统计学常用分布及其分位数
- 格式:doc
- 大小:295.50 KB
- 文档页数:8


分位数的计算分位数是统计学中常用的一种描述数据分布形态的方法。
它将数据按大小的顺序排列,然后将数据分为四等份,分别是四分之一位数、四分之二位数(即中位数)、四分之三位数。
四分之一位数也称为下四分位数,四分之三位数也称为上四分位数。
在统计学中,分位数的计算方法有多种,下面将介绍一种常用的计算方法。
计算分位数的方法是将数据按从小到大的顺序排列,然后找出对应位置的数值。
以求下四分位数为例,首先将数据从小到大排序。
如果数据个数为奇数,下四分位数的位置就是(n+1)/4,其中n是数据个数。
如果数据个数为偶数,下四分位数的位置就是n/4与(n/4+1)两个位置的数值的平均值。
通过这种方法,可以计算出下四分位数的值。
同样的方法可以用来计算中位数和上四分位数。
中位数的位置是(n+1)/2,上四分位数的位置是(3n+1)/4(奇数个数据)或3n/4与(3n/4+1)两个位置的数值的平均值(偶数个数据)。
通过这种方法,可以计算出中位数和上四分位数的值。
使用分位数可以更好地描述数据的分布形态。
例如,假设有一组数据表示一群学生的成绩,通过计算下四分位数、中位数和上四分位数,可以得到这些学生的成绩分布情况。
如果下四分位数和中位数接近,说明大部分学生的成绩较低;如果中位数和上四分位数接近,说明大部分学生的成绩较高。
通过分位数的计算,可以更直观地了解数据的分布情况,从而更好地进行数据分析和决策。
分位数的应用不仅局限于统计学领域,还可以应用于其他领域。
例如,在金融领域中,分位数可以用来描述股票的收益分布情况;在经济学中,分位数可以用来描述不同收入群体的分布情况。
分位数的计算方法简单明了,可以方便地应用于各种数据分析场景。
在实际应用中,除了计算单一的分位数,还可以计算多个分位数来更全面地描述数据的分布情况。
例如,常用的是五数概括法,即计算最小值、下四分位数、中位数、上四分位数和最大值。
通过这五个分位数,可以得到数据的最小值和最大值,以及数据的集中趋势和离散程度。


统计学中的随机变量的分布与分位数概念在质量工程师的培训中,我们经常询问学员以下图形是什么曲线,学员普遍能够回答是正态分布曲线,但进一步询问学员该曲线的纵轴f(x)表示什么,许多同学以为是概率值。
其实这个曲线是正态分布概率密度曲线,f(x)是指随机变量X在观察值为x时的概率密度,如果随机变量X的单位为mm,则f(x)的单位为%/mm。
曲线与X轴所围成的面积表示概率,该面积等于1,因为随机变量的所有可能取值(即:100%)都在X轴上。
随机变量的分布与分位数概念以下是一个均值=10,标准差=0.5的正态分布概率密度曲线的例子,x=9.020的垂线与该分布的概率密度曲线和X轴所围成的左侧区域面积=0.025,该面积表示在随机变量X的总体分布中,有2.5%的值小于9.020,也就是说在总体分布中,随机变量X的取值小于9.020的概率为2.5%。
同样,x=10.98的垂线与该分布的概率密度曲线和X 轴所围成的右侧区域面积=0.025,该面积表示在随机变量X的总体分布中,有2.5%的值大于10.98,也就是说在总体分布中,随机变量X 的取值大于10.98的概率为2.5%(也即是随机变量X的取值小于10.98的概率为97.5%)。
在这个分布中,x=9.020的值被称为X的2.5%分位数(即:X2.5%=9.020),x=10.98的值被称为X的97.5%分位数(X97.5%=10.98)。
随机变量X有95%(即:97.5% -2.5%=95%)的取值落在9.020至10.98之间。
每个分位数都是随机变量所有可能取值中的某个值。
按照定义,若某个值Xp被称为随机变量X的p分位数,则随机变量X的取值小于Xp的概率为p。
随机变量的分布与分位数概念以下是该正态分布对应的累积概率分布曲线,该曲线的纵轴表示的是累积概率,比如:x=9.020对应的累积概率为2.5%(即:随机变量X的取值小于x=9.020的概率为2.5%), x=10对应的累积概率为50%(即:随机变量X的取值小于x=10的概率为50%), x=10.98对应的累积概率为97.5%(即:随机变量X的取值小于x=10.98的概率为97.5%)。

