数据结构课程设计哈希表
- 格式:doc
- 大小:65.50 KB
- 文档页数:6

哈希表数据结构例题哈希表(HashTables)是一种用于存储数据的结构,它根据键(key)计算出一个值(value),从而将数据存储到对应的位置上。
它是一种用空间换取时间的算法,通过哈希函数将键值转化为整数,并将其映射到一个“桶”中,快速定位查找所需的数据,从而大大减少搜索时间。
哈希表也常用于排序、缓存、验证数据的完整性等方面。
哈希表的原理哈希表的主要原理就是使用一种称为哈希函数(hash function)的算法来将键值转化为整数,然后将其映射到一个“桶”中,也就是一个包含要存储的值的有序数组。
哈希函数是把任意字符串或其他数据类型,转换为一个固定长度的整数,也就是所谓的“哈希值”。
这个哈希值可以根据“哈希函数”的设计,映射到0到桶的大小减一之间的某一个整数。
这样,哈希表就可以把原来的数据,通过哈希值转换为一个范围较小的数,把数据存储到一个有序的桶中,从而大大缩短搜索时间。
哈希表的实现哈希表是使用数组和链表实现的。
数组存放键值对,链表可以解决键值重复的情况,其中每个节点存放着该键值对应的值。
为了更有效的利用存储空间,哈希表有时会采取扩容的方式,即把原来的数组容量翻倍,当存储满的时候就重新分配内存空间,并把原来的数据重新哈希映射到新的桶中。
哈希表的用途哈希表除了作为存储数据的结构,也可以用于排序、缓存、验证数据的完整性等问题。
哈希表常被用来实现快速查找和插入功能,而且它的查找时间复杂度主要取决于所使用的哈希函数,一般在O(1)时间内就可以完成查找。
哈希表也可以快速统计某一个键出现的次数,实现计数排序(Counting Sort)等功能。
哈希表的例题例子1:设计一个哈希表,能够把一个字符串(String)转换为一个哈希值,并且能够用这个哈希值搜索相应的字符串。
解题思路:首先,需要设计一种哈希函数,把一个任意长度的字符串,转换为一个固定长度的哈希值,这里可以采用把字符串中每个字符的ASCII码值相加,再除以字符串长度,取余数的方法。

福建工程学院课程设计课程:算法与数据结构题目:哈希表专业:网络工程班级:xxxxxx班座号:xxxxxxxxxxxx姓名:xxxxxxx2011年12 月31 日实验题目:哈希表一、要解决的问题针对同班同学信息设计一个通讯录,学生信息有姓名,学号,电话号码等。
以学生姓名为关键字设计哈希表,并完成相应的建表和查表程序。
基本要求:姓名以汉语拼音形式,待填入哈希表的人名约30个,自行设计哈希函数,用线性探测再散列法或链地址法处理冲突;在查找的过程中给出比较的次数。
完成按姓名查询的操作。
运行的环境:Microsoft Visual C++ 6.0二、算法基本思想描述设计一个哈希表(哈希表内的元素为自定义的结构体)用来存放待填入的30个人名,人名为中国姓名的汉语拼音形式,用除留余数法构造哈希函数,用线性探查法解决哈希冲突。
建立哈希表并且将其显示出来。
通过要查找的关键字用哈希函数计算出相应的地址来查找人名。
通过循环语句调用数组中保存的数据来显示哈希表。
三、设计1、数据结构的设计和说明(1)结构体的定义typedef struct //记录{NA name;NA xuehao;NA tel;}Record;录入信息结构体的定义,包含姓名,学号,电话号码。
typedef struct //哈希表{Record *elem[HASHSIZE]; //数据元素存储基址int count; //当前数据元素个数int size; //当前容量}HashTable;哈希表元素的定义,包含数据元素存储基址、数据元素个数、当前容量。
2、关键算法的设计(1)姓名的折叠处理long fold(NA s) //人名的折叠处理{char *p;long sum=0;NA ss;strcpy(ss,s); //复制字符串,不改变原字符串的大小写strupr(ss); //将字符串ss转换为大写形式p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}(2)建立哈希表1、用除留余数法构建哈希函数2、用线性探测再散列法处理冲突int Hash1(NA str) //哈希函数{long n;int m;n=fold(str); //先将用户名进行折叠处理m=n%HASHSIZE; //折叠处理后的数,用除留余数法构造哈希函数return m; //并返回模值}Status collision(int p,int c) //冲突处理函数,采用二次探测再散列法解决冲突{int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();}else printf("\n此人不存在,查找不成功!\n");benGetTime();}(4)显示哈希表void ShowInformation(Record* a) //显示输入的用户信息{int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}(5)主函数的设计void main(int argc, char* argv[]){Record a[MAXSIZE];int c,flag=1,i=0;HashTable *H;H=(HashTable*)malloc(LEN);for(i=0;i<HASHSIZE;i++){H->elem[i]=NULL;H->size=HASHSIZE;H->count=0;}while (1){ int num;printf("\n ");printf("\n 欢迎使用同学通讯录录入查找系统");printf("\n 哈希表的设计与实现");printf("\n 【1】. 添加用户信息");printf("\n 【2】. 读取所有用户信息");printf("\n 【3】. 以姓名建立哈希表(再哈希法解决冲突) ");printf("\n 【4】. 以电话号码建立哈希表(再哈希法解决冲突) ");printf("\n 【5】. 