ID获取对应的数据。
3. save()方法:该方法用于保存或更新数据库中的数据。
当传入的实体对象的ID为空时,表示新增操作;当ID不为空时,表示更新操作。
该方法会根据ID的值自动判断是执行保存还是更新。
4. deleteById()方法:该方法用于根据给定的ID删除数据库中的数据。
它可以通过ID来删除指定的记录。
5. count()方法:该方法用于统计数据库中的数据数量。
它可以用于获取数据表中的总记录数。
6. existsById()方法:该方法用于判断给定的ID是否存在于数据库中。
它返回一个boolean类型的值,表示给定的ID是否存在。
7. findAll(Pageable pageable)方法:该方法用于分页查询数据库中的数据。
它接受一个Pageable对象作为参数,用于指定查询的页数、每页的数据量等信息。
通过该方法可以实现分页查询功能。
8. deleteAll()方法:该方法用于删除数据库中的所有数据。
它会删除整个数据表中的所有记录。
9. flush()方法:该方法用于立即将持久化上下文中的修改同步到数据库。
它可以用于强制将未保存的更改立即写入数据库。
10. findAll(Sort sort)方法:该方法用于根据给定的排序规则查询数据库中的数据。

jparepository查询方法JPQL(JPA Query Language)是Java Persistence API(JPA)中定义的查询语言,它是一种面向对象的查询语言,用于查询持久化实体对象。
在JPA中,可以使用JPQL来查询数据库中的数据。
JPQL提供了一种简单而强大的查询语法,可以通过面向对象的方式查询数据库。
JpaRepository是Spring Data JPA中的一个接口,它提供了一组通用的数据库操作方法,用于简化数据访问层的开发。
JpaRepository是一个泛型接口,根据实体类型自动生成增删改查的基本方法。
[jparepository查询方法]是指在继承JpaRepository接口的Repository 中,可以直接调用其定义的方法来完成数据库操作,而无需手动编写SQL 语句。
下面我们将一步一步来回答这个主题。
第一步:创建实体类和Repository接口首先,我们需要创建一个实体类,并使用@Entity注解标识该类是一个持久化实体。
同时,我们还需要创建一个接口,并继承JpaRepository接口。
java@Entitypublic class User {@Idprivate Long id;private String name;private Integer age;省略getter和setter方法}@Repositorypublic interface UserRepository extends JpaRepository<User, Long> {}在上面的代码中,我们创建了一个名为User的实体类,并标识为@Entity,表示该类是一个持久化实体。
接着,我们创建了一个名为UserRepository 的接口,并继承了JpaRepository接口,泛型参数分别为User和Long,表示该Repository用于操作User实体,User实体的主键类型为Long。

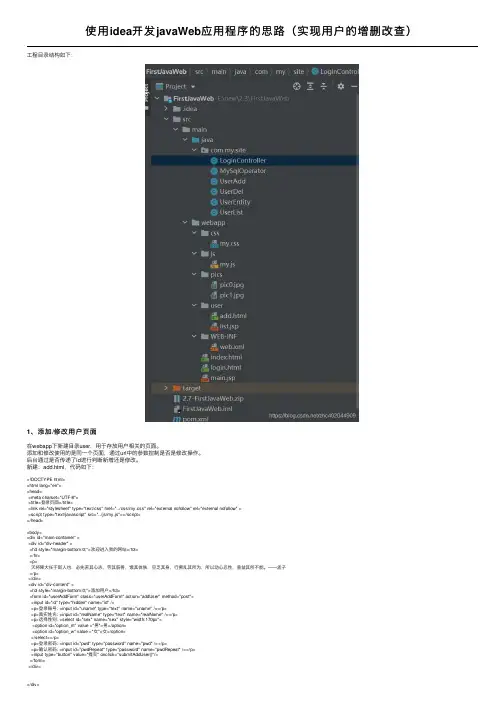
使⽤idea开发javaWeb应⽤程序的思路(实现⽤户的增删改查)⼯程⽬录结构如下:1、添加/修改⽤户页⾯在webapp下新建⽬录user,⽤于存放⽤户相关的页⾯。
添加和修改使⽤的是同⼀个页⾯,通过url中的参数控制是否是修改操作。
后台通过是否传递了id进⾏判断新增还是修改。
新建:add.html,代码如下:<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>登录页⾯</title><link rel="stylesheet" type="text/css" href="../css/my.css" rel="external nofollow" rel="external nofollow" ><script type="text/javascript" src="../js/my.js"></script></head><body><div id="main-container" ><div id="div-header" ><h3 style="margin-bottom:0;">欢迎进⼊我的⽹站</h3></hr><p>天将降⼤任于斯⼈也,必先苦其⼼志,劳其筋⾻,饿其体肤,空乏其⾝,⾏拂乱其所为,所以动⼼忍性,曾益其所不能。
——孟⼦</p></div><div id="div-content" ><h3 style="margin-bottom:0;">添加⽤户</h3><form id="userAddForm" class="userAddForm" action="addUser" method="post"><input id="id" type="hidden" name="id" /><p>登录账号: <input id="uname" type="text" name="uname" /></p><p>真实姓名: <input id="realName" type="text" name="realName" /></p><p>选择性别: <select id="sex" name="sex" style="width:170px"><option id="option_m" value ="男">男</option><option id="option_w" value ="⼥">⼥</option></select></p><p>登录密码: <input id="pwd" type="password" name="pwd" /></p><p>确认密码: <input id="pwdRepeat" type="password" name="pwdRepeat" /></p><input type="button" value="提交" onclick="submitAddUser()"/></form></div></div><script type="text/javascript">//检查输⼊是否为⾮空function submitAddUser(){var uname = document.getElementById("uname").value;//获取输⼊的⽤户名的值var pwd = document.getElementById("pwd").value;//获取输⼊的密码值var pwdRepeat = document.getElementById("pwdRepeat").value;//获取输⼊确认密码值var realName = document.getElementById("realName").value;//获取输⼊的姓名值var sex = document.getElementById("sex").value;//获取输⼊的性别值if(uname == "" || pwd == "" || pwdRepeat == "" || realName == "" || sex == "" ){alert("请将信息填写完整后再提交。

