参考值范围估计
- 格式:ppt
- 大小:3.65 MB
- 文档页数:41
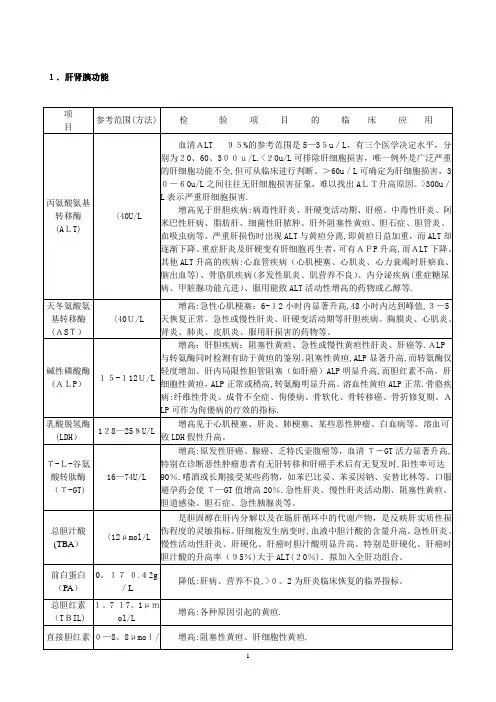

·医学研究统计方法应用·作者单位:515031广东汕头大学医学院预防医学教研室第十一讲 如何确定参考值的范围陈彬 李丽萍 李克 参考值范围(reference range ,旧称正常值),又叫临床参考值范围或正常参考值范围等,源于临床医学中对疾病诊断和治疗的实际需要,重点放在个体求医者或病人,用于鉴别诊断、筛选病人、评价疗效与预后评估,因此,临床应提供生理、生化、病理及免疫等方面的参考值范围。
从当前医学期刊中有关确定参考值范围的论文看,应该注意的问题为:(1)保证研究对象的同质性,如调查不同季节,不同时间的正常人;限定条件,如晨起空腹,一日内某时间或某状态下,用回归分析校正某相关因素的影响等;(2)控制监测误差;(3)判定分组,是否按地区、民族、性别和年龄等分组;(4)适宜的样本例数;(5)合理确定单、双侧;(6)选定适宜的百分范围:(7)必要时确定可疑范围;(8)结合资料分布,分别按单指标或多指标选用统计方法和估计界值。
一般说,对于近似正态分布的单指标资料,正态分布法与百分位数法结果相近;(9)对新确定的参考值范围进行医学实践检验、诊断试验评价。
现对临床应用中选择方法、样本例数、诊断试验评价、百分数大小、建立方程与确定时间等作如下介绍。
一、选择适宜的确定医学参考值范围的统计方法医学上为判断受检查者属于何种状态,可采用:(1)单指标评价(称单指标法),确定参考值范围的方法有百分位数法、正态分布法和回归方程法(一个方程)等[123];(2)多指标综合评价(属多指标方法),确定参考值范围的方法有多指标百分位数法和多指标正态分布法、组合指标法、两类指标组合指标法、多个回归方程法[3],观察结果可直接用于判断,可提供具体异常指标;(3)用一至数个综合指标判别(属多指标方法),确定参考值范围的方法有方差方程法、多元容许区间H 值法和多维标度法[224]。
查阅1998~2000年中华医学会系列杂志14篇确定参考值范围的文章,其中有12篇为多指标,但没有一篇论文明确提出用多指标方法确定参考值范围。

95的可信区间和参考值范围1.引言1.1 概述引言是一篇文章的开头部分,用于概述文章的主题和目的。
本文将探讨95的可信区间和参考值范围。
在统计学中,可信区间是用于估计参数真实值的一种方法,常用于分析数据和进行推断。
而参考值范围则是用于确定一组数据中的正常范围或标准范围。
通过对这两个概念的研究和应用,我们可以更准确地评估数据的可靠性和确定合适的标准。
在正文中,我们将首先介绍可信区间的概念和计算方法。
可信区间是对参数真实值的估计范围,它给出了一个具有一定置信度的区间范围。
通过了解如何计算95的可信区间,我们可以在数据分析和预测中获得更准确的结果。
接着,我们将探讨可信区间的应用。
可信区间可以帮助我们评估样本数据的可靠性,从而更好地理解总体参数的真实情况。
此外,我们还将讨论参考值范围的确定方法。
通过确定参考值范围,我们可以判断一组数据是否在正常范围内,对异常值进行排除或进一步分析。
综上所述,本文将详细介绍95的可信区间和参考值范围的概念、计算方法和应用。
通过学习和理解这些内容,我们可以提高数据分析的准确性和可靠性,为决策提供科学依据。
1.2文章结构1.2 文章结构本文将分为以下几个部分进行讨论和分析。
第一部分是引言,将概述本文所要论述的内容,并介绍文章的结构和目的。
引言部分将帮助读者了解本文的主题和背景,使其有针对性地理解和解读后续的论述。
第二部分是正文,主要分为两个小节。
第二节将介绍可信区间的概念,包括其定义、意义和应用。
我们将详细解释什么是可信区间,为什么需要使用可信区间进行统计推断,以及可信区间在实际问题中的作用。
在第三节中,我们将详细说明如何计算得到一个数据的95的可信区间。
通过具体的计算案例,我们将演示如何根据给定的样本数据和置信水平来计算得到可信区间。
