spss常见题型及解题思路与注意事项
- 格式:doc
- 大小:44.50 KB
- 文档页数:2
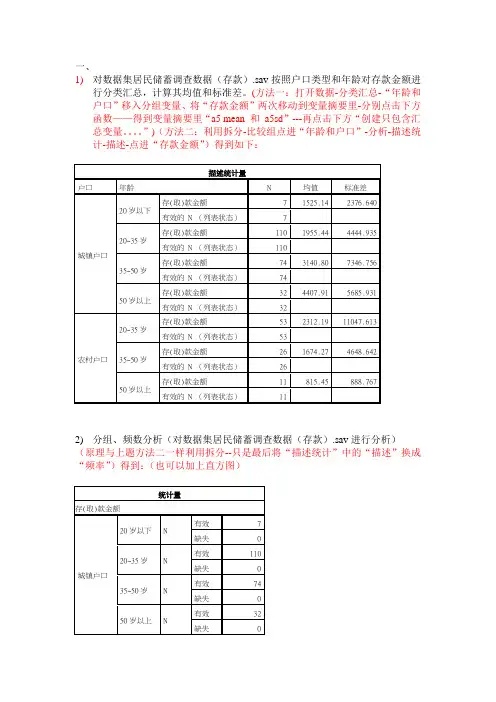
一、1)对数据集居民储蓄调查数据(存款).sav按照户口类型和年龄对存款金额进行分类汇总,计算其均值和标准差。
(方法一:打开数据-分类汇总-“年龄和户口”移入分组变量、将“存款金额”两次移动到变量摘要里-分别点击下方函数——得到变量摘要里“a5 mean 和a5sd”---再点击下方“创建只包含汇总变量。
”)(方法二:利用拆分-比较组点进“年龄和户口”-分析-描述统计-描述-点进“存款金额”)得到如下:2)分组、频数分析(对数据集居民储蓄调查数据(存款).sav进行分析)(原理与上题方法二一样利用拆分--只是最后将“描述统计”中的“描述”换成“频率”)得到:(也可以加上直方图)3)分析储户的户口和职业的基本情况(听老师说可以直接做饼状图:去掉拆分——图形-——旧对话框——饼图——个案组摘要、定义——职业移入“定义区分”,户口移入“行”)得出:4)分析储户一次存款金额的分布,并对城镇储户和农村储户进行比较。
存款金额分为500元以下(包括500元)、500~2000元,2000~3500元、3500-5000元,5000以上。
(将存款金额重新编码为不同变量,定义新值,做拆分—描述——频率:转换——重新编码不同变量——。
这个应该都熟悉具体不赘述,重新定义完后要返回到变量视图给“金额等级”赋值1代表500一下,2代表500-2000.。
然后做拆分(选入户口)——分析——频率——选入“金额等级”)得到:然后可以利用“复式条形图”做出下面:(去掉拆分——图形——旧对话框——条形图——复式条形图、定义——“金额等级”到类别轴,户口到定义类聚。
两个颠倒无所谓)二. 打开数据Employee data.sav,进行如下操作:1)计算薪水增加额(saladd = salary- salbegin)(简单不说了)2)将薪水增加额分为四组(1:<=10000;2:10000-20000;3:20000-30000;4:>30000)并将分组结果保存在为变量saladd_g,定义变量saladd_g的Label (变量名标签)为薪水增加等级。

1、 (1)操作:分析-回归-线性,因变量y,自变量x1,x2-确定。
得方程y=+。
(2)对回归方程的显著性检验:采用P 值法做检验,提出原假设H 0:β1=β2=0,构造统计量F=1)-p -SSE/(n SSR/p,p 是自变量个数此时是2,n 是样本个数14。
F 服从分布:F~F (2,11)。
从上图最后两列看出,在显著性水平α=的条件下,p 值=sig<α,从而拒绝原假设,即在显著性水平α=的条件下,认为y 与x1,x2有显著的线性关系。
对回归系数的显著性检验:采用P 值法做检验,提出原假设H 0:βi =0(i=1,2),构造统计量)1(t ~iii--=∧∧p n i c t σβ,其中1--=∧p n SSEσ。
p值=sig<α),从而拒绝原假设,即在显著性水平α=的条件下,认为xi(i=1,2)对因变量y的线性效果显著。
(3)操作:分析-回归-线性,因变量y,自变量x1,x2-统计量-回归系数-置信区间、估计。