分位数的概念分位数是指统计学中常用的一个概念,用来描述数据的分布情况。
它把一组数据分成几部分,每部分包含相同比例的数据。
分位数通常用来衡量数据的集中趋势和离散程度,是统计学和数据分析中非常重要的一个概念。
在统计学中,常用的分位数有四分位数、中位数和百分位数。
其中,四分位数又分为下四分位数(Q1)、中位数(Q2)和上四分位数(Q3)。
下四分位数是数据中25%的位置的值,中位数是数据中50%的位置的值,上四分位数是数据中75%的位置的值。
除了四分位数之外,还有百分位数,百分位数是指数据中有百分之几的观察值小于或等于它。
分位数的概念可以通过举例来更好地理解。
假设有一个班级的学生成绩数据,我们想要了解学生成绩的分布情况。
我们可以计算这组成绩的四分位数,从而找到25%、50%和75%位置的分数。
这样我们就可以得出学生成绩的集中趋势和离散程度。
比如,中位数可以帮助我们确定学生成绩的中间位置,四分位数可以帮助我们了解学生成绩中较低、中等和较高的位置,进而得出整体上学生成绩的分布情况。
分位数的计算方法有很多,最常用的是通过对数据进行排序,然后找到对应位置的数据点。
比如,要计算下四分位数,首先对数据进行排序,然后找到数据的25%位置的值即为下四分位数。
类似地,中位数和上四分位数也可以通过这种方法来计算。
分位数的应用非常广泛,它在数据分析、统计推断、风险管理等领域都有着重要的作用。
在数据分析中,分位数可以帮助我们了解数据的分布情况,发现异常值和离群点,寻找数据的集中趋势等。
在统计推断中,分位数可以用来构建置信区间、进行假设检验等。
在风险管理中,分位数可以用来衡量风险的不确定性和波动性,帮助决策者做出合理的决策。
此外,在金融领域中,分位数也有着重要的应用。
比如,价值-at-风险(Value-at-Risk,VaR)是衡量金融风险的一种常用方法,它主要通过计算分位数来对金融资产的风险进行评估。
总之,分位数是统计学中非常重要的一个概念,它可以帮助我们了解数据的分布情况,衡量数据的集中趋势和离散程度,对数据进行分析和推断,并在风险管理和决策中发挥重要作用。

分位数教学目标:1.理解分位数的概念2.会查表求常用统计分布的分位数教学内容:一、分位数的概念分位数或临界值与随机变量的分布函数有关,根据应用的需要,有三种不同的称呼,即α分位数、上侧α分位数与双侧α分位数,它们的定义如下:定义1:设随机变量X 的分布函数为()x F ,对于给定的实数α满足10<<α时,若有αx 满足(){}ααα=≤=x X P x F ,则称αx 为X 的α分位数;上侧α分位数是使{}()αλλ=-=>F X P 1的数λ,双侧α分位数是使{}()αλλ5011.F X P ==<的数1λ,使{}()αλλ50122.F X P =-=>的数2λ。
因为()()αλαλ-==-11F ,F ,所以上侧α分位数λ就是α-1分位数α-1x ;因为()()αλαλ5015021.F ,.F =-=,所以双侧α分位数1λ就是α50.的分位数α50.x ,双侧α分位数2λ就是α501.-分位数α501.x -。
二、几种常用统计分布的分位数1.标准正态分布的α分位数记作αu ,α50.分位数记作α50.u ,α501.-分位数记作α501.u -。
当X ~N(0,1)时,{}()ααα==<u F u X P 1,0,{}()ααα50501050.u F u X P .,.==<,{}()ααα50150110501.u F u X P .,.-==<--。
根据标准正态分布密度曲线的对称性,可知αα--=1u u 论述如下:当X ~N(0,1)时,{}()ααα==<u F u X P ,10, {}()ααα-==<--11101u F u X P ,,{}()ααα=-=>--11011u F u X P ,,故根据标准正态分布密度曲线的对称性,可知αα--=1u u 。
例如,u 0.10=-u 0.90=-1.282,u 0.05=-u 0.95=-1.645,u 0.01=-u 0.99=-2.326,u 0.025=-u 0.975=-1.960,u 0.005=-u 0.995=-2.576。