第三部分是结论,将对前面的内容进行总结,并进一步讨论可信区间的应用和参考值范围的确定。
我们将强调可信区间在统计推断中的重要性,并介绍如何利用可信区间来确定参考值范围。



医学参考值范围摘要】目的医学参考值范围(reference value range)传统上称作正常值范围(normal range),指正常人的解剖、生理、生化、免疫及组织代谢产物的含量等各种数据的波动范围。
讨论医学参考值范围。
方法查阅文献资料并根据个人经验进行归纳总结。
结论关于“正常值范围”这一说法,在其意义、推理和观念上都比较模糊,现已很少使用,而改用“参考值范围”。
其确切含义为从选择的参照总体上获得的所有检查结果,用统计方法建立百分位数界限时所得到的区间称为参考值范围。
习惯上是包含95%的参照总体的范围。
【关键词】医学参考值范围一、医学参考值范围的概念医学参考值范围(reference value range)传统上称作正常值范围(normal range),指正常人的解剖、生理、生化、免疫及组织代谢产物的含量等各种数据的波动范围。
由于存在生物一、医学参考值范围的概念医学参考值范围(reference value range)传统上称作正常值范围(normal range),指正常人的解剖、生理、生化、免疫及组织代谢产物的含量等各种数据的波动范围。
由于存在生物个体变异,每个正常人的测量值会有所不同,即使是同一个人也会因机体的内外环境变化而改变。
因此同属正常人也不能以某一个测量数据作为标准,而必须确定一个波动范围,如一般以4.0×109/L~10.0×109/L作为成人白细胞数总数的参考值范围。
关于“正常值范围”这一说法,在其意义、推理和观念上都比较模糊,现已很少使用,而改用“参考值范围”。
其确切含义为从选择的参照总体上获得的所有检查结果,用统计方法建立百分位数界限时所得到的区间称为参考值范围。
习惯上是包含95%的参照总体的范围。
使用“参考值范围”的目的主要有两个方面:一是基于临床实践,着眼于个体,作为划分正常人与异常人的界线;二是基于预防医学实践,着眼于人群,如制订不同性别、年龄的儿童某项发育指标的等级标准,用来评价儿童的发育水平等。

95医学参考值范围的计算公式在医学领域,参考值范围用于描述健康人群在项指标上的正常范围。
参考值的计算通常基于大量健康人群的研究数据,统计分析其指标测量结果的分布情况。
下面将介绍一些常用的方法和公式来计算参考值范围。
1.正态分布方法:正态分布是一种常见的连续性数据分布,适用于许多生物学和生理学指标的描述。
如果项指标呈正态分布,则可以使用以下公式计算其参考值范围:参考值下限=平均值-1.96*标准差参考值上限=平均值+1.96*标准差95%的正态分布落在平均值的两个标准差范围内,因此1.96是标准差的常数倍数,可以确保覆盖95%的数据。
2.百分位数方法:百分位数是用于描述数据排序位置的一种统计度量。
在计算参考值范围时,常用的是第2.5百分位数(下限)和第97.5百分位数(上限),它们刚好对应着覆盖95%的数据。
参考值下限=第2.5百分位数参考值上限=第97.5百分位数这种方法不需要假设数据服从正态分布,适用于任意分布形状的数据。
3.非参数方法:非参数方法是一类不需要对数据进行分布假设的统计分析技术。
其中,最常用的是基于中位数和四分位数的计算方法。
参考值下限=第25百分位数-1.5*IQR参考值上限=第75百分位数+1.5*IQR其中,IQR是四分位数间距(第75百分位数减去第25百分位数的差),1.5是一个常用的缩放因子。
这种方法对峰态分布和存在离群值的数据更具有鲁棒性。
需要注意的是,以上方法都是基于给定数据集的计算范围,而且以覆盖大多数正常人的数据为目标。
具体的参考值范围可能会因地区、种族、年龄等因素的差异而有所变化。
此外,对于一些指标,性别和年龄是重要的影响因素,可以通过建立不同性别和年龄组的子参考值范围来更准确地确定正常范围。
最后,计算参考值范围时还需要考虑样本大小和样本分布的合理性。
