数据库部署步骤
- 格式:doc
- 大小:29.50 KB
- 文档页数:1

数据库安装、迁移及验证实施方案.txt
数据库安装、迁移及验证实施方案
1.引言
本方案旨在指导数据库的安装、迁移和验证过程,确保数据库系统的稳定和可靠性。
2.数据库安装
在进行数据库安装之前,需要准备以下材料和工具:
- 数据库软件安装包
- 服务器硬件
- 操作系统
- 数据库服务器配置参数
具体的数据库安装步骤如下:
1.安装操作系统并进行必要的配置。
2.安装数据库软件,并根据需求进行配置。
3.验证数据库安装成功,并确保数据库服务正常运行。
3.数据库迁移
数据库迁移是将现有数据库迁移到新的硬件或操作系统上的过程。
迁移的具体步骤如下:
1.创建数据库备份。
2.安装新的数据库服务器,并进行必要的配置。
3.将数据库备份恢复到新的数据库服务器上。
4.验证数据库迁移是否成功,确保新的数据库服务器正常运行。
4.数据库验证
数据库验证是为了确保数据库系统在安装和迁移过程后正常运行。
验证过程包括以下几个方面:
1.验证数据库连接是否正常,可以通过连接数据库并执行简单
的查询语句来验证。
2.验证数据库服务器的性能,可以通过模拟高负载环境下的并
发访问进行测试。
3.验证数据库备份和恢复功能,可以通过备份和恢复数据库进
行测试。
5.总结
本方案提供了数据库安装、迁移和验证的实施方案,通过按照
具体的步骤和方法进行操作,可以确保数据库系统的稳定和可靠性。
在实施过程中,需要严格按照方案进行操作,并进行必要的验证和
测试。

达梦数据库主备部署服务器硬件需求按实际业务需求,选择合适的服务器,参考如下:硬件要求物理内存>= 16 GB交换分区Swap空间 >= 物理内存/tmp⼤⼩> 1000MB⽹络物理机器需要 2 个⽹卡磁盘根据实际应⽤系统需要挂载合适⼤⼩磁盘时间服务器按机房要求配置连接时间服务器⽬录与存储规划:⽤途⽬录路径备注数据库软件安装⽬录/dm8可⽤空间 > 50GB实例安装⽬录/dmdata单独挂载性能最好的磁盘建议SSD 归档⽇志存放⽬录/dmarch单独挂载磁盘备份⽂件存放⽬录/dmbak单独挂载磁盘IP规划主机⽹卡 IP地址备注DM1 Eth0 192.168.2.37 对外通信DM1 Eth1 10.0.0.1 主备之间通信DM2 Eth0 192.168.2.38 对外通信DM2 Eth1 10.0.0.2 主备之间通信特别注意:所有关于dm的⽬录及下属⽬录属主和属组必须为 "dmdba" 和 "dinstall"操作步骤(主备都需要操作)1、⽤户与组groupadd dinstall //创建⽤户组useradd -g dinstall -m -d /home/dmdba -s /bin/bash dmdba //创建⽤户passwd dmdba //修改⽤户密码2、资源限制vim /etc/security/limits.conf#添加如下内容dmdba soft core unlimiteddmdba hard core unlimiteddmdba soft nofile 65536dmdba hard nofile 65536dmdba soft nproc 65536dmdba hard nproc 65536dmdba soft stack 65536dmdba hard stack 655363、⽤户环境变量vi /home/dmdba/.bash_profile //⽂件末尾添加如下内容:export DM_HOME=/dm8export PATH=$PATH:$DM_HOME/binexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$DM_HOME/bin4、安装数据库(这⾥以centos7系统安装)1)将安装包上传到服务器后使⽤ root ⽤户挂载 iso 安装包⽂件到 /mnt ⽬录下:2)切换到dmdba⽤户Su – dmdbaCd /mnt./DMInstall.bin -i①选择安装语⾔,c/C中⽂,e/E英⽂②提⽰是否安装key⽂件,输⼊y,输⼊key⽂件的位置③选择时区,21即东8区④选择安装类型,默认典型安装(包含所有内容)3)使⽤root⽤户执⾏命令/dm8/script/root/root_installer.sh4)授权属主Chown -R dmdba.dinstal /dmdata /dm8 /dmbak /dmarch5、使⽤ dminit ⼯具初始化实例cd /dm8/bin./dminit path=/dmdata page_size=326、参数优化安装完成需要调整 dm.ini ⽂件参数。

盘库管理系统的部署和配置步骤在进行盘库管理系统的部署和配置之前,首先需要明确盘库管理系统的基本概念。
