一个新的多分类器组合模型_蒋林波
- 格式:pdf
- 大小:249.82 KB
- 文档页数:5


2023年《人工智能》现代科技知识考试题与答案目录简介一、单选题:共40题二、多选题:共20题三、判断题:共26题一、单选题1、下列哪部分不是专家系统的组成部分?A .用户B.综合数据库C.推理机D.知识库正确答案:A解析:《人工智能导论》(第4版)作者:王万良出版社: 高等教育出版社2、下列哪个神经网络结构会发生权重共享?A.卷积神经网络B.循环神经网络C.全连接神经网络D. A 和B正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社3、下列哪个不属于常用的文本分类的特征选择算法?A.卡方检验值B.互信息C .信息增益D.主成分分析正确答案:D解析:《自然语言处理》作者:刘挺出版社:高等教育出版社4、下列哪个不是人工智能的技术应用领域?A.搜索技术B.数据挖掘C.智能控制D .编译原理解析:《走进人工智能》作者:周旺出版社:高等教育出版社5、Q(s,a)是指在给定状态s的情况下,采取行动a之后,后续的各个状态所能得到的回报()。
A.总和B.最大值C.最小值D.期望值正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社6、数据科学家可能会同时使用多个算法(模型)进行预测,并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是()。
A.单个模型之间有高相关性B.单个模型之间有低相关性C,在集成学习中使用“平均权重”而不是“投票”会比较好D.单个模型都是用的一个算法解析:《机器学习方法》作者:李航出版社:清华大学出版社7、以下哪种技术对于减少数据集的维度会更好?A.删除缺少值太多的列B.删除数据差异较大的列C.删除不同数据趋势的列D.都不是正确答案:A解析:《机器学习》作者:周志华出版社:清华大学出版社8、在强化学习过程中,学习率越大,表示采用新的尝试得到的结果比例越(),保持旧的结果的比例越()。
A .大,小B.大,大C.小,大D.小,小正确答案:A解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社9、以下哪种方法不属于特征选择的标准方法?A.嵌入B.过滤C ,包装D.抽样正确答案:D解析:《深度学习、优化与识别》作者:焦李成出版社: 清华大学出版社10、要想让机器具有智能,必须让机器具有知识。

人工智能导论第二章答案1、单选题:下列关于智能说法错误的是()选项:A:细菌不具有智能B:任何生命都拥有智能C:从生命的角度看,智能是生命适应自然界的基本能力D:目前,人类智能是自然只能的最高层次答案: 【细菌不具有智能】2、判断题:目前,智能的定义已经明确,其定义为:智能是个体能够主动适应环境或针对问题,获取信息并提炼和运用知识,理解和认识世界事物,采取合理可行的(意向性)策略和行动,解决问题并达到目标的综合能力。
()选项:A:错B:对答案: 【错】3、判断题:传统人工智能领域将人工智能划分为强人工智能与弱人工智能两大类。
所谓强人工智能指的就是达到人类智能水平的技术或机器,否则都属于弱人工智能技术。
()选项:A:错B:对答案: 【对】4、判断题:人类历史上第一个人工神经元模型为MP模型,由赫布提出。
()选项:A:对B:错答案: 【错】5、单选题:下列关于数据说法错误的是()选项:A:数据可以分为模拟数据和数字数据两类B:数据就是描述事物的符号记录,是可定义为有意义的实体C:我们通常所说的数据即能够直接作为计算机输入的数据是模拟数据D:在当今社会,数据的本质是生产资料和资产答案: 【我们通常所说的数据即能够直接作为计算机输入的数据是模拟数据】6、多选题:下列关于大数据的说法中正确的有()选项:A:大数据具有多样、高速的特征B:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产C:大数据带来的思维变革中,更多是指更多的随机样本D:“大数据时代”已经来临答案: 【大数据具有多样、高速的特征;“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产;“大数据时代”已经来临】7、判断题:大数据在政府公共服务、医疗服务、零售业、制造业、以及涉及个人位置服务等领域都将带来可观的价值。
()选项:A:对B:错答案: 【对】8、多选题:人工智能在各个方面都有广泛应用,其研究方向也众多,下面属于人工智能研究方向的有()选项:A:知识图谱B:模式识别C:语音识别D:机器学习答案: 【知识图谱;模式识别;语音识别;机器学习】9、判断题:机器人发展经历了程序控制机器人(第一代)、自适应机器人(第二代)、智能机器人(现代)三代发展历程。

基于遗传算法和模糊积分的多分类器集成
姚明海;李澎林
【期刊名称】《计算机应用与软件》
【年(卷),期】2003(020)008
【摘要】多分类器联合是解决复杂模式识别问题的有效办法.模糊积分是其中一种多分类器联合方法.但是对于模糊积分,如何计算模糊积分密度是一个尚未解决的问题.本文提出了一种基于模糊积分和遗传算法的分类器集成方法,该方法利用遗传算法计算模糊积分密度函数,再利用模糊积分把分类器输出信息联合起来.实验结果表明,该方法比其他方法能够得到更好的识别性能.