得到βi 的1-α的置信区间为()β1的置信水平为的置信区间是(,);β2的置信水平为的置信区间是(,);(4)回归方程的复相关系数SST SSRR2=,比较接近1,说明回归方程拟合效果较好。
模型汇总模型RR 方 调整 R 方 标准 估计的误差1 .941a.885 .864a. 预测变量: (常量), x2, x1。
(5)操作:先把待预测的数据输入表格,分析-回归-线性,因变量y,自变量x1,x2,保存-预测值、残差项选择“未标准化”-预测区间(“均值”)。
得到E (y )的点估计值是,置信水平为的置信区间是(,)3、(1)操作:分析-回归-线性,因变量y,自变量x,确定。
得方程y=。
系数a模型 非标准化系数标准系数tSig. B标准 误差试用版 1(常量).442.065 x.004 .000.839.000a. 因变量: y(2)诊断该问题是否存在异方差性,两种方法等级相关系数法残差图e y ~∧。
一、
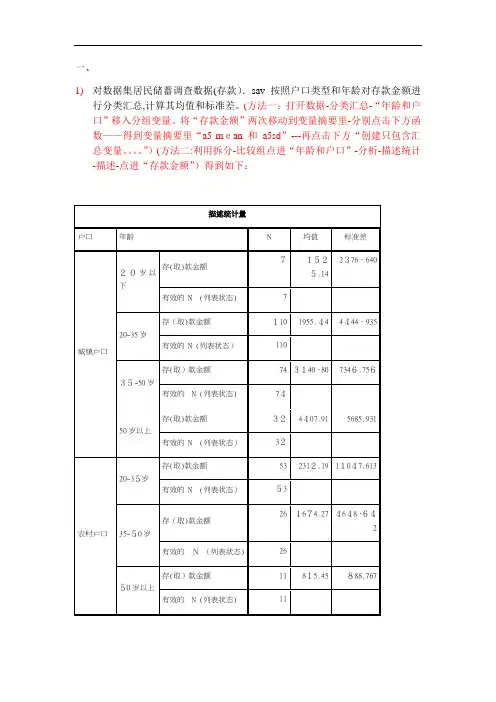
1)对数据集居民储蓄调查数据(存款).sav按照户口类型和年龄对存款金额进
行分类汇总,计算其均值和标准差。
(方法一:打开数据-分类汇总-“年龄和户口”移入分组变量、将“存款金额”两次移动到变量摘要里-分别点击下方函数——得到变量摘要里“a5 mean 和a5sd”---再点击下方“创建只包含汇总变量。
”)(方法二:利用拆分-比较组点进“年龄和户口”-分析-描述统计-描述-点进“存款金额”)得到如下:
2)分组、频数分析(对数据集居民储蓄调查数据(存款).sav进行分析)
(原理与上题方法二一样利用拆分--只是最后将“描述统计”中的“描述”换成“频率”)得到:(也可以加上直方图)
3)分析储户的户口和职业的基本情况(听老师说可以直接做饼状图:去掉拆分—
—图形-——旧对话框——饼图——个案组摘要、定义——职业移入“定义区分”,户口移入“行”)得出:。

spss习题及其答案
SPSS习题及其答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学和商业研究。
它可以帮助研究人员对数据进行分析、建模和预测。
在学习和使用SPSS的过程中,习题和答案是非常重要的,可以帮助我们更好地理解和掌握SPSS的使用方法和技巧。
下面是一些常见的SPSS习题及其答案,供大家参考:
1. 问题:如何在SPSS中导入数据?
答案:在SPSS中,可以通过“文件”菜单中的“打开”选项来导入数据,也可以直接拖拽数据文件到SPSS的工作区。
2. 问题:如何计算变量的描述性统计量?
答案:在SPSS中,可以使用“分析”菜单中的“描述统计”选项来计算变量的描述性统计量,包括均值、标准差、最大值、最小值等。
3. 问题:如何进行相关性分析?
答案:在SPSS中,可以使用“分析”菜单中的“相关”选项来进行相关性分析,可以计算变量之间的皮尔逊相关系数或斯皮尔曼相关系数。
4. 问题:如何进行回归分析?
答案:在SPSS中,可以使用“回归”选项来进行回归分析,可以进行简单线性回归、多元线性回归等不同类型的回归分析。
5. 问题:如何进行因子分析?