盘库管理系统是一种用于管理库存,并进行盘点、统计和分析的软件系统。
它能够帮助企业实现库存的精准管理和优化,提高成本控制和效率。
一、操作系统选择和配置1.根据盘库管理系统的要求,选择适合的操作系统。
常用的操作系统有Windows、Linux和MacOS等。
根据需要选择与盘库管理系统兼容的操作系统版本。
2.为操作系统进行必要的配置和优化,确保系统运行的稳定性和性能。
二、服务器环境的配置1.选择合适的服务器软件。
常用的服务器软件有Apache、Nginx等。
根据需求选择合适的服务器软件,并进行安装和配置。
2.配置服务器的硬件环境,包括CPU、内存、磁盘空间等。
根据系统需求,确保服务器的配置满足盘库管理系统的运行需求。
3.配置服务器的网络环境,包括IP地址、子网掩码、网关等。
确保服务器能够正常与其他设备通信。
三、数据库的安装和配置1.选择合适的数据库软件。
常用的数据库软件有MySQL、Oracle、SQL Server 等。
根据需要选择与盘库管理系统兼容的数据库软件,并进行安装和配置。
2.创建数据库,并设置数据库的名称、用户名和密码等。
3.配置数据库的相关参数,包括连接数、缓冲区大小等。
根据系统需求进行优化。
四、安装盘库管理系统1.获取盘库管理系统的安装包。
可以从官方网站或授权渠道获取安装包。
2.解压安装包,并将文件复制到服务器的指定目录下。
3.根据安装指南,依次运行安装程序,并按照提示进行安装。
在安装过程中,要注意选择适当的安装选项,并填写必要的配置信息。
五、配置盘库管理系统1.启动盘库管理系统,并登录管理界面。
2.根据系统提供的配置向导,依次填写配置信息。
包括数据库连接信息、邮箱配置、短信配置等。
3.配置系统的基本参数,包括仓库信息、物料信息、供应商信息等。
根据实际情况填写相关信息,并进行保存。
4.根据需要配置用户权限和角色,确保系统的安全性和可用性。
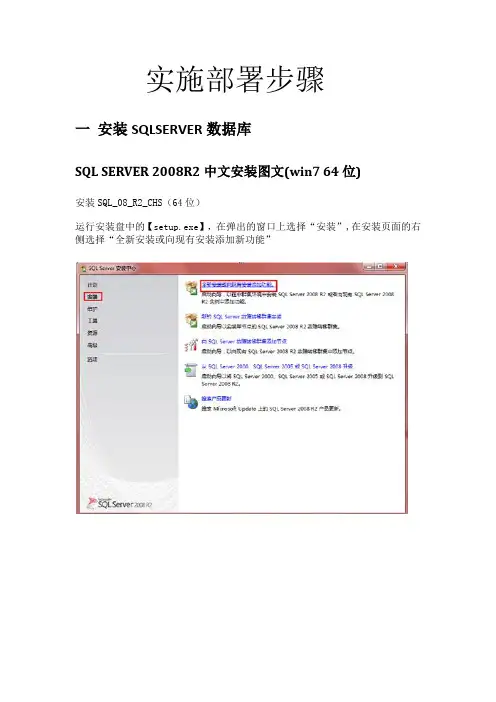
实施部署步骤一安装SQLSERVER数据库SQL SERVER 2008R2中文安装图文(win7 64位)安装SQL_08_R2_CHS(64位)运行安装盘中的【setup.exe】,在弹出的窗口上选择“安装”,在安装页面的右侧选择“全新安装或向现有安装添加新功能”弹出安装程序支持规则,检测安装是否能顺利进行,通过就点击确定,否则可点击重新运行来检查。
在弹出的【产品密钥】对话框中选择【输入产品密钥】选项,并输入SQL Server 2008 R2安装光盘的产品密钥,点击下一步。
在弹出的许可条款对话框中,勾选【我接受许可条款】,并点击下一步。
弹出【安装程序支持文件】对话框,单机【安装】以安装程序支持文件,若要安装或更新SQL Server 2008,这些文件是必须的。
点击下一步弹出【安装程序支持规则对话框】,安装程序支持规则可确定在您安装SQL Server安装程序文件时可能发生的问题。
必须更正所有失败,安装程序才能继续。
确认通过点击下一步。
勾选【SQL Server功能安装】,点击下一步。
在弹出的【功能选择】对话框中选择要安装的功能并选择【共享功能目录】,点击下一步。
弹出【安装规则】对话框,安装程序正在运行规则以确定是否要阻止安装过程,有关详细信息,请单击“帮助”。
点击下一步,出现【实例配置】对话框。
制定SQL Server实例的名称和实例ID。
实例ID将成为安装路径的一部分。
这里选择默认实例。
点击下一步弹出【磁盘空间要求】对话框,可以查看您选择的SQL Server功能所需的磁盘摘要。
点击下一步,弹出【服务器配置】对话框,指定服务账户和排序规则配置,页面中点击【对所有SQL Server服务使用相同的账户】在出现的对话框中,为所有SQL Server服务账户指定一个用户名和密码点击下一步,弹出【数据库引擎配置】对话框,选择【混合模式】,输入用户名和密码,添加【当前用户】。
“添加当前用户”,点击下一步。

在Docker容器中搭建和运行PostgreSQL数据库的步骤Docker是一种开源的容器化平台,它能够将应用程序及其依赖项打包到一个可移植的容器中。
使用Docker能够更加高效地部署和管理应用程序,提高开发和运维的效率。
本文将介绍在Docker容器中搭建和运行PostgreSQL数据库的步骤。
1. 安装Docker在开始之前,首先需要安装Docker。
可以根据操作系统类型下载相应的Docker安装包,并按照官方文档的指引完成安装。
2. 获取PostgreSQL镜像Docker提供了一个集中式的镜像仓库,称为Docker Hub。
在Docker Hub中,有很多官方和社区提供的镜像供用户使用。
我们可以搜索并获取PostgreSQL的官方镜像。
