Uniprot数据库介绍及信息检索下载指南
- 格式:docx
- 大小:509.91 KB
- 文档页数:5

uniprot数据库名词解释
uniprot数据库名词解释形式可以采用以下方式进行:
1. 通俗易懂的形式,用简单易懂的语言解释名词的意义。
例如:UniProt数据库是一个全球公认的蛋白质信息库,包括大量蛋白质的序列、结构、功能等信息。
2. 专业术语表达形式,使用专业术语解释名词的含义。
例如:Uniprot数据库是一种生物信息学数据库,为研究人员提供了蛋白质序列、组成、功能及相互作用等信息。
3. 举例说明形式,通过实际案例展示名词所代表的含义。
例如:Uniprot数据库中包括了各种生物物种的蛋白质信息,例如P53蛋白等。
总的来说,uniprot数据库名词解释形式需要简明扼要,准确清晰,便于读者理解。

uniprot使用方法一、什么是UniProt?UniProt(Universal Protein Resource)是一个全球性的蛋白质数据库,致力于提供蛋白质序列、结构、功能和概述相关信息的公共资源。
UniProt 由三个组件组成:UniProtKB、UniRef和UniParc。
其中,UniProtKB是最主要的组件,它包含了三个子数据库:Swiss-Prot、TrEMBL和PROSITE。
1. Swiss-Prot:Swiss-Prot是一个经过人工注释和校正的蛋白质序列数据库,提供了详细的蛋白质功能和注释信息。
2. TrEMBL:TrEMBL是一个基于计算的蛋白质序列数据库,它包含了从未经过详细注释的Swiss-Prot数据集中的序列。
这些序列待进一步注释和校正后会被转移到Swiss-Prot数据库中。
3. PROSITE:PROSITE是一个用于识别蛋白质序列中保守结构域和模体的数据库。
它提供了一系列的蛋白质域和模体的特征模式和描述。
UniRef是一个聚类蛋白质序列数据库,用于提高蛋白质注释效率,减少重复注释。
UniParc是一个蛋白质数据库,用于记录已知和未知蛋白质序列的标识符。
二、使用UniProt的步骤使用UniProt数据库可以帮助研究者快速获取蛋白质信息,查找已知蛋白质、发现新的蛋白质序列和结构等。
以下是使用UniProt的步骤:1. 访问UniProt官方网站,地址为2. 在搜索框中输入要查询的蛋白质名称、序列或标识符等关键词,并选择搜索类型。
3. 点击“搜索”按钮进行搜索。
4. UniProt将会显示与搜索关键词相关的蛋白质信息列表。
用户可以根据需求筛选蛋白质数据库(如Swiss-Prot或TrEMBL)或其他过滤条件,以缩小搜索范围。
5. 点击感兴趣的蛋白质条目,将显示该蛋白质的详细信息页面。
用户可以阅读蛋白质的注释信息、功能描述、序列特征、结构域、文献引用等内容。
6. 若需要进一步了解蛋白质的结构、亚细胞定位等信息,用户可以点击相关链接或标签,以跳转到其他相关数据库或工具。

联合目录数据库检索指南联合目录数据库检索的目的主要解决依据文摘记录中提供的文献出处索取全文问题。
通过联合目录数据库查询我们可以知道某条文摘所在期刊的收藏单位,以便向其提取全(原文)。
同时也可做文献检索。
一.CALIS联合书目数据库(中、外文期刊、图书及会议文献收藏单位均可查询)CALIS(China Academic Library & Information System:中国高等教育文献保障体系)联合书目数据库是全国“211工程”100所高校图书馆馆藏联合目录数据库,是CALIS在“九五”期间重点建设的数据库之一。
它的主要任务是建立多语种书刊联合目录数据库和联机合作编目、资源共享系统,为全国高校的教学科研提供书刊文献资源网络公共查询。
(opac:online public access catalogue) 1.登录网站:/advanceSearch.do检索中文期刊或其它出版物馆藏信息检索外文期刊或其它出版物馆藏信息2.选择字段:如果查询期刊文献馆藏信息,选择“题名”或“ISSN”字段,在对话框内输入期刊名称(中、英文均可)或ISSN(国际标准刊号);如果查询会议文献馆藏信息,可选择“会议名称”字段;如果查询图书文献馆藏信息,可选择“题名”在对话框内输入会议题名(中、英文均可)。
3.选择检索词匹配程度:英文期刊通常选择“包含”,中文期刊通常选择“精确匹配”。
4.选择语种:在“数据库”后的选项内选择所查期刊或会议出版物的语种。
系统提供:全部、中文、西文、日文、俄文5个选项。
5.输入检索词:如果查询期刊文献馆藏信息,选择“期刊题名”或“ISSN”字段,在对话框内输入期刊名称(中、英文均可)或ISSN(国际标准刊号);如果查询会议文献馆藏信息,可选择“会议名称”字段,在对话框内输入会议题名(中、英文均可)。