答案:在SPSS中,可以使用“因子”选项来进行因子分析,可以帮助研究人员发现变量之间的潜在结构和关联。
通过以上习题及其答案的学习和实践,我们可以更好地掌握SPSS的使用方法,提高数据分析的效率和准确性。
希望大家在学习SPSS的过程中能够多多练习,不断提升自己的数据分析能力。
SPSS习题及其答案是我们学习的好帮手,也是我们进步的动力。
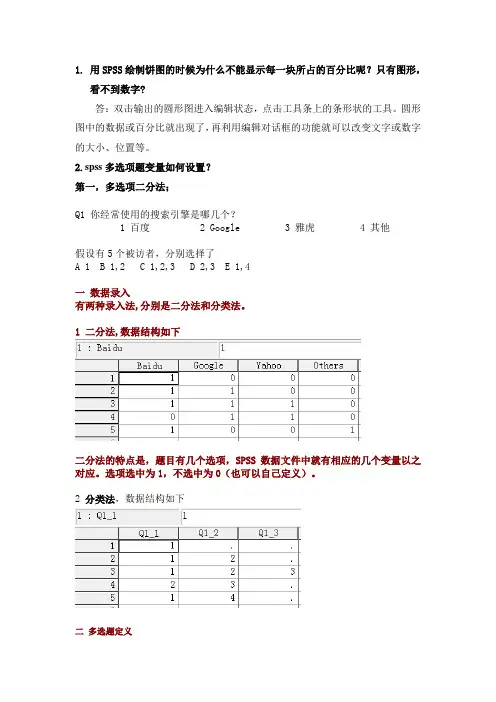
1.用SPSS绘制饼图的时候为什么不能显示每一块所占的百分比呢?只有图形,看不到数字?答:双击输出的圆形图进入编辑状态,点击工具条上的条形状的工具。
圆形图中的数据或百分比就出现了,再利用编辑对话框的功能就可以改变文字或数字的大小、位置等。
2.spss多选项题变量如何设置?第一,多选项二分法;Q1 你经常使用的搜索引擎是哪几个?1 百度2 Google3 雅虎4 其他假设有5个被访者,分别选择了A 1B 1,2C 1,2,3D 2,3E 1,4一数据录入有两种录入法,分别是二分法和分类法。
1 二分法,数据结构如下二分法的特点是,题目有几个选项,SPSS数据文件中就有相应的几个变量以之对应。
选项选中为1,不选中为0(也可以自己定义)。
2 分类法,数据结构如下二多选题定义SPSS中处理多选题,其实有两个模块。
一个是在菜单Analyze -- Multiple Response –define sets中,这个地方定义的多选题是临时的,如果你关闭SPSS后再打开,多选题还得重新定义。
1 二分法:1)在菜单中打开定义多选题的对话框,然后把同一道题目的几个变量选中,点击向右的三角形将它们移动到"Variables in Set" 这个框中2)在Variable Coding里选中Dichotomies,即二分法3)在Category Label Source里选"Variable Labels"4)Set Name:填入多选题编号,Set Label:填入多选题的题干(或其他你觉得合适的标签)5)点击Add定义完后,可操作Analyze -- Multiple Response –frequencies,定义的多选变量只能频数统计(Analyze -- Multiple Response --frequencies)和交叉列表(Analyze -- Multiple Response - crosstabs)2.假设检验1. 单一样本t检验(One-sample t test),是用来比较一组数据的平均值和一个数值有无差异。

spss试题简介:SPSS(Statistical Package for the Social Sciences)是一种用于统计学分析的软件工具。
它可以帮助研究者进行数据收集、数据清理、数据分析等一系列统计学任务。
本文将探讨SPSS试题的相关内容,包括SPSS的基本操作、常见题型以及解答技巧等。
一、SPSS基本操作在使用SPSS进行数据分析之前,首先需要掌握一些基本的操作技巧。
以下是一些常用的SPSS操作命令:1. 数据导入与保存:在SPSS中,可以通过导入数据文件的方式将外部数据引入到软件中。
常见的数据文件格式包括Excel、CSV等。
导入数据后,可以将数据保存为SPSS文件格式(.sav)以便后续使用。
2. 数据清理:数据清理是为了去除数据中的错误、缺失或异常值,保证数据的准确性和完整性。
SPSS提供了多种数据清理方法,包括删除异常值、插值处理等。
3. 数据描述性统计:使用SPSS进行描述性统计可以对数据进行初步分析,了解数据的分布情况、中心趋势和离散程度等。
常用的描述性统计方法包括频数、均值、标准差等。
4. 数据分析:SPSS提供了丰富的数据分析方法,包括t检验、方差分析、回归分析等。
根据实际需求,选择合适的分析方法进行数据处理和结果解读。
5. 图表制作:SPSS可以生成各种类型的图表,例如柱状图、折线图、散点图等,用于数据可视化展示。
通过图表,可以更直观地观察数据的特征和趋势。
二、SPSS常见试题1. 描述性统计题试题要求对一组数据进行描述性统计分析,如计算均值、标准差、频数等。
学生需要了解SPSS的描述性统计命令以及结果解读方法。
2. 假设检验题试题给出一组数据和相应的假设,要求学生使用SPSS进行假设检验,并给出结论。
学生需要掌握t检验、方差分析等假设检验方法,并能够解读SPSS输出结果。
3. 数据清理题试题提供一个包含错误或缺失值的数据集,要求学生使用SPSS进行数据清理。
学生需要了解SPSS的数据清理功能,并能够选择合适的方法进行数据处理。
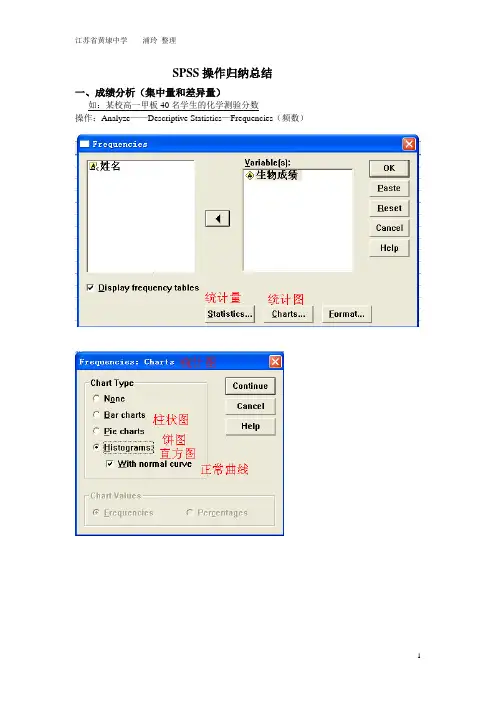
SPSS操作归纳总结一、成绩分析(集中量和差异量)如:某校高一甲板40名学生的化学测验分数操作:Analyze——Descriptive Statistics—Frequencies(频数)二、相关量1、积差相关系数如:40名学生的数学和化学成绩操作:Analyze——Correlate(相关)——BIvariate(双变量)结论:在0.01水平上学生的化学成绩与生物成绩相关,也就是说我们有99%的把握说学生的化学成绩与生物成绩密切相关。