打开终端或命令行界面,并执行以下命令:```bashdocker pull postgres```这个命令会从Docker Hub上下载最新的PostgreSQL镜像。
3. 创建容器下载完成后,我们可以通过运行容器来启动PostgreSQL数据库。
执行以下命令:```bashdocker run -d --name mypg -e POSTGRES_PASSWORD=mypassword postgres```这个命令会在后台创建一个名为`mypg`的容器,并使用`mypassword`作为数据库的密码。
4. 连接到数据库现在,我们可以连接到正在运行的PostgreSQL数据库了。
执行以下命令:```bashdocker exec -it mypg psql -U postgres```这个命令将会以`postgres`用户身份连接到`mypg`容器中的PostgreSQL数据库。
5. 使用PostgreSQL通过上一步成功连接到数据库后,我们就可以进行一些基本的数据库操作了。
例如,创建数据库、创建表等。
以创建一个名为`mydb`的数据库为例,执行以下命令:```sqlCREATE DATABASE mydb;```这个命令会在当前连接的PostgreSQL数据库中创建一个名为`mydb`的数据库。

在Docker中部署和管理PostgreSQL数据库随着云计算和虚拟化技术的快速发展,Docker已成为一种热门的容器化管理工具。
它提供了一种轻量级的、可移植的部署方式,使得软件应用可以在不同的环境中运行,这也使得Docker成为部署和管理PostgreSQL数据库的理想选择。
一、安装Docker和Docker Compose首先,我们需要安装Docker和Docker Compose。
你可以在官方网站上找到对应的安装包,并按照官方说明进行安装。
二、获取PostgreSQL的Docker镜像Docker镜像是预配置的容器,其中包含了PostgreSQL数据库。
你可以通过在终端执行以下命令来获取PostgreSQL的Docker镜像:```docker pull postgres```三、创建和配置Docker Compose文件Docker Compose是一种用于定义和运行多容器的工具。
我们可以通过一个YAML文件来定义我们的容器配置。
在你的项目目录下,创建一个名为`docker-compose.yml`的文件,并写入以下配置信息:```yamlversion: '3.1'services:db:image: postgresrestart: alwaysenvironment:POSTGRES_USER: myuserPOSTGRES_PASSWORD: mypasswordPOSTGRES_DB: mydatabasevolumes:- ./data:/var/lib/postgresql/dataports:- "5432:5432"```在这个配置文件中,我们定义了一个名为`db`的服务,使用了之前拉取的PostgreSQL镜像。
我们还配置了数据库的用户名、密码和数据库名称。
`volumes`部分指定了数据库数据存储的路径,你可以根据自己的需求进行修改。

中标麒麟离线部署SqlServer数据库
⼀、环境说明
1.服务器系统:中标麒麟⾼级服务器操作系统软件V7.0 update4
2.相关软件:、
3.服务器软件相关:
⼆、安装数据库
1.将下载好的RPM包复制到中标麒麟上(直接在中标麒麟上下载的跳过这⼀步)
2.执⾏ rpm -ivh mssql-server-14.0.322
3.3-15.x86_6
4.rpm ,这是会提⽰确实依赖项
3.根据提⽰下载相应的依赖项,这⾥推荐⽤阿⾥的镜像源(能FQ的请⽆视),这⾥要说明⼀下,有的依赖像还还
需要依赖其它的依赖项,如:cyrus-sasl就依赖cyrus-sasl-lib所以下载这个rpm包还需要下载依赖的包
4.安装依赖项
根据提⽰安装好相应的依赖项,有些依赖会xx冲突,
只需要rpm –ivh xx.rpm 后⾯加上—replacefiles 表⽰替换冲突⽂件
5.解决缺少的依赖项后,尝试再次安装 mssql-server 包
6.完成 SQL Server 安装。
使⽤“mssql-conf”完成 SQL Server 安装
/opt/mssql/bin/mssql-conf setup 然后根据提⽰安装即可。

