PSM原理及软件操作
- 格式:pptx
- 大小:6.13 MB
- 文档页数:12

倾向匹配模型近邻匹配原理
倾向匹配模型(Propensity Score Matching, PSM)是一种常用的统计方法,用于处理因果推断中的选择偏差问题。
在实际应用中,我们经常面临着无法进行随机实验的情况,因此需要借助倾向匹配模型来模拟实验条件,从而得到更加可靠的因果推断结果。
倾向匹配模型的核心原理是通过寻找近邻匹配来建立处理组和对照组之间的类似性,以减少处理组和对照组之间的差异性,从而实现更为准确的比较。
其基本步骤包括以下几个方面:
1. 倾向得分估计,首先,需要建立一个倾向得分模型,用于预测每个个体被处理的概率。
常用的建模方法包括逻辑回归、梯度提升树等。
2. 近邻匹配,在得到倾向得分后,需要通过一定的匹配算法,如最近邻匹配、卡方匹配等,来找到处理组和对照组之间的近邻。
3. 检验匹配质量,匹配完成后,需要进行匹配质量的检验,以确保匹配的有效性和可靠性。
4. 因果效应估计,最后,基于匹配后的样本数据,可以利用各种统计方法,如差分法、倾向得分加权法等,来估计处理效应的大小及显著性。
倾向匹配模型的近邻匹配原理能够有效地减少处理组和对照组之间的选择偏差,提高因果推断的可信度。
在医学、经济学、社会学等领域,倾向匹配模型都得到了广泛的应用,并取得了许多成功的研究成果。
然而,倾向匹配模型也存在着一定的局限性,如匹配质量依赖于倾向得分模型的准确性、匹配后样本量的减少等问题,因此在实际应用中需要谨慎使用并结合其他方法进行验证。

倾向性评分匹配的原理及文献解读倾向性评分匹配(Propensity Score Matching,PSM)是一种常用的数据分析方法,用于处理观察研究中的选择偏倚问题。
它的主要原理是通过建立一个倾向性评分模型,将具有相似倾向性评分的处理组和对照组进行匹配,来减少处理组和对照组之间的混杂因素。
在匹配完成后,可以使用匹配后的数据进行比较分析,从而获得更加准确的因果效应估计。
倾向性评分是对个体进行处理与否的概率进行预测的一种模型。
该模型基于观察到的个体的特征变量(confounding variables),通过回归分析或者机器学习等方法得到处理与否的倾向性评分。
常见的建模方法包括Logistic回归、Probit回归和Propensity Score Forest等。
模型建立好后,可以得到每个个体的倾向性评分,即个体进入处理组的概率。
在进行倾向性评分匹配时,首先需要选择一个适当的匹配算法来将处理组和对照组之间的个体进行配对。
常见的匹配算法包括最近邻匹配、卡尔曼匹配和基于距离的匹配法等。
这些算法都是根据个体的倾向性评分来寻找最接近的个体进行匹配。
匹配完成后,可以通过均衡性检验来验证匹配结果的有效性,主要包括倾向性评分比较、标准差比较和均衡性图形展示等。
倾向性评分匹配的主要优势在于可以在观察研究中解决选择偏倚问题,提供更为准确的因果效应估计。
通过匹配处理组和对照组,可以使得两组之间在观察到的个体特征上更加均衡,减少混杂因素对因果效应的干扰。
此外,倾向性评分匹配方法还具有较强的灵活性和可解释性,可以根据具体研究问题进行模型的设定和调整。
倾向性评分匹配方法已经在很多领域的研究中得到广泛应用。
例如,在医学研究中,可以用来评估一种新的治疗方法的效果;在教育研究中,可以用来评价一种新的教育政策的影响。
以下是一些与倾向性评分匹配方法相关的文献解读。
2. Stuart EA. Matching methods for causal inference: A review and a look forward. Stat Sci. 2024; 25(1):1-21.。
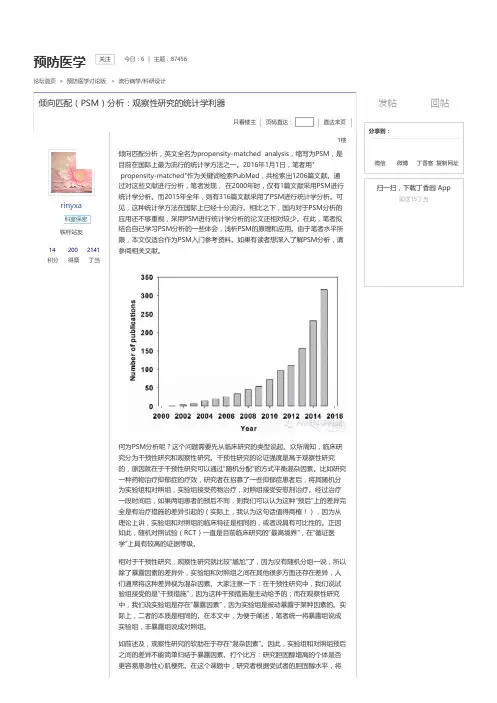
