(完整word版)数学建模四大模型总结,推荐文档
- 格式:doc
- 大小:174.01 KB
- 文档页数:8

数学建模数学建模是利用数学方法解决实际问题的一种实践。
即通过抽象、简化、假设、引进变量等处理过程后,将实际问题用数学方式表达,建立起数学模型,然后运用先进的数学方法及计算机技术进行求解。
简单地说:就是系统的某种特征的本质的数学表达式(或是用数学术语对部分现实世界的描述),即用数学式子(如函数、图形、代数方程、微分方程、积分方程、差分方程等)来描述(表述、模拟)所研究的客观对象或系统在某一方面的存在规律。
数学建模的几个过程模型准备:了解问题的实际背景,明确其实际意义,掌握对象的各种信息。
用数学语言来描述问题。
模型假设:根据实际对象的特征和建模的目的,对问题进行必要的简化,并用精确的语言提出一些恰当的假设。
模型建立:在假设的基础上,利用适当的数学工具来刻划各变量之间的数学关系,建立相应的数学结构。
(尽量用简单的数学工具)模型求解:利用获取的数据资料,对模型的所有参数做出计算(估计)。
模型分析:对所得的结果进行数学上的分析。
模型检验:将模型分析结果与实际情形进行比较,以此来验证模型的准确性、合理性和适用性。
如果模型与实际较吻合,则要对计算结果给出其实际含义,并进行解释。
如果模型与实际吻合较差,则应该修改假设,再次重复建模过程。
模型应用:应用方式因问题的性质和建模的目的而异。
模型的求解方法1. 微分方程方法微分方程的一般理论微分方程的平衡点及稳定性战争的预测与评估问题 SARS传播问题2.差分方程方法常系数线性差分方程差分方程的平衡点及其稳定性连续模型的差分方法最优捕鱼问题3. 插值与拟合方法一般插值方法样条函数插值方法B样条函数插值方法最小二乘拟合方法黄河小浪底调水调沙问题4. 层次分析方法层次分析的一般方法一类选优排序问题合理分配住房问题5.概率统计方法概率分布与数字特征样本与统计量参数估计法方差分析法相关分析法足球门的危险区域问题最优评卷问题6. 回归分析方法一元线性回归方法多元线性回归方法回归模型的选择方法回归模型的正交化设计方法多重共线性与有偏估计方法沼气的生成问题7. 综合评价方法综合评价的基本概念综合评价的一般方法动态加权综合评价方法长江水质的综合评价问题8. 线性规划方法线性规划的模型线性规划解的概念与理论线性规划的求解方法线性规划的对偶问题线性规划的灵敏度分析南水北调水指标的分配问题9. 整数规划方法整数规划的模型整数规划的分枝定界法整数规划的割平面法0-1整数规划指派问题的匈牙利方法整数规划的uNCO解法招聘公务员问题10. 非线性规划方法非线性规划的基本概念无约束非线性规划的解法带有约束的非线性规划带约束非线性规划的解法奶制品的加工计划问题11. 动态规划方法动态规划的基本概念和基本方程动态规划的求解方法动态规划方法的应用选拔队员与组队问题12. 排队论方法排队论的基本概念到达时间的间隔分布和服务时间的分布单服务台的排队模型多服务台的排队模型排队系统的最优化问题校园网的设计和调节收费问题13. 对策论方法对策论的基本概念矩阵对策的概念和理论矩阵对策的解法双矩阵对策玫瑰有约问题14. 随机性决策分析方法随机性决策问题的基本概念效用函数理论常用效用函数的构造彩票中的数学问题15. 多目标决策分析方法多目标决策分析的基本概念多目标决策问题的非劣解多目标群决策问题的解股份制公司的综合投资问题16. 灰色系统分析方法灰色系统分析的基本概念灰色模型GM 灰色预测灰色决策SARS疫情对某些经济指标影响问题一:线性规划(一):线性规划的相关概念线性规划是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法.在经济管理、交通运输、工农业生产等经济活动中,提高经济效果是人们不可缺少的要求,而提高经济效果一般通过两种途径:一是技术方面的改进,例如改善生产工艺,使用新设备和新型原材料.二是生产组织与计划的改进,即合理安排人力物力资源.线性规划所研究的是:在一定条件下,合理安排人力物力等资源,使经济效果达到最好.一般地,求线性目标函数在线性约束条件下的最大值或最小值的问题,统称为线性规划问题。

初中数学模型归纳大全初中数学模型归纳大全近年来,初中数学的课程安排越来越注重将数学的思维方法和现实生活相结合,让学生在数学学习中掌握丰富的实际应用技能。
其中一个重要的教学方式就是数学建模。
初中数学模型归纳大全,决是一篇非常有用的参考资料。
这篇文章将会对初中数学中的各种数学模型进行归纳介绍,供初中生及学科教师们参考学习。
模型一:生活中的数学模型物质交换、能量转化、社会相互作用、周期变化等生活中的各种现象都可以用数学模型来描述和研究,例如:1.物质平衡模型:糖果换水果的比例;汽油和尾气的关系。
2.周期变化模型:季节变换图;一天的时间变换图。
3.变化速率模型:打车计价器;电费计算表。
模型二:图形化数学模型在初中数学中,一些图形化的数学模型可以帮助学生更好地理解和掌握一些抽象的数学概念。
以下是几种常见的图形化数学模型:1.函数图像模型:介绍函数图像的概念,如y=x^2、y=|x|等等。
