概率统计模型
- 格式:ppt
- 大小:486.00 KB
- 文档页数:25

概率与统计的模型与应用在概率与统计领域,模型是一种描述随机事件或现象的数学工具,而应用则是利用模型对实际问题进行分析、预测和决策的过程。
本文将探讨概率与统计的模型以及其在实际应用中的重要性和效果。
一、概率与统计模型的概述概率与统计模型是对随机变量和概率分布的数学描述,它们可以从数学角度上表达随机性、不确定性和变异性。
概率模型通常用来描述随机事件的可能性,例如掷硬币的结果、骰子的点数等;而统计模型则用来描述数据的变化和规律,例如人口增长、气温变化等。
这些模型可以是离散的或连续的,可以是简单的或复杂的,但它们的核心目标都是对现实世界进行建模和分析。
二、常见的概率与统计模型1. 随机变量模型随机变量模型是概率与统计中最基础的模型之一,它描述了随机事件的可能取值和相应的概率分布。
随机变量可以分为离散和连续两种类型。
离散随机变量的取值是有限或可数的,例如扔一个硬币的结果只有正面和反面两种可能;而连续随机变量的取值是无限的,例如人的身高、温度等。
通过对随机变量的建模,可以进行各种概率计算和预测。
2. 假设检验模型假设检验模型是统计推断的一种重要工具,用于验证关于总体参数的假设。
它将问题划分为一个原假设和一个备择假设,并通过对样本数据的分析来判断是否拒绝原假设。
假设检验模型广泛应用于医学、社会科学、市场调研等领域,帮助研究人员做出科学的决策。
3. 回归分析模型回归分析模型是统计学中一种常见的分析方法,用于研究变量之间的关系。
它通过建立一个线性或非线性回归模型来描述自变量与因变量之间的关系,并通过求解最小二乘法来确定模型参数。
回归分析模型可以用来预测和解释变量之间的关系,广泛应用于经济学、金融学、市场营销等领域。
三、概率与统计模型的应用概率与统计模型在各个领域中都有广泛的应用,下面以几个具体的例子来说明。
1. 风险评估与管理概率与统计模型可以用于风险评估与管理。
通过对历史数据的分析和建模,可以预测各种风险事件的概率和可能的影响程度,以便采取相应的措施进行应对和管理。

概率统计数学模型在数学领域,概率统计是一个非常重要的分支,它涉及到各种随机现象的数学描述和统计分析。
概率统计数学模型则是这些分析的基础,它能够准确地描述和预测各种随机现象的结果。
一、概率统计数学模型的基本概念概率统计数学模型是建立在随机试验基础上的数据分析方法。
在概率论中,随机试验的结果通常被视为不可预测的,但可以通过概率分布来描述它们。
而统计方法则是对数据进行收集、整理、分析和推断的方法,它依赖于概率论的知识。
二、概率统计数学模型的应用概率统计数学模型在各个领域都有广泛的应用,例如在金融领域中,它可以帮助我们预测股票价格的波动;在医学领域中,它可以帮助我们理解疾病的传播方式;在工程领域中,它可以帮助我们优化设计方案。
三、概率统计数学模型的建立过程建立概率统计数学模型通常包括以下几个步骤:1、确定研究问题:首先需要明确研究的问题是什么,以及我们想要从中获得什么样的信息。
2、设计随机试验:针对研究问题,设计合适的随机试验,以便收集数据。
3、收集数据:通过试验或调查等方式收集数据,并确保数据的准确性和可靠性。
4、分析数据:利用统计分析方法对收集到的数据进行处理和分析,提取有用的信息。
5、建立模型:根据分析结果,建立合适的概率统计模型,以描述数据的分布规律和预测未来的趋势。
6、验证模型:对建立的模型进行验证,确保其准确性和适用性。
7、应用模型:将建立的模型应用于实际问题的解决和预测中。
概率统计数学模型是处理和分析随机现象的重要工具,它在各个领域都有广泛的应用前景。
通过建立合适的概率统计模型,我们可以更好地理解和预测各种随机现象的结果,从而为实际问题的解决提供有力的支持。
概率统计数学模型在投资决策中的应用在投资决策的制定过程中,准确理解和应用概率统计数学模型是至关重要的。
概率统计数学模型为投资者提供了定量分析工具,帮助他们更准确地预测投资结果,从而做出更合理的决策。
一、概率模型的应用概率模型在投资决策中的应用广泛。


关键词:营销活动;概率统计模型;市场调查;市场预测;不可控因素营销活动中商品的销售情况是经营者最为关心的问题,同时也是难以预测的问题,其直接决定着营销活动成功与否。
通常,营销活动成功与否、销售业绩好坏是不可控因素,不是经营者能够决定的,其中也存在一定的随机性。
概率统计模型是数学领域重要的统计方法,其在营销活动中也有着一定的应用。
运用概率统计模型,一方面能够帮助解决现实生活中实际问题,另一方面能够确保经济利益最大化。
一、概率统计模型在市场调查环节的应用作为营销活动重要的组成部分,市场调查能够为市场预测及营销方案的制定提供可靠的参考依据,其主要指的是对市场营销相关资料、信息进行搜集、整理、分析,常用的调查方法为随机抽样法,引入数理统计知识,能够提升市场调查的科学性,包括分层抽样、整群抽样以及随机抽样等。
市场是由多个购买者构成的,购买群体不同、地理位置不同、购买态度及习惯等不同,其购买行为也会呈现明显的差异。
因此,市场调查期间,必须将市场细分,充分了解市场需求。
好的运营活动除了制定活动主题,还需要撰写活动方案,制定详细的活动流程,按照活动流程一步步地进行活动,并且能够详细传达活动的各项信息。
针对消费者年龄的不同,可以采用分层抽样法。
首先,根据某一特点将抽样单位中没有重叠的抽取出来,抽出的样本构成一个新的总样本,将其用于对总体目标量的推断。
如:在调查某一地区乳制品需求量时,首先需要对该地区居民每年用于乳制品的消费支出进行调查统计,抽样单位为地区居民户;在市场细分环节,可以按照居民收入水平将其划分成为4个级别,从每个级别中随机抽取10户作为样本,经过调查可获得以下数据(见表1),结合该地区居民乳制品年消费额对标准差进行估计。
胡俊红/文营销活动的概率统计模型构建及运用10.13999/ki.scyj.2020.05.026表1某地区乳制品消费支出情况总样本数量N 为2750,n k =10,其中k 表示1,2,3,4,对各层层权以及抽样比进行计算,计算方法为W 1=N 1N=2502750≈0.09,f 1=n1N 1=15250=0.06,根据该计算方法可以一次求出W 2、W 3、W 4的值。