查找并显示给定用户名的记录");printf("\n 【6】. 查找并显示给定电话号码的记录");printf("\n 【7】. 清屏");printf("\n 【8】. 保存");printf("\n 【9】. 退出程序");printf("\n 温馨提示:");printf("\n Ⅰ.进行5操作前请先输出3 ");printf("\n Ⅱ.进行6操作前请先输出4 ");printf("\n");printf("请输入一个任务选项>>>");printf("\n");scanf("%d",&num);switch(num){case 1:getin(a);break;case 2:ShowInformation(a);break;case 3:CreateHash1(H,a); /* 以姓名建立哈希表*/break;case 4:CreateHash2(H,a); /* 以电话号码建立哈希表*/break;case 5:c=0;SearchHash1(H,c);break;case 6:c=0;SearchHash2(H,c);break;case 7:Cls(a);break;case 8:Save();break;case 9:return 0;break;default:printf("你输错了,请重新输入!");printf("\n");}}system("pause");return 0;3、模块结构图及各模块的功能:四、源程序清单:#include<stdio.h>#include<stdlib.h>#include<string.h>#include <windows.h>#define MAXSIZE 20 #define MAX_SIZE 20 #define HASHSIZE 53 #define SUCCESS 1#define UNSUCCESS -1#define LEN sizeof(HashTable)typedef int Status;typedef char NA[MAX_SIZE];typedef struct {NA name;NA xuehao;NA tel;}Record;typedef struct {Record *elem[HASHSIZE]; int count; int size; }HashTable;Status eq(NA x,NA y) {if(strcmp(x,y)==0)return SUCCESS;else return UNSUCCESS;}Status NUM_BER;void getin(Record* a) {int i;system("cls");printf("输入要添加的个数:\n");scanf("%d",&NUM_BER);for(i=0;i<NUM_BER;i++){printf("请输入第%d个记录的姓名:\n",i+1);scanf("%s",a[i].name);printf("请输入%d个记录的学号:\n",i+1);scanf("%s",a[i].xuehao);printf("请输入第%d个记录的电话号码:\n",i+1);scanf("%s",a[i].tel);}}void ShowInformation(Record* a){int i;system("cls");for( i=0;i<NUM_BER;i++)printf("\n第%d个用户信息:\n 姓名:%s\n 学号:%s\n 电话号码:%s\n",i+1,a[i].name,a[i].xuehao,a[i].tel);}void Cls(Record* a){printf("*");system("cls");}long fold(NA s){char *p;long sum=0;NA ss;strcpy(ss,s);strupr(ss);p=ss;while(*p!='\0')sum+=*p++;printf("\nsum====================%d",sum);return sum;}int Hash1(NA str){int m;n=fold(str);m=n%HASHSIZE;return m;}int Hash2(NA str){long n;int m;n = atoi(str);m=n%HASHSIZE;return m;}Status collision(int p,int c){int i,q;i=c/2+1;while(i<HASHSIZE){if(c%2==0){c++;q=(p+i*i)%HASHSIZE;if(q>=0) return q;else i=c/2+1;}else{q=(p-i*i)%HASHSIZE;c++;if(q>=0) return q;else i=c/2+1;}}return UNSUCCESS;}void benGetTime();void CreateHash1(HashTable* H,Record* a){ int i,p=-1,c,pp;system("cls"); benGetTime();for(i=0;i<NUM_BER;i++){p=Hash1(a[i].name);pp=p;while(H->elem[pp]!=NULL) {pp=collision(p,c);if(pp<0){printf("第%d记录无法解决冲突",i+1);continue;}}H->elem[pp]=&(a[i]);H->count++;printf("第%d个记录冲突次数为%d。

哈希表又称散列表,实际上就是一个数组。
哈希函数是一个用来求存储在哈希的关键字在哈希表的地址下标的函数.比如一个哈希表int hashtable[5];现在有下面4个数要存入到哈希表中:(3,15,22,24)给定一个哈希函数: H(k)=k % 5最终数据存储如下图:理想情况下,哈希函数在关键字和地址之间建立了一个一一对应关系,从而使得查找只需一次计算即可完成。
由于关键字值的某种随机性,使得这种一一对应关系难以发现或构造。
因而可能会出现不同的关键字对应一个存储地址。
即k1≠k2,但H(k1)=H(k2),这种现象称为冲突。