尽量输入检索词全称,常用缩写词也可以识别。
例如:输入的中文期刊名称为:《机械制造》,语种选择:“中文”;输入的英文期刊名称为:international journal, manufacturing, technology,语种选择:“西文”6.检索词逻辑组配关系:通常选择“AND”。

Nucleic Acids Research, 2004, Vol. 32, Database issue D115-D119© 2004 Oxford University PressUniProt:蛋白质的全信息数据库摘要为了给科学界提供一个专门,集中,权威的蛋白质序列和功能的信息资源,瑞士-Prot,TrEMBL 和PIR蛋白质数据库已经合作组成了蛋白质的全信息数据库 (UniProt)。
我们的目的是用广泛的对照和询问接口来提供一个全面的,分类完全的,丰富并且准确的蛋白质序列信息。
中心数据库将有两个部分:符合熟悉的瑞士-Prot(完全手工操作入口)和TrEMBL(使用丰富的自动化的分类,注释和广泛的对照)。
为方便序列查寻,UniProt也提供几个无冗余的序列数据库。
UniProt NREF(UniRef)数据库为高效率的搜寻提供适当的蛋白质的全信息数据库的代表性的子集。
全面的UniProt 档案(UniParc)每天从很多公共来源数据库更新。
数据库那些UniProt接口可在线访问()或者以几个形式下载(ftp:///pub)。
我们鼓励科学界人士向UniProt 提供数据。
介绍近来,瑞士-Prot + TrEMBL和PIR-PSD如同蛋白质数据库不同的序列信息覆盖面和注释优势共存。
2002年,在生物信息科学(SIB)的瑞士研究所和欧洲生物信息科学研究所的瑞士-Prot + TrEMBL 组 (EBI)和蛋白质信息资源(PIR)组织在乔治敦大学医学中心和国家生物医学的研究基金会联合协作。
新联合的组织的主要任务是通过建立一个综合,详细分类,丰富并且准确注释蛋白质序列的优质的数据库和广泛序列对比和询问服务的到科学团体免费接口—knowledgebase来支持生物学的研究。
UniProt 将在组织成员多年合作的坚实基础上建立起来。
UniProt 数据库包括3 个数据库层:1、UniProt 档案(UniParc),通过储存全部可公开得到的蛋白质序列数据供一个稳定,综合,无冗余的序列收集。

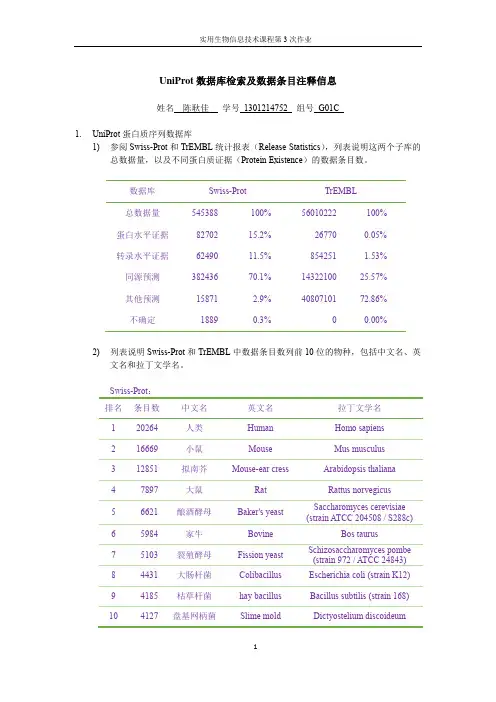
UniProt 数据库检索及数据条目注释信息姓名 陈耿佳 学号 1301214752 组号 G01C1. UniProt 蛋白质序列数据库1) 参阅Swiss-Prot 和TrEMBL 统计报表(Release Statistics ),列表说明这两个子库的总数据量,以及不同蛋白质证据(Protein Existence )的数据条目数。
数据库 Swiss-Prot TrEMBL 总数据量 545388100%56010222100% 蛋白水平证据 8270215.2%267700.05% 转录水平证据 6249011.5%854251 1.53% 同源预测 38243670.1%1432210025.57% 其他预测 158712.9%4080710172.86% 不确定 18890.3%00.00%2) 列表说明Swiss-Prot 和TrEMBL 中数据条目数列前10位的物种,包括中文名、英文名和拉丁文学名。
Swiss-Prot :排名 条目数 中文名 英文名 拉丁文学名1 20264 人类 Human Homo sapiens2 16669 小鼠 Mouse Mus musculus3 12851 拟南芥 Mouse-ear cress Arabidopsis thaliana4 7897 大鼠 RatRattus norvegicus 5 6621 酿酒酵母 Baker's yeast Saccharomyces cerevisiae (strain ATCC 204508 / S288c)6 5984 家牛 Bovine Bos taurus7 5103 裂殖酵母 Fission yeast Schizosaccharomyces pombe (strain 972 / ATCC 24843)8 4431 大肠杆菌Colibacillus Escherichia coli (strain K12) 9 4185 枯草杆菌 hay bacillus Bacillus subtilis (strain 168)10 4127 盘基网柄菌 Slime moldDictyostelium discoideumTrEMBL :排名 条目数 中文名英文名 拉丁文学名1 590031 人类免疫缺陷病毒 Human immunodeficiency virus 1 --2 352018 海洋沉积物宏基因组marine sediment metagenome --3 217903 非培养细菌 uncultured bacterium --4 115939人类 Human Homo sapiens 5 105994 小麦 Wheat Triticum aestivum6 96773 粳稻 Rice Oryza sativa subsp. japonica7 92711 丙型肝炎病毒 Hepatitis C virus --8 81523 乙型肝炎病毒Hepatitis B virus -- 9 73928 大豆Soybean Glycine max 10 73055 矿山排水宏基因组 mine drainage metagenome --3) 列表说明以下已基本完成基因组测序的重要模式生物数据条目数总数N 、已审阅序列条目数Nr 、具有蛋白质证据的序列条目数Np 、在参考序列数据库RefSeq 中具有mRNA 序列的序列条目数Nm 、在蛋白质结构数据库PDB 中具有结构的序列条目数Nb 。


数据库高级检索及数据条目注释信息姓名学号编号日期1.人珠蛋白家族检索1)写出从数据库中检索已审阅的人珠蛋白()家族个亚基的步骤。
2)列表说明这个珠蛋白的登录号、蛋白质名称、和序列长度。
3)与血红蛋白亚基差异最大的序列是哪个?相同位点百分比?4)与血红蛋白亚基差异最小的序列是哪个?差异位点共多少个?3.列表说明从数据库中检索以下序列条目的步骤和结果:1)所有拟南芥序列2)已审阅拟南芥序列3)已审阅拟南芥序列中具有蛋白质证据的序列4)已审阅拟南芥序列中具有蛋白质证据、且具有跨膜螺旋的序列5)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋和信号肽的序列6)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋和信号肽、并具有二硫键的序列7)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋、信号肽、二硫键,且已经测定三维结构的序列3.课题相关蛋白检索1)数据库中与你研究课题相关的物种共有多少序列条目2)其中已审阅的序列条目有多少3)上述已审阅的序列条目中具有蛋白质证据的有多少4)上述具有蛋白质证据的条目中与你们实验室研究方向相关的有多少5)上述具有与你们实验室研究方向相关的序列中与你课题相关的有多少4.血红蛋白注释信息(请在认真查看注释信息基础上用中文总结,不要用屏幕拷贝)1)以人血红蛋白亚基为例,说明该序列条目包括几类相关文献。
2)以人血红蛋白亚基为例,说明该序列条目包括几类注释信息。
3)以人血红蛋白亚基为例,说明该序列条目包括哪些特征位点信息。
4)以人血红蛋白亚基为例,说明该序列条目包括哪几类数据库交叉链接,其中你最感兴趣的有哪些数据库。
5.豌豆内膜蛋白注释信息(请在认真查看注释信息基础上用中文总结,不要用屏幕拷贝)1)以豌豆内膜蛋白为例,说明该序列条目包括哪些注释信息。
2)通过注释信息或高级检索,查找拟南芥中与属于同一家族的内膜蛋白。
3)通过查看注释信息和多序列比对,找出拟南芥中的直系同源蛋白。
4)查看的注释信息,特别是拟南芥专门数据库和,并与的注释信息进行比较,说明如何将模式生物研究结果用于非模式生物。

用uniprot检索蛋白序列
Uniprot是世界上最大的蛋白质数据库之一,包括了大量的蛋白质序列、功能、结构和相互作用等信息。
在进行生物信息学研究的过程中,常常需要从Uniprot中检索蛋白质序列,以便进行后续的分析和研究。
在使用Uniprot检索蛋白序列时,首先需要进入Uniprot网站并进行
注册,注册完成后,即可开始使用Uniprot提供的各种功能。
在检索
蛋白序列之前,可以先根据需要设置相关的检索条件,例如蛋白名称、序列长度、生物学功能、亚细胞定位和物种等信息,以提高检索效率
和准确性。
在输入检索条件后,Uniprot会返回符合条件的蛋白质列表,用户可
以根据需要选择感兴趣的蛋白质进行查看和下载。
同时,Uniprot还
提供了详细的蛋白质信息,包括基因名称、功能注释、结构域、同源
序列、文献引用和序列特性等,这些信息可以帮助研究人员更深入地
了解蛋白质的生物学特性和功能。