通常,需要大样本量的数据才能更准确地估计参考值范围,并应探究分析数据是否呈现正态分布或其他偏离正态分布的特征。

参考范围的确定方法1980年美国医学检验杂志(AmJMedTechnol)发表了一篇文章,题为“参考值(正常范围)”:对实验室工作者的挑战。
文章一开头就提出,没有适当的参考资料,要解释实验室数据是不可能的。
参考资料主要来自实验室,应该受到象对待个别病人结果一样的仔细研究。
说明参考资料的重要性及存在的问题。
确定参考范围是医学科研和卫生工作的重要课题,是医学试验评价的重要内容之一,也是检验工作者需要掌握和解决的问题。
参考范围有个体参考范围与群体参考范围两种,个体参考范围代表生物个体内变异,而群体参考范围反映生物个体间变异。
群体参考范围可以来源于文献报告,但采用文献报告要慎重,仪器厂商与商品试剂盒提供的参考范围更不可轻易引用。
一般来说,引进一种新方法,应该首先进行小样本量的参考值调查,如果结果与文献或厂家提供的数据相一致,就可以不再调查,否则应做进一步的调查,确定本实验室的参考范围。
下面就确定参考范围的做法和要求、常用统计方法、正态性检验及值得注意的几个问题作一简单介绍。
一、确定参考范围的通常做法和要求确定参考范围通常的做法是:选定足够数量的“健康”人(参考个体)作为调查的对象,根据实际测定条件进行统一而准确的测定,然后进行统计学处理。
在调查中应尽可能注意下列内容:1、参考人群的特点及其选择:性别、年龄、职业、身高、体重、习惯、遗传、种族与地理位置,调查人数及调查对象的征集方法,从集体中排除或包括的指标。
2、取标本时的环境与生理条件:紧张、运动、姿势、饮食(包括酒与饮料)、空腹时间、吸烟、住院或非住院、内分泌及生殖状况(月经、妊娠、口服避孕药)及药物。
3、标本的收集与贮存:动脉血、毛细管血或静脉血,有无用止血带,收集时间、抗凝剂、抽血与分离血浆(清)的间隔时间,标本运输、分析前贮存的温度及时间,冰冻、融化、溶血。
尿的一部分或24小时总量、防腐剂。
4、所用分析方法的可靠性:准确度、精密度,质量控制情况等。

总体均数可信区间与参考值范围的通联一、概述在统计学中,总体均数可信区间和参考值范围都是用来描述数据的指标范围,但二者的概念和应用情境略有不同。
本文将围绕总体均数可信区间和参考值范围的通联展开讨论,从简单到复杂,由表面到深层逐步探究二者之间的关联。
二、总体均数可信区间的概念总体均数可信区间是用来估计总体均数的范围,它告诉我们总体均数落在一个区间内的概率有多大。
一般来讲,总体均数可信区间可以用样本均数加减一个临界值来估计,临界值受到置信水平、总体标准差和样本量的影响。
总体均数可信区间常用于研究中,帮助我们了解总体均数的取值范围。
三、参考值范围的概念参考值范围是指在正常情况下某一生化指标或生理指标的参考取值范围,也叫正常参考值范围。
通常情况下,参考值范围是通过大样本的正常人裙进行统计得出的,它告诉我们在正常情况下某一指标应该具备的取值范围。
医学、生物学和健康管理领域经常使用参考值范围来评估个体的健康状况。
四、二者的通联总体均数可信区间和参考值范围都是用来描述指标范围的统计概念,二者之间存在一定的通联。
在某些情境下,总体均数可信区间可以用来解释参考值范围,也就是说,参考值范围可以看作是总体均数可信区间对于某一特定指标的应用。
通过对大量样本的统计分析,可以得出某一指标的参考值范围,而这个范围实质上也反映了总体均数可信区间的应用。
五、总结和回顾总体均数可信区间和参考值范围是统计学和医学领域常用的两种概念,它们都是用来描述指标范围的重要工具。
在理解和应用这两种概念时,我们需要注意其通联和区别,以便更好地理解数据和指标的含义。
总体均数可信区间可以帮助我们估计总体均数的范围,而参考值范围则是用来评估个体健康状况的重要参考。
二者在一定程度上存在通联,但在不同领域的应用和解释方式略有不同。
六、个人观点从我个人的角度来看,总体均数可信区间和参考值范围虽然在概念和应用上有些通联,但其实质和使用场景有很大的差异。
