数据仓库与数据钻取实验二
- 格式:doc
- 大小:290.05 KB
- 文档页数:6

数据仓库与数据挖掘教程(第2版)课后习题答案第二章1. 什么是数据仓库?它与传统数据库有什么不同?答:数据仓库是一个面向主题、集成、稳定、可学习的数据集合,用于支持企业决策制定和决策支持系统。
与传统数据库相比,数据仓库更注重数据的整合和大数据的处理能力,以支持更高级别的数据分析和决策。
2. 什么是元数据?有哪些类型?答:元数据指描述数据仓库中数据的数据,用于描述数据的含义、格式、内容、质量、来源、使用和存储等方面的信息。
元数据有三种类型:技术元数据、业务元数据和操作元数据。
3. 数据仓库的架构有哪些组成部分?请简述各组成部分的作用。
答:数据仓库的架构主要包括数据源、数据抽取、清理和转换、存储和管理、元数据管理、查询和分析等几个组成部分。
- 数据源:指数据仓库的数据来源,可以是事务处理系统、外部数据源、第三方提供商等。
- 数据抽取、清理和转换:将数据从各种不同的来源抽取出来并转化为简单、标准的格式,以便进行加工和分析。
- 存储和管理:将经过抽取、转换和清洗后的数据存储在数据仓库中并进行管理,查找、更新和删除等操作。
- 元数据管理:对数据仓库中的元数据进行管理,并将其存储在元数据存储库中。
- 查询和分析:通过各种查询和分析工具来进行数据挖掘、分析和报告。
4. 请列出数据仓库中的三种主要数据类型。
答:数据仓库中的三种主要数据类型包括事实数据、维度数据和元数据。
5. 请列出数据仓库的三种不同的操作类型。
答:数据仓库的三种不同的操作类型包括基础操作、加工操作和查询操作。
6. 数据挖掘的定义是什么?答:数据挖掘是一种通过分析大量数据来发现有意义模式、趋势和关联的过程。
它是既包含统计学、机器学习和数据库技术的交叉学科,又包含更广泛的知识和业务领域。
7. 请列出数据挖掘中的四个主要任务。
答:数据挖掘中的四个主要任务包括描述性数据挖掘、预测性数据挖掘、关联数据挖掘和分类和聚类。
8. 数据仓库中经常使用OLAP分析方式,您了解OLAP是什么吗?答: OLAP是一种面向主题的数据分析方式,可以帮助用户对快速变化的数据进行多维分析和决策支持。
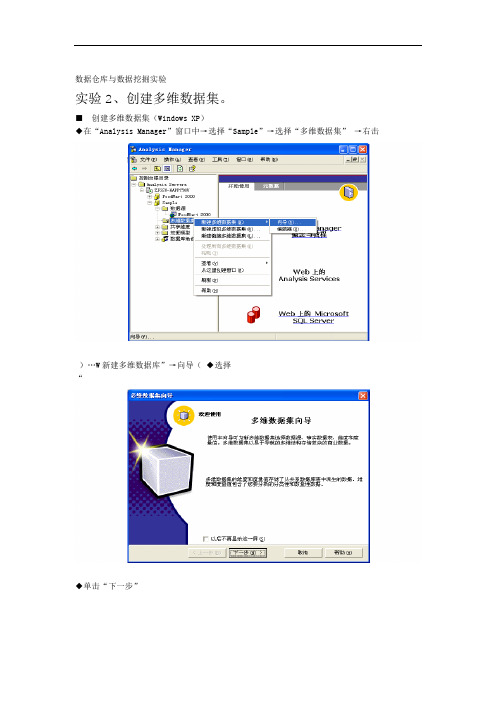
数据仓库与数据挖掘实验实验2、创建多维数据集。
■创建多维数据集(Windows XP)◆在“Analysis Manager”窗口中→选择“Sample”→选择“多维数据集”→右击)…W新建多维数据库”→向导(◆选择“◆单击“下一步”” Sales_fact_1998“→选择“默认构架””→展开2000 FoodMart “选择◆建立事实表。
.◆单击“浏览数据(R). . .”◆浏览数据后,关闭浏览数据窗口,单击“下一步”◆选择销售金额、销售成本和销售数量为事实表的度量值。
双击“ store_sales”、“ store_cost”、“ unit_sales”,然后单击“下一步”◆建立时间维度表。
在“选择多维数据集的维度”步骤中,单击“新建维度”◆单击“下一步”◆选择“星型构架(T):单个维度表”→单击“下一步””time_by_day◆选择时间表。
单击表“◆单击“浏览数据(R). . .”单击“下一步”→◆浏览数据后,关闭浏览数据窗口.◆选择“时间维度(T)”→单击“下一步”→单击“下一步”的右侧,选择“年、季度、月”(S)◆在选择时间级别◆单击“下一步”◆在维度名称(D)的右侧,输入:Time →选中“与其它多维度数据集共享此维度”→单击。
“完成”◆建立产品维度。
在建立时间维度后,再单击“新建维度(E). . .”◆单击“下一步”◆选择“雪花构架(W):多个相关维度表”→单击“下一步”◆选择并双击“product”和“product_class”→将它们添加到“选定的表”中◆单击“下一步”◆单击“下一步”◆定义三个维度级别,依次为:产品类、产品子类和品牌。
选择并双击“product_category”和“product_ subcategory ”和“brand_name”→将它们添加到“维度级别(D)”中◆单击“下一步”◆单击“下一步”◆单击“下一步”◆在维度名称(D)的右侧,输入:Product →选中“与其它多维度数据集共享此维度”→单击“完成”。