【总页数】3页(P66-68)
【作者】姚明海;李澎林
【作者单位】浙江工业大学信息工程学院,杭州,310032;浙江工业大学信息工程学院,杭州,310032
【正文语种】中文
【中图分类】TP31
【相关文献】
1.基于模糊积分多分类器融合的JPEG图像隐写算法识别 [J], 李开达;张涛;李星
2.基于Sugeno模糊积分的多分类器融合方法在多属性决策中的应用 [J], 侯帅;韩中庚;黄洁;于俊杰
3.基于模糊积分的多分类器融合文本分类研究 [J], 邹晴;钮焱;李军
4.基于模糊积分和粒子群算法的多分类器融合 [J], 陈曦;赵志伟
5.基于多分类器多模糊积分的信息融合方法 [J], 段宝彬;孙梅兰
因版权原因,仅展示原文概要,查看原文内容请购买。
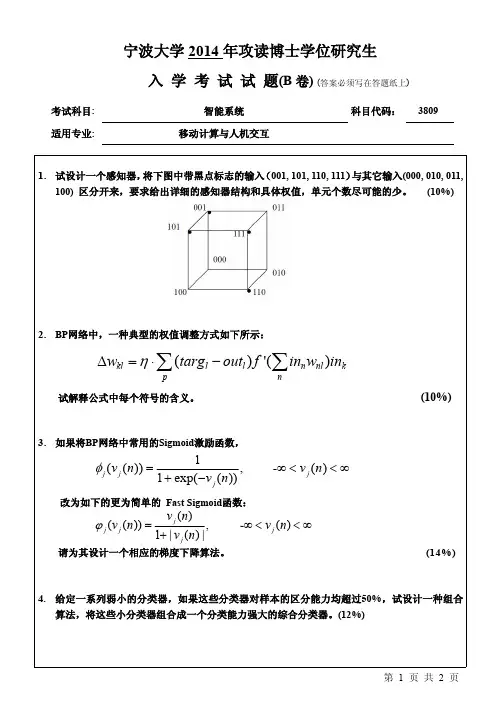

精选全文完整版(可编辑修改)人工智能导论测试题库及答案1、在关联规则分析过程中,对原始数据集进行事务型数据处理的主要原因是。
A、提高数据处理速度B、节省存储空间C、方便算法计算D、形成商品交易矩阵答案:C2、计算机视觉可应用于下列哪些领域()。
A、安防及监控领域B、金融领域的人脸识别身份验证C、医疗领域的智能影像诊断D、机器人/无人车上作为视觉输入系统E、以上全是答案:E3、1943年,神经网络的开山之作《A logical calculus of ideas immanent in nervous activity》,由()和沃尔特.皮茨完成。
A、沃伦.麦卡洛克B、明斯基C、唐纳德.赫布D、罗素答案:A4、对于自然语言处理问题,哪种神经网络模型结构更适合?()。
A、多层感知器B、卷积神经网络C、循环神经网络D、感知器答案:C5、图像的空间离散化叫做:A、灰度化B、二值化C、采样D、量化答案:C6、()越多,所得图像层次越丰富,灰度分辨率高,图像质量好。
A、分辨率B、像素数量C、量化等级D、存储的数据量答案:C7、一个完整的人脸识别系统主要包含人脸图像采集和检测、人脸图像特征提取和人脸识别四个部分。
A、人脸分类器B、人脸图像预处理C、人脸数据获取D、人脸模型训练答案:B8、下列不属于人工智能学派的是()。
A、符号主义B、连接主义C、行为主义D、机会主义答案:D9、关于正负样本的说法正确是。
A、样本数量多的那一类是正样本B、样本数量少的那一类是负样本C、正负样本没有明确的定义D、想要正确识别的那一类为正样本答案:D10、以下不属于完全信息博弈的游戏有()。
A、井字棋B、黑白棋C、围棋D、桥牌答案:D11、下列关于人工智能的说法中,哪一项是错误的。
A、人工智能是一门使机器做那些人需要通过智能来做的事情的学科B、人工智能主要研究知识的表示、知识的获取和知识的运用C、人工智能是研究机器如何像人一样合理思考、像人一样合理行动的学科D、人工智能是研究机器如何思维的一门学科答案:D12、认为智能不需要知识、不需要表示、不需要推理;人工智能可以像人类智能一样逐步进化;智能行为只能在现实世界中与周围环境交互作用而表现出来。



机器学习知识:机器学习中的模型融合随着人工智能技术的快速发展,机器学习成为了越来越多领域的关键技术之一。
在机器学习模型的设计和应用中,一个重要但容易被忽视的问题是如何将多个模型进行融合,以达到更好的预测性能和更好的效果。
本文将对机器学习中的模型融合进行详细介绍和分析。
一、什么是模型融合模型融合简单来说就是将多个不同的模型结合在一起,生成一个更强大、更具有鲁棒性的预测模型。
通常情况下,一个单独的模型可能无法完全符合预测目标,因为不同的算法或模型对于不同的特征有不同的偏好和约束条件。
因此,将多个模型结合起来可以在各自优势的基础上,弥补彼此的劣势,从而提高了预测性能和准确度。
