IPv6路由协议及重分发
- 格式:docx
- 大小:428.74 KB
- 文档页数:6


IPv6技术——路由协议IPv6 单播路由协议:IGP(Internal Gateway Protocol)EGP(External Gateway Protocol)IPv6 IGP主要有:1. RIPng是在RIP基础上开发的⽤于IPv6⽹络的路由协议,在⼯作机制上与RIP基本相同,是IPv6中基于距离向量的内部⽹关路由协议。
但为了⽀持IPv6地址格式,RIPng对RIP做了⼀些改动。
RIPng⼀般作为中等或者偏⼩规模的⽹络⾃治系统中的内部⽹关路由协议RIPng技术实现:通过UDP报⽂进⾏路由信息交换,使⽤端⼝号521发送和接收数据报。
特别的查询信息可以不从源节点端⼝521发出,但是必须发送到⽬标节点的端⼝521每个路由器都有接⼝连接⼀个或者多个⽹络(直连⽹络)。
RIP协议的实现依赖这些⽹络的相关信息。
包括⽬的地址前缀、前缀长度以及度量等。
RIPng使⽤跳数(hop count)作为度量(metric)。
RIPng⽹络的度量是1~15之间的整数,⼤于或等于16的跳数定义为⽆穷⼤,即⽬的⽹络或主机不可达。
RIP的启动和运⾏过程:RIPng与RIP的不同点报⽂格式不同。
RIPng有两类RTE:⽬的前缀RTE和下⼀跳RTE。
⽬的前缀RTE指明可达⽬的⽹络,下⼀跳RTE 为RIPng提供了直接指定下⼀跳IPv6地址的能⼒。
下⼀跳RTE指明的IPv6地址适⽤于跟随其后的⽬的前缀RTE,直到RIPng报⽂结束或者出现另⼀个下⼀跳RTE为⽌报⽂长度不同发送⽅式不同端⼝号不同安全机制不同OSPFv3OSPFv3是在OSPFv2基础上开发的⽤于IPv6⽹络的路由协议。
作为链路状态路由选择算法,其实现机制没有本质改变OSPFv3运⾏在IPv6⽹络中,它同OSPFv2并不兼容,但处理流程基本保持⼀致,eg:泛洪过程,DR选举。
对区域的⽀持以及SPF计算流程,OSPFv3只是在v2基础上进⾏了⼀些改进,以⽀持报⽂格式的变化并处理IPv6中128bit的地址OSPFv3和OSPFv2的不同点:OSPFv3在OSPFv2基础上做出了⼀些必要的改造,这些改进包括以下⼏⽅⾯链路概念取代⽹络概念OSPFv2是基于⽹络运⾏的,两个路由器要形成邻居关系必须在同⼀⽹段:OSPFv3的实现是基于链路的,同⼀链路不同⼦⽹上的节点也可以直接通话报⽂去除地址语义对于OSPFv3来说,除了LS Update报⽂载荷中存在地址以外,协议报⽂中不再提供地址信息;Router-LSA和Network-LSA中也不再包含⽹络地址;OSPF Router ID,区域ID和Link State ID仍然保留IPv4中32bit的长度,因此不能使⽤IPv6地址来代表这些信息增加泛洪范围LSA的泛洪范围已经被明确地定义在LSA的LS Type字段,⽬前有以下3种LSA泛洪范围:本链路范围:⽤于Link LSA;区域范围:⽤于Router LSA、Network LSA、Inter Area Prefix LSA、 Inter Area Router LSA和Intra Area Prefix LSA;⾃治域范围:⽤于AS-external-LSA 链路⽀持多实例复⽤link-local地址的使⽤IS-ISv6IS-ISv6可以同时承载IPv4和IPv6的路由信息,完全可以独⽴⽤于IPv4⽹络和IPv6⽹络。

ipv6协议的工作原理引言随着互联网的飞速发展和IP地址需求的激增,I Pv6协议作为下一代互联网协议,逐渐引起了广泛关注。
本文将详细介绍I Pv6协议的工作原理,包括地址结构、分片与重组、邻居发现、路由协议等方面的内容。
I P v6地址结构I P v6地址是由128位二进制数表示的,与I Pv4的32位地址相比,地址空间更加广阔。
I P v6地址由8组16进制数字组成,每组之间使用冒号分隔,例如:2001:0d b8:85a3:0000:0000:8a2e:0370:7334。
I P v6地址可以分为三种类型:单播地址、多播地址和任播地址,分别用于点对点通信、一对多通信和一对一通信。
I P v6分片与重组由于链路层M TU的限制,当IP v6数据包的大小超过链路层M TU时,需要将数据包进行分片。
分片由源主机完成,将数据包划分为适应MT U大小的分段,经过网络传输后再由目标主机进行重组。
与IP v4协议类似,I P v6分片也会增加网络开销,因此在网络设计中应尽量避免分片的发生。
I P v6邻居发现I P v6邻居发现是I Pv6网络中用于确定邻居设备IP v6地址与M AC地址的过程。
I Pv6邻居发现使用I CM Pv6报文实现,包括邻居请求和邻居应答两种类型。
邻居请求用于查询目标设备的MA C地址,邻居应答则是对邻居请求的响应。
这种机制可以有效解决I Pv6网络中链路层地址解析的问题。
I P v6路由协议I P v6使用路由协议来决定数据包从源主机到目标主机的转发路径。
常见的IP v6路由协议有R IP ng、O SP Fv3和B GP等。
这些协议基于不同的路由选择算法,通过交换网络拓扑信息,实现网络中路由器的动态路由更新和转发决策。
I P v6与I P v4过渡技术由于IP v6与I Pv4之间存在互不兼容性的问题,为了实现平稳过渡,提供双协议栈支持,出现了一系列的I Pv6与IP v4过渡技术。
IPv6路由协议及重分发配置用于IPv6的EIGRP使用全局命令ipv6 unicast-routing启用ipv6路由使用全局配置命令ipv6 router eigrp asn启用eigrp在接口上启用ipv6,配置方法同RIPng使用接口子命令ipv6 eigrp asn在接口上启用eigrp,指定的asn必须与全局命令一致在eigrp配置模式下,使用命令no shutdown 启用用于ipv6的eigrp如果没有自动选择eigrp路由器id,在eigrp配置模式下使用命令eigrp router-id rid配置一个eigrp路由器idIPv6的EIGRP通告有关接口上所有直连子网的信息,但链路本地地址和本地路由除外。
验证用于IPv6的EIGRPOSPF第3版比较OSPFv2和OSPFv3说明:OSPFv3不要求邻接路由器必须位于同一个子网才能成为邻居OSPFv3支持在一条链路上使用多个OSPF实例,而OSPFv2只允许每条链路使用一个实例使用邻居的链路本地IPv6地址用于下一跳地址ospfv3必须有RID才能工作配置OSPFv3下一代RIPRIPng--理念及其与RIP-2的比较由于IPv6使用IPSec身份验证报头(AH)来支持身份验证,因此RIPng本身不支持身份验证,而依赖于IPSec进行身份验证配置RIPngRIPng基本配置步骤:使用全局命令ipv6 unicast-routing启用ipv6路由。