数据仓库与数据挖掘课程实验课程实验课程实验部分安排八个有代表性的上机实验与课程内容相呼应,每一个实验安排两学时。
学生应在实际操作中规范地完成各项实验。
更深入理解数据仓库及OLAP系统工作原理,构建数据仓库、熟练掌握OLAP操作。
实验完成后,教师在实验结束前,现场验收学生的完成情况,并给出现场评定,最后结合实验报告给出实验成绩。
实验一认识sql server2000一、实验目的1、通过某个商用数据库管理系统的安装使用,初步了解DBMS的工作环境和系统构架。
2、熟悉对DBMS的安装。
搭建今后实验的平台。
3、了解所选DBMS系统的主要组件。
4、理解数据库、数据表、属性、关键字等关系数据库中的基本概念。
5、熟悉利用管理器创建数据库、数据表并向表中插入数据6、查询数据表中数据。
二、实验平台操作系统:windows2000或者windows XP数据库管理系统:国产如KingbaseES,国外如:MS SQL Server, Oracle。
三、实验内容及要求1.安装和启动i.根据安装文件的说明安装数据库管理系统。
在安装过程中记录安装的选择,并且对所作的选择进行思考,为何要进行这样的配置,对今后运行数据库管理系统会有什么影响。
ii.学会启动和停止数据库服务,思考可以用哪些方式来完成启动和停止。
2.初步了解DBMS的安全性i.这里主要是用户的登录和服务器预定义角色。
可以尝试建立一个新的用户,赋予其数据库管理员的角色,今后的实验可以用该用户来创建数据库应用。
3.数据库系统的构架i.了解数据库系统的逻辑组件:它们主要是数据库对象,包括基本表、视图、触发器、存储过程、约束等。
今后将学习如何操作这些数据库对象。
4.DBMS的管理和使用了解DBMS如何通过它提供的工具对数据和数据库服务器进行管理和使用的。
i.学会运用控制管理器和企业管理器进行操作。
◆利用管理器创建school数据库,创建关系数据库SCHOOL表:◆学生表student(sno,sname,ssex.sage,sdept,grade),◆课程表course(cno,cname,cpno,chour,ccredit),◆教师表teacher(tno,tname,email,salary)。

一、上机目的及内容目的:1.理解数据挖掘的基本概念及其过程;2.理解数据挖掘与数据仓库、OLAP之间的关系3.理解基本的数据挖掘技术与方法的工作原理与过程,掌握数据挖掘相关工具的使用。
内容:将创建一个数据挖掘模型以训练销售数据,并使用“Microsoft 决策树”算法在客户群中找出购买自行车模式。
请将要挖掘的维度(事例维度)设置为客户,再将客户的属性设置为数据挖掘算法识别模式时要使用的信息。
然后算法将使用决策树从中确定模式。
下一步需要训练模型,以便能够浏览树视图并从中读取模式。
市场部将根据这些模式选择潜在的客户发送自行车促销信息。
要求:利用实验室和指导教师提供的实验软件,认真完成规定的实验内容,真实地记录实验中遇到的各种问题和解决的方法与过程,并根据实验案例绘出模型及操作过程。
实验完成后,应根据实验情况写出实验报告。
二、实验原理及基本技术路线图(方框原理图或程序流程图)关联分析:关联分析是从数据库中发现知识的一类重要方法。
时序模式:通过时间序列搜索出重复发生概率较高的模式。
分类:分类是在聚类的基础上对已确定的类找出该类别的概念描述,代表了这类数据的整体信息,既该类的内涵描述,一般用规则或决策树模式表示。
三、所用仪器、材料(设备名称、型号、规格等或使用软件)1台PC及Microsoft SQL Server套件四、实验方法、步骤(或:程序代码或操作过程)及实验过程原始记录( 测试数据、图表、计算等)创建 Analysis Services 项目1.打开 Business Intelligence Development Studio。
2.在“文件”菜单上,指向“新建”,然后选择“项目”。
3.确保已选中“模板”窗格中的“Analysis Services 项目”。