分析:若Sig.(2-tailed)的值<0.05,则相关程度密切若Sig.(2-tailed)的值<0.01,则相关程度非常密切若Sig.(2-tailed)的值>0.05,则相关程度不密切2、点双列相关系数如:求若干名考生的生物成绩与性别之间的相关系数,并判断他们之间有无相关关系?操作:Analyze——Correlate(相关)——BIvariate(双变量)分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的生物成绩与性别无密切相关,也就是说我们没有95%的把握说学生的生物成绩与性别密切相关,或者说学生的生物成绩和性别无密切关系。
3、等级相关系数如:高考总分与生物等级、化学等级的相关操作:Analyze ——Correlate (相关)——BIvariate (双变量)注:相关系数为负值,说明为负相关,正值为正相关,而且绝对值越大,相关性越大。
该题中男表示为1,女表示为0,该结果为负值,说明女的成绩好,而男的成绩不好。
分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的三科总分与物理等级无密切相关,也就是说我们没有95%的把握说学生的三科总分与物理等级密切相关,或者说学生的三科总分与物理等级无密切关系。
补充:“物理等级”转换成“等级数”操作:Transform——Recode——Into different variables三、考试质量的分析1、难度分析(P)Analyze——Descriptive Statistics—Frequencies结论:客观题的难度P ——直接看得分的valid percent主观题的难度P——mean 除以该题的总分值2、区分度分析(1)用相关系数法求试题的区分度某一题的得分与该生总分的相关程度作为该题的区分度。

Spss试题(附解答和Spss数据库)一、对某型号的20根电缆依次进行耐压试验,测得数据如数据1,试在α=0.10的水平下检验这批数据是否受到非随机因素干扰。
解:本题采用单样本游程检验的方法来判断样本随机性。
原假设:这批数据是随机的;备择假设:这批数据不是随机的。
SPSS操作:Analyze -> Nonparametric Test -> Runs数据分析结果如下表所示:Runs Test耐电压值aTest Value 204.55Cases < Test Value 10Cases >= Test Value 10Total Cases 20Number of Runs 13Z .689Asymp. Sig. (2-tailed) .491a. Median结果:-- Test Value:204.55(即上面Cut Point设置的值)-- Asymp. Sig.=0.491,即P值=0.491大于显著水平0.10,则接受原假设,即样本是随机抽取的,这批数据未收到非随机因素干扰。
1二、为研究吸烟有害广告对吸烟者减少吸烟量甚至戒烟是否有作用。
从吸烟者总体中随机抽取33位吸烟者,调查他们在观看广告前后的每天吸烟量(支)。
试问影片对他们的吸烟量有无产生作用,(见数据2)解:本题采用配对样本T检验的方法。
原假设:影片对他们的吸烟量无显著影响;备择假设:影片对他们的吸烟量有显著影响。
SPSS操作:Analyze -> Compare Means -> Paired-Samples T Test… 数据分析结果如下表所示:Paired Samples StatisticsMean N Std. Deviation Std. Error MeanPair 1 21.58 33 10.651 1.854 看前(支)17.58 33 10.680 1.859 看后(支)Paired Samples CorrelationsN Correlation Sig.Pair 1 33 .878 .000 看前(支) & 看后(支)Paired Samples TestPaired Differences95% ConfidenceInterval of the Std.Difference Sig. Std. ErrorMean Deviation Mean Lower Upper t df (2-tailed)Pair 1 看前(支) 4.000 5.268 .917 2.132 5.868 4.362 32 .000 - 看后(支) 由表可知,看前样本均值为21.58,看后样本均值为17.58,此外,p值为0.000<0.05,因此,拒绝原假设,接受备择假设,即在α=0.05显著性水平下,影片对他们的吸烟量有显著影响。

数据分析技巧如何使用SPSS进行常见统计分析数据分析是现代社会中重要的一项技能,而SPSS是目前最为常用的数据分析软件之一。
本文将介绍如何使用SPSS进行常见的统计分析,并分享一些数据分析技巧。
一、准备数据在使用SPSS进行统计分析之前,首先需要准备好所需的数据。