rinyxa科室保密何为PSM分析呢?这个问题需要先从临床研究的类型说起。
众所周知,临床研究分为干预性研究和观察性研究。
干预性研究的论证强度是高于观察性研究的,原因就在于干预性研究可以通过“随机分配”的方式平衡混杂因素。
比如研究一种药物治疗抑郁症的疗效,研究者在招募了一些抑郁症患者后,将其随机分为实验组和对照组,实验组接受药物治疗,对照组接受安慰剂治疗。
经过治疗一段时间后,如果两组患者的预后不同,则我们可以认为这种“预后”上的差异完全是有治疗措施的差异引起的(实际上,我认为这句话值得商榷!),因为从理论上讲,实验组和对照组的临床特征是相同的,或者说具有可比性的。
正因我的丁香客精品栏目找人随便看看更多版内搜索此时,如果贫血组和非贫血组患者在三年缺血时间发生风险上存在差异,则就可以将原因归结为贫血,因为两组患者其他特征都是相同的。
关于PSM的统计学原理,笔者在此以JTD这篇文章为例进行一简要介绍。
其基本流程为:首先将患者分为贫血患者非贫血患者,然后采用logistic回归,以贫血与否作为应变量(Y),以其他所有已知的临床特征(比如BMI、NYHA分级、高血压等)作为自变量(X),计算出每个患者的“贫血概率”。
这个贫血概率实际上就是PSM最核心的内容之一。
然后,根据贫血概率,将实验组和对照组进行匹配。
比如,贫血组一个患者的贫血概率为0.361,那么就在非贫血患者sunnymilanhuang入门站友黄春雨入门站友htelyon 入门站友影灯麻醉科李珂薇ake 入门站友。


psm方法PSM方法。
PSM(Propensity Score Matching)方法是一种常用的处理因果推断问题的统计方法,它通过匹配处理组和对照组的潜在得分,来减小因变量与自变量之间的干扰,从而更准确地估计处理效应。
本文将对PSM方法的原理、步骤和应用进行详细介绍。
一、原理。
PSM方法的核心原理是通过建立处理组和对照组之间的潜在得分(即倾向得分)来实现处理效应的估计。
在实际应用中,通常使用Logistic回归模型来预测处理组的概率,得到每个个体的倾向得分。
然后,根据倾向得分进行处理组和对照组的匹配,使得两组个体在倾向得分上尽可能接近,从而消除了因变量与自变量之间的干扰,更准确地估计处理效应。
二、步骤。
PSM方法的实施步骤通常包括以下几个步骤:1. 建立倾向得分模型,使用Logistic回归模型,以处理变量为因变量,其他自变量为自变量,预测处理组的概率,得到每个个体的倾向得分。
2. 匹配处理组和对照组,根据倾向得分,采用不同的匹配算法(如最近邻匹配、最优匹配等),将处理组和对照组进行一对一的匹配。
3. 检验匹配质量,对匹配后的样本进行倾向得分平衡检验,确保匹配后处理组和对照组之间的倾向得分分布差异较小。
4. 估计处理效应,在匹配后的样本中,使用各种统计方法(如 t 检验、回归分析等)估计处理效应,并进行稳健性检验。
5. 结果解释,根据估计的处理效应,对研究结果进行解释和讨论,得出结论。
三、应用。
PSM方法广泛应用于医学、经济学、社会学等领域的因果推断问题中。
例如,在医学研究中,研究者常常面临着无法进行随机对照实验的情况,此时可以利用PSM方法来减小观测数据中的选择偏差,更准确地估计治疗效应。
在教育政策评估中,PSM方法也被广泛应用于评估政策对学生学业成绩、就业情况等的影响。
总之,PSM方法作为一种处理因果推断问题的有效工具,具有较强的实用性和灵活性,能够在一定程度上弥补观测数据中的选择偏差,为研究者提供了一种有效的因果推断方法。

倾向匹配得分结果解读-回复题目:倾向匹配得分结果解读:了解其原理与应用引言:在今天的数据科学领域,倾向匹配(Propensity Score Matching, PSM)作为一种常用的因果推论方法,被广泛应用于各种研究领域。