达梦数据库安装部署文档 一.数据库安装过程 1. Windows环境安装 基本上就是下一步下一步,按照默认安装就好,安装路径根据自己的要求选择;在利用我们的数据库配置助手dbca工具初始化库的过程中,需要将下图红色框选部分改为如图所示即可;详细的安装细节可以参考我们的DM7_Install_zh.pdf文档; 注意:页大小 除去Clob、Blob等大字段外,数据库中一行记录的所有字段的实际长度的和不能超过页大小的一半; 日志文件的大小 数据库redo日志文件的大小正式环境一般设置为2048; 字符串比较大小写敏感 默认为大小写敏感的,根据具体情况进行设置; 建议:在开发环境和测试环境的页大小、字符串大小写敏感这两个参数一定要保持一致,不然当涉及到用.bak文件还原的时候就会因这两个参数不一致导致无法还原; 2. Linux环境安装 在中标麒麟的系统中打开一个终端窗口,通过命令:ulimit –a查看,如下图所示: 如果open files这个参数的值为65536表示之前修改过,如果没有修改按照下面的方法进行修改; Linux系统在安装之前先确认打开文件数的那个参数的设置情况,现在在中标麒麟
6.0的操作系统上安装我们DM7数据库,在使用我们的数据库配置助手dbca进行初始化数据库时经常会碰到“打开文件数过多的问题”; 解决办法如下: 用vim打开/etc/profile文件,在该文件最后加上一行ulimit -n 65536,注意在添加的时候只需添加ulimit –n 65536即可,后面不需要标点符号;然后重启服务器即可;修改好操作系统的打开文件这个参数后就可以按照下面的安装步骤进行安装了; 详细安装流程如下:
(1) 确定当前用户是不是root用户在命令行窗口中输入: who am i,最好
在root用户下安装,否则有可能有些权限不够; (2) 进入到我们安装文件所在的目录,并赋予它777权限命令为:chmod 777 DMInstall.bin; (3) 执行安装 ./DMInstall.bin –i (4) 在安装的过程中按照提示一步一步操作,基本上选择默认的就可以了;只有在时区的选择上注意选择中国的时区; (5) 选好之后等待安装过程结束,会有相应的提示信息; (6) 初始化库,切入到我们安装目录的bin目录,一般默认安装路径为/opt/dmdbms/bin, 执行命令 ./dminit path=/opt/dmdbms/data page_size=16 log_size=2048 case_sensitive=n;当然如果我们能够直接接触到服务器的话,也可以利用桌面上我们DMDBMS文件夹里面的client文件夹里面有一个数据库配置助手初始化我们的数据库,使用方法与Windows平台相同; (7) 切入到到我们安装目录的bin目录,一般路径为/opt/dmdbms/bin, 在该目录下有个dmserverd的文件,用vim打开这个文件后, 把这一行改为如上图所示的情况path=/opt/dmdbms/data/DAMENG/dm.ini,然后保存退出; (8) 至此我们的数据库就已经安装配置完成了,现在我们可以切入到安装目录的bin,路径为/opt/dmdbms/bin,执行命令 ./dmserverd start 就可以启动我们的数据库服务了,然后就可以通过本地客户端访问服务器上的数据库了; 注:切入到安装目录的bin路径为/opt/dmdbms/bin目录后执行以下命令: ./dmserverd start 启动数据库服务; ./dmserverd stop 停止数据库服务; ./dmserverd restart重启数据库服务; 二. 操作流程介绍: 1. 服务器启动问题 一般如果服务器重启之后,我们首先得查看我们数据库服务是否正常起来,这个可以通过命令ps –ef|grep dmserver命令查看,如下图所示: 情况1: 如果打印出了以上信息表示我们数据库服务器处于正常启动状态; 情况2: 如果只打印出了一行信息,如上图所示,则表示我们数据库服务器没有起来;需要我们手动启动;手动启动步骤如下: (1) 首先切入到我们数据库的安装目录的bin目录,一般默认路径为 /opt/dmdbms/bin ,这个需要视具体安装情况而定;然后执行命令 ./dmserverd start;如下图所示: 如果打印出如下信息,表示数据库服务器启动成功; (2) 如果想停止我们的数据库服务器,同样需要切入到安装目录的bin目录,执行命令 ./dmserverd stop;如下图所示: 如果打印出如下信息,表示数据库服务器停止成功; (3) 如果想重启我们的数据库服务器,也需要切入到安装目录的bin目录,执行命令./dmserverd restart;如下图所示: 如果打印出以上信息,表示数据库服务器重启成功; 2. 创建表空间、用户和赋予权限的问题 (1) 创建表空间 可以使用我们的图形管理工具进行创建,使用非常方便;当然也可以使用SQL脚本创建,可以参考我们的DM_SQL手册的相关章节,根据自己的需求创建合适的表空间; (2) 创建用户 注意:给用户关联上相应的表空间,红色框选部分指定为之前创建的表空间; (3) 给用户授权 注意:在表空间路径的选择上最好放在我们数据库安装目录的DAMENG文件夹下面,如/opt/dmdbms/data/DAMENG/TEST.DBF;这样便于统一管理,最好不要放在其路径下面,防止人为不小心误操作将其删除;