分位数教学目标:1.理解分位数的概念2.会查表求常用统计分布的分位数教学内容:一、分位数的概念分位数或临界值与随机变量的分布函数有关,根据应用的需要,有三种不同的称呼,即α分位数、上侧α分位数与双侧α分位数,它们的定义如下:定义1:设随机变量X 的分布函数为()x F ,对于给定的实数α满足10<<α时,若有αx 满足(){}ααα=≤=x X P x F ,则称αx 为X 的α分位数;上侧α分位数是使{}()αλλ=-=>F X P 1的数λ,双侧α分位数是使{}()αλλ5011.F X P ==<的数1λ,使{}()αλλ50122.F X P =-=>的数2λ。
因为()()αλαλ-==-11F ,F ,所以上侧α分位数λ就是α-1分位数α-1x ;因为()()αλαλ5015021.F ,.F =-=,所以双侧α分位数1λ就是α50.的分位数α50.x ,双侧α分位数2λ就是α501.-分位数α501.x -。
二、几种常用统计分布的分位数1.标准正态分布的α分位数记作αu ,α50.分位数记作α50.u ,α501.-分位数记作α501.u -。
当X ~N(0,1)时,{}()ααα==<u F u X P 1,0,{}()ααα50501050.u F u X P .,.==<,{}()ααα50150110501.u F u X P .,.-==<--。
根据标准正态分布密度曲线的对称性,可知αα--=1u u 论述如下:当X ~N(0,1)时,{}()ααα==<u F u X P ,10, {}()ααα-==<--11101u F u X P ,,{}()ααα=-=>--11011u F u X P ,,故根据标准正态分布密度曲线的对称性,可知αα--=1u u 。
例如,u 0.10=-u 0.90=-1.282,u 0.05=-u 0.95=-1.645,u 0.01=-u 0.99=-2.326,u 0.025=-u 0.975=-1.960,u 0.005=-u 0.995=-2.576。


分位数的计算方法1. 分位数是统计学中常用的一种描述数据分布的方法。
它可以帮助我们了解数据集中各个部分的特点和位置,以及数据的相对大小。
2. 首先,我们需要知道分位数的定义。
分位数是指将一个数据集按照大小进行排序后,将其分为若干等份,每一等份包含相等数量的数据。
这样,我们就可以得到一系列的分位数,比如四分位数、中位数等。
3. 其中,最常用的是四分位数,它将数据集分为四等份。
第一个四分位数(Q1)是将数据按照从小到大的顺序排列后,处于25%位置上的数值;中位数(Q2)是处于50%位置上的数值;第三个四分位数(Q3)是处于75%位置上的数值。
4. 计算分位数的方法有多种,下面介绍最常用的一种方法——线性插值法。
首先,我们将数据集按照大小进行排序。
然后,通过以下公式计算分位数的位置:- 位置= (n+1) * p其中,n是数据集中的观测值数量,p是所求分位数的百分位数,通常用小数表示。
5. 如果位置是整数,那么该位置上的观测值就是所求分位数。
如果位置是小数,我们需要进行线性插值。
线性插值是通过找到该位置下方和上方两个整数位置的观测值,然后根据位置的小数部分进行插值计算。
6. 假设位置为k,下方整数位置的观测值为x1,上方整数位置的观测值为x2,那么可以通过以下公式计算分位数:- 分位数= x1 + (x2 - x1) * 小数部分其中,小数部分是位置的小数部分。
7. 举个例子来说明线性插值法的计算过程。
假设我们有一个包含10个观测值的数据集,按照大小排列后如下:1, 2, 3, 4, 5, 6, 7, 8, 9, 10如果我们要计算第三个四分位数(Q3),位置为(10+1) * 0.75 = 7.75。
那么下方整数位置为7,上方整数位置为8。
根据公式,可以计算得到:Q3 = 7 + (8 - 7) * 0.75 = 7.758. 最后,需要注意的是,对于有序数据集中的极端值(比如异常值),在计算分位数时需要进行适当的处理。

标准正态分布分位数表标准正态分布是统计学中非常重要的一个概念,它是指均值为0,标准差为1的正态分布。
在实际应用中,我们经常需要计算标准正态分布的分位数,以便进行概率统计和推断。
本文将介绍标准正态分布分位数表的相关知识,并提供一份标准正态分布分位数表,以供大家参考使用。
首先,我们来了解一下标准正态分布的概念。