PSM常用于评估某项政策、干预措施或者其他因素对于特定领域的影响。
在使用PSM 时,研究人员能够根据得分模型,将受众分为“干预组”和“对照组”,进而进行比较研究。
本文将逐步解读倾向匹配得分结果的原理和应用,帮助读者更好地理解这一方法的潜力与局限性。
一、倾向匹配原理的概述倾向匹配的核心思想是将个体或群体进行分类,使得两组之间的“干预效果”的差异能够被减少至最小。
这种分类的基础是构建每个个体的倾向得分,即他们进入“干预组”或者“对照组”的概率。
这一得分可以通过基线特征变量如性别、年龄、教育背景等进行预测,通常使用回归模型实现。
倾向得分能够将个体的特征转化为一个连续的分数,代表其进入某一组的概率。
二、倾向匹配得分结果的解释与应用得分模型通过前期数据收集和分析,能够得到个体倾向得分之间的差异。
然后,研究人员可以使用倾向匹配算法,将干预组的个体与对照组的个体进行匹配。
匹配的目标是使得干预组和对照组之间在倾向得分上的差异最小化,尽量类似。
匹配完成后,研究人员便可以通过比较干预组和对照组在不同变量上的差异,来评估干预的效果。
倾向匹配得分的应用领域广泛,可用于政策效果评估、医学研究和市场研究等诸多领域。
以政策效果评估为例,我们可以通过比较收入衡量、就业率等变量在接受政策干预前后的变化,来判断政策干预是否具有显著影响。
倾向匹配能够帮助研究人员有效控制潜在的混淆因素,提高因果关系研究的可靠性和准确性。
三、倾向匹配得分结果的解读策略1. 初步观察倾向匹配得分差异首先,研究人员需要观察和比较干预组和对照组在倾向得分上的差异。
如果差异较大,可能意味着两组之间存在较大的混淆因素。
这时应当进一步检查潜在的混淆因素是否得到很好的控制,或者考虑重新设计研究方案。

倾向得分匹配法(Propensity Score Matching,简称PSM)是一种在经济学和其他社会科学中广泛使用的统计方法,主要用于处理自选择偏误和观察数据中的潜在偏差。
其基本原理是通过计算一个倾向得分,将处理组(例如,接受某种干预或处理的对象)与控制组(未接受处理的对象)进行匹配,以消除非处理因素(即干扰因素)的影响,从而更准确地估计处理效应。
原理:倾向得分匹配法的核心在于建立一个倾向得分模型。
这个模型基于一系列可能影响处理分配的协变量(即特征变量),计算每个观察对象接受处理的概率,即倾向得分。
这个得分反映了观察对象在给定其协变量特征的情况下,接受处理的倾向程度。
通过倾向得分,我们可以将处理组和控制组中的观察对象进行匹配。
匹配的目标是找到与处理组对象在协变量特征上尽可能相似的控制组对象。
这样,匹配后的处理组和控制组在协变量上应该是平衡的,即它们在这些特征上的分布应该是相似的。
因此,处理效应的估计就可以更准确地归因于处理本身,而不是其他潜在的干扰因素。
实现:倾向得分匹配法的实现通常包括以下步骤:1.选择协变量:首先,需要确定哪些协变量可能影响处理分配和结果变量。
这些协变量应该被包括在倾向得分模型中。
2.估计倾向得分:使用逻辑回归或其他适当的模型来估计倾向得分。
这个模型以处理分配为因变量,以选定的协变量为自变量。
3.进行倾向得分匹配:根据估计得到的倾向得分,使用适当的匹配方法(如k近邻匹配、卡尺匹配等)将处理组和控制组进行匹配。
4.计算处理效应:在匹配后的样本上计算处理效应。
这通常涉及到比较处理组和控制组在结果变量上的差异。
在实际应用中,倾向得分匹配法可以通过各种统计软件来实现,如Stata、R和Python等。
这些软件提供了丰富的功能和工具,可以帮助研究者进行倾向得分估计、匹配和处理效应的计算。
需要注意的是,倾向得分匹配法虽然可以有效地处理自选择偏误和潜在偏差,但它也有一些局限性和假设条件。

倾向得分匹配法原理-回复倾向得分匹配法(Propensity Score Matching,PSM)是一种常用于处理因果推断问题的统计方法。
