25列联表的独立性检验
- 格式:ppt
- 大小:1.01 MB
- 文档页数:36





独立性检验基本思想及应用独立性检验是一种用于确定两个变量之间是否存在关联的统计方法。
其基本思想是通过比较观察到的数据与预期的数据之间的差异来推断这两个变量之间的关系。
独立性检验的应用非常广泛。
在社会科学中,独立性检验常被用于研究两个分类变量之间是否存在关联,例如性别和职业、教育水平和政治倾向等。
在医学研究中,独立性检验也可以用来检查某种治疗方法是否与疾病的发展有关,以及风险因素和某种疾病之间的关系。
此外,独立性检验还被广泛应用于市场调查、品牌定位以及质量控制等领域。
独立性检验的基本思想是建立一个零假设(H0)和一个备择假设(H1)。
零假设认为两个变量是独立的,即它们之间没有关联;备择假设则认为两个变量之间存在关联。
独立性检验的步骤可以分为以下几步:1. 收集数据:需要收集两个分类变量的数据,例如通过问卷调查或观察获得数据。
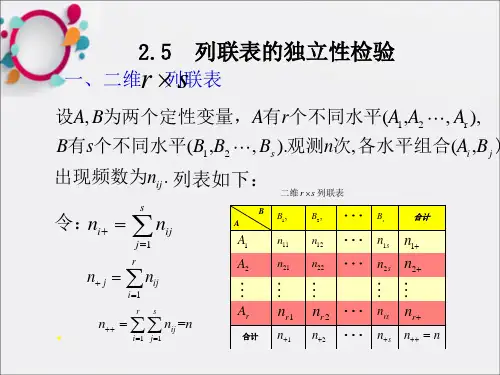
2. 建立列联表:将数据整理成列联表形式,列联表是一种用于描述两个或多个分类变量之间关系的矩阵。
表格的行表示一个变量的不同类别,列表示另一个变量的不同类别,表格中的每个单元格表示两个类别的交叉数量。
3. 计算期望频数:在独立性检验中,我们假设两个变量是独立的,因此可以基于各类别的边际总数以及样本总数来计算期望频数。
期望频数是在两个变量独立情况下,各个类别的交叉数量。
4. 计算卡方统计量:卡方统计量用于衡量观察到的数据与期望数据之间的差异程度。
计算公式为:χ2 = Σ((观察频数- 期望频数)^2 / 期望频数)。
其中,Σ表示对所有单元格进行求和。
5. 设定显著性水平:显著性水平α为决策的临界点,用于决定是否拒绝零假设。
通常,α的常见选择为0.05或0.01。
6. 判断和解释结果:根据计算出的卡方统计量与临界值进行比较,如果计算出的卡方值大于临界值,拒绝零假设,认为两个变量之间存在关联;反之,接受零假设,认为两个变量是独立的。
独立性检验的结果常常以卡方统计量和p值的形式呈现。
p值是在零假设成立的条件下,观察到的数据与期望数据之间差异的概率。





独⽴性检验(卡⽅检验)
独⽴性检验(Test for Independence)是根据频数来判断两类因⼦是彼此独⽴还是彼此相关的⼀种假设检验。
假如对某⼀个数据集有X(值域为x1, x2)跟Y(值域为y1, y2)变量,下⾯是他们的频数表:
x1x2汇总
y1a b a+b
y2c d c+d
汇总a+c b+d n = a+b+c+d
我们可以使⽤独⽴性检验来了解变量x与y是否有关系,并且能较准确的给出这种判断的可靠程度。
具体做法是由上⾯的频数表计算出随机变量K2的值:
其中K⽅的值越⼤,说明变量X与变量Y有关系的可能性越⼤。
当频数表中a、b、c、d的值都不⼩于5的时候,可以查阅下表来确定“X与Y有关系”的可信程度:
P(K^2≥k)0.50.40.250.150.1
k0.4550.708 1.323 2.072 2.706
P(K^2≥k)0.050.0250.010.0050.001
k 3.841 5.024 6.6357.87910.828
我们为什么不能只凭列联表中的数据和由其绘出的图形得出两个变量是否有关系的结论呢?由列联表可以粗略地估计出两个变量(两类对象)是否有关(即粗略地进⾏独⽴性检验),但2×2列联表中的数据是样本数据,它只是总体的代表,具有随机性,故需要⽤独⽴性检验的⽅法确认所得结论在多⼤程度上适⽤于总体。