hutool db使用x一、介绍Hutool DB是一个轻量级的Java数据库操作库,它提供了一种简单易用的方式来操作数据库,包括CRUD(增删改查)、查询和分页等操作,支持任意JAVA数据库,统一对接JDBC API。
二、特性1、直接使用JDBC API,没有任何侵入性;2、简单快速,只需要几行代码即可实现简单的CRUD操作;3、完善的API,有更多的特性,如强大的SQL构造器、多数据源支持、自定义查询结果集映射规则、自定义数据源配置、ORM等功能;4、全程安全,提供安全警示提示,防止SQL注入;5、可以有效处理大数据量的情况,能够自动进行分页处理等。
三、安装Hutool DB支持maven和gradle安装,详细步骤如下:(1)在maven项目中,在pom.xml文件中添加Hutool DB的依赖:<dependency><groupId>cn.hutool</groupId><artifactId>hutool-db</artifactId><version>4.4.2</version></dependency>(2)在gradle项目中,在build.gradle文件中添加Hutool DB 的依赖:compile group: 'cn.hutool', na'hutool-db',version:'4.4.2'四、使用教程(1)创建数据库连接:// 创建数据库连接DruidPlugin plugin = newDruidPlugin('jdbc:mysql://127.0.0.1/test', 'root', 'root'); // 启动数据库连接池plugin.start();// 获取数据库对象Database db = plugin.getDatabase();(2)插入数据:// 插入一条数据String sql = 'INSERT INTO user(name, age) VALUES(?, ?)'; int n = db.update(sql, '张三', 20);(3)查询数据:// 查询数据String sql = 'SELECT * FROM user';List<Entity> list = db.find(sql);(4)更新数据:// 更新数据String sql = 'UPDATE user SET age = ? WHERE name = ?'; int n = db.update(sql, 22, '张三');(5)删除数据:// 删除数据String sql = 'DELETE FROM user where name = ?';int n = db.update(sql, '张三');五、总结Hutool DB是一个轻量级的Java数据库操作库,它提供了简单易用的安全接口来操作数据库,支持CRUD、查询和分页等操作,完全可以替代传统JDBC操作。

Java中使用MyBatis Plus连接和操作MySQL数据库1. 简介近年来,Java语言以其跨平台特性和广泛的应用领域成为了全球最受欢迎的编程语言之一。
而MySQL作为一种强大的开源关系型数据库,也是Java开发者首选的数据库之一。
在Java中,我们可以使用MyBatis Plus来连接和操作MySQL数据库,提升开发效率和简化数据库操作。
2. MyBatis Plus简介MyBatis Plus是基于MyBatis的一款增强工具,旨在简化和提升MyBatis的使用体验。
它提供了一系列强大的功能,如代码生成器、分页插件、性能分析插件等,使得开发者能够更加便捷地开发和维护数据库相关的应用程序。
3. 连接MySQL数据库在使用MyBatis Plus连接MySQL数据库之前,我们需要先在项目中引入相关的依赖。
可以通过Maven或Gradle等构建工具来管理项目的依赖。
在pom.xml或build.gradle文件中添加相应的依赖项,然后进行构建操作。
在Java代码中,我们需要创建一个数据源并配置相关的数据库连接信息。
可以使用MySQL提供的JDBC驱动程序来管理数据库连接。
在MyBatis Plus中,我们可以使用com.mysql.cj.jdbc.Driver作为驱动类,指定数据库的URL、用户名和密码来建立连接。
4. 创建实体类在进行数据库操作之前,我们需要定义与数据库表对应的实体类。
在Java中,我们可以使用POJO(Plain Old Java Object)来表示实体类。
POJO是一种普通的Java对象,不继承任何特定的父类或实现任何特定的接口。
在MyBatis Plus中,实体类需要使用@Table注解来指定对应的数据库表名,使用@Column注解来指定字段名,以及指定主键等属性。
通过在实体类中定义与表对应的字段和属性,我们可以通过MyBatis Plus来进行数据库的增删改查操作。

mongorepository 增删改查MongoRepository 是 Spring Data MongoDB 提供的一个接口,用于简化 MongoDB 数据库的操作。
它提供了常见的 CRUD 操作,即创建(Create)、读取(Read)、更新(Update)和删除(Delete)。
下面是使用 MongoRepository 进行基本的增删改查操作的简单示例。
创建实体类首先,定义一个与 MongoDB 集合对应的实体类。
假设我们有一个名为 User 的实体类:import org.springframework.data.annotation.Id;importorg.springframework.data.mongodb.core.mapping.Document;@Document(collection = "users")public class User {@Idprivate String id;private String username;private String email;// Getters and setters}创建 Repository 接口接下来,创建一个继承自 MongoRepository 的接口,指定实体类类型和 ID 类型。
在这个例子中,我们使用 User 类作为实体类,ID 类型为 String。
