最新高中数学必修三第二章复习
- 格式:doc
- 大小:313.00 KB
- 文档页数:13



高中数学必修三知识点总结第一章算法初步算法的概念算法的特点(1)有限性:一个算法的步骤序列是有限的,必须在有限操作之后停止,不能是无限的.(2)确定性:算法中的每一步应该是确定的并且能有效地执行且得到确定的结果,而不应当是模棱两可.(3)顺序性与正确性:算法从初始步骤开始,分为若干明确的步骤,每一个步骤只能有一个确定的后继步骤,前一步是后一步的前提,只有执行完前一步才能进行下一步,并且每一步都准确无误,才能完成问题.(4)不唯一性:求解某一个问题的解法不一定是唯一的,对于一个问题可以有不同的算法.(5)普遍性:很多具体的问题,都可以设计合理的算法去解决,如心算、计算器计算都要经过有限、事先设计好的步骤加以解决.程序框图1、程序框图基本概念:(一)程序构图的概念:程序框图又称流程图,是一种用规定的图形、指向线及文字说明来准确、直观地表示算法的图形。
一个程序框图包括以下几部分:1.表示相应操作的程序框;2.带箭头的流程线;3.程序框外4.必要文字说明。
(二)构成程序框的图形符号及其作用画程序框图的规则如下: 1、使用标准的图形符号。
2、框图一般按从上到下、从左到右的方向画。
3、除判断框外,大多数流程图符号只有一个进入点和一个退出点。
判断框具有超过一个退 出点的唯一符号。
4、判断框分两大类,一类判断框“是”与“否”两分支的判断,而且有且仅有两个结果; 另一类是多分支判断,有几种不同的结果。
5、在图形符号内描述的语言要非常简练清楚。
(三)、算法的三种基本逻辑结构:顺序结构、条件结构、循环结构。
1、顺序结构:顺序结构是最简单的算法结构,语句与语句之间,框与框之间是按从上到下的顺序进行的,它是由若干个依次执行的处理步骤组成的,结构。
而下地连接起来,按顺序执行算法步骤。
如在示意图中,A框和B框是依次执行的,只有在执行完A框指定的操作后,才能接着执行B框所指定的操作。
2、条件结构:条件结构是指在算法中通过对条件的判断根据条件是否成立而选择不同流向的算法结构。

高中数学必修三课后习题答案第一章 算法初步 1.1算法与程序框图练习(P5) 1、算法步骤:第一步,给定一个正实数r .第二步,计算以r 为半径的圆的面积2S r π=.第三步,得到圆的面积S .2、算法步骤:第一步,给定一个大于1的正整数n .第二步,令1i =.第三步,用i 除n ,等到余数r .第四步,判断“0r =”是否成立. 若是,则i 是n 的因数;否则,i 不是n 的因数. 第五步,使i 的值增加1,仍用i 表示.第六步,判断“i n >”是否成立. 若是,则结束算法;否则,返回第三步.练习(P19)算法步骤:第一步,给定精确度d ,令1i =.的到小数点后第i 位的不足近似值,赋给a 的到小数点后第i 位的过剩近似值,赋给b . 第三步,计算55b am =-.第四步,若m d <,则得到5a;否则,将i 的值增加1,仍用i 表示.返回第二步. 第五步,输出5a.程序框图:习题1.1 A 组(P20)1、下面是关于城市居民生活用水收费的问题.为了加强居民的节水意识,某市制订了以下生活用水收费标准:每户每月用水未超过7 m 3时,每立方米收费1.0元,并加收0.2元的城市污水处理费;超过7m 3的部分,每立方收费1.5元,并加收0.4元的城市污水处理费.设某户每月用水量为x m 3,应交纳水费y 元,那么y 与x 之间的函数关系为 1.2,071.9 4.9,7x x y x x ≤≤⎧=⎨->⎩我们设计一个算法来求上述分段函数的值.算法步骤:第一步:输入用户每月用水量x .第二步:判断输入的x 是否不超过7. 若是,则计算 1.2y x =;若不是,则计算 1.9 4.9y x =-.第三步:输出用户应交纳的水费y .程序框图:2、算法步骤:第一步,令i =1,S=0.第二步:若i ≤100成立,则执行第三步;否则输出S. 第三步:计算S=S+i 2.第四步:i = i +1,返回第二步.程序框图:3、算法步骤:第一步,输入人数x ,设收取的卫生费为m 元.第二步:判断x 与3的大小. 若x >3,则费用为5(3) 1.2m x =+-⨯;若x ≤3,则费用为5m =.第三步:输出m .程序框图:B 组 1、算法步骤:第一步,输入111222,,,,,a b c a b c ..第二步:计算21121221b c b c x a b a b -=-.第三步:计算12211221a c a c y ab a b -=-.第四步:输出,x y .程序框图:INPUT “a ,b=”;a ,bsum=a+b diff=a -b pro=a*b quo=a/bPRINT sum ,diff ,pro ,quoEND2、算法步骤:第一步,令n =1第二步:输入一个成绩r ,判断r 与6.8的大小. 若r ≥6.8,则执行下一步;若r<6.8,则输出r ,并执行下一步.第三步:使n 的值增加1,仍用n 表示.第四步:判断n 与成绩个数9的大小. 若n ≤9,则返回第二步;若n >9,则结束算法.程序框图:说明:本题在循环结构的循环体中包含了一个条件结构.1.2基本算法语句 练习(P24) 1、程序:2、程序:3、程序:练习(P29) 1、程序:INPUT “a ,b ,c=”;a ,b ,cIF a+b>c AND a+c>b AND b+c>a THEN PRINT “Yes.” ELSEPRINT “No.” END IF INPUT “a ,b ,c=”;a ,b ,cp=(a+b+c)/2 s=SQR(p*(p -a) *(p -b) *(p -c)) PRINT “s=”;s END INPUT “F=”;F C=(F -32)*5/9 PRINT “C=”;C END4、程序: INPUT “a ,b ,c=”;a ,b ,csum=10.4*a+15.6*b+25.2*c PRINT “sum =”;sum END2、本程序的运行过程为:输入整数x . 若x 是满足9<x <100的两位整数,则先取出x 的十位,记作a ,再取出x 的个位,记作b ,把a ,b 调换位置,分别作两位数的个位数与十位数,然后输出新的两位数. 如输入25,则输出52. 34练习(P32) 1 2习题1.2 A 组(P33)1、1(0)0(0)1(0)x x y x x x -+<⎧⎪==⎨⎪+>⎩23、程序: 习题1.2 B 组(P33) 1、程序:23 41.3算法案例 练习(P45) 1、(1)45; (2)98; (3)24; (4)17. 2、2881.75.3、2200811111011000=() ,820083730=() 习题1.3 A 组(P48) 1、(1)57; (2)55. 2、21324.3、(1)104; (2)7212() (3)1278; (4)6315().4、习题1.3 B 组(P48)1、算法步骤:第一步,令45n =,1i =,0a =,0b =,0c =.第二步,输入()a i .第三步,判断是否0()60a i ≤<. 若是,则1a a =+,并执行第六步. 第四步,判断是否60()80a i ≤<. 若是,则1b b =+,并执行第六步. 第五步,判断是否80()100a i ≤≤. 若是,则1c c =+,并执行第六步. 第六步,1i i =+. 判断是否45i ≤. 若是,则返回第二步.2、如“出入相补”——计算面积的方法,“垛积术”——高阶等差数列的求和方法,等等. 第二章复习参考题A组(P50)1、(1)程序框图:程序:1、(2)程序框图:程序:2、见习题1.2 B组第1题解答.INPUT “x=”;x IF x<0 THENy=0ELSEIF x<1 THENy=1ELSEy=xEND IFEND IFPRINT “y=”;y ENDINPUT “x=”;x IF x<0 THENy=(x+2)^2 ELSEIF x=0 THENy=4ELSEy=(x-2)^2 END IFEND IFPRINT “y=”;y END34、程序框图:程序:INPUT “t=0”;t IF t<0 THEN PRINT “Please input again.”ELSE IF t>0 AND t<=180 THENy=0.2ELSEIF (t -180) MOD 60=0 THENy=0.2+0.1*(t-180)/60ELSEy=0.2+0.1*((t-180)\60+1)END IFEND IFPRINT “y=”;yEND IF END INPUT “n=”;n i=1 S=0WHILE i<=n S=S+1/i i=i+1 WENDPRINT “S=”;S END5、 (1)向下的运动共经过约199.805 m (2)第10次着地后反弹约0.098 m (3)全程共经过约299.609 m 第二章 复习参考题B 组(P35)1、 2、3、算法步骤:第一步,输入一个正整数x 和它的位数n . 第二步,判断n 是不是偶数,如果n 是偶数,令2n m =;如果n 是奇数,令12n m -=. 