标准正态分布的概率密度函数为:\[f(x) = \frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\]其中,x为随机变量,e为自然对数的底。
标准正态分布的分布函数可以用积分形式表示:\[F(x) = \int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}}dt\]标准正态分布的分位数即为给定概率下的随机变量取值。
以α表示给定的概率,标准正态分布的上侧概率为1-α,即P(X > x) = 1-α。
而标准正态分布分位数表则是给定概率α下,对应的随机变量取值x。
接下来,我们给出一份标准正态分布分位数表的部分内容,以便大家在实际应用中参考使用:```。
α Zα。
0.90 1.28。
0.95 1.64。
0.975 1.96。
0.99 2.33。
```。
在上表中,α表示给定的概率,Zα表示对应的标准正态分布分位数。
以α=0.95为例,对应的Zα=1.64,即在标准正态分布下,随机变量取值小于1.64的概率为0.95。
标准正态分布分位数表的使用可以帮助我们进行概率统计和推断。
例如,在假设检验中,我们可以根据标准正态分布分位数表来确定临界值,从而进行假设检验。
在置信区间估计中,我们也可以利用标准正态分布分位数表来确定置信水平对应的临界值。
总之,标准正态分布分位数表是统计学中非常重要的工具,它可以帮助我们进行概率统计和推断,为科学研究和实际应用提供了重要的支持。
希望大家在使用标准正态分布分位数表时,能够结合具体问题加以灵活运用,更好地发挥其作用。
统计学常用分布及其分位数1. 引言在统计学中,分布是指一组数据在各个取值上的分布情况。
统计学常用的分布包括正态分布、均匀分布、二项分布等。
而分位数是衡量分布上部分数据所占比例的一个指标,常用于描述数据的分布形状和集中程度。
本文将介绍统计学常用分布以及它们的分位数。
2. 正态分布及其分位数正态分布是统计学中最重要的分布之一,其分布曲线呈钟形。
它的分布的均值为μ,方差为σ^2。
正态分布的分位数可以通过查找标准正态分布表来获得。
常用的分位数包括:•第一四分位数(Q1):将数据集分为四个部分,该分位数将数据集的前25%数据与后75%数据分开。
•第二四分位数(Q2):也就是中位数,将数据集分为两个相等的部分。
•第三四分位数(Q3):将数据集分为四个部分,该分位数将数据集的前75%数据与后25%数据分开。
3. 均匀分布及其分位数均匀分布是指在一段连续的数据区间内,各个数据点出现的概率是相等的。
均匀分布的分位数可以通过计算来获得。
常用的分位数包括:•下四分位数(Q1):将数据集分为四个部分,该分位数将数据集的前25%数据与后75%数据分开。
•上四分位数(Q3):将数据集分为四个部分,该分位数将数据集的前75%数据与后25%数据分开。
4. 二项分布及其分位数二项分布是常用的离散型分布,用于描述二分法试验在n次独立试验中成功的次数。
二项分布的分位数可以通过计算来获得。
常用的分位数包括:•下百分之P分位数:将数据集分为P%和(100-P)%两部分,下百分之P分位数将数据集的前P%数据与后(100-P)%数据分开。
5.本文介绍了统计学常用的分布及其分位数,分布的选取需要根据具体问题的特点来决定。
在实际应用中,通过计算或查表可以获得分布的分位数,从而对数据集的分布形状和集中程度有更深入的了解。
对于需要进行数据分析和统计推断的问题,了解常用分布及其分位数的特点和应用是非常重要的。
注意:本文只是对统计学常用分布及其分位数进行简要介绍,如需深入学习和应用,请参考相关的统计学教材和资料。
内容和要求•分布函数、分位数的一般算法;正态分布、χ2分布、t分布、F分布、二项分布、泊松分布等常用分布的分布函数以及分位数的计算。
•1.熟悉常用分布的分布函数及其关系;•2.熟练掌握分布函数和分位数的一般算法;•3.熟练掌握常用分布之分布函数和分位数的计算。
(2). 指数分布如果随机变量在[0,)¥上取值,具有概率密度函数, 0()0, xe x p x 其它λλ−⎧≤<∞=⎨⎩其中0l >, 那么称X 服从参数为l 的指数分布分布,记作exp()X l :。