列联表的两种抽样模型以及齐性和独立性的检验问题禹建奇(桂林理工大学理学院,广西桂林541004)摘要:本文讨论二维列联表数据的两种抽样模型,以及相关的齐性和独立性检验问题,说明两种抽样模型的联系,以及齐性及独立性检验的一致性.关键词:列联表;抽样模型;齐性;独立性检验中图分类号:G642.0文献标志码:A文章编号:1674-9324(2015)14-0071-02作者在讲授统计课程时,经常会遇到列联表的齐性和独立性检验问题,这两个问题分别牵涉到两种抽样方式,但两种检验的检验统计量与结果却是一样的.大多数教材,如吴喜之、赵博娟所著《非参数统计》,只是简单指出两种抽样方式的不同,两种检验的一致性只是殊途同归,巧合而已.本文论证了这两种模型的联系,导出两种检验的一致性,可见,这种一致性绝不是巧合.一、乘积多项分布模型与整体多项分布模型首先我们来看两个二位列联表的例子(摘自吴喜之、赵博娟所著《非参数统计》第八章).例1对于某种疾病有三种处理方法,某医疗机构分别对22,15和19个病人用这三种方法处理,处理的结果分“改善”和“没有改善”两种,并且列在下表中:问:不同处理的改善比例是不是一样?例2在一个有三个主要百货商场的商贸中心,调查者问479个不同年龄段的人首先去三个商场中的哪一个,结果如下:问:人们对这三个商场的选择和他们的年龄是否独立?这两个例子的数据都有下面的两因子列联表形式:这里,每个格子的频数n ij 为随机变量,行频数总和n i •=∑j n ij ,列频数总和n •j =∑i n ij ,频数总和n ••=∑i n i •=∑j n •j ,A 1,A 2,…,A r 为行因子的r 个水平,B 1,B 2,…,B c 为列因子的c 个水平.用p ij 表示第ij 个格子频数占总频数的理论比例(概率).显然,p ij =E (n ij )/n ••,这里E (n ij )为n ij的数学期望,而相应的第i 行的理论比例(概率)p i •及第j 列的理论比例(概率)p •j 分别为p i •=∑j p ij ,p •j =∑i p ij •对于例1代表的那一类问题,要检验的是每行分布的齐性(homogeneity ).一般来说,对齐性的检验就是检验H 0:“对所有行,给定行的条件列概率相同.”记给定第i 行后第j 列的条件概率为p j|i =p ij p i •,零假设则为H 0∶p j|i =p j|i *=,∀j ,i ≠i *.而备选假设为H 1“零假设中的等式至少有一个不成立.”在零假设下,条件概率p j|i 与i 无关,我们可以记该条件概率为p j ,则p •j =∑i p ij =∑i p i •p j|i =∑i p i .p j =p j ∑i p i .=p j ,零假设即为H 0∶p j|i =p •j ,∀j ,i对于例1的具体问题,零假设为:“对于各种不同的处理,改善的比例或概率相同.”注意,这里因为只有两种结果,所以,对不同处理改善的比例相同就意味着对各种处理没有改善的比例也相同.这种关于齐性的检验的数据获取,一般都类似于例8.1,对行变量的每一水平i ,试验前选定一定数目(n i ·)的对象,然后在试验时观测并记录在列变量的不同水平所得到的相应频数.在零假设之下,第ij 个格子的期望值E ij =E (n ij )应该资助项目:本文获“桂林理工大学博士科研启动基金(2014)”支持作者简介:禹建奇(1970-),男,湖南邵阳人,数学博士,教师,研究方向:数理统计. All Rights Reserved.等于n i •p •j ,但p •j 未知,零假设下,可以用其估计p^•j =n •jn ••代替.这样期望值的估计值为E ^ij =n i •p ^•j =n i •n •j /n ••而第ij 个格子的实际频数为n ij ,故Pearson χ2统计量为Q=∑i ∑j (n ij -E ij )2E ij =∑i ∑j(n ij -n i •n •j n ••)2n i •n •j /n ••它在样本量较大时(E ij ≥5,∀i ,j )近似地服从自由度为(r-1)(c-1)的χ2分布.一般而言,对r ×c 的列联表,试验前先选定各行的总频数n i ·,再进行独立抽样,记录各个格子的频数,这样,每行的分布是一独立的多项分布P (n ij =o ij ,j=1.2.…,c )=n i •!n i1!n i2!…n ic !p 1|i n i1…p c|inic这里,o ij 是n ij 的观测值,p i|1,….p i|c 为给定行的条件概率.