如果不配置此命令,将不能配置RIPng使用全局配置命令ipv6 router rip name启用RIPng.指定的名称必须在当前路由器中是唯一的,但不必与邻接路由器使用的名称相同在接口上启用IPv6.方法一:使用接口命令ipv6 address address/prefix-length [eui-64]给接口配置一个ipv6单播地址。
方法二:配置命令ipv6 enable.如果不配置此步,将不能在接口上启用RIPng.使用接口子命令ipv6 rip name enable在接口上启用RIP,其中的名称必须与全局配置命令指定的名称相同。


运营商ipv6分发机制
运营商的IPv6分发机制是确保网络地址的唯一性和可扩展性的重要环节。
IPv6地址由128位二进制数字组成,与IPv4相比,提供了更为丰富的地址空间。
运营商在分发IPv6地址时,主要遵循以下几个方面的机制:
首先,IPv6地址的分配是基于网络的规模、拓扑结构、服务要求和用户数量等因素进行的。
运营商会根据自己的网络架构和服务需求,将IPv6地址空间划分为不同的块,然后分配给各个网络节点。
其次,IPv6地址的分配方式主要有两种:通过固定长度的前缀来确定网络标识,以及通过DHCPv6(动态主机配置协议第6版)来分配IPv6地址。
固定长度前缀的方式适用于大型网络,运营商会分配一个固定的前缀给网络,然后由网络内部的设备根据这个前缀生成具体的IPv6地址。
而DHCPv6则适用于中小型网络,它可以动态地为设备分配IPv6地址,简化了地址管理的复杂性。
此外,IPv6地址的分配还涉及到地址的唯一性和可持续性问题。
为了确保地址的唯一性,运营商会采用全球唯一的地址分配策略,避免地址冲突。
同时,运营商还会考虑地址的可持续性,避免地址资源的浪费和过度消耗。
最后,IPv6地址的分配还需要考虑地址的安全性和隐私保护问题。
运营商会采取一系列的安全措施,如加密、认证等,确保IPv6地址的分配和使用过程中数据的安全性和隐私性。
综上所述,运营商的IPv6分发机制是一个复杂而精细的过程,需要考虑到多个方面的因素。
通过合理的地址分配和管理策略,运营商可以确保IPv6地址的唯一性、可扩展性、安全性和可持续性,为网络的发展提供坚实的基础。

路由重分发的基本概念在计算机网络中,路由器是用于转发网络数据包的设备。
路由器根据目的地地址将数据包从一个网络接口转发到另一个网络接口,以便将数据从源主机传输到目标主机。
如果网络结构发生改变或者某个路径出现故障,路由器就需要重新分发路由信息,以便确保数据能够正确地到达目标主机。
下面是路由重分发的基本概念。
路由重分发是指将新的路由信息通知给其它路由器,以便它们能够将数据包转发到正确的目标。
当网络拓扑发生改变时,例如有一条链路故障或者新增了一条链路,路由重分发就需要被执行。
在路由重分发的过程中,路由器会发送路由更新消息给其它路由器,以便让它们更新它们的路由表。
这样,当一个数据包到达网络时,路由器就可以根据最新的路由表将其正确地转发到目标主机。
路由器可以采用不同的路由协议来执行路由重分发。
常用的路由协议包括距离向量路由协议和链路状态路由协议。
距离向量路由协议根据最短距离确定最佳路径,并向其它路由器发送这些路径的距离信息。
当一条路径不可用时,路由器会从其它可能的路径中选择一个最佳路径,然后向其它路由器发送更新消息。
链路状态路由协议则根据网络中各链路的状态动态计算出路由信息。
当网络结构发生改变时,路由器会重新计算路由信息并通知其它路由器。
在执行路由重分发之前,路由器通常会先删除旧的路由信息。
这样可以避免新的路由信息和旧的路由信息冲突,导致数据包被错误地转发。
当路由重分发完成后,路由器会重新建立路由信息表。
新的路由表将包含最新的路由信息,以便将数据包正确地转发到目标主机。
总之,路由重分发是计算机网络中维护路由信息的重要过程。
它可以确保数据包能够正确地到达目标主机,同时避免了路由信息的冲突。
在实际应用中,路由重分发的频率对网络的性能有重要影响。
如果路由重分发太频繁,会导致网络负载过大,从而降低网络的吞吐量。
因此,在设计网络拓扑时,需要仔细考虑路由重分发的频率,并采取相应的措施来保证网络的高效稳定运行。

IP报⽂的分⽚与重组(ipv6)
总论:
IPv6的分⽚处理只在作为起点的发送端主机上进⾏,中间路由器不参与分⽚,可以减少路由器的负担,提⾼⽹速,所以呢,IPv6中的路径MTU发现功能必不可少,不过IPv6最⼩MTU为1280字节。
IPv6关于分⽚最主要的改变就是分⽚只在端主机上进⾏,中间⽹络只负责转发,上⼀篇中IPv4关于分⽚的16⽐特的Identification和3⽐特的Flags字段在IPv6中都没有了,IPv6的标准头⾸部长度是固定的40字节,Ipv6中的分⽚信息放在了IPv6的扩展⾸部⾥
关于何时Ipv6报⽂需要分⽚:
1. skb的长度⼤于PMTU发现的mtu值
2. 本地链路mtu⼩于1280字节
3. skb分⽚中的最⼤分⽚长度⼤于PMTU发现的mtu值
IPv6部分⾸部:
流标号-Flow Label
20⽐特,准备⽤于QoS
有效载荷长度-Payload Length
这16⽐特指的是包的数据部分,⽽不是像IPv4中的Total Length指包括⾸部在内的所有长度
下⼀个⾸部-Next Header
相当于IPv4中的协议字段,共8⽐特,通常表⽰IP的上⼀层是什么协议,⼀般为UDP,TCP,不过当IPv6有扩展⾸部的时候,该字段表⽰后⾯第⼀个扩展⾸部的协议类型
跳数限制-Hop Limit
8⽐特,就是IPv4中的TTL
IPv6扩展⾸部
扩展⾸部通常位于IPv6⾸部和TCP/UDP⾸部中间,且扩展⾸部没有长度限制,⽐如需要对IPv6的数据进⾏分⽚时,可以设置扩展域为
44(IPv6-Frag)。

IPv6的分片重组流程是一个涉及源节点分片和目的节点重组的过程,中间节点路由器只负责转发,不再进行分片或重组。
以下是IPv6分片重组流程的详细步骤:1. 路径MTU发现:源节点首先通过路径MTU发现机制(PMTUD)确定到目的节点的路径上的最大传输单元(MTU)。
如果源节点要发送的数据包大小超过了这个MTU,那么就需要进行分片。
2. 源节点分片:源节点将数据包分为两个部分:不可分片部分和可分片部分。