第三步,令1i =i=100 sum=0 k=1 WHILE k<=10 sum=sum+i i=i /2 k=k+1 WEND PRINT “(1)”;sum PRINT “(2)”;i PRINT “(3)”;2*sum -100 ENDINPUT “n=”;n IF n MOD 7=0 THEN PRINT “Sunday ” END IF IF n MOD 7=1 THEN PRINT “Monday ” END IF IF n MOD 7=2 THEN PRINT “Tuesday ” END IF IF n MOD 7=3 THEN PRINT “Wednesday ” END IF IF n MOD 7=4 THEN PRINT “Thursday ” END IF IF n MOD 7=5 THEN PRINT “Friday ” END IF IF n MOD 7=6 THEN PRINT “Saturday ” END IF END第四步,判断x 的第i 位与第(1)n i +-位上的数字是否相等. 若是,则使i 的值增加1,仍用i 表示;否则,x 不是回文数,结束算法.第五步,判断“i m >”是否成立. 若是,则n 是回文数,结束算法;否则,返回第四步.第二章 统计 2.1随机抽样 练习(P57)1、.况之间有误差. 如抽取的部分个体不能很好地代表总体,那么我们分析出的结果就会有偏差. 2、(1)抽签法:对高一年级全体学生450人进行编号,将学生的名字和对应的编号分别写在卡片上,并把450张卡片放入一个容器中,搅拌均匀后,每次不放回地从中抽取一张卡片,连续抽取50次,就得到参加这项活动的50名学生的编号. (2)随机数表法:第一步,先将450名学生编号,可以编为000,001, (449)第二步,在随机数表中任选一个数. 例如选出第7行第5列的数1(为了便于说明,下面摘取了附表的第6~10行).16 22 77 94 39 49 54 43 54 82 17 37 93 23 78 87 35 20 96 43 84 26 34 91 64 84 42 17 53 31 57 24 55 06 88 77 04 74 47 67 21 76 33 50 25 83 92 12 06 76 63 01 63 78 59 16 95 55 67 19 98 10 50 71 75 12 86 73 58 07 44 39 52 38 79 33 21 12 34 29 78 64 56 07 82 52 42 07 44 38 15 51 00 13 42 99 66 02 79 54 57 60 86 32 44 09 47 27 96 54 49 17 46 09 62 90 52 84 77 27 08 02 73 43 28第三步,从选定的数1开始向右读,得到一个三位数175,由于175<450,说明号码175在总体内,将它取出;继续向右读,得到331,由于331<450,说明号码331在总体内,将它取出;继续向右读,得到572,由于572>450,将它去掉. 按照这种方法继续向右读,依次下去,直到样本的50个号码全部取出,这样我们就得到了参加这项活动的50名学生. 3、用抽签法抽取样本的例子:为检查某班同学的学习情况,可用抽签法取出容量为5的样本. 用随机数表法抽取样本的例子:部分学生的心理调查等.抽签法能够保证总体中任何个体都以相同的机会被选到样本之中,因此保证了样本的代表性.4、与抽签法相比,随机数表法抽取样本的主要优点是节省人力、物力、财力和时间,缺点是所产生的样本不是真正的简单样本. 练习(P59)1、系统抽样的优点是:(1)简便易行;(2)当对总体结构有一定了解时,充分利用已有信息对总体中的个体进行排队后再抽样,可提高抽样调查;(3)当总体中的个体存在一种自然编号(如生产线上产品的质量控制)时,便于施行系统抽样法.系统抽样的缺点是:在不了解样本总体的情况下,所抽出的样本可能有一定的偏差. 2、(1)对这118名教师进行编号;(2)计算间隔1187.37516k==,由于k不是一个整数,我们从总体中随机剔除6个样本,再来进行系统抽样. 例如我们随机剔除了3,46,59,57,112,93这6名教师,然后再对剩余的112位教师进行编号,计算间隔7k=;(3)在1~7之间随机选取一个数字,例如选5,将5加上间隔7得到第2个个体编号12,再加7得到第3个个体编号19,依次进行下去,直到获取整个样本.3、由于身份证(18位)的倒数第二位表示性别,后三位是632的观众全部都是男性,所以这样获得的调查结果不能代表女性观众的意见,因此缺乏代表性.练习(P62)1、略2、这种说法有道理,因为一个好的抽样方法应该能够保证随着样本容量的增加,抽样调查结果会接近于普查的结果. 因此只要根据误差的要求取相应容量的样本进行调查,就可以节省人力、物力和财力.3、可以用分层抽样的方法进行抽样. 将麦田按照气候、土质、田间管理水平的不同而分成不同的层,然后按照各层麦田的面积比例及样本容量确定各层抽取的面积,再在各层中抽取个体(这里的个体是单位面积的一块地).习题2.1 A组(P63)1、产生随机样本的困难:(1)很难确定总体中所有个体的数目,例如调查对象是生产线上生产的产品.(2)成本高,要产生真正的简单随机样本,需要利用类似于抽签法中的抽签试验来产生非负整值随机数.(3)耗时多,产生非负整数值随机数和从总体中挑选出随机数所对的个体都需要时间.2、调查的总体是所有可能看电视的人群.学生A的设计方案考虑的人数是:上网而且登录某网址的人群,那些不能上网的人群,或者不登录某网址的人群就被排除在外了. 因此A方案抽取的样本的代表性差.学生B的设计方案考虑的人群是小区内的居民,有一定的片面性. 因此B方案抽取的样本的代表性差.学生C的设计方案考虑的人群是那些有电话的人群,也有一定的片面性. 因此C方案抽取的样本的代表性.所以,这三种调查方案都有一定的片面性,不能得到比较准确的收视率.3、(1)因为各个年级学习任务和学生年龄等因素的不同,影响各年级学生对学生活动的看法,所以按年级分层进行抽样调查,可以得到更有代表性的样本.(2)在抽样的过程中可能遇到的问题如敏感性问题:有些学生担心提出意见对自己不利;又如不响应问题:由于种种原因,有些学生不能发表意见;等等.(3)前面列举的两个问题都可能导致样本的统计推断结果的误差.(4)为解决敏感性问题,可以采用阅读与思考栏目“如何得到敏感性问题的诚实反应”中的方法设计调查问卷;为解决不响应问题,可以事先向全体学生宣传调查的意义,并安排专人负责发放和催收调查问卷,最大程度地回收有效调查问卷.4、将每一天看作一个个体,则总体由365天组成. 假设要抽取50个样本,将一年中的各天按先后次序编号为0~364天用简单随机抽样设计方案:制作365个号签,依次标上0~364. 将号签放到容器内充分搅拌均匀,从容器中任意不放回取出50个号签. 以签上的号码所对应的那些天构成样本,检测样本中所有个体的空气质量.用系统抽样设计抽样方案:先通过简单随机抽样方法从365天中随机抽出15天,再把剩下的350天重新按先后次序编号为0~349. 制作7个分别标有0~7的号签,放在容器中充分搅拌均匀. 从容器中任意取出一个号签,设取出的号签的编号为a,则编号为7(050)a k k +≤<所对应的那些天构成样本,检测样本中所有个体的空气质量.显然,系统抽样方案抽出的样本中个体在一年中排列的次序更规律,因此更好实施,更受方案的实施者欢迎.5、田径队运动员的总人数是564298+=(人),要得到28人的样本,占总体的比例为27.于是,应该在男运动员中随机抽取256167⨯=(人),在女运动员中随机抽取281612-=(人).这样我们就可以得到一个容量为28的样本.6、以10为分段间隔,首先在1~10的编号中,随机地选取一个编号,如6,那么这个获奖者奖品的编号是:6,16,26,36,46.7、说明:可以按年级分层抽样的方法设计方案. 习题2.1 B 组(P64)1、说明:可以按年级分层抽样的方法设计方案,调查问卷由学生所关心的问题组成. 例如:(1)你最喜欢哪一门课程? (2)你每月的零花钱平均是多少? (3)你最喜欢看《新闻联播》吗? (4)你每天早上几点起床? (5)你每天晚上几点睡觉?要根据统计的结果和具体的情况解释结论,主要从引起结论的可能原因及结论本身含义来解释.2、说明:这是一个开放性的题目,没有一个标准的答案. 2.2用样本估计总体 练习(P71) 1、说明:由于样本的极差为364.41362.51 1.90-=,取组距为0.19,将样本分为10组. 可以按照书上的方法制作频率分布表、频率分布直观图和频率折线图. 2、说明:此题目属于应用题,没有标准的答案.3、茎叶图为:由该图可以看出30名工人的日加工零件个数稳定在120件左右. 练习(P74)这里应该采用平均数来表示每一个国家项目的平均金额,因为它能反应所有项目的信息. 但平均数会受到极端数据2000万元的影响,所以大多数项目投资金额都和平均数相差比较大.练习(P79)1、甲乙两种水稻6年平均产量的平均数都是900,但甲的标准差约等于23.8,乙的标准差约等于41.6,所以甲的产量比较稳定.2、(1)平均重量496.86x ≈,标准差 6.55s ≈.(2)重量位于(,)x s x s -+之间有14袋白糖,所占的百分比约为66.67%.3、(1)略. (2)平均分19.25x ≈,中位数为15.2,标准差12.50s ≈.这些数据表明这些国家男性患该病的平均死亡率约为19.25,有一半国家的死亡率不超过15.2,15.2x >说明存在大的异常数据,值得关注. 这些异常数据使标准差增大. 习题2.2 A 组(P81) 1、(1)茎叶图为:(2)汞含量分布偏向于大于1.00 ppm 的方向,即多数鱼的汞含量分布在大于1.00 ppm 的区域. (3)不一定. 因为我们不知道各批鱼的汞含量分布是否都和这批鱼相同. 即使各批鱼的汞含量分布相同,上面的数据只能为这个分布作出估计,不能保证平均汞含量大于1.00 ppm. (4)样本平均数 1.08x ≈,样本标准差0.45s ≈.