2.平面几何模型:为学生介绍平面几何中的各种概念,如直线、角度和三角形等等。
3.三维几何模型:三维几何不仅可以帮助学生更好地理解三维空间的概念,同时还可以培养学生的空间想象力和建模能力。
模型三:奥数模型奥数一直以来都是中国教育中的一大特色,在初中数学中也有一些与奥数相关的数学模型,例如:1.排列组合模型:介绍排列组合的概念,如A(4,2)、C(4,2)等等。
2.数学归纳模型:帮助学生更好地掌握数学归纳的思路,如猴子吃桃、阶乘问题等等。
3.数形结合模型:利用具体的图形问题结合数学解法,例如数轴上的问题、目测问题等等。
模型四:工程数学模型在工程领域中,数学模型的运用是不可或缺的。
初中数学中也有一些与工程相关的数学模型,例如:1.自然增长模型:介绍自然增长的概念,如人口增长、金融投资等等。
2.传热模型:帮助学生了解传热的基本原理,如热力学等等。
3.循环流动模型:帮助学生了解循环流动的规律和应用,例如水循环、风循环等等。
总结初中数学模型的归纳总结可以为学生提供更多的实践题材,培养学生发掘问题并解决问题的能力,更重要的是,可以加深学生对数学知识的理解和应用。


2常用的建模方法
(I)初等数学法。
主要用于一些静态、线性、确定性的模型。
例如,席位分配问题,学生成绩的比较,一些简单的传染病静态模型。
(2)数据分析法。
从大量的观测数据中,利用统计方法建立数学模型,常见的有:回归分析法,时序分析法。
(3)仿真和其他方法。
主要有计算机模拟(是一种统计估计方法,等效于抽样试验,可以离散系统模拟和连续系统模拟),因子试验法(主要是在系统上做局部试验,根据试验结果进行不
断分析修改,求得所需模
型结构),人工现实法(基于对系统的了解和所要达到的目标,人为地组成一个系统)。
(4)层次分析法。
主要用于有关经济计划和管理、能源决策和分配、行为科学、军事科学、军事指挥、运输、农业、教育、人才、医疗、环境等领
域,以便进行决策、评价、分析、预测等。
该方法关键的一步是建立层次结
构模型。

常用几何模型总结
几何模型是数学和物理学中用来描述特定现象或系统的抽象数学模型。
根据不同的应用领域,有许多不同的几何模型。
以下是一些常用的几何模型:
欧几里得几何模型:描述二维平面和三维空间中的点和线段的性质和关系。
拓扑几何模型:研究拓扑空间中元素之间的关系,包括连通性、紧致性、同胚等概念。
解析几何模型:通过解析式或函数来描述几何对象的位置、形状和大小。
微分几何模型:研究曲线、曲面等几何对象的微分性质,包括曲率、挠率等。
线性代数模型:描述向量空间和矩阵运算的性质和关系,广泛应用于物理学、工程学等领域。
极坐标模型:通过极坐标系来描述平面上的点和线段的性质和关系。
参数方程模型:通过参数方程来描述几何对象的形状和位置,常用于计算机图形学等领域。
代数几何模型:结合代数和几何的思想,研究代数方程组在几何空间中的解和性质。
概率几何模型:通过概率论和几何学的结合,描述随机现象的分布和性质。
微分流形模型:将流形和微分结构结合起来,描述复杂的几何对象和现象。
以上是一些常用的几何模型,每种模型都有其特定的应用场景和优势。
在实际应用中,需要根据具体问题选择合适的几何模型来进行描述和分析。

数学建模模型和技巧数学建模是指利用数学方法来描述和解决实际问题的过程。
在进行数学建模时,需要掌握一些模型和技巧,以使模型更加准确、可行和有效。
以下是一些常用的数学建模模型和技巧:1.基于方程的模型:这是数学建模中最基本的模型形式,通过建立适当的方程来描述问题。
例如,通过建立动力学方程来描述物体的运动,或者建立微分方程来描绘人口增长模型。
2.统计模型:统计模型通过收集和分析数据,来描述和预测随机现象。
常见的统计模型包括回归分析、时间序列分析和概率模型等。
通过统计模型,可以分析数据之间的相关性和影响因素,从而做出合理的预测和决策。
3.优化模型:优化模型的目标是找到最优解,以满足给定的约束条件。
这种模型常见的问题包括最短路径问题、最大流问题和线性规划等。
通过优化模型,可以帮助决策者做出最佳的决策,以最大化效益或最小化成本。
4.离散模型:离散模型是用来描述非连续、离散的问题。
例如,图论可以用来描述网络结构和路径优化问题,排队论可以用来分析排队系统的性能。
离散模型在实际问题中起着重要的作用,特别是在计算机科学和网络科学领域。
5.系统动力学模型:系统动力学模型是一种用来描述动态系统行为的模型。
它利用微分方程和差分方程来描述因果关系和变化规律,通过模拟和预测系统的行为。
这种模型在复杂系统建模和决策支持中得到广泛应用,比如气候变化、交通流量和经济发展等领域。
在进行数学建模时,还需要掌握一些技巧:1.简化模型:在建立数学模型时,通常需要简化问题的复杂性,以便进行分析和求解。
可以通过做出适当的假设、采用近似方法和合理的简化等方式来简化模型。
这样可以降低模型的复杂度,提高求解的可行性和效率。
2.参数估计:在实际建模中,往往需要对一些参数进行估计。
这可以通过收集实验数据、观察数据或依靠领域专家的知识来进行。
参数估计的准确性直接影响模型的有效性和预测的可靠性。