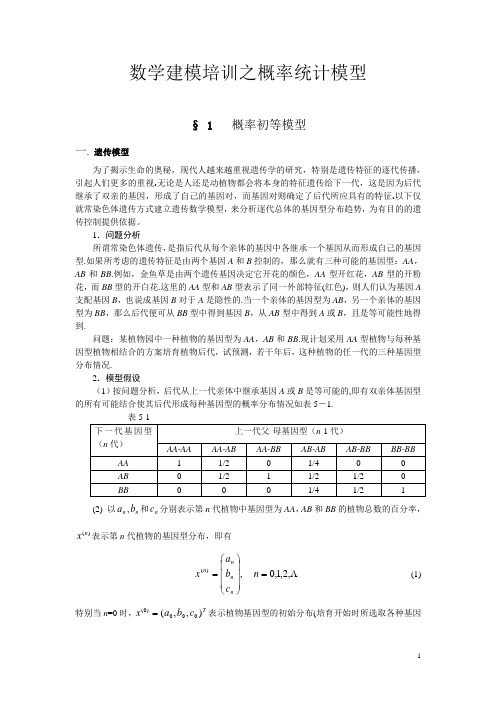
数学建模培训之概率统计模型§ 1 概率初等模型一. 遗传模型为了揭示生命的奥秘,现代人越来越重视遗传学的研究,特别是遗传特征的逐代传播,引起人们更多的重视.无论是人还是动植物都会将本身的特征遗传给下一代,这是因为后代继承了双亲的基因,形成了自己的基因对,而基因对则确定了后代所应具有的特征.以下仅就常染色体遗传方式建立遗传数学模型,来分析逐代总体的基因型分布趋势,为有目的的遗传控制提供依据。
1.问题分析所谓常染色体遗传,是指后代从每个亲体的基因中各继承一个基因从而形成自己的基因型.如果所考虑的遗传特征是由两个基因A 和B 控制的,那么就有三种可能的基因型:AA ,AB 和BB .例如,金鱼草是由两个遗传基因决定它开花的颜色,AA 型开红花,AB 型的开粉花,而BB 型的开白花.这里的AA 型和AB 型表示了同一外部特征(红色),则人们认为基因A 支配基因B ,也说成基因B 对于A 是隐性的.当一个亲体的基因型为AB ,另一个亲体的基因型为BB ,那么后代便可从BB 型中得到基因B ,从AB 型中得到A 或B ,且是等可能性地得到.问题:某植物园中一种植物的基因型为AA ,AB 和BB .现计划采用AA 型植物与每种基因型植物相结合的方案培育植物后代,试预测,若干年后,这种植物的任一代的三种基因型分布情况.2.模型假设 (1)按问题分析,后代从上一代亲体中继承基因A 或B 是等可能的,即有双亲体基因型的所有可能结合使其后代形成每种基因型的概率分布情况如表5-1.表5-1(2) 以n n b a ,和n c 分别表示第n 代植物中基因型为AA ,AB 和BB 的植物总数的百分率,)(n x 表示第n 代植物的基因型分布,即有,)(⎪⎪⎪⎭⎫⎝⎛=n n n n c b a x ,2,1,0=n (1) 特别当n =0时,T c b a x ),,(000)0(=表示植物基因型的初始分布(培育开始时所选取各种基因型分布),显然有.1000=++c b a3.模型建立注意到原问题是采用AA 型与每种基因型相结合,因此这里只考虑遗传分布表的前三列. 首先考虑第n 代中的AA 型,按上表所给数据,第n 代AA 型所占百分率为1110211---⋅+⋅+⋅=n n n n c b a a 即第n-1代的AA 与AA 型结合全部进入第n 代的AA 型,第n -1代的AB 型与AA 型结合只有一半进入第n 代AA 型,第n -1代的BB 型与AA 型结合没有一个成为AA 型而进入第n 代AA 型,故有1121--+=n n n b a a (2)同理,第n 代的AB 型和BB 型所占有比率分别为1121--+=n n n c b b (3)0=n c (4)将(2)、(3)、(4) 式联立,并用矩阵形式表示,得到,)1()(-=n n Mx x),2,1( =n (5)其中⎪⎪⎪⎭⎫ ⎝⎛=00012/1002/11M利用(5)进行递推,便可获得第n 代基因型分布的数学模型)0()2(2)1()(x M x M Mx x n n n n ====-- (6)(6)式明确表示了历代基因型分布均可由初始分布)0(x与矩阵M 确定.4.模型求解这里的关键是计算nM .为计算简便,将M 对角化,即求出可逆阵P ,使Λ=-MP P 1,即有1-Λ=P P M从而可计算 1-Λ=P P M nn),2,1( =n其中Λ为对角阵,其对角元素为M 的特征值,P 为M 的特征值所对应的特征向量.分别为,11=λ 212=λ,03=λ⎪⎪⎪⎭⎫ ⎝⎛-=⎪⎪⎪⎭⎫ ⎝⎛-=⎪⎪⎪⎭⎫ ⎝⎛=121,011,001321p p p故有1100210111,0211-=⎪⎪⎪⎭⎫ ⎝⎛--=⎪⎪⎪⎪⎭⎫ ⎝⎛=ΛP P即得⎪⎪⎪⎭⎫ ⎝⎛--⎪⎪⎪⎪⎭⎫ ⎝⎛⎪⎪⎪⎭⎫ ⎝⎛--=1002101110211100210111nnM ⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛--=--00021210211211111n n n n 于是 ⎪⎪⎪⎭⎫ ⎝⎛⎪⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛--=⎪⎪⎪⎭⎫ ⎝⎛=--00011)(000212102112111c b a c b a x n nn nn n n n或写为⎪⎪⎪⎩⎪⎪⎪⎨⎧=+=--=--0)21()21()21()21(1010010n n n n n n nc c b b c b a 由上式可见,当∞→n 时,有0,0,1→→→n n n c b a即当繁殖代数很大时,所培育出的植物基本上呈现的是AA 型,AB 型的极少,BB 型不存在.5.模型分析(1)完全类似地,可以选用AB 型和BB 型植物与每一个其它基因型植物相结合从而给出类似的结果.特别是将具有相同基因植物相结合,并利用前表的第1、4、6列数据使用类似模型及解法而得到以下结果:000021,0,,21b c c b b a a n n n +→→+→这就是说,如果用基因型相同的植物培育后代,在极限情形下,后代仅具有基因AA 与BB ,而AB 消失了.(2)本例巧妙地利用了矩阵来表示概率分布,从而充分利用特征值与特征向量,通过对角化方法解决了矩阵n 次幂的计算问题,可算得上高等代数方法应用于解决实际的一个范例.二. 传送系统的效率模型1.问题的提出在机械化生产车间里你可以看到这样的情景:排列整齐的工作台旁工人们紧张地生产同一种产品,工作台上方一条传送带在运转,带上设置着若干钩子,工人们将产品挂在经过他上方的钩子上带走,如图1.当生产进入稳定状态后,每个工人生产出一件产品所需时间是不变的,而他要挂产品的时刻却是随机的.衡量这种传送系统的效率可以看它能否及时地把工人们生产的产品带走,显然在工人数目不变的情况下传送带速度越快,带上钩子越多,效率会越高.我们要构造一个衡量传送系统效率的指标,并且在一些简化假设下建立一个模型来描述这个指标与工人数目、钩子数量等参数的关系.2.问题的分析进入稳态后为保证生产系统的周期性运转,应假定工人们的生产周期相同,即每人作完一件产品后,要么恰有空钩经过他的工作台,使他可将产品挂上运走,要么没有空钩经过,迫使他放下这件产品并立即投入下件产品的生产。