数据可以来自不同的来源,如问卷调查、实验结果等。
确保数据的完整性和准确性对于后续的分析至关重要。
二、数据导入在SPSS中,可以通过导入功能将数据从外部文件导入到软件中进行分析。
SPSS支持多种数据格式,如Excel、CSV等。
导入数据时需要注意选择正确的数据类型和变量类型,并进行数据格式的转换和清理。
三、数据清洗数据清洗是数据分析的前提,通过删除或纠正数据中的错误或缺失值,确保数据的质量和一致性。
SPSS提供了强大的数据清洗功能,可以进行数据筛选、变量转换、缺失值处理等操作。
四、描述性统计分析描述性统计分析是对数据的基本特征进行统计概括和展示。
在SPSS中,可以使用频数分布表、均值、标准差等统计指标对数据进行描述性统计分析。
此外,还可以通过直方图、箱线图等图表形式展示数据的分布情况和异常值。
五、推断统计分析推断统计分析是在样本数据的基础上对总体进行推断的统计方法。
SPSS提供了多种推断统计分析方法,如t检验、方差分析、回归分析等。
这些方法可以用于检验假设、比较群体差异、预测因果关系等。
六、相关性分析相关性分析用于研究两个或多个变量之间的关系强度和方向。
在SPSS中,可以使用相关系数、散点图等方法进行相关性分析。
相关性分析可以帮助我们了解变量之间的关联性,从而更好地理解数据。
七、因子分析因子分析是一种数据降维的方法,可以将一组相关变量转化为较少的无关因子。
在SPSS中,可以通过因子分析来探索数据的内在结构和维度。
通过提取主成分或因子,可以简化数据集,使得后续分析更加便捷。
八、时间序列分析时间序列分析用于研究数据随着时间变化的趋势和规律。
SPSS提供了多种时间序列分析方法,如趋势分析、季节性分析等。
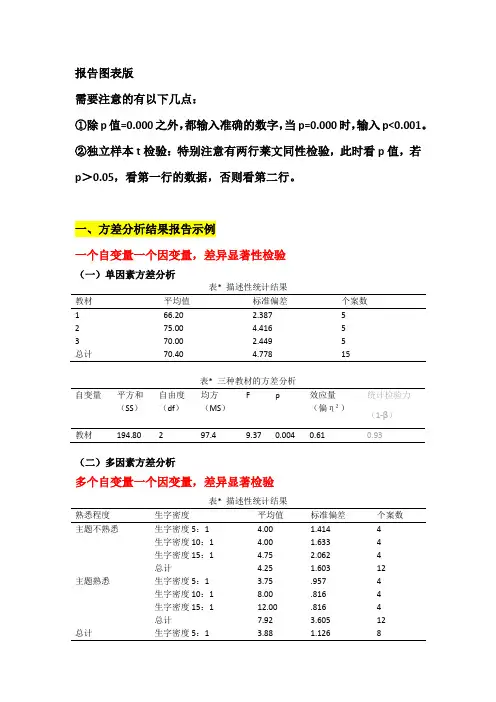
报告图表版需要注意的有以下几点:①除p值=0.000之外,都输入准确的数字,当p=0.000时,输入p<0.001。
②独立样本t检验:特别注意有两行莱文同性检验,此时看p值,若p>0.05,看第一行的数据,否则看第二行。
一、方差分析结果报告示例一个自变量一个因变量,差异显著性检验(一)单因素方差分析表* 描述性统计结果教材平均值标准偏差个案数166.20 2.3875275.00 4.4165370.00 2.4495总计70.40 4.77815表* 三种教材的方差分析自变量平方和(SS)自由度(df)均方(MS)F p效应量(偏η²)统计检验力(1-β)194.80297.49.370.0040.610.93(二)多因素方差分析多个自变量一个因变量,差异显著检验表* 描述性统计结果熟悉程度生字密度平均值标准偏差个案数主题不熟悉生字密度5:1 4.00 1.4144生字密度10:1 4.00 1.6334生字密度15:1 4.75 2.0624总计 4.25 1.60312主题熟悉生字密度5:1 3.75.9574生字密度10:18.00.8164生字密度15:112.00.8164总计7.92 3.60512总计生字密度5:1 3.88 1.1268生字密度10:1生字密度15:18.38 4.1388总计 6.08 3.30924表* 多因素方差分析结果误差来源平方和(SS)自由度(df)均方(MS)F p效应量(偏η²)统计检验力(1-β)熟悉程度80.67180.6743.34<0.0010.711生字密度81.08240.5421.78<0.0010.711熟悉程度*生字密度56.58228.2915.20<0.0010.630.997(三)协方差分析消除额外变量(干扰变量)对因变量的影响表* 描述性统计结果数学教学方法平均值标准偏差个案数187.00 5.57810271.608.23510381.90 5.36310总计80.179.06030表* 三种教学方法的分析误差来源平方和(SS)自由度(df)均方(MS)F p效应量(偏η²)统计检验力(1-β)数学平时成绩295.711295.719.010.0060.260.82数学教学方法73.67236.84 1.120.340.080.23二、t检验结果报告示例(一)单样本t检验对样本均数与总体均数之间的差异检验属于单样本t检验单样本t检验还适用于某一样本的均值与某一指定检验值的差异分析单样本t检验的原假设H0=某一样本的均值与总体均值(指定检验值)没有差异表* 某学校智力分数与总体均值的差异检验样本数(N)平均值(M)标准差(SD)检验值t p效应量(d)统计检验力智力4095.5310.994100-2.5740.0140.4070.709(二)独立样本t检验表* 男生与女生推理能力差异比较检验性别N M SD t p效应量(d)统计检验力男35103.8611.622 4.555<0.001 1.090.995女3591.8610.387ps:先看莱文方差等同性检验若p>0.05,就看第一行的数据。

SPSS练习题1、现有两个SPSS数据文件,分别为“学生成绩一”和“学生成绩二”,请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