(5)有28条鱼的汞含量在平均数与2倍标准差的和(差)的范围内.2比较短,所以在这批棉花中混进了一些次品.3、说明:应该查阅一下这所大学的其他招生信息,例如平均数信息、最低录取分数线信息等. 尽管该校友的分数位于中位数之下,而中位数本身并不能提供更多录取分数分布的信息.在已知最低录取分数线的情况下,很容易做出判断;在已知平均数小于中位数很多,则说明最低录取分数线较低,可以推荐该校友报考这所大学,否则还要获取其他的信息(如标准差的信息)来做出判断. 4、说明:(1)对,从平均数的角度考虑; (2)对,从标准差的角度考虑;(3)对,从标准差的角度考虑; (4)对,从平均数和标准差的角度考虑; 5、(1)不能. 因为平均收入和最高收入相差太多,说明高收入的职工只占极少数. 现在已知知道至少有一个人的收入为50100x =万元,那么其他员工的收入之和为4913.55010075ii x==⨯-=∑(万元)每人平均只有1.53. 如果再有几个收入特别高者,那么初进公司的员工的收入将会很低. (2)不能,要看中位数是多少.(3)能,可以确定有75%的员工工资在1万元以上,其中25%的员工工资在3万元以上.(4)收入的中位数大约是2万. 因为有年收入100万这个极端值的影响,使得年平均收入比中位数高许多.6、甲机床的平均数=1.5x 甲,标准差=1.2845s 甲;乙机床的平均数 1.2z y =,标准差0.8718z s =. 比较发现乙机床的平均数小而且标准差也比较小,说明乙机床生产出的次品比甲机床少,而且更为稳定,所以乙机床的性能较好. 7、(1)总体平均数为199.75,总体标准差为95.26. (2)可以使用抓阄法进行抽样. 样本平均数和标准差的计算结果和抽取到的样本有关. (3) (4)略 习题2.2 B 组(P82)1、(1)由于测试1T 的标准差小,所以测试1T 结果更稳定,所以该测试做得更好一些. (2)由于2T 测出的值偏高,有利于增强队员的信心,所以应该选择测试2T .2、说明:此题需要在本节开始的时候就布置,先让学生分头收集数据,汇总所收集的数据才能完成题目.2.3变量间的相关关系 练习(P85)1、从已经掌握的知识来看,吸烟会损害身体的健康. 但除了吸烟之外,还有许多其他的随机因素影响身体健康,人体健康是很多因素共同作用的结果. 我们可以找到长寿的吸烟者,也更容易发现由于吸烟而引发的患病者,所以吸烟不一定引起健康问题. 但吸烟引起健康问题的可能性大,因此“健康问题不一定是由吸烟引起的,所以可以吸烟”的说法是不对的.2、从现在我们掌握的知识来看,没有发现根据说明“天鹅能够带来孩子”,完全可能存在既能吸引天鹅和又使婴儿出生率高的第3个因素(例如独特的环境因素),即天鹅与婴儿出生率之间没有直接的关系,因此“天鹅能够带来孩子”的结论不可靠.而要证实此结论是否可靠,可以通过试验来进行. 相同的环境下将居民随机地分为两组,一组居民和天鹅一起生活(比如家中都饲养天鹅),而另一组居民的附近不让天鹅活动,对比两组居民的出生率是否相同. 练习(P92)1、当0x =时,147.767y =,这个值与实际卖出的热饮杯数150不符,原因是:线性回归方程中的截距和斜率都是通过样本估计的,存在随机误差,这种误差可以导致预测结果的偏差;即使截距和斜率的估计没有误差,也不可能百分之百地保证对应于x ,预报值y 能够等于实际值y . 事实上:y bx a e =++. (这里e 是随机变量,是引起预报值y 与真实值(1)散点图如下: y 之间的误差的原因之一,其大小取决于e 的方差.)2、数据的散点图为:从这个散点图中可以看出,鸟的种类数与海拔高度应该为正相关(事实上相关系数为0.793). 但是从散点图的分布特点来看,它们之间的线性相关性不强. 习题2.3 A 组(P94)1、教师的水平与学生的学习成绩呈正相关关系. 又如,“水涨船高”“登高望远”等.2、(3)基本成正相关关系,即食品所含热量越高,口味越好.(4)因为当回归直线上方的食品与下方的食品所含热量相同时,其口味更好. 3、(1)散点图如下:(2)回归方程为:0.66954.933y x =+.(2)回归直线如下图所示:(3)加工零件的个数与所花费的时间呈正线性相关关系. 4、(1)散点图为:(2)回归方程为:0.546876.425y x =+.(3)由回归方程知,城镇居民的消费水平和工资收入之间呈正线性相关关系,即工资收入水平越高,城镇居民的消费水平越高. 习题2.3 B 组(P95) 1、(1)散点图如下:(2)回归方程为: 1.44715.843y x =-.(3)如果这座城市居民的年收入达到40亿元,估计这种商品的销售额为42.037y ≈(万元). 2、说明:本题是一个讨论题,按照教科书中的方法逐步展开即可.第二章 复习参考题A 组(P100)1、A .2、(1)该组的数据个数,该组的频数除以全体数据总数; (2)nmN. 3、(1)这个结果只能说明A 城市中光顾这家服务连锁店的人比其他人较少倾向于选择咖啡色,因为光顾连锁店的人使一种方便样本,不能代表A 城市其他人群的想法. (2)这两种调查的差异是由样本的代表性所引起的. 因为A 城市的调查结果来自于该市光顾这家服装连锁店的人群,这个样本不能很好地代表全国民众的观点.4、说明:这是一个敏感性问题,可以模仿阅读与思考栏目“如何得到敏感性问题的诚实反应”来设计提问方法.5、表略. 可以估计出句子中所含单词的分布,以及与该分布有关的数字特征,如平均数、标准差等.6、(1)可以用样本标准差来度量每一组成员的相似性,样本标准差越小,相似程度越高. (2)A 组的样本标准差为 3.730A S ≈,B 组的样本标准差为11.789B S ≈. 由于专业裁判给分更符合专业规则,相似程度应该高,因此A 组更像是由专业人士组成的.7、(1)中位数为182.5,平均数为217.1875.(2)这两种数字特征不同的主要原因是,430比其他的数据大得多,应该查找430是否由某种错误而产生的. 如果这个大数据的采集正确,用平均数更合适,因为它利用了所有数据的信息;如果这个大数据的采集不正确,用中位数更合适,因为它不受极端值的影响,稳定性好. 8、(1)略.(2)系数0.42是回归直线的斜率,意味着:对于农村考生,每年的入学率平均增长0.42%.(3)城市的大学入学率年增长最快. 说明:(4)可以模仿(1)(2)(3)的方法分析数据.第二章 复习参考题B 组(P101)1、频率分布如下表:从表中看出当把指标定为17.46千元 时,月65%的推销员 经过努力才能完成销 售指标.2、(1)数据的散点图如下:(2)用y 表示身高,x 表示年龄,则数据的回归方程为 6.31771.984y x =+. (3)在该例中,斜率6.317表示孩子在一年中增加的高度.(4)每年身高的增长数略. 3~16岁的身高年均增长约为6.323 cm. (5)斜率与每年平均增长的身高之间之间近似相等.第三章 概率3.1随机事件的概率 练习(P113) 1、(1)试验可能出现的结果有3个,两个均为正面、一个正面一个反面、两个均为反面. (2)通过与其他同学的结果汇总,可以发现出现一个正面一个反面的次数最多,大约在50次左右,两个均为正面的次数和两个均为反面的次数在25次左右. 由此可以估计出现一个正面一个反面的概率为0.50,出现两个均为正面的概率和两个均为反面的概率均为0.25. 2、略 3、(1)例如:北京四月飞雪;某人花两元钱买福利彩票,中了特等奖;同时抛10枚硬币,10枚都正面朝上.(2)例如:在王府井大街问路时,碰到会说中文的人;去烤鸭店吃饭的顾客点烤鸭;在1~1000的自然数任选一个数,选到的数大于1. 练习(P118)1、说明:例如,计算机键盘上各键盘的安排,公交线路及其各站点的安排,抽奖活动中各奖项的安排等,其中都用到了概率. 学生可能举出各种各样的例子,关键是引导他们正确分析例子中蕴涵的概率思想.2、通过掷硬币或抽签的方法,决定谁先发球,这两种方法都是公平的. 而猜拳的方法不太公平,因为出拳有时间差,个人反应也不一样.3、这种说法是错误的. 因为掷骰子一次得到2是一个随机事件,在一次试验中它可能发生也可能不发生. 掷6次骰子就是做6次试验,每次试验的结果都是随机的,可能出现2也可能不出现2,所以6次试验中有可能一次2都不出现,也可能出现1次,2次,…,6次. 练习(P121)1、0.72、0.6153、0.44、D5、B 习题3.1 A 组(P123) 1、D . 2、(1)0; (2)0.2; (3)1.3、(1)430.067645≈; (2)900.140645≈; (3)7010.891645-≈.4、略5、0.136、说明:本题是想通过试验的方法,得到这种摸球游戏对先摸者和后摸者是公平的结论. 最好把全班同学的结果汇总,根据两个事件出现的频率比较近,猜测在第一种情况下摸到红球的概率为110,在第二种下也为110. 第4次摸到红球的频率与第1次摸到红球的频率应该相差不远,因为不论哪种情况,第4次和第1次摸到红球的概率都是1 10.习题3.1 B组(P124)1、D.2、略. 说明:本题是为了学生根据实际数据作出一些推断. 一般我们假定每个人的生日在12个月中哪一个月是等可能的,这个假定是否成立,引导学生通过收集的数据作出初步的推断.3.2古典概率练习(P130)1、110. 2、17. 3、16.练习(P133)1、38,38.2、(1)113;(2)1213;(3)14;(4)313;(5)0;(6)213;(7)12;(8)1.说明:模拟的方法有两种.(1)把1~52个自然数分别与每张牌对应,再用计算机做模拟试验.