概率统计模型自然界中存在两种现象:确定性现象和不确定性现象.同一实验或者试验在不同次重复中,可能出现不同的结果的现象称为随机现象.随机现象的结果尽管是不确定的,但是,同一随机现象的多次重复却表现出某种规律性,即同一事件在不同次试验或者实验中出现的概率是确定的、唯一的.因此,随机现象中包含确定性现象.对随机现象的研究可以通过对随机现象的某些事件的发生概率来研究.变量之间也存在两种关系:确定性关系和不确定性关系.确定性关系:可用一个表达式确切描述,如圆的面积与半径之间的关系.描述确定性关系的数学模型有函数,微分方程,差分方程等.不确定性关系:不可用一个表达式确切描述,如人的体重与身高等.不确定性关系在现实生活中大量存在,即使许多看来是确定性关系的变量,在实际中也会受到各种不同随机因素的影响而变得不确定,确定性关系只是它们的一种近似,如自然科学的很多规律.本章主要介绍利用概率统计知识分析随机现象和随机数据,建立随机模型,求解随机模型,并对得到的结果进行分析,最后运用于实际.第一节介绍几个直接利用概率知识的建模问题,如赌博问题,巴拿赫(Banach)火柴盒问题,信与信封的配对问题,切割机的收益问题;第二节回归分析模型,主要介绍施肥效果分析问题;第三节判别分析模型,主要介绍螨虫分类问题;第四节时间序列分析,主要介绍Chesapeake 海湾的收成预测问题;第五节随机模拟模型,主要介绍利用随机模拟方法产生随机数据及模拟随机现象的方法;第六节排队论模型,主要介绍用排队论的方法分析,处理等候问题.通过以上这些模型和方法的学习,使读者了解和掌握一些处理随机问题的一般思想和方法,如果读者想进一步学习和了解随机数学的专业理论与方法,可阅读随机数学的一些分支的专门著作,如:随机过程,时间序列分析,回归分析,多元统计分析等.§4-1 几个直接利用概率知识的建模问题对随机现象的研究可以通过对随机现象的某些事件的发生概率来研究.本节就来介绍几个概率模型,主要利用的基本知识就是古典概率模型的概率计算及其相关问题,随机变量的概率分布及其计算.可以参看任意一本大学理工科的《概率论与数理统计》教科书[7],也可以参考周义仓、赫孝良两位老师编写的教科书[6]. 问题描述问题1:赌博问题均匀正方体骰子的六个面分别编号1,2,3,4,5,6.现将一对骰子抛掷6次以决定胜负,请问将赌注押在“出现两个1点”和“完全不出现两个1点”哪个更有利?问题2:巴拿赫(Banach)火柴盒问题波兰数学家巴拿赫随身带着两盒火柴,分别放在两个衣袋里,每盒有n 根火柴.使用时,每次随机地从其中一盒中取出一根.试求他将一盒火柴用完时,另一盒剩余火柴根数的分布律.问题3:信与信封的配对问题某人给它的N 个朋友写信,写好后,分别将这些信装入N 个信封中,并在信封上随机、不重复地写上N 个收信人的地址.问他一个都没写正确和恰有r 个写正确的概率各是多少?问题4:切割机的收益问题[3]一台线切割机把金属线切割成规定的长度.由于切割机的某种不准确性,切割线的长度X 可以看作是在区间[11.5,12.5]上的均匀分布的随机变量.规定的长度是12cm .如果11.712.2X ≤<,该种线能卖出去而获利润0.25元.如果12.2X ≥,可以重切,并且最后得到0.10元的利润,而如果11.7X <,则以0.02元的损失丢弃.试计算:如果切割N 段金属线,那么,请估计平均每根金属线为老板贡献的利润是多少? 问题求解1. 问题1的求解问题1是一个古典概率模型的概率计算问题.解决这样的问题的关键就是事件的表示.为此,我们令k i A 分别表示第i 次抛掷骰子时第k 枚骰子(1,2k =)出现1点的事件.那么,在第i 次抛掷中,两枚骰子都出现1点的事件i A 表示为12i i i A A A = (4.1.1)而6次抛掷中至少出现一次两个1点的事件B 可以表示为()6121i i i B A A == (4.1.2)这样,事件B 的对立事件是()661211iii i i B A AA ===+=∏∏ (4.1.3)所以()()1P B P B =- (4.1.4)由于事件12,,1,2,3,4,5,6i i A A i --=相互独立,于是有()()()6111i i P B P B P A ==-=-∏ (4.1.5)而()()()()()212125553566636i iiiiP A P A P A P A P A ⎛⎫=+-=+-=⎪⎝⎭所以()()()661351110.155536i i P B P B P A =⎛⎫=-=-=-= ⎪⎝⎭∏ (4.1.6)这样,出现两个一点的概率是0.1555,大大小于完全不出现两个一点的概率0.8445.因此,应将赌注押在"完全不出现两个一点"上.2. 问题2的求解设巴拿赫总共取出的火柴根数为Z ,而分别来自于两个火柴盒,设从左右口袋的两个火柴盒中分别取出的火柴根数分别是,X Y ,于是Z X Y =+ (4.1.7)而用U 表示总共剩余的火柴根数,于是()()(),,U k X k Y n Y k X n ====== (4.1.8) 那么,我们要计算的随机变量U 的分布列.设巴拿赫发现左口袋火柴刚好取完时,右口袋里还剩Y k =根火柴,因此,右口袋已经被取了n k -根.这样,当巴拿赫首次发现左口袋没有火柴时,已经进行了2n k n n k -+=-次随机试验.在这2n k -次试验中,事件A ,即火柴取自左口袋出现了n 次,事件A ,即火柴取自右口袋出现了n k -次.对右口袋先取完,我们又类似的讨论.这样,这个问题实际上是一个二项分布的概率计算问题.于是()()()()()()()2222,,||111111112222221,0,1,2,,2n knn knn n n kn k n kn n kP U k P X k Y n P Y k X n P X k Y n P Y n P Y k X n P X n C C Ck n------====+======+===⎛⎫⎛⎫⎛⎫⎛⎫=-+- ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭⎝⎭⎛⎫== ⎪⎝⎭(4.1.9) 3. 问题3的求解经过分析,问题相当于将N 封写好的信放到写着正确地址的信封.