不可分片部分包括IPv6基本头部和必须由中间节点路由器处理的扩展头部(如路由头部之前的所有头部)。
可分片部分包括其他扩展头部和上层数据(如TCP或UDP数据)。
源节点根据MTU大小将可分片部分切割成若干个分片数据包,每个分片数据包的大小为8 octets(64位)的整数倍。
3. 分片数据包的构造:每个分片数据包包含不可分片部分、Fragment Header(扩展头部,类型值为44)和分片数据。
Fragment Header包含以下字段:Next Header:标识源数据包中可分片部分的数据首部类型。
Reserved:保留字段,初始化为零。
Fragment Offset:13位字段,表示分片数据在原始数据包中的位置,以8 octets为单位。
Res:保留位,初始化为零。
M flag:表示更多分片的标志,0表示最后一个分片,1表示还有更多分片。
Identification:用于标识属于同一个源数据包的所有分片,确保目的节点可以正确重组数据包。
4. 分片数据包的发送:源节点将这些分片数据包发送到网络中,它们独立地通过网络传输到目的节点。
5. 中间节点的处理:中间节点路由器仅对分片数据包进行转发,不进行重组或进一步分片。
如果收到的分片数据包大小仍然超过下一跳的MTU,路由器会发送ICMPv6的Packet Too Big消息给源节点,告知其MTU大小。
6. 目的节点重组:目的节点收到所有分片数据包后,根据源地址、目的地址、Identification和Fragment Offset等信息,将分片数据包正确排序和重组。

ipv6路由协议栈原理与技术IPv6路由协议栈是一种用于在IPv6网络中进行路由选择和转发的程序集合。
它通常由一系列协议组成,包括路由协议、转发协议和管理协议。
以下是IPv6路由协议栈的原理和技术:1. 路由协议:IPv6路由协议用于在路由器之间交换路由信息,以确定最佳路径和目的地对于数据包的下一跳。
常用的IPv6路由协议包括OSPFv3(开放最短路径优先),RIPng(路由信息协议下一代),ISIS和BGP。
2. 转发协议:IPv6转发协议用于在单个路由器内的转发决策。
它根据接口上的目的地地址和路由表中的路由信息选择最佳的输出接口。
常用的IPv6转发协议包括IP(Internet协议),ICMPv6(Internet控制消息协议下一代)和NDP(邻居发现协议)。
3. 管理协议:IPv6管理协议用于配置和监视IPv6网络。
其中包括DHCPv6(动态主机配置协议下一代)用于自动配置IPv6地址,SLAAC(无状态地址自动配置)用于提供IPv6地址的自治配置,以及SNMPv3(简单网络管理协议下一代)用于监视和管理网络设备。
IPv6路由协议栈的工作原理如下:1. 当一个IPv6数据包到达路由器,路由协议会根据路由表中的路由信息选择最佳路径和目的地对于数据包的下一跳。
2. 转发协议根据接口上的目的地地址和路由表中的信息选择最佳的输出接口,并将数据包发送到该接口。
3. 如果目的地地址时本地链路的一部分,邻居发现协议会寻找目的地地址的MAC地址,并将数据包直接转发到相应的接口。
4. 管理协议用于配置和监视IPv6网络设备,以确保网络的正常运行。
通过使用IPv6路由协议栈,IPv6网络可以实现可靠的路由选择和转发,并提供更好的性能和安全性。

ipv6通信流程IPv6通信流程1. 概述本文将详细介绍IPv6通信流程,包括地址分配、路由选择和数据传输等关键流程。
IPv6是下一代互联网协议,为解决IPv4的地址枯竭问题而诞生。
它比IPv4具有更大的地址空间、更好的安全性和性能优化等特点。
2. 地址分配IPv6地址由128位二进制数字表示,采用8组4位十六进制数表示。
地址分配主要有两种方式:静态分配静态分配是由网络管理员手动为每个设备分配固定的IPv6地址。
这种方式适用于重要的服务器和网络设备,可以提供更好的安全性和可追踪性。
动态分配动态分配是使用DHCPv6协议自动为设备分配IPv6地址。
DHCPv6服务器在网络上提供地址池,当设备连接到网络时,自动从地址池中获取可用地址。
这种方式适用于普通用户设备,方便管理和维护。
3. 路由选择IPv6路由选择基于路由表来确定最佳路径发送数据包。
路由选择过程如下:邻居发现邻居发现是IPv6设备在同一链路上自动发现并识别其邻居设备的过程。
设备通过发送邻居请求和邻居响应消息来获取邻居设备的地址。
路由广播路由广播是路由器在网络中广播路由信息的过程。
路由器使用ICMPv6协议发送路由通告消息,以便其他设备学习到可达目的地的路由信息。
路由选择算法路由选择算法根据路由器收到的路由信息,计算出最佳路径并更新路由表。
常用的路由选择算法有距离矢量路由选择协议(Distance Vector Routing Protocol)和链路状态路由选择协议(Link State Routing Protocol)。
4. 数据传输IPv6数据传输过程如下:封装数据包发送方将待传输的数据封装成IPv6数据包。
数据包包含发送方和接收方的IPv6地址、数据内容和其他必要的控制信息。
寻找下一跳发送方根据目标IPv6地址查询路由表,确定下一跳路由器的地址。
数据传输数据包通过网络依次传输到下一跳路由器,直至到达目标设备。
每个路由器根据转发表将数据包转发到下一跳,直至数据包到达目标网络。
IPv6协议协议名称:IPv6协议一、协议目的IPv6协议旨在解决因IPv4地址枯竭而带来的问题,并提供更加可靠、高效和安全的互联网通信。
本协议的目的是确保全球互联网的可持续发展,为网络设备提供唯一的全球标识,并支持更多的网络连接和地址分配。
二、协议范围本协议适用于所有使用IPv6协议的网络设备、互联网服务提供商和网络运营商。
协议内容包括IPv6地址分配、路由协议、安全性和隐私保护等方面的规定。
三、协议内容1. IPv6地址分配1.1 IPv6地址格式IPv6地址由128位二进制数字表示,采用8个16进制数(每个数占16位)表示,以冒号分隔。
例如,2001:0db8:85a3:0000:0000:8a2e:0370:7334。
1.2 IPv6地址分配原则1.2.1 为每个网络设备分配唯一的IPv6地址。
1.2.2 鼓励使用自动化机制进行IPv6地址分配,如动态主机配置协议(DHCPv6)或IPv6前缀发现协议(SLAAC)。
1.2.3 提供足够的IPv6地址资源以满足未来互联网的发展需求。
2. 路由协议2.1 路由选择算法2.1.1 支持基于最短路径优先(SPF)的路由选择算法。
