数据结构实验9哈希查找
- 格式:doc
- 大小:74.50 KB
- 文档页数:12

哈希表查找方法原理哈希表查找方法什么是哈希表•哈希表是一种常见的数据结构,也被称为散列表。
•它可以提供快速的插入、删除和查找操作,时间复杂度在平均情况下为O(1)。
•哈希表由数组组成,每个数组元素称为桶(bucket)。
•存储数据时,通过哈希函数将数据映射到对应的桶中。
哈希函数的作用•哈希函数是哈希表的核心部分,它将数据转换为哈希值。
•哈希函数应该具备以下特点:–易于计算:计算哈希值的时间复杂度应尽量低。
–均匀分布:哈希函数应能将数据均匀地映射到不同的桶中,以避免桶的过度填充或者空闲。
–独特性:不同的输入应该得到不同的哈希值,以尽量减少冲突。
哈希冲突及解决方法•哈希冲突指两个或多个数据被哈希函数映射到同一个桶的情况。
•常见的解决哈希冲突的方法有以下几种:–链地址法(Chaining):将相同哈希值的数据存储在同一个桶中,通过链表等数据结构来解决冲突。
–开放地址法(Open Addressing):当发生冲突时,通过特定的规则找到下一个可用的桶来存储冲突的数据,如线性探测、二次探测等。
–再哈希法(Rehashing):当发生冲突时,使用另一个哈希函数重新计算哈希值,并将数据存储到新的桶中。
哈希表的查找方法•哈希表的查找方法分为两步:1.根据哈希函数计算数据的哈希值,并得到对应的桶。
2.在桶中查找目标数据,如果找到则返回,否则表示数据不存在。
哈希表的查找性能•在理想情况下,哈希表的查找时间复杂度为O(1)。
•然而,由于哈希冲突的存在,查找时间可能会稍微增加。
•如果哈希函数设计得不好,导致冲突较多,可能会使查找时间复杂度接近O(n)。
•因此,选择合适的哈希函数和解决冲突的方法对于提高哈希表的查找性能非常重要。
总结•哈希表是一种高效的数据结构,适用于快速插入、删除和查找操作的场景。
•哈希函数的设计和解决冲突的方法直接影响哈希表的性能。
•在实际应用中,需要根据数据特点选择合适的哈希函数和解决冲突的方法,以提高哈希表的查找性能。

第九章查找一、选择题1•若查找每个记录的概率均等,则在具有n 个记录的连续顺序文件中采用顺序查找法查找一个记录,其平均查找长度ASL 为()。
A .(n-1)/2B.n/2C.(n+1)/2D.n 2. 下面关于二分查找的叙述正确的是()A. 表必须有序,表可以顺序方式存储,也可以链表方式存储C.表必须有序,而且只能从小到大排列B. 表必须有序且表中数据必须是整型,实型或字符型D.表必须有序,且表只 能以顺序方式存储3. 用二分(对半)查找表的元素的速度比用顺序法() A. 必然快B.必然慢C.相等D.不能确定4. 具有12个关键字的有序表,折半查找的平均查找长度()A.3.1B.4C.2.5D.55.当采用分块查找时,数据的组织方式为()A. 数据分成若干块,每块内数据有序B. 数据分成若干块,每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块C. 数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块D. 数据分成若干块,每块(除最后一块外)中数据个数需相同6. 二叉查找树的查找效率与二叉树的((1))有关,在((2))时其查找效率最低(1) :A.高度B.结点的多少C.树型D.结点的位置(2) :A.结点太多B.完全二叉树C.呈单枝树D.结点太复杂。
7. 对大小均为n 的有序表和无序表分别进行顺序查找,在等概率查找的情况下,对于查找失败,它们的平均查找长度是((1)),对于查找成功,他们的平均查找长度是((2))供选择的答案:A.相同的B.不同的9.分别以下列序列构造二叉排序树,与用其它三个序列所构造的结果不同的是()A .(100,80,90,60,120,110,130)B.(100,120,110,130,80,60,90) C. (100,60,80,90,120,110,130)D.(100,80,60,90,120,130,110)10. 在平衡二叉树中插入一个结点后造成了不平衡,设最低的不平衡结点为A,并已知A 的左孩子的平衡因子为0右孩子的平衡因子为1,则应作()型调整以使其平衡。



哈希查找的时间复杂度哈希查找(Hash Search)是一种常用的快速查找算法,通过将数据存储在哈希表中,可以快速地定位到需要查找的元素。
在哈希查找中,关键字的哈希值将决定其在哈希表中的位置,从而实现了快速查找的目的。