Uniprot不仅提供了蛋白质序列的检索和下载服务,还提供了多种工
具和数据库,例如序列比对、序列注释、蛋白结构、基因本体论、互
作网络和化学生物学等,这些工具和数据库可以帮助研究人员深入地
探究蛋白质的结构和功能。
同时,Uniprot还定期更新数据库,保持
其信息的完整性和准确性。
综上所述,Uniprot是一个非常有价值的蛋白质数据库,在生物信息学研究中发挥着重要的作用,可以帮助研究人员更加深入地了解蛋白质的生物学特性和功能。
同时,通过Uniprot检索蛋白序列,研究人员可以为后续的生物信息学研究提供有力的支持和帮助。

uniprot数据库的主要内容UniProt数据库是世界上最大的蛋白质数据库,它是由世界著名的蛋白质信息学会联合维护的,是生物信息学家和生物药学研究者在研究蛋白质活性方面的一个重要数据库。
它涵盖了基因组、转录组、蛋白质组等多方面的知识,提供了蛋白质的基本结构组成、功能活性、交互作用等方面的声明与数据库的查询服务。
UniProt数据库包括4个不同的模块:UniProtKB、UniParc、UniRef和UniMes,每个模块都具有独特的功能。
UniProtKB模块是最大的,它是一个蛋白质的全面数据库,包括蛋白质的基本结构、功能活性、交互作用以及疾病相关基因等,可以提供蛋白质的参考标准信息。
UniParc模块是数据库中蛋白质序列的记录模块,其主要功能是记录蛋白质序列,方便他人引用。
UniRef模块主要是提供蛋白质优化等功能,它可以帮助研究者进行结构性分析和比较,以提高蛋白质结构的理解能力。
最后,UniMes模块收集来自多个信息源的全球蛋白质实验数据,以及关于蛋白质的结构和功能的文献。
UniProt数据库一直在持续更新,它有助于研究者和生物学家获取最新的蛋白质知识和信息,以帮助他们开发新的药物和技术。
UniProt数据库的准确性和可靠性非常高,在很多生物学和医学领域,都被广泛使用。
此外,UniProt还与多家生物信息服务公司合作,提供深入的生物学应用支持,以帮助研究者更好地利用UniProt数据库中的信息。
总之,UniProt数据库是一个详尽且全面的蛋白质数据库,具有精准的数据查询服务,能够帮助生物学家和药学研究者更有效地研究和开发蛋白质的功能活性。
UniProt数据库也是一个交互友好的社区,可以使用户更好地了解数据库中的信息以及使用数据库中的数据进行研究。
实用生物信息技术课程第2次作业UniProt数据库高级检索及数据条目注释信息姓名________ 学号______________ 编号_____ 日期________1.UniProt蛋白质序列数据库1)参阅Swiss-Prot和TrEMBL统计报表(Release Statistics),列表说明这两个子库的总数据量,以及不同蛋白质证据(Protein Existence)的数据条目数。
2)列表说明以下已基本完成基因组测序的重要模式生物和你研究课题相关的物种数据条目数总数N、已审阅序列条目数Nr、具有蛋白质证据的序列条目数Np、在参考序列数据库RefSeq中具有mRNA序列的序列条目数Nm、在蛋白质结构数据库PDB中具有结构的序列条目数Ns。
2.人珠蛋白家族检索1)写出从UniProt数据库中检索已审阅的人珠蛋白(globin)家族12个亚基的步骤。
2)列表说明这12个珠蛋白的登录号、蛋白质名称、和序列长度。
3)与血红蛋白alpha亚基差异最大的序列是哪个?相同位点百分比?4)与血红蛋白beta亚基差异最小的序列是哪个?差异位点共多少个?3.列表说明从UniProt数据库中检索以下序列条目的步骤和结果:1)所有拟南芥序列2)已审阅拟南芥序列3)已审阅拟南芥序列中具有蛋白质证据的序列4)已审阅拟南芥序列中具有蛋白质证据、且具有跨膜螺旋的序列5)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋和信号肽的序列6)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋和信号肽、并具有二硫键的序列7)已审阅拟南芥序列中具有蛋白质证据、具有跨膜螺旋、信号肽、二硫键,且已经测定三维结构的序列4.利用高级检索功能,从UniProt数据库中检索你课题相关或最感兴趣的蛋白质,阅读其注释信息和相关文献,并通过数据库交叉链接,总结该蛋白质的研究进展。
5.序列条目注释信息1)以人血红蛋白alpha亚基为例,说明该序列条目的注释信息包括哪几个主要类别。