2.1.2 支持多路径选择,以提高网络的容错性和负载均衡能力。
2.2 路由信息协议2.2.1 支持动态路由协议,如开放最短路径优先(OSPF)和边界网关协议(BGP)。
2.2.2 提供路由信息的自动传播机制,确保网络中的路由表保持最新和一致。
3. 安全性和隐私保护3.1 IPsec协议3.1.1 支持IPsec协议,提供数据的加密、认证和完整性保护。
3.1.2 强制要求网络设备支持IPsec协议,并提供配置和管理接口。
3.2 地址隐私3.2.1 提供随机化的IPv6地址生成机制,以保护用户的隐私。
3.2.2 支持临时IPv6地址和固定IPv6地址的使用,用户可以根据需求选择合适的地址类型。
四、协议实施1. 各网络设备制造商、互联网服务提供商和网络运营商应遵守本协议的规定,并在其产品或服务中实施IPv6协议。
第40章ipv6单播路由配置本章主要介绍如何使用几种主流的路由协议实现IPv6网络互联。
路由协议主要分为内部网关协议(IGP)和外部网关协议(EGP)两大类。
我们一般会将整个大的路由域分割成多个自治区域(AS),区域内部的路由学习通过内部网关协议(IGP)来完成,区域之间的路由学习通过外部网关协议(EGP)来完成。
内部网关协议(IGP)根据算法分为两类,一类是距离矢量算法(Distance-Vector)路由协议,一类是最短路径优先算法(SPF)路由协议。
本章主要内容:●配置IPv6 静态路由●配置IPv6 RIPng动态路由●配置IPv6 OSPFv3动态路由●配置IPv6 IS-IS动态路由●配置IPv6 BGP动态路由40.1配置IPv6 静态路由本节主要内容:●IPv6静态路由简介●IPv6静态路由基本指令描述●IPv6静态路由应用实例●IPv6静态路由监控和调试40.1.1IPv6静态路由简介同IPv4的静态路由相似,IPv6的静态路由也是由用户手动配置的路由,它是在IPv6源和目的之间传输IPv6包采用用户已指定路径。
40.1.2IPv6静态路由基本指令描述命令描述前带“*”符号的表示该命令有配置实例详细说明。
⏹ipv6 route命令在全局模式下用ipv6 route 命令建立IPv6静态路由,使用本命令的no格式删除已配置的IPv6静态路由。
ipv6 route destination-prefix {nexthop-ipv6-address | interface-name [nexthop-linklocal-address]} [name nexthop-name] [tag tag-value] [track track-id] [administrative-distance]no ipv6 route destination-prefix{nexthop-ipv6-address| interface-name} [name nexthop-name] [tag tag-value] [track track-id] [administrative-distance]语法描述destination-prefix IPv6目的前缀nexthop-ipv6-address 下一跳IPv6 地址interface-name 转发的接口名nexthop-linklocal-address 下一跳link-local地址nexthop-name 下一跳的描述字符tag-value 静态路由关联的tag值,取值1~4294967295track-id 静态路由关联的track ID值,取值1~500administrative-distance 管理距离,取值1~255【缺省情况】无IPv6静态路由配置40.1.3 IPv6静态路由应用实例PC-1PC-23::2/64图 40-1 IPv6静态路由配置示例图解:两台迈普交换机switch-a 和switch-b ,作为转发设备,连接了1::/64和3::/64两个网络。
ØRIPng协议ØOSPFv3协议ØIPv6路由协议配置流程ØIPv6路由协议配置命令•随着IPv6网络的建设,同样需要部署动态路由协议来完成IPv6路由的学习。
•RIPng、OSPFv3延续了其IPv4版本的基本原理和功能,并进行了改良和设计。
它们在IPv6网络中的部署实现上与IPv4网络存在着一些区别。
•本次任务介绍RIPng、OSPFv3协议的基本原理和配置方法。
ØRIPng是一种较为简单的内部网关协议,主要用于规模较小的网络中,由于RIPng的实现较为简单,在配置和维护管理方面较其它IPv6动态路由协议更加容易,因此在实际组网中仍有广泛的应用。
ØRIPng与RIPv2的区别•UDP端口:使用UDP的521端口发送和接收路由信息。
•源地址:使用链路本地地址FE80::/10作为源地址发送RIPng路由信息更新报文。
•组播地址:使用FF02::9作为链路本地范围内的路由器组播地址,周期性地发送路由信息。
•前缀长度:目的地址使用128比特的前缀长度。
•下一跳地址:使用128比特的IPv6地址作为下一跳地址。
•安全性:RIPng没有安全认证机制,存在安全隐患。
ØRIPng工作机制RIPng运行机制与RIPv2基本相同,表现在:•RIPng同样基于距离矢量算法计算路由。
使用跳数来衡量到达目的网络的距离,当跳数大于15时,目的网络或主机不可达。
•RIPng具有路由更新计时器(30s)、老化计时器(180s)和垃圾回收计时器(120s)。
各计时器的时限与RIPv2相同。
•RIPng具备防环机制,如水平分割、毒性逆转等。
•RIPng支持修改度量值、优先级来实现路由选路。
•RIPng支持抑制接口、路由重分发等功能来控制路由信息的发布。
ØOSPFv3是运行于IPv6的OSPF路由协议,在OSPFv2的基础上进行了增强,对内部路由器信息进行了重新设计,改良为一种独立于任何具体网络层的路由协议。
