统计学课后习题参考答案
- 格式:doc
- 大小:1.00 MB
- 文档页数:30

第一章复习思考题与练习题:一、思考题1.统计的基本任务是什么?2.统计研究的基本方法有哪些?3.如何理解统计总体的基本特征。
4.试述统计总体和总体单位的关系。
5.标志与指标有何区别何联系。
二、判断题1、社会经济统计的研究对象是社会经济现象总体的各个方面。
()2、在全国工业普查中,全国企业数是统计总体,每个工业企业是总体单位。
()3、总体单位是标志的承担者,标志是依附于单位的。
()4、数量指标是由数量标志汇总来的,质量指标是由品质标志汇总来的。
()5、全面调查和非全面调查是根据调查结果所得的资料是否全面来划分的()。
三、单项选择题1、社会经济统计的研究对象是()。
A、抽象的数量关系B、社会经济现象的规律性C、社会经济现象的数量特征和数量关系D、社会经济统计认识过程的规律和方法2、某城市工业企业未安装设备普查,总体单位是()。
A、工业企业全部未安装设备B、工业企业每一台未安装设备C、每个工业企业的未安装设备D、每一个工业3、标志是说明总体单位特征的名称,标志有数量标志和品质标志,因此()。
A、标志值有两大类:品质标志值和数量标志值B、品质标志才有标志值C、数量标志才有标志值D、品质标志和数量标志都具有标志值4、统计规律性主要是通过运用下述方法经整理、分析后得出的结论()。
A、统计分组法B、大量观察法C、综合指标法D、统计推断法5、指标是说明总体特征的,标志是说明总体单位特征的,所以()。
A、标志和指标之间的关系是固定不变的B、标志和指标之间的关系是可以变化的C、标志和指标都是可以用数值表示的D、只有指标才可以用数值表示答案:二、 1.× 2.× 3.√ 4.× 5.×三、 1.C 2.B 3.C 4.B 5.B第三章一、复习思考题1.什么是平均指标?平均指标可以分为哪些种类?2.为什么说平均数反映了总体分布的集中趋势?3.为什么说简单算术平均数是加权算术平均数的特例?4.算术平均数的数学性质有哪些?5.众数和中位数分别有哪些特点?6.什么是标志变动度?标志变动度的作用是什么?7.标志变动度可分为哪些指标?它们分别是如何运用的?8.平均数与标志变动度为什么要结合运用?二、练习题(教材第四章P108课后习题答案)1.某村对该村居民月家庭收入进行调查,获取的资料如下:按月收入分组(元)村民户数(户)500~600 600~700 700~800 800~900 900以上20 30 35 25 10合计120 要求:试用次数权数计算该村居民平均月收入水平。

《统计学》课后题答案第一章导论一、选择题1.C2.A3.C4.C5.C6.B7.A8.D9.C 10.D 11.A 12.C 13.C 14.A 15.B 16.A 17.C 18.B 19.D 20.A 21.D 22. D23.B 24.C 25.A 26.A 27.A 28.B 29.A 30.D 31.C 32.A 33.B第二章数据的收集一、选择题1.A2.B3.A4.D5.B6.C7.D8.D9.D 10.C 11.C 12.A 13.D 14.D 15.C 16.A 17.D 18.C 19.B 20.B 21.A 22.B 23.C 24.A 25.B 26.B 27.A 28.B 29.C 30.C (A)二、判断题1.∨2.∨3.×4. ∨5. ×6. ×7. ∨8. ×9. ×10. ×第三章数据整理与显示一、选择题CABCD CBBAB BACBD DDBC第四章数据分布特征的测度一、选择题1.A2.C3.B4.C5.D6.D7.A8.B9.A 10.B 11.A 12.D 13.C 14.C 15.D 16.A 17.A 18.B 19.A 20.B 21.A 22.A 23.B 24.C 25.C 26.D 27.D 28.A 29.D 30.C 31.C 32.D二、判断题1. ×2. ∨3. ×4. ×5. ×6. ×7. ∨8. ×9. × 10. ∨ 11. ∨ 12. ×四、计算题1. 11399073.8954ki ii kii x fx f=====∑∑甲11.96σ===甲73.89100%100% 6.18%11.96x σν=⨯=⨯=甲73.8100%100%7.43%9.93x σν=⨯=⨯=乙甲的代表性强2. 10.2510.966ki ii kii x fx f====∑∑0.250.056σ==0.250.056100%100% 5.834%0.966xσν=⨯=⨯= 1114.534ki ii kii x fx f====∑∑10.1295σ==10.1295100%100% 2.857%4.534xσν=⨯=⨯=该教练的说法不成立。

版权归wagxjysys所有违者必究第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。

统计学课后习题答案第七章相关分析与回归分析第七章相关分析与回归分析⼀、单项选择题1.相关分析是研究变量之间的A.数量关系B.变动关系C.因果关系D.相互关系的密切程度2.在相关分析中要求相关的两个变量A.都是随机变量B.⾃变量是随机变量C.都不是随机变量D.因变量是随机变量3.下列现象之间的关系哪⼀个属于相关关系A.播种量与粮⾷收获量之间关系B.圆半径与圆周长之间关系C.圆半径与圆⾯积之间关系D.单位产品成本与总成本之间关系4.正相关的特点是A.两个变量之间的变化⽅向相反B.两个变量⼀增⼀减C.两个变量之间的变化⽅向⼀致D.两个变量⼀减⼀增5.相关关系的主要特点是两个变量之间A.存在着确定的依存关系B.存在着不完全确定的关系C.存在着严重的依存关系D.存在着严格的对应关系6.当⾃变量变化时, 因变量也相应地随之等量变化,则两个变量之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系7.当变量X值增加时,变量Y值都随之下降,则变量X和Y之间存在着A.正相关关系B.直线相关关系C.负相关关系D.曲线相关关系8.当变量X值增加时,变量Y值都随之增加,则变量X和Y之间存在着A.直线相关关系B.负相关关系C.曲线相关关系D.正相关关系9.判定现象之间相关关系密切程度的最主要⽅法是A.对现象进⾏定性分析B.计算相关系数C.编制相关表D.绘制相关图10.相关分析对资料的要求是A.⾃变量不是随机的,因变量是随机的B.两个变量均不是随机的C.⾃变量是随机的,因变量不是随机的D.两个变量均为随机的11.相关系数A.既适⽤于直线相关,⼜适⽤于曲线相关B.只适⽤于直线相关C.既不适⽤于直线相关,⼜不适⽤于曲线相关D.只适⽤于曲线相关12.两个变量之间的相关关系称为A.