通常情况下,模型融合可以分为三类:Bagging、Boosting和Stacking。
Bagging通常使用的算法是随机森林(Random Forest),在此基础上会采用“自举法”(Bootstrap)的方式,将随机抽取的数据集,分配给多个随机森林,从而得到多个不同的分类器。
这些分类器进行预测后,结果进行投票决定最终的分类结果。
Boosting的算法核心是Adaboost,在根据数据训练出一个模型后,会对错误分类的样本给予更高的权重,从而让后续的模型能够“更具针对性、更注重误差的修正”。
Stacking又被称为Staked Generalization,它的核心思想是“用一些基本模型产生的预测结果来作为输入,然后拟合一个模型来学习哪些输出是最好的”。
这种方法需要同时训练两个模型,一个是基础模型,另一个是元模型(Meta-model)。
二、模型融合的优势与缺陷模型融合的最大优势在于可以通过不同方法和优化模型性能,将多个不同模型的优点进行结合,从而获得更高的预测效果。
在处理大量数据和较为复杂的预测任务时,模型融合表现出了极大的优势,可显著提高模型预测的准确性和有效性,同时,还可大大降低模型的误差率,从而提高了算法模型的可靠性和泛化性能,在解决多元分类问题上表现出色。

多分类模型多分类模型全名:多类别图像分类的经典模型一、LeNet网络1. LeNet5模型结构一共7层,3个卷积层,2个池化层,3个全连接层,输入图像大小为32*32(灰度图——单通道)。
C1:6个5*5的卷积核C3:60个5*5的卷积核(为什么不是16*6个5*5的卷积核,下文会给出解释)C5:120*16个5*5卷积核两个池化层S2和S4:都是2*2的平均池化,并添加了非线性映射第一个全连接层:84个神经元(为什么不是2的整数次幂,解释见下文)第二个全连接层:10个神经元2. LeNet5的工程技巧(1) C3层与S2层之间非密集的特征图连接关系:打破对称性,同时减少计算量,共60组卷积核。
图2 C3层特征图与S2层特征图之间的连接关系(2) 全连接层的设计倒数第2层维度不是常见的2的指数次幂的维度,而是84,为什么?计算机中字符的编码是ASCII编码,这些图是用7*12大小的位图表示,84可以用于对每一个像素点的值进行估计。
二、AlexNet网络1. AlexNet模型结构C1:96*3个11*11卷积核C2:256*96个5*5卷积核C3:384*256个3*3卷积核C4:384*384个3*3卷积核C5:256*384个3*3卷积核全连接层F1,F2,Output神经元数量:4096,4096,10002. AlexNet工程技巧多GPU训练:尽量使用更多特征图,并减少计算量。
除了将模型的神经元进行了并行,还使得通信被限制在了某些网络层。
第三层卷积要使用第二层所有的特征图,但是第四层却只需要同一块GPU中的第三次的特征图。
ReLU激活函数:加快模型收敛。
LRN归一化:抑制反馈较小的神经元,放大反馈较大的神经元,增强模型泛化能力Dropout正则化:防止过拟合,提高泛化能力。
重叠池化:更有利于减轻过拟合。
数据增强:提高模型泛化能力。
测试时增强:指的是在推理(预测)阶段,将原始图片进行水平翻转、垂直翻转等数据增强操作,得到多张图分别进行推理,再对结果融合。

一、单选题1、下列哪位是人工智能之父?( )A.Marniv Lee MinskyB.HerbertA.SimonC.Allen NewellD.John Clifford Shaw正确答案:A2、根据王珏的理解,下列不属于对问题空间W的统计描述是( )。
A.一致性假设B.划分C.泛化能力D.学习能力正确答案:D3、下列描述无监督学习错误的是( )。
A.无标签B.核心是聚类C.不需要降维D.具有很好的解释性正确答案:C4、下列描述有监督学习错误的是( )。