请简述空间数据库设计的步骤。
空间数据库设计是一个庞大而复杂的过程,它包含了多个步骤。
在实际的设计工作中,需要遵循一定的流程和方法论,才能确保数据库的可靠性和高效性。
下面是空间数据库设计的步骤:1.需求分析需求分析是空间数据库设计的第一步。
在这一阶段,需要与用户和相关人员进行沟通,了解他们的需求和要求,分析他们的工作流程和数据处理过程。
这样可以确定数据库的数据类型、数据量、数据结构和功能等方面的需求。
2.数据建模数据建模是空间数据库设计的第二步。
在这一阶段,需要对需求分析的结果进行数据建模,确定数据的实体、属性和关系等方面的内容。
通常采用实体关系图(ER图)进行建模,以便直观地显示数据的结构和关系。
3.数据库设计数据库设计是空间数据库设计的核心步骤。
在这一阶段,需要具体设计数据库的结构和功能,包括数据表的设计、索引的设计、视图的设计、存储过程的设计等方面的内容。
同时,还需要考虑数据库的安全性、可靠性和性能等方面的问题。
4.数据实现数据实现是空间数据库设计的第四步。
在这一阶段,需要根据数据库设计的结果,实现数据库的结构和功能。
通常采用数据库管理系统(DBMS)进行实现,例如Oracle、SQL Server、MySQL等。
5.数据测试数据测试是空间数据库设计的第五步。
在这一阶段,需要对数据库进行测试,验证数据库的功能和性能是否符合需求。
通常采用数据抽样、数据比较、性能测试等方法进行测试,以确保数据库的稳定性和可靠性。
6.数据部署数据部署是空间数据库设计的最后一步。
在这一阶段,需要将数据库部署到实际的环境中,并进行数据迁移和数据备份等工作。
同时,还需要进行数据库的性能优化和安全加固等方面的工作,以确保数据库的高效性和安全性。
空间数据库设计是一个复杂而系统的过程,需要遵循一定的流程和方法论,才能确保数据库的可靠性和高效性。
在实际的工作中,需要注意数据建模、数据库设计、数据实现、数据测试和数据部署等方面的问题,以确保数据库的质量和稳定性。

一).创建部署项目1. 打开2011。
2.在“File”菜单上指向“New Project”。
3. 在“New Project”对话框中,选择“Installed Templates”窗格中的”Other Project Types”中的“Setup and Deployment”,然后选择“Visual Studio Installer”窗格中的“Setup Project”。
在“Name”框中键入MySetup。
4. 单击“OK”关闭对话框。
5. 项目被添加到解决方案资源管理器中,并且文件系统编辑器打开。
6. 在“Property”窗口中,选择ProductName属性,并键入数据库打包安装。
二).将主程序项目的输出添加到部署项目中1. 在“File System”中,选择“Application Folder”。
右击指向“Add”,然后选择“File”。
2. 在“Add File”对话框中,选择你程序的dll及exe文件.3. 单击“打开”关闭对话框.三).创建安装程序类1. 在“Solution Explorer”中的“Solution’MySetup’”上右键选择“Add”后选择“New Project”。
2. 在“New Project”对话框中,选择“Other Languages”窗格中的“Visual Basic“,然后选择“Class Library”。
在“Name”框中键入InstallDB。
3. 单击“OK”关闭对话框。
4. 从“InstallDB”类库下右键选择"Add”中的“New Item”。
5. 在“New Item”对话框中选择“General”后选择“Installer Class”。
在“Name”框中键入InstallDB。
6. 单击“Add”关闭对话框。
7. “InstallDB”安装程序类详细代码附后。
四).创建自定义安装对话框1. 在解决方案资源管理器中选择“MySetup”项目。

流程k2的使用与部署介绍流程k2是一款功能强大的工作流程管理系统,可以帮助企业实现流程自动化和协作。
本文将详细介绍流程k2的使用和部署步骤。
使用流程k2的优势•提高工作效率:流程k2可以将繁琐的工作流程进行自动化,减少重复性工作,提高工作效率。
•实现流程协作:流程k2可以将不同岗位的工作人员进行协作,提高工作效率和沟通效果。
•提升管理能力:流程k2可以实现对工作流程的监控和管理,帮助企业提升管理能力和业务水平。
使用流程k2的基本步骤1.登录流程k2:打开流程k2的登录页面,在用户名和密码的输入框中输入正确的账号信息,点击登录按钮进入系统。
