短语、直接短语和句柄
- 格式:ppt
- 大小:1.99 MB
- 文档页数:81
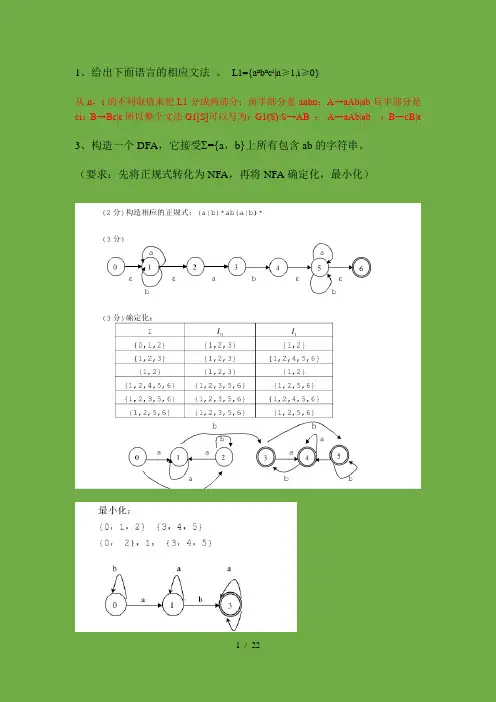
1、给出下面语言的相应文法。
L1={a n b n c i|n≥1,i≥0}从n,i的不同取值来把L1分成两部分:前半部分是anbn:A→aAb|ab后半部分是ci:B→Bc|ε所以整个文法G1[S]可以写为:G1(S):S→AB;A→aAb|ab;B→cB|ε3、构造一个DFA,它接受 ={a,b}上所有包含ab的字符串。
(要求:先将正规式转化为NFA,再将NFA确定化,最小化)4、对下面的文法G:E →TE ’ E ’→+E|ε T →FT ’ T ’→T|εF →PF ’ F ’ →*F ’|ε P →(E)|a|b|∧(1)证明这个文法是LL(1)的。
(2)构造它的预测分析表。
(1)FIRST(E)={(,a,b,^}FIRST(E')={+,ε}FIRST(T)={(,a,b,^}FIRST(T')={(,a,b,^,ε}FIRST(F)={(,a,b,^}FIRST(F')={*,ε}FIRST(P)={(,a,b,^}FOLLOW(E)={#,)} FOLLOW(E')={#,)}FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#}FOLLOW(F')={(,a,b,^,+,),#}FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φFIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法. (3)+*()a b ^ #EE TE →'E TE →' E TE →' E TE →'E' '→+E E'→E ε'→E εTT F T →'T F T →' T F T →' T F T →'T' '→T ε'→T T '→T ε '→T T '→T T '→T T '→T εFF P F →'F P F →' F P F →' F P F →'F' '→F ε '→'F F * '→F ε '→F ε '→F ε '→F ε '→F ε '→F εPP E →()P a → P b → P →^5、考虑文法: S →AS|b A →SA|a (1)列出这个文法的所有LR(0) 项目。

短语,直接短语,句柄
短语指的是一个或多个单词构成的语言单位,可以作为语句的组成部分。
例如,“大红花”、“跳舞的小狗”、“在车站等车”等都是短语。
直接短语也是短语的一种,指的是在句子中作为主语或宾语等的短语。
例如,在句子“小明喜欢看电影”中,“看电影”就是一个直接短语。
句柄则是一种特殊的直接短语,指的是在句子中作为句子核心的短语。
例如,在句子“我喜欢吃苹果”中,“吃苹果”就是一个句柄。
在语言学中,短语、直接短语和句柄都是非常重要的概念,对于语言的理解和分析都具有重要的意义。
- 1 -。

