Hacmp_监视群集状态
- 格式:doc
- 大小:260.00 KB
- 文档页数:5


一、功能原理1.HACMP的概念HACMP(High Availability Cluster Multi-Processing)是IBM基于Unix平台开发的一套高可用性集群软件,这个软件是为了确保关键资源或应用可以获得处理。
在hacmp集群环境中,应用必须在hacmp的管理之下,这样才可以确保应用的高可用性,当集群中的一个节点或组件出现问题,集群会将这个节点或组件所需的资源转移至其他节点上。
建立集群的目的✓减少计划或非计划的宕机时间✓避免单点故障✓快速故障恢复,但不能实现容错2.节点,网络,心跳2.1节点节点是安装并运行AIX操作系统和hacmp软件的一台独立系统,节点之间可以共享一系列资源:磁盘,卷组,文件系统,网络,网络IP地址和应用程序。
2.2网络集群各个节点之间通过网络进行相互通讯,当一个节点的某个网卡出现故障后,网络连接会自动切换到这个节点的其他网卡上,如果这个节点的所有网络连接都不可用的时候,集群会把应用极其所使用资源切换到其他节点上,并进行IP 地址接管操作IPAT(IP Address Takeover)。
集群的网络IP接管方式有2种:IP别名和IP替换IP别名:当集群把资源组以及IP地址从主节点切换目标节点时,在目标节点上并不会用主节点的服务地址去替代目标节点的网卡地址,而是在目标节点的网卡上建立IP别名(IP Alias),这样允许一个网卡绑定多个服务地址,因此同一节点可以装载更多的资源组。
IP替换:当集群把资源组以及IP地址从主节点切换目标节点时,目标节点的初始化启动IP将被主节点的服务IP所替换,这样只有使用同一服务地址的资源组可以装载到目标节点。
如果使用IP替换的接管方式还可以配置网络硬件地址HWAT(Hardware Address Takeover)即MAC地址切换,以确保ARP cache对网络地址的影响。
注:在HACMP4.5版本以前网络接管方式只能配置为IP替换方式。
一、HACMP 双机系统配置计划在配置中间业务平台HACMP环境之前首先要制定配置计划。
在IBM HACMP 的配置指南中推荐了一种配置计划表的方式(Planning Worksheet ),在进行配置考虑的时候将这些表格填完即可。
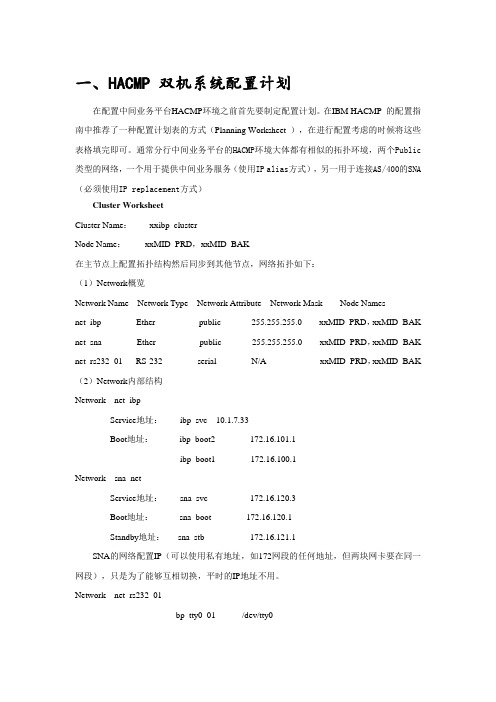
通常分行中间业务平台的HACMP环境大体都有相似的拓扑环境,两个Public 类型的网络,一个用于提供中间业务服务(使用IP alias方式),另一用于连接AS/400的SNA (必须使用IP replacement方式)Cluster WorksheetCluster Name:xxibp_clusterNode Name:xxMID_PRD,xxMID_BAK在主节点上配置拓扑结构然后同步到其他节点,网络拓扑如下:(1)Network概览Network Name Network Type Network Attribute Network Mask Node Namesnet_ibp Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_sna Ether public 255.255.255.0 xxMID_PRD,xxMID_BAK net_rs232_01 RS-232 serial N/A xxMID_PRD,xxMID_BAK (2)Network内部结构Network net_ibpService地址:ibp_svc 10.1.7.33Boot地址:ibp_boot2 172.16.101.1ibp_boot1 172.16.100.1Network sna_netService地址:sna_svc 172.16.120.3Boot地址:sna_boot 172.16.120.1Standby地址:sna_stb 172.16.121.1SNA的网络配置IP(可以使用私有地址,如172网段的任何地址,但两块网卡要在同一网段),只是为了能够互相切换,平时的IP地址不用。

HACMP操作手册强制方式停掉HACMP:HACMP 的停止分为3 种,graceful(正常),takeover(手工切换),force(强制)。