2.创建流程:在流程k2的首页上找到创建流程的入口,点击进入流程创建页面。
根据实际需求选择流程类型,并根据流程图进行步骤的配置。
3.配置流程权限:在流程创建完成后,可以对流程的权限进行配置。
根据不同的岗位和工作人员,设置相应的权限和操作范围。
4.运行流程:在流程k2的首页上找到运行流程的入口,点击进入运行流程页面。
根据实际需求选择要运行的流程,并填写相应的表单信息。
5.监控流程:在流程k2的首页上可以查看当前正在运行的流程和已完成的流程。
可以通过监控流程来了解流程的进度和情况。
6.导出流程报表:在流程k2的首页上找到导出流程报表的入口,点击进入导出流程报表页面。
根据需要选择要导出的流程和报表类型,点击导出按钮即可生成报表。
流程k2的部署步骤1.安装流程k2:首先需要从流程k2官网下载流程k2的安装程序。
运行安装程序,并按照提示完成安装流程k2的步骤。
2.配置数据库:在安装流程k2的过程中,需要配置数据库的连接信息。
根据实际情况填写数据库的地址、用户名和密码等信息。
3.配置邮件服务器:流程k2的邮件通知功能需要配置邮件服务器的信息。
根据实际情况填写邮件服务器的地址、端口、用户名和密码等信息。
4.配置流程k2的参数:在流程k2的安装目录下,找到配置文件,根据实际情况修改配置文件中的参数。
数据库部署方案目标本文档旨在提供一个数据库部署方案,以确保系统的数据可靠性和高可用性。
该方案将基于以下几个目标:1. 提供可扩展性和容错性,以应对系统中的高负载和故障。
2. 保证数据的安全性和完整性。
3. 提供高可用性,以确保系统在故障发生时仍能正常运行。
4. 简化管理和维护任务,提高操作效率。
方案概述我们将采用主从复制的数据库架构来实现上述目标。
具体而言,我们将设置一个主数据库和多个从数据库,其中主数据库用于处理写入操作并将数据同步到从数据库。
从数据库用于处理读取操作,以减轻主数据库的负载。
同时,我们将利用自动故障转移和备份策略来提供高可用性和数据备份。
主数据库主数据库将用于处理写入操作,包括新增、修改和删除数据。
为了提供容错性和高可用性,我们建议采用主数据库集群的形式。
主数据库集群由多个节点组成,通过主-备份模式运行。
在主节点发生故障时,备份节点将会自动接管主节点的工作。
我们可以使用数据库复制技术来确保数据在主从节点之间的同步。
从数据库从数据库将用于处理读取操作,包括查询数据。
为了提供可扩展性和负载均衡,我们建议采用多个从数据库的架构。
从数据库将使用主数据库的复制功能进行数据同步。
通过将读取操作分散到多个从数据库,我们可以减轻主数据库的负载,提高系统的响应速度。
自动故障转移为了提供高可用性,我们建议配置自动故障转移机制。
具体而言,我们可以使用心跳检测机制来监测主节点的状态。
当主节点发生故障时,自动故障转移系统将会自动将备份节点切换为主节点,以确保系统的连续运行。
数据备份数据的备份是确保数据安全性和完整性的重要措施。
我们建议定期对主数据库进行备份,并将备份数据存储在安全的存储介质上。
同时,我们还可以设置增量备份和日志备份,以提高备份效率和节省存储空间。
管理和维护为了简化数据库管理和维护任务,我们建议使用数据库管理工具来自动化一些常见的操作,如备份、恢复和监测。
此外,我们还可以设置定期的数据库性能优化和索引优化任务,以提高数据库的查询效率和响应速度。
华为⾼斯数据库openGauss部署经验记录分享 华为openGauss开源是⼀个令⼈振奋的消息,本着好奇的⼼思在虚拟机linux上部署了⼀下,以下是在部署过程中记录的⼀部分安装环境配置和问题修改的⽅法。
(由于作者本⾝是⼩⽩,所以有些问题可能在⼤神看来很easy,但是对于⼩⽩来说,可能还是有个记录会⽐较有帮助。
)有⼀部分是安装ODBC环境时的问题。
废话不多说,上记录。
以下都是在参考官⽅的安装指导⽂档的前提下遇到的部分问题,其中有⼀部分问题是作者本⾝对⽂档说明没有理解到位造成的。
(实在想吐槽⼀句,有的⽂档说明实在是不清楚,多加⼏个字就能说明⽩,也可能⼩⽩理解不了⼤神的思路。
)openGauss部署⼀、安装环境部署1. 下载 openGauss server1. 