把这种具有不同关键字值而具有相同哈希地址的对象称“同义词”。
在大多数情况下,冲突是不能完全避免的。
这是因为所有可能的关键字的集合可能比较大,而对应的地址数则可能比较少。
对于哈希技术,主要研究两个问题:(1)如何设计哈希函数以使冲突尽可能少地发生。
(2)发生冲突后如何解决。
哈希函数的构造方法:构造好的哈希函数的方法,应能使冲突尽可能地少,因而应具有较好的随机性。
这样可使一组关键字的散列地址均匀地分布在整个地址空间。
根据关键字的结构和分布的不同,可构造出许多不同的哈希函数。
1.直接定址法直接定址法是以关键字k本身或关键字加上某个数值常量c作为哈希地址的方法。
该哈希函数H(k)为:H(k)=k+c (c≥0)这种哈希函数计算简单,并且不可能有冲突发生。
当关键字的分布基本连续时,可使用直接定址法的哈希函数。
否则,若关键字分布不连续将造成内存单元的大量浪费。
2.除留余数法(注意:这种方法常用)取关键字k除以哈希表长度m所得余数作为哈希函数地址的方法。
即:H(k)=k %m这是一种较简单、也是较常见的构造方法。
这种方法的关键是选择好哈希表的长度m 。
使得数据集合中的每一个关键字通过该函数转化后映射到哈希表的任意地址上的概率相等。
理论研究表明,在m 取值为素数(质数)时,冲突可能性相对较少。

合肥学院计算机科学与技术系课程设计报告2007~2008学年第2学期课程数据结构与算法课程设计名称哈希表的设计与实现学生姓名学号0604011026专业班级06 计科 (1)指导教师2008年9月一、课程设计题目:(哈希表的设计与实现的问题)设计哈希表实现电话号码查询系统。
设计程序完成以下要求:( 1)设每个记录有下列数据项:电话号码、用户名、地址;(2)从键盘输入各记录,分别以电话号码和用户名为关键字建立哈希表;( 3)采用再哈希法解决冲突;(4)查找并显示给定电话号码的记录;(5)查找并显示给定用户的记录。
二、问题分析和任务定义1、问题分析要完成如下要求:设计哈希表实现电话号码查询系统。
实现本程序需要解决以下几个问题:(1)如何设计一个结点使该结点包括电话号码、用户名、地址。
(2)如何分别以电话号码和用户名为关键字建立哈希表。
(3)如何利用再哈希法解决冲突。
(4)如何实现用哈希法查找并显示给定电话号码的记录。
(5)如何查找并显示给定用户的记录。
2、任务定义由问题分析知,本设计主要要求分别以电话号码和用户名为关键字建立哈希表,并实现查找功能。
所以本设计的核心问题是如何解决散列的问题,亦即设计一个良好的哈希表。
由于结点的个数无法确认,并且如果采用线性探测法散列算法,删除结点会引起“信息丢失”的问题。
所以采用链地址法散列算法。
采用链地址法,当出现同义词冲突时,使用链表结构把同义词链接在一起,即同义词的存储地址不是散列表中其他的空地址。
首先,解决的是定义链表结点,在链地址法中,每个结点对应一个链表结点,它由三个域组成,而由于该程序需要分别用电话号码和用户名为关键字建立哈希表,所以该链表结点它是由四个域组成.name[8]、num[11]和address[20]都是char浮点型,输入输出都只能是浮点型的。
采用链地址法,其中的所有同义词构成一个单链表,再由一个表头结点指向这个单链表的第一个结点。
这些表头结点组成一个一维数组,即哈希表。
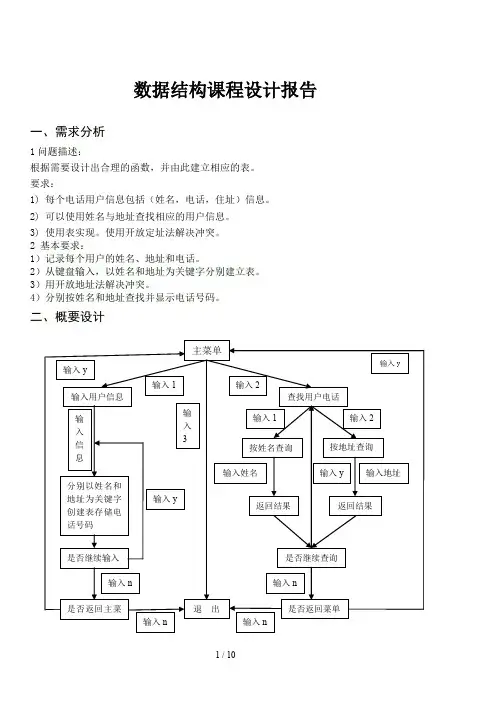
数据结构课程设计报告一、需求分析1问题描述:根据需要设计出合理的函数,并由此建立相应的表。
要求:1)每个电话用户信息包括(姓名,电话,住址)信息。
2)可以使用姓名与地址查找相应的用户信息。
3)使用表实现。
使用开放定址法解决冲突。
2 基本要求:1)记录每个用户的姓名、地址和电话。
2)从键盘输入,以姓名和地址为关键字分别建立表。
3)用开放地址法解决冲突。
4)分别按姓名和地址查找并显示电话号码。
二、概要设计三、详细设计定义结构表{定义表内的所有成员}[];( x[])关键字转换为数值{求字符数组x每个字符对应的值的绝对值之和,并返回最后结果}( )创建表{创建表,并初始化它}( d) 按姓名插入{以姓名为关键字,调用关键字转换函数将对应的电话号码存储到相应的存储空间。
若该位置已经被存储,则向后移一位(当移到最后一位,就移到头部继续)。
若还有冲突重复上一步。
当所有空间都查过一遍,发现没有空位,则输出“没有存储空间”。
}( d)按地址插入{以地址为关键字,调用关键字转换函数将对应的电话号码存储到相应的存储空间。
若该位置已经被存储,则向后移一位(当移到最后一位,就移到头部继续)。
若还有冲突重复上一步。
当所有空间都查过一遍,发现没有空位,则输出“没有存储空间”。
}( )表插入{输入用户姓名、地址和电话,分别调用按姓名插入和按地址插入函数进行插入。
重复上面的步骤,直到你不想继续或空间已满。
}( )按姓名查找{输入你想要查询的姓名,对它进行转换,再查找。
若该位置不空或求得的关键字所对应的数值与该位置的数值不相等,则向后移一位(当移到最后一位,就移到头部继续)。
若还有冲突重复上一步。
当所有空间都查过一遍,发现没有找到,则输出“不存在”。
若该位置空,则输出“不存在”。
若查找到,则输出电话号码。
}( )按地址查找{输入你想要查询的地址,对它进行转换,再查找。
若该位置不空或求得的关键字所对应的数值与该位置的数值不相等,则向后移一位(当移到最后一位,就移到头部继续)。



《数据结构》课程标准课程名称:数据结构课程代码:3250619适用专业:软件技术专业(软件开发方向)课程性质:专业必修课学时:48学时(理论:24 实践: 24)学分:3学分一、课程概述(一)课程的地位和作用《数据结构》是软件技术专业(软件开发方向)的一门专业必修课。
课程的前导课程是《Java面向对象编程》,本课程在后续软件开发类课程中起着非常重要的作用,其知识的应用将贯穿于本专业的所有课程。
在程序设计中,一个好的程序无非是选择一个合适的数据结构和好的算法,而好的算法的选择很大程度上取决于描述实际问题的数据结构的选取。