ipv6分片重组流程## English Answer:IPv6 Fragmentation and Reassembly Process.IPv6 fragmentation and reassembly is the process of breaking down an IPv6 packet that is larger than the maximum transmission unit (MTU) of a link into smaller fragments and then reassembling them at the destination. Fragmentation occurs when a router encounters an IPv6 packet that is too large to fit on the outgoing link. The router then breaks the packet into smaller fragments, each of which has a maximum size of 1280 bytes. The fragments are then sent independently to the destination.At the destination, the fragments are reassembled into the original packet. The reassembly process is handled by the IPv6 stack on the destination host. The IPv6 stack uses the Fragment Header field in the IPv6 header to identify the fragments that belong to the same packet. The FragmentHeader field contains the following information:Fragment Offset: The offset of the fragment within the original packet, in 8-byte units.More Fragments Flag: A flag that indicates whether the fragment is the last fragment in the packet.The IPv6 stack on the destination host uses the Fragment Offset field to order the fragments and the More Fragments Flag to identify the last fragment. Once all of the fragments have been received, the IPv6 stack reassembles them into the original packet.Benefits of Fragmentation.Fragmentation has several benefits, including:Increased network throughput: Fragmentation can help to increase network throughput by reducing the number of retransmissions. When a large packet is fragmented, the fragments are more likely to be transmitted successfullythan the original packet. This is because the fragments are smaller and are therefore less likely to be dropped due to errors.Reduced link utilization: Fragmentation can help to reduce link utilization by reducing the size of the packets that are transmitted. This can help to improve network performance and reduce congestion.Drawbacks of Fragmentation.Fragmentation also has several drawbacks, including:Increased processing overhead: Fragmentation can increase the processing overhead on routers and other network devices. This is because routers must fragment packets and reassemble fragments, which can be a time-consuming process.Increased latency: Fragmentation can increase the latency of packets. This is because fragments must be reassembled at the destination, which can add delay to thetransmission.## 中文回答:IPv6 分片重组流程。
路由协议重分发设备接口Ip地址子网掩码R1 F0/0 192.168.1.1 255.255.255.0Loopback 0 1.1.1.1 255.255.255.0 R2 F1/0 192.168.2.1 255.255.255.0Loopback 0 2.2.2.2 255.255.255.0 R3 F0/0 192.168.3.1 255.255.255.0Loopback 0 3.3.3.3 255.255.255.0 R4 F0/0 192.168.1.2 255.255.255.0F1/0 192.168.2.2 255.255.255.0F6/0 192.168.3.2 255.255.255.01.