(2)让计算机分两次产生两个随机数,第一次产生1~4的随机数,代表4个花色;第二次产生1~13的随机数,代表牌号.3、(1)不可能事件,概率为0;(2)随机事件,概率为49;(3)必然事件,概率为1;(4)让计算机产生1~9的随机数,1~4代表白球,5~9代表黑球.4、(1)16;(2)略;(3)应该相差不大,但会有差异. 存在差异的主要原因是随机事件在每次试验中是否发生是随机的,但在200次试验中,该事件发生的次数又是有规律的,所以一般情况下所得的频率与概率相差不大.习题3.2 A组(P133)1、游戏1:取红球与取白球的概率都为12,因此规则是公平的.游戏2:取两球同色的概率为13,异色的概率为23,因此规则是不公平的.游戏3:取两球同色的概率为12,异色的概率为12,因此规则是公平的.2、第一位可以是1~9这9个数字中的一个,第二位可以是0~9这10个数字中的一个,所以(1)190;(2)18919090-=;(3)9919010-=3、(1)0.52;(2)0.18.4、(1)12;(2)16;(3)56;(4)16.5、(1)25;(2)825.6、(1)920;(2)920;(3)12.习题3.2 B组(P134)1、(1)13;(2)14.2、(1)35;(2)310;(3)910.说明:(3)先计算该事件的对立事件发生的概率会比较简单.3、具体步骤如下:①建立概率模型. 首先要模拟每个人的出生月份,可用1,2,…,11,12表示月份,用产生取整数值的随机数的办法,随机产生1~12之间的随机数. 由于模拟的对象是一个有10个人的集体,故把连续产生的10个随机数作为一组模拟结果,可模拟产生100组这样的结果.②进行模拟试验. 可用计算器或计算机进行模拟试验.如使用Excel软件,可参看教科书125页的步骤,下图是模拟的结果:其中,A,B,C,D,E,F,G,H,I,J的每一行表示对一个10人集体的模拟结果. 这样的试验一共做了100次,所以共有100行,表示随机抽取了100个集体.③统计试验的结果. K,L,M,N列表示统计结果. 例如,第一行前十列中至少有两个数相同,表示这个集体中至少有两个人的生日在同一月. 本题的难点是统计每一行前十列中至少有两个数相同的个数. 由于需要判断的条件态度,所以用K,L,M三列分三次完成统计.其中K列的公式为“=IF(OR(A1=B1,A1=C1,A1=D1,A1=E1,A1=F1,A1=G1,A1=H1,A1=I1,A1=J1,B1=C1,B1=D1,B1=E1,B1=F1,B1=G1,B1=H1,B1=I1,B1=J1,C1=D1,C1=E1,C1=F1,C1=G1,C1=H1,C1=I1,C1=J1,D1=E1,D1=F1,D1=G1,D1=H1,D1=I1,D1=J1),1,0)”,L列的公式为“=IF(OR(E1=F1,E1=G1,E1=H1,E1=I1,E1=J1,F1=G1,F1=H1,F1=I1,F1=J1,G1=H1,G1=I1,G1=J1,H1=I1,H1=J1,I1=J1),1,0)”,M列的公式为“=IF(OR(K1=1,L1=1),1,0)”,M列的值为1表示该行所代表的10人集体中至少有两个人的生日在同一个月. N1表示100个10人集体中至少有两个人的生日在同一个月的个数,其公式为“=SUM(M$1:M$100)”. N1除以100所得的结果0.98,就是用模拟方法计算10人集体中至少有两个人的生日在同一个月的概率的估计值. 可以看出,这个估计值很接近1.3.3几何概率。



高中数学必修三第二章《统计》学案2.3.变量间的相关关系(学生专用)(A版)普通高中数学必修3(A版)学案 2.3. 变量间的相关关系2.3.1变量之间的相关关系授课时间:年月日【学习目标】通过收集现实问题中两个有关联变量的数据认识变量间的相关关系。
【重点难点】1. 通过收集现实问题中两个有关联变量的数据直观认识变量间的相关关系。
2. 变量之间相关关系的理解。
【学习过程】一、学习引导在中学校园里,有这样一种说法:“如果你的数学成绩好,那么你的物理学习就不会有什么大问题.”按照这种说法,似乎学生的物理成绩与数学成绩之间存在着某种关系,我们把数学成绩和物理成绩看成是两个变量,那么这两个变量之间的关系是函数关系吗?二、合作交流(教师可做点拨)相关关系的概念:两个变量之间的关系可能是确定的关系(如:函数关系),或非确定性关系。
当自变量取值一定时,因变量也确定,则为确定关系;当自变量取值一定时,因变量带有随机性,这种变量之间的关系称为相关关系。
相关关系是一种非确定性关系。
(分析:两个变量→自变量取值一定→因变量带有随机性→相关关系)三、随堂练习思考1:考察下列问题中两个变量之间的关系:(1)商品销售收入与广告支出经费;(2)粮食产量与施肥量;(3)人体内的脂肪含量与年龄.这些问题中两个变量之间的关系是函数关系吗?思考2:“名师出高徒”可以解释为教师的水平越高,学生的水平就越高,那么学生的学业成绩与教师的教学水平之间的关系是函数关系吗?你能举出类似的描述生活中两个变量之间的这种关系的成语吗?思考3:商品销售收入与广告支出经费之间的关系。
(还与商品质量,居民收入,生活环境等有关)四、能力提升1. 上述两个变量之间的关系是一种非确定性关系,称之为相关关系,那么相关关系的含义如何?2. 对于一个变量,可以控制其数量大小的变量称为可控变量,否则称为随机变量,那么相关关系中的两个变量有哪种类型?3. 相关关系与函数关系的异同点?【小结反思】1. 变量具有不确定性,需要通过收集大量的数据(通过调查或试验)在对数据进行统计分析的基础上,发现其中的规律,才能对它们之间的关系做出正确的判断。

高中数学必修三知识点总结第1篇1.一些基本概念:(1)向量:既有大小,又有方向的量。
(2)数量:只有大小,没有方向的量。
(3)有向线段的三要素:起点、方向、长度。
(4)零向量:长度为0的向量。
(5)单位向量:长度等于1个单位的向量。
(6)平行向量(共线向量):方向相同或相反的非零向量。
※零向量与任一向量平行。
(7)相等向量:长度相等且方向相同的向量。
2.向量加法运算:⑴三角形法则的特点:首尾相连。
⑵平行四边形法则的特点:共起点高中数学必修三知识点总结第2篇一、高中数学函数的有关概念1.高中数学函数函数的概念:设A、B是非空的数集,如果按照某个确定的对应关系f,使对于函数A中的任意一个数x,在函数B中都有确定的数f(x)和它对应,那么就称f:A →B为从函数A到函数B的一个函数。
记作:y=f(x),x∈A.其中,x叫做自变量,x的取值范围A叫做函数的定义域;与x的值相对应的y值叫做函数值,函数值的函数{f(x)|x∈A}叫做函数的值域。
注意:函数定义域:能使函数式有意义的实数x的函数称为函数的定义域。
求函数的定义域时列不等式组的主要依据是:(1)分式的分母不等于零;(2)偶次方根的被开方数不小于零;(3)对数式的真数必须大于零;(4)指数、对数式的底必须大于零且不等于1.(5)如果函数是由一些基本函数通过四则运算结合而成的。
那么,它的定义域是使各部分都有意义的x的值组成的函数。
(6)指数为零底不可以等于零,(7)实际问题中的函数的定义域还要保证实际问题有意义。
相同函数的判断方法:①表达式相同(与表示自变量和函数值的字母无关);②定义域一致(两点必须同时具备)2.高中数学函数值域:先考虑其定义域(1)观察法(2)配方法(3)代换法3.函数图象知识归纳(1)定义:在平面直角坐标系中,以函数y=f(x),(x∈A)中的x为横坐标,函数值y为纵坐标的点P(x,y)的函数C,叫做函数y=f(x),(x∈A)的图象。
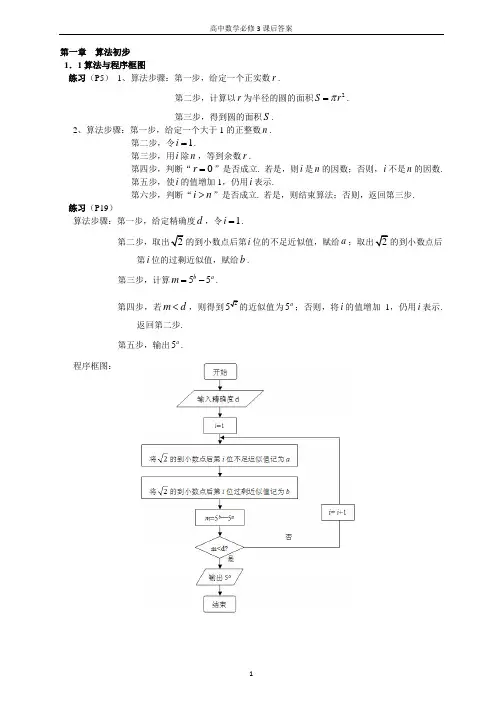
第一章 算法初步 1.1算法与程序框图练习(P5) 1、算法步骤:第一步,给定一个正实数r .第二步,计算以r 为半径的圆的面积2S r π=.第三步,得到圆的面积S .2、算法步骤:第一步,给定一个大于1的正整数n .第二步,令1i =.第三步,用i 除n ,等到余数r .第四步,判断“0r =”是否成立. 若是,则i 是n 的因数;否则,i 不是n 的因数. 第五步,使i 的值增加1,仍用i 表示.第六步,判断“i n >”是否成立. 若是,则结束算法;否则,返回第三步.练习(P19)算法步骤:第一步,给定精确度d ,令1i =.i 位的不足近似值,赋给a 第i 位的过剩近似值,赋给b . 第三步,计算55bam =-.第四步,若m d <,则得到5a;否则,将i 的值增加1,仍用i 表示.返回第二步. 第五步,输出5a.程序框图:习题1.1 A 组(P20)1、下面是关于城市居民生活用水收费的问题.为了加强居民的节水意识,某市制订了以下生活用水收费标准:每户每月用水未超过7 m 3时,每立方米收费1.0元,并加收0.2元的城市污水处理费;超过7m 3的部分,每立方收费1.5元,并加收0.4元的城市污水处理费.设某户每月用水量为x m 3,应交纳水费y 元,那么y 与x 之间的函数关系为 1.2,071.9 4.9,7x x y x x ≤≤⎧=⎨->⎩我们设计一个算法来求上述分段函数的值. 算法步骤:第一步:输入用户每月用水量x .第二步:判断输入的x 是否不超过7. 若是,则计算 1.2y x =;若不是,则计算 1.9 4.9y x =-.第三步:输出用户应交纳的水费y .程序框图:2、算法步骤:第一步,令i =1,S=0.第二步:若i ≤100成立,则执行第三步;否则输出S. 第三步:计算S=S+i 2.第四步:i = i +1,返回第二步.程序框图:3、算法步骤:第一步,输入人数x ,设收取的卫生费为m 元.第二步:判断x 与3的大小. 若x >3,则费用为5(3) 1.2m x =+-⨯;若x ≤3,则费用为5m =.