总体均数可信区间更偏向于对总体均数的估计和推断,而参考值范围更侧重于评估个体健康和生理状态。


置信区间与参考值范围的区别和联系全文共四篇示例,供读者参考第一篇示例:置信区间与参考值范围是统计学中常用的两个概念,它们在数据分析和推断中扮演着重要的角色。
虽然它们都涉及到一定范围内的数值,但是它们的含义、计算方式和应用场景都有所不同。
本文将重点讨论置信区间与参考值范围的区别和联系。
我们来解释一下置信区间和参考值范围的定义。
置信区间是用来估计一个总体参数(如平均值、比例等)的范围,该范围是在一定置信水平下的估计结果。
置信区间的计算方式通常是根据样本数据来进行推断,通过利用抽样方法和统计推断的理论,得出一个包含真实总体参数的区间。
我们可以说“某药物的疗效在95%置信水平下的置信区间为0.8到1.2”,这意味着我们有95%的把握相信该药物的疗效在0.8到1.2之间。
而参考值范围则是用来判断一个个体或样本中某个变量的数值是否在正常范围内的参考标准。
参考值范围通常是根据大量的观测数据和临床实验结果来建立的,它反映了某个变量在正常人群中的典型数值范围。
我们可以说“健康成年人的血压范围为90/60mmHg到140/90mmHg”,这就是血压的参考值范围。
置信区间和参考值范围的联系在于它们都涉及到了一定范围内的数值。
在统计学中,我们经常需要估计总体参数的范围或判断某个数值是否在正常范围内,这就需要用到置信区间和参考值范围。
它们都是从不同角度去描述数据的范围,在一定程度上可以相互补充。
置信区间和参考值范围之间也存在一些明显的区别。
置信区间是用来估计总体参数的范围,是对总体特征的一种推断;而参考值范围是根据个体或样本数据建立的参考标准,是对个体数值是否在正常范围内的判断。
置信区间通常涉及到一定的置信水平,如95%置信水平;而参考值范围则是根据健康人群的数据来建立的标准,通常不涉及置信水平。
置信区间和参考值范围在实际应用中也有着不同的用途。
置信区间可以帮助我们对总体参数进行估计,并评估估计结果的精确程度;而参考值范围则可以帮助医生判断个体的健康状况,指导诊断和治疗。
百分位数法估计参考值范围的条件百分位数法是一种用于对统计数据进行分类的数学方法,可以用来估计参考值范围,从而有助于分析数据以及预测未来结果。
根据统计学定义,百分位数可以定义为:“任何整数值,其前面的k%的数据等于该数值或更小的数字”,如median,它经常用来计算数据的中位数(50%)。
百分位数法可以用来估算参考值范围,确定数据所处的一定位置,从而更好地了解数据分布。
大多数统计分析都会使用百分位数法,以估算95%参考值范围。
根据样本总体分布,百分位数可以有效识别在同一位置的数据组,因此可以帮助我们分析数据中潜在的异常值,进而对未来结果进行预测。
要进行百分位数估计参考值范围,需要遵循一定的条件。
首先,样本总体必须正态分布,其次,数据分布必须服从贝塔分布,这就意味着不能有任何偏态或尖峰数据。
其次,数据必须是缺乏任何异常值,这包括离群点。
最后,数据分布必须是一致的,这样才能有助于形成整个参考值范围。
此外,在运用百分位数法估计参考值范围时,还必须计算偏度和峰度,以确定数据是否服从贝塔分布,以及无异常值。
其中,偏度是指数据的偏斜程度,峰度是指数据的尖形程度,它们可以帮助我们判断数据是否符合正态分布,从而进行百分位数分析或预测。
另外,当处理百分位数法估计参考值范围时,还必须考虑因素的相关性,如年龄、性别、教育程度、收入和其他特征等。
这些因素,以及它们之间的相关性,可以改变数据分布以及参考值范围,因此也不能忽视这种关系。
最后,在运用百分位数法估计参考值范围时,要注意样本数量的问题。
样本数量越大,可以形成的参考值范围越稳定,结果也越准确。
如果样本数量过小,数据的稳定性和准确性就不会很高,因此样本的大小也不可忽视。
百分位数法是一种非常有用的数据分析工具,可以帮助我们估算参考值范围,从而对未来结果进行预测。
但是,在使用百分位数法估计范围时,必须遵守一定的条件,例如样本总体在分布上必须正态分布,数据必须服从贝塔分布,样本数量也不能太小,才能形成更精准的参考值范围。