安装cenos7.6CenOs-7-x86_64-DVD-1810.iso1. openGauss的软件依赖软件名称是否⾃带版本建议版本0.3.109-130.3.109-13libaio-devel否/命令:yuminstall libaio-develflex否/命令:yum2.5.37 2.5.31以上install flexbison否/安装见表格下⽅2.7-12 2.7-45.9-13.20130511 5.9-13.20130511ncurses-devel否/yum installncurses-devel2.17-307 2.17-111glibc.devel否/yum installglibc.devel.x86_64patch是 2.7.1-10 2.7.1-10bison安装:2)、将下载的⽂件传输到linux系统下,进⾏解压Tar xvzf bison-2.7.tar.gz3)、进⼊解压⽂件⽬录 ccd bison-2.74)、执⾏命令./configuremakemake installmake clean5)、验证安装bison -V1. Huawei JDK 1.8.0安装第⼆步解压安装:tar -zxvf jdk-8u201-linux-x64.tar.gz第三步配置环境:vim /etc/profile打开之后,在⽂件最后加上export JAVA_HOME=/usr/local/jdk1.8.0_231export JRE_HOME=/usr/local/jdk1.8.0_231/jreexport CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/libexport PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin第四步启动:source /etc/profile第五步验证是否安装成功:java -version1. Psmisc安装yum install psmisc1. bzip2linux系统安装之后⾃带。
图数据库NebulaGraph的安装部署:⼀个开源的分布式图数据库。
作为唯⼀能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在⾼并发场景下满⾜毫秒级的低时延查询要求,还能够实现服务⾼可⽤且保障数据安全性。
本⽂⽬录1. 简介2. Nebula 整体架构1. Meta Service2. Storage Service3. Graph Service3. 安装部署1. 单机运⾏2. 集群部署1. 环境准备2. 安装3. 配置3. 测试集群简介是开源的第三代分布式图数据库,不仅能够存储万亿个带属性的节点和边,⽽且还能在⾼并发场景下满⾜毫秒级的低时延查询要求。
不同于Gremlin 和 Cypher,Nebula 提供了⼀种 SQL-LIKE 的查询语⾔,通过三种组合⽅式(管道、分号和变量)完成对图的 CRUD 的操作。
在存储层 Nebula Graph ⽬前⽀持RocksDB和HBase两种⽅式。
感谢 Nebula Graph 社区 Committer 伊兴路供稿本⽂。
Nebula Graph整体架构Nebula Graph 主要有三个服务进程:Meta ServiceMeta Service 是整个集群的元数据管理中⼼,采⽤ Raft 协议保证⾼可⽤。
主要提供两个功能:1. 管理各种元信息,⽐如 Schema2. 指挥存储扩容和数据迁移Storage ServiceStorage Service 负责 Graph 数据存储。
图数据被切分成很多的分⽚ Partition,相同 ID 的 Partition 组成⼀个 Raft Group,实现多副本⼀致性。
Nebula Graph 默认的存储引擎是 RocksDB 的 Key-Value 存储。
Graph ServiceGraph Service 位于架构中的计算层,负责同 Console 等 Client 通信,解析 nGQL 的请求并⽣成执⾏计划。
⼿⼯部署AisinoA6的步骤⼿⼯部署Aisino A6的步骤⼀.安装JDK如果计算机上没有安装JDK1.5以上的版本,请执⾏安装盘中的ISSetupPrerequisites\Java 2 Platform Standard Edition Runtime Environment 5.0 Update 1\jre-1_5_0_01-windows-i586-p.exe ⽂件。
⼆.安装MSDE如果要使⽤MSDE作为数据库,请执⾏安装盘中的ISSetupPrerequisites\msde\setup.exe⽂件。
三.执⾏建库脚本1.启动数据库服务,通过查询分析器连接到MSDE实例或者计算机上已有的数据库实例(具体⽅法请查看《在未安装SQL Server的计算机上访问MSDE数据库的⽅法.doc》)2.将安装盘中PROGRAME\script⽬录下0.create_databases.sql⽂件中的内容拷贝到查询分析器中执⾏,创建acc_sys库和AIDataDemo库,AIDataDemo随后可以删除3.在查询分析器中选择acc_sys库,将安装盘中PROGRAME\script⽬录下1.create_acc_sys_stucture.sql⽂件中的内容拷贝到查询分析器中执⾏,在acc_sys库中创建所需的数据表4.