3.模型验证:建立好模型后,需要对模型进行验证,验证模型的有效性和准确性。

数学建模四大模型总结1优化模型1.1 数学规划模型线性规划、整数线性规划、非线性规划、多目标规划、动态规划。
1.2 微分方程组模型阻滞增长模型、SARS传播模型。
1.3 图论与网络优化问题最短路径问题、网络最大流问题、最小费用最大流问题、最小生成树问题(MST)、旅行商问题(TSP)、图的着色问题。
1.4 概率模型决策模型、随机存储模型、随机人口模型、报童问题、Markov链模型。
1.5 组合优化经典问题l 多维背包问题(MKP)背包问题:个物品,对物品,体积为,背包容量为。
如何将尽可能多的物品装入背包。
多维背包问题:个物品,对物品,价值为,体积为,背包容量为。
如何选取物品装入背包,是背包中物品的总价值最大。
多维背包问题在实际中的应用有:资源分配、货物装载和存储分配等问题。
该问题属于难问题。
l 二维指派问题(QAP)工作指派问题:个工作可以由个工人分别完成。
工人完成工作的时间为。
如何安排使总工作时间最小。
二维指派问题(常以机器布局问题为例):台机器要布置在个地方,机器与之间的物流量为,位置与之间的距离为,如何布置使费用最小。
二维指派问题在实际中的应用有:校园建筑物的布局、医院科室的安排、成组技术中加工中心的组成问题等。
l 旅行商问题(TSP)旅行商问题:有个城市,城市与之间的距离为,找一条经过个城市的巡回(每个城市经过且只经过一次,最后回到出发点),使得总路程最小。
l 车辆路径问题(VRP)车辆路径问题(也称车辆计划):已知个客户的位置坐标和货物需求,在可供使用车辆数量及运载能力条件的约束下,每辆车都从起点出发,完成若干客户点的运送任务后再回到起点,要求以最少的车辆数、最小的车辆总行程完成货物的派送任务。
TSP问题是VRP问题的特例。
l 车间作业调度问题(JSP)车间调度问题:存在个工作和台机器,每个工作由一系列操作组成,操作的执行次序遵循严格的串行顺序,在特定的时间每个操作需要一台特定的机器完成,每台机器在同一时刻不能同时完成不同的工作,同一时刻同一工作的各个操作不能并发执行。

数学建模中常见的十大模型集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#数学建模常用的十大算法==转(2011-07-24 16:13:14)1. 蒙特卡罗算法。
该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。
2. 数据拟合、参数估计、插值等数据处理算法。
比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MATLAB 作为工具。
3. 线性规划、整数规划、多元规划、二次规划等规划类算法。
建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。
4. 图论算法。
这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。
5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。
这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。
6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。
这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。
7. 网格算法和穷举法。
两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8. 一些连续数据离散化方法。
很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
9. 数值分析算法。
如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。
10. 图象处理算法。
赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。
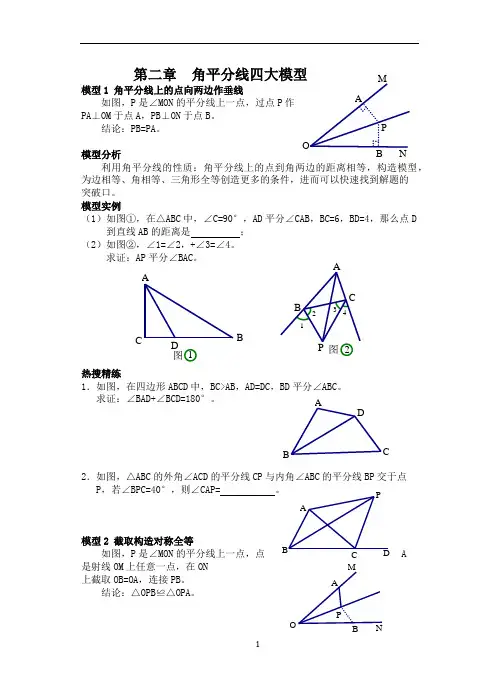
N MOA B P 2图4321A CP B D AB C图1A B D C AB D CPP ONM BA 第二章 角平分线四大模型模型1 角平分线上的点向两边作垂线如图,P 是∠MON 的平分线上一点,过点P 作PA ⊥OM 于点A ,PB ⊥ON 于点B 。
结论:PB=PA 。
模型分析利用角平分线的性质:角平分线上的点到角两边的距离相等,构造模型,为边相等、角相等、三角形全等创造更多的条件,进而可以快速找到解题的突破口。
模型实例(1)如图①,在△ABC 中,∠C=90°,AD 平分∠CAB ,BC=6,BD=4,那么点D到直线AB 的距离是 ; (2)如图②,∠1=∠2,+∠3=∠4。