importorg.springframework.data.mongodb.repository.MongoRepository;public interface UserRepository extends MongoRepository<User, String> {// 可以在这里定义一些自定义的查询方法}使用 Repository 进行增删改查操作在其他组件中,你可以注入 UserRepository 并使用它进行数据库操作。

mybatis抽取基类BaseMapper增删改查的实现⽬录准备⼯作:1:数据库表2:准备实体类步骤1:编写⼯具类Tools:作⽤:⽤于驼峰和数据库字段的转换步骤2:⾃定义两个注解,分别⽤于类字段的排除和字义主键步骤3:⾃定义动态sql⽣成类BaseSqlProvider<T>步骤4:编写BaseMapper基类接⼝举例:⽬前项⽬当中使⽤mapper.xml⽂件⽅式对数据库进⾏操作,但是每个⾥边都有增/删/改/查,为了⽅便开发,把这些公共的代码提取出来,不⽤当做基类,不⽤每个Mapper⽂件都写了准备⼯作:1:数据库表CREATE TABLE `t_permission` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '权限ID',`type` int(11) NOT NULL COMMENT '权限类型',`name` varchar(255) NOT NULL COMMENT '权限名称',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=24 DEFAULT CHARSET=utf8 COMMENT='权限表';2:准备实体类public class TPermissionEntity {@PrimaryKey //下⾯步骤2中⾃定义注解private Integer id;//权限IDprivate Integer type;//权限类型private String name;//权限名称//省略了get,set⽅法....}步骤1:编写⼯具类Tools:作⽤:⽤于驼峰和数据库字段的转换因为类的名称⽤的是驼峰命名,所以这⾥需要转换⼀下import java.util.regex.Matcher;import java.util.regex.Pattern;/** 驼峰名称和下划线名称的相互转换*/public class Tool {private static Pattern linePattern = pile("_(\\w)");/** 下划线转驼峰 */public static String lineToHump(String str) {str = str.toLowerCase();Matcher matcher = linePattern.matcher(str);StringBuffer sb = new StringBuffer();while (matcher.find()) {matcher.appendReplacement(sb, matcher.group(1).toUpperCase());}matcher.appendTail(sb);return sb.toString();}private static Pattern humpPattern = pile("[A-Z]");/** 驼峰转下划线,效率⽐上⾯⾼ */public static String humpToLine(String str) {Matcher matcher = humpPattern.matcher(str);StringBuffer sb = new StringBuffer();while (matcher.find()) {matcher.appendReplacement(sb, "_" + matcher.group(0).toLowerCase());}matcher.appendTail(sb);return sb.toString();}}步骤2:⾃定义两个注解,分别⽤于类字段的排除和字义主键@Target({ElementType.FIELD})@Retention(RetentionPolicy.RUNTIME)public @interface Exclude {}@Target({ElementType.FIELD})@Retention(RetentionPolicy.RUNTIME)public @interface PrimaryKey {String value() default "";}步骤3:⾃定义动态sql⽣成类BaseSqlProvider<T>作⽤:根据传⼊的对象动态获取表名和字段名⽣成动态的sql语句,再执⾏@Insert,@Select,@update,@Delete是直接配置SQL语句,⽽@InsertProvider,@UpdateProvider,@SelectProvider,@DeleteProvider则是通过SQL⼯⼚类及对应的⽅法⽣产SQL语句import ng.reflect.Field;import java.util.ArrayList;import java.util.List;import org.apache.ibatis.annotations.Options;import org.apache.ibatis.jdbc.SQL;import mon.utils.Tool;public class BaseSqlProvider<T> {@Optionspublic String add(T bean) {SQL sql = new SQL();Class clazz = bean.getClass();String tableName = clazz.getSimpleName();String realTableName = Tool.humpToLine(tableName).replaceAll("_entity", "").substring(1);sql.INSERT_INTO(realTableName);List<Field> fields = getFields(clazz);for (Field field : fields) {field.setAccessible(true);String column = field.getName();System.out.println("column:" + Tool.humpToLine(column));sql.VALUES(Tool.humpToLine(column), String.format("#{" + column + ",jdbcType=VARCHAR}"));}return