它的基本原理是通过构建倾向得分模型,将被处理的个体(处理组)与未处理的个体(对照组)进行配对,以便在某些特定的变量上达到类似或相同的分布,从而减少处理选择引起的偏倚。
PSM方法主要适用于在实验条件不具备的情况下进行因果推断。
在实验研究中,研究人员可以通过随机分组将个体分配到处理组和对照组,从而控制潜在的混淆因素。
然而,在实际应用中,一些因果问题无法通过实验进行研究,因此需要使用非实验数据来进行推断。
在这种情况下,倾向得分匹配法就能派上用场。
PSM方法的核心思想是通过估计个体的倾向得分,来度量个体进入处理组的概率。
倾向得分(Propensity Score)是指个体进入处理组的条件概率。
我们可以使用一些统计模型,例如逻辑回归模型,来估计这个得分。
这个模型会基于一系列观察到的协变量(confounding variables),也就是可能影响个体进入处理组的变量,比如年龄、性别、教育水平等,来预测个体进入处理组的概率。
在得到个体的倾向得分后,我们可以使用这个得分来进行配对。
具体来说,我们首先将处理组中的个体与对照组中的个体按照倾向得分进行配对。
一般可以使用一对一匹配、一对多匹配或者多对多匹配等方式。
匹配的目标是使处理组和对照组在倾向得分上的分布相似。
配对完成后,我们可以比较处理组和对照组在结果变量上的差异,来得到处理的因果效应。
这种比较可以通过计算平均处理效应(Average Treatment Effect,ATE)来实现。
ATE表示处理组与对照组在结果变量上的平均差异。
在计算ATE时,常常还会考虑到一些非随机选择问题带来的偏倚。
例如,可能存在选择性个体退出、数据缺失或者其他特殊情况。
为了解决这些问题,可以使用倾向得分匹配法的改进方法,如加权倾向得分匹配法(Weighted Propensity Score Matching)或者可接受性函数(Acceptance Function)等。



PSM短波发射机功率控制板工作原理与故障分析一、引言PSM短波发射机功率控制板是短波发射机的关键部件之一,负责控制发射机的输出功率,以确保发射机的稳定运行和输出信号的质量。
本文将介绍PSM短波发射机功率控制板的工作原理以及常见故障分析,以便工程师们能够更好地了解和维护该设备。
二、工作原理1. 功率控制原理PSM短波发射机功率控制板的主要功能是监测和调节发射机的输出功率。
其工作原理主要包括以下几个方面:(1) 信号检测:功率控制板通过信号检测电路监测发射机输出信号的功率水平。
(2) 比较调节:将监测到的功率信号与预设的目标功率进行比较,通过比较得到误差信号。
(3) 控制调节:根据误差信号调节控制放大器的增益,以实现对发射机输出功率的精确控制。
2. 工作流程PSM短波发射机功率控制板的工作流程如下:(4) 输出信号:经过功率控制板的调节后,发射机输出符合要求的信号。
三、故障分析1. 无法调节功率当发现PSM短波发射机功率控制板无法正常调节功率时,可能有以下几个故障原因:(2) 信号检测电路故障:当信号检测电路故障时,无法准确监测到发射机的输出功率,导致误差信号无法正确生成。
(3) 电源供应故障:电源供应的不稳定或者电源故障将导致功率控制板无法正常工作。
2. 输出功率不稳定(1) 温度变化:温度的变化会影响功率控制板的基准,导致输出功率波动。
(2) 调节元件故障:例如可变电阻或电容故障,都可能导致输出功率不稳定。
3. 其他故障除以上故障外,还可能出现其他故障,如接触不良、电路板损坏等。
四、维护方法针对以上故障情况,我们可以采取一些维护方法来保证PSM短波发射机功率控制板的正常工作:(1) 定期检查:定期检查功率控制板的各个部件,确保它们的正常工作。
(3) 消除干扰:采取一些措施来消除外部信号干扰,确保功率控制板的正常工作。