所以,学好数据结构,将是进一步提高学生程序设计水平的关键之一。
数据结构的应用水平是区分软件开发、设计人员水平高低的重要标志之一,缺乏数据结构和算法的深厚功底,很难设计出高水平的具有专业水准的应用程序。
本课程的改革理念是,坚持工程化、实用化教学,密切适应计算机技术的发展趋势,坚持学以致用;解决抽象理论与实践相脱节现象,让绝大多数学生在有限的时间内迅速掌握课程的基本理论知识,并把理论知识应用到软件开发的实际工作中,开发出高质是的应用软件。
(二)课程设计思路课程资源建设遵循三个原则、一个过程、四个应用层次。
课程内容的选取遵循科学性原则,课程内容的选取依据数据结构课程在学科体系的理论体系,结合其在实际开发中的使用频度及难易程度,选取适合高职学生的学习内容;课程内容的组织遵循情境性原则,所有模块的内容按一个过程进行组织。
课程内容置于由实践情境建构的以软件开发过程主要逻辑为主线的行动体系之中,采用打碎、集成的思想,将学科体系中所涉及的概念、方法、原理打碎,然后按照软件开发过程逻辑重新集成。
课程资源的建设充分体现人本性原则,按人类掌握知识的基本规律“获取—>内化—>实践—>反思—>新的获取”,开发四个实践层次“验证性应用、训练性应用、设计性应用、创造性应用”的训练题库。
二、培养目标(一)总体目标《数据结构》课程以培养学生的数据抽像能力和复杂程序设计的能力为总目标。

【算法与数据结构】哈希表-链地址法哈希表的链地址法来解决冲突问题将所有关键字为同义词的记录存储在同⼀个线性链表中,假设某哈希函数产⽣的哈希地址在区间[0, m - 1]上,则设⽴⼀个⾄振兴向量Chain ChainHash[m];数据结构//链表结点typedef struct _tagNode{int data; //元素值(关键字)struct _tagNode* next; //下⼀个结点}Node, *PNode;//哈希表结点typedef struct _tagHashTable{//这⾥⽤⼀个联合体来解释⼀下,其index也即哈希值union{int index; //哈希表index(这⾥也是哈希值)int nHashValue; //也即哈希值}INDEX;Node* firstChild; //该哈希结点在第⼀个⼦节点,即哈希值为该结点INDEX字段的struct _tagHashTable* next; //指向下⼀个哈希结点}HashTable, *PHashTable;构造哈希表,输⼊为头结点指针的引⽤//pHashTable 哈希表头结点//length 哈希表长度//pArr 关键字元素数组//nums 关键字元素数组长度void CreateHashTable(PHashTable& pHashTable, int length, int* pArr, int nums){pHashTable = new HashTable();if(NULL == pHashTable) { cerr << "Create Hashtable error! \n"; return;}pHashTable->firstChild = NULL;pHashTable->INDEX = 0;pHashTable->next = NULL;PHashTable pTemp = pHashTable;for (int i = 1; i < length; ++ i){PHashTable pt = new HashTable();if(NULL == pt) {cerr << "Create Hahstable error ! \n"; return;}pt->firstChild = NULL;pt->INDEX = i;pt->next = NULL;pTemp->next = pt;pTemp = pt;} //for//Hash(key) = key MOD length;for(int i = 0; i < nums; ++ i){//计算哈希值int nHashValue = pArr[i] % length;PHashTable pTemp2 = NULL;if(NULL != (pTemp2 = LocateHashNode(pHashTable, nHashValue)) ){Insert(pTemp2, pArr[i]);}else{cerr << "元素值为 "<< pArr[i]<< " 的元素,哈希值为 "<< nHashValue<< ", 查找其所在哈希结点失败"<<endl;}}}向某个哈希表结点(不⼀定是头结点)中插⼊元素//将关键字插⼊所在的pHashtable结点的链表//返回其在该链表上的位置(下标从1开始)int Insert(PHashTable& pHashtable, int data){if(NULL == pHashtable){cerr << "当前哈希表结点为空 \r\n"; return -1;}int nIndex = 1;PNode pNewNode = new Node();if(NULL == pNewNode){cerr << "建⽴新链表结点失败"<<endl; return -1;}pNewNode->data = data;pNewNode->next = NULL;PNode pNode = pHashtable->firstChild;if (NULL == pNode){pHashtable->firstChild = pNewNode;}else{while(pNode->next != NULL){++ nIndex;pNode = pNode->next;}++nIndex;pNode->next = pNewNode;}cout << "元素 "<< data << " 插⼊在了哈希表结点 "<< pHashtable->INDEX<< " 的第 "<< nIndex<< " 个位置"<<endl; return nIndex;}根据哈希值,返回其所在结点的指针,输⼊为表⽰该哈希表的头结点指针的引⽤//根据哈希值,返回该值应该所在的哈希表结点指针//pHashtable 