4.在“名称”框中,将新项目命名为 AdventureWorks。
5.单击“确定”。
更改存储数据挖掘对象的实例1.在 Business Intelligence Development Studio 的“项目”菜单中,选择“属性”。

数据仓库与数据挖掘实验指导书王浩畅资料.doc数据仓库与数据挖掘实验指导书东北⽯油⼤学计算机与信息技术系王浩畅实验⼀Weka实验环境初探⼀、实验名称:Weka实验环境初探⼆、实验⽬的:通过⼀个已有的数据集,在weka环境下,测试常⽤数据挖掘算法,熟悉Weka 环境。
三、实验要求1.熟悉weka的应⽤环境。
2.了解数据挖掘常⽤算法。
3.在weka环境下,测试常⽤数据挖掘算法。
四、实验平台新西兰怀卡托⼤学研制的Weka系统五、实验数据Weka安装⽬录下data⽂件夹中的数据集weather.nominal.arff,weather.arff六、实验⽅法和步骤1、⾸先,选择数据集weather.nominal.arff,操作步骤为点击Explorer,进⼊主界⾯,点击左上⾓的“Open file...”按钮,选择数据集weather.nominal.arff⽂件,该⽂件中存储着表格中的数据,点击区域2中的“Edit”可以看到相应的数据:选择上端的Associate选项页,即数据挖掘中的关联规则挖掘选项,此处要做的是从上述数据集中寻找关联规则。
点击后进⼊如下界⾯:2、现在打开weather.arff,数据集中的类别换成数字。
选择上端的Associate选项页,但是在Associate选项卡中Start按钮为灰⾊的,也就是说这个时候⽆法使⽤Apriori算法进⾏规则的挖掘,原因在于Apriori算法不能应⽤于连续型的数值类型。
所以现在需要对数值进⾏离散化,就是类似于将20-30℃划分为“热”,0-10℃定义为“冷”,这样经过对数值型属性的离散化,就可以应⽤Apriori算法了。
Weka提供了良好的数据预处理⽅法。
第⼀步:选择要预处理的属性temperrature从中可以看出,对于“温度”这⼀项,⼀共有12条不同的内容,最⼩值为64(单位:华⽒摄⽒度,下同),最⼤值为85,选择过滤器“choose”按钮,或者在同⾏的空⽩处点击⼀下,即可弹出过滤器选择框,逐级找到“Weka.filters.unsupervised.attribute.Discretize”,点击;若⽆法关闭这个树,在树之外的地⽅点击“Explorer”⾯板即可。

数据仓库与数据挖掘上机实验报告实验目的:学习Analysis Services的操作和基本的数据清洗实验内容:浏览SQL Server 2000 Analysis Services 随机教程;规划需求分析;仓库设计;数据清洗转换;建立分析数据库,设置数据源;建立多维数据库(Cube);设置多维数据库的数据存储方式及访问权限;利用Excel2000访问Analysis Services实验分析:下面只进行两个关键的实验,数据清洗转换和建立多维数据库(使用Northwind数据库),先用数据清洗转换,将需要的表从源库转换到新数据库,为数据仓库提供需要的数据,要形成的维表有Products,Category,Employees,Dates,Facts(事实表),在实验二中Products和Category将组成雪花架构的维表。
实验一:数据清洗转换内容:为数据仓库新建一个数据库,将Products,Categories,Employees,Orders,Order Details转换到新数据库,为数据仓库提供需要的数据目的:为数据仓库事实表和各维表建立基本数据步骤:1)新建一个数据库myNorthwind,并准备从Northwind导入数据。
2)建立Products和Categories两个维度表,将维度表需要的列从Northwind数据库复制到myNorthwind。
3)建立Employees维度表,将源表的列内容复制过来,并将源表中first name和lastname合成一个fullname列,在DTS导入/导出向导中使用SQL语句合成新的列fullname。
4)建立Dates维度表,由源表Orders表中OrderDate一列产生出年、月、日、周、季等列,同时保留OrderDate一列。