A.有标签B.核心是分类C.所有数据都相互独立分布D.分类原因不透明正确答案:C5、下列哪种归纳学习采用符号表示方式?( )A. 经验归纳学习B.遗传算法C.联接学习D.强化学习正确答案:A6、混淆矩阵的假正是指( )。
A.模型预测为正的正样本B.模型预测为正的负样本C.模型预测为负的正样本D.模型预测为负的负样本正确答案:B7、混淆矩阵的真负率公式是为( )。
A.TP/(TP+FN)B.FP/(FP+TN)C.FN/(TP+FN)D.TN/(TN+FP)正确答案:D8、混淆矩阵中的TP=16,FP=12,FN=8,TN=4,准确率是( )。
A.1/4B.1/2C.4/7D.4/6正确答案:B9、混淆矩阵中的TP=16,FP=12,FN=8,TN=4,精确率是( )。
A.1/4B.1/2C.4/7D.2/3正确答案:C10、混淆矩阵中的TP=16,FP=12,FN=8,TN=4,召回率是( )。
A.1/4B.1/2C.4/7D.2/3正确答案:D11、混淆矩阵中的TP=16,FP=12,FN=8,TN=4,F1-score是( )。
A.4/13B.8/13C.4/7D.2/30.00/2.00正确答案:B12、EM算法的E和M指什么?( )A.Expectation-MaximumB.Expect-MaximumC.Extra-MaximumD.Extra-Max正确答案:A13、EM算法的核心思想是?( )A.通过不断地求取目标函数的下界的最优值,从而实现最优化的目标。
————————————————————————————————————————————————多类型分类器融合的文本分类方法研究作者李惠富,陆光机构东北林业大学信息与计算机工程学院基金项目黑龙江省自然科学基金资助项目(F201201)预排期卷《计算机应用研究》2019年第36卷第3期摘要传统的文本分类方法大多数使用单一的分类器,而不同的分类器对分类任务的侧重点不同,就使得单一的分类方法有一定的局限性,同时每个特征提取方法对特征词的考虑角度不同。
针对以上问题,提出了多类型分类器融合的文本分类方法。
该模型使用了word2vec、主成分分析、潜在语义索引以及TFIDF特征提取方法作为多类型分类器融合的特征提取方法。
并在多类型分类器加权投票方法中忽略了类别信息的问题,提出了类别加权的分类器权重计算方法。
通过实验结果表明,多类型分类器融合方法在二元语料库、多元语料库以及特定语料库上都取得了很好的性能,类别加权的分类器权重计算方法比多类型分类器融合方法在分类性能方面提高了1.19%。
关键词文本分类;分类器融合;主成分分析;潜在语义索引作者简介李惠富(1992-),男,黑龙江讷河人,硕士研究生,主要研究方向为文本挖掘;陆光(1963年-),男(通信作者),副教授,博士,主要研究方向为电子商务与系统开发(lg603@).中图分类号TP391访问地址/article/02-2019-03-005.html发布日期2018年4月17日引用格式李惠富, 陆光. 多类型分类器融合的文本分类方法研究[J/OL]. 2019, 36(3). [2018-04-17]./article/02-2019-03-005.html.第36卷第3期 计算机应用研究V ol. 36 No. 3 优先出版Application Research of ComputersOnline Publication——————————基金项目:黑龙江省自然科学基金资助项目(F201201)作者简介:李惠富(1992-),男,黑龙江讷河人,硕士研究生,主要研究方向为文本挖掘;陆光(1963年-),男(通信作者),副教授,博士,主要研究方向为电子商务与系统开发(lg603@ ).多类型分类器融合的文本分类方法研究 *李惠富,陆 光†(东北林业大学 信息与计算机工程学院, 哈尔滨 150040)摘 要:传统的文本分类方法大多数使用单一的分类器,而不同的分类器对分类任务的侧重点不同,就使得单一的分类方法有一定的局限性,同时每个特征提取方法对特征词的考虑角度不同。