单相关B.复相关C.不相关D.负相关13.相关系数的取值范围是≤r≤1 ≤r≤0≤r≤1 D. r=014.两变量之间相关程度越强,则相关系数A.愈趋近于1B.愈趋近于0C.愈⼤于1D.愈⼩于115.两变量之间相关程度越弱,则相关系数A.愈趋近于1B.愈趋近于0C.愈⼤于1D.愈⼩于116.相关系数越接近于-1,表明两变量间A.没有相关关系B.有曲线相关关系C.负相关关系越强D.负相关关系越弱17.当相关系数r=0时,A.现象之间完全⽆关B.相关程度较⼩B.现象之间完全相关 D.⽆直线相关关系18.假设产品产量与产品单位成本之间的相关系数为,则说明这两个变量之间存在A.⾼度相关B.中度相关C.低度相关D.显着相关19.从变量之间相关的⽅向看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和⽆相关20.从变量之间相关的表现形式看可分为A.正相关与负相关B.直线相关和曲线相关C.单相关与复相关D.完全相关和⽆相关21.物价上涨,销售量下降,则物价与销售量之间属于A.⽆相关B.负相关C.正相关D.⽆法判断22.配合回归直线最合理的⽅法是A.随⼿画线法B.半数平均法C.最⼩平⽅法D.指数平滑法23.在回归直线⽅程y=a+bx中b表⽰A.当x增加⼀个单位时,y增加a的数量B.当y增加⼀个单位时,x增加b的数量C.当x增加⼀个单位时,y的平均增加量D.当y增加⼀个单位时, x的平均增加量24.计算估计标准误差的依据是A.因变量的数列B.因变量的总变差C.因变量的回归变差D.因变量的剩余变差25.估计标准误差是反映A.平均数代表性的指标B.相关关系程度的指标C.回归直线的代表性指标D.序时平均数代表性指标26.在回归分析中,要求对应的两个变量A.都是随机变量B.不是对等关系C.是对等关系D.都不是随机变量27.年劳动⽣产率(千元)和⼯⼈⼯资(元)之间存在回归⽅程y=10+70x,这意味着年劳动⽣产率每提⾼⼀千元时,⼯⼈⼯资平均A.增加70元B.减少70元C.增加80元D.减少80元28.设某种产品产量为1000件时,其⽣产成本为30000元,其中固定成本6000元,则总⽣产成本对产量的⼀元线性回归⽅程为:=6+ =6000+24x=24000+6x =24+6000x29.⽤来反映因变量估计值代表性⾼低的指标称作A.相关系数B.回归参数C.剩余变差D.估计标准误差⼆、多项选择题1.下列现象之间属于相关关系的有A.家庭收⼊与消费⽀出之间的关系B.农作物收获量与施肥量之间的关系C.圆的⾯积与圆的半径之间的关系D.⾝⾼与体重之间的关系E.年龄与⾎压之间的关系2.直线相关分析的特点是A.相关系数有正负号B.两个变量是对等关系C.只有⼀个相关系数D.因变量是随机变量E.两个变量均是随机变量3.从变量之间相互关系的表现形式看,相关关系可分为A.正相关B.负相关C.直线相关D.曲线相关E.单相关和复相关4.如果变量x与y之间没有线性相关关系,则A.相关系数r=0B.相关系数r=1C.估计标准误差等于0D.估计标准误差等于1E.回归系数b=05.设单位产品成本(元)对产量(件)的⼀元线性回归⽅程为y=,则A.单位成本与产量之间存在着负相关B.单位成本与产量之间存在着正相关C.产量每增加1千件,单位成本平均增加元D.产量为1千件时,单位成本为元E.产量每增加1千件,单位成本平均减少元6.根据变量之间相关关系的密切程度划分,可分为A.不相关B.完全相关C.不完全相关D.线性相关E.⾮线性相关7.判断现象之间有⽆相关关系的⽅法有A.对现象作定性分析B.编制相关表C.绘制相关图D.计算相关系数E.计算估计标准误差 8.当现象之间完全相关的,相关系数为 B.-1 E.- 9.相关系数r =0说明两个变量之间是A.可能完全不相关B.可能是曲线相关C.肯定不线性相关D.肯定不曲线相关E.⾼度曲线相关10.下列现象属于正相关的有A.家庭收⼊愈多,其消费⽀出也愈多B.流通费⽤率随商品销售额的增加⽽减少C.产量随⽣产⽤固定资产价值减少⽽减少D.⽣产单位产品耗⽤⼯时,随劳动⽣产率的提⾼⽽减少E.⼯⼈劳动⽣产率越⾼,则创造的产值就越多 11.直线回归分析的特点有A.存在两个回归⽅程B.回归系数有正负值C.两个变量不对等关系D.⾃变量是给定的,因变量是随机的E.利⽤⼀个回归⽅程,两个变量可以相互计算 12.直线回归⽅程中的两个变量A.都是随机变量B.都是给定的变量C.必须确定哪个是⾃变量,哪个是因变量D.⼀个是随机变量,另⼀个是给定变量E.⼀个是⾃变量,另⼀个是因变量13.从现象间相互关系的⽅向划分,相关关系可以分为A.直线相关B.曲线相关C.正相关D.负相关E.单相关 14.估计标准误差是A.说明平均数代表性的指标B.说明回归直线代表性指标C.因变量估计值可靠程度指标D.指标值愈⼩,表明估计值愈可靠E.指标值愈⼤,表明估计值愈可靠 15.下列公式哪些是计算相关系数的公式16.⽤最⼩平⽅法配合的回归直线,必须满⾜以下条件A.?(y-y c )=最⼩值B.?(y-y c )=0C.?(y-y c )2=最⼩值D.?(y-y c )2=0E.?(y-y c )2=最⼤值 17.⽅程y c =a+bx222222)()(.)()())((...))((.y y n x x n yx xy n r E y y x x y y x x r D L L L r C L L L r B n y y x x r A xxxy xyyy xx xy y x ∑-∑?∑-∑∑?∑-∑=-∑?-∑--∑===--∑=σσA.这是⼀个直线回归⽅程B.这是⼀个以X为⾃变量的回归⽅程C.其中a是估计的初始值D.其中b是回归系数是估计值18.直线回归⽅程y c=a+bx中的回归系数bA.能表明两变量间的变动程度B.不能表明两变量间的变动程度C.能说明两变量间的变动⽅向D.其数值⼤⼩不受计量单位的影响E. 其数值⼤⼩受计量单位的影响19.相关系数与回归系数存在以下关系A.回归系数⼤于零则相关系数⼤于零B.回归系数⼩于零则相关系数⼩于零C.回归系数等于零则相关系数等于零D.回归系数⼤于零则相关系数⼩于零E.回归系数⼩于零则相关系数⼤于零20.配合直线回归⽅程的⽬的是为了A.确定两个变量之间的变动关系B.⽤因变量推算⾃变量C.⽤⾃变量推算因变量D.两个变量相互推算E.确定两个变量之间的相关程度21.若两个变量x和y之间的相关系数r=1,则A.观察值和理论值的离差不存在的所有理论值同它的平均值⼀致和y是函数关系与y不相关与y是完全正相关22.直线相关分析与直线回归分析的区别在于A.相关分析中两个变量都是随机的;⽽回归分析中⾃变量是给定的数值,因变量是随机的B.回归分析中两个变量都是随机的;⽽相关分析中⾃变量是给定的数值,因变量是随机的C.相关系数有正负号;⽽回归系数只能取正值D.相关分析中的两个变量是对等关系;⽽回归分析中的两个变量不是对等关系E.相关分析中根据两个变量只能计算出⼀个相关系数;⽽回归分析中根据两个变量只能计算出⼀个回归系数三、填空题1.研究现象之间相关关系称作相关分析。