所以,整个列联表的分布为独立多项分布的乘积P (n ij =o ij ,j=1.2.…,c ,i=1.2.…,r )=∏ri=1n i •!∏ri=1∏cj=1n ij !∏ri=1∏cj=1p j|in ij这种抽样模型称列联表的乘积多项分布模型.而对于例2那一类问题,要检验的是行和列变量的独立性(INDEPENDENCE ).当行变量与列变量独立时,一个观测值分配到第ij 个格子的理论概率p ij 应该等于行列两个概率之积p i •p •j ,即零假设为H 0∶p ij =p i •p •j ,∀i ,j这时,在零假设下,它的估计值为p^ij =p ^i •p ^•j =n i •n ••n •j n ••,而第ij 个格子的期望值估计为E ^ij ≈n ••p ^ij =n i •n •j /n ••可以看到,这和前面检验齐性时零假设下的期望值一样,由此可以得到和上面检验齐性时导出的同样的统计量Q ,这样导出的Q 当然也有同样的渐近χ2分布.这类关于独立性的问题的数据获取,通常是随机选取一定数目的样本,然后记录这些个体分配到各个格子的数目(频数).它并不事先固定某变量各水平的观测对象数目,这和齐性问题有所区别.一般地,对r ×c 的列联表,试验前先选定总频数n ••,再进行独立抽样,记录n ••个对象落在各个格子的频数,这样,整个列联表的分布为一多项分布P (n ij =o ij ,j=1.2.…,c ,i=1.2.…,r )=∏ri=1n ••!∏ri=1∏cj=1n ij !∏r i=1∏c j=1p ijn ij这种抽样模型称列联表的整体多项分布模型.二、两种模型的联系如上所述,很多的统计教材也都指出,同一个列联表数据可以有两种抽样模型,而且对两种模型分别做齐性和独立性检验时,检验过程与结论完全一样,但是其中的缘由却未见说明.其实可以证明,这并不是巧合,它是下面两个定理的结果.定理一:齐性问题与独立性问题等价,即各行的齐性等价于行与列变量的独立性.证明:各行齐性,即对∀i ,j ,p j|i =p •j ,⇔p ij =p i •p j|i⇔p ij =p i •p •j ,即独立性定理二:在整体多项分布中,考虑固定各行总频数的条件概率,则得乘积多项分布.证明:整体多项分布即:P (n ij =o ij ,j=1.2.…,c ,i=1.2.…,r )=∏ri=1n ••!∏r i=1∏cj=1n ij !∏r i=1∏c j=1p ijn ij注意到n i •,i=1.2.…,r 的分布亦为一多项分布P (n i •=o i •,i=1.2.…,r )=n ••!∏r i=1n i •!∏ri=1p i •n i •可以得到,固定各行总频数的条件概率为:P (n ij =o ij ,j=1.2.…,c ,i=1.2.…,r|n i •=o i •,i=1.2.…,r )=P (n ij =o ij ,j=1.2.…,c ,i=1.2.…,r )P (n i •=o i •,i=1.2.…,r )=(n ••!∏r i=1∏c j=1n ij !∏r i=1∏c j=1p ij n ij)/(n ••!∏ri=1n i •!∏ri=1p i •n i •)=∏ri=1n i •!∏r i=1∏cj=1n ij !∏r i=1∏cj=1(p ij /p i •)nij=∏ri=1n i •!∏r i=1∏cj=1n ij !∏r i=1∏c j=1(p j|i )n ij三、最后结论整体抽样模型的独立性当然等价于固定各行总频数时的齐性,所以,综合可得以下结论:二维列联表的数据,可能来自两种不同的抽样模型:整体多项分布模型和乘积多项分布模型,但是两种模型其实是一致的,即乘积多项分布模型可以认为是整体多项分布模型在限定各行总频数的条件下的条件分布模型,同时由于齐性与独立性的等价,不论以何种模型分析同一个列联表的齐性或独立性,得到的结果是一样的.参考文献:[1]吴喜之,赵博娟.非参数统计[M].中国统计出版社,2013.[2]阿兰,阿格莱斯蒂.分类数据分析[M].重庆大学出版,2012.. All Rights Reserved.。