在查询分析器中选择acc_sys库,将安装盘中PROGRAME\script⽬录下2.create_acc_sys_data.sql⽂件中的内容拷贝到查询分析器中执⾏,向acc_sys库的数据表中填充预置数据注意:此脚本中的前两条删掉,不要运⾏INSERT [accinfo]……INSERT [dbinfo]……5.在查询分析器中选择acc_sys库,执⾏以下脚本:INSERT [dbinfo] ( [dbtype] , [sysdbname] , [dbdriverclass] , [dburl] , [defaultuser] ,[defaultpassword] , [userid] , [password] , [hibernate_dialect] , [port] , [dbpath] ,[commandpath] , [dbserver_savepath] ) V ALUES ( 'SQLServer' , 'master' ,'com.microsoft.sqlserver.jdbc.SQLServerDriver' ,'jdbc:sqlserver://ip#:port#;databaseName=db#' , 'sa' , 'Password' , 'sa' , 'Password' ,'org.hibernate.dialect.SQLServerDialect' , 'TcpPort' , '127.0.0.1' , '' , '' )其中Password为数据库超级管理员sa的密码,如果是使⽤安装盘所带的MSDE作为数据库,此处Password为sa,如果是使⽤计算机上已有的数据库,请向⽤户确认密码。
建立数据库的六个步骤第一步:需求分析需求分析是建立数据库的第一步,也是最关键的一步。
在这个阶段,需要与用户和利益相关者进行密切合作,以确保数据库能够满足他们的需求。
需求分析包括以下几个方面的工作:1.收集和分析用户需求:与用户交流,了解他们对数据库的需求,包括数据类型、数据量、数据之间的关系等。
同时也要与其他利益相关者(如管理层、技术人员等)进行沟通,以了解他们对数据库的期望。
2.定义数据库范围和目标:根据用户需求,确定数据库应该包含哪些数据和功能,以及数据库的目标是什么。
例如,一个客户关系管理系统的目标可能是提高客户满意度和销售业绩。
3.制定数据字典:建立一个数据字典,用于记录数据库中所涉及的所有数据元素以及它们的定义。
数据字典可以帮助开发人员和用户更好地理解数据。
4.进行数据调查和现有系统分析:调查现有的数据和系统,了解已有的数据处理过程和信息流,以便在数据库设计中考虑这些因素。
第二步:概念设计概念设计是指创建数据库的概念模型,也就是使用实体-关系(ER)图描述数据库中的实体、属性和关系。
概念设计的主要任务包括:2.确定实体、属性和关系的约束:根据需求分析确定每个实体、属性和关系的约束条件。
例如,一个员工实体的属性可能包括姓名、性别、年龄等,其中年龄必须大于18岁。
3.优化概念模型:优化概念模型,以确保数据库的性能和效率。
例如,通过合并一对一关系、消除冗余等方式减少实体和关系的数量。
第三步:逻辑设计逻辑设计是指将概念模型转化为数据库系统可以理解和执行的逻辑结构。
逻辑设计的主要任务包括:1.将实体、属性和关系转化为关系模式:将概念模型中的实体、属性和关系转化为关系数据库中的关系表。
每个实体成为一个表,每个属性成为一个字段,每个关系成为一个外键。
2.确定关系表的主键:根据实体的唯一标识符确定每个关系表的主键。
主键可以是一个或多个字段的组合。
主键用于唯一标识关系表中的记录。
3.设计表之间的关系:根据概念模型中的关系,创建表之间的关系。
数据库部署步骤
1. 使用系统管理员登录。
Sqlplus /nolog
--在sqlplus下执行。
conn / as sysdba
2. 创建数据库表空间
表空间名称CMS,初始大小500M,自动扩展每次大小50M,最大为20G。
create tablespace cms
logging
datafile 'D:\oradata\cms.dbf'
size 500m
autoextend on
next 50m maxsize 20480m
extent management local;
3.创建数据库用户。
创建用户cms,密码cms,指定默认表空间为HotentCms
create user cms identified by cms
default tablespace HotentCMS;
3. 用户授权
给cms授予connect ,resource 的权限。
grant connect,resource to cms;
5.执行创建数据库表SQL。
在sqlplus下执行cms_create_table.sql
6.初始化数据
执行 cms_setup.sql