先排序data---sort cases再合并data---merge files2、有一份关于居民储蓄调查的数据存储在EXCEL中,请将该数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。
转换Data---transpose,输题目3、利用第2题的数据,将数据分成两份文件,其中第一份文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000-2000之间的调查数据,第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
选取数据data---select cases4、利用第2题数据,将其按常住地(升序)、收入水平(升序)存款金额(降序)进行多重排序。
排序data---sort cases一个一个选,加5、根据第1题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算transform---count按个输,把所有课程选取,define设区间,再排序6、根据第1题的完整数据,计算每个学生课程的平均分和标准差,同时计算男生和女生各科成绩的平均分。
描述性统计,先转换Data---transpose学号放下面,全部课程(poli到his)放上面,ok,analyze---descriptive statistics---descriptives,全选,options。
先拆分data---split file 按性别拆分,analyze---descriptive statistics---descriptives全选所有课程options---mean7、利用第2题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
数据分组Transform---recode---下面一个,输名字,change,old,range,new value---add 挨个输,从小加到大,等距8、在第2题的数据中,如果认为调查“今年的收入比去年增加”且“预计未来一两年收入仍会会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。
spss多变量分析流程及注意事项下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!一、数据准备1. 收集数据:确保数据的准确性和完整性。
⼲货:SPSS问卷分析详解1编码录⼊调查分析问卷回收,在经过核实和清理后就要⽤SPSS做数据分析,⾸先的第⼀步就是把问题编码录⼊。
要根据问卷问题的不同定义变量。
定义变量值得注意的两点:1、区分变量的度量,其中Scale是定量、Ordinal是定序、Nominal是指定类;2、注意定义不同的数据类型。
各⾊各样的问卷题⽬的类型⼤致可以分为单选、多选、排序、开放题⽬四种类型,他们的变量的定义和处理的⽅法各有不同,现详细举例介绍如下:(1)、单选题:答案只能有⼀个选项 例⼀、当前贵组织机构是否设有⾯向组织的职业⽣涯规划系统? A有 B 正在开创 C没有 D曾经有过但已中断编码:只定义⼀个变量,Value值1、2、3、4分别代表A、B、C、D 四个选项。
录⼊:录⼊选项对应值,如选C则录⼊3(2)、多选题:答案可以有多个选项,其中⼜有项数不定多选和项数限定多选。
⽅法⼀(⼆分法): 例⼆、贵处的职业⽣涯规划系统⼯作涵盖哪些组群?画钩时请把所有提⽰考虑在内。
A⽉薪员⼯ B⽇薪员⼯ C钟点⼯编码:把每⼀个相应选项定义为⼀个变量,每⼀个变量Value值均如下定义:“0” 未选,“1” 选。
录⼊:被调查者选了的选项录⼊1、没选录⼊0,如选择被调查者选AC,则三个变量分别录⼊为1、0、1。
⽅法⼆(多重分类法):⽅法⼆(多重分类法) 例三、你认为开展保持党员先进性教育活动的最重要的⽬标是那三项: 1() 2 () 3()A、提⾼党员素质B、加强基层组织C、坚持发扬民主D、激发创业热情E、服务⼈民群众F、促进各项⼯作编码:定义三个变量分别代表题⽬中的1、2、3三个括号,三个变量Value值均同样的以对应的选项定义,即录⼊的数值1、2、3、4、5、6分别代表选项ABCDEF,相应录⼊到每个括号对应的变量下。
如被调查者三个括号分别选ACF,则在三个变量下分别录⼊1、3、6。
(3)、排序题:对选项重要性进⾏排序 例四、您购买商品时在①品牌②流⾏③质量④实⽤⑤价格中对它们的关注程度先后顺序是(请填代号重新排列) 第⼀位第⼆位第三位第四位第五位编码:定义五个变量,分别可以代表第⼀位~第五位,每个变量的Value都做如下定义:“1” 品牌,“2” 流⾏,“3” 质量,“4” 实⽤,“5” 价格录⼊:录⼊的数字1、2、3、4、5分别代表五个选项,如被调查者把质量排在第⼀位则在代表第⼀位的变量下输⼊“3“。