统计学课后习题答案附录三:部分习题参考解答老师说这份答案有些错误,慎重参考哈~~第一章(15-16)一、判断题2.答:对。
3.答:错。
实质性科学研究该领域现象的本质关系和变化规律;而统计学则是为研究认识这些关系和规律提供合适的方法,特别是数量分析的方法。
4.答:对。
5.答:错。
描述统计不仅仅使用文字和图表来描述,更重要的是要利用有关统计指标反映客观事物的数量特征。
6.答:错。
有限总体全部统计成本太高,经常采用抽样调查,因此也必须使用推断技术。
7.答:错。
不少社会经济的统计问题属于无限总体。
例如要研究消费者的消费倾向,消费者不仅包括现在的消费者而且还包括未来的消费者,因而实际上是一个无限总体。
8.答:对。
二、单项选择题1.A;2.A;3.A;4.B。
三、分析问答题1.答:定类尺度的数学特征是“=”或“”,所以只可用来分类,民族可以区分为汉、藏、回等,但没有顺序和优劣之分,所以是定类尺度数据。
;定序尺度的数学特征是“”或“”,所以它不但可以分类,还可以反映各类的优劣和顺序,教育程度可划分为大学、中学和小学,属于定序尺度数据;定距尺度的主要数学特征是“+”或“-”,它不但可以排序,还可以用确切的数值反映现象在两方面的差异,人口数、信教人数、进出口总额都是定距尺度数据;定比尺度的主要数学特征是“”或“”,它通常都是相对数或平均数,所以经济增长率是定比尺度数据。
3.答:如考察全国居民人均住房情况,全国所有居民构成统计总体,每一户居民是总体单位,抽查其中5000户,这被调查的5000户居民构成样本。
第二章(45-46)一、单项选择题1.C;2.A;3.A。
二、多项选择题1.A.B.C.D;2.A.B.D;3.A.B.C.三、简答题1.答:这种说法不对。
从理论上分析,统计上的误差可分为登记性误差、代表性误差2.答:统计报表的日常维持需要大量的人力、物力、财力;而且统计报表的统计指标、指标体系不容易调整,对现代社会经济调查来说很不合适。

第一章总论一、单项选择题1.威廉·配第是(B )的代表人物。
A.记述学派B.政治算术学派C.社会学派D.数理统计学派2.以下属于推断统计学研究范围的是(D)。
A.数据调查与收集B.数据的计算C.数据汇总D.抽样估计3.调查某企业职工的健康状况,总体单位是(D )。
A.这个企业B.所有的职工C.每个职工D.每个职工的健康状况4.数量指标表现为(C)。
A.相对数В.平均数C.绝对数D.变异数5.名义级数据可以用来(A )。
A.分类B.比较大小C.加减运算D.加、减、乘、除四则运算6.间距级数据之间不可以(D )。
A.比较是否相等B.比较大小C.进行加减运算D.进行乘除运算7.2个大学生的身高分别为165厘米、172厘米,则165、172是(D )。
A.2个变量B. 2 个标志C.2个指标D. 2个数据8.总体与总体单位的确定(A)。
A.与研究目的有关B.与研究目的无关C.与总体范围大小有关D.与研究方法有关9,通过有限数量的种子发芽试验结果来估计整批种子的发芽率,这种统计方法属于(A)。
A. f断统计学B.描述统计学C.数学D.逻辑学10.国势学派对统计学的主要贡献是(C)A.采用了数量分析方法B.引入了大数法则C.提出了“统计学"一词D.证明了小样本理论11.统计学是一门关于研究客观事物数量方面和数量关系的(C )。
A.社会科学B.自然科学C.方法论科学D.实质性科学12.数理统计学的奠基人是(C )。
A.威廉·配第B.阿亭瓦尔C.凯特勒D.恩格尔13.统计学研究的特点是(B)A.大量性、总体性、变异性B.数量性、总体性、变异性C.大量性、总体性、同质性D.数量性、总体性、同质性14.通过测量或计算取得其值的是(B)A.品质变量B.连续变量C.离散变量D.以上都不对15.统计学的创始人是(A)。
A.威廉·配第B.阿享瓦尔C.凯特勒D.恩格尔二、多项选择题1.“统计”一词有三层含义,即(BD)。
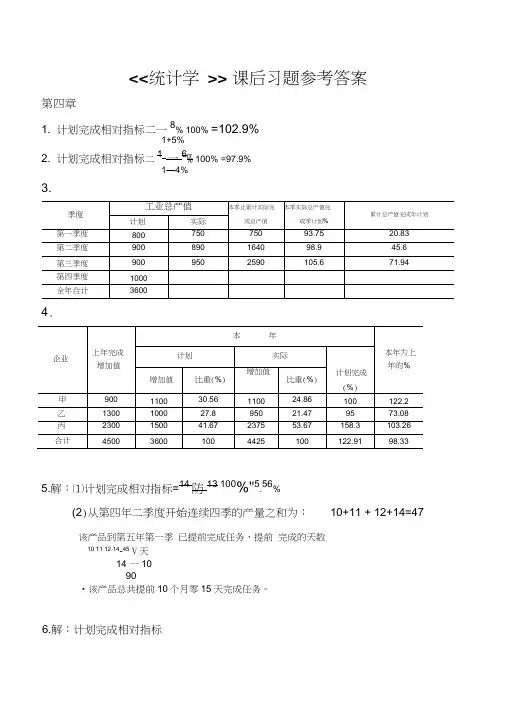
<<统计学 >> 课后习题参考答案第四章1. 计划完成相对指标二一8% 100% =102.9%1+5%2. 计划完成相对指标二1一6% 100% =97.9%1—4%3.4.5.解:⑴计划完成相对指标=14防13 100%"5.56%(2)从第四年二季度开始连续四季的产量之和为:10+11 + 12+14=47该产品到第五年第一季 已提前完成任务,提前 完成的天数90•该产品总共提前10个月零15天完成任务。
6.解:计划完成相对指标10 11 12 14-45V 天 14 一10156 230 540 279 325 470 535200 1040.1% 100% =126.75%(2) 156+230+540+279+325+470=2000 (万吨)所以正好提前半年完成计划7.第五章平均指标与标志变异指标1 . X 甲= :.26 27 28 29 30 31 32 3334=309—20 25 28 30 32 34 36 38 40 '1.44X乙二9AD甲二26-30卩27 -30 28-30 29 -30 30-30 |31 -30 32 - 30 亠|33 - 30 叫34 - 309-2.22AD乙二20—31.44” 25—31.44 十2〔8—31.44 屮30—31.44 +|32|— 31.44 + 34卜31.44 + 網 + 31.44 + 38—|31.44 + 4Q — 9= 5.06R 甲=34-26=8R 乙=40-20=20(26一30)2 (27 一30)2 (28一30)2 (29一30)2 (30 一 30)2 ⑶ 一 30)2 (32 一 30)2 (33一 30)2 (34一33)2--------------------------------------------------------------------- 9=2.58(T 乙一(20 -31.44)2 - (25 -31.44)2 (28 —31.44)2 (30 -31.44)2 (32 -31.44)2 (34-31.44)2 (36 -31.44)2 • (38-31.44)2 • (40_31.44)2----------------------------------------------------------------------------------------- 9=6.06 2 58 V 甲二 100%=8.6% 30V 乙二100% =19.3%31.44 所以甲组的平均产量代表性大一些2. 