相应的分布函数为:0,0 ()1, 0x x F x e x λ−<⎧=⎨−≤<∞⎩正如前面学过的几何分布一样,指数分布也具有无记忆性,即(|)()yP X x y X x e P X y l ->+>==> 我们今后还会看到:指数分布和Poisson 分布有着密切的联系。
当20,1m s ==时,我们称为标准正态分布。
正态分布这个名称也许首先 F.Galton 在1885年之前给出,它被认为是最重要的一种概率分布。
根据著名的中心极限定理(以后将介绍),在自然界和人类社会中许多现象都可由正态分布加以描述。
例. 设(2,9)X N :, 求(520)P X <<.例. 设2(,)X N m s :, 求(||)P X m s -, (||2)P X m s -, 以及(||3)P X m s -. 解解正态随机变量的99.73 %的值落在 (3,3)m s m s -+之中, 落在该区间之外的概率几乎为零. 这情况被实际工作者称为“3σ原则”例.从南郊某地乘车到北区火车站有两条路可走,第一条路较短,但交通拥挤,所需时间X服从N分布;第二条路线略长,但意外阻塞较(50,100)N.少,所需时间Y服从(60,16)(1) 若有70分钟可用,问应走哪一条路?(2) 若只有65分钟可用,又应走哪一条路?解(7). Weibull 分布其中,0a b >, 那么称X 服从参数为,a b 的Weibull 分布。
标准正态分布分位数标准正态分布是统计学中非常重要的一种分布,它具有许多重要的性质和应用。
在实际应用中,我们经常需要计算标准正态分布的分位数,以便进行统计推断和假设检验。
本文将介绍标准正态分布分位数的计算方法和应用。
首先,我们来了解一下标准正态分布。
标准正态分布是均值为0,标准差为1的正态分布。
其概率密度函数为:\[ f(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \]其中,\( \pi \) 是圆周率,\( e \) 是自然对数的底数。
标准正态分布的分布函数是一个没有解析表达式的积分,因此我们通常使用统计软件或查表的方式来计算分位数。
标准正态分布的分位数通常用符号 \( z \) 来表示。
对于给定的概率 \( p \),标准正态分布的 \( p \) 分位数是一个数值,记作 \( z_p \),满足以下等式:\[ P(Z \leq z_p) = p \]其中,\( Z \) 代表标准正态随机变量。
换句话说,\( z_p \) 是使得标准正态分布随机变量落在 \( z_p \) 以下的概率为 \( p \) 的点。
计算标准正态分布的分位数是统计学中的常见问题。
在实际应用中,我们通常使用统计软件或查表的方式来获取分位数。
在统计软件中,可以直接使用相应的函数来计算分位数,而在查表的方式中,我们需要查阅标准正态分布的分位数表来获取相应的数值。
除了计算分位数,标准正态分布的分位数还有许多重要的应用。
例如,在假设检验中,我们常常需要计算临界值来进行判断;在置信区间估计中,我们也需要使用分位数来确定置信水平。
因此,掌握标准正态分布分位数的计算方法和应用是统计学习者必备的基本技能。
总之,标准正态分布分位数是统计学中非常重要的概念,它具有广泛的应用。
在实际应用中,我们通常使用统计软件或查表的方式来获取分位数。
掌握标准正态分布分位数的计算方法和应用,对于进行统计推断和假设检验具有重要的意义。
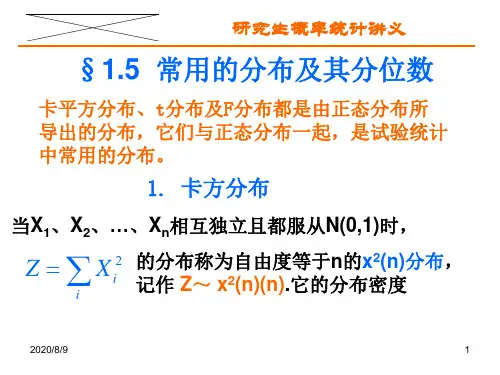
§1、4 常用得分布及其分位数1、 卡平方分布卡平方分布、t 分布及F 分布都就是由正态分布所导出得分布,它们与正态分布一起,就是试验统计中常用得分布。
当X 1、X 2、…、Xn 相互独立且都服从N(0,1)时,Z=∑ii X 2 得分布称为自由度等于n 得2χ分布,记作Z ~2χ(n),它得分布密度 p(z )=⎪⎪⎩⎪⎪⎨⎧>⎪⎭⎫ ⎝⎛Γ--,,00,2212122其他z e x n z n n 式中得⎪⎭⎫ ⎝⎛Γ2n =u d e u u n ⎰∞+--012,称为Gamma 函数,且()1Γ=1,⎪⎭⎫ ⎝⎛Γ21=π。
2χ分布就是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。