sql.toString();}public String delete(T bean) {SQL sql = new SQL();Class clazz = bean.getClass();String tableName = clazz.getSimpleName();String realTableName = Tool.humpToLine(tableName).replaceAll("_entity", "").substring(1); sql.DELETE_FROM(realTableName);List<Field> primaryKeyField = getPrimarkKeyFields(clazz);if (!primaryKeyField.isEmpty()) {for (Field pkField : primaryKeyField) {pkField.setAccessible(true);sql.WHERE(pkField.getName() + "=" + String.format("#{" + pkField.getName() + "}"));}} else {sql.WHERE(" 1= 2");throw new RuntimeException("对象中未包含PrimaryKey属性");}return sql.toString();}private List<Field> getPrimarkKeyFields(Class clazz) {List<Field> primaryKeyField = new ArrayList<>();List<Field> fields = getFields(clazz);for (Field field : fields) {field.setAccessible(true);PrimaryKey key = field.getAnnotation(PrimaryKey.class);if (key != null) {primaryKeyField.add(field);}}return primaryKeyField;}private List<Field> getFields(Class clazz) {List<Field> fieldList = new ArrayList<>();Field[] fields = clazz.getDeclaredFields();for (Field field : fields) {field.setAccessible(true);Exclude key = field.getAnnotation(Exclude.class);if (key == null) {fieldList.add(field);}}return fieldList;}public String get(T bean) {SQL sql = new SQL();Class clazz = bean.getClass();String tableName = clazz.getSimpleName();String realTableName = Tool.humpToLine(tableName).replaceAll("_entity", "").substring(1); sql.SELECT("*").FROM(realTableName);List<Field> primaryKeyField = getPrimarkKeyFields(clazz);if (!primaryKeyField.isEmpty()) {for (Field pkField : primaryKeyField) {pkField.setAccessible(true);sql.WHERE(pkField.getName() + "=" + String.format("#{" + pkField.getName() + "}"));}} else {sql.WHERE(" 1= 2");throw new RuntimeException("对象中未包含PrimaryKey属性");}System.out.println("getSql:"+sql.toString());return sql.toString();}public String update(T bean) {SQL sql = new SQL();Class clazz = bean.getClass();String tableName = clazz.getSimpleName();String realTableName = Tool.humpToLine(tableName).replaceAll("_entity", "").substring(1);sql.UPDATE(realTableName);List<Field> fields = getFields(clazz);for (Field field : fields) {field.setAccessible(true);String column = field.getName();if (column.equals("id")) {continue;}System.out.println(Tool.humpToLine(column));sql.SET(Tool.humpToLine(column) + "=" + String.format("#{" + column + ",jdbcType=VARCHAR}")); }List<Field> primaryKeyField = getPrimarkKeyFields(clazz);if (!primaryKeyField.isEmpty()) {for (Field pkField : primaryKeyField) {pkField.setAccessible(true);sql.WHERE(pkField.getName() + "=" + String.format("#{" + pkField.getName() + "}"));}} else {sql.WHERE(" 1= 2");throw new RuntimeException("对象中未包含PrimaryKey属性");}System.out.println("updateSql:"+sql.toString());return sql.toString();}}步骤4:编写BaseMapper基类接⼝public interface BaseMapper<T> {//新增⼀条数据@InsertProvider(method = "add",type=BaseSqlProvider.class)@Options(useGeneratedKeys=true)public