求证:AP 平分∠BAC 。
热搜精练1.如图,在四边形ABCD 中,BC>AB ,AD=DC ,BD 平分∠ABC 。
求证:∠BAD+∠BCD=180°。
2.如图,△ABC 的外角∠ACD 的平分线CP 与内角∠ABC 的平分线BP 交于点 P ,若∠BPC=40°,则∠CAP= 。
模型2 截取构造对称全等如图,P 是∠MON 的平分线上一点,点A 是射线OM 上任意一点,在ON 上截取OB=OA ,连接PB 。
结论:△OPB ≌△OPA 。
图2DP AB C D C 1图P B A ABC DA BC DE DC B AP ONM B A 模型分析利用角平分线图形的对称性,在角的两边构造对称全等三角形,可以得到对应边、对应角相等。
利用对称性把一些线段或角进行转移,这是经常使用的一种解题技巧。
模型实例(1)如图①所示,在△ABC 中,AD 是△ABC 的外角平分线,P 是AD 上异于点A 的任意一点,试比较PB+PC 与AB+AC 的大小,并说明理由;(2)如图②所示, AD 是△ABC 的内角平分线,其他条件不变,试比较 PC-PB 与AC-AB 的大小,并说明理由。

数学建模常用模型方法总结无约束优化线性规划连续优化非线性规划整数规划离散优化组合优化数学规划模型多目标规划目标规划动态规划从其他角度分类网络规划多层规划等…运筹学模型(优化模型)图论模型存储论模型排队论模型博弈论模型可靠性理论模型等…运筹学应用重点:①市场销售②生产计划③库存管理④运输问题⑤财政和会计⑥人事管理⑦设备维修、更新和可靠度、项目选择和评价⑧工程的最佳化设计⑨计算器和讯息系统⑩城市管理优化模型四要素:①目标函数②决策变量③约束条件④求解方法(MATLAB--通用软件LINGO--专业软件)聚类分析、主成分分析因子分析多元分析模型判别分析典型相关性分析对应分析多维标度法概率论与数理统计模型假设检验模型相关分析回归分析方差分析贝叶斯统计模型时间序列分析模型决策树逻辑回归传染病模型马尔萨斯人口预测模型微分方程模型人口预测控制模型经济增长模型Logistic 人口预测模型战争模型等等。
灰色预测模型回归分析预测模型预测分析模型差分方程模型马尔可夫预测模型时间序列模型插值拟合模型神经网络模型系统动力学模型(SD)模糊综合评判法模型数据包络分析综合评价与决策方法灰色关联度主成分分析秩和比综合评价法理想解读法等旅行商(TSP)问题模型背包问题模型车辆路径问题模型物流中心选址问题模型经典NP问题模型路径规划问题模型着色图问题模型多目标优化问题模型车间生产调度问题模型最优树问题模型二次分配问题模型模拟退火算法(SA)遗传算法(GA)智能算法蚁群算法(ACA)(启发式)常用算法模型神经网络算法蒙特卡罗算法元胞自动机算法穷举搜索算法小波分析算法确定性数学模型三类数学模型随机性数学模型模糊性数学模型。

数学建模方法总结数学建模方法总结(通用17篇)数学建模方法总结篇1这学期参加数学建模培训,使我感触良多:它所教给我们的不单是一些数学方面的知识,更多的其实是综合能力的培养、锻炼与提高。
它培养了我们全面、多角度考虑问题的能力,使我们的逻辑推理能力和量化分析能力得到很好的锻炼和提高。
它还让我了解了多种数学软件,以及运用数学软件对模型进行求解。
数学模型主要是将现实对象的信息加以翻译,归纳的产物。
通过对数学模型的假设、求解、验证,得到数学上的解答,再经过翻译回到现实对象,给出分析、决策的结果。
其实,数学建模对我们来说并不陌生,在我们的日常生活和工作中,经常会用到有关建模的概念。
例如,我们平时出远门,会考虑一下出行的路线,以达到既快速又经济的目的;一些厂长经理为了获得更大的利润,往往会策划出一个合理安排生产和销售的最优方案。
这些问题和建模都有着很大的联系。
而在学习数学建模训练以前,我们面对这些问题时,解决它的方法往往是一种习惯性的思维方式,只知道该这样做,却不很清楚为什么会这样做,现在,我们这种陈旧的思考方式己经在被数学建模训练中培养出的多角度、层次分明、从本质上区分问题的新颖多维的思考方式所替代。
这种凝聚了许多优秀方法为一体的思考方式一旦被你把握,它就转化成了你自身的素质,不仅在你以后的学习工作中继续发挥作用,也为你的成长道路印下了闪亮的一页。
数学建模所要解决的问题决不是单一学科问题,它除了要求我们有扎实的数学知识外,还需要我们不停地去学习和查阅资料,除了我们要学习许多数学分支问题外,还要了解工厂生产、经济投资、保险事业等方面的知识,这些知识决不是任何专业中都能涉猎得到的。
它能极大地拓宽和丰富我们的内涵,让我们感到了知识的重要性,也领悟到了“学习是不断发现真理的过程”这句话的真谛所在,这些知识必将为我们将来的学习工作打下坚实的基础。
从现在我们的学习来看,我们都是直接受益者。
就拿我此次学习数学建模后写论文。
数学建模模型常用的四大模型及对应算法原理总结四大模型对应算法原理及案例使用教程:一、优化模型线性规划线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,在线性回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