《编译原理》课后习题答案第三章第3 章文法和语言第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2 题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0 开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4 题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
盛威网()专业的计算机学习网站 1《编译原理》课后习题答案第三章答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5 题写一文法,使其语言是偶正整数的集合。
要求:(1) 允许0 打头;(2)不允许0 打头。
答案:(1)允许0 开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0 开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6 题已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
(5)i+(i+i)(6)i+i*i盛威网()专业的计算机学习网站 2 《编译原理》课后习题答案第三章答案:<表达式><表达式> + <项><因子><表达式><表达式> + <项><因子>i<项><因子>i<项><因子>i( )(5) <表达式>=><表达式>+<项>=><表达式>+<因子>=><表达式>+(<表达式>)=><表达式>+(<表达式>+<项>)=><表达式>+(<表达式>+<因子>)=><表达式>+(<表达式>+i)=><表达式>+(<项>+i)=><表达式>+(<因子>+i)=><表达式>+(i+i)=><项>+(i+i)=><因子>+(i+i)=>i+(i+i)<表达式><表达式> + <项><项> * <因子><因子> i<项><因子>ii(6) <表达式>=><表达式>+<项>=><表达式>+<项>*<因子>=><表达式>+<项>*i=><表达式>+<因子>*i=><表达式>+i*i=><项>+i*i=><因子>+i*i=>i+i*i盛威网()专业的计算机学习网站 3《编译原理》课后习题答案第三章第7 题证明下述文法G[〈表达式〉]是二义的。

第7 题证明下述文法G[〈表达式〉]是二义的。
〈表达式〉∷=a|(〈表达式〉)|〈表达式〉〈运算符〉〈表达式〉〈运算符〉∷=+|-|*|/答案:可为句子a+a*a 构造两个不同的最右推导:最右推导1 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉a=>〈表达式〉* a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a最右推导2 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a第8 题文法G[S]为:S→Ac|aB A→ab B→bc该文法是否为二义的?为什么?答案:对于串abc(1)S=>Ac=>abc (2)S=>aB=>abc即存在两不同的最右推导。
所以,该文法是二义的。
或者:对输入字符串abc,能构造两棵不同的语法树,所以它是二义的。
第9 题考虑下面上下文无关文法:S→SS*|SS+|a(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树。
(2)G[S]的语言是什么?答案:(1)此文法生成串aa+a*的最右推导如下S=>SS*=>SS*=>Sa*=>SS+a*=>Sa+a*=>aa+a*(2)该文法生成的语言是:*和+的后缀表达式,即逆波兰式。
第10 题文法S→S(S)S|ε(1) 生成的语言是什么?(2) 该文法是二义的吗?说明理由。
答案:(1)嵌套的括号(2)是二义的,因为对于()()可以构造两棵不同的语法树。
第11 题令文法G[E]为:E→T|E+T|E-T T→F|T*F|T/F F→(E)|i证明E+T*F 是它的一个句型,指出这个句型的所有短语、直接短语和句柄。

编译原理试题及参考答案课程测试试题(04A卷)I、命题院(部):数学与计算机科学学院II、课程名称:编译原理III、测试学期:2006-2007 学年度第1 学期IV、测试对象:数计、国交学院计科专业2004 级1、2、国交班V、问卷页数(A4):3 页VI、答卷页数(A4):4 页VII、考试⽅式:闭卷(开卷、闭卷或课程⼩论⽂,请填写清楚)VIII、问卷内容:(请⽼师在出题时安排紧凑,填空题象征性的留出⼀点空格,学⽣将所有的答案做在答题纸上的规定位置,并写清楚⼤题、⼩题的题号)⼀、填空题(共30分,30个空,每空1分)1、典型⾼级程序设计语⾔编译系统的⼯作过程⼀般分为六个阶段,即词法分析、语法分析、语义分析、中间代码⽣成、、⽬标代码⽣成。
编译阶段的两种组合⽅式是组合法和按遍组合法,这两种组合⽅式的主要参考因素都是的特征。
2、Chomsky将⽂法按其所表⽰语⾔的表达能⼒,由⾼往低分为四类:0型,1型,2型,3型⽂法。
其中,2型⽂法也称,它的所有规则α→β都满⾜:α∈,β∈ ((V N∪V T) *且,仅当β= ε时例外。
3、现代编译系统多采⽤⽅法,即在语法分析过程中根据各个规则所相联的或所对应的语义⼦程序进⾏翻译的办法。
该⽅法使⽤为⼯具来说明程序设计语⾔的语义。
4、构造与NFA M等价的正规⽂法G的⽅法如下:(1)对转换函数f(A,a)=B或f(A,ε)=B,改成形如或的产⽣式;(2)对可识别终态Z,增加⼀个产⽣式:。
5、代码⽣成要考虑的主要问题:充分利⽤的问题、选择的问题、选择的问题。
6、设有穷⾃动机M=(K,∑,f,S,Z),若当M为时,满⾜z0∈f(S,α)且z0∈Z,或当M为时,满⾜f(S,α)=P∈Z,则称符号串α∈∑*可被M所。
7、符号表中每⼀项对应⼀个多元组。
符号表项的组织可分为组织、组织、组织等。
8、对于A∈?VN 定义A的后续符号集:FOLLOW(A)={a|S=*>uAβ,a∈VT,且a∈,u∈VT*,β∈V+;若,则#∈FOLLOW(A)。