int add(T bean);//根据主键删除⼀条数据@DeleteProvider(method = "delete",type=BaseSqlProvider.class)public int delete(T bean);//根据主键获取⼀条数据@SelectProvider(method = "get",type=BaseSqlProvider.class)public T get(T bean);//修改⼀条数据@UpdateProvider(method = "update",type=BaseSqlProvider.class)public int update(T bean);}说明:@InsertProvider注解中的type指明⾃定义的SQL⼯⼚类,method是⼯⼚类⾥对应的⽅法,⽅法返回的是对⽅的sql语句到这⾥基类以及它的配置就完成了,接下来,可以使⽤了举例:编写⼀个TPermissionMapper接⼝,实现BaseMapper类,并传⼊⼀个泛型参数,此时这个TPermissionMapper接⼝已经具备了,BaseMapper中基本的增/删/改/查功能.同时TPermissionMapper还可以再写⾃⼰独有的⽅法和mapper.xml⽂件对功能进⾏扩展public interface TPermissionMapper extends BaseMapper<TPermissionEntity>{//List<TPermissionEntity> queryByPage();}在controller当中的应⽤:@Controllerpublic class LoginController {@Autowiredprivate TPermissionMapper tPermissionMapper;//新增@ResponseBody@RequestMapping(value = "/add")public Integer add() {TPermissionEntity permissionEntiry = new TPermissionEntity();permissionEntiry.setName("test");permissionEntiry.setType(3);Integer num = tPermissionMapper.add(permissionEntiry);return num;}//修改@ResponseBody@RequestMapping(value = "/update")public Integer update() {TPermissionEntity permissionEntiry = new TPermissionEntity();permissionEntiry.setId(23);permissionEntiry.setName("test");permissionEntiry.setType(3);Integer num = tPermissionMapper.update(permissionEntiry);return num;}//查询@ResponseBody@RequestMapping(value = "/query")public TPermissionEntity query() {TPermissionEntity tPermissionEntity = new TPermissionEntity();tPermissionEntity.setId(23);tPermissionEntity= (TPermissionEntity) tPermissionMapper.get(tPermissionEntity);return tPermissionEntity;}//删除@ResponseBody@RequestMapping(value = "/delete")public Integer delete() {TPermissionEntity permissionEntiry = new TPermissionEntity();permissionEntiry.setId(22);Integer num = tPermissionMapper.delete(permissionEntiry);return num;}}到此这篇关于mybatis抽取基类BaseMapper增删改查的实现的⽂章就介绍到这了,更多相关mybatis BaseMapper增删改查内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。


tkmybatis 用法TKMyBatis 是基于 MyBatis 的增强工具,可以简化 MyBatis 的使用并提供一些便利的功能。
本文将介绍 TKMyBatis 的用法,帮助读者更好地理解和使用该工具。
一、TKMyBatis 简介TKMyBatis 是一个开源的 Java 持久层框架,它是 MyBatis 的增强版,提供了一系列的功能和工具,简化了 MyBatis 的配置和使用。
TKMyBatis 的主要特点如下:1. 简化增删改查操作:TKMyBatis 提供了一套通用的增删改查接口和实现类,可以大大简化开发者的编码工作。
2. 内置分页功能:TKMyBatis 封装了常用的分页功能,使得分页查询非常方便。
3. 自动生成代码:TKMyBatis 可以根据数据库表结构自动生成实体类、Mapper 接口、Mapper XML 文件等,减少手动编写代码的工作量。
4. 支持通用的数据库操作:TKMyBatis 支持的数据库种类较多,包括 MySQL、Oracle、SQL Server 等。
二、TKMyBatis 的安装与配置要使用 TKMyBatis,首先需要将 TKMyBatis 的 jar 包导入项目中。
可以通过 Maven 或手动下载 jar 包并添加到项目中。
在项目的配置文件中,需要配置 MyBatis 和 TKMyBatis 的相关信息。
这包括数据库连接信息、Mapper 接口、Mapper XML 文件的路径等。
配置完成后,就可以开始使用 TKMyBatis 进行数据库操作了。
三、TKMyBatis 的基本用法1. 通用增删改查操作TKMyBatis 提供了一套通用的增删改查接口和实现类。
通过继承通用 Mapper 类,可以使用 TKMyBatis 提供的一系列简化的数据库操作方法。
例如,可以使用 `insertSelective` 方法插入一条记录,使用`updateByPrimaryKeySelective` 方法根据主键更新记录,使用`selectByPrimaryKey` 方法根据主键查询记录,使用`deleteByPrimaryKey` 方法根据主键删除记录。