第三步:输出m .程序框图:B 组 1、算法步骤:第一步,输入111222,,,,,a b c a b c ..第二步:计算21121221b c b c x a b a b -=-.第三步:计算12211221a c a c y ab a b -=-.第四步:输出,x y .程序框图:2、算法步骤:第一步,令n =1第二步:输入一个成绩r ,判断r 与6.8的大小. 若r ≥6.8,则执行下一步;若r<6.8,则输出r ,并执行下一步.第三步:使n 的值增加1,仍用n 表示.第四步:判断n 与成绩个数9的大小. 若n ≤9,则返回第二步;若n >9,则结束算法.程序框图:说明:本题在循环结构的循环体中包含了一个条件结构.1.2基本算法语句 练习(P24) 12、程序:3练习(P29) 12、本程序的运行过程为:输入整数x . 若x 是满足9<x <100的两位整数,则先取出x 的十位,记作a ,再取出x 的个位,记作b ,把a ,b 调换位置,分别作两位数的个位数与十位数,然后输出新的两位数. 如输入25,则输出52.4、34练习(P32) 1 2习题1.2 A 组(P33)1、1(0)0(0)1(0)x x y x x x -+<⎧⎪==⎨⎪+>⎩23、程序:习题1.2 B 组(P33) 1、程序:23 41.3算法案例 练习(P45) 1、(1)45; (2)98; (3)24; (4)17. 2、2881.75.3、2200811111011000=() ,820083730=() 习题1.3 A 组(P48) 1、(1)57; (2)55. 2、21324.3、(1)104; (2)7212() (3)1278; (4)6315().4、习题1.3 B 组(P48)1、算法步骤:第一步,令45n =,1i =,0a =,0b =,0c =.第二步,输入()a i .第三步,判断是否0()60a i ≤<. 若是,则1a a =+,并执行第六步. 第四步,判断是否60()80a i ≤<. 若是,则1b b =+,并执行第六步. 第五步,判断是否80()100a i ≤≤. 若是,则1c c =+,并执行第六步. 第六步,1i i =+. 判断是否45i ≤. 若是,则返回第二步.第七步,输出成绩分别在区间[0,60),[60,80),[80,100]的人数,,a b c .2、如“出入相补”——计算面积的方法,“垛积术”——高阶等差数列的求和方法,等等.第二章 复习参考题A 组(P50)1、(1)程序框图:程序:1、(2)程序框图:程序:2、见习题1.2 B组第1题解答.34、程序框图:5(1)向下的运动共经过约199.805 m (2)第10次着地后反弹约0.098 m(3)全程共经过约299.609 m第二章 复习参考题B 组(P35)12、3、算法步骤:第一步,输入一个正整数x 和它的位数n . 第二步,判断n 是不是偶数,如果n 是偶数,令2n m =;如果n 是奇数,令12n m -=. 第三步,令1i =第四步,判断x 的第i 位与第(1)n i +-位上的数字是否相等. 若是,则使i 的值增加1,仍用i 表示;否则,x 不是回文数,结束算法.第五步,判断“i m >”是否成立. 若是,则n 是回文数,结束算法;否则,返回第四步.第二章 统计2.1随机抽样 练习(P57)1、.之间有误差. 如抽取的部分个体不能很好地代表总体,那么我们分析出的结果就会有偏差.2、(1)抽签法:对高一年级全体学生450人进行编号,将学生的名字和对应的编号分别写在卡片上,并把450张卡片放入一个容器中,搅拌均匀后,每次不放回地从中抽取一张卡片,连续抽取50次,就得到参加这项活动的50名学生的编号.(2)随机数表法:第一步,先将450名学生编号,可以编为000,001, (449)第二步,在随机数表中任选一个数. 例如选出第7行第5列的数1(为了便于说明,下面摘取了附表的第6~10行).16 22 77 94 39 49 54 43 54 82 17 37 93 23 78 87 35 20 96 43 84 26 34 91 6484 42 17 53 31 57 24 55 06 88 77 04 74 47 67 21 76 33 50 25 83 92 12 06 7663 01 63 78 59 16 95 55 67 19 98 10 50 71 75 12 86 73 58 07 44 39 52 38 7933 21 12 34 29 78 64 56 07 82 52 42 07 44 38 15 51 00 13 42 99 66 02 79 5457 60 86 32 44 09 47 27 96 54 49 17 46 09 62 90 52 84 77 27 08 02 73 43 28第三步,从选定的数1开始向右读,得到一个三位数175,由于175<450,说明号码175在总体内,将它取出;继续向右读,得到331,由于331<450,说明号码331在总体内,将它取出;继续向右读,得到572,由于572>450,将它去掉. 按照这种方法继续向右读,依次下去,直到样本的50个号码全部取出,这样我们就得到了参加这项活动的50名学生.3、用抽签法抽取样本的例子:为检查某班同学的学习情况,可用抽签法取出容量为5的样本. 用随机数表法抽取样本的例子:部分学生的心理调查等.抽签法能够保证总体中任何个体都以相同的机会被选到样本之中,因此保证了样本的代表性.4、与抽签法相比,随机数表法抽取样本的主要优点是节省人力、物力、财力和时间,缺点是所产生的样本不是真正的简单样本.练习(P59)1、系统抽样的优点是:(1)简便易行;(2)当对总体结构有一定了解时,充分利用已有信息对总体中的个体进行排队后再抽样,可提高抽样调查;(3)当总体中的个体存在一种自然编号(如生产线上产品的质量控制)时,便于施行系统抽样法.系统抽样的缺点是:在不了解样本总体的情况下,所抽出的样本可能有一定的偏差.2、(1)对这118名教师进行编号;(2)计算间隔1187.37516k==,由于k不是一个整数,我们从总体中随机剔除6个样本,再来进行系统抽样. 例如我们随机剔除了3,46,59,57,112,93这6名教师,然后再对剩余的112位教师进行编号,计算间隔7k=;(3)在1~7之间随机选取一个数字,例如选5,将5加上间隔7得到第2个个体编号12,再加7得到第3个个体编号19,依次进行下去,直到获取整个样本.3、由于身份证(18位)的倒数第二位表示性别,后三位是632的观众全部都是男性,所以这样获得的调查结果不能代表女性观众的意见,因此缺乏代表性.练习(P62)1、略2、这种说法有道理,因为一个好的抽样方法应该能够保证随着样本容量的增加,抽样调查结果会接近于普查的结果. 因此只要根据误差的要求取相应容量的样本进行调查,就可以节省人力、物力和财力.3、可以用分层抽样的方法进行抽样. 将麦田按照气候、土质、田间管理水平的不同而分成不同的层,然后按照各层麦田的面积比例及样本容量确定各层抽取的面积,再在各层中抽取个体(这里的个体是单位面积的一块地). 习题2.1 A 组(P63)1、产生随机样本的困难:(1)很难确定总体中所有个体的数目,例如调查对象是生产线上生产的产品.(2)成本高,要产生真正的简单随机样本,需要利用类似于抽签法中的抽签试验来产生非负整值随机数.(3)耗时多,产生非负整数值随机数和从总体中挑选出随机数所对的个体都需要时间. 2、调查的总体是所有可能看电视的人群.学生A 的设计方案考虑的人数是:上网而且登录某网址的人群,那些不能上网的人群,或者不登录某网址的人群就被排除在外了. 因此A 方案抽取的样本的代表性差.学生B 的设计方案考虑的人群是小区内的居民,有一定的片面性. 因此B 方案抽取的样本的代表性差.学生C 的设计方案考虑的人群是那些有电话的人群,也有一定的片面性. 因此C 方案抽取的样本的代表性.所以,这三种调查方案都有一定的片面性,不能得到比较准确的收视率. 3、(1)因为各个年级学习任务和学生年龄等因素的不同,影响各年级学生对学生活动的看法,所以按年级分层进行抽样调查,可以得到更有代表性的样本.(2)在抽样的过程中可能遇到的问题如敏感性问题:有些学生担心提出意见对自己不利;又如不响应问题:由于种种原因,有些学生不能发表意见;等等. (3)前面列举的两个问题都可能导致样本的统计推断结果的误差.(4)为解决敏感性问题,可以采用阅读与思考栏目“如何得到敏感性问题的诚实反应”中的方法设计调查问卷;为解决不响应问题,可以事先向全体学生宣传调查的意义,并安排专人负责发放和催收调查问卷,最大程度地回收有效调查问卷.4、将每一天看作一个个体,则总体由365天组成. 假设要抽取50个样本,将一年中的各天按先后次序编号为0~364天 用简单随机抽样设计方案:制作365个号签,依次标上0~364. 将号签放到容器内充分搅拌均匀,从容器中任意不放回取出50个号签. 以签上的号码所对应的那些天构成样本,检测样本中所有个体的空气质量.用系统抽样设计抽样方案:先通过简单随机抽样方法从365天中随机抽出15天,再把剩下的350天重新按先后次序编号为0~349. 制作7个分别标有0~7的号签,放在容器中充分搅拌均匀. 从容器中任意取出一个号签,设取出的号签的编号为a ,则编号为7(050)a k k +≤<所对应的那些天构成样本,检测样本中所有个体的空气质量.显然,系统抽样方案抽出的样本中个体在一年中排列的次序更规律,因此更好实施,更受方案的实施者欢迎.5、田径队运动员的总人数是564298+=(人),要得到28人的样本,占总体的比例为27.