问题要求,计算所有的信都没有正确放到该放的信封的事件的概率,以及计算恰有r 封信正确放到该放的信封的概率.这是一个古典概型问题.我们分别用,r A B 表示没有正确放到该放的信封的事件以及恰有r 封信正确放到该放的信封的事件.用i A 表示第i 封信能正确放对信封的事件,1,2,,i N = ,那么12N A A A A = (4.1.10)这里特别要注意:1,,N A A 不是相互独立的,而事件121r r N i i i i i A A A A A + 是互不相容(12,,,N i i i 是1,2,,N 的一个排列)的.因此,不能利用下式计算概率()P A()()()()12N P A P A P A P A = (4.1.11)但是,注意到公式()()111N i i P A P A P A =⎛⎫=-=- ⎪⎝⎭(4.1.12)而()()()()()()()()()()()()()()111,1,,,1,1,1,,,1,1112112311|||1|...1111111112N N N NN i i i j i j k N i i j i j i j k i j k i N Ni j i i j i k i j i j i j i j k i j kN N N N NN P A P A P A A P A A A P A A N P A P A A P A P A A P A A A N P A P A A A A C C N N N N N -==<=<<==<=<<---⎛⎫=-+++- ⎪⎝⎭=⋅-+++-=-⋅+⋅⋅++----∑∑∑∑∑()11111111!k Nk N N k -=⋅--=∑(4.1.13)所以,由(4.1.12),有()()01!kNk P A k =-=∑(4.1.14)用r C 表示恰好指定的r 封信装对信封,则由乘法原理,r B 中的样本点数为(这里()r n B 和()r n C 分别是事件,r r B C 的基本事件个数,或称样本点数)()()rr N r n B C n C = (4.1.15) 而()()()!!r r rr Nn B n C P B C N N == (4.1.16)根据前面的分析和结论,有()()01!kN rr k P C k -=-=∑(4.1.17)而由古典概率的计算公式,有()()()()01!!kN rr r k n C P C k N r -=-==-∑(4.1.18)于是,得到()()()01!!kN rr k n C N r k -=-=-∑(4.1.19)()()011,0,1,2,,!!kN r r k P B k N r k -=-==∑ (4.1.20) 4. 问题4的求解我们只要知道了在三类区间的线段的数目,就可以计算出总的收益.设长度在区间11.712.2X ≤<、区间12.2X ≥和区间11.7X <上的切割线的数目分别是,,p g l N N N ,而总数目为N ,则p g l N N N N =++ (4.1.21)如果总利润是I ,那么平均每根金属线的利润为0.250.100.02p g l N N N Iw N N N N==+- (4.1.22)我们知道,,,p g l N N NN N N分别是随机变量X 落在如上三个区间的频率,而频率具有稳定性,当N 充分大时,频率近似等于相应的概率值,即()()()12.211.712.512.211.711.5111.711.20.512.511.5112.20.312.511.5111.70.212.511.5p g l N P X dx N N P X dx N N P X dx N≈≤<==-≈≥==-≈<==-⎰⎰⎰ 所以,平均来说,单根金属线的利润为0.250.50.100.30.020.20.151w =⨯+⨯-⨯=(元) (4.1.23)研究性问题4-2-1 供电问题:设某车间有200台车床相互独立地工作,由于经常需要维修、测量、调换刀具、变换位置等种种原因要停车.若每台车床有60%的时间在开动,而每台车床在开动时要耗电1KW ,问应供给这个车间多少电力才能保证在8h 生产中大约仅有0.5min 因电力不足而影响生产?4-2-2 钓鱼问题:为了估计湖中鱼的数量,先从湖中钓出r 条鱼做上记号,并放回湖中过一段时间后再从湖中钓出S 条鱼,结果发现其中有x 条鱼标有记号.问应该如何估计湖中鱼的数量N .§4-2 农作物施肥量与产量的关系问题描述某地区农作物生长所需的营养素主要是氮(N )、磷(P )、钾(K ),农作物研究所在该地区对土豆与生菜做了一定数量的实验,实验数据如表4.2.1,其中:ha 表示公顷,t 表示吨,kg 表示公斤.当一个营养素的施肥量变化时,将另二个营养素的施肥量保持在第七水平,如对土豆关于N 的施肥量做实验时,P 与K 的施肥量分别取196kg/ha(第七水平)与372kg/ha(第七水平) .表4.2.1 施肥量与产量实验数据土豆NPK施肥量(kg/ha) 产量 (t/ha) 施肥量 (kg/ha) 产量 (t/ha) 施肥量 (kg/ha) 产量 (t/ha) 0 15.18 0 33.46 0 18.98 3421.362432.474727.3567 25.72 49 36.06 96 34.86 101 32.29 73 37.96 140 38.52 135 34.03 98 41.04 186 38.44 202 39.45 147 40.09 279 37.73 259 43.15 196 41.26 372 38.43 336 43.46 245 42.17 465 43.87 404 40.83 294 40.36 558 42.77 471 30.75 342 42.73 651 46.22N P K施肥量(kg/ha) 产量(t/ha)施肥量(kg/ha)产量(t/ha)施肥量(kg/ha)产量(t/ha)0 11.02 0 6.39 0 15.7528 12.70 49 9.48 47 16.7656 14.56 98 12.46 93 16.8984 16.27 147 14.33 140 16.24112 17.25 195 17.10 185 17.56168 22.59 294 21.94 279 19.20224 21.63 391 22.64 372 17.97280 19.34 489 21.34 465 15.84336 16.12 587 22.07 558 20.11392 14.11 685 24.53 651 19.40 试建立模型分析施肥量与产量的关系,并对所得结果从应用价值与如何改进等方面作出分析.