解:计算过程如下表:3. 解:计算过程如下表:X 甲80 77600X 乙=80= 970(元)X 甲=9550 119.480 (件)X 乙二 9660120.8=80(件)V 甲二旦06100%=7.58%119.4V 乙二!08! 100% =8.94%120.8所以甲厂工人的平均产量的代表性要高些4. 解:55 3 65 7 75 18 85 12 95 5=11 =7010=76.4718-7 18-1245 “10=70 上 10 = 76.94185.解:(1)上期的平均计划完成程度为100% =99.67%CT 甲=6568.7580二 9.06 (件)9355'80-10.81(件)3 7 18 12 5 18 -780 110% 700 108% 1000 100% 1500 95%80 700 1000 1500(2)下期的平均计划完成程度为:96 810 1200 1400------------------------------------------ =103.37%96 810 1200 1400110% 107% 101% 103%6解:P =300 _28100% =90.67%300X P二P = 90.67%二P「90.67% 1 -90.67% =0.2910.291V P100% =32.1%0.9067432.604 321.255 506.943 1042884.3兀/t 432.604 321.255 506.943、 4----------- +------------- +------------ ix 102800 2900 2950 丿苗吾第八章1.= 8722.a =600 670 2 .670 840 2 . 840 1020 1 . 1020 900 2 • 900 980 3 980 4030 ?2 2 2 2 2 23.解:全年月平均计划完成程 度为: 303 306 324 310 350 368 410 412 485 463 350 385 303 306 ------ + -------- 101% 102% 435 如00% = 105.85%324 310 350 368 410 412 485 463 350 385 + ------- + -------- + -------- + ------- + -------- + -------- + ------- + ------- + --------- + --------- 110% 105% 106% 98% 112% 105% 120% 97% 102% 113%576 4500 462亠 100% =79.63% 580 620 580 600 - 2 25.解:⑴甲工区上半年建筑安装 工人的月平均工资为:680 620 620 680 680 720 720 690 690 700 700 710 /汇600+ 汇620+ 江640+ 汇645 + ^625+ 汉610 2 2 2 680 620 680 720 690 7002 22乙工区上半年建筑安装工人的月平均工资为:650 670 670 680 “c 680 730 730 655 655 710 一 710 690640 600 620 655 615600 =623.7(元)2 650 + 670 + 680+730 + 655 + 710 +2 2 二 621.6(元)6■解:平均增长速度=4黔1皿7% 2000年该县粮食产量为:500 1 4.67% 10 = 788.7(万吨) 7解:计算过程如下表a y=竺=45.44 n 9则直线趋势方程为:y = a bt1994年的地方财政支出额为:45.44, 4.3 5 =66.94(万元)二次曲线方程为:y = 0.0108x2 + 4.1918x + 24.143过程略)指数曲线方程为:y = 26.996e0.0978x8.解:计算过程如下表原数列趋势图日期9•解:(1)同季平均法求季节比率的过程如下表第一季第二季第三季度第四季合计1987 13 18 311988 5 8 14 18 451989 6 10 16 22 541990 8 12 19 25 641991 15 17 32平均8.5 11.75 15.5 20.75 14.125 季节比率60.2% 83.2% 109.7% 146.9% 100.0%⑵趋势剔除法测定的季节变动如下表第一季第二季第三季度第四季合计19871988 44.94 71.11 123.08 153.191989 48.98 76.92 116.36 154.391990 53.78 76.8 112.59 136.051991平均49.23 74.94 117.34 147.88 389.40校正系数 1.0272214 1.027221366 1.027221366 1.02722137季节比率50.57 76.98 120.54 151.90 400.00第七章统计指数' q i Z。

《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑nxx i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12 (3)2.494.1561)(2==-=∑-n i s x x (4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1(2)==∑nxx i63/9=7,714.0808.41)(2==-=∑-n i s x x (3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 2=0.714/7=0.102.由于v 1>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑nx x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5(2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5(3) 17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。