jpa repository 自定义删除方法JPA(Java持久化API)Repository是Spring Data JPA提供的一种用于简化数据库操作的工具。
它提供了一组内置的方法,用于对实体进行增删改查操作。
然而,在某些情况下,我们可能需要根据特定的需求自定义删除方法。
要实现自定义删除方法,我们需要按照以下步骤进行操作:1. 创建一个继承自JpaRepository的自定义Repository接口。
例如,我们可以创建一个名为"CustomRepository"的接口。
2. 在自定义Repository接口中定义我们想要的删除方法。
可以使用标准的JPA查询语句或者使用@Query注解来指定自定义的SQL查询。
3. 在实体类中使用注解声明我们创建的自定义Repository接口。
例如,使用@Repository注解指定实体类与自定义Repository接口的对应关系。
下面是一个简单的示例来说明如何自定义删除方法:1. 创建自定义Repository接口:```javapublic interface CustomRepository extends JpaRepository<YourEntity, Long> {@Modifying@Query("DELETE FROM YourEntity WHERE condition = :condition")void deleteByCustomCondition(@Param("condition") String condition);}```2. 在实体类中使用注解声明自定义Repository接口:```java@Entity@Table(name = "your_entity_table")@Repositorypublic class YourEntity {// 实体类的属性和方法}```使用以上方法,我们可以自定义一个删除方法来根据特定条件来删除数据库中的实体。
增删改查简单-概述说明以及解释1.引言1.1 概述在现代信息时代,数据的管理和处理变得越来越重要。
无论是个人用户还是企业组织,都需要对数据进行增加、删除、修改以及查询等操作。
这些操作合称为增删改查(CRUD)操作,是数据管理中最基本、最常见的操作。
增删改查操作是数据管理的核心,它们在各个领域都得到广泛应用。
在个人数据管理方面,人们通过增加数据来记录生活中的重要事件、保存联系人信息等;删除数据可以清理不再需要的内容、释放存储空间;修改数据使其与当前状态保持一致;查询数据能够快速找到所需的信息。
而在企业层面,增删改查操作更是不可或缺的。
企业需要通过增加数据来记录各项业务活动,包括客户信息、订单记录、销售数据等,为后续的决策和分析提供基础;删除数据可以清理过时的、无效的或违规的内容;修改数据可以纠正错误或更新信息;查询数据则是企业分析和决策的重要依据。
在进行增删改查操作时,不仅需要掌握相应的方法和技术,还需要注意一些注意事项。
例如,在增加数据时,应确保数据的完整性和准确性,避免重复或错误的录入;在删除数据时,要谨慎操作,避免误删重要数据;在修改数据时,需要考虑影响范围和相关性,并确保相应的审批和权限控制;在查询数据时,要充分利用相关的搜索、过滤和排序功能,以提高查询效率。
评估增删改查操作的效果也是很重要的。
通过对增删改查操作的效果进行评估,可以不断改进和优化数据管理的流程和方法,提高工作效率和数据质量。
综上所述,增删改查操作是数据管理中不可或缺的基本操作,无论是个人用户还是企业组织,都需要掌握和运用这些操作技巧。
正确地进行增删改查操作,能够更好地管理和利用数据,提高工作效率和决策能力。
1.2 文章结构文章结构部分的内容如下:2. 正文2.1 增2.1.1 增加数据的重要性2.1.2 增加数据的方法2.1.3 增加数据的注意事项2.1.4 增加数据的效果评估2.2 删2.2.1 删除数据的重要性2.2.2 删除数据的方法2.2.3 删除数据的注意事项2.2.4 删除数据的效果评估2.3 改2.3.1 修改数据的重要性2.3.2 修改数据的方法2.3.3 修改数据的注意事项2.3.4 修改数据的效果评估2.4 查2.4.1 查询数据的重要性2.4.2 查询数据的方法2.4.3 查询数据的注意事项2.4.4 查询数据的效果评估以上是本文的文章结构。
一、Vue框架介绍Vue.js是一款流行的前端JavaScript框架,它能够帮助开发者构建用户界面。
Vue提出了一种全新的前端开发理念,它采用了组件化的思想,使得前端开发更加模块化和灵活。
通过Vue,开发者可以轻松地管理页面状态、数据绑定、事件监听等功能。
在Vue的生态系统中,也有很多周边库和插件,用来扩展Vue的功能。
二、SQLite3数据库介绍SQLite3是一款轻量级的关系型数据库管理系统,它被广泛应用在移动设备、嵌入式设备以及小型全球信息站的开发中。
相比于传统的关系型数据库系统,SQLite3的特点在于无需配置、零配置、无服务器和无需安装。
它支持多种编程语言调用,包括但不限于C、C++、Java、Python等。
SQLite3的数据存储在一个单一的文件中,数据库操作简单、高效。
三、在Vue中使用SQLite3的方法在现代的Web应用程序中,也经常需要使用数据库来存储和管理数据。
在Vue中使用SQLite3可以借助一些第三方插件或者进行简单封装。
在Vue的生态系统中,有一些与SQLite3相关的插件可以简化与SQLite3的交互过程。
四、Vue中SQLite3的增删改查写法1. 增加数据在Vue中与SQLite3数据库进行数据插入的操作,可以通过以下步骤:(1)创建数据库连接:在Vue的methods中创建数据库连接,引入SQLite3的模块;(2)执行SQL语句:通过执行SQL语句来插入数据,首先编写插入数据的SQL语句,然后通过数据库连接执行该语句;(3)数据处理:根据执行SQL语句的返回结果进行数据处理,例如显示插入成功的提示信息或者刷新页面显示最新的数据。
2. 删除数据在Vue中与SQLite3数据库进行数据删除的操作,可以通过以下步骤:(1)创建数据库连接:同样在Vue的methods中创建数据库连接,并引入SQLite3的模块;(2)执行SQL语句:编写删除数据的SQL语句,通过数据库连接执行该语句;(3)数据处理:根据执行SQL语句的返回结果进行数据处理,例如显示删除成功的提示信息或者刷新页面显示最新的数据。