证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、X n+m 相互独立且都服从N(0,1),再根据2χ分布得定义以及上述随机变量得相互独立性,令Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +,Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +,即可得到Y+Z ~2χ(n +m )。
2、 t 分布 若X 与Y 相互独立,且X ~N(0,1),Y ~2χ(n ),则Z =nY X 得分布称为自由度等于n 得t 分布,记作Z ~ t (n ),它得分布密度P(z)=)()(221n nn ΓΓ+2121+-⎪⎪⎭⎫ ⎝⎛+n n z 。
请注意:t 分布得分布密度也就是偶函数,且当n>30时,t分布与标准正态分布N(0,1)得密度曲线几乎重叠为一。
这时, t 分布得分布函数值查N(0,1)得分布函数值表便可以得到。
3、 F 分布 若X 与Y 相互独立,且X ~2χ(n ),Y ~2χ(m ),则Z=mY n X 得分布称为第一自由度等于n 、第二自由度等于m 得F 分布,记作Z ~F (n , m ),它得分布密度 p(z)=⎪⎪⎪⎩⎪⎪⎪⎨⎧>++-⎪⎭⎫ ⎝⎛Γ⎪⎭⎫ ⎝⎛Γ⎪⎭⎫ ⎝⎛+Γ•。
其他,00,2)(1222222z m n z n m n z m n m n m m n n 请注意:F 分布也就是非对称分布,它得分布密度与自由度得次序有关,当Z ~F (n , m )时,Z1~F (m ,n )。
4、 t 分布与F 分布得关系若X ~t(n ),则Y=X 2~F(1,n )。
证:X ~t(n ),X 得分布密度p(x )=⎪⎭⎫ ⎝⎛Γ⎪⎭⎫ ⎝⎛+Γ221n n n π2121+-⎪⎪⎭⎫ ⎝⎛+n n x 。
Y=X 2得分布函数F Y (y ) =P{Y<y }=P{X 2<y }。
当y ≤0时,F Y (y)=0,p Y (y )=0;当y >0时,F Y (y ) =P{-y <X<y } =x d x p y y )(⎰-=2x d x p y )(0⎰, Y=X 2得分布密度p Y (y )=21)(121221212n y n y n n n n ++-⎪⎭⎫ ⎝⎛Γ⎪⎭⎫ ⎝⎛Γ⎪⎭⎫ ⎝⎛+Γ•,与第一自由度等于1、第二自由度等于n 得F 分布得分布密度相同,因此Y=X 2~F(1,n )。
为应用方便起见,以上三个分布得分布函数值都可以从各自得函数值表中查出。
但就是,解应用问题时,通常就是查分位数表。
有关分位数得概念如下:4、常用分布得分位数1)分位数得定义分位数或临界值与随机变量得分布函数有关,根据应用得需要,有三种不同得称呼,即α分位数、上侧α分位数与双侧α分位数,它们得定义如下:当随机变量X得分布函数为F(x),实数α满足0 <α<1 时,α分位数就是使P{X< xα}=F(xα)=α得数xα,上侧α分位数就是使P{X >λ}=1-F(λ)=α得数λ,双侧α分位数就是使P{X<λ1}=F(λ1)=0、5α得数λ1、使P{X>λ2}=1-F(λ2)=0、5α得数λ2。
因为1-F(λ)=α,F(λ)=1-α,所以上侧α分位数λ就就是1-α分位数x1-α;F(λ1)=0、5α,1-F(λ2)=0、5α,所以双侧α分位数λ1就就是0、5α分位数x0、5α,双侧α分位数λ2就就是1-0、5α分位数x1-0、5α。
2)标准正态分布得α分位数记作uα,0、5α分位数记作u0、5α,1-0、5α分位数记作u1-0、5α。
当X~N(0,1)时,P{X< uα}=F 0,1(uα)=α,P{X<u0、5α}= F 0,1 (u0、5α)=0、5α,P{X<u1-0、5α}= F 0,1 (u1-0、5α)=1-0、5α。
根据标准正态分布密度曲线得对称性,当α=0、5时,uα=0;当α<0、5时,uα<0。
uα=-u1-α。
如果在标准正态分布得分布函数值表中没有负得分位数,则先查出 u1-α,然后得到uα=-u1-α。
论述如下:当X~N(0,1)时,P{X< uα}= F 0,1 (uα)=α,P{X< u1-α}= F 0,1 (u1-α)=1-α,P{X> u1-α}=1- F 0,1 (u1-α)=α,故根据标准正态分布密度曲线得对称性,uα=-u1-α。