本文将探讨哈希查找算法的时间复杂度及其影响因素。
一、哈希查找算法概述哈希查找算法主要分为两个步骤:哈希函数的构造和哈希冲突的处理。
具体步骤如下:1. 哈希函数的构造:根据待查找的关键字的特点,设计一个哈希函数,将关键字映射为哈希值,并将其存储在哈希表中。
2. 哈希冲突的处理:由于哈希函数的映射可能存在冲突(即不同的关键字可能映射到相同的哈希值),需要设计一种冲突解决方法,如开放地址法、链地址法等。
二、哈希查找的时间复杂度分析在理想情况下,哈希查找的时间复杂度为O(1),即常数时间。
这是因为通过哈希函数,可以直接计算得到待查找元素在哈希表中的位置,不需要遍历整个表格,从而实现了快速查找。
然而,在实际应用中,哈希函数的设计和哈希冲突的处理可能会影响查找效率。
如果哈希函数设计得不好,或者哈希表的装载因子过高,会导致哈希冲突的发生频率增加,从而影响查找性能。
三、影响哈希查找时间复杂度的因素1. 哈希函数的设计:好的哈希函数应该能够将关键字均匀地映射到哈希表的各个位置,从而降低哈希冲突的概率。
常用的哈希函数包括除留余数法、平方取中法等。
2. 哈希表的装载因子:装载因子是指哈希表中已存储元素个数与哈希表总大小的比值。
装载因子过高会增加哈希冲突的概率,从而降低查找性能。
通常情况下,装载因子的取值应控制在0.7以下。
3. 哈希冲突的处理方法:常见的哈希冲突解决方法有开放地址法和链地址法。
开放地址法通过线性探测、二次探测等方式寻找下一个可用位置,链地址法则使用链表或其他数据结构存储具有相同哈希值的关键字。
四、总结哈希查找是一种高效的查找算法,可以在常数时间内完成查找操作。
然而,其性能受到哈希函数的设计、哈希表的装载因子和哈希冲突的处理方式的影响。

福建工程学院课程设计课程:算法与数据结构题目:哈希表专业:网络工程班级:xxxxxx班座号:xxxxxxxxxxxx姓名:xxxxxxx2011年12 月31 日实验题目:哈希表一、要解决的问题针对同班同学信息设计一个通讯录,学生信息有姓名,学号,电话号码等。
以学生姓名为关键字设计哈希表,并完成相应的建表和查表程序。
基本要求:姓名以汉语拼音形式,待填入哈希表的人名约30个,自行设计哈希函数,用线性探测再散列法或链地址法处理冲突;在查找的过程中给出比较的次数。
完成按姓名查询的操作。
运行的环境:Microsoft Visual C++ 6.0二、算法基本思想描述设计一个哈希表(哈希表内的元素为自定义的结构体)用来存放待填入的30个人名,人名为中国姓名的汉语拼音形式,用除留余数法构造哈希函数,用线性探查法解决哈希冲突。
建立哈希表并且将其显示出来。
通过要查找的关键字用哈希函数计算出相应的地址来查找人名。
通过循环语句调用数组中保存的数据来显示哈希表。
三、设计1、数据结构的设计和说明(1)结构体的定义typedef struct //记录{NA name;NA xuehao;NA tel;}Record;录入信息结构体的定义,包含姓名,学号,电话号码。
typedef struct //哈希表{Record *elem[HASHSIZE]; //数据元素存储基址int count; //当前数据元素个数int size; //当前容量}HashTable;哈希表元素的定义,包含数据元素存储基址、数据元素个数、当前容量。
2、关键算法的设计(1)姓名的折叠处理long fold(NA s) //人名的折叠处理{char *p;long sum=0;NA ss;strcpy(ss,s); //复制字符串,不改变原字符串的大小写strupr(ss); //将字符串ss转换为大写形式p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}(2)建立哈希表1、用除留余数法构建哈希函数2、用线性探测再散列法处理冲突int Hash1(NA str) //哈希函数{long n;int m;n=fold(str); //先将用户名进行折叠处理m=n%HASHSIZE; //折叠处理后的数,用除留余数法构造哈希函数return m; //并返回模值}Status collision(int p,int c) //冲突处理函数,采用二次探测再散列法解决冲突{int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();}else printf("\n此人不存在,查找不成功!