哈希表头结点//nHashValue 元素的哈希值PHashTable LocateHashNode(PHashTable& pHashtable, int nHashValue){if(NULL == pHashtable) {cerr << "哈希表头结点为空"<<endl; return NULL;}PHashTable pTemp = pHashtable;do{if (pTemp->INDEX == nHashValue) return pTemp;pTemp = pTemp->next;} while (pTemp != NULL);return NULL;}从头结点为pHashtable的哈希表中,查找关键字为data,哈希值为nHashValue的元素在哈希表中的位置,返回值为在该哈希结点的链表中的位置(下标从1开始)//查找头结点为pHashtable的哈希表//其数据为data,哈希值为nHashValue的元素//在哈希表某个结点的链表中的位置(下标从1开始)int Find(PHashTable& pHashtable, int data, int nHashValue){if(NULL == pHashtable){cerr << "哈希表头结点为空"<<endl; return -1;}PHashTable pHashNode = LocateHashNode(pHashtable, nHashValue);if(NULL == pHashNode) {cerr << "找不到元素 " << data << " ,其哈希值为 "<<nHashValue<< " 在哈希表中的位置"; return -1;} int nINDEX = 1;PNode pNode = pHashNode->firstChild;if (NULL == pNode){{cerr << "找不到元素 " << data << " ,其哈希值为 "<<nHashValue<< " 在哈希表中的位置"; return -1;}}else{bool b = false;while(pNode != NULL){if(pNode->data == data){b = true;break;}++ nINDEX;pNode = pNode->next;}if (false == b){cerr << "找不到元素 " << data << " ,其哈希值为 "<<nHashValue<< " 在哈希表中的位置";return -1;}else{cout << "元素 "<< data << " 插⼊在了哈希表结点 "<< pHashNode->INDEX<< " 的第 "<< nINDEX<< " 个位置"<<endl;}}return nINDEX;}int _tmain(int argc, _TCHAR* argv[]){PHashTable pHashtable = NULL;int length = 0;int nums = 0;cout <<endl<< "请输⼊元素个数:";cin >> nums;int* pArr = new int[nums]();if(NULL == pArr) {cerr<<"申请元素空间错误"; return -1;}ZeroMemory(pArr, sizeof(int) * nums);for (int i = 0; i < nums; ++ i){int data = 0;cout << "请输⼊第 "<< i << " 个元素的值:";cin >> data;pArr[i] = data;}cout << endl<<"输⼊完毕"<<endl;cout << "请输⼊哈希表长度:";cin >> length;cout << endl <<endl <<"开始构造哈希表"<<endl; CreateHashTable(pHashtable, length, pArr, nums); cout <<endl<<"哈希表构造完毕"<<endl<<endl;cout<<endl<<endl;int value = 0;for (int i = 0; i < nums * 10; ++ i){cout << "请输⼊要查查找的元素:";cin >> value;Find(pHashtable, value, value % length);cout<<endl;}return0;}。

csdn数据结构课程设计1、数据结构是计算机科学中非常重要的一门课程,它主要研究不同数据结构在存储、管理和操作数据时的性能和效率。
在这门课程的课程设计中,我们需要设计一个能够展示数据结构的应用项目。
我选择了使用CSDN作为项目的背景,将设计一个能够实现用户注册、登录和发表博客的系统。
2、首先,我会使用链表这种数据结构来设计用户和博客的存储。
链表由节点组成,每个节点包含一个存储元素和指向下一个节点的指针。
用户和博客可以通过链表节点来进行存储和管理。
通过链表结构,我们可以轻松地实现用户列表的存储和遍历,以及博客的发布和查找。
3、接着,我会使用树这种数据结构来设计用户的登录。
树是一种非线性的数据结构,它由一系列的节点组成,每个节点可以有零个或多个子节点。
将用户信息存储在树中,并通过树的遍历和查找操作来验证用户的登录信息。
这样可以提高系统的安全性和稳定性。
4、然后,我会使用哈希表这种数据结构来设计用户的注册。
哈希表是一种根据关键码值而直接进行访问的数据结构。
将用户注册的姓名和密码作为关键码值进行存储和查找,可以提高用户注册的效率和准确性。
5、在实现过程中,我还会运用队列和栈这两种数据结构来辅助我们的系统。
队列是一种先进先出(FIFO)的数据结构,适用于处理用户请求和系统任务。
栈是一种后进先出(LIFO)的数据结构,适用于处理系统日志和用户活动。
通过队列和栈的应用,我们能够更好地管理数据和用户交互。
6、最后,我会利用图这种数据结构来设计用户之间的关系。
图是一种由节点和边组成的数据结构,通过节点和边之间的关系来描述对象之间的联系。