例如,u 0、10=-u 0、90=-1、282,u 0、05=-u 0、95=-1、645,u 0、01=-u 0、99=-2、326,u 0、025=-u 0、975=-1、960,u 0、005=-u 0、995=-2、576。
又因为P{|X|< u1-0、5α}=1-α,所以标准正态分布得双侧α分位数分别就是u1-0、5α与-u1-0、5α。
标准正态分布常用得上侧α分位数有:=1、282;α=0、10,u 0、90=1、645;α=0、05,u 0、95α=0、01,u 0=2、326;、99=1、960;α=0、025,u 0、975=2、576。
α=0、005,u 0、995χα(n)。
3)卡平方分布得α分位数记作2χα(n)>0,当X~2χ(n)时,P{X<2χα(n)}=α。
2χ0、005(4)=0、21,2χ0、025(4)=0、48,例如,2χ0、05 (4)=0、71,2χ0、95(4)=9、49,2χ0、975(4)=11、1,2χ0、995(4)=14、9。
24)t分布得α分位数记作tα(n)。
当X~t (n)时,P{X<tα(n)}=α,且与标准正态分布相类似,根据t分布密度曲线得对称性,也有tα(n)=-t1-α(n),论述同uα=-u1-α。
例如,t0、95(4)=2、132,t 0、975(4)=2、776,t 0、995(4)=4、604,t 0、005(4)=-4、604,t 0、025(4)=-2、776,t 0、05(4)=-2、132。
另外,当n>30时,在比较简略得表中查不到tα(n),可用uα作为tα(n)得近似值。
5)F分布得α分位数记作Fα(n , m)。
Fα(n , m)>0,当X~F (n , m)时,P{X<Fα(n , m)}=α。
另外,当α较小时,在表中查不出F α(n , m ),须先查F 1-α(m , n ),再求F α(n , m )=),(11n m F α-。
论述如下: 当X ~F(m , n )时,P{X< F 1-α(m , n )}=1-α, P{X 1>),(11n m F α-}=1-α,P{X 1<),(11n m F α-}=α, 又根据F 分布得定义,X 1~F(n , m ),P{X 1<F α(n , m ) }=α, 因此 F α(n , m )= ),(11n m F α-。
例如,F 0、95 (3,4)=6、59,F 0、975 (3,4)=9、98,F 0、99 (3,4)=16、7,F 0、95 (4,3)=9、12,F 0、975 (4,3)=15、1,F 0、99 (4,3)=28、7,F 0、01 (3,4)=7.281,F 0、025 (3,4)=1.151,F 0、05 (3,4)=12.91。
【课内练习】1、 求分位数①χ20、05(8),②χ20、95(12)。
2、 求分位数① t 0、05(8),② t 0、95(12)。
3、 求分位数①F 0、05(7,5),②F 0、95(10,12)。
4、 由u 0、975=1、960写出有关得上侧分位数与双侧分位数。
5、 由t 0、95(4)=2、132写出有关得上侧分位数与双侧分位数。
6、 若X ~χ2(4),P{X<0、711}=0、05,P{X<9、49}=0、95,试写出有关得分位数。
7、 若X ~F(5,3),P{X<9、01}=0、95,Y ~F(3,5),{Y<5、41}= 0、95,试写出有关得分位数。
8、 设X 1、X 2、…、X 10相互独立且都服从N(0,0、09)分布,试求P{X i i2∑>1、44}。
习题答案:1、 ①2、73,②21、0。
2、 ①-1、860,②1、782。
3、 ①1488.,②3、37。
4、 1、960为上侧0、025分位数,-1、960与1、960为双侧0、05分位数。
5、 2、132为上侧0、05分位数,-2、132与2、132为双侧0、1分位数。
6、 0、711为上侧0、95分位数,9、49为上侧0、05分位数,0、711与19、49为双侧0、1分位数。
7. 9.01为上侧0、05分位数,5、41为上侧0、05分位数,1901.与5、41为双侧0、1分位数,1541.与9、01为双侧0、1分位数。
8、 0、1。