\n");benGetTime();}(4)显示哈希表void ShowInformation(Record* a) //显示输入的用户信息{int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}(5)主函数的设计void main(int argc, char* argv[]){Record a[MAXSIZE];int c,flag=1,i=0;HashTable *H;H=(HashTable*)malloc(LEN);for(i=0;i<HASHSIZE;i++){H->elem[i]=NULL;H->size=HASHSIZE;H->count=0;}while (1){ int num;printf("\n ");printf("\n 欢迎使用同学通讯录录入查找系统");printf("\n 哈希表的设计与实现");printf("\n 【1】. 添加用户信息");printf("\n 【2】. 读取所有用户信息");printf("\n 【3】. 以姓名建立哈希表(再哈希法解决冲突) ");printf("\n 【4】. 以电话号码建立哈希表(再哈希法解决冲突) ");printf("\n 【5】. 查找并显示给定用户名的记录");printf("\n 【6】. 查找并显示给定电话号码的记录");printf("\n 【7】. 清屏");printf("\n 【8】. 保存");printf("\n 【9】. 退出程序");printf("\n 温馨提示:");printf("\n Ⅰ.进行5操作前请先输出3 ");printf("\n Ⅱ.进行6操作前请先输出4 ");printf("\n");printf("请输入一个任务选项>>>");printf("\n");scanf("%d",&num);switch(num){case 1:getin(a);break;case 2:ShowInformation(a);break;case 3:CreateHash1(H,a); /* 以姓名建立哈希表*/break;case 4:CreateHash2(H,a); /* 以电话号码建立哈希表*/break;case 5:c=0;SearchHash1(H,c);break;case 6:c=0;SearchHash2(H,c);break;case 7:Cls(a);break;case 8:Save();break;case 9:return 0;break;default:printf("你输错了,请重新输入!");printf("\n");}}system("pause");return 0;3、模块结构图及各模块的功能:四、源程序清单:#include<stdio.h>#include<stdlib.h>#include<string.h>#include <windows.h>#define MAXSIZE 20 #define MAX_SIZE 20 #define HASHSIZE 53 #define SUCCESS 1#define UNSUCCESS -1#define LEN sizeof(HashTable)typedef int Status;typedef char NA[MAX_SIZE];typedef struct {NA name;NA xuehao;NA tel;}Record;typedef struct {Record *elem[HASHSIZE]; int count; int size; }HashTable;Status eq(NA x,NA y) {if(strcmp(x,y)==0)return SUCCESS;else return UNSUCCESS;}Status NUM_BER;void getin(Record* a) {int i;system("cls");printf("输入要添加的个数:\n");scanf("%d",&NUM_BER);for(i=0;i<NUM_BER;i++){printf("请输入第%d个记录的姓名:\n",i+1);scanf("%s",a[i].name);printf("请输入%d个记录的学号:\n",i+1);scanf("%s",a[i].xuehao);printf("请输入第%d个记录的电话号码:\n",i+1);scanf("%s",a[i].tel);}}void ShowInformation(Record* a){int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}void