路由器的基本配置R1Router>Router>enableRouter#conf tRouter(config)#hostname R1R1(config)#int f0/0R1(config-if)#ip add 192.168.1.1 255.255.255.0R1(config-if)#no shutR1(config-if)#exitR1(config)#int lR1(config)#int loopback 0R1(config-if)#ip add 1.1.1.1 255.255.255.0R1(config-if)#no shutR1(config-if)#exitR1(config)#R2Router>Router>enableRouter#conf tRouter(config)#hostname R2R2(config)#int f1/0R2(config-if)#ip add 192.168.2.1 255.255.255.0 R2(config-if)#no shutR2(config-if)#exitR2(config)#int loopback 0R2(config-if)#ip add 2.2.2.2 255.255.255.0R2(config)#R3Router>enableRouter#conf tRouter(config)#hostname R3R3(config)#int f0/0R3(config-if)#ip add 192.168.3.1 255.255.255.0 R3(config-if)#no shutR3(config-if)#exitR3(config)#int lR3(config)#int loopback 0R3(config-if)#ip add 3.3.3.3 255.255.255.0R3(config-if)#exitR3(config)#R4Router>enableRouter#conf tRouter(config)#hostname R4R4(config)#int f0/0R4(config-if)#ip ad 192.168.1.2 255.255.255.0 R4(config-if)#no shutR4(config-if)#exitR4(config)#int f1/0R4(config-if)#ip add 192.168.2.2 255.255.255.0 R4(config-if)#no shutR4(config-if)#exitR4(config)#int f6/0R4(config-if)#ip add 192.168.3.2 255.255.255.0R4(config-if)#no shutR4(config-if)#exitR4(config)#2.配置路由器协议R1:RIP协议R1(config)#router ripR1(config-router)#version 2R1(config-router)#no auto-summaryR1(config-router)#net 192.168.1.0R1(config-router)#net 1.1.1.1R1(config-router)#exitR2:OSPF协议R2(config)#router ospf 1R2(config-router)#network 192.168.2.0 0.0.0.255 area 0 R2(config-router)#network 2.2.2.0 0.0.0.255 area 0R2(config-router)#exitR3:EIGRP协议R3(config)#router eigrp 1R3(config-router)#no auto-summaryR3(config-router)#network 192.168.3.0R3(config-router)#network 3.3.3.0R3(config-router)#exitR4:RIPR4(config)#router ripR4(config-router)#version 2R4(config-router)#no auto-summaryR4(config-router)#network 192.168.1.0R4(config-router)#exitOSPFR4(config)#router ospf 1R4(config-router)#net 192.168.2.0 0.0.0.255 aR4(config-router)#net 192.168.2.0 0.0.0.255 area 0R4(config-router)#exitEIGRPR4(config)#router eigrp 1R4(config-router)#no auto-summaryR4(config-router)#network 192.168.3.0R4(config-router)#exitR4(config)#测试R4#show ip routeCodes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGPi - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area* - candidate default, U - per-user static route, o - ODRP - periodic downloaded static routeGateway of last resort is not set1.0.0.0/24 is subnetted, 1 subnetsR 1.1.1.0 [120/1] via 192.168.1.1, 00:00:02, FastEthernet0/02.0.0.0/32 is subnetted, 1 subnetsO 2.2.2.2 [110/2] via 192.168.2.1, 00:01:10, FastEthernet1/03.0.0.0/24 is subnetted, 1 subnetsD 3.3.3.0 [90/] via 192.168.3.1, 00:00:55, FastEthernet6/0C 192.168.1.0/24 is directly connected, FastEthernet0/0C 192.168.2.0/24 is directly connected, FastEthernet1/0C 192.168.3.0/24 is directly connected, FastEthernet6/0R4#配置路由协议重分发RIPR4(config)#router ripR4(config-router)#redistribute ospf 1 metric 3R4(config-router)#redistribute eigrp 1 metric 3R4(config-router)#exitR1#show ip routeCodes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGPi - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area* - candidate default, U - per-user static route, o - ODRP - periodic downloaded static routeGateway of last resort is not set1.0.0.0/24 is subnetted, 1 subnetsC 1.1.1.0 is directly connected, Loopback02.0.0.0/32 is subnetted, 1 subnetsR 2.2.2.2 [120/3] via 192.168.1.2, 00:00:11, FastEthernet0/03.0.0.0/24 is subnetted, 1 subnetsR 3.3.3.0 [120/3] via 192.168.1.2, 00:00:11, FastEthernet0/0C 192.168.1.0/24 is directly connected, FastEthernet0/0R 192.168.2.0/24 [120/3] via 192.168.1.2, 00:00:11, FastEthernet0/0R 192.168.3.0/24 [120/3] via 192.168.1.2, 00:00:11, FastEthernet0/0R1#OSPFR4(config)#router ospf 1R4(config-router)#redistribute rip subnetsR4(config-router)#redistribute eigrp 1 subnetsR4(config-router)#R2#show ip routeCodes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGPi - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area* - candidate default, U - per-user static route, o - ODRP - periodic downloaded static routeGateway of last resort is not set1.0.0.0/24 is subnetted, 1 subnetsO E2 1.1.1.0 [110/20] via 192.168.2.2, 00:00:40, FastEthernet1/02.0.0.0/24 is subnetted, 1 subnetsC 2.2.2.0 is directly connected, Loopback03.0.0.0/24 is subnetted, 1 subnetsO E2 3.3.3.0 [110/20] via 192.168.2.2, 00:00:29, FastEthernet1/0O E2 192.168.1.0/24 [110/20] via 192.168.2.2, 00:00:40, FastEthernet1/0C 192.168.2.0/24 is directly connected, FastEthernet1/0O E2 192.168.3.0/24 [110/20] via 192.168.2.2, 00:00:29, FastEthernet1/0 EIGRPR4(config)#router eigrp 1R4(config-router)#redistribute rip metric 15000 10 255 1 1500R4(config-router)#redistribute ospf 1 metric 15000 10 255 1 1500R4(config-router)#exitR4(config)#R3#show ip routeCodes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGPi - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area* - candidate default, U - per-user static route, o - ODRP - periodic downloaded static routeGateway of last resort is not set1.0.0.0/24 is subnetted, 1 subnetsD EX 1.1.1.0 [170/] via 192.168.3.2, 00:02:12, FastEthernet0/02.0.0.0/32 is subnetted, 1 subnetsD EX 2.2.2.2 [170/] via 192.168.3.2, 00:01:43, FastEthernet0/03.0.0.0/24 is subnetted, 1 subnetsC 3.3.3.0 is directly connected, Loopback0D EX 192.168.1.0/24 [170/] via 192.168.3.2, 00:02:12, FastEthernet0/0D EX 192.168.2.0/24 [170/] via 192.168.3.2, 00:01:43, FastEthernet0/0C 192.168.3.0/24 is directly connected, FastEthernet0/0R3#最后测试所有地址能通信R1#ping 2.2.2.2Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 2.2.2.2, timeout is 2 seconds:!!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/0 msR1#ping 3.3.3.3Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds:!!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/1 msR1#R2#ping 1.1.1.1Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds:!!