案例实操非线性规划如果目标函数或者约束条件中至少有一个是非线性函数时的最优化问题叫非线性规划问题,是求解目标函数或约束条件中有一个或几个非线性函数的最优化问题的方法。
建立非线性规划模型首先要选定适当的目标变量和决策变量,并建立起目标变量与决策变量之间的函数关系,即目标函数。
然后将各种限制条件加以抽象,得出决策变量应满足的一些等式或不等式,即约束条件。
整数规划整数规划分为两类:一类为纯整数规划,记为PIP,它要求问题中的全部变量都取整数;另一类是混合整数规划,记之为MIP,它的某些变量只能取整数,而其他变量则为连续变量。
整数规划的特殊情况是0-1规划,其变量只取0或者1。
多目标规划求解多目标规划的方法大体上有以下几种:一种是化多为少的方法,即把多目标化为比较容易求解的单目标,如主要目标法、线性加权法、理想点法等;另一种叫分层序列法,即把目标按其重要性给出一个序列,每次都在前一目标最优解集内求下一个目标最优解,直到求出共同的最优解。
目标规划目标规划是一种用来进行含有单目标和多目标的决策分析的数学规划方法,是线性规划的特殊类型。
目标规划的一般模型如下:设xj是目标规划的决策变量,共有m个约束条件是刚性约束,可能是等式约束,也可能是不等式约束。
设有l个柔性目标约束条件,其目标规划约束的偏差为d+, d-。
设有q个优先级别,分别为P1, P2, …, Pq。
在同一个优先级Pk中,有不同的权重,分别记为[插图], [插图](j=1,2, …, l)。
数学模型与数学建模《经济数学基础》是电大财经与管理类专科学生的一门必修课程,也是学习其它技术基础课和专业课的必要基础课程,无论学生和教师都非常重视这门课程的教学。
但是现在的经济数学教材,多数只注重理论和计算,对应用性不够重视,即使有个别的应用也是限于较少的几何方面以及经济方面的简单应用。
很多学生都有这样的认识:数学很重要,但很枯燥,学了半天除了知道能在几何等方面的应用外,不知道还能有什么用,但又不得不学。
学生学习数学的目的不明确、缺少自觉学习的动力。
归于一点,就是学生不知道学了数学有什么用。
在今后的学习和工作中数学到底有什么作用呢?学生很茫然,但数学又是非常重要的课程。
因此,很多学生都是怀着不得不学的态度来学习数学的,缺乏自觉学习的动力。
这就要求我们数学教师进行课程内容和教学方法的大胆改革,让学生明白数学除了在几何以及经济上应用以外,还有很多用处,可以说我们的生活中、工作中无时无刻的充满着数学,只是你没有认识它,不知道该怎样用它。
近20年来发展起来的数学建模正是为数学的应用性提供了展示的舞台,也为大学生们提供了一个很好的学习机会。
一、数学模型什么是数学模型呢?1、模型所谓模型是指为了某个特定目的将原型的某一部分信息简缩,提炼而成的原型替代物。
这里的原型是指人们在现实世界里关心、研究或者从事生产、管理的实际对象。
模型可以分为形象模型与抽象模型,前者包括直观模型(如机械模型,玩具等)和物理模型(如核爆炸反应模拟设备等),后者包括思维模型(如个人凭经验行事的思维模式及习惯等)和符号模型(如地图,电路图,化学分子结构式等)。
模型的特征:目的性、应用性、功能性、抽象性是一般模型所普遍具有的特征。
这里特别强调模型的目的性,模型的基本特征是由模型的目的决定的。
一个原型,为了不同的目的可以有多种不同的模型。
例如,为了制定大型企业的生产管理计划,模型就不必反映各生产装置的动态特性,但必须反映产品的产量、销售量和库存原料等变化情况。
最全:初中数学几何模型(附打印版)几何是初中数学中非常重要的内容,一般会在压轴题中进行考察,而掌握几何模型能够为考试节省不少时间,小编整理了常用的各大模型,一定要认真掌握哦~全等变换平移:平行等线段(平行四边形)对称:角平分线或垂直或半角旋转:相邻等线段绕公共顶点旋转对称全等模型说明:以角平分线为轴在角两边进行截长补短或者作边的垂线,形成对称全等。
两边进行边或者角的等量代换,产生联系。
垂直也可以做为轴进行对称全等。
对称半角模型说明:上图依次是45°、30°、22.5°、15°及有一个角是30°直角三角形的对称(翻折),翻折成正方形或者等腰直角三角形、等边三角形、对称全等。
旋转全等模型半角:有一个角含1/2角及相邻线段自旋转:有一对相邻等线段,需要构造旋转全等共旋转:有两对相邻等线段,直接寻找旋转全等中点旋转:倍长中点相关线段转换成旋转全等问题旋转半角模型说明:旋转半角的特征是相邻等线段所成角含一个二分之一角,通过旋转将另外两个和为二分之一的角拼接在一起,成对称全等。
自旋转模型构造方法:遇60度旋60度,造等边三角形遇90度旋90度,造等腰直角遇等腰旋顶点,造旋转全等遇中点旋180度,造中心对称共旋转模型说明:旋转中所成的全等三角形,第三边所成的角是一个经常考察的内容。
通过“8”字模型可以证明。
模型变形说明:模型变形主要是两个正多边形或者等腰三角形的夹角的变化,另外是等腰直角三角形与正方形的混用。