于是,应该在男运动员中随机抽取256167⨯=(人),在女运动员中随机抽取281612-=(人).这样我们就可以得到一个容量为28的样本.6、以10为分段间隔,首先在1~10的编号中,随机地选取一个编号,如6,那么这个获奖者奖品的编号是:6,16,26,36,46.7、说明:可以按年级分层抽样的方法设计方案. 习题2.1 B 组(P64)1、说明:可以按年级分层抽样的方法设计方案,调查问卷由学生所关心的问题组成. 例如:(1)你最喜欢哪一门课程? (2)你每月的零花钱平均是多少? (3)你最喜欢看《新闻联播》吗? (4)你每天早上几点起床? (5)你每天晚上几点睡觉?要根据统计的结果和具体的情况解释结论,主要从引起结论的可能原因及结论本身含义来解释.2、说明:这是一个开放性的题目,没有一个标准的答案. 2.2用样本估计总体 练习(P71) 1、说明:由于样本的极差为364.41362.51 1.90-=,取组距为0.19,将样本分为10组. 可以按照书上的方法制作频率分布表、频率分布直观图和频率折线图. 2、说明:此题目属于应用题,没有标准的答案.3、茎叶图为:由该图可以看出30名工人的日加工零件个数稳定在120件左右. 练习(P74)这里应该采用平均数来表示每一个国家项目的平均金额,因为它能反应所有项目的信息. 但平均数会受到极端数据2000万元的影响,所以大多数项目投资金额都和平均数相差比较大.练习(P79)1、甲乙两种水稻6年平均产量的平均数都是900,但甲的标准差约等于23.8,乙的标准差约等于41.6,所以甲的产量比较稳定.2、(1)平均重量496.86x ≈,标准差 6.55s ≈.(2)重量位于(,)x s x s -+之间有14袋白糖,所占的百分比约为66.67%.3、(1)略. (2)平均分19.25x ≈,中位数为15.2,标准差12.50s ≈.这些数据表明这些国家男性患该病的平均死亡率约为19.25,有一半国家的死亡率不超过15.2,15.2x >说明存在大的异常数据,值得关注. 这些异常数据使标准差增大. 习题2.2 A 组(P81) 1、(1)茎叶图为:(2)汞含量分布偏向于大于1.00 ppm 的方向,即多数鱼的汞含量分布在大于1.00 ppm 的区域. (3)不一定. 因为我们不知道各批鱼的汞含量分布是否都和这批鱼相同. 即使各批鱼的汞含量分布相同,上面的数据只能为这个分布作出估计,不能保证平均汞含量大于1.00 ppm.(4)样本平均数 1.08x ≈,样本标准差0.45s ≈.(5)有28条鱼的汞含量在平均数与2倍标准差的和(差)的范围内.2比较短,所以在这批棉花中混进了一些次品.3、说明:应该查阅一下这所大学的其他招生信息,例如平均数信息、最低录取分数线信息等. 尽管该校友的分数位于中位数之下,而中位数本身并不能提供更多录取分数分布的信息.在已知最低录取分数线的情况下,很容易做出判断;在已知平均数小于中位数很多,则说明最低录取分数线较低,可以推荐该校友报考这所大学,否则还要获取其他的信息(如标准差的信息)来做出判断. 4、说明:(1)对,从平均数的角度考虑; (2)对,从标准差的角度考虑;(3)对,从标准差的角度考虑; (4)对,从平均数和标准差的角度考虑; 5、(1)不能. 因为平均收入和最高收入相差太多,说明高收入的职工只占极少数. 现在已知知道至少有一个人的收入为50100x =万元,那么其他员工的收入之和为4913.55010075ii x==⨯-=∑(万元)每人平均只有1.53. 如果再有几个收入特别高者,那么初进公司的员工的收入将会很低. (2)不能,要看中位数是多少.(3)能,可以确定有75%的员工工资在1万元以上,其中25%的员工工资在3万元以上.(4)收入的中位数大约是2万. 因为有年收入100万这个极端值的影响,使得年平均收入比中位数高许多. 6、甲机床的平均数=1.5x 甲,标准差=1.2845s 甲;乙机床的平均数 1.2z y =,标准差0.8718z s =. 比较发现乙机床的平均数小而且标准差也比较小,说明乙机床生产出的次品比甲机床少,而且更为稳定,所以乙机床的性能较好. 7、(1)总体平均数为199.75,总体标准差为95.26.(2)可以使用抓阄法进行抽样. 样本平均数和标准差的计算结果和抽取到的样本有关. (3) (4)略 习题2.2 B 组(P82)1、(1)由于测试1T 的标准差小,所以测试1T 结果更稳定,所以该测试做得更好一些.(1)散点图如下:(2)由于2T 测出的值偏高,有利于增强队员的信心,所以应该选择测试2T .2、说明:此题需要在本节开始的时候就布置,先让学生分头收集数据,汇总所收集的数据才能完成题目.2.3变量间的相关关系 练习(P85)1、从已经掌握的知识来看,吸烟会损害身体的健康. 但除了吸烟之外,还有许多其他的随机因素影响身体健康,人体健康是很多因素共同作用的结果. 我们可以找到长寿的吸烟者,也更容易发现由于吸烟而引发的患病者,所以吸烟不一定引起健康问题. 但吸烟引起健康问题的可能性大,因此“健康问题不一定是由吸烟引起的,所以可以吸烟”的说法是不对的.2、从现在我们掌握的知识来看,没有发现根据说明“天鹅能够带来孩子”,完全可能存在既能吸引天鹅和又使婴儿出生率高的第3个因素(例如独特的环境因素),即天鹅与婴儿出生率之间没有直接的关系,因此“天鹅能够带来孩子”的结论不可靠.而要证实此结论是否可靠,可以通过试验来进行. 相同的环境下将居民随机地分为两组,一组居民和天鹅一起生活(比如家中都饲养天鹅),而另一组居民的附近不让天鹅活动,对比两组居民的出生率是否相同. 练习(P92)1、当0x =时,147.767y =,这个值与实际卖出的热饮杯数150不符,原因是:线性回归方程中的截距和斜率都是通过样本估计的,存在随机误差,这种误差可以导致预测结果的偏差;即使截距和斜率的估计没有误差,也不可能百分之百地保证对应于x ,预报值y 能够等于实际值y . 事实上:y bx a e =++. (这里e 是随机变量,是引起预报值y 与真实值y 之间的误差的原因之一,其大小取决于e 的方差.)2、数据的散点图为:从这个散点图中可以看出,鸟的种类数与海拔高度应该为正相关(事实上相关系数为0.793). 但是从散点图的分布特点来看,它们之间的线性相关性不强. 习题2.3 A 组(P94)1、教师的水平与学生的学习成绩呈正相关关系. 又如,“水涨船高”“登高望远”等.2、 (2)回归直线如下图所示:(3)基本成正相关关系,即食品所含热量越高,口味越好.(4)因为当回归直线上方的食品与下方的食品所含热量相同时,其口味更好. 3、(1)散点图如下:(2)回归方程为:0.66954.933y x =+.(3)加工零件的个数与所花费的时间呈正线性相关关系. 4、(1)散点图为:(2)回归方程为:0.546876.425y x =+.(3)由回归方程知,城镇居民的消费水平和工资收入之间呈正线性相关关系,即工资收入水平越高,城镇居民的消费水平越高.习题2.3 B 组(P95) 1、(1)散点图如下:(2)回归方程为: 1.44715.843y x =-.(3)如果这座城市居民的年收入达到40亿元,估计这种商品的销售额为42.037y ≈(万元). 2、说明:本题是一个讨论题,按照教科书中的方法逐步展开即可.第二章 复习参考题A 组(P100)1、A .2、(1)该组的数据个数,该组的频数除以全体数据总数; (2)nmN. 3、(1)这个结果只能说明A 城市中光顾这家服务连锁店的人比其他人较少倾向于选择咖啡色,因为光顾连锁店的人使一种方便样本,不能代表A 城市其他人群的想法.(2)这两种调查的差异是由样本的代表性所引起的. 因为A 城市的调查结果来自于该市光顾这家服装连锁店的人群,这个样本不能很好地代表全国民众的观点.4、说明:这是一个敏感性问题,可以模仿阅读与思考栏目“如何得到敏感性问题的诚实反应”来设计提问方法.5、表略. 可以估计出句子中所含单词的分布,以及与该分布有关的数字特征,如平均数、标准差等.6、(1)可以用样本标准差来度量每一组成员的相似性,样本标准差越小,相似程度越高. (2)A 组的样本标准差为 3.730A S ≈,B 组的样本标准差为11.789B S ≈. 由于专业裁判给分更符合专业规则,相似程度应该高,因此A 组更像是由专业人士组成的.7、(1)中位数为182.5,平均数为217.1875.(2)这两种数字特征不同的主要原因是,430比其他的数据大得多,应该查找430是否由某种错误而产生的. 如果这个大数据的采集正确,用平均数更合适,因为它利用了所有数据的信息;如果这个大数据的采集不正确,用中位数更合适,因为它不受极端值的影响,稳定性好. 8、(1)略.(2)系数0.42是回归直线的斜率,意味着:对于农村考生,每年的入学率平均增长0.42%.(3)城市的大学入学率年增长最快. 说明:(4)可以模仿(1)(2)(3)的方法分析数据.第二章 复习参考题B 组(P101)1、频率分布如下表:从表中看出当把 指标定为17.46千元时,月65%的推销员 经过努力才能完成销售指标.2、(1)数据的散点图如下:(2)用y 表示身高,x 表示年龄,则数据的回归方程为 6.31771.984y x =+. (3)在该例中,斜率6.317表示孩子在一年中增加的高度.(4)每年身高的增长数略. 3~16岁的身高年均增长约为6.323 cm. (5)斜率与每年平均增长的身高之间之间近似相等.第三章 概率3.1随机事件的概率 练习(P113) 1、(1)试验可能出现的结果有3个,两个均为正面、一个正面一个反面、两个均为反面. (2)通过与其他同学的结果汇总,可以发现出现一个正面一个反面的次数最多,大约在50次左右,两个均为正面的次数和两个均为反面的次数在25次左右. 