第七章 参数估计(1)x σ==(2)2x z α∆==1.96=某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x σ=== (2)在95%的置信水平下,求估计误差。
x x t σ∆=⋅,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=z α 因此,x x t σ∆=⋅x z ασ=⋅0.025x z σ=⋅=×=(3)如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:2x z x z αα⎛-+ ⎝=()120 4.2,120 4.2-+=(,)2x z x z αα⎛-+ ⎝=104560±(,) 从总体中抽取一个n=100的简单随机样本,得到x =81,s=12。
要求:大样本,样本均值服从正态分布:2,x N n σμ⎛⎫ ⎪⎝⎭:或2,s x N n μ⎛⎫⎪⎝⎭:置信区间为:22x z x z αα⎛-+ ⎝, (1)构建μ的90%的置信区间。
2z α=0.05z =,置信区间为:()81 1.645 1.2,81 1.645 1.2-⨯+⨯=(,) (2)构建μ的95%的置信区间。
2z α=0.025z =,置信区间为:()81 1.96 1.2,81 1.96 1.2-⨯+⨯=(,) (3)构建μ的99%的置信区间。
2z α=0.005z =,置信区间为:()81 2.576 1.2,81 2.576 1.2-⨯+⨯=(,)(1)2x z α±=25 1.96±(,) (2)2x z α±=119.6 2.326±=(,) (3)2x z α±=3.419 1.645±(,) (1)2x z α±=8900 1.96±=(,)(2)2x z α±=8900 1.96±=(,) (3)2x z α±=8900 1.645±=(,)(4)2x z α±=8900 2.58±=(,) 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,调查解:(1)样本均值x =,样本标准差s=1α-=,t=z α=0.05z =,xz α±=3.32 1.645±(,) 1α-=,t=z α=0.025z =,x z α±=3.32 1.96±(,)1α-=,t=z α=0.005z =,x zα±=3.32 2.76±(,)2x t α±=10 2.365±=,某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样本,他们到单位的距离(单位:km)分别是:10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2假定总体服从正态分布,求职工上班从家里到单位平均距离的95%的置信区间。

第1章导论1、某森林公园的一项研究试图确定哪些因素有利于成年松树长到60英尺以上的高度。
经估计,森林公园生长着25000颗成年松树,该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。
该研究的总体是()A、250颗成年松树B、公园中25000颗成年松树C、所有高于60英尺的成年松树D、森林公园中所有年龄的松树2、某森林公园的一项研究试图确定成年松树的高度。
该研究需要从中随机抽取250颗成年松树并丈量它们的高度后进行分析。
该研究所感兴趣的变量是()A、森林公园中松树的年龄B、森林公园中松树的数量C、森林公园中松树的高度D、森林公园中数目的种类3、推断统计的主要功能是()A、应用总体的信息描述样本B、描述样本中包含的信息C、描述总体中包含的信息D、应用样本信息描述总体4、对高中生的一项抽样调查表明,85%的高中生愿意接受大学教育。
这一叙述是()的结果A、定性变量B、试验C、描述统计D、推断统计5、一名统计学专业的学生为了完成其统计学作业,在图书馆找到一本参考书中包含美国50个州的家庭收入中位数.在该生的作业中,他应该将此数据报告来源于()A、试验B、实际观察C、随机抽样D、已发表的资料6、某大公司的人力资源部主任需要研究公司雇员的饮食习惯.他注意到,雇员的午饭要么从家里带来,要么在公司餐厅就餐,要么在外面的餐馆就餐.该研究的目的是为了改善公司餐厅的现状。
这种数据的收集方式可以认为是()A、观察研究B、设计的试验C、随机抽样D、全面调查7、下列不属于描述统计问题的是()A、根据样本信息对总体进行的推断B、感兴趣的总体或样本C、图、表或其他数据汇总工具D、了解数据分布特征8、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。
该研究人员感兴趣的总体是()A、该大学的所有学生 B、所有的大学生C、该大学所有的一年级新生D、样本中的200名新生9、某大学的一位研究人员希望估计该大学一年级新生在教科书上的花费,为此,他观察了200名新生在教科书上的花费,发现他们每个学期平均在教科书上的花费是250元。

统计学习题参考答案 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】第一章导论(1)数值型变量。
(2)分类变量。
(3)离散型变量。
(4)顺序变量。
(5)分类变量。
(1)总体是该市所有职工家庭的集合;样本是抽中的2000个职工家庭的集合。
(2)参数是该市所有职工家庭的年人均收入;统计量是抽中的2000个职工家庭的年人均收入。
(1)总体是所有IT从业者的集合。
(2)数值型变量。
(3)分类变量。
(4)截面数据。
(1)总体是所有在网上购物的消费者的集合。
(2)分类变量。
(3)参数是所有在网上购物者的月平均花费。
(4)参数(5)推断统计方法。
第二章数据的搜集1.什么是二手资料使用二手资料需要注意些什么与研究内容有关的原始信息已经存在,是由别人调查和实验得来的,并会被我们利用的资料称为“二手资料”。
使用二手资料时需要注意:资料的原始搜集人、搜集资料的目的、搜集资料的途径、搜集资料的时间,要注意数据的定义、含义、计算口径和计算方法,避免错用、误用、滥用。
在引用二手资料时,要注明数据来源。
2.比较概率抽样和非概率抽样的特点,举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。
概率抽样是指抽样时按一定概率以随机原则抽取样本。
每个单位被抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽中的概率,概率抽样的技术含量和成本都比较高。
如果调查的目的在于掌握和研究总体的数量特征,得到总体参数的置信区间,就使用概率抽样。