java中ResultSet遍历数据操作1.查找数据库中表的列名<pre name="code" class="html">String sql = "select *from tblmetadatainfo";ResultSet rs = MySqlHelper.executeQuery(sql, null);String str="";try {ResultSetMetaData rsmd = rs.getMetaData();for (int i = 1; i < rsmd.getColumnCount(); i++) {str+=rsmd.getColumnName(i)+",";}str=str.substring(0, str.length()-1);} catch (SQLException e) {// TODO Auto-generated catch blocke.printStackTrace();}2.查找数据库中表中每条记录的列值for(int i=1;i<rs.getMetaData().getColumnCount();i++){str+=rs.getString(i)+",";}补充知识:Java:使⽤ResultSet.next()执⾏含有rownum的SQL语句速度缓慢在使⽤Oracle数据库进⾏分页查询时,经常会⽤到如下SQL:select tm.* from (select rownum rm, t.* xmlrecord from testtable t) tm where tm.rm > ? and tm.rm <= ?使⽤的java代码如下:int startIdx = 0;int endIdx = 10000;String sql = "select tm.* from (select rownum rm, t.* xmlrecord from testtable t) tm where tm.rm > ? and tm.rm <= ?";try (Connection conn = dataSource.getConnection(); PreparedStatement ps = conn.prepareStatement(sql);) {ps.setInt(1, startIdx);ps.setInt(2, endIdx);try (ResultSet rs = ps.executeQuery();) {while (rs.next()) {String id = rs.getString(2);System.out.println("id="+id);}}}当使⽤以上代码时,会发现当取完最后⼀条记录后,再执⾏rs.next()时,本来希望返回false后跳出循环,但rs.next()会执⾏⾮常长的时间。
Java SQL语句拼接一、概述SQL(Structured Query Language)是一种用于管理关系数据库系统(RDBMS)的标准化语言,而Java作为一种通用的编程语言,在与数据库进行交互时,需要通过拼接SQL语句来实现数据的增删改查操作。
SQL语句拼接是指将字符串和变量进行组合,构建完整的SQL语句。
正确的SQL语句拼接可以提高代码的可读性、维护性和安全性,同时还可以实现动态的数据库操作。
本文将详细探讨Java中SQL语句拼接的方法、注意事项以及一些常见的例子和最佳实践。
二、拼接方法在Java中,有多种方法可以进行SQL语句拼接,下面介绍其中几种常见的方法。
1. 使用字符串连接符(+)最简单的方法是使用字符串连接符(+)来将字符串和变量进行拼接。
例如:String name = "Alice";int age = 25;String sql = "SELECT * FROM users WHERE name = '" + name + "' AND age = " + ag e;上述代码中,使用字符串连接符将name和age拼接进SQL语句中。
但是,这种方法存在一些问题,例如SQL注入漏洞、字符串引号的处理等,会引起潜在的安全风险和错误。
2. 使用String.format()Java中的String类提供了format()方法,可以使用类似于C语言中的printf()函数的格式化字符串来拼接SQL语句。
例如:String name = "Alice";int age = 25;String sql = String.format("SELECT * FROM users WHERE name = '%s' AND age = %d ", name, age);上述代码中,使用%s和%d分别表示字符串和整数的占位符,通过在format()方法中传入相应的参数,可以将它们替换为具体的值。
利用crudrepository接口实现功能的总结利用CrudRepository接口实现功能的总结[引言]在现代软件开发中,数据处理是一个极为重要的环节。
为了简化开发过程,许多开发人员选择使用现成的框架来处理与数据库的交互。
Spring框架是一个广泛使用的Java框架,其中有一个非常有用的接口叫做CrudRepository,能够大大简化数据库操作的过程。
本文将介绍CrudRepository接口的功能和使用方法,并重点讨论如何利用CrudRepository接口实现常见的功能。
[正文]1. CrudRepository接口概述CrudRepository接口是Spring框架中的一个核心接口,它提供了常见的增删改查(CRUD)功能。
CrudRepository接口是Spring Data JPA模块的一部分,实现了对数据库的基本操作。
开发人员只需定义一个继承CrudRepository接口的接口,Spring框架会自动生成实现类并提供相应的方法。
2. CrudRepository接口的常用方法CrudRepository接口提供了常用的增删改查方法,其中包括:- save方法:用于保存或更新实体对象。
- delete方法:用于根据实体对象或ID删除记录。
- findAll方法:用于获取所有记录。
- findById方法:用于根据ID获取记录。
- count方法:用于统计记录个数。
3. 利用CrudRepository接口实现创建记录功能创建记录是数据库操作中的基本功能之一。
首先,我们需要定义一个继承CrudRepository接口的接口,并指定实体类类型以及ID类型。
接着,我们在这个接口中添加一个继承自CrudRepository的方法:public interface UserRepository extends CrudRepository<User, Long> { }在这个方法中,我们可以调用CrudRepository的save方法来保存实体对象:User user = new User();user.setName("张三");user.setAge(20);user.setEmail("zhangsan@example");userRepository.save(user);通过调用save方法,我们可以将一个新的用户对象保存到数据库中。
