计量经济学精要(第四版)重点
- 格式:docx
- 大小:138.05 KB
- 文档页数:10

第一章导论第一节什么是计量经济学计量经济学是现代经济学的重要分支。
为了深入学习计量经济学的理论与方法,有必要首先从整体上对计量经济学有一些概略性的认识,了解计量经济学的性质、基本思想、基本研究方法以及若干常用的基本概念。
一、计量经济学的产生与发展在对实际经济问题的研究中,经常需要对经济活动及其数量变动规律作定量的分析。
例如,为了研究中国经济的增长,需要分析中国国内生产总值(GDP)变动的状况? 分析有哪些主要因素会影响中国GDP的增长?分析中国的GDP与各种主要影响因素关系的性质是什么?分析各种因素对中国GDP影响的程度和具体数量规律是什么?分析所得到的数量分析结果的可靠性如何?还要分析经济增长的政策效应,或者预测中国GDP发展的趋势。
显然,对这类经济问题的定量分析,需要解决一些共性问题:提出所研究的经济问题及度量方式,确定表现研究对象的经济变量(如用GDP的变动度量经济的增长);分析对研究对象变动有影响的主要因素,选择若干作为影响因素的变量;分析各种影响因素与所研究经济现象相互关系的性质,决定相互联系的数学关系式;运用科学的数量分析方法,确定所研究的经济对象与各种影响因素间具体的数量规律;运用统计方法分析和检验所得数量结论的可靠性;运用数量研究的结果作经济分析和预测。
对社会经济问题数量规律的研究具有普遍性,计量经济学是专门研究这类问题的经济学科。
计量经济学(Econometrics)这个词是挪威经济学家、第一届诺贝尔经济学奖获得者弗瑞希(R.Frisch)在其1926年发表的《论纯经济问题》一文中,按照”生物计量学”(Biometrics)一词的结构仿造出来的。
Econometrics一词的本意是指“经济度量”,研究对经济现象和经济关系的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为计量经济学,是为了强调计量经济学是一门经济学科,不仅要研究经济现象的计量方法,而且要研究经济现象发展变化的数量规律。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
第一章导论第一节什么是计量经济学计量经济学是现代经济学的重要分支。
为了深入学习计量经济学的理论与方法,有必要首先从整体上对计量经济学有一些概略性的认识,了解计量经济学的性质、基本思想、基本研究方法以及若干常用的基本概念。
一、计量经济学的产生与发展在对实际经济问题的研究中,经常需要对经济活动及其数量变动规律作定量的分析。
例如,为了研究中国经济的增长,需要分析中国国内生产总值(GDP)变动的状况? 分析有哪些主要因素会影响中国GDP的增长?分析中国的GDP与各种主要影响因素关系的性质是什么?分析各种因素对中国GDP影响的程度和具体数量规律是什么?分析所得到的数量分析结果的可靠性如何?还要分析经济增长的政策效应,或者预测中国GDP发展的趋势。
显然,对这类经济问题的定量分析,需要解决一些共性问题:提出所研究的经济问题及度量方式,确定表现研究对象的经济变量(如用GDP的变动度量经济的增长);分析对研究对象变动有影响的主要因素,选择若干作为影响因素的变量;分析各种影响因素与所研究经济现象相互关系的性质,决定相互联系的数学关系式;运用科学的数量分析方法,确定所研究的经济对象与各种影响因素间具体的数量规律;运用统计方法分析和检验所得数量结论的可靠性;运用数量研究的结果作经济分析和预测。
对社会经济问题数量规律的研究具有普遍性,计量经济学是专门研究这类问题的经济学科。
计量经济学(Econometrics)这个词是挪威经济学家、第一届诺贝尔经济学奖获得者弗瑞希(R.Frisch)在其1926年发表的《论纯经济问题》一文中,按照”生物计量学”(Biometrics)一词的结构仿造出来的。