在处理数据时使用了VBScript中的DatePart 函数。
5)建立Facts表,(事实表)该表的数据来自Order Details表,首先用Select语句将产品类别编号和员工编号等从各自表中取出;其次计算合计列值,计算方法为单价*(1-折扣)*数量;然后将Order Details表的内容复制到Facts表各列即可;再建立主、外键关系。
数据仓库与数据挖掘实验报告题目Glass(玻璃)数据集分析院系姓名学号专业班级科目数据仓库与数据挖掘任课老师目录一、实验目的 (1)二、实验内容 (1)1.数据预处理方法(缺失值处理) (1)2.数据可视化 (1)3.分类算法测试及比较 (1)三、实验步骤 (1)1.Weka平台搭建及收集该数据集 (1)2.加载 Glass(玻璃)数据集 (1)3.数据预处理 (2)4.数据可视化 (4)5.分类算法 (5)四、实验总结 (9)一、实验目的1.使用Weka数据预处理方法,对缺失值数据进行处理。
缺失值会使数据挖掘混乱,分析可能会得到错误结论,所以在数据挖掘前最好进行缺失值数据进行处理。
2.使用数据挖掘中的分类算法,对数据集进行分类训练并测试,应用不同的分类算法,比较他们之间的不同。
3.学习与了解Weka平台的基本功能与使用方法。
二、实验内容1.数据预处理方法(缺失值处理)2.数据可视化3.分类算法测试及比较三、实验步骤1.Weka平台搭建及收集该数据集2.加载 Glass(玻璃)数据集(1)Glass(玻璃)数据集预处理界面如图2.1所示:(2)Glass(玻璃)数据属性含义如表2.1所示:表2.1 Glass(玻璃)数据属性含义3.数据预处理(1)Glass(玻璃)数据预处理前数据如图3.1所示:(2)使用缺失值处理函数:weka.filters.unsupervised.attribute.ReplaceMissingValues。
Glass(玻璃)数据预处理后数据如图3.2所示:图3.2 Glass(玻璃)数据预处理后数据图示4.数据可视化Glass(玻璃)数据可视化如图4.1所示:图4.1 Glass(玻璃)数据可视化图示5.分类算法(1)KNN算法:一种统计分类器,对数据的特征变量的筛选尤其有效。
KNN算法如图5.1所示:图5.1 KNN算法图示①元素分析结果如表5.1所示:表5.1 元素分析结果②类型分析结果:准确率为70.5607%,其中214个实例数据有151个正确分类,63个错误分类。
数据仓库与数据挖掘实验数据挖掘实验指导书数据仓库与数据挖掘实验数据挖掘实验指导书《数据挖掘》实验指导书xx年3月1日长沙学院信息与计算科学系前言随着数据库技术的发展,特别是数据仓库以及Web 等新型数据源的日益普及,形成了数据丰富,知识缺乏的严重局面。
针对如何有效地利用这些海量的数据信息的挑战,数据挖掘技术应运而生,并显示出强大的生命力。
数据挖掘技术使数据处理技术进入了一个更高级的阶段,是对未来人类产生重大影响的十大新兴技术之一。
因此加强数据挖掘领域的理论与实践学习也已成为专业学生的必修内容。
本实验指导书通过大量的实例,循序渐进地引导学生做好各章的实验。
根据实验教学大纲,我们编排了五个实验,每个实验又分了五部分内容:实验目的、实验内容、实验步骤、实验报告要求、注意事项。
在实验之前,由教师对实验作一定的讲解后,让学生明确实验目的,并对实验作好预习工作。
在实验中,学生根据实验指导中的内容进行验证与,然后再去完成实验步骤中安排的任务。
实验完成后,学生按要求完成实验报告。
整个教学和实验中,我们强调学生切实培养动手实践能力,掌握数据挖掘的基本方法。
实验一 K-Means聚类算法实现一、实验目的通过分析K-Means 聚类算法的聚类原理,利用Vc 编程工具编程实现K-Means 聚类算法,并通过对样本数据的聚类过程,加深对该聚类算法的理解与应用过程。
实验类型:验证计划课间:4学时二、实验内容1、分析K-Means 聚类算法;2、分析距离计算方法;3、分析聚类的评价准则;4、编程完成K-Means 聚类算法,并基于相关实验数据实现聚类过程;三、实验方法1、K-means 聚类算法原理K-means聚类算法以k 为参数,把n 个对象分为k 个簇,以使簇内的具有较高的相似度。