总体均数可信区间与参考值范围的联系总体均数可信区间与参考值范围的联系在统计学中,总体均数可信区间和参考值范围都是重要的概念,它们在数据分析和推断中扮演着关键的角色。
本文将深入探讨这两个概念之间的联系,通过从简到繁、由浅入深的方式,帮助读者更深入地理解它们。
1. 总体均数可信区间的定义总体均数可信区间是对总体均数的一个区间估计,它告诉我们总体均数落在这个区间的概率有多大。
一般来说,我们使用样本数据来估计总体均数,然后根据统计理论计算出一个区间,这个区间就是总体均数的可信区间。
如果我们通过抽样得到一个样本平均数为100,其95%置信水平的置信区间为[90, 110],那么我们就可以说我们有95%的把握认为总体均数在90到110之间。
2. 参考值范围的定义参考值范围是用来评价个体测定结果的合理范围,它是根据大量健康人群的数据计算得出的。
通常情况下,参考范围被定义为包含95%的健康人群的数值范围。
血糖的正常参考范围是4.0-6.0mmol/L,这意味着对于一个健康人群,有95%的人的血糖值会在这个范围内。
3. 总体均数可信区间与参考值范围的联系总体均数可信区间和参考值范围都是用来描述数据的范围,但它们的应用场景和含义有所不同。
总体均数可信区间是用来对总体均数进行估计和推断的,它反映了对总体均数的估计精度和可靠性。
而参考值范围则是用来评价个体测定结果的合理性,它反映了健康人群的数据范围。
4. 个人观点和理解在我的理解中,总体均数可信区间和参考值范围都是非常重要的统计概念。
在数据分析和统计推断中,我们经常需要对总体均数进行估计和推断,而总体均数可信区间提供了一个有效的工具。
而在临床诊断和健康评估中,参考值范围则可以帮助我们判断个体测定结果的合理性,对健康状况进行评估。
总体均数可信区间和参考值范围在实际应用中有着密切的联系,它们都是帮助我们更好地理解和解释数据的重要工具。
通过深入研究和理解这两个概念,我们能够更加准确地进行数据分析和推断,也能够更好地评价个体的健康状况。
参考范围的确定方法1980年美国医学检验杂志(AmJMedTechnol)发表了一篇文章,题为“参考值(正常范围)”:对实验室工作者的挑战。
文章一开头就提出,没有适当的参考资料,要解释实验室数据是不可能的。
参考资料主要来自实验室,应该受到象对待个别病人结果一样的仔细研究。
说明参考资料的重要性及存在的问题。
确定参考范围是医学科研和卫生工作的重要课题,是医学试验评价的重要内容之一,也是检验工作者需要掌握和解决的问题。
参考范围有个体参考范围与群体参考范围两种,个体参考范围代表生物个体内变异,而群体参考范围反映生物个体间变异。
群体参考范围可以来源于文献报告,但采用文献报告要慎重,仪器厂商与商品试剂盒提供的参考范围更不可轻易引用。
一般来说,引进一种新方法,应该首先进行小样本量的参考值调查,如果结果与文献或厂家提供的数据相一致,就可以不再调查,否则应做进一步的调查,确定本实验室的参考范围。
下面就确定参考范围的做法和要求、常用统计方法、正态性检验及值得注意的几个问题作一简单介绍。
一、确定参考范围的通常做法和要求确定参考范围通常的做法是:选定足够数量的“健康”人(参考个体)作为调查的对象,根据实际测定条件进行统一而准确的测定,然后进行统计学处理。
在调查中应尽可能注意下列内容:1、参考人群的特点及其选择:性别、年龄、职业、身高、体重、习惯、遗传、种族与地理位置,调查人数及调查对象的征集方法,从集体中排除或包括的指标。
2、取标本时的环境与生理条件:紧张、运动、姿势、饮食(包括酒与饮料)、空腹时间、吸烟、住院或非住院、内分泌及生殖状况(月经、妊娠、口服避孕药)及药物。
3、标本的收集与贮存:动脉血、毛细管血或静脉血,有无用止血带,收集时间、抗凝剂、抽血与分离血浆(清)的间隔时间,标本运输、分析前贮存的温度及时间,冰冻、融化、溶血。
尿的一部分或24小时总量、防腐剂。
4、所用分析方法的可靠性:准确度、精密度,质量控制情况等。