第17卷第3期2019年09月生物信息学Chinese Journal of BioinfbrmaticsVol.17No.3Sep.2019DOI:10.12113/j.issn.1672-5565.201903005UniProt蛋白质数据库简介罗静初(北京大学生命科学学院,北京100871)摘要:UniProt(https:///)是国际知名蛋白质数据库,主要包括UniProtKB知识库UniParc归档库和UniRef参考序列集三部分。
UniProtKB知识库是UniProt的核心,除蛋白质序列数据外,还包括大量注释信息。
UniProtKB知识库分Swiss-Prot和TrEMBL两个子库。
Swiss-Prot子库中50多万条序列均由人工审阅和注释,而TrEMBL子库中1.4亿多条序列是由核酸序列数据库EMBL中的蛋白质编码序列翻译所得,并由计算机根据一定规则进行注释。
UniParc归档库将存放于不同数据库中的同一个蛋白质归并到一个记录中以避免冗余,并赋予序列唯一性特定标识符。
UniRef参考序列集按相似性程度将UniProtKB和UniParc中的序列分为UniRefl00、UniRef90和UniRef50三个数据集。
UniProt网站为用户提供了高效实用的高级检索系统和大量帮助文档。
UniProt数据库每4周发布新版的同时也发布统计报表,用户可通过统计报表了解该数据库的数据量及更新情况、数据类别和物种分布等基本信息,查看常规注释信息、序列特征注释信息和数据库交叉链接等统计数据。
UniProt是目前国际上序列数据最完整、注释信息最丰富的非冗余蛋白质序列数据库,自本世纪初创建以来,为生命科学领域提供了宝贵资源。
关键词:数据库;蛋白质序列;蛋白质功能;数据库注释;数据库交叉链接;数据库高级检索中图分类号:Q51汀P392文献标志码:A文章编号:1672-5565(2019)03-131-14A brief introduction to UniProtLUO Jingchu(College of Life Sciences,Peking University,Beijing100871,China)Abstract:The Universal Protein Resource(https:///,UniProt)is a well-known protein database,which consists of the UniProt knowledgebase(UniProtKB),the UniProt unique protein identifier archive (UniParc),and the UniProt reference sequence clusters(UniRef).Apart from protein sequence data,the UniProtKB has comprehensive annotations and is the core of the database.UniProtKB/Swiss-Prot has more than500 thousand entries and is a manually reviewed and annotated subset of UniProtKB,while the UniProtKB/TrEMBL contains more than140million un-reviewed sequences which are translated from the coding sequences in the nucleotide database EMBL and computationally annotated based on certain rules.UniParc merges the same sequence stored in UniProtKB and other available protein sequence databases into a single record to avoid redundancy and gives each record a permanent and unique identifier.UniRef clusters the UniProtKB and the selected UniParc sequences into three different sets,i.e.,UniRefl00,UniRef90,and UniRef50,according to their sequence identity.The UniProt website provides users with an easy-to-use