当遇到复杂图形找不到旋转全等时,先找两个正多边形或者等腰三角形的公共顶点,围绕公共顶点找到两组相邻等线段,分组组成三角形证全等。
中点旋转:说明:两个正方形、两个等腰直角三角形或者一个正方形一个等腰直角三角形及两个图形顶点连线的中点,证明另外两个顶点与中点所成图形为等腰直角三角形。
证明方法是倍长所要证等腰直角三角形的一直角边,转化成要证明的等腰直角三角形和已知的等腰直角三角形(或者正方形)公旋转顶点,通过证明旋转全等三角形证明倍长后的大三角形为等腰直角三角形从而得证。
数学建模中常见的十大模型文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-数学建模常用的十大算法==转(2011-07-24 16:13:14)1. 蒙特卡罗算法。
该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。
2. 数据拟合、参数估计、插值等数据处理算法。
比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MATLAB 作为工具。
3. 线性规划、整数规划、多元规划、二次规划等规划类算法。
建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。
4. 图论算法。
这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。
5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。
这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。
6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。
这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。
7. 网格算法和穷举法。
两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。
8. 一些连续数据离散化方法。
很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。
9. 数值分析算法。
如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。
10. 图象处理算法。
赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。
数学建模方法归类(很全很有用)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(数学建模方法归类(很全很有用))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为数学建模方法归类(很全很有用)的全部内容。
在数学建模中常用的方法:类比法、二分法、量纲分析法、差分法、变分法、图论法、层次分析法、数据拟合法、回归分析法、数学规划(线性规划,非线性规划,整数规划,动态规划,目标规划)、机理分析、排队方法、对策方法、决策方法、模糊评判方法、时间序列方法、灰色理论方法、现代优化算法(禁忌搜索算法,模拟退火算法,遗传算法,神经网络)。
用这些方法可以解下列一些模型:优化模型、微分方程模型、统计模型、概率模型、图论模型、决策模型。
拟合与插值方法(给出一批数据点,确定满足特定要求的曲线或者曲面,从而反映对象整体的变化趋势): matlab可以实现一元函数,包括多项式和非线性函数的拟合以及多元函数的拟合,即回归分析,从而确定函数; 同时也可以用matlab实现分段线性、多项式、样条以及多维插值.在优化方法中,决策变量、目标函数(尽量简单、光滑)、约束条件、求解方法是四个关键因素。
其中包括无约束规则(用fminserch、fminbnd实现)线性规则(用linprog实现)非线性规则、( 用fmincon实现)多目标规划(有目标加权、效用函数)动态规划(倒向和正向)整数规划。
回归分析:对具有相关关系的现象,根据其关系形态,选择一个合适的数学模型,用来近似地表示变量间的平均变化关系的一种统计方法 (一元线性回归、多元线性回归、非线性回归),回归分析在一组数据的基础上研究这样几个问题:建立因变量与自变量之间的回归模型(经验公式);对回归模型的可信度进行检验;判断每个自变量对因变量的影响是否显著;判断回归模型是否适合这组数据;利用回归模型对进行预报或控制。
四类基本模型1 优化模型1.1 数学规划模型线性规划、整数线性规划、非线性规划、多目标规划、动态规划。
1.2 微分方程组模型阻滞增长模型、SARS 传播模型。
1.3 图论与网络优化问题最短路径问题、网络最大流问题、最小费用最大流问题、最小生成树问题(MST)、旅行商问题(TSP)、图的着色问题。
1.4 概率模型决策模型、随机存储模型、随机人口模型、报童问题、Markov 链模型。