问题分析农作物的产量与施肥量之间存在密切的关系,但很难用一个确定的函数关系来表达,故可考虑用回归分析方法来研究其相关关系,建立回归方程近似描述产量与施肥量之间的相关关系.模型假设1. 实验中,只考虑施肥量对农作物产量的影响,其它因素:如温度,湿度,其它微量元素的含量,均处于相同水平,不预考虑.2. 各次实验相互独立,结果互不影响,观测误差独立同分布,服从()20,,0Nσσ>,N,P,K的用量可精确控制,误差忽略不计.变量及符号说明n : 实验总次数,本问题中为10.1i Q : 对土豆而言,第i 次实验的产量,1,2,,i n = 2i Q : 对生菜而言,第i 次实验的产量,1,2,,i n =1Ni Q : 对土豆而言,与1i N 对应的第i 次实验的产量,1,2,,i n = 1Pi Q : 对土豆而言,与1i P 对应的第i 次实验的产量,1,2,,i n =1Ki Q : 对土豆而言,与1i K 对应的第i 次实验的产量,1,2,,i n = 2Ni Q : 对生菜而言,与2i N 对应的第i 次实验的产量,1,2,,i n = 2Pi Q : 对生菜而言,与2i P 对应的第i 次实验的产量,1,2,,i n = 2Ki Q : 对生菜而言,与2i K 对应的第i 次实验的产量,1,2,,i n = 1i N : 对土豆而言,第i 次实验的N 的用量,1,2,,i n = 2i N : 对生菜而言,第i 次实验的N 的用量,1,2,,i n = 1i P : 对土豆而言, 第i 次实验的P 的用量,1,2,,i n = 2i P : 对生菜而言, 第i 次实验的P 的用量,1,2,,i n = 1i K : 对土豆而言, 第i 次实验的K 的用量,1,2,,i n = 2i K : 对生菜而言, 第i 次实验的K 的用量,1,2,,i n = .模型建立1. 先对实验数据,作出散点图,直观分析产量与施肥量的变化趋势及关系. 从散点图来看,三种营养素的施肥量与产量之间存在非线性关系,尤其,氮肥的施用量与产量之间存在明显的二次关系,故可考虑建立三种营养素的施肥量与产量之间的一元二次回归模型.2. 三种营养素的施肥量与产量之间的一元二次回归模型21101111211,1,2,,Ni i i Ni Q a a N a N i n ε=+++=21101111211,1,2,,Pi i i Pi Q b b P b P i n ε=+++= 21101111211,1,2,Ki i i Ki Q c c K c K i n ε=+++= 22202112212,1,2,,Ni i i Ni Q a a N a N i nε=+++=22202112212,1,2,,Pi i i Pi Q b b P b P i n ε=+++= 22202112212,1,2,,Ki i i Ki Q c c K c K i n ε=+++=对上述模型,由已知实验数据,利用Mathematica 软件编程计算可得回归方程.但是,考虑到作物的产量是各种营养素综合作用的结果,而以上建立的仅仅是一元回归模型,故须对模型进行改进.3. 包含所有变量的全回归模型21011111121111111i N i P i K i NN i NP i iNK i i PP i PK i i KK i iQ a a N a P a K a N a N P a N K a P a P K a K ε=++++++++++由全回归模型的求解结果(如表4.2.7)及残差可看出,残差均匀分布在零点两侧,无系统偏差,模型基本合适.但注意到,作物产量受各种营养素的影响不是同样的,且营养素两两之间的交互作用对产量的影响也不是同等的,故需对变量进行选择,进行逐步回归.4. 逐步回归模型利用MA TLAB 中的逐步回归函数stepwise 对变量进行逐步回归,回归结果表明:① 对于土豆,首先进入模型的是N 与K 的交互作用项,其次是NN 项; ② 对于生菜,首先进入模型的是P ,其次是NN 项. 模型求解对以上三个模型的求解,采用MA TLAB 软件进行.结果如下:1. 一元回归模型的结果及分析对土豆而言,N的施肥量与产量的回归方程系数:表4.2.2常数项一次项二次项14.7416 0.1972 -0.0003对土豆而言,P的施肥量与产量的回归方程系数:表4.2.3常数项一次项二次项32.9161 0.0719 -0.00013783对土豆而言,K的施肥量与产量的回归方程系数:表4.2.4常数项一次项二次项24.4144 0.0749752 -7*10^(-5)对生菜而言,N的施肥量与产量的回归方程系数:表4.2.5常数项一次项二次项79.2501 3.516472 -0.0106883对生菜而言,P的施肥量与产量的回归方程系数:表4.2.6常数项一次项二次项6.87795 0.0606347 -5.5*10^(-5)对生菜而言,K的施肥量与产量的回归方程系数:表4.2.7常数项一次项二次项16.2329 0.00511548 -7.2*10^(-7)以上一元回归模型结果表明:二次项系数较小且为负值,说明产量先随施肥量增加而增加,达到一个峰值,然后,随施肥量增加而下降.说明,在一定范围内,施肥量对产量有促进作用,这对我们在生产管理中,科学、有效、经济地确定施肥量具有指导意义.2. 对土豆的全回归模型的结果及分析表4.2.8常数项一次项交互作用项 二次项N P K NP NK P KNNPPKK15.20930.07497520.02654780.02844310.0002224940.0001738970 -000325779-0.00017 1209-0.000067809结果表明:一次项系数由大到小依次是N ,K ,P ,交互作用项依次是NP ,NK ,说明我们在生产管理中,不但要重视每中肥料的单独作用,还要充分重视肥料间的交互作用,这样才能在生产中充分发挥肥料对产量的促进作用.3. 