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/1 msR2#ping 3.3.3.3Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds: !!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/1 msR3#ping 1.1.1.1Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds: !!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/1 ms R3#ping 2.2.2.2Type escape sequence to abort.Sending 5, 100-byte ICMP Echos to 2.2.2.2, timeout is 2 seconds: !!!!!Success rate is 100 percent (5/5), round-trip min/avg/max = 0/0/1 ms R3#。
IPv6路由协议及重分发
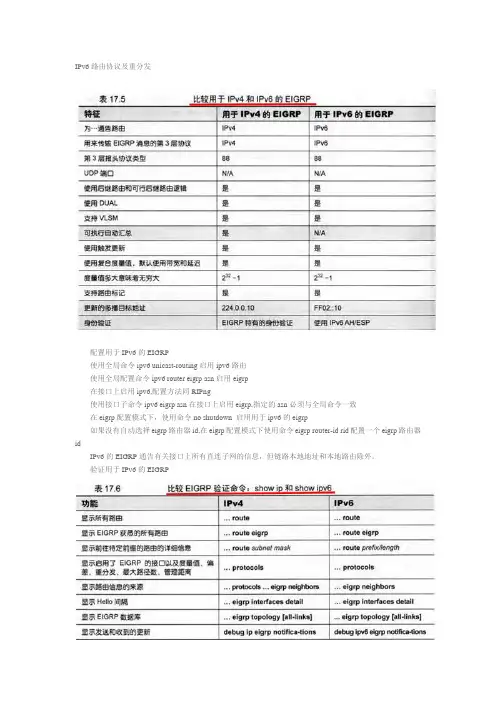
配置用于IPv6的EIGRP
使用全局命令ipv6 unicast-routing启用ipv6路由
使用全局配置命令ipv6 router eigrp asn启用eigrp
在接口上启用ipv6,配置方法同RIPng
使用接口子命令ipv6 eigrp asn在接口上启用eigrp,指定的asn必须与全局命令一致
在eigrp配置模式下,使用命令no shutdown 启用用于ipv6的eigrp
如果没有自动选择eigrp路由器id,在eigrp配置模式下使用命令eigrp router-id rid配置一个eigrp路由器id
IPv6的EIGRP通告有关接口上所有直连子网的信息,但链路本地地址和本地路由除外。
验证用于IPv6的EIGRP
OSPF第3版
比较OSPFv2和OSPFv3
说明:
OSPFv3不要求邻接路由器必须位于同一个子网才能成为邻居
OSPFv3支持在一条链路上使用多个OSPF实例,而OSPFv2只允许每条链路使用一个实例使用邻居的链路本地IPv6地址用于下一跳地址
ospfv3必须有RID才能工作
配置OSPFv3
下一代RIP
RIPng--理念及其与RIP-2的比较
由于IPv6使用IPSec身份验证报头(AH)来支持身份验证,因此RIPng本身不支持身份验证,而依赖于IPSec进行身份验证
配置RIPng
RIPng基本配置步骤:
使用全局命令ipv6 unicast-routing启用ipv6路由。
如果不配置此命令,将不能配置RIPng
使用全局配置命令ipv6 router rip name启用RIPng.指定的名称必须在当前路由器中是唯一的,但不必与邻接路由器使用的名称相同
在接口上启用IPv6.方法一:使用接口命令ipv6 address address/prefix-length [eui-64]给接口配置一个ipv6单播地址。
方法二:配置命令ipv6 enable.如果不配置此步,将不能在接口上启用RIPng.
使用接口子命令ipv6 rip name enable在接口上启用RIP,其中的名称必须与全局配置命令指定的名称相同。
如果忘记配置第二步,此步将会使IOS自动生成第二步的命令。
验证RIPng
RIPng使用链路本地IPv6地址用做下一跳IP地址
用于IPv6的EIGRP
用于IPv4和IPv6的EIGRP--理论及比较
用于IPv6和IPv6的EIGRP的差异:
用于IPv6的EIGRP通告IPv6前缀/长度,而不是IPv4子网/掩码信息
用于IPv6的EIGRP将邻居的链路本地地址用做下一跳IP地址
用于IPv6的EIGRP依赖于IPv6内置的身份验证和保密功能进行身份验证
用于IPv6的EIGRP不能执行自动汇总
用于IPv6的EIGRP不要求邻居位于同一个IPv6子网以便成为邻居
OSPFv3只支持一种配置方法,就是使用ipv6 ospf area在接口上启用OSPFv3.OSPFv3不支持network命令。
配置步骤如下:
使用全局命令ipv6 unicast-routing启用ipv6路由
使用全局配置命令ipv6 router ospf process-id创建一个ospfv3路由进程
在接口上启用ipv6,方法同RIPng
使用接口子命令ipv6 ospf process-id area areanmuber在接口上启用ospfv3
配置ospf路由器id,方法同eigrp
验证OSPFv3
IPv6 IGP重分发
IPv4与IPv6路由重分发之间的相似之处如下:
重分发使用iP路由表中的路由,而不是源路由协议控制的拓扑表和数据库中的路由
重分发时可使用路由映射表来过滤路由,设置度量值以及设置路由标记
IPv6路由协议使用的默认管理距离与IPv4相同,覆盖这些默认设置的机制也相同
IPv6使用同样的基本机制来避免环路问题:管理距离,路由标记和过滤
IPv6路由协议使用给内部和外部路由设置的默认管理距离与IPv4路由协议相同
配置重分发的命令语法相同
配置和概念方面的不同之处如下:
IPv6片redistribute命令默认只重分发IGP获悉的路由,而不重分发启用了该IGP的接口的直连路由。
要重分发这些直连路由,必须在命令redistribute中指定参数include-connected.ipv4 IGP重分发总是考虑IGP 获悉的路由以及启用了该IGP的接口的直连路由。
不同于OSPFv2,OSPFv3不需要在命令redistribute中包含参数subnets,因为IPv6没有分类网络及其子网的概念
IPv6重分发不考虑IPv6路由表中的本地路由
在不使用路由映射表的情况下重分发
使用路由映射表进行重分发
静态IPv6路由
使用命令配置IPv6静态路由,语法如下:
ipv6 route prefix/length {outgoing-interface [next-hop-address] | next-hop-address} [admin-distance] [tag
tag-value]
注意:1、可将邻接路由器的任何地址用做下一跳iP地址,包括邻居的链路本地Ipv6地址。
2、如果将链路本地地址用做下一跳地址,则必须配置出站接口和链路本地地址。