spss笔试期末试题及答案为了帮助大家更好地备考SPSS(统计软件)的使用能力,以下是一份关于SPSS的期末试题及答案。
通过完成这些试题,你将能够加深对SPSS的理解,并提升在统计分析领域的能力。
请务必仔细阅读每个试题,并按要求进行答题。
试题一:数据输入与管理(共20分)1. 请问SPSS支持的数据类型有哪些?(5分)答案:SPSS支持以下数据类型:数值型、字符型、日期型等。
2. 假设你有一份调查问卷数据,文件名为"survey.sav",其中包含了学生的姓名、性别、年龄、所在学院、成绩等信息。
请写出导入该数据文件的SPSS语法。
(5分)答案:GET DATA /TYPE=SCE /FILE='survey.sav'/ENCODING='UTF8' /DELCASE=LINE /DOT=10 /DBMS=SPSS/REPLACE /MAP.3. 如果你想了解学生的平均成绩与年龄之间的关系,请写出相应的SPSS语法。
(5分)答案:MEANS TABLES=score BY age.4. 如果你想在数据文件中新建一个变量,用于表示学生的性别是否为女性,该如何操作?(5分)答案:首先,打开"变量视图",然后在新增的一列中输入变量名,例如"female",选择"数字"作为变量类型。
接下来,在"值"一栏中填入0和1,分别代表性别为男和女。
最后点击"确定"保存变量设置。
试题二:描述性统计(共20分)1. 如果你想查看某一变量的频数分布情况,请写出相应的SPSS语法。
(5分)答案:FREQUENCIES VARIABLES=variable_name.2. 如果你想计算某一变量的均值、标准差、最小值、最大值等描述性统计量,请写出相应的SPSS语法。
(5分)答案:DESCRIPTIVES VARIABLES=variable_name/STATISTICS=MEAN STDDEV MINIMUM MAXIMUM.3. 如果你想查看两个变量之间的相关性,请写出相应的SPSS语法。
SPSS期末考试题型总结一、单样本t检验(单个正态总体的均值检验与置信区间)(P48)1、题目类型:某糖厂打包机打包的糖果标准值为,给出一系列抽取值。
问:(1)这天打包机的工作是否正常?(2)这天打包机平均装糖量的置信区间是多少?2、操作:(1)Analyze Compare mean One—Sample T Test(2)将左边源变量X送入Test Variable(s)中,在Test Value中输入3、结果分析:若Sig。
>0.05,接受假设,即没有显著性差异若Sig。
<0。
05,拒绝假设,即有显著性差异置信区间(100+Lower,100+uppper)二、两个样本t检验(两个正态总体的均值检验与置信区间)(P50)1、题目类型:从A批导线抽取4根,从B批导线抽取5根。
问:这两批导线的平均电阻是否有显著差异?并求的置信区间。
2、操作:(1)Analyze Compare mean Indepvendent Sample T Test(2)将检验变量x送入Test Variable(s),将分组变量group送入Grouping Variable(3)选按钮define Groups Use specified values,分别输入1和2。
3、结果分析:(1)若F显著性概率Sig.>0.05,接受假设,两组方差没有显著性差异,即可认为两组方差是相等的(2)若t显著性概率Sig。
2—tailed>0。
05,可以得出A、B两批电线的电阻值没有显著差异.三、单因素方差分析(P54)1、题目类型:6种不同农药在相同条件下的杀虫率。
问:杀虫率是否因农药的不同而有显著性差异?2、操作:(1)Analyze Compare mean One-Way ANOV(2)将源变量x送入Dependent List(因变量),将类型变量kind送入Factor.3、结果分析:(1)若Sig.>0。
【1】11瓶罐头的净重(g)分别为450,450,500,500,500,550,550,550,600,600,650,计算平均数,方差,标准差。
【2】例4-5 海关抽检出口罐头质量,发现有胀听现象,随机抽取了6个样品,同时随机抽取6个正常罐头样品测定其SO2含量,测定结果见表4-3。
试分析两种罐头的SO2含量有无差异。
表4-3 正常罐头及异常罐头SO2含量测定结果Excel:SPSS:【例4-6】现有两种茶多糖提取工艺,分别从两种工艺中各取1个随机样本来测定其粗提物中的茶多糖含量,结果见表4-4。
问两种工艺的粗提物中茶多糖含量有无差异?表4-4 两种工艺粗提物中茶多糖含量测定结果【例4-8】为研究电渗处理对草莓果实中的钙离子含量的影响,选用10个草莓品种进行电渗处理及对照处理对比试验,结果见表4-5。
问电渗处理对草莓钙离子含量是否有影响?本例因每个品种实施了一对处理,试验资料为成对资料。
表4-5 电渗处理对草莓钙离子含量的影响SPSS:【例5-1】以淀粉为原料生产葡萄糖过程中,残留的许多糖蜜可用于酱色生产。
生产酱色之前应尽可能彻底除杂,以保证酱色质量。