下面的维护工作,很多时候需要强制停掉HACMP 来进行,此时资源组不会释放,这样做的好处是,由于IP 地址、文件系统等等没有任何影响,只是停掉HACMP 本身,所以应用服务可以继续提供,实现了在线检查和变更HACMP 的目的。
一般所有节点都要进行这样操作。
强制停掉后的HACMP 启动:在修改HACMP 的配置后,大多数情况下需要重新申请资源启动,这样才能使HACMP 的配置重新生效.日常检查及处理为了更好地维护HACMP,平时的检查和处理是必不可少的.下面提供的检查和处理方法除非特别说明,均是不用停机,而只需停止应用即可进行,不影响用户使用。
不过具体实施前需要仔细检查状态,再予以实施。
clverify 检查这个检查可以对包括LVM 的绝大多数HACMP 的配置同步状态,是HACMP 检查是否同步的主要方式。
smitty clverify—〉Verify HACMP Configuration回车即可经过检查,结果应是OK。
如果发现不一致,需要区别对待。
对于非LVM 的报错,大多数情况下不用停止应用,可以用以下步骤解决:1.先利用强制方式停止HACMP 服务。
同样停止host2 的HACMP 服务.1.只检查出的问题进行修正和同步:smitty hacmp —〉Extended Configuration—>Extended Verification and Synchronization这时由于已停止HACMP 服务,可以包括"自动修正和强制同步“。
对于LVM 的报错,一般是由于未使用HACMP 的C-SPOC 功能,单边修改文件系统、lv、VG 造成的,会造成VG 的timestamp 不一致.这种情况即使手工在另一边修正(通常由于应用在使用,也不能这样做),如何选取自动修正的同步,也仍然会报failed。

HACMP的基本概念IBM的高可靠性群集系统软件HACMP-- High Availability Cluster Multi-Processing提供了RS/6000平台上关键应用的高可靠性解决方案,该软件能使一个群集内的所有的RS/6000系统不存在单点失效( 在群集中单独某一部分出现故障而引起对用户端的服务失效) 。
HACMP系统能自动地检测系统硬件失效,重新配置群集系统,使得所有的资源完全不受系统硬件失效的影响,从而提供了可靠的应用平台。
HACMP可用来最多将32部RS/6000服务器或SP的节点连结成高可用性的群集结构。
对于企业关键性的应用程序而言,群集式的服务器或节点提供代理式的数据访问,具备复制性(redundancy),使得系统应用程序具有灵活的容错能力。
HACMP所具有灵活的结构和简单的使用。
从单一处理机(SMP)主机到SP节点皆可结构成高可用性之群集,您可混用,且跨越系统大小及性能等级,将各种网络适配卡和磁盘子系统融合在一起确,来满足您的应用程序、网络等方面的需求。
HACMP的群集因不同的处理需求可以结构成几种不同的模式。
同时访问模式(Concurrent access mode)适用在所有处理机必须在相同的工作负载及在相同的时间共享相同的数据之环境。
相互备援模式(mutual takeover mode)则是群集中的各个节点分别承担有应用和任务,并且各节点间相互备援。
而热待机模式则为一节点备援任何群集上的另一节点。
无论您选择哪一种备援模式,HACMP所提供的数据访问及备援方案都将应用程序的执行及增长性在避免不正常死机状况下做了最佳化处理。
HACMP用户界面相当简易,AIX的系统管理界面工具(SMIT)及视觉化系统管理(VSM)图形使用界面两者皆提供非常简易的方式,给予您在高可用性的集群中针对服务器处理机执行安装、结构及系统管理工作。
对于一般的群集管理工作【例如HACMP启动/停止、用户及群集管理、卷组、逻辑卷(Logic Volume)及文件系统】,您可以使用群集单点控制(CSPOC)工具来执行这些工作,即使是二个节点之群集,您完全无需考虑群集资源的所有权。

HACMP日常系统管理1:日常日志:日常日志主要是记录平时事件的启动,从中可以了解HACMP的动作,例如主机standby网卡故障,有fail_standby事件发生,系统管理员可从日志中得知何时出的故障,及有没有解决。
主要日志文件有:/tmp/hacmp.out:记录HACMP启动或有动作时执行的各事件。