相似度的计算根据一个簇中对象的平均值来进行。
算法描述:输入:簇的数目k 和包含n 个对象的数据库输出:使平方误差准则最小的k 个簇过程:任选k 个对象作为初始的簇中心; Repeatfor j=1 to n DO根据簇中对象的平均值,将每个对象赋给最类似的簇 for i=1 to k DO 更新簇的平均值计算EUnitl E不再发生变化按簇输出相应的对象2、聚类评价准则: E 的计算为:E =∑∑|x -xi =1x ∈C iki|2四、实验步骤 4.1 实验数据P192:154.2初始簇中心的选择选择k 个样本作为簇中心For (i=0;i For (j=0;jClusterCenter[i][j]=DataBase[i][j]4.3 数据对象的重新分配Sim=某一较大数;ClusterNo=-1;For (i=0;iIf (Distance(DataBase[j],ClusterCenter[i])ClusterNo=i;}ObjectCluster[j]=ClusterNo;4.4 簇的更新For (i=0;i{Temp=0;Num=0; For (j=0;jIf (ObjectCluster[j]==i){Num++; T emp+=DataBase[j];} If (ClusterCenter[i]!=Temp) HasChanged=TRUE;ClusterCenter[i]=T emp; }4.5 结果的输出 For (i=0;iPrintf(“输出第%d个簇的对象:”,i); For (j=0;jIf (ObjectCluster[j]==i) printf(“%d ”,j); Printf(“\n”);Printf(“\t\t\t 簇平均值为(%d,%d)\n”, ClusterCenter[i][0], ClusterCenter[i][1]); }五、注意事项 1、距离函数的选择 2、评价函数的计算实验二 DBSCAN算法实现一、实验目的要求掌握DBSCAN 算法的聚类原理、了解DBSCAN 算法的执行过程。
《数据仓库与数据挖掘》实验报告册20 - 20 学年第学期班级:学号:姓名:授课教师:杨丽华实验教师:杨丽华实验学时: 16 实验组号: 1信息管理系目录实验一 Microsoft SQL Server Analysis Services的使用 (3)实验二使用WEKA进行分类与预测 (6)实验三使用WEKA进行关联规则与聚类分析 (7)实验四数据挖掘算法的程序实现 (8)实验一 Microsoft SQL Server Analysis Services的使用实验类型:验证性实验学时:4实验目的:学习并掌握Analysis Services的操作,加深理解数据仓库中涉及的一些概念,如多维数据集,事实表,维表,星型模型,雪花模型,联机分析处理等。
实验内容:在实验之前,先通读自学SQL SERVER自带的Analysis Manager概念与教程。
按照自学教程的步骤,完成对FoodMart数据源的联机分析。
建立、编辑多维数据集,进行OLAP操作,看懂OLAP的分析数据。
实验步骤:1、启动联机分析管理器:开始->程序->Microsoft SQL Server->Analysis Manager。
2、按照Analysis Service的自学教程完成对FoodMart数据源的联机分析。
3、在开始-设置-控制面板-管理工具-数据源(ODBC),数据源管理器中设置和源数据的连接,“数据源名”为你的班级+学号+姓名,如T3730101张雨。
4、在开始-设置-控制面板-管理工具-服务-MSSQLServerOLAPService, 启动该项服务。
在Analysis Manager中,单击服务器名称,即可建立与Analysis Servers 的连接;否则,在Analysis Servers 上单击右键,注册服务器,在服务器名称中输入本地计算机的名字,如pc56。
本地计算机的名字可右击:我的电脑,选择属性,网络标志,里面有本地计算机的名字。