JAVA 数据库基本操作, 增删改查
package mypack; JAVA 数据库基本操作, 增删改查
import java.sql.Connection;
import java.sql.ResultSet;
import java.util.ArrayList;
public class DbOper {//查询多行记录public ArrayList select({Connection conn =null;
ResultSet rs =null;
try {import java.sql.PreparedStatement; import java.sql.SQLException; PreparedStatement pstmt =null; ArrayList al =new ArrayList(;
conn =DbConn.getConn(;pstmt =conn.prepareStatement(“select *from titles ”; rs =pstmt.executeQuery(;while (rs.next({Titles t =new
Titles(;t.setTitleid(rs.getString(1;t.setTitle(rs.getString(2;al.add(t;}}catch (SQLExceptione {
e.printStackTrace(;}finally {try {//TODO 自动生成catch 块if (rs!=null rs.close(;if (pstmt!=nullpstmt.close(;if (conn!=nullconn.close(;}catch (SQLExceptione {
e.printStackTrace(;}}//TODO 自动生成catch 块
return al; }//查询单个对象public Titles selectOne(Stringtitleid{Connection conn =null;
ResultSet rs =null;
try {PreparedStatement pstmt =null; Titles t =new Titles(;
conn =DbConn.getConn(;
pstmt.setString(1,titleid;
while (rs.next({pstmt =conn.pre pareStatement(“select *from titles where title_id=?”; rs =pstmt.executeQuery(;
t.setTitleid(rs.getString(1;t.setTitle(rs.getString(2;
}}catch (SQLExceptione {
e.printStackTrace(;}finally {try {//TODO 自动生成catch 块if (rs!=null rs.close(;if (pstmt!=nullpstmt.close(;if (conn!=nullconn.close(;}catch (SQLExceptione {
e.printStackTrace(;}}
}//TODO 自动生成catch 块return t;
//增加记录public boolean insert(Titlest{Connection conn =null;
boolean b =false; try {PreparedStatement pstmt=null;conn
=DbConn.getConn(;pstmt =conn.prep areStatement(“insert into titles(title_id,titlevalues (?,?”; pstmt.setString(1,t.getTitleid(;pstmt.setString(2,t.getTitle(;
int n =pstmt.executeUpdate(;if(n==1b=true;
}catch (SQLExceptione {
e.printStackTrace(;}finally{try {//TODO 自动生成catch 块
if(pstmt!=nullpstmt.close(;if(conn!=nullconn.close(;}catch (SQLExceptione {
e.printStackTrace(;}}
}//TODO 自动生成catch 块return b;
//删除记录public boolean delete(Stringtitleid{Connection conn =null;
boolean b =false; try {PreparedStatement pstmt=null;conn =DbConn.getConn(;
pstmt.setString(1,titleid;
if(n==1b=true;pstmt =conn.prepareStatement(“delete from titles where title_id=?”; int n =pstmt.executeUpdate(;
}catch (SQLExceptione {
e.printStackTrace(;}finally{try {//TODO 自动生成catch 块
if(pstmt!=nullpstmt.close(;if(conn!=nullconn.close(;}catch (SQLExceptione {
e.printStackTrace(;}}//TODO 自动生成catch 块return b;
}//修改表public boolean update(Titlest{Connection conn =null;
boolean b PreparedStatement pstmt=null;
try {=false;
conn =DbConn.getConn(;pstmt =conn.prepareStatement(“update titles set
title=?where title_id=?”; pstmt.setString(1,t.getTitle(;pstmt.setString(2,t.getTitleid(;int n =pstmt.executeUpdate(;if(n==1b=true;
}catch (SQLExceptione {
e.printStackTrace(;}finally{try {//TODO 自动生成catch 块
if(pstmt!=nullpstmt.close(;if(conn!=nullconn.close(;}catch (SQLExceptione {
e.printStackTrace(;}}
}}//TODO 自动生成catch 块return b;。