1.5 组合优化经典问题● 多维背包问题(MKP)背包问题:n 个物品,对物品i ,体积为i w ,背包容量为W 。
如何将尽可能多的物品装入背包。
多维背包问题:n 个物品,对物品i ,价值为i p ,体积为i w ,背包容量为W 。
如何选取物品装入背包,是背包中物品的总价值最大。
多维背包问题在实际中的应用有:资源分配、货物装载和存储分配等问题。
该问题属于NP 难问题。
● 二维指派问题(QAP)工作指派问题:n 个工作可以由n 个工人分别完成。
工人i 完成工作j 的时间为ij d 。
如何安排使总工作时间最小。
二维指派问题(常以机器布局问题为例):n 台机器要布置在n 个地方,机器i 与k 之间的物流量为ik f ,位置j 与l 之间的距离为jl d ,如何布置使费用最小。
二维指派问题在实际中的应用有:校园建筑物的布局、医院科室的安排、成组技术中加工中心的组成问题等。
● 旅行商问题(TSP)旅行商问题:有n 个城市,城市i 与j 之间的距离为ij d ,找一条经过n 个城市的巡回(每个城市经过且只经过一次,最后回到出发点),使得总路程最小。
● 车辆路径问题(VRP)车辆路径问题(也称车辆计划):已知n 个客户的位置坐标和货物需求,在可供使用车辆数量及运载能力条件的约束下,每辆车都从起点出发,完成若干客户点的运送任务后再回到起点,要求以最少的车辆数、最小的车辆总行程完成货物的派送任务。
TSP 问题是VRP 问题的特例。
● 车间作业调度问题(JSP)车间调度问题:存在j 个工作和m 台机器,每个工作由一系列操作组成,操作的执行次序遵循严格的串行顺序,在特定的时间每个操作需要一台特定的机器完成,每台机器在同一时刻不能同时完成不同的工作,同一时刻同一工作的各个操作不能并发执行。
如何求得从第一个操作开始到最后一个操作结束的最小时间间隔。
2 分类模型判别分析是在已知研究对象分成若干类型并已经取得各种类型的一批已知样本的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分析。
聚类分析则是给定的一批样品,要划分的类型实现并不知道,正需要通过局内分析来给以确定类型的。
2.1 判别分析● 距离判别法基本思想:首先根据已知分类的数据,分别计算各类的重心即分组(类)的均值,判别准则是对任给的一次观测,若它与第i 类的重心距离最近,就认为它来自第i 类。
至于距离的测定,可以根据实际需要采用欧氏距离、马氏距离、明科夫距离等。
● Fisher 判别法基本思想:从两个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个判别函数或称判别式1pi i i y c x ==∑。
其中系数i c 确定的原则是使两组间的区别最大,而使每个组内部的离差最小。
对于一个新的样品,将它的p 个指标值代人判别式中求出 y 值,然后与判别临界值(或称分界点(后面给出)进行比较,就可以判别它应属于哪一个总体。
在两个总体先验概率相等的假设下,判别临界值一般取: (1)(2)12012n y n y y n n +=+最后,用F 统计量来检验判别效果,若F F α>则认为判别有效,否则判别无效。
以上描述的是两总体判别,至于多总体判别方法则需要加以扩展。
Fisher 判别法随着总体数的增加,建立的判别式也增加,因而计算比较复杂。
● Bayes 判别法基本思想:假定对所研究的对象有一定的认识,即假设k 个总体中,第i 个总体i G 的先验概率为i q ,概率密度函数为()i f x 。
利用bayes 公式计算观测样品X 来自第j 个总体的后验概率1()(/)()j j j k i i i q f x p G X q f x ==∑,当1,2,,(/)(/)max h j j kp G X p G X ==L 时,将样本X 判为总体h G 。
● 逐步判别法基本思想与逐步回归法类似,采用“有进有出”的算法,逐步引入变量,每次引入一个变量进入判别式,则同时考虑在较早引入判别式的某些作用不显著的变量剔除出去。
2.2 聚类分析聚类分析是一种无监督的分类方法,即不预先指定类别。
根据分类对象不同,聚类分析可以分为样本聚类(Q 型)和变量聚类(R 型)。
样本聚类是针对观测样本进行分类,而变量聚类则是试图找出彼此独立且有代表性的自变量,而又不丢失大部分信息。
变量聚类是一种降维的方法。
● 系统聚类法(分层聚类法)基本思想:开始将每个样本自成一类;然后求两两之间的距离,将距离最近的两类合成一类;如此重复,直到所有样本都合为一类为止。
适用范围:既适用于样本聚类,也适用于变量聚类。
并且距离分类准则和距离计算方法都有多种,可以依据具体情形选择。
● 快速聚类法(K-均值聚类法)基本思想:按照指定分类数目n ,选择n 个初始聚类中心(1,2,,)i Z i n =L ;计算每个观测量(样本)到各个聚类中心的距离,按照就近原则将其分别分到放入各类中;重新计算聚类中心,继续以上步骤;满足停止条件时(如最大迭代次数等)则停止。
使用范围:要求用户给定分类数目n ,只适用于样本聚类(Q 型),不适用于变量聚类(R 型)。