(4) 检修替换:一旦发现故障,及时进行检修或替换,保证功率控制板的正常运行。
PSM專案管理系統(Practical Software and Systems Measurement) 它是美國國防部和陸軍所贊助,用來解決今日軟體及系統有關技術和管理的挑戰。
PSM乃根據美國政府、國防部和企業界實際的度量經驗所發展而成,它描述以議題為導向的分析方法,用來闡明每個組織獨特的企業目標,是現今軟體或系統的採購及工程領域中最佳的執行方法之一。
PSM認為度量是一個彈性的流程,並非事先定義的圖形或報告,它包含一組共9個最佳執行方法,稱為度量原理(measurement principles),這組度量原理可整合至每個系統,確保度量流程不但是最經濟的,亦能提供有意義且有效的結果。
PSM分為三大部分[Select]、[Tailor]、[Apply]。
一、[Select]主要管理[Projects]專案的新增(Add)、編輯(Edit)、刪除(Delete)、開啟(Open)、關閉(Close)、備份(Pack)、讀取備分(Unpack)。
新增(Add):主要新增專案名稱(Project’s name)、定義專案描述(description)、指定目錄資料夾及註記(note)等編輯(Edit):重新編輯上述”新增”所做的事情。
刪除(Delete):刪除專案。
開啟(Open):開啟專案。
在使用PSM時,有可能存在好幾個專案,所以一次只能開啟一個專案,其他專案則須處於關閉狀態。
關閉(Close):關閉專案。
備份(Pack):可選擇不含資料備份(一種是不含Structure values備份、一種是不含attribute values備份,或者是兩種都不備份),再者是備份到指定的資料夾或檔案(可隨意自行指定到磁片或設定的資料夾)。
讀取備分(Unpack):[Specify file name]欄位則是選擇你要讀取的專案路徑,[Specify directory name]則是要你設定要備份到哪裡。
PSM-ID电能量远方终端1.概述PSM-ID电能量远方终端用于变电站、发电厂等高压关口电能量数据的采集、处理、发送,配合主站端数据处理系统,完成电能量自动抄表,实现电能量远方计量。
PSM-ID电能量远方终端的核心部分采用了流行的工业控制模块和嵌入式多任务操作系统,在硬件软件两方面保证了系统的可靠性,实现了大容量的数据存储和快速的数据交换,在应用中很好地满足了用户的需求。
2.工作原理PSM-ID电能量远方终端主要用于对电子式电度表的数据采集,通过电度表的RS485接口抄读数据。
需要脉冲量、遥信量采集的地方,可以使用我公司生产的专用于与PSM-ID配套使用的PSM-IS脉冲采集终端采集,并由PSM-ID 将数据集中,实现脉冲量、遥信量的采集。
PSM-ID与PSM-IS以主、从方式通过RS485接口交换数据,系统结构图如下图所示。
3.装置构成PSM-ID电能量远方终端采用PC/104模块为核心硬件,PSM-ID电能量远方终端可以根据需要对以太网接口、RS485/RS232/RS422接口的个数进行配置,各串口同时并相互独立工作。
终端具有LCD液晶显示、六键操作键盘。
终端供电电源为双电源冗余配置,其原理框图如下图所示。
1)硬件核心硬件:采用Intel 486DX4 32位CPU为核心处理器,高硬件配置使系统具有非常强大的处理能力。
采用PC/104总线结构设计,增强了系统的可靠性及扩展能力。
配备了电子硬盘,由于没有机械式硬盘的转动部分,使系统更可靠,加上先进的flash技术,更使电子盘的使用寿命长达10年。
内部时钟RTC,使电能量远方终端能准确的记录SOE,并能实现带时标存储电度量数据。
电源:为了保证电能量远方终端的可靠运行,真正做到双电源的无扰动切换,我们对电源采用了双冗余设计,既可以每一路电源单独运行,也可以双路电源共同运行,每一路电源直流、交流均可。