非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。
非概率抽样操作简单、实效快、成本低,而且对于抽样中的专业技术要求不是很高。
它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。
非概率抽样也适合市场调查中的概念测试。
3.调查中搜集数据的方法主要有自填式、面方式、电话式,除此之外,还有那些搜集数据的方法?实验式、观察式等。
第五章 平均指标与标志变异指标一、判断题: 题号 1 2 3 4 5 6 7 8 9 10 答案××√√××××××二、单选题: 题号 1 2 3 4 5 6 7 8 9 10 答案ACBADADCAD三、多选题:应用能力训练题:⒈试根据下列某大型商场销售员日工资资料,计算该商场销售员的日平均工资:解:根据已知条件,计算有关数据资料如下表:所以:)(35.741007435件===∑∑f xf x⒉某公司下属10个企业,某年合格率资料如下表:要求:计算该产品的平均合格率解:根据题意,将有关数据计算入下表:%14.85140000119200===∑∑f xf x ⒊某市场上有三种鸡蛋,每公斤分别为16元、18元、20元,试计算: ⑴各买10公斤,平均每公斤多少钱? ⑵各买10元,平均每公斤多少钱? 解:⑴元)(1830102010181016............3213332211=⨯+⨯+⨯=++++++++=n n f f f f f x f x f x f x x⑵元)(85.17201018101610101010111=++++===∑∑∑∑m x m mm x x h ⒋某企业生产一种产品需顺次经过四个程序,这四个程序的废品率分别为1.2%、1.5%、1.3%和1.8%,该企业生产的平均废品率是多少?解:首先,计算该企业生产的平均合格率:%18.95%)8.11(%)3.11(%)5.11(%)2.11(......421=-⨯-⨯-⨯-=∏==n n n g x x x x x 该企业生产的平均废品率=1-95.18%=4.82%⒌某企业的销售额2011年比2010年增长7.5%,2012年比2011年增长9.8%,2013年比2012年增长6.3%,2014年比2013年增长11.4%。
计算2010年至2014年该企业销售额的平均增长速度。
统计学费宇石磊(主编)第2章练习题参考答案2.1解:(1)首先将顾客态度分别用代码1、2、3表示,然后在数据文件的Varible View窗口Values栏定义变量值标签:1代表“喜欢并愿意购买”;2代表“不喜欢”,3代表“喜欢并愿意购买”。
操作步骤:依次点击File→点击open→点击Data→打开数据文件ex2.1→点击Analyze→点击Descriptive Statistics→点击Frequencies→将“态度”选入Variable框→点击OK。
输出结果如表2.1所示:(2)根据表2.1频数分布表资料建立的数据文件为绘制条形图操作步骤:依次点击File→点击open→点击Data→打开数据文件,选中Summaries for groups of cases→单击Define→选中Other Summary function→将“人数”选入Variable(纵轴),将“态度分类”选入Category Axis (横轴)→点击OK。
输出结果如图2.1所示:图2.1 30名顾客满意程度分布条形图绘制饼图操作步骤:依次点击File→点击open→点击Data→打开数据文件ofindividual cases→点击Define→将“人数”选入Slices Represent栏,将“态度分类”选入Variable栏→点击OK。
输出结果如图2.2所示:2.2解:首先列计算表如表2.2所示:表2.2 120名学生英语成绩的均值、中位数、众数、偏态系数、峰度系数计算表(1)均值151872072.67120iii ii xf x f=====∑∑(分) 表2.2中,分布次数最多的组是“40~50”组,这就是众数所在组;2N=60,中位数大约在第60位,可确定中位数也在“40~50”组。
众数10124230701073.333018M L i ∆-=+⨯=+⨯=∆+∆-+-(分)(42)(42)中位数11204922701072.6242m e m N S M L i f ---=+⨯=+⨯=(分) (2)首先计算标准差:11.65s ==(分)31133()/38389.64/1200.202311.65kki ii i x x f f SK s ==-===∑∑由计算结果可看出,偏态系数为正值,但与零的差距不大,说明120名大学生英语成绩为轻微右偏分布,成绩较低的同学占有一定的比例,但偏斜程度不大。
思考题与练习题参考答案【友情提示】请各位同学完成思考题和练习题后再对照参考答案。
回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。
学而不思则罔,如果直接抄答案,对学习无益,危害甚大。
想抄答案者,请三思而后行!第一章绪论思考题参考答案1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。
即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔是危险的。
2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在他的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域是军机的危险区域。
3.能,拯救和发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。
练习题参考答案一、填空题1.调查。
2.探索、调查、发现。
3. 目的。
二、简答题1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。
2.统计学解决实际问题的基本思路,即基本步骤是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。
不解决问题时,重复第②-⑥步。
3.在结合实质性学科的过程中,统计学是能发现客观世界规律,更好决策,改变世界和培养相应领域领袖的一门学科。
三、案例分析题1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩;指标体系:上学期全班同学学习的科目;统计量:我班部分同学课程的平均成绩;定性数据:姓名;定量数据:课程成绩;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。