● 两步聚类法(智能聚类方法)基本思想:先进行预聚类,然后再进行正式聚类。
适用范围:属于智能聚类方法,用于解决海量数据或者具有复杂类别结构的聚类分析问题。
可以同时处理离散和连续变量,自动选择聚类数,可以处理超大样本量的数据。
● 模糊聚类分析与遗传算法、神经网络或灰色理论联合的聚类方法2.3 神经网络分类方法3评价模型3.1 层次分析法(AHP)基本思想:是定性与定量相结合的多准则决策、评价方法。
将决策的有关元素分解成目标层、准则层和方案层,并通过人们的判断对决策方案的优劣进行排序,在此基础上进行定性和定量分析。
它把人的思维过程层次化、数量化,并用数学为分析、决策、评价、预报和控制提供定量的依据。
基本步骤:构建层次结构模型;构建成对比较矩阵;层次单排序及一致性检验(即判断主观构建的成对比较矩阵在整体上是否有较好的一致性);层次总排序及一致性检验(检验层次之间的一致性)。
优点:它完全依靠主观评价做出方案的优劣排序,所需数据量少,决策花费的时间很短。
从整体上看,AHP在复杂决策过程中引入定量分析,并充分利用决策者在两两比较中给出的偏好信息进行分析与决策支持,既有效地吸收了定性分析的结果,又发挥了定量分析的优势,从而使决策过程具有很强的条理性和科学性,特别适合在社会经济系统的决策分析中使用。
缺点:用AHP进行决策主观成分很大。
当决策者的判断过多地受其主观偏好影响,而产生某种对客观规律的歪曲时,AHP的结果显然就靠不住了。
适用范围:尤其适合于人的定性判断起重要作用的、对决策结果难于直接准确计量的场合。
要使AHP的决策结论尽可能符合客观规律,决策者必须对所面临的问题有比较深入和全面的认识。
另外,当遇到因素众多,规模较大的评价问题时,该模型容易出现问题,它要求评价者对问题的本质、包含的要素及其相互之间的逻辑关系能掌握得十分透彻,否则评价结果就不可靠和准确。
改进方法:(1)成对比较矩阵可以采用德尔菲法获得。
(2)如果评价指标个数过多(一般超过9个),利用层次分析法所得到的权重就有一定的偏差,继而组合评价模型的结果就不再可靠。
可以根据评价对象的实际情况和特点,利用一定的方法,将各原始指标分层和归类,使得每层各类中的指标数少于9个。
3.2 灰色综合评价法(灰色关联度分析)基本思想:灰色关联分析的实质就是,可利用各方案与最优方案之间关联度大小对评价对象进行比较、排序。
关联度越大,说明比较序列与参考序列变化的态势越一致,反之,变化态势则相悖。
由此可得出评价结果。
基本步骤:建立原始指标矩阵;确定最优指标序列;进行指标标准化或无量纲化处理;求差序列、最大差和最小差;计算关联系数;计算关联度。
优点:是一种评价具有大量未知信息的系统的有效模型,是定性分析和定量分析相结合的综合评价模型,该模型可以较好地解决评价指标难以准确量化和统计的问题,可以排除人为因素带来的影响,使评价结果更加客观准确。
整个计算过程简单,通俗易懂,易于为人们所掌握;数据不必进行归一化处理,可用原始数据进行直接计算,可靠性强;评价指标体系可以根据具体情况增减;无需大量样本,只要有代表性的少量样本即可。
缺点:要求样本数据且具有时间序列特性;只是对评判对象的优劣做出鉴别,并不反映绝对水平,故基于灰色关联分析综合评价具有“相对评价”的全部缺点。
适用范围:对样本量没有严格要求,不要求服从任何分布,适合只有少量观测数据的问题;应用该种方法进行评价时,指标体系及权重分配是一个关键的问题,选择的恰当与否直接影响最终评价结果。
改进方法:(1)采用组合赋权法:根据客观赋权法和主观赋权法综合而得权系数。
(2)结合TOPSIS法:不仅关注序列与正理想序列的关联度γ+,而且关注序列与负理想序列的关联度γ-,依据公式γγγγ+-+=+计算最后的关联度。
3.3 模糊综合评价法基本思想:是以模糊数学为基础,应用模糊关系合成的原理,将一些边界不清、不易定量的因素定量化,从多个因素对被评价事物隶属等级(或称为评语集)状况进行综合性评价的一种方法。
综合评判对评判对象的全体,根据所给的条件,给每个对象赋予一个非负实数评判指标,再据此排序择优。
基本步骤:确定因素集、评语集;构造模糊关系矩阵;确定指标权重;进行模糊合成和做出评价。
优点::数学模型简单,容易掌握,对多因素、多层次的复杂问题评判效果较好。
模糊评判模型不仅可对评价对象按综合分值的大小进行评价和排序,而且还可根据模糊评价集上的值按最大隶属度原则去评定对象所属的等级,结果包含的信息量丰富。
评判逐对进行,对被评对象有唯一的评价值,不受被评价对象所处对象集合的影响。
接近于东方人的思维习惯和描述方法,因此它更适用于对社会经济系统问题进行评价。
缺点:并不能解决评价指标间相关造成的评价信息重复问题,隶属函数的确定还没有系统的方法,而且合成的算法也有待进一步探讨。
其评价过程大量运用了人的主观判断,由于各因素权重的确定带有一定的主观性,因此,总的来说,模糊综合评判是一种基于主观信息的综合评价方法。
应用范围:广泛地应用于经济管理等领域。
综合评价结果的可靠性和准确性依赖于合理选取因素、因素的权重分配和综合评价的合成算子等。