Cls(Record* a){printf("*");system("cls");}long fold(NA s){char *p;long sum=0;NA ss;strcpy(ss,s);strupr(ss);p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}int Hash1(NA str){int m;n=fold(str);m=n%HASHSIZE;return m;}int Hash2(NA str){long n;int m;n = atoi(str);m=n%HASHSIZE;return m;}Status collision(int p,int c){int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();void CreateHash1(HashTable* H,Record* a){ int i,p=-1,c,pp;system("cls"); benGetTime();for(i=0;i<NUM_BER;i++){p=Hash1(a[i].name);pp=p;while(H->elem[pp]!=NULL) {pp=collision(p,c);if(pp<0){printf("第%d记录无法解决冲突",i+1);continue;}}H->elem[pp]=&(a[i]);H->count++;printf("第%d个记录冲突次数为%d。

引言概述:本文旨在对哈希实验进行报告,重点介绍哈希实验的二次探测法、哈希函数、哈希表的查找、插入与删除操作,并分析实验结果。
通过本实验的开展,我们对哈希算法的原理、实现和性能有了更深入的理解,也增加了对数据结构的实践能力。
正文内容:一、二次探测法1.定义与原理2.步骤与流程3.优缺点分析4.实验过程与结果5.实验中的注意事项二、哈希函数1.哈希函数的设计原则2.常见的哈希函数算法3.哈希冲突与解决方法4.哈希函数的优化策略5.实验中的哈希函数选择与应用三、哈希表的查找操作1.哈希表的存储结构与基本操作2.直接定址法查找3.拉链法查找4.其他查找方法与比较5.实验结果与分析四、哈希表的插入与删除操作1.插入操作的实现思路2.插入操作的效率分析3.删除操作的实现思路4.删除操作的效率分析5.实验结果分析与对比五、实验结果与总结1.实验数据的统计与分析2.实验中的问题与解决方案3.实验结论与总结4.对哈希算法的进一步探讨与应用展望5.实验的意义与启示总结:通过对哈希实验的详细阐述,我们对二次探测法、哈希函数、哈希表的查找、插入与删除操作有了更深入的了解。
实验结果与分析表明,在哈希表的实现中,选择合适的哈希函数、解决哈希冲突以及优化插入与删除操作,对提高哈希表的性能至关重要。
哈希算法作为一种重要的数据结构应用,具有广泛的应用前景,在实际问题中具有重要的实践意义。
通过本次实验,我们不仅提升了对数据结构的理论理解,也增强了数据结构算法的实践能力,为今后的学习与研究打下了坚实的基础。

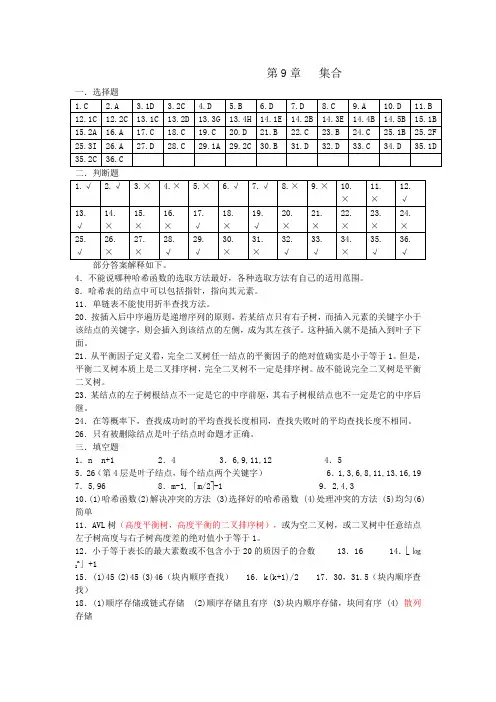
第9章集合部分答案解释如下。
4.不能说哪种哈希函数的选取方法最好,各种选取方法有自己的适用范围。
8.哈希表的结点中可以包括指针,指向其元素。
11.单链表不能使用折半查找方法。
20.按插入后中序遍历是递增序列的原则,若某结点只有右子树,而插入元素的关键字小于该结点的关键字,则会插入到该结点的左侧,成为其左孩子。
这种插入就不是插入到叶子下面。
21.从平衡因子定义看,完全二叉树任一结点的平衡因子的绝对值确实是小于等于1。
但是,平衡二叉树本质上是二叉排序树,完全二叉树不一定是排序树。
故不能说完全二叉树是平衡二叉树。
23.某结点的左子树根结点不一定是它的中序前驱,其右子树根结点也不一定是它的中序后继。
24.在等概率下,查找成功时的平均查找长度相同,查找失败时的平均查找长度不相同。
26.只有被删除结点是叶子结点时命题才正确。
三.填空题1.n n+1 2.4 3.6,9,11,12 4.55.26(第4层是叶子结点,每个结点两个关键字) 6.1,3,6,8,11,13,16,19 7.5,96 8.m-1,「m/2⎤-1 9.2,4,310.(1)哈希函数(2)解决冲突的方法 (3)选择好的哈希函数 (4)处理冲突的方法 (5)均匀(6)简单11.AVL树(高度平衡树,高度平衡的二叉排序树),或为空二叉树,或二叉树中任意结点左子树高度与右子树高度差的绝对值小于等于1。