and highly efficient interface for advanced search and various help documents.The UniProt database releases statistics published online along with the update of the database every four weeks,which lists useful information such as the number of newly added and updated entries,the sequence types and their taxonomic sources,as well as general annotations,sequence features,and database cross-references.UniProt has been serving the user community of life sciences as the most-comprehensive, well-annotated,non-redundant,and freely-accessible resource of protein sequence and function since it was established at the beginning of this century.Keywords:Database;Protein sequence;Protein function;Database annotation;Database cross-reference; Database query收稿日期:2019-03-19;修回日期:2019-4-25.作者简介:罗静初,男,教授,研究方向:实用生物信息技术.E-mail:luojc@.132生勃信息学第17悪1UniProt数据库及其前身的创建历史1.1国际上最早创建的蛋白质序列数据库PIR-PSD蛋白质序列数据库的创建可以追溯到半个多世纪以前。
一、Uniprot 数据库简介Uniprot 数据库是一个重要的蛋白质序列数据库,提供了丰富的蛋白质及其功能信息。
Uniprot 数据库由三个不同的部分组成,分别是UniprotKB、Uniparc 和Uniref。
UniprotKB 是最为广泛应用的部分,包含了蛋白质的序列及其相关的注释信息。
Uniparc 是一个备份数据库,存储了由不同来源提供的蛋白质序列。
Uniref 则是对UniprotKB 中的相似蛋白进行了聚类和注释,提供了更加全面和详细的信息。
二、Uniprot 数据库的格式介绍1. UniprotIDUniprotID 是Uniprot 数据库中用来唯一标识一个蛋白质的一组字母和数字。
每一个UniprotID 对应着一个蛋白质的基本信息和功能注释。
用户可以通过UniprotID 来快速查找感兴趣的蛋白质,获取其相关信息。
2. Entry nameEntry name 是Uniprot 数据库中的另一种标识蛋白质的方式。
每一个Entry name 对应着一个蛋白质的通用名,方便用户进行简单的查询和浏览。
3. Protein nameProtein name 是Uniprot 数据库中对蛋白质的命名,包括了其组成成分和功能。
Protein name 的格式通常是由多个部分组成,包括了蛋白质的家族、亚家族、结构域和功能等信息。
4. Gene namesGene names 是Uniprot 数据库中记录的蛋白质对应的基因名称。
每一个蛋白质都可以由一个或多个基因进行编码,因此在Uniprot 数据库中也会提供蛋白质对应的基因名称。
5. OrganismOrganism 记录了蛋白质来源的生物种属信息。
在Uniprot 数据库中,蛋白质来源于不同的生物种类,因此Organism 字段可以帮助用户区分不同来源的蛋白质。
6. SequenceSequence 是Uniprot 数据库中记录蛋白质序列的部分。
【技术分享】UniProt 数据库使用指南1753 人阅读发布时间:2020-07-01 13:42在这个信息大爆炸的年代,浩瀚的信息流如同汪洋大海一般,将每个人都紧紧环绕。
如何利用已有的工具从中筛选有用信息,对我们每个人,尤其是科研人而言,尤为重要。
在免疫学,医学,药学科研和工作中,我们常常会用到蛋白数据库,关于蛋白质的结构,蛋白质质谱等数据库均较多,今天给大家分享讲讲使用频率最高且冗余度最低的uniprot数据库。