在我们的系统中,用户之间可以通过关注和粉丝等关系来形成一张关系图,通过图的遍历和连接操作来展示用户之间的关系。
7、总结起来,本课程设计通过使用链表、树、哈希表、队列、栈和图等多种数据结构,设计了一个能够展示数据结构的CSDN应用系统。
通过设计这个系统,我们能够更好地理解和应用数据结构的概念和原理,提高我们的编程能力和计算机科学素养。
哈希表数据结构哈希表是一种常用的数据结构,它可以将元素的添加、查找和删除的操作时间复杂度降至O(1),是一种快速、紧凑的数据结构。
它也可以被用于存储大量的键值对,如字典或者关联数组。
哈希表的内部结构有不同的实现方式,可以根据不同的实现方法达到不同的性能。
本文将详细介绍哈希表的背景、实现方式和应用等内容,以期使读者对哈希表有更深入的理解。
一、哈希表的概念哈希表是一种索引定位数据的数据结构。
哈希表(又称散列表)使用一种称为哈希函数的函数,根据键来计算出一个索引值,然后将值存储在数组的指定位置。
由于其有效的搜索时间,哈希表在许多不同的应用程序中被广泛的使用。
二、哈希表的实现方式哈希表的实现方式有多种,如拉链法、开放寻址法等,但其常用的实现方式为拉链法。
(1)拉链法拉链法是最基本的哈希表实现方式,它将散列值相同的键值(元素)存储在链表中,当需要查找或添加元素时只需要在链表中进行查找和操作,从而达到减少对查找和添加的时间复杂度。
拉链法中每个数组位置上存放一个链表的指针,链表中的每个节点中存放着存储的元素。
(2)开放寻址法开放寻址法是一种空间换时间的实现方式,它首先将输入的元素通过哈希函数映射成一个数组下标,如果该数组位置已经有数据存在,则重新使用哈希函数映射得到一个新的下标,直到找到一个没有被占用的位置将元素存放进去,以此来解决碰撞问题。
三、哈希表的应用哈希表在计算机科学中有着广泛的应用,它可以用来存储、查询和管理大量的键值对,如字典或者关联数组,减少查找的时间复杂度。
同时它也可以被用来存储表格数据,将表格转换成哈希表,使得查询性能更优。
此外,哈希表还可以被用来实现复杂的数据结构,如字典树,它可以帮助我们快速查询字符串是否存在。
总结哈希表是一种常用的数据结构,它可以将元素的添加、查找和删除的操作时间复杂度降至O(1),是一种快速、紧凑的数据结构。
它的实现方式主要有拉链法和开放寻址法,广泛应用于字典的存储、表格的查询和复杂的数据结构的实现等等。
数据结构模块化课程标准课程名称:数据结构适用专业:计算机科学与技术、通信工程、信息管理与信息系统等相关专业学时/学分:64/4一、课程定位《数据结构》是研究现实世界中数据的各种逻辑结构在计算机中的存储结构以及进行各种非数值操作的方法。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
数据结构往往同高效的检索算法和索引技术有关。
它不仅是计算机程序设计的理论基础,而且是学习计算机操作系统、编译原理、数据库原理等课程的重要基础。
数据结构是要培养学生分析和研究计算机加工的数据对象特征的能力,本课程定位严格服务于应用型高等学校专业人才培养目标,坚持理论与上机实践相结合,通过算法训练提高学生的编程思维与编程能力,通过程序设计的技能训练来促进学生的综合应用能力和专业素质的提高。
二、课程设计思路课程建设指导思想是:树立精品意识;渗透创新理念;体现应用型办学特色;注重实践教学。
课程安排在大学二年级第一个学期,学习数据结构的目的是为了可以更好地理解计算机处理对象的特性、将实际问题所涉及的处理对象在计算机中表示出来并对它们进行处理。
数据结构课程内容概念多、综合性和技巧性强,对于学生来说,学生难以听懂,因此,在教学方法上宜采用案例教学,实验上采用项目驱动。
课程教学要结合学校应用型人才培养的定位,培养学生的学习兴趣和良好的学习习惯,通过实践教学中以培养学生的独立思考能力、动手能力。
通过小组合作、项目带动等方式进一步培养学生的沟通能力和创新能力。
课程结束后,学生应能独立上机编写并调试程序,用程序解决实际问题。
在二年级的学习中,学生需要掌握各种逻辑结构在不同存储方式下的常用算法,能够编写课程标准中的所有实训项目。
教学方法和手段:在实际教学中,我们采取多媒体进行教学,课外让学生在慕课网注册学习,学生可根据自身的学习情况利用课外时间进行针对性的复习;根据不同的章节内容,在教学中突出重点,并根据不同的章节制订相应的授课计划。
hash表哈希表是计算机科学中常见的数据结构,也称为散列表。
哈希表是由一个数组和一个哈希函数组成的数据结构,其中数组的每个元素被称为“哈希桶”,哈希函数用于计算元素索引,这个索引通常称为“哈希码”,该索引用于在数组中定位正确的哈希桶。
哈希表的设计目标是提供一种在常数时间内完成查找、插入和删除操作的数据结构,因此它通常被用作高效的字典数据结构。
哈希表的基本操作包括put(插入)、get(查找)和delete(删除)。
在哈希表中,元素的索引是根据哈希函数的计算结果得出的。
哈希函数是将输入值(元素)映射到哈希码的函数,哈希函数应该满足的性质是它应该是一致的,即对于同一个输入,哈希函数应该总是返回相同的哈希码,在不同的输入之间,哈希函数应该尽可能地让哈希码分布均衡。
同一个哈希码可能是由不同的输入得出的,这种情况在哈希表中称为“哈希冲突”,哈希冲突的解决方法有开放式寻址和链表法。
在开放式寻址中,当一个哈希冲突发生时,它会尝试向后遍历桶数组,选择第一个空桶,并在这个桶中插入元素。
如果该桶被另一个元素占据,就尝试下一个空桶,如果整个数组被遍历完毕,那么原来的插入操作就失败了。
在开放式寻址中,哈希表中的元素被紧密地存储,所以这种方法较适用于内存空间较小的情况,但这种方法的缺点是在高度填满的哈希表中,访问哈希表的效率会显著降低,并且哈希表中的操作也变得非常耗时。
在链表法中,数组每个位置都是一个链表的头结点,当哈希冲突发生时,新的元素会被插入到对应桶中的链表末尾。
链表法是一种天然并行的数据结构,它允许在同一桶内的元素并行地插入和删除,并且支持调整哈希表的负载因子,使哈希表在高度填充时的性能保持稳定。
但是,链表法的缺点是每个元素都需要存储一个指向下一个元素的指针,在大型哈希表中会占用大量的内存空间。