Econometrics一词的本意是指“经济度量”,研究对经济现象和经济关系的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为计量经济学,是为了强调计量经济学是一门经济学科,不仅要研究经济现象的计量方法,而且要研究经济现象发展变化的数量规律。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。


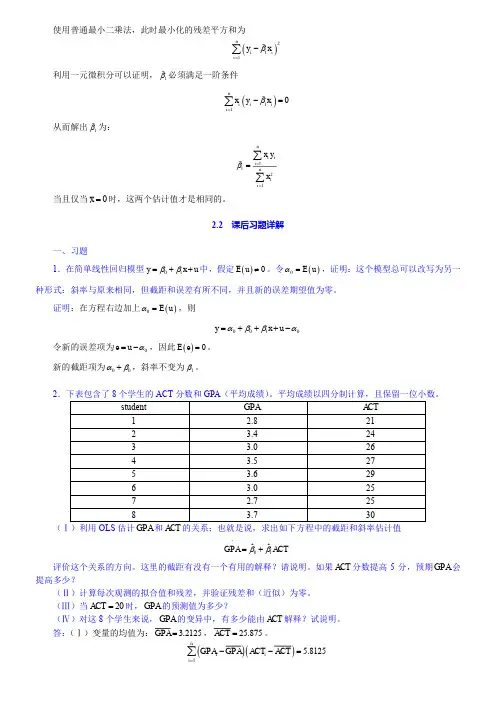
使用普通最小二乘法,此时最小化的残差平方和为()211niii y x β=-∑利用一元微积分可以证明,1β必须满足一阶条件()110niiii x y x β=-=∑从而解出1β为:1121ni ii nii x yxβ===∑∑当且仅当0x =时,这两个估计值才是相同的。
2.2 课后习题详解一、习题1.在简单线性回归模型01y x u ββ=++中,假定()0E u ≠。
令()0E u α=,证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:在方程右边加上()0E u α=,则0010y x u αββα=+++-令新的误差项为0e u α=-,因此()0E e =。
新的截距项为00αβ+,斜率不变为1β。
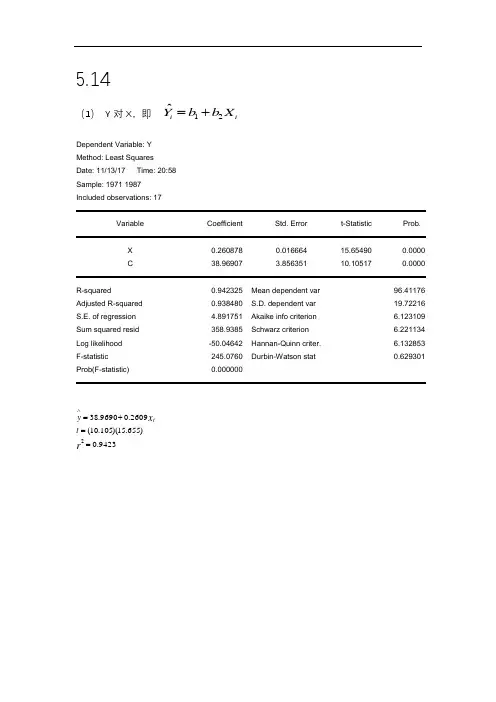
2(Ⅰ)利用OLS 估计GPA 和ACT 的关系;也就是说,求出如下方程中的截距和斜率估计值01ˆˆGPA ACT ββ=+^评价这个关系的方向。
这里的截距有没有一个有用的解释?请说明。
如果ACT 分数提高5分,预期GPA 会提高多少?(Ⅱ)计算每次观测的拟合值和残差,并验证残差和(近似)为零。
(Ⅲ)当20ACT =时,GPA 的预测值为多少?(Ⅳ)对这8个学生来说,GPA 的变异中,有多少能由ACT 解释?试说明。
答:(Ⅰ)变量的均值为: 3.2125GPA =,25.875ACT =。
()()15.8125niii GPA GPA ACT ACT =--=∑根据公式2.19可得:1ˆ 5.8125/56.8750.1022β==。
根据公式2.17可知:0ˆ 3.21250.102225.8750.5681β=-⨯=。
因此0.56810.1022GPA ACT =+^。
此处截距没有一个很好的解释,因为对样本而言,ACT 并不接近0。
如果ACT 分数提高5分,预期GPA 会提高0.1022×5=0.511。
(Ⅱ)每次观测的拟合值和残差表如表2-3所示:根据表可知,残差和为-0.002,忽略固有的舍入误差,残差和近似为零。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
By DT 计量经济学精要重点 什么是OLS估计?原理ols估计是指样本回归函数尽可能好的拟合这组织,即样本回归线上的点与真实观测点的总体误差尽可能小的估计方法。
一、什么是计量经济学? 答:计量经济学以经济理论为指导,以事实为依据,以数学和统计学为方法,以电脑技术为工具,从事经济关系与及经济活动数量规律的研究,并以建立和应用随机性的经济计量模型为核心的一门经济学科。 计量经济学模型揭示经济活动中各种因素之间的定量关系,用随机性的数量方程加以描述。
二、建立计量经济学模型的步骤和要点 1.理论模型的设计(确定模型所包含的变量,确定模型的数量形式,拟定理论模型中的待估参数的理论期望值) 2.样本数据的收集(常用的样本数据:时间序列数据,截面数据,虚变量数据) 3.模型参数的估计(选择模型参数估计方法,应用软件的使用) 4.模型的检验 模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。 经济意义检验——需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合; 统计检验——需要检验模型参数估计值的可靠性,即检验模型的统计学性质; 计量经济学检验——需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等; 模型的预测检验——主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 5.模型成功的三要素:理论、方法、数据