逐步回归模型的结果对于土豆,首先进入模型的是N 与K 的交互作用项,其次是NN 项;对于生菜,首先进入模型的是P ,其次是NN 项.回归结果表明,对土豆等块茎类作物,NK 的交互作用对作物的生长起显著作用,对生菜等叶类作物,P 的作用非常显著,其次,N 的作用对各种作物都是重要的.得到的结果符合作物栽培学原理与实际经验. 研究性问题以上是从产量的角度考虑其与施肥量的关系.对此问题,还可以从经济学的角度考虑以下问题:1. 研究产量与肥料用量的变化关系,确定各种肥料的边际用量;2. 考虑到各种肥料的成本不同,为了达到最大效益,确定各种肥料用量的 最佳组合.§4-3 AF 螨虫和APF 螨虫的区分问题问题描述现有9只AF 螨虫和6只APF 螨虫的触角长与翼长数据: AF :(1.24,1.72),(1.36,1.74),(1.38,1.64),(1.38,1.82),(1.38,1.90),(1.40,1.70),(1.48,1.82),(1.54,1.82),(1.56,2.08).APF :(1.14,1.78),(1.18,1.96),(1.20,1.86),(1.26,2.00),(1.28,2.00),(1.30,1.96).对以上数据,制定一种方法正确区分螨虫;依据确立的方法,判别新样品(1.4,1.80),(1.28,1.84),(1.40,2.04)的归属;若AF 是宝贵的益虫,APF 是某疾病的载体,是否修改分类方法. 问题分析此问题属于判别分析问题,即根据样本的指标(螨虫的触角长与翼长),建立判别规则,来判断样本来自哪个总体(AF ,APF ).判别分析的一般模型可这样描述:设有k 个总体12,,,k G G G ,它们的分布分别是()()12,,,F x F x ()k F x ,均为p 维分布,制定判别规则,对给定的新样品,确定它来自哪个总体.判别分析的方法有很多,如距离判别,Bayes 判别,Fisher 判别等.这里,我们采用距离判别. 模型假设1. 两种螨虫的触角长与翼长服从二维正态分布()211,N μ∑,()222,N μ∑,1212,μμ≠∑≠∑;2. 判别时仅考虑触角长与翼长两项指标,不考虑其它指标. 模型建立设AF 螨虫为总体1G ,APF 螨虫为总体2G ,()1211,G N μ∑ ,()2222,G N μ∑ .1. 首先对两总体的均值进行显著性检验,即检验:12μμ=,当其有显著性差异时再进行判别.2. 给出样品X 到总体i G 的距离(这里采用马氏距离)()()21',1,2i i i i d X X i μμ-=-∑-=3. 建立判别函数及判别规则 判别函数为()2221W X d d =-判别规则为()()1200W X X G W X X G ⎧>∈⎪⎨<∈⎪⎩若,则若,则模型求解1. 首先,对两总体的均值进行显著性检验,即检验:12μμ=,利用MATLAB软件统计工具箱中的kstest2函数检验两总体分布是否相同,利用ttest2检验均值是否相同,检验结果表明:两总体分布相同,均值存在显著性差异,故可继续进行判别.2. 利用已知样本数据,计算判别函数值.由于两总体均值与方差未知,采用极大似然估计,即()1ˆˆ,,1,21i i i ixx i X L i n μ=∑==- 最终的判别函数为:()1212, 2.935829.1128190.293W x x x x =-+-.对最初的两类样本,代入,回判结果如下:表4.3.1样本序号样本值 原属类别 判别函数值 判定类别 1 (1.24,1.72) AF 0.433676 AF 2 (1.36,1.74) AF 3.54663 AF 3 (1.38,1.64) AF 6.03181 AF 4 (1.38,1.82) AF 2.60654 AF 5 (1.38,1.90) AF 1.08419 AF 6 (1.40,1.70) AF 5.47231 AF 7 (1.48,1.82) AF 5.51782 AF 8 (1.54,1.82) AF 7.26459 AF 9 (1.56,2.08) AF 2.89922 AF 10 (1.14,1.78) APF -3.61936APF 11 (1.18,1.96) APF -5.88012APF 12 (1.20,1.86) APF -3.39494 APF 13 (1.26,2.00) APF -4.31227 APF 14 (1.28,2.00) APF -3.73002 APF 15(1.30,1.96)APF-2.38659APF对新样品的判别结果:表4.3.2样本序号 样本值 判别函数值 判定类别 16 (1.4,1.80) 3.56938AF 17 (1.28,1.84) -0.685328 APF 18(1.40,2.04)-0.997652APF结果分析对制定的判别函数及判别规则,用已知的经验样本进行计算,验证,结果表明,回判正确率100%,判别规则及方法有效. 研究性问题在判别分析中,应考虑误判损失,若AF 是宝贵的益虫,APF 是某疾病的载体,则本属于APF 而误判为AF 的损失要大于本属于AF 而误判为APF 的损失,则应提高进入AF 的阀值(即判别样本落入某一类的判别函数临界值,如 以上判别样本属于AF 的阀值为0).§4-4 Chesapeake 海湾的收成预测问题时间序列分析的方法来源人们对生产实践中所产生的历史数据的分析.人们期望通过这些数据获得对未来某个较近时间的数据的估计.一般地,我们所得到的数据可以写为下面的数据序列()()()1122,,,,,,n n x y x y x y (4.4.1)这里,i x 是n 维向量,i y 实值标量.我们可以这样想象:历史数据(4.1.1)是按照某种具有固定生产程序的机器所产生,对于同一个x ,所对应的y 是按照一个条件分布密度函数 ()|f t x (4.4.2)产生的,因而y 的期望值为()()|y tf t x dt x ϕ==⎰ (4.4.3)因此,从理论上,我们要寻找的依赖关系应当是这个函数关系(4.4.3).这个函数关系称为回归函数.我们的目的是借助于概率统计的方法给出实值变量y 与n 维向量x 之间的回归函数或者估计,并且给出这个函数或者估计的误差限.寻找这样的函数关系或者估计的方法是较多的.