12.小于等于表长的最大素数或不包含小于20的质因子的合数 13.16 14.⎣㏒n」+1215.(1)45 (2)45 (3)46(块内顺序查找) 16.k(k+1)/2 17.30,31.5(块内顺序查找)18.(1)顺序存储或链式存储 (2)顺序存储且有序 (3)块内顺序存储,块间有序 (4) 散列存储19.(n+1)/2 20.(n+1)/n*log2(n+1)-1 21.结点的左子树的高度减去结点的右子树的高度22.(1)顺序表(2)树表(3)哈希表(4)开放定址方法(5)链地址方法(6)再哈希(7)建立公共溢出区23.直接定址法 24.log⎡m/2⎤(21n+)+1 25.O(N) 26.n(n+1)/227.54 28.31 29.37/12 30.主关键字 31.左子树右子树32.插入删除 33.14 34.(1)126 (2)64 (3)33 (4)65 35.(1)low<=high (2) (low+hig) DIV 2 (3) binsrch:=mid (4)binsrch:=0 36.(1) k (2) I<n+1 37.(1)rear=mid-1 (2)head=mid+1 (3)head>rear 38.(1)p!=null (2)pf=p (3)p!=*t (4)*t=null四.应用题1.概念是基本知识的主要部分,要牢固掌握。

哈希查找的名词解释
哈希查找(HashSearch)是一种快速检索技术,通过计算一个项目的哈希值,来快速检索该项目是否存在于数据表中。
它的原理是:数据集合中的每一个元素首先通过哈希函数映射成一个数字,然后根据这个数字对查询表进行定位,再根据查找表中的信息检索出查找的数据。
哈希查找可用于查看某个数据是否存在于某集合之中,也可以用于查看某个数据的各种相关信息。
哈希函数:
哈希函数是一种将原始数据映射成散列值的函数,它常用于实现哈希操作,即从原始数据中找到一个映射而来的数据。
根据哈希函数,相同的原始数据将会映射到相同的散列值上,由此来节省查找时间,提高查找效率。
桶:
桶(Bucket)是哈希查找的一种技术,它是把所有映射到同一散列值上的元素放在同一个桶中,以加快查找速度。
哈希查找时,先根据哈希函数计算出元素的散列值,然后根据这个散列值在桶中查找,直到找到查找元素为止。
哈希表:
哈希表(Hash Table)是一种存储数据的数据结构,它由一个固定大小的数组组成,其中每个元素都以键值对保存数据,其中键是一个数字或字符串,而值是任意类型的数据。
哈希表很容易根据键快速查找到对应的值,因此,使用哈希表可以实现快速查找操作。

第9章查找一、选择题1.顺序查找一个共有n个元素的线性表,其时间复杂度为(),折半查找一个具有n个元素的有序表,其时间复杂度为()。
【*,★】A.O(n)B. O(log2n)C. O(n2)D. O(nlog2n)2.在对长度为n的顺序存储的有序表进行折半查找,对应的折半查找判定树的高度为()。
【*,★】A.nB.C.D.3.采用顺序查找方式查找长度为n的线性表时,平均查找长度为()。
【*】A.nB. n/2C. (n+1)/2D. (n-1)/24.采用折半查找方法检索长度为n的有序表,检索每个元素的平均比较次数()对应判定树的高度(设高度大于等于2)。
【**】A.小于B. 大于C. 等于D. 大于等于5.已知有序表(13,18,24,35,47,50,62,83,90,115,134),当折半查找值为90的元素时,查找成功的比较次数为()。
【*】A. 1B. 2C. 3D. 46.对线性表进行折半查找时,要求线性表必须()。
【*】A.以顺序方式存储B. 以链接方式存储C.以顺序方式存储,且结点按关键字有序排序D. 以链接方式存储,且结点按关键字有序排序7.顺序查找法适合于存储结构为()的查找表。
【*】A.散列存储B. 顺序或链接存储C. 压缩存储D. 索引存储8.采用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应分()个结点最佳。
【**】A.10B. 25C. 6D. 6259.从键盘依次输入关键字的值:t、u、r、b、o、p、a、s、c、l,建立二叉排序树,则其先序遍历序列为(),中序遍历序列为()。
【**,★】A.abcloprstuB. alcpobsrutC. trbaoclpsuD. trubsaocpl10.折半查找和二叉排序树的时间性能()。