三、计量经济学模型的应用方面(功能) 答:结构分析,经济预测,政策评价,检验与发展经济理论
四、引入随机干扰项的原因,内容? 原因:1.代表未知的影响因素2.代表数据观测误差3.代表残缺数据4.代表模型设定误差5.代表众多细小影响因素6.变量的内在随机性 内容:1.被遗漏的影响因素(由于研究者对客观经济现象了解不充分,或是由于经济理论上的不完善,以至于使研究者在建立模型时遗漏了一些对被解释变量有重要影响的变量);2.变量的测量误差(在观察和测量变量时,种种原因使观测值并不等于他的真实值而造成的误差);3.随机误差(在影响被解释变量的诸因素中,还有一些不能控制的因素);4.模型的设定误差(在建立模型时,由于把非线性关系线性化,或者略去模型)
五、什么是随机误差项和残差,他们之间的区别是什么 随机误差项u=Y-E(Y/X),而总体回归函数Y=Y^+e,其中e就是残差,利用Y^估计Y时带来的误差e=Y-Y^是对随机变量u的估计
六、一元线性回归模型的基本假设主要有哪些?违背基本假设是否就不能进行估计 1.回归模型是正确设定的; 2.解释变量X是确定性变量不是随机变量;在重复抽样中取固定值。 3.解释变量在x所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的样本方差趋于一个非零的有限常数。 4.随机误差项u具有给定X条件下的零均值,同方差以及不序列相关性,即E(ui/Xi)=0; Var (ui/Xi)=sm2;Cov(ui,uj/ Xi,Xj)=0 5. 随机误差项与解释变量之间不相关:Cov(Xi, Ui)=0 By DT
6. 随机误差项服从零均值、同方差的正态分布 违背..还可进行估计,只是不能使用普通最小二乘法进行估计。
七、高斯-马尔可夫定理 如果满足古典线性回归模型的基本假定,则在所有线性无偏估计量中,OLS估计量具有最小方差,即OLS估计量是最优线性无偏估计量。 假设条件:1.回归模型是正确设定的;2.解释变量X是确定性变量不是随机变量;在重复抽样中取固定值。3. 解释变量在x所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的样本方差趋于一个非零的有限常数。4.随机误差项u具有给定X条件下的零均值,同方差以及不序列相关性
八、异方差性 对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。 类型:单调递增型,单调递减型,复杂型。 原因: ⑴模型中遗漏了随时间变化影响逐渐增大的因素。(即测量误差变化) ⑴模型函数形式设定误差。 ⑴随机因素的影响。(即截面数据中总体各单位的差异) 后果:1.参数估计量非有效2.变量的显著性检验失去意义3.模型的预测失效 检验:图示检验法 , 戈德菲尔德-匡特检验,怀特检验,帕克检验和戈里瑟检验 处理:基本思想:变异方差为同方差,或尽量缓解方差变异的程度。(加权最小二乘法(WLS),异方差稳健标准误法)
九、序列相关性 如果模型的随机干扰项违背了相互独立的基本假设,则称为存在... 原因:1.经济数据序列惯性;2.模型设定的偏误;3.滞后效应;4.蛛网现象;5.数据的编造 后果:1.参数估计量非有效;2.变量的显著性检验失去意义;3.模型的预测失效 检验方法:一、图示法;二、回归检验法;三、D.W.检验法;四、拉格朗日乘数检验 补救方法:广义最小二乘法(GLS),广义差分法,随机干扰项相关系数的估计,广义差分法在计量经济学软件中的实现,序列相关稳健标准误法。
十、多重共线性 如果模型的解释变量之间存在着较强的相关关系,则称模型存在多重共线性。 原因:(1)经济变量相关的共同趋势2.滞后变量的引入3.样本资料的限制 后果:1.完全共线性下参数估计量不存在2.近似共线性下普通最小二乘法参数估计量的方差变大3.参数估计量经济含义不合理4.变量的显著性检验和模型的预测功能失去意义 检验:1.检验多重共线性是否存在2.判明存在多重共线性的范围 克服方法:1.排除引起共线性的变量2.差分法3.见笑参数估计量的方差