时间序列预测[4,8]的一些方法:如回归估计、平稳时间序列的滑动平均、自回归、自回归滑动平均模型、Markov链等可以用来处理预测预报问题,也可以使用现代基于支持向量机[5-6]的非参数统计的线性回归或非线性回归的方法.本节将利用一般的基于最小二乘法的参数回归估计方法、以及基于支持向量机回归的非参数统计学习等方法来解决Chesapeake 海湾的收成预测问题,并主要介绍非平稳时间序列的预测问题.在这里我们不过多地拘泥于理论的陈述,具体的细节,请读者参阅相关资料.问题描述1992年《每日评论》(Daily Press)报告了过去50年中收集到的Chesapeake 海湾海产品收成方面的数据.我们将考察几种场合,并使用Chesapeake海湾的商贸行业提供的如下数据:(a)收获蓝鱼的观测数据表4.4.1,(b)收获蓝蟹的观测数据表4.4.1,回答下面两个问题:问题1:请预测1995年收获的蓝鱼磅数;问题2:请预测1995年收获的蓝蟹磅数.表4.4.1 Chesapeake海湾海产品收成方面的数据[11]年蓝鱼(磅)蓝蟹(磅)年蓝鱼(磅)蓝蟹(磅)1940 15000 100000 1970 290000 4400000 1945 15000 850000 1975 650000 4660000 1950 250000 133**** **** 1200000 4800000 1955 275000 2500000 1985 1500000 4420000 1960 270000 3000000 1990 2750000 5000000 1965 280000 3700000(注1磅=453.6g.)问题分析直观上,这不是一个平稳时间序列.因此,我们不能采用处理平稳时间序列的模型[8]进行预测.但是,我们可以使用多项式回归估计的方法.另外,我们也可以使用支持向量机回归[9,10]的方法来解决问题1和问题2.因为,支持向量机的方法对于具有小样本的数据估计问题也具有很好的效果.由这样,我们就可以采用相应的方法,分别求解这两个问题. 模型假设(1)假设对于固定的年度x 所收获的两类海产品都是按照一定的概率密度函数产生的.(2)在未来的年度,这样的统计规律也不发生太大的变化. 模型建立为了能够对问题的中数据变化趋势有一个清楚地直观感觉,我们将这些数据用Excel 画在坐标系中进行观察.可以看出,我们不能用线性回归的方法来求解.下面,根据我们刚才的分析,首先采用多项式回归的方法来建模,然后再用支持向量机回归的方法来建模.模型1 为了讨论问题的方便,我们对年度重新编号为1211,,,x x x ,另外,给蓝鱼和蓝蟹分别编号为1,2.我们采用五次多项式回归估计(当然,可以采用其它阶数的回归多项式).设回归函数的近似形式是如下k J 次多项式()0,1,2kJ k j j j y a x k ===∑ (4.4.4)模型2 由于这里的数据较少,用支持向量机回归的方法是最合适的.就是要寻找一个回归函数()()*1,,1,2kl k k k k kxj j j j y K x x b k αα==-+=∑ (4.4.5)这里,k l 是第k 类海产品的样本数,()()()12,K x x 是称为核函数,其选择方法可以参考文献[9-10],这里,我们选择径向基核函数()()()()()21212,x x K x x eσ--= (4.4.6)而()*,1,2,1,2,,11k kj j k j αα== 都是非负数,其意义见参考文献[10].其中,()*,,1,2,1,2,,11k k k j j bk j αα== 是下面优化问题的最优解()()()()()()***,,1**11*1*1min,2..00,,1,2,,1,2,,k l li i kkkl k k k ki i j j i j R R i j l l k k k k iii ii i i l k k ii i k k i i k kK x x y s tCk i j l l ααααααεαααααααα∈∈====--++---=≤≤==∑∑∑∑ (4.4.7)ε是事先选定的一个正数,它确定了回归函数(4.4.5)与样本函数的差别大小.详细的思想请参看文献[9,10].我们选定的支持向量方法是解决模式识别和回归估计问题的通用方法,是建立在三大统计定律上的现代非参数统计学习方法(见文献[9,10]).我们不需要回归函数或者识别函数的太多的信息,只要这些数据就可以了,算法会将包含在数据中的信息提取出来而用于预测或者模式识别.这种方法对于小样本问题同样适用. 模型求解模型1的求解 我们关键是如何选择(),1,2,,,1,2k j k a j J k == .显然,最小二乘法的思想是一个不错的选择.建立下面的最优化问题()()()2,0,1,,01min ,1,2kl k k k j J k L k t a j j J l j l j y k a t ===⎛⎫-= ⎪⎝⎭∑∑ (4.4.8) 根据极值的必要条件,我们得到,回归多项式满足的代数方程为()011,0,1,,,1,2k k kJ L L k i j ij l ll k j l l a t y t i J k +===⎛⎫=== ⎪⎝⎭∑∑∑ (4.4.9) 我们通过MA TLAB 编程,运行后,得到蓝鱼和蓝蟹的预测多项式分别是23454.8424 6.8984 2.44240.40360.03250.0012y x x x x x =-+-+-+ (4.4.10)23451.1729 1.75720.63320.16140.01750.0006y x x x x x =-+-+-+ (4.4.11)用指数函数和多项式拟合的方法,可以得到蓝鱼和蓝蟹的预测公式分别是()5.28571 1.4635,1,2,,11,xy x =⋅= (4.4.12)1,2,,11,.y x == (4.4.13)将原始数据与预测值分别画在同一坐标系中,可以观察到一些现象.结果发现,用多项式预测具有随机波动的数值具有很大的偏离实际问题的本意(如对蓝蟹的多项式预测函数),在后面的时段的预测效果可能让人难以接受,即对于长期预测的效果可能比较差.但是对于短期的预测效果还是比较好的.为此,我们可以采用用于处理预测的当前的流行方法,即基于支持向量机的回归预测的方法[9,10].这就是我们采用模型2的原因之一.