语法树、短语、直接短语、句柄、素短语、最左素短语乘积设A和B是符号串的集合,则A和B的乘积定义为AB = {xy | x∈A and y∈B}。
eg:若A={a,b},B={b,c},则AB = {ab,ac,bb,bc}。
对任意符号串集合A,有{ε}A = A{ε} = A。
幂运算设A是符号串的集合,则A的幂运算定义为A0 = {ε} A1 = A An = AAn-1(n>0)eg:若A={0,1},则A0={ε},A1={0,1},A2={00,01,10,11}。
4)正闭包与闭包设A是符号串的集合,则集合A的正闭包A+和闭包A*定义为A+ = A1∪A2∪…∪An∪…A* = A0∪A1∪…∪An∪…eg:若A={0,1},则A+={0,1,00,01,10,11,000,001,…},A*={ε,0,1,00,01,10,11,000,001,…}。
推导:若存在⼀个直接推导序列:α0⇒α1⇒α2⇒…⇒αn,则称这个序列是⼀个从α0⾄αn的长度为n的推导。
当n>0时,α0⾄αn的推导记为α0 ⇒+ αn,表⽰从α0出发,经过1步或者若⼲步可推导出αn。
当n≥0时,α0⾄αn的推导记为α0 ⇒* αn,表⽰从α0出发,经过0步或者若⼲步可推导出αn。
句型和句⼦设有⽂法G[Z],Z是⽂法G的开始符号。
1)句型:若Z ⇒* x,x∈(VN∪VT)*,则称符号串x为⽂法G[Z]的句型。
2)句⼦:若Z ⇒* x,x∈VT*,则称符号串x为⽂法G[Z]的句⼦。
3)句⼦⼀定是句型,句型不⼀定是句⼦。
语⾔1)定义:⽂法G[Z]产⽣的所有句⼦的集合称为⽂法G所定义的语⾔,记为L(G[Z]),简写为L(G)。
L(G)={x| Z ⇒+ x且x∈VT*}。
2)语⾔L(G)是VT*的⼦集。
⽂法递归1)定义:对于⽂法中的任⼀⾮终结符,若能建⽴⼀个推导过程,在推导所得的符号串中⼜出现该终结符本⾝,则称⽂法是递归的。