此文件一天刷新一次,保留七天,文件保存为/tmp/hacmp.out.1-7;/usr/adm/cluster.log:记录HACMP的错误信息及各事件,另记录事件发生的时间;/tmp/cm.log:保存HACMP中clstrmgr进程产生信息的时间;/usr/sbin/cluster/history/cluster.mmdd:HACMP的历史记录文件。
2:启动和关闭HACMP:每次机器启动后,由系统管理员手工启动HACMP,机器shutdown前,手工关闭HACMP。
启动命令:# smit clstart 选项按缺省,启动顺序为先启主机,待主机的/tmp/hacmp.out文件中node_up_local_complete执行完后,再启动备机的HACMP;关闭命令:# smit clstop shutdown mode选项要确认为graceful。
当出现以下情况时须按指定步骤操作:主、备机在关电后,再次启动时,备机正常,主机不能启动。
指定步骤:在备机上执行# smit hacmp 选择cluster configuration进入,选择Cluster Resources进入,选择Chage/show Resources for a Resource Group进入,将Inactive Takeover Activated 改为true执行。
退出到命令行,启动HACMP,这时备机接管主机的资源。
3:查看HACMP状态:在HACMP中,它启动一个进程来监控各节点。
用# ps –ef|grep clinfo 命令查看clinfo 进程是否启动。
HA工作原理HACMP工作原理 [转帖]HACMP工作原理HACMP的工作原理是利用LAN来监控主机及网络、网卡的状态。
在一个HACMP环境中有TCP/IP网络和非TCP/IP网络。
TCP/IP网络即应用客户端访问的公共网,该网可以是大多数AIX所支持的网络,如Ethernet,T.R.,FDDI,ATM,SOCC,SLIP,等等。
非TCP/IP网络用来为HACMP对HA环境(Cluster)中的各节点进行监控而提供的一个替代TCP/IP的通讯路径,它可以是用RS232串口线将各节点连接起来,也可以是将各节点的SCSI卡或SSA卡设置成Target Mode方式。
HACMP将诊测并响应于三种类型的故障:1网卡故障,2网络工作,3节点故障。
下面就这三种故障分别进行介绍。
1、网卡故障前面讲到,HACMP的群集结构中,除了TCP/IP网络以外,还有一个非TCP/IP网络,它实际上是一根“心跳”线,专门用来诊测是节点死机还是仅仅网络发生故障。
如下图所示,一旦节点加入了Cluster(即该节点上的HACMP已正常启动),该节点的各个网卡、非TCP/IP网络就会不断地接收并送Keep-Alive信号,K-A的参数是可调的,HA在连续发送一定数量个包都丢失后就可确认对方网卡,或网络,或节点发生故障。
因此,有了K-A后,HACMP可以很轻易地发现网卡故障,因为一旦某块网卡发生故障发往该块网卡的K-A就会丢失。
此时node 1上的cluster manager( HACMP的“大脑”)会产生一个swap-adapter的事件,并执行该事件的script(HACMP中提供了大部分通用环境下的事件scripts,它们是用标准AIX命令和HACMP 工具来写的)。
每个节点上都有至少两块网卡,一块是service adapter,提供对外服务,另一块是standby adapter,它的存在只有cluster manager知道,应用和client并不知道。
**省操作风险管理系统小型机安装配置手册目录小型机安装配置手册 (4)1.1操作系统安装 (4)1.2安装操作系统bundle (10)1.3limit参数设置 (11)1.4开启IOCP (11)1.5打开fullcore设置 (12)1.6调整maxpout,minpout设置 (12)1.7调整maxuproc设置 (12)1.8调整syncd设置 (12)1.9设置时区 (13)1.10增加error log文件大小 (13)1.11系统网络参数设置 (13)1.12系统AIO参数设置 (14)1.13系统VM参数设置 (14)1.14HBA卡参数设置 (15)1.15语言包安装 (15)1.16补丁包安装 (16)1.17创建oracle软件的文件系统 (16)1.18操作系统镜像 (17)1.19设置SWAP大小 (17)1.20修改文件系统大小设置 (17)1.21dump设置 (18)1.22安装hacmp软件 (19)1.23安装hacmp补丁 (20)1.24配置网络 (20)1.25添加cluster 名字 (21)1.26添加cluster的主机 (21)1.27添加基于IP的网络 (22)1.28添加基于非IP的网络(即串口心跳) (22)1.29添加IP地址 (22)1.30添加串口设备 (23)1.31添加资源组 (24)1.32添加SVC IP (25)1.33添加应用脚本 (26)1.34添加卷组到资源组 (28)1.35同步串口通讯 (30)1.36同步两台主机HACMP配置 (30)1.37主节点上启动Cluster (31)1.38备节点上启动Cluster (34)1.39查看hacmp的运行状态 (34)1.40Hacmp资源组切换测试 (38)1.41EMC存储powerpath多路径管理软件安装 (41)1.42创建VG (47)1.41.1 创建sqdbvg (47)1.41.2创建hddbvg (54)1.41.3创建rmansqvg (58)1.41.4创建rmanhdvg (59)小型机安装配置手册1.1操作系统安装要求统一使用****6100-07 SP4操作系统安装介质进行操作系统安装。
4.3.监视群集状态
你总是可以将群集状态作为一个整体(启动、停机、不稳定)来监视或者针对不同的节点状态(启动、停机、加入中、离开中或者重建中)来分别监视。
4.3.1.使用clstat
你可以使用命令/usr/sbin/cluster/clstat来获得有关群集的不同的片段的信息,包括群集状态、节点数目、节点名称和状态、资源组名称和状态以及接口名称和状态。
要使用这个命令,必须运行clinfo后台进程。
Example 4-5显示了命令的输出结果:
如果群集节点具有图形终端,你可以使用命令/usr/sbin/cluster/clstat来显示一个描述群集和节点状态的图形窗口。
执行这一步以前,确保DISPLAY变量输出到X server的地址并且允许X client访问。
命令结果如Figure 4-1所示:
4.3.2.使用snmpinfo
如果你想使用基于SNMP的监视,记住:HACMP使用V1代理,AIX 5L 5.2默认使用V3,因此,你要使用命令/usr/sbin/snmpv3_ssw -1来改变版本。
4.3.3.使用Tivoli
如果你想使用Tivoli监视你的群集,你需要安装Tivoli监视组件。
操作原理及更多信息参考SG24-5979:提高群集多处理能力(HACMP V4.4)。
4.4.群集停止
你可以使用SMIT快速路经smitty clstop停止群集服务,在这里可以选择在所有节点上停止群集服务,停止类型可以是完美的、接管的或者强制的。
如何停止群集服务请参考Example 4-6:
在一个节点上成功提高停止群集服务后,命令lssrc -g cluster的输出将没有任何内容。
同样,你可以使用别名命令lsha来校验所有群集相关进程的状态。
如何校验群集相关服务的状态参考Example 4-7:
请注意:clcomd后台进程在群集服务停止后依然在运行。
节点停止类型决定在节点上成功停止群集服务后资源组被获取的行为。
在/tmp/hacmp.out文件中查找node_down和node_down_complete事件。
Example 4-8显示了一个node_down事件:
Example 4-9显示了一个node_down_complete事件:
无论何时,你都应该避免用kill -9命令停止群集管理后台进程。
在这种情况下(使用kill -9命令),系统资源控制器(SRC)会检测到clstrmgr后台进程异常退出并调用/usr/es/sbin/cluster/utilities/clexit.rc脚本。
这会造成系统停止并有可能造成共享存储数据的破坏。
依照资源组策略,其他节点会初始化接管。
如果你遇到有关群集停止问题或者你想更好的理解群集停止过程,请参考SC23-4862-02:AIX 5L V5.1下HACMP管理和故障排除一书第七章“启动、停止群集服务”。
完美停止
如果选择这个参数,属于该节点的资源组会被释放,但该资源组不能被其他节点获取。
带接管的完美停止
如果选择这个参数,属于该节点的资源组会被释放,并且该资源组依照资源组类型会被被其他节点获取。
强制停止
如果选择这个参数,群集服务会停止,但是资源组不会被释放。
注意:我们不推荐您在同一时间在多个节点上使用强制选项来停止群集服务。