希望能对你们有所帮助~下面,菲小恩以研究得比较多的IL-6为例,分享如何有机结合数据库和产品信息。
一、查找用浏览器打开https:/// 页面,输入关键词IL-6,点击右上方的Search 按钮,然后找到需要研究的物种,就会出现该蛋白的详细信息。
二、详细信息界面首先介绍的是“Function”详细信息界面,该板块会罗列出蛋白的基本功能及参与的生物学过程。
每句介绍后的链接即是相应的参考文献,有需要可点击查阅。
三、“Names & Taxonomy” 板块随后的“Names & Taxonomy” 板块展示的是命名和来源种属信息、NCBI 和Enzembl 的基因数据库链接,可直接点击查阅。
NCBI 和Enzembl 数据库也可查询。
四、表达谱和定位之后便是与实验密切相关的重要信息:蛋白的组织细胞表达谱和亚细胞定位。
我们在进行IHC、IF 实验时,常常会遇到一个重要而棘手的问题:我看到的阳性信号是不是特异的?UniProt 就可以给予一定的支持信息,在“Expression” 板块,阐述多细胞生物中,基因(mRNA 水平/蛋白水平)在细胞/组织中的表达情况;在“Subcellular location” 板块,包含成熟蛋白在细胞中的定位和拓扑结构信息。
综合以上信息,我们不难发现,IL-6在体内是普遍存在的,在脂肪和淋巴组织中会更高。
它的亚细胞定位是内质网,细胞膜和分泌表达,那么IHC 的阳性信号主要是细胞间隙,以及细胞外围一圈和细胞内的核周围。
uniprot 蛋白库下载及添加到PD流程
Uniprot网址
/
1、打开网址
2、如果选择单个蛋白的数据库,则选择UniProtKB
3、输入蛋白名称,如breast milk,回车搜索。
结果显示有10, 395个蛋白。
4、点击download,在对话框中选择download all,FASTA文件可以选择正式蛋白,或者正式加同分异构体;选择不压缩文件。
点击GO,save。
5、如果选择下载蛋白质组,则选择Proteomes,在随后的搜索框中输入比如“Homo Spiens”(human 智人的学名),其他同上方法下载。
注意:下载过程中可能会下载不完全而显示下载完成的情况,这可能是由于网速不好造成的,可以多下载几次,比对数据库大小的差异,选择较为完整的数据库。
二、
1、打开PD软件,在任务栏点击Administration下拉的Maintain FASTA Files
2、在打开的窗口任务栏点击Add,找到所下载的数据库文件即可。
3、等待状态显示为“Completed”即为添加完成。
4、打开原有Workflow平台,在Sequest HT下更改Protein Database文件即可。
5、在菜单栏中Workflow下选择Save As Template一个新名称即可。
uniprot数据库的主要内容UniProt数据库是目前最大的蛋白质数据库,其中收录了来自世界各地的蛋白质数据。
该数据库涵盖了细菌、植物、真核生物和其他生物的蛋白质数据,并于1985年启动,现有超过160多个国家参与数据提供和收集。
本文将详细讨论UniProt数据库的主要内容。
UniProt数据库所收录的蛋白质数据可以归类为两部分:UniProtKB和UniParc。
其中,UniProtKB是一个包含了比较强的序列验证的数据库,其中收录了来自于NCBI、EMBL、DDBJ等各种蛋白质数据。
UniParc是一个精确的蛋白质序列库,其中收录了来自于UniProtKB以外的其他蛋白质数据,这些数据来自于其他基因组学和蛋白质组学项目,以及其他相关shiye。
UniProt数据库不仅提供了蛋白质序列数据,而且还提供了其他相关的信息,如附加的描述性的概述,以及特定的功能。
这些特定的功能包括:蛋白质的位置、保守度、亚结构、亚细胞定位等等。
此外,UniProt数据库还提供了许多其他的有用的信息,如蛋白质的活动、疾病关联、反应谱等。
此外,UniProt数据库对蛋白质数据进行了分类,分为各种不同的蛋白质家族、子家族、簇和单元。
这种特殊的分类方案让用户可以更加容易地查找某个特定的蛋白质信息。
除此之外,UniProt数据库还提供了一些额外的功能,比如数据可视化、数据分析、序列比对等,这些服务对于研究蛋白质不可或缺。
UniProt数据库同时也提供了一些关于蛋白质结构的有用的信息,比如蛋白质的结构和特性,以及蛋白质分子的三维结构等。
总而言之,UniProt数据库收录了来自许多来源的蛋白质数据,并提供了大量的附加功能,如数据可视化、数据分析、序列比对等。
UniProt数据库涵盖了细菌、植物、真核生物和其他生物的蛋白质信息,可以帮助生物学家们针对各种蛋白质相关的问题进行更有效的研究。