今选用5中除杂方法,每种方法做4次试验,试验结果见表5-2,试分析不同除杂方法的除杂效果有无差异?选择两两比较,后按确定。
0.00代表极显著。
除杂量处理水平Nalpha = 0.05 的子集1234Tukey HSD a5421.25001425.22503427.02502427.45004428.4250显著1.000 1.000.153性Duncan a5421.25001425.22503427.02502427.450027.45004428.4250显著1.000 1.000.467.107性将显示同类子集中的组均值。
a. 将使用调和均值样本大小 = 4.000。
同列表示互相不显著区别,不同列表示互相显著区别,1-a,2-b。
【例5-3】在食品质量检查中,对4种不同品牌腊肉的酸价进行了随机抽样检测,结果见表5-16,试分析4种不同品牌腊肉的酸价指标有无差异。
Spss期中考试
•考试的数据文件为:aasc
•题目1:检查数据文件中变量e1—e12是否有异常数据。
(15分)
Analyze----Descriptive statistic---Frequencies
•题目2:分组描述不同性别、年级的被试在A型性格量表上的得分(15分)Analyze----Compare Means---Means PS;结合其他变量。
分组描述要分层,其他不分
•题目3:计算,在控制个我取向之后,自信与A型行为的相关。
(20分)
Analyze----Correlate---Partial
•题目4:多因素方差分析,自变量为性别与年级,因变量为总体自信。
(25分)Analyze----General Lineal Model---Univariate pspost和option选两个
Ps单因素方差分析
•Analyze----Compare Means---One-way ANOV A(>=3时,选事后检验)
很轻中等偏重很重
自愿77.50±18.55 67.57±11.51 69.59±9.17 57.56±15.76
非自愿65.38±12.14 66.89±13.68 63.95±9.49 58.29±10.11
F
自愿与否 4.19*
生产任务 4.10**
自愿*生产任务 1.84
(单因素的f值在右侧即可,多因素的要另起行)
事后检验没受过教育的在
•题目5:分析A型性格量表的内部一致性信度(分类表与总量表)、结构效度。
(25分)信度看Crronbach Alpha 效度看KMO
信度:Analyze----Scale---Reliability analysis---Statistics--- Descriptive for ---scale if item deleted 效度:Analyze----Date Reduction ---Factor Analysis---Rotation:Method---Varimax Option---coefficient display format :suppress absolute less than 0.5
6、重编码:将平均气温在28℃以上的月份视为高温月。
统计90年代(90~94年)武汉、北京、昆明三地每年高温月的个数。
做三线表。
(15分)
(1)Transform---recode different---莫忘label
(2) Analyze----Compare Means---Means 注:independent里用year即可
7、分组描述。
将1~6月重编码为上半年,7~12月重编码为下半年。
描述80年代(85~89年)上海市上半年与下半年的温度。
做三线表。
(20分)
(1)Transform---recode different---莫忘label
(2)Analyze---General Lineal Model---Univariate莫忘因变量还有年
8、t检验。
检验成都、昆明、武汉上半年与下半年的温度是否有差别。
做三线表。
(20分)(1)Transform---recode different---莫忘label
(2)Analyze----Compare Means---Independent-Sample T Test (只考)ps:方差齐星与否看levens
留守非留守T
婚姻质量98.87±21.14 102.89±19.83 -2.29*
社会支持42.69±6.46 42.81±6.81 -0.20
(文字描述)留守与非留守妇女在主观支持上没有显著差异。
自愿留守妇女在ab上显著高于非自愿留守妇女
9、用重复测量方差分析比较北京、上海、成都、昆明四地平均温度的差异。
做三线表(20)Analyze ----General Lineal Model ---Repeated Measures : factors 4 注contrast : difference 10、灵活运用统计手段:找出所有城市中哪些城市四季如春。
并写出你的分析思路(25分)Analyze ----Descriptive statistics---- Descriptive。