电能量远方终端的运行环境存在着大量电磁干扰,其中有很大成份来自于电源线路,为了消除干扰,首先,我们采用隔离技术,使弱电系统和强电系统完全隔离,这样能去除大部分低频干扰;其次,对于高频干扰,我们在每一路电源中使用高性能的EMI滤波器,使干扰信号在电源入口处便被滤除,良好的结构设计大大增强了装置的电磁兼容性能。
广义倾向得分匹配法(Generalized Propensity Score Matching, GPSM)是一种用于处理因果推断的统计方法,它基于倾向得分匹配法(Propensity Score Matching, PSM)的基本原理。
倾向得分是指个体进入某个处理组的概率。
在GPSM中,首先通过建立一个预测模型来估计个体进入处理组的概率(倾向得分),这个模型可以是逻辑回归或其他合适的方法。
GPSM的原理如下:
1.倾向得分估计:使用预测模型来估计每个个体进入处理组的概率,得到每个个体的倾向
得分。
2.匹配处理组和对照组:根据倾向得分将处理组和对照组中的个体进行匹配。
匹配的目的
是使得处理组和对照组在倾向得分上更加接近,从而减少选择偏差。
3.比较处理效果:在匹配后的样本中,比较处理组和对照组之间的结果差异。
通过比较两
组的平均差异或其他统计指标,可以评估处理的因果效应。
GPSM的优点是可以在控制了潜在混淆变量的情况下,尽可能减少选择偏差,从而更准确地评估处理的效果。
然而,GPSM也有一些限制,例如需要对倾向得分进行合理的模型假设和选择适当的匹配算法。
总而言之,广义倾向得分匹配法通过估计个体的倾向得分,并根据倾向得分进行匹配,可以减少因选择偏差而引起的结果偏差,用于进行因果推断和处理效果评估。
倾向得分匹配法对样本再回归的结果引言在社会科学研究中,倾向得分匹配法(Propensity Score Matching,简称PSM)是一种常用的因果推断方法。
它通过建立一个倾向得分模型,将样本划分为具有相似倾向得分的处理组和对照组,从而实现减少选择偏差、估计处理效应的目的。
当我们使用PSM进行因果推断时,需要对样本再回归以验证PSM方法的有效性和可靠性。
本文将详细介绍倾向得分匹配法对样本再回归的结果。
首先,我们将介绍PSM方法的基本原理和步骤。
然后,我们将讨论如何进行样本再回归,并解释其背后的统计原理。
最后,我们将总结并提出一些建议,以便更好地理解和应用倾向得分匹配法对样本再回归结果。
一、倾向得分匹配法基本原理和步骤1.1 倾向得分匹配法基本原理倾向得分匹配法是一种非随机实验设计的因果推断方法。
它通过建立一个预测个体被处理(接受处理)的概率的模型,即倾向得分模型,来估计处理效应。
倾向得分模型的核心思想是利用个体的观测特征(协变量)来预测其被处理的概率,进而将样本划分为处理组和对照组。
1.2 倾向得分匹配法步骤倾向得分匹配法的步骤如下: 1. 确定研究目标和问题。
明确需要评估的处理效应和相关变量。
2. 收集数据并进行预处理。
包括数据清洗、缺失值处理等。
3. 构建倾向得分模型。
根据研究问题选择适当的方法(如Logistic回归、Probit回归等)建立倾向得分模型,并根据模型结果计算每个个体的倾向得分。
4. 进行匹配。
根据个体的倾向得分进行匹配,将具有相似倾向得分的处理组和对照组配对。
5. 检验匹配结果。
使用标准化差异检验或基于Bootstrap方法进行检验,评估匹配结果是否有效。
6. 进行样本再回归。
在进行样本再回归之前,需要先检查匹配后样本是否平衡,并选取合适的回归方法进行分析。
7. 分析结果和解释。
根据样本再回归的结果,评估处理效应的大小、显著性和可信度。
二、样本再回归的方法和统计原理样本再回归是对倾向得分匹配法的一个重要补充,它可以进一步验证PSM方法的有效性和可靠性。