十一、回归模型中引入虚拟变量的作用是什么?有哪几种基本的引入方式?它们各适合用于什么情况 答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。 加法方式与乘法方式是最主要的引入方式。 前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
十二、滞后变量模型有哪几种类型?分布滞后模型使用OLS方法存在哪些问题? 答:滞后变量模型有分布滞后模型和自回归模型两大类,前者只有解释变量及其滞后变量作为模型的解释变量,不包含被解释变量的滞后变量作为模型的解释变量;而后者则以当期解释变量与被解释变量的若干期滞后变量作为模型的解释变量。分布滞后模型有无限期的分布滞后模型和有限期的分布滞后模型;自回归模型又以Coyck模型、自适应预期模型和局部调整模型最为多见。 By DT
分布滞后模型使用OLS法存在以下问题:(1)对于无限期的分布滞后模型,由于样本观测值的有限性,使得无法直接对其进行估计。(2)对于有限期的分布滞后模型,使用OLS方法会遇到:没有先验准则确定滞后期长度,对最大滞后期的确定往往带有主观随意性;如果滞后期较长,由于样本容量有限,当滞后变量数目增加时,必然使得自由度减少,将缺乏足够的自由度进行估计和检验;同名变量滞后值之间可能存在高度线性相关,即模型可能存在高度的多重共线性。
传统或经典方法论(建立模型)(一)理论模型的设计1、理论或假说的陈述;2、理论的数学模型的设定;3、理论的计量经济模型的设定;(二)获取数据(三)模型的参数估计(四)模型的检验1、经济意义的检验2、统计检验3、计量经济学检验4、预测检验(五)模型应用1、经济分析/构分析2、经济预测3、政策评价4、检验与发展经济理论 计量经济学模型成功的三要素理论、方法、数据 回归分析是研究一个变量关于另一个(些)变量的依赖关系的计算方法和理论。用意在于通过后者的已知或设定值,去估计和(或)预测前者的(总体均值。前一个变量被称为被解释变量或应变量后一个变量被称为解释变量或自变量 总体回归函数(方程):PRF由于统计相关的随机性,回归方程关心的是根据解释变量的已知或给定值,考察被解释变量的总体均值,即当解释变量取某个确定值时,与之统计相关的被解释变量所可能出现的对应值的平均值。
在给定解释变量iX条件下被解释变量iY的期望轨迹称为总体回归线,或更一般地称为总体回归曲线相应的函数(方程):
总体回归函数(方程)(PRF)含义:回归函数(PRF)说明被解释变量tY的平均状态(总体条件期望)随解释变量X变化的规律 随机干扰项是在模型设定中省略下来而由集体地影响着被解释变量Y的全部变量的替代物
样本回归函数(SRF)iiiXXfY10ˆˆ)(ˆ 样本回归函数的随机形式iiiiieXYY10ˆˆˆˆ 线性回归模型在上述意义上的基本假设:(1) 解释变量1X,2X,…kX是确定性变量,不是随机变量,而且解释变量之间互不相关。(2) 随机误差项具有0均值和同方差。即E(i)=0 i=1,2,…n Var(i
)=2
i=1,2,…n其中E表示均值或期望,也可用M表示;Var表示方差,也可以用D表示。(3) 随机误差项在
不同样本点之间是独立的,不存在序列相关。即 Cov(i
,j)=0 ij i,j=1,2,…n其中Cov表示协方
差。(4) 随机误差项与解释变量之间不相关。即 Cov(jiX,i)=0 j=1,2,…k i=1,2,…n(5) 随机误差项
服从0均值、同方差的正态分布。即 ),0(~2Ni i=1,2,…n
一元线性回归模型的参数估计:普通最小二乘法估计已知一组样本观测值(iY,iX),(i=1,2,…n),要求样本回归函数尽可能好地拟合这组值,即样本回归线上的点iYˆ与真实观测点iY的“总体误差”尽可能地小,或者说被解释变量的估计值与观测值应该在总体上最为接近,最小二乘法给出的判断的标准是:二
者之差的平方和niiiinXYYYQ121021))ˆˆ(()ˆ(最小。即在给定样本观测值之下,选择出0ˆ、1
ˆ