基于模糊积分和遗传算法的分类器组合算法
李玉榕;乔斌;蒋静坪
【期刊名称】《计算机工程与应用》
【年(卷),期】2002(038)012
【摘要】将多个分类器进行组合能提高分类精度.基于模糊测度的Sugeno和Choquet积分具有理想的特性,因此该文利用其进行分类器组合.然而在实际中难以求得模糊测度.该文利用两种方法求取模糊测度,一是分类器对样本数据的分类能力,另一种是根据遗传算法.这两种方法均考虑了每个分类器对不同类的分类能力不同这一经验知识.实验中对UCI中的几个数据库进行了测试,同时将该组合方法应用于一多传感器融合工件识别系统.测试结果表明了该算法是一种计算简便、精度较高的分类器组合方法.
【总页数】4页(P119-121,140)
【作者】李玉榕;乔斌;蒋静坪
【作者单位】福州大学电气工程系,福州,350002;浙江大学电气工程学院,杭
州,310027;浙江大学电气工程学院,杭州,310027
【正文语种】中文
【中图分类】TP301.6
【相关文献】
1.基于模糊积分多分类器融合的JPEG图像隐写算法识别 [J], 李开达;张涛;李星
2.分类器动态组合及基于分类器组合的集成学习算法 [J], 付忠良;赵向辉
3.基于遗传算法和模糊积分的多分类器集成 [J], 姚明海;李澎林
4.基于模糊积分的多分类器组合的入侵检测 [J], 孙钢;张莉;郭军
5.基于模糊积分和粒子群算法的多分类器融合 [J], 陈曦;赵志伟
因版权原因,仅展示原文概要,查看原文内容请购买。
基于高斯混合模型的遥感影像连续型朴素贝叶斯网络分类器陶建斌,舒宁,沈照庆(武汉大学遥感信息工程学院,武汉430079)摘要:提出了一种新的嵌入高斯混合模型(GM M,Gaussian M ixt ure M odel)遥感影像朴素贝叶斯网络模型GM M NBC(GM M based Na ve Bayesian Classif ier)。
针对连续型朴素贝叶斯网络分类器中假设地物服从单一高斯分布的缺点,该方法将地物在特征空间的分布用高斯混合模型来模拟,用改进EM算法自动获取高斯混合模型的参数;高斯混合模型整体作为一个子节点嵌入朴素贝叶斯网络中,将其输出作为节点(特征)的中间类后验概率,在朴素贝叶斯网络的框架下进行融合获得最终的类后验概率。
对多光谱和高光谱数据的分类实验结果表明,该方法较传统贝叶斯分类器分类效果要好,且有较强的鲁棒性。
关键词:朴素贝叶斯分类器;高斯混合模型;EM算法;子高斯;遥感影像;分类doi:10.3969/j.issn.1000-3177.2010.02.004中图分类号:T P79 文献标识码:A 文章编号:1000-3177(2010)108-0018-071 引 言在用最大似然法或连续型朴素贝叶斯网络分类器对影像分类时,要假定遥感影像中的各类地物服从单一高斯分布(在多维空间中呈超椭球体)。
然而由于遥感信息本质上的复杂性和随机性,当样本点的概率密度比较离散、训练样本的选取不充分或不具有代表性时,会导致样本点不符合预先假设的参数化分布密度[1],并可能表现为任意的形状。
这直接导致各个高斯分布间的重叠及分类混淆的增大。
高斯混合模型是一种对数据的 真实分布进行模拟和逼近的半参数表达模型,它将数据的概率密度函数用多个高斯函数的凸函数(多个高斯函数的线性组合)来表示,在有充分样本的前提下能模拟任意形状的分布。
GM M广泛应用于说话人确认[2]、混合像元分解[3]、图像分割[4]、监督分类[5]等方面。