模型2的求解 模型2涉及一个高级的模式识别和回归估计的方法[9-10].我们直接求解优化问题,并将上述的两种方法预测的结果与支持向量机回归预测得到结果进行比较(图4.4.2和图4.4.3).对蓝鱼得到的预测函数(核函数中选择的2 5.0000002σ=)是 ()()()()()()()()()()12335789101163.60123.28,172.68,236.90,186.13,145.70,109.91,265.79,278.76,227.47,64.44,y K x x K x x K x x K x x K x x K x x K x x K x x K x x K x x =-+-+-+-+-+ (4.4.14)对蓝蟹得到预测函数(核函数中选择的25.6σ=)为()()()()()()157910115.2083 4.9843, 2.1754,0.5785,0.3656,0.8640,0.6628,y K x x K x x K x x K x x K x x K x x =--+--+ (4.4.15)结果分析从图4.4.2和图4.4.3,我们清楚地发现,本文对于蓝蟹的多项式预测公式对原数据的拟合显然优于文献[11]的根式函数的预测结果.我们在实际问题中应该尝试使用不同次幂的回归多项式,以达到最佳的拟合.通过尝试我们发现3次多项式回归可能要更好点.同学们通过自己编程,体验研究的乐趣.对于蓝鱼模型和蓝蟹模型,我们得到的预测结果画在图4.4.5中.结果分析从图4.4.4和图4.4.5可以看出,支持向量机回归的方法得到的结果最好,对于本问题来说,多项式回归预测的方法不比文献[11]的方法好.但是,如果选择合适的多项式的次数,也许会得到较好的预测,希望有兴趣的同学试试.对于没有支持向量机理论和方法的大学生来说,基于最小二乘法的多项式回归还是比较合适的.当然,有兴趣的同学可以参看文献[9-10]学习支持向量机的理论和方法.研究性问题读者可以尝试选择合适的回归多项式的阶使得预测更合理,或者根据观察的数据散点图,选用你认为更好的函数类型进行拟合.能否依据所给数据采用微分方程建模方法求解预测问题,或者利用最近几次历史数据值或预测值,预测以后较近时段的数据.这些都是非常有意思的问题.你会从中体会到研究的乐趣.§4-5 随机模拟问题对于研究对象的数量关系过于复杂或提出的解释性(定性或定量)模型难以处理时,研究者很难得到一个能充分说明问题的符号分析模型,但又必须对研究对象的行为(随机依赖关系或者确定性关系)做出预报时,研究者可以在某种给定条件下进行多次重复的实验来收集数据,以获得这样的随机依赖关系.这种方法称为随机模拟方法[7,11].前面对于变量之间的随机依赖关系的预报是直接利用给定数据,采用某种对回归函数的近似估计来实现的.但是,在没有这些数据情况下,我们只能采用模拟实验的方法.在许多实际问题中,具体地进行实验来获得所需要数据是不切实际的.比如,为了确定人类对某种药物的敏感性,我们可以用小白鼠或者猴子进行模拟试验;为了能够获得人体各个器官对失重环境的适应性,我们可以进行模拟太空失重环境;为了测试电梯的某种运行方式是否合理(如停偶数上层还是停奇数层),我们不能在各种运行方式下进行多次实验,这样对顾客多有惊扰.这里的几个例子,前两个是可以有替代的试验对象,后一个则没有.在这样的情况下,我们必须设计出能够模拟实际环境或者条件的理论上的模拟仿真实验,来分析研究对象的随机依赖关系或者确定性关系.这里介绍的前两个例子也是模拟,它们是一种真实环境的模拟.而后者是借助于计算机仿真的模拟,这种模拟方法通常称为蒙特卡洛(Monete Carlo )方法.这里仅介绍这种方法.蒙特卡洛(Monete Carlo )方法分为确定性行为模拟和随机行为模拟.我们分别举例说明.问题1:曲线下的面积计算-确定性问题问题描述我们要计算由曲线[]()(),,y f x x a b =∈与直线x a =、x b =以及x 轴所围成的曲边梯形的面积A [11],如图4.5.1. 模型的建立所求的面积为()baf x dx ⎰(4.5.1)这个面积可以通过下面的分析给出求解的近似公式:在矩形[],;,a b Q M 中随机产生点(),P x y (通过产生随机数来获得,x y ),统计出落在曲线下方的随机点。
经济问题中的概率统计模型及应用摘要:概率统计的研究拓展使其可以应用在经济领域,解决一些现实问题,而其普遍性是不容忽视的。
实践证明,概率统计在与经济问题向结合的过程中体现了其特有的指导性作用,利用合理的概率分析可以获得较好的预测和决策效果。
关键词:概率统计;统计模型;市场调研;风险决策;市场预测中图分类号:f22 文献标识码:a 文章编号:1009-0118(2011)-06-00-01一、概率统计模型在市场调查中的应用(一)对样本容量的评价在市场调研中,样本的容量是最为基础的数据,其关系到市场调研的精确度和企业效益关系的重要的指标。
样本的容量如果估算过大就会造成调查费用的增加,同时也给调研的人力资源投入和管理费用增加负担,从而难以体现出抽样调查的优势,而变为撒网式的调研;而容量过小则会造成样品没有代表性,增加了样本抽样的误差。
所以在调研中确定样本容量是对调研过程和成果都会产生影响的重要因素。
从统计学的角度看,样本容量需要关注的层面有:置信度、允许误差、总体标准差等。
具体的一个调研项目而言,项目的总体预算费用将构成一个样本容量的上限。
容量的增加将形成对上限的压力,如果导致超载则会让委托方受到损失。
因此,在实际的调研设计中,首先应当根据费用所形成的函数对样本进行评估。
其中样本的容量就可以解释为与成本相关的函数,而利用此函数就可以形成概率、置信水平、允许误差相关的样本容量的数学公式,并以此来确定样本的最终的容量,此种计算的方式和评估模式是建立在成本支出的基础上的,评价和估算,其中概率在这里成为了一个重要的因子。
(二)随机抽样的方式在现实的调查过程中,主要是采用的随机抽样的方式,其具体方式有简单随机、层次抽样、整群随机、等距离抽样等。
其中利用层次抽样的方式是现代统计学中常见的方式,也就是分类抽样的方式。
其步骤:按照相关的研究内容对各个调研对象进行分类;然后按照比例或者不按照比例,在每个类别中进行抽样的调研,可以采用简单随机抽取或者机械抽取,而常用的是在按照比例的基础上的抽取。