【*】A.相同B. 不相同11.一棵深度为k的平衡二叉树,其每个非终端结点的平衡因子均为0,则该树共有()个结点。
第九章 查找一、填空题1. 在数据的存放无规律而言的线性表中进行检索的最佳方法是 顺序查找(线性查找) 。
2. 线性有序表(a 1,a 2,a 3,…,a 256)是从小到大排列的,对一个给定的值k ,用二分法检索表中与k 相等的元素,在查找不成功的情况下,最多需要检索 8 次。
设有100个结点,用二分法查找时,最大比较次数是 7 。
3. 假设在有序线性表a[1..20]上进行折半查找,则比较一次查找成功的结点数为1;比较两次查找成功的结点数为 2 ;比较四次查找成功的结点数为 8 ,其下标从小到大依次是1,3,6,8,11,13,16,19______,平均查找长度为 3.7 。
解:显然,平均查找长度=O (log 2n )<5次(25)。
但具体是多少次,则不应当按照公式)1(log 12++=n nn ASL 来计算(即(21×log 221)/20=4.6次并不正确!)。
因为这是在假设n =2m -1的情况下推导出来的公式。
应当用穷举法罗列:全部元素的查找次数为=(1+2×2+4×3+8×4+5×5)=74; ASL =74/20=3.7 !!! 4.折半查找有序表(4,6,12,20,28,38,50,70,88,100),若查找表中元素20,它将依次与表中元素 28,6,12,20 比较大小。
5. 在各种查找方法中,平均查找长度与结点个数n 无关的查找方法是 散列查找 。
6. 散列法存储的基本思想是由 关键字的值 决定数据的存储地址。
7. 有一个表长为m 的散列表,初始状态为空,现将n (n<m )个不同的关键码插入到散列表中,解决冲突的方法是用线性探测法。
如果这n 个关键码的散列地址都相同,则探测的总次数是 n(n-1)/2=( 1+2+…+n-1) 。
(而任一元素查找次数 ≤n-1)8、设一哈希表表长M 为100 ,用除留余数法构造哈希函数,即H (K )=K MOD P (P<=M ), 为使函数具有较好性能,P 应选( 97 )9、在各种查找方法中,平均查找长度与结点个数无关的是哈希查找法 10、对线性表进行二分查找时,要求线性表必须以 顺序 方式存储,且结点按关键字有序排列。
第九章 查找一、填空题1. 在数据的存放无规律而言的线性表中进行检索的最佳方法是 顺序查找(线性查找) 。
2. 线性有序表(a 1,a 2,a 3,…,a 256)是从小到大排列的,对一个给定的值k ,用二分法检索表中与k 相等的元素,在查找不成功的情况下,最多需要检索 8 次。
设有100个结点,用二分法查找时,最大比较次数是 7 。
3. 假设在有序线性表a[1..20]上进行折半查找,则比较一次查找成功的结点数为1;比较两次查找成功的结点数为 2 ;比较四次查找成功的结点数为 8 ,其下标从小到大依次是1,3,6,8,11,13,16,19______,平均查找长度为 3.7 。
解:显然,平均查找长度=O (log 2n )<5次(25)。
但具体是多少次,则不应当按照公式)1(log 12++=n n n ASL 来计算(即(21×log 221)/20=4.6次并不正确!)。
因为这是在假设n =2m -1的情况下推导出来的公式。
应当用穷举法罗列:全部元素的查找次数为=(1+2×2+4×3+8×4+5×5)=74; ASL =74/20=3.7 !!!4.折半查找有序表(4,6,12,20,28,38,50,70,88,100),若查找表中元素20,它将依次与表中元素 28,6,12,20 比较大小。
5. 在各种查找方法中,平均查找长度与结点个数n 无关的查找方法是 散列查找 。
6. 散列法存储的基本思想是由 关键字的值 决定数据的存储地址。
7. 有一个表长为m 的散列表,初始状态为空,现将n (n<m )个不同的关键码插入到散列表中,解决冲突的方法是用线性探测法。
如果这n 个关键码的散列地址都相同,则探测的总次数是 n(n-1)/2=( 1+2+…+n-1) 。
(而任一元素查找次数 ≤n-1)8、设一哈希表表长M 为100 ,用除留余数法构造哈希函数,即H (K )=K MOD P (P<=M ), 为使函数具有较好性能,P 应选( 97 )9、在各种查找方法中,平均查找长度与结点个数无关的是哈希查找法10、对线性表进行二分查找时,要求线性表必须以 顺序 方式存储,且结点按关键字有序排列。