除了以上两种解决哈希冲突的方法,还有一些其他的方法被广泛地应用在哈希表中,比如线性探测和双重哈希等算法。
线性探测是一种开放式寻址算法,它尝试寻找下一个可用的哈希桶作为冲突的解决方法。
Word格式通讯录查询系统的设计与实现完美整理一、需求分析1、问题描述为某个单位建立一个员工通讯录管理系统,可以方便查询每一个员工的电话与地址。
设计散列表存储,设计并实现通讯录查找系统。
2、基本要求a.每个记录有下列数据项:电话号码、用户名、地址;b.从键盘输入各记录,分别以电话号码为关键字建立散列表;c.采用二次探测再散列法解决冲突;d.查找并显示给定电话号码的记录;e.通讯录信息文件保存。
二、概要设计1.数据结构本程序需要用到两个结构体,分别为通讯录 message以及哈希表HxList2.程序模块本程序包含两个模块,一个是实现功能的函数的模块,另一个是主函数模块。
系统子程序及功能设计本系统共有三个子程序,分别是:int Hx(long long key,int data)//哈希函数void BulidHx(HxList &L)//建立通讯录int Search(HxList &L)//查找3.各模块之间的调用关系以及算法设计主函数调用BulidHx以及Search函数。
函数BulidHx调用函数Hx。
三、详细设计1.数据类型定义typedef struct{char *name;char *add;long long phonenumber;}message;typedef struct{message *list;int number;//记录数}HxList;2.系统主要子程序详细设计a. 建立通讯录void BulidHx(HxList &L)//建立通讯录{FILE *f = fopen("E:\\tongxunlu.txt", "w");char buf[20]={0},str[20]={0};long long key;cout<<"输入要建立的记录数:";cin>>L.number;L.number+=1;L.list=new message[L.number];//分配哈希表的存储空间for(int i=0;i<L.number;i++){L.list[i].phonenumber=-1;}L.list[L.number-1].name=NULL;L.list[L.number-1].add=NULL;cout<<"输入记录信息(电话号码用户名地址)"<<endl; for(int i=0;i<L.number-1;i++){cin>>key>>buf>>str;int pose=Hx(key,L.number);//获取理论上的存储位置if(L.list[pose].phonenumber==-1){}else{//用二次探测再散列法解决冲突//1^2 -1^2 2^2 -2^2int di,count=1;xunhuan: if(count%2==0)di=-(count/2)*(count/2);elsedi=((count/2)+1)*((count/2)+1);int site=Hx(key+di,L.number);if(site>=0){if(L.list[site].phonenumber==-1){pose=site;}else{count++;goto xunhuan;}}else{site=L.number-abs(site);if(L.list[site].phonenumber==-1){pose=site;}else{count++;goto xunhuan;}}}L.list[pose].phonenumber=key;fprintf(f,"%lld",key);fprintf(f," ");L.list[pose].name=new char[strlen(buf)+1];strcpy(L.list[pose].name,buf);fprintf(f,"%s",buf);fprintf(f," ");L.list[pose].add=new char[strlen(str)+1];strcpy(L.list[pose].add,str);fprintf(f,"%s",str);fprintf(f,"\n");}}b.查找int Search(HxList &L)//查找{long long key;cout<<"输入要查找记录的关键字(电话号码):";cin>>key;int pose=Hx(key,L.number);//计算理论上的位置if(L.list[pose].phonenumber==key){}else{int count=1,di;//二次探测再散列,查找xunhuan: if(count%2==0){di=-(count/2)*(count/2);}else{di=((count/2)+1)*((count/2)+1);}int site=Hx(key+di,L.number);if(site>=0){if(L.list[site].phonenumber==key){pose=site;}else{count++;if(L.list[site].phonenumber==-1){cout<<"没有找到"<<endl;return -1;//没有找到}goto xunhuan;}}else{site=L.number-abs(site);if(L.list[site].phonenumber==key){pose=site;}else{count++;if(L.list[site].phonenumber==-1){cout<<"没有找到"<<endl;return -1;//没有找到}goto xunhuan;}}}if(L.list[pose].phonenumber==key){cout<<"电话号码\t"<<"用户名\t"<<"地址"<<endl;cout<<L.list[pose].phonenumber<<"\t"<<L.list[pose].name<<"\t"<<L.list [pose].add<<endl;return pose;}}四、测试与分析1.显示主菜单,运行程序可以显示出如下界面。