由此可以估计出现一个正面一个反面的概率为0.50,出现两个均为正面的概率和两个均为反面的概率均为0.25. 2、略3、(1)例如:北京四月飞雪;某人花两元钱买福利彩票,中了特等奖;同时抛10枚硬币,10枚都正面朝上.(2)例如:在王府井大街问路时,碰到会说中文的人;去烤鸭店吃饭的顾客点烤鸭;在1~1000的自然数任选一个数,选到的数大于1.练习(P118)1、说明:例如,计算机键盘上各键盘的安排,公交线路及其各站点的安排,抽奖活动中各奖项的安排等,其中都用到了概率. 学生可能举出各种各样的例子,关键是引导他们正确分析例子中蕴涵的概率思想.2、通过掷硬币或抽签的方法,决定谁先发球,这两种方法都是公平的. 而猜拳的方法不太公平,因为出拳有时间差,个人反应也不一样.3、这种说法是错误的. 因为掷骰子一次得到2是一个随机事件,在一次试验中它可能发生也可能不发生. 掷6次骰子就是做6次试验,每次试验的结果都是随机的,可能出现2也可能不出现2,所以6次试验中有可能一次2都不出现,也可能出现1次,2次,…,6次. 练习(P121)1、0.72、0.6153、0.44、D5、B习题3.1 A组(P123)1、D.2、(1)0;(2)0.2;(3)1.3、(1)430.067645≈;(2)900.140645≈;(3)7010.891645-≈.4、略5、0.136、说明:本题是想通过试验的方法,得到这种摸球游戏对先摸者和后摸者是公平的结论. 最好把全班同学的结果汇总,根据两个事件出现的频率比较近,猜测在第一种情况下摸到红球的概率为110,在第二种下也为110. 第4次摸到红球的频率与第1次摸到红球的频率应该相差不远,因为不论哪种情况,第4次和第1次摸到红球的概率都是1 10.习题3.1 B组(P124)1、D.2、略. 说明:本题是为了学生根据实际数据作出一些推断. 一般我们假定每个人的生日在12个月中哪一个月是等可能的,这个假定是否成立,引导学生通过收集的数据作出初步的推断.3.2古典概率练习(P130)1、110. 2、17. 3、16.练习(P133)1、38,38.2、(1)113;(2)1213;(3)14;(4)313;(5)0;(6)213;(7)12;(8)1.说明:模拟的方法有两种.(1)把1~52个自然数分别与每张牌对应,再用计算机做模拟试验.(2)让计算机分两次产生两个随机数,第一次产生1~4的随机数,代表4个花色;第二次产生1~13的随机数,代表牌号.3、(1)不可能事件,概率为0;(2)随机事件,概率为49;(3)必然事件,概率为1;(4)让计算机产生1~9的随机数,1~4代表白球,5~9代表黑球.4、(1)16;(2)略;(3)应该相差不大,但会有差异. 存在差异的主要原因是随机事件在每次试验中是否发生是随机的,但在200次试验中,该事件发生的次数又是有规律的,所以一般情况下所得的频率与概率相差不大.习题3.2 A组(P133)1、游戏1:取红球与取白球的概率都为12,因此规则是公平的.游戏2:取两球同色的概率为13,异色的概率为23,因此规则是不公平的.游戏3:取两球同色的概率为12,异色的概率为12,因此规则是公平的.2、第一位可以是1~9这9个数字中的一个,第二位可以是0~9这10个数字中的一个,所以(1)190;(2)18919090-=;(3)9919010-=3、(1)0.52;(2)0.18.4、(1)12;(2)16;(3)56;(4)16.5、(1)25;(2)825.6、(1)920;(2)920;(3)12.习题3.2 B组(P134)1、(1)13;(2)14.2、(1)35;(2)310;(3)910.说明:(3)先计算该事件的对立事件发生的概率会比较简单.3、具体步骤如下:①建立概率模型. 首先要模拟每个人的出生月份,可用1,2,…,11,12表示月份,用产生取整数值的随机数的办法,随机产生1~12之间的随机数. 由于模拟的对象是一个有10个人的集体,故把连续产生的10个随机数作为一组模拟结果,可模拟产生100组这样的结果.②进行模拟试验. 可用计算器或计算机进行模拟试验.如使用Excel软件,可参看教科书125页的步骤,下图是模拟的结果:其中,A,B,C,D,E,F,G,H,I,J的每一行表示对一个10人集体的模拟结果. 这样的试验一共做了100次,所以共有100行,表示随机抽取了100个集体.③统计试验的结果. K,L,M,N列表示统计结果. 例如,第一行前十列中至少有两个数相同,表示这个集体中至少有两个人的生日在同一月. 本题的难点是统计每一行前十列中至少有两个数相同的个数. 由于需要判断的条件态度,所以用K,L,M三列分三次完成统计.其中K列的公式为“=IF(OR(A1=B1,A1=C1,A1=D1,A1=E1,A1=F1,A1=G1,A1=H1,A1=I1,A1=J1,B1=C1,B1=D1,B1=E1,B1=F1,B1=G1,B1=H1,B1=I1,B1=J1,C1=D1,C1=E1,C1=F1,C1=G1,C1=H1,C1=I1,C1=J1,D1=E1,D1=F1,D1=G1,D1=H1,D1=I1,D1=J1),1,0)”,L列的公式为“=IF(OR(E1=F1,E1=G1,E1=H1,E1=I1,E1=J1,F1=G1,F1=H1,F1=I1,F1=J1,G1=H1,G1=I1,G1=J1,H1=I1,H1=J1,I1=J1),1,0)”,M列的公式为“=IF(OR(K1=1,L1=1),1,0)”,M列的值为1表示该行所代表的10人集体中至少有两个人的生日在同一个月. N1表示100个10人集体中至少有两个人的生日在同一个月的个数,其公式为“=SUM(M$1:M$100)”. N1除以100所得的结果0.98,就是用模拟方法计算10人集体中至少有两个人的生日在同一个月的概率的估计值. 可以看出,这个估计值很接近1.3.3几何概率练习(P140)1、(1)1;(2)38.2、如果射到靶子上任何一点是等可能的,那么大约有100个镖落在红色区域.说明:在实际投镖中,命中率可能不同,这里既有技术方面的因素,又是随机因素的影响,所以在投掷飞镖、射击或射箭比赛中不会以一枪或一箭定输赢,而是取多次成绩的总和,这就是为了减少随机因素的影响.习题3.3 A组(P142)1、(1)49;(2)13;(3)29;(4)23;(5)59.2、(1)126;(2)12;(3)326;(4)326;(5)12;(6)313.说明:(4)是指落在6,23,9三个相邻区域的情况,而不是编号为6,7,8,9,四个区域.。


高中数学第二章统计 2.1 随机抽样教材习题点拨新人教B版必修3练习A1.什么是简单随机抽样?解:一般地,从元素个数为N的总体中不放回地抽取容量为n的样本,如果每一次抽取时总体中的各个个体有相同的可能性被抽到,这种抽样方法叫做简单随机抽样.2.在一般“调查”时,为什么要进行抽样调查?解:做一般“调查”最好是对每一个个体逐一进行“调查”,但这样做有时费时、费力,有时根本无法实现,一个行之有效的办法就是在每一个个体被抽取的机会均等的前提下从总体中抽取部分个体,进行抽样调查.3.如果想了解你所在班上同学喜欢听数学课的比例,计划抽取8名同学做调查.请你用抽签法抽取一个样本.解:(1)将班内60名同学的学号1,2,…,60分别写在相同的60X纸片上.(2)将60X纸片放在一个容器里均匀搅拌之后,就可以抽样.(3)抽出一X纸片,记下上面的,然后均匀搅拌,继续抽取第2X纸片,记下这个,重复这个过程,直到取得8个时终止.(4)于是,和这8个对应的同学就构成了一个简单随机样本.练习B1.某居民区有730户居民,居委会计划从中抽取25户调查其家庭收入状况,你能帮助居委会抽出一个简单随机样本吗?解:随机数表法:(用教材第87页的随机数表)(1)将730户居民编号为001,002, (730)(2)给出的随机数表是5个数一组,使用各个5位数组的后3位,从各个数组中任选一个后3位小于或等于730的数作为起始,如从第2行的第6组开始,取出572作为25户中的第1个代号;(3)继续向右读,每组后3位符合要求的数取出,前面已经取出的跳过,到行末转下一行从左向右继续读,得数据:572,483,459,073,242,372,048,088,600,636,171,247,303,422,421,183,546,385,120,042 ,320,500,219,225,059.编号为以上所选的25个的居户被选中.2.使用计算器或计算机制作一X1 000个一位数的随机数表,并检查0~9这10个数在表中出现的可能性是否相同?解:相同.练习A1.什么是系统抽样?系统抽样有什么优点?解:将总体分成均衡的若干部分,然后按照预先制定的规则,从每一部分抽取一个个体,得到所需要的样本,这种抽样的方法叫做系统抽样.系统抽样的优点:它很好地解决了当总体容量和样本容量都较大时,用简单随机抽样不方便的问题.2.从编号为1~900的总体中用系统抽样的办法抽取一个容量为9的样本.解:按编号顺序分成9组,每组100个号,先在第一组用简单随机抽样方式抽出k(1≤k≤100)号,其余的k+100n(n=1,2,…,8)也被抽到,即可得所需样本.练习B1.某批产品共有1 563件,产品按出厂顺序编号,为从1~1 563.检测员要从中抽取15件产品作检测,请你给出一个系统抽样方案.