第四章 抽样分布与参数估计3.某地区粮食播种面积5000亩,按不重复抽样方法随机抽取了100亩进行实测,调查结果,平均亩产450公斤,亩产量标准差为52公斤。
试以95%的置信度估计该地区粮食平均亩产量和总产量的置信区间。
解:已知X =450公斤,n =100(大样本),n/N=1/50,11≈-Nn,不考虑抽样方式的影响,用重复抽样计算。
s =52公斤,1-α=95%,α=5%。
这时查标准正态分布表,可得临界值:96.1025.02/==z z α该地区粮食平均亩产量的置信区间是:1005296.14502⨯±=±nsz x α=[439.808,460.192] (公斤) 总产量的置信区间是:[439.808⨯5000,460.192⨯5000] (公斤) =[2199040,2300960](公斤)4.已知某种电子管使用寿命服从正态分布。
从一批电子管中随机抽取16只,检测结果,样本平均寿命为1490小时,标准差为24.77小时。
试以95%的置信度估计这批电子管的平均寿命的置信区间。
解:(1)已知X =1490小时,n =16,s =24.77小时,1-α=95%,α=5%。
这时查t 分布表,可得 2.13145)1(2/=-n t α该批电子管的平均寿命的置信区间是:1677.2413145.214902⨯±=±nst x α=[ 1476.801,1503.199](小时)因此,这批电子管的平均寿命的置信区间在1476.801小时与1503.199小时之间。
6.采用简单随机重复抽样的方法,从2 000件产品中抽查200件,其中合格品190件。
要求:(1)计算合格品率及其抽样平均误差。
(2)以95.45%的置信度,对合格品率和合格品数量进行区间估计。
(3)如果极限误差为2.31%,则其置信度是多少? 解:(1)合格品率:P=190/200⨯100%=95% 抽样平均误差:np p p )1()(-=σ=0.015(2)%3%95%100015.02%95)(22/02275.02/±=⨯⨯±=±==p Z P Z Z σαα]19601840[]2000%982000%92[(%]98%92[,,的置信区为:件合格品数量,:合格品率的置信区间为=⨯⨯)(3)%64.87)(8764.01,54.1%31.2%100015.0%31.2)(2/2/2/==-==⨯⨯==∆z F Z Z p Z ασααα查表得7.从某企业工人中随机抽选部分进行调查,所得工资分布数列如下:试求:(1)以95.45%的置信度估计该企业工人平均工资的置信区间,以及该企业工人中工资不少于800元的工人所占比重的置信区间;(2)如果要求估计平均工资的允许误差范围不超过30元,估计工资不少于800元的工人所占比重的允许误差范围不超过10%,置信度仍为95.45%,试问至少应抽多少工人? 解(1)通过EXCEL 计算可得: X =816元,n =50人,s =113.77元。
思考题与练习题参考答案【友情提示】请各位同学完成思考题与练习题后再对照参考答案。
回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。
学而不思则罔,如果直接抄答案,对学习无益,危害甚大。
想抄答案者,请三思而后行!第一章绪论思考题参考答案1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。
即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。
2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。
3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。
练习题参考答案一、填空题1.调查。
2.探索、调查、发现。
3、目的。
二、简答题1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。
2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。
不解决问题时,重复第②-⑥步。
3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。
三、案例分析题1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。
2.(1)总体:广州市大学生;单位:广州市的每个大学生。
(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。
(3)广州市大学生在网上购物的平均花费。
(4)就是用统计量作为参数的估计。
(5)推断统计。
3.(1)10。
(2)6。
(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。
(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。
(5)40%;(6)30%。
第二章收集数据思考题参考答案1.二手数据的特点主要有:易获得;成本低;快速获得;相关性差;时效性差与可靠性低。
对于任何一项研究,首先想到有没有现成的二手数据可用,实在没有或有但无法使用时才进行原始数据的收集。
2.普查的特点有:一次性的;规定统一的标准时点调查期限;数据一般比较准确,规范化程度较高;使用范围比较窄;调查质量不易控制;工作量大,花费大,组织工作复杂;易产生重复与遗漏现象等特点。
抽样调查的特点有:经济性好;实效性强;适应面广;准确性高。
3.两者不能替代。
两者的目的不同,调查对象不同,组织方式不同。
经济普查的“全面”包括所有经济体,比如个体户,而全面统计报表中的“全面”就是相对的,只有注册为公司或企业并具有一定经济规模的经济体,才就是调查对象,并不包括个体经营户。
4.略。
练习题参考答案一、判断题1、×2、×3、√4、√5、×6、√7、√8、√9、×10、√二、单项选择题1、C2、B3、C4、A5、D6、C三、略。
第三章整理与显示数据思考题答案1.因为收集的数据符合数据通常要求后,往往杂乱无章,不可用,所以有必要对数据进行整理。
2.比如市场营销专业。
为了解各种不同饮料在市场的占有率情况,于就是采用了问卷调查方法,得到相关的数据结果,整理成如下所示频数分布表与复式条形图来显示结果。
3.洛伦茨曲线的思想就是洛伦茨曲线图就是用人口累计率与收入累计率绘出散点图,并用平滑曲线来连接这些散点,以此来描述一国财富或收入分配状况的统计工具。