哈希表(hash)详解哈希表结构讲解:哈希表(Hash table,也叫散列表),是根据关键码值(Key value)⽽直接进⾏访问的数据结构。
也就是说,它通过把关键码值映射到表中⼀个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
记录的存储位置 = function(关键字)这⾥的对应关系function称为散列函数,⼜称为哈希(Hash函数),采⽤散列技术将记录存储在⼀块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key,value) 就是把Key通过⼀个固定的算法函数function既所谓的哈希函数转换成⼀个整型数字,然后就将该数字对数组长度进⾏取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间⾥。
(或者:把任意长度的输⼊(⼜叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。
这种转换是⼀种压缩映射,也就是,散列值的空间通常远⼩于输⼊的空间,不同的输⼊可能会散列成相同的输出,⽽不可能从散列值来唯⼀的确定输⼊值。
简单的说就是⼀种将任意长度的消息压缩到某⼀固定长度的消息摘要的函数。
)⽽当使⽤哈希表进⾏查询的时候,就是再次使⽤哈希函数将key转换为对应的数组下标【仍通过映射哈希函数function】,并定位到该空间获取value,如此⼀来,就可以充分利⽤到数组的定位性能进⾏数据定位。
Hash的应⽤:1、Hash主要⽤于信息安全领域中加密算法,它把⼀些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash 就是找到⼀种数据内容和数据存放地址之间的映射关系。
2、查找:哈希表,⼜称为散列,是⼀种更加快捷的查找技术。
我们之前的查找,都是这样⼀种思路:集合中拿出来⼀个元素,看看是否与我们要找的相等,如果不等,缩⼩范围,继续查找。
数据结构课程设计报告
课题四哈希表查找的设计
1. 任务和功能要求
设哈希表长为20,用除留余数法构造一个哈希函数,以开放定址法中的线性探测再散列法作为解决冲突的方法,编程实现哈希表查找、插入和建立算法。
2. 需求分析
用户输入20个以内的数字存储在哈希表中,并可以在表中查找关键字。
3.概要设计
typedef struct
{
int *key; //关键字
int count; //表长
}HashTable;
int creat(HashTable *T) //初始化哈希表
程序调用关系如下:
主函数模块
哈希表初始化模块查询模块
插入模块
4. 详细设计
#include<stdio.h>
#include <stdlib.h>
#include <windows.h>
#include <conio.h>
typedef struct
{
int *key; //关键字
int count; //表长
}HashTable;
int search(HashTable *T,int k) //初始化哈希表
{
int a;
a=k%13;
while(a<20)
{
if(T->key[a]==k) break;
a++;
}
if(a<20)
return a;
else
return 0;
}
void insert(HashTable *T,int k)
{
int i,j;
i=search(T,k);
if(i!=0)
printf(" 关键字已存在于位置%d",i); else
{
j=k%13;
while(j<20)
{
if(T->key[j]==0)
{
T->key[j]=k;break;
}
else j++;
}
}
}
int func(HashTable *T)
{
int a,k;
printf("______________________________________________________\n"); printf(" 查找\n\n"); printf("请输入关键字:");
scanf("%d",&k);
a=search(T,k);
if(a!=0)
printf(" \n关键字位置为%d\n",a);
else
printf(" \n未查找到关键字");
return 0;
printf("\n\n输入任意值返回");
getch();
system("cls");
}
int creat(HashTable *T)
{
int i,j,m,a;
T->key=(int *)malloc(20*sizeof(int));
for(m=0;m<20;m++)
T->key[m]=0;
printf("________________________________________________________\n"); printf("请输入关键字个数:");
scanf("%d",&i);
printf("\n请输入关键字:\n");
for(j=0;j<i;j++)
{
scanf("%d",&a);
insert(T,a);
T->count++;
}
return 0;
}
int main()
{
HashTable T;
creat(&T);
func(&T);
return 0;
}
5. 调试分析
1)在函数insert中,T->key[j]=k;后没有写break;使得插入第一个数会占满所有空间,无法再次插入。
6. 用户手册
1)演示程序的运行环境为Windows8.1系统,Microsoft Visual Studio 6.0中的Microsoft Visual C++ 6.0中运行。
执行文件为:哈希表.exe
2)进入演示程序后即显示DOS形式的界面:
3)接受其他命令后即执行相应运算和显示相应结果。
7.测试结果
1)
2)输入12个关键字
3)查找关键字。