解:S1 将产品的调整为0001,0002,0003, (1563)S2 从总体中剔除3件产品(剔除方法可用随机数表法),将剩下的1 560件产品重新编号(分别为0001,0002,…,1560),并分成15段;S3 在第一段0001,0002,...,0104,这104个编号中用简单随机抽样抽出一个(如0003)作为起始,则各段对应编号分别为0003,0107,0211, (1459)S4 将编号为0003,0107,0211,…,1459的个体抽出,即得到一个容量为15的样本.2.要考察某商场2003年的日销售额,从一年时间中抽取52天的销售额作为样本,请给出你的系统抽样方案.并说说你的抽样方案的优点和不足.解:S1 用随机数表法从365天中随机剔除1天;S2 将其余的364天编号,为001,002,003,…,364,并将依次分为52段;S3 在第一段001,002,…,007这7个中用抽签法选取一个,如002;S4 将为002,009,016,…,359的日期找出,组成样本.该抽样方案的优点是:抽取的样本能代表总体;缺点是:所抽取的日期与日常用的日期相比规律性差,不便于该方案的操作.练习A1.某校高一学生共500名,经调查,喜欢数学的学生占全体学生的30%,不喜欢数学的人数占40%,介于两者之间的学生占30%.为了考查学生的期中考试的数学成绩,如何用分层抽样抽取一个容量为50的样本.解:由题意知喜欢数学的学生有150人,不喜欢数学的有200人,介于两者之间的有150人.三个层次的学生人数之比为3∶4∶3.所以应抽喜欢数学的学生15人,不喜欢数学的学生20人,介于两者之间的学生15人.用随机数表法抽样分别从对应的部分抽取相应的人数即可.2.某公司有员工500人,其中不到35岁的有125人,35~49岁的有280人,50岁以上的有95人.为了调查员工的身体健康状况,从中抽取100名员工,用分层抽样应当怎样抽取?解:S1 确定抽样比100500=15,所以不到35岁的应抽取125÷5=25(人),35~49岁的应抽取280÷5=56(人),50岁以上的应抽取95÷5=19(人);S2 用简单随机抽样法或系统抽样法分别抽取不到35岁的25人,35~49岁的56人;50岁以上的19人.这些人便组成了我们要抽取的样本.3.某大学就餐中心为了了解新生的饮食习惯,以分层抽样的方式从1 500名新生中抽取200名进行调查,新生中的南方学生有500名,北方学生有800名,西部地区的学生有200名,应如何抽取?解:由题意知南方学生有500名,北方学生有800名,西部地区的学生有200名.样本容量与总体容量的比为200∶1 500=2∶15.所以应抽取南方学生约67名,北方学生约106名,西部地区的学生约27名.用分层抽样法分别从对应的部分抽取相应的人数即可.练习B某市电视台在因特网上征集电视节目的现场参与观众,报名的共有12 000人,分别来自4个城区,其中东城区2 400人,西城区4 605人,南城区3 795人,北城区1 200人.用分层抽样的方式从中抽取60人参加现场节目,应当如何抽取?解:从12 000人中抽取60人,抽取比例为12 000∶60=200∶1,所以应在东城区抽取 2 400÷200=12(人),在西城区抽取 4 605÷200≈23(人),在南城区抽取 3 795÷200≈19(人),在北城区抽取1 200÷200=6(人).用系统抽样法分别从对应的部分抽取相应的数即可.练习A1.想一想怎样可以得到你所在班级同学的身高数据.解:设计调查问卷请每位同学填写自己的身高,然后汇总即可.2.你还能想到哪些可以得到数据资料的途径?解:如:教材或教材提供的数据;课堂数据(它们是在教室中收集的,主要与班上的学生有关,而不问结论是否对于更大的群体也成立).练习B为了了解中学生如何度过课余时间,请你设计一份关于中学生课余活动的调查问卷,实际调查后写出调查分析报告.解:提示:在设计调查问卷时,设计的题目意思要明确,覆盖面要广,不要有答题倾向即可.习题2-1A1.为了考察某地10 000名高一学生的体重情况,从中抽出了200名学生做调查.这里的总体、个体、样本、样本容量各指什么?为什么我们一般要从总体中抽取一个样本,通过样本来研究总体?解:统计的总体是指该地10 000名高一学生的体重;个体是指这10 000名学生中每一名学生的体重;样本是指这10 000名学生中抽出的200名学生的体重;样本容量为200.若对每一个个体逐一进行“调查”,有时费时、费力,有时根本无法实现,一个行之有效的办法就是在每一个个体被抽取机会均等的前提下从总体中抽取部分个体,进行抽样调查.2.要从编号为1~100的100道选择题中随机抽取20道题组成一份考卷,请你用抽签法给出考题的编号.解:(1)编号1~100;(2)制作大小相同的号签,并写上;(3)放入一个大容器,均匀搅拌;(4)依次抽取20个签(注意每次都要均匀搅拌),具有这20个编号的题组成一份考卷.3.某商店有590件货物,要从中选出50件货物做质量检查,请你用随机数表法给出一个抽样方案.解:(1)将590件货物编号为001,002, (590)(2)给出的随机数表是5个数一组,使用各个5位数组的中间3位,从各个数组中任选中间3位小于或等于590的数作为起始,如从第3行的第4列数037开始,取出037作为590件货物中的第1个代号;(3)继续向右读,将每组中间3位符合要求的数取出,已取出重复的跳过,到行末转下一行从左向右继续读,得数据:037,104,460,463,317,290,030,042,142,237,318,154,038,212,404,132,…,编号为以上所选的50个的货物被选中,即得到一个容量为50的样本.4.故宫博物院某天接待游客10 000人(假设把他们编号为0~9 999),如果要从这些游客中随机选出10名幸运游客,请你用系统抽样的方式给出幸运游客的编号.解:按编号顺序分成10组,每组1 000个号,先在第1组用简单随机抽样方式取出k(0≤k≤999)号,其余的k+1 000n(n=1,2,…,9)也被抽到,即可得到所需样本.5.一支田径队中有男运动员56人,女运动员42人,用分层抽样的方式从全队中抽取28名运动员.解:从男运动员中抽16人,女运动员中抽12人.6.某市有210家百货商店,其中大型商店有20家,中型商店有40家,小型商店有150家.为了了解商店的销售情况,要从中抽取21家商店进行调查,请你用分层抽样的方式进行抽取.解:大型商店、中型商店、小型商店分别抽取2家、4家、15家.习题2-1B1.某公园为了考察每天游览的人数,从一年中要抽取30天进行统计,请你分别用随机数表法、系统抽样法、分层抽样法给出样本,并根据样本比较这3种抽样方式.解:方法1:随机数表法S1 将一年的365天编号为001,002, (365)S2 在教材第一节提供的随机数表中任选一数作为开始,任选一方向作为读数方向,比如,选第1行第6个数“5”,向右读;S3 从数“5”开始,向右读,每次读取3位,凡不在001~365中的数跳过去不读,前面已经读过的也跳过去不读,依次可得到30个符合要求的;S4 以上对应的日期就是抽取的对象.方法2:系统抽样法S1 将365天用随机方式编号;S2 从总体中剔除5天(剔除方法可用随机数表法),将剩下的360天重新编号(分别为001,…,360),并分成30段;S3 在第一段001,…,012这12个编号中用简单随机抽样抽出一个(如003)作为起始;S4 将编号为003,015,027,…,351的日期抽出,组成样本.方法3:分层抽样法S1 将一年分为春、夏、秋、冬四个层次;S2 在每个层次中用随机数表法抽取8天;S3 4×8=32,再用抽签法剔除2天,剩下的30天组成样本.点拨:3种抽样方法的共同点是每个个体被抽到的可能性均相等.2.随着互联网络的发展与普及,网络调查方式的使用越来越多.你能比较一下传统的调查方式与网络调查方式的优劣吗?解:网络调查省时、省力,但有时也不具备代表性.如调查农业方面的问题,应该调查农民,但农民上网的人数很少;传统调查方式虽费时、费力,但针对性强.。
高中数学必修三第二章复习1
组内所取值的个数与总数比值的大小。
这条光滑的曲线就叫做总体密度曲线。
总体密度曲线精确的反应了一个总体在各个区域内取值的百分比。
总体密度曲线频率分布折线图
1、一个容量100的样本,其数据的分组与各组的频数如下表
组别(0,10](10,20](20,30](30,40](40,50](50,60](60,70]
频数12 13 24 15 16 13 7 则样本数据落在(10,40]上的频率为()
A. 0.13
B. 0.39
C. 0.52
D. 0.64
2、(山东理8)某工厂对一批产品进行了抽样检测.有图是根据抽样检测后的
产品净重(单位:克)数据绘制的频率分布直方图,其中产品
净重的范围是[96,106],样本数据分组为[96,98),[98,100),
0.150
0.125
(n x x ++-
1、(江苏6)某校甲、乙两个班级各有5名编号为1,2,3,4,5的学生进行投篮练习,每人投10次,投中的次数如下表:
学生1号2号3号4号5号
甲班 6 7 7 8 7
乙班 6 7 6 7 9
则以上两组数据的方差中较小的一个为2s .
2、(浙江文14)某个容量为100的样本的频率分布直方图如下,则在区间[4,5)上的数据的频数
..为.
其中平均数为;
众数为;
中位数为。
3、天津11)某学院的A,B,C三个专业共有1200名学生,为了调查这些学生勤工俭学的情况,拟采用分层抽样的方法抽取一个容量为120的样本。
已知该学院的A专业有380名学生,B专业有420名学生,则在该学院的C专业应抽取____名学生。
3、右图是根据某赛季甲、乙两名篮球运动员每场比赛得
分情况画出的茎叶图.从这个茎叶图可以看出甲、乙两名运
动员得分的中位数分别是()
A. 31,26 B. 36,23
12
2
13。