UniProt数据库
一、UniProt数据库简介
蛋白质组常用数据库——UniProt数据库,是信息最丰富、资源最广的蛋白质数据库。
它由Swiss-Prot、TrEMBL 和PIR-PSD三大数据库的数据整合而成,数据主要来自于基因组测序项目完成后,后续获得的蛋白质序列,并包含了大量来自文献的蛋白质生物功能的信息。
一般蛋白质组搜库首选数据库也是UniProt,所以对于通过UniProt库搜库的组学数据,可以在此网站中进行蛋白功能查询。
UniProt数据库可以提供的信息包括蛋白功能描述、GO条目、细胞定位、组织特异性表达情况、生理病理情况描述、互作蛋白、Domain、翻译后修饰位点等信息。
蛋白的信息描述段落均会标出引用文章,并且可以跳转到PubMed界面进行浏览。
UniProt 数据库由UniProt 知识库(UniProtKB )、UniProt 档案(UniParc )、UniProt 参考资料库(UniRef)以及UniProt元基因组学与环境微生物序列数据库(UniMES)构成。
UniProtKB全称 UniProt Knowledgebase(UniProt知识库)它是经过专家校验的数据集,主要由两部分组成:UniProtKB/Swiss-Prot (包含检查过的、手工注释的条目) 和 UniProtKB/TrEMBL (包含未校验的、自动注释的条目)。
Swiss-Prot 数据库特点高质量的、手工注释的、非冗余的数据集;主要来自文献中的研究成果和E-value校验过计算分析结果。
有质量保证的数据才被加入该数据库!TrEMBL数据集包含高质量的计算分析结果,一般都在自动注释中富集,主要应对基因组项目获得的大量数据流以人工校验在时间上和人力上的不足。
它能注释所有可用的蛋白序列。
在三大核酸数据库(EMBL-Bank/GenBank/DDBJ)中注释的编码序列都被自动翻译并加入该数据库中。
它也有来自PDB数据库的序列,以及Ensembl、Refeq和CCDS基因预测的序列。
UniParc全称是UniProt Archive(UniProt 档案),他是一个综合性的非冗余数据库,它包含了所有主要的、公开的数据库的蛋白质序列。
由于蛋白质可能在不同的数据库中存在,并且可能在同一个数据库中有多个版本,为了去冗余,UniaraParc对每条唯一的序列只存一次!无论是否为同一物种的序列,只要序列相同就被合并为一条,每条序列提供稳定的、唯一的编号UPI。
该数据库只含有蛋白质的序列信息,而没有注释数据。
UniRef(UniProt 参考资料库)可以通过序列同一性对最相近的序列进行归并,加快搜索速度。
UniRef对来自UniProtKB的各种数据包括各种剪接变异体进行了分类汇总,还从UniParc中选取了一些数据以求能完整的、没有遗漏的
收录所有数据,同时也保证没有冗余数据,该数据库的同一性(identity)分为三个级别:包括UniRef100, UniRef90和UniRef50,分别包括了相似度为100%,90%和50%的序列的总和。
UniMES是metagenomics和环境生物学的序列数据库,其中的数据可能是未知的,UniMES提供UniRef类似的聚类功能。
二、UniProt数据库信息检索
如何检索:文字检索和序列相似性(BLAST)检索。
1.首先在地址栏中输入网址https:///,跳转后页面显示如下:
2.在UniProtKB栏输入蛋白ID或Accession Number以查询蛋白功能。
例如,当我们将TP53输入功能栏后回车,界面将跳转如下,可以通过左侧的条件(物种来源、主题、数据库等)进行数据筛选过来。
通过点击“Columns”,对搜索的信息进行筛选排序,结果如下:
3.检索结果:数据库可以提供的信息包括蛋白质名、基因名、蛋白功能描述、GO注释信息、细胞定位、组织特异性表达情况、生理病理情况描述、互作蛋白、Domain、翻译后修饰位点等信息。
蛋白的信息描述段落均会标出引用文章,并且可以跳转到PubMed界面进行浏览。
4.UniProt数据库同样具有相对应的批量处理方法,可以同时搜索多个蛋白信息,对其功能进行快速浏览、筛选。
首先,打开网站后,点击“Retrieve/ID mapping”,在编辑栏中输入或上传标识符列表,点击search按钮。
编辑栏中也可以将不同类型的标识符转换为UniProt标识符,反之亦然,并下载标识符列表。
5.界面跳转后,将会显示蛋白对应的基因名、蛋白描述、序列长度等信息,可以使得蛋白功能信息批量呈现。
选中所有的蛋白,可以Download到本地,数据库提供了多种数据格式选择下载。