其一般为一条向下弯曲的曲线,偏离45度角直线越小,表明该社会收入分配状况的平等化程度越高,偏离45度角直线越大,表明该社会收入分配状况的平等化程度越低。
练习题参考答案一、单选题1.C2.D3.A二、简答题1、数值型数据的统计分组方法有两种,一种就是单变量值分组,一种就是组距分组。
单变量值分组就就是将一个变量值作为一组,总体中有几个不同的变量值就分几个组,适合于离散型变量,且适合变量值较少的情况。
组距式分组就是将变量值的一个区间作为一组,适合于连续变量与变量值较多的离散型变量情况。
2、(1)70应为第四组,因为就是遵循“上组限不在内”的原则。
70只能作为下限值放在第四组。
(2)91没有被分入组内,就是违背了“不重不漏”的原则。
三、实操题1、(1)上面数据属于分类型数据(2)频数分布表如下表所示:类别频数比例百分比(%)A 10 0、25 25B 9 0、225 22、5C 7 0、175 17、5D 6 0、15 15E 8 0、20 20(3)条形图如下所示饼图如下所示2、2、(1)Excel中得到的频数分布表贷款数分组频数频率(%) 向上累计频率(%)500以下 6 15 15500~1000 16 40 551000~1500 8 20 751500~2000 6 15 902000以上 4 10 100合计40 100 –(2)在Excel中绘制的频率直方图在Excel中绘制的累计频率分布图(3)钟型右偏分布。
3.最低温度的茎叶图最低温度Stem-and-Leaf PlotFrequency Stem& Leaf3、00 3 、7896、00 4、0023344、00 4 、56778、00 5 、000112332、00 5 、592、00 6 、134、00 6 、56781、00 7 、 4Stem width: 10Each leaf: 1 case(s)第四章数据分布的数字特征思考题参考答案1.典型案例5中解决问题的科学家就是日本质量管理学家田口玄一教授。
解决的结果就是:田口玄一教授发现:当产品质量数据服从以最佳位置m为中心的正态分布2[,(3)]N m T时,产品质量高。
T与2.3σ质量管理原则的基本思想: 3σ质量管理中的最佳位置m与平均数重合,3标准差重合,产品质量数据的分布与正态分布重合,此时的产品质量最高。
其中3σ质量代表了较高的对产品质量要求的符合性与较低的缺陷率。
它把产品质量值的期望作为目标,并且不断超越这种期望,企业从3σ开始,然后就是4σ、5σ、最终达到6σ。
对做人、做事的启示就是:找到做人或做事的最佳目标,然后尽一切努力不断地靠近此目标,从而达到最佳状态。
3.3σ质量管理原则大到能拯救与强大一个国家,小到能拯救与强大自己。
生活中,每个人都有自己的目标,目标或大或小,可能会有很多,但这些目标不可能全部实现,我们需要根据自己的实际情况选择一个合适的、最有可能实现的目标(最佳目标),然后尽一切努力,心无旁骛地、不断地靠近此目标,继而达到理想状态。
4.煮饭的水位有一个最佳刻度值(最优目标),水位越靠近这个刻度值,则煮出的饭口感越好;水位越远离这个刻度值,则煮出的饭口感越差。
即水位越向该刻度值(最优目标)靠拢则煮出的饭口感越好,这也体现了3σ质量管理原则的思想。
练习题参考答案一、单选题1.B2.C3.B4.D5.D6.C 二、判断题1.×2.×3.√4.√5.√ 三、计算题1、(1)161o M =;161.5eM =;160.27ix x n=≈∑(2)=7.54L n Q =位置;3=22.54U nQ =位置 153153167168=153;167.522L U Q Q ++∴===(3)9.06s =≈(4)因为就是单峰分布,且满足e x M <,所以该组数据近似左偏分布。
2、(1)因为该题中产品销售额与销售利润两组数据的变量值水平不同,所以比较产品销售额与销售利润的差异应该选用离散系数这个统计量。
(2)因为1584ixx n ==∑;1290.91s =≈238.21ix x n==∑;224.02s =≈所以 111290.910.4981584s s v x ==≈ 22224.020.628638.21s s v x ==≈因为12s s v v <,所以销售利润这组数据的差异大。
3、(1)假定数据对称分布,判断数据的百分比问题应该用经验法则。
因为新员工的平均得分就是85分,标准差就是5分,所以可以判断75~95分正好对应着均值±2倍的标准差范围,根据经验法则可知大约有95%的数据落在此范围内。
(2)假定员工得分的分布未知,判断数据的百分比问题应该用切比雪夫不等式。
因为新员工的平均得分就是85分,标准差就是5分,所以可以判断75~95分正好对应着均值±2倍的标准差范围,根据切比雪夫不等式(21-1k,其中k 为标准差前的倍数)可知至少有75%的数据落在此范围内。
4.根据题意,应用标准分数来比较。
第一学期小明微积分的标准分数:;2570801111=-=-=s x x z 第二学期小明微积分的标准分数:;5.11065802222=-=-=s x x z 因为21z z >,所以小明第一学期的微积分成绩更理想。
5、(1)84400105580i iix fx f===∑∑甲 85000106380i i ix f x f ===∑∑乙因为x x <甲乙,所以供应商乙的灯泡寿命更长。
(2)因为258.4765s =≈甲261.6283s =≈乙所以258.47650.24501055s s v x ==≈甲甲甲261.62830.24611063s s v x ==≈乙乙乙因为s s v v <甲乙,所以可知供应商甲灯泡寿命更稳定。
(3)因为就是分组数据,所以偏态系数0262.098.1726885045225033-≈-=s a SK =甲 1553.05.1790829125.278203133≈=s a SK =乙峰态系数6940.034463593014510292898123-44-≈-=s a K =甲0109.034685315855314005004883-44-≈-=sa K =乙 (4)从(3)可知:00262.0<-≈甲SK ,可知供应商甲的灯泡使用寿命分布就是左偏分布,但偏斜程度较小;01553.0>≈乙SK ,可知供应商乙的灯泡使用寿命分布就是右偏分布,但由于SK SK >乙甲,所以供应商乙灯泡寿命的偏斜程度比供应商甲的要大;06940.0<-≈甲K ,可知数据就是扁平分布,即数据较分散;00109.0<-≈乙K ,可知数据就是扁平分布,但因乙甲K K <,所以供应商甲的灯泡寿命分布要比乙的分散。