中南大学网络教育课程考试复习题及参考答案编译原理一、判断题:1.一个上下文无关文法的开始符,可以是终结符或非终结符。
( )2.一个句型的直接短语是唯一的。
( )3.已经证明文法的二义性是可判定的。
( )4.每个基本块可用一个DAG表示。
( )5.每个过程的活动记录的体积在编译时可静态确定。
( )6.2型文法一定是3 型文法。
( )7.一个句型一定句子。
( )8.算符优先分析法每次都是对句柄进行归约。
( )9.采用三元式实现三地址代码时,不利于对中间代码进行优化。
( )10.编译过程中,语法分析器的任务是分析单词是怎样构成的。
( )11.一个优先表一定存在相应的优先函数。
( )12.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
( )13.递归下降分析法是一种自下而上分析法。
( )14.并不是每个文法都能改写成 LL(1)文法。
( )15.每个基本块只有一个入口和一个出口。
( )16.一个 LL(1)文法一定是无二义的。
( )17.逆波兰法表示的表达试亦称前缀式。
( )18.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
( )19.正规文法产生的语言都可以用上下文无关文法来描述。
( )20.一个优先表一定存在相应的优先函数。
( )21.3型文法一定是 2型文法。
( )22.如果一个文法存在某个句子对应两棵不同的语法树,则文法是二义性的。
( )二、填空题:1.( )称为规范推导。
2.编译过程可分为(),(),(),()和()五个阶段。
3.如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是()。
4.从功能上说,程序语言的语句大体可分为()语句和()语句两大类。
5.语法分析器的输入是(),其输出是()。
6.扫描器的任务是从()中识别出一个个()。
7.符号表中的信息栏中登记了每个名字的有关的性质,如()等等。
8.一个过程相应的DISPLAY表的内容为()。

在此深情而热烈的感谢沈仲秋同学的大力支持和帮助,同时希望本文档对各位有些帮助。
一1、画出编译程序的总体结构图,简述其部分的主要功能。
[答案]编译程序的总框图见下图。
图编译程序的总体结构图其中词法分析器,又称扫描器,它接受输入的源程序,对源程序进行词法分析,识别出一个个的单词符号,其输出结果上单词符号。
语法分析器对单词符号串进行语法分析(根据语法规则进行推导或归纳),识别出程序中的各类语法单位,最终判断输入串是否构成语语义分析及中间代码产生器,按照语义规则对语法分析器归纳出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间优化器对中间代码进行优化处理。
一般最初生成的中间代码执行效率都比较低,因此要做中间代码的优化,其过程实际上是对中间代码目标代码生成器把中间代码翻译成目标程序。
中间代码一般是一种与机器无关的表示形式,只有把它再翻译成与机器硬件相关的机器能表格管理模块保持一系列的表格,登记源程序的各类信息和编译各阶段的进展状况。
编译程序各个阶段所产生的中间结果都记录在表格出错处理程序对出现在源程序中的错误进行处理。
如果源程序有错误,编译程序应设法发现错误,把有关错误信息报告给用户。
编译程2、计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?[答案]计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。
像Basic之类的语言,属于解释型的高级语言。
它们的特点是计算机并不事先对高级语言进行全盘翻译,将其变为机器代码,而是每读总而言之,是边翻译边执行。
像C,Pascal之类的语言,属于编译型的高级语言。
它们的特点是计算机事先对高级语言进行全盘翻译,将其全部变为机器代码,再统1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。
1、给出算符优先文法的定义,算符优先表是否都存在对应的优先函数?给出优先函数的定义。
设有一不含ε产生式的算符文法G,如果对任意两个终结符对a,b之间至多只有、和h三种关系的一种成立,则称G一个算符优先文法。
算符优先关系表不一定存在对应的优先函数优先函数为文法字汇表中2、考虑文法G[T]:T→T*F|FF→F↑P|PP→(T)|i证明T*P↑(T*F)是该文法的一个句型,并指出直接短语和句柄。
首先构造T*P↑(T*F)的语法树如图所示。
句型T*P↑(T*F)的语法树由图可知,T*P↑(T*F)是文法G[T]的一个句型。
直接短语有两个,即P和T*F;句柄为P。
3、文法G[S]为:S→SdT | TT→T<G | GG→(S) | a试给出句型(SdG)<a的短语、简单(直接)短语、句柄和最左素短语。
句型(SdG)<a的短语:(SdG)<a 、(SdG)、SdG 、G 、a简单(直接)短语:G 、a句柄:G最左素短语:SdG4、目标代码有哪几种形式?生成目标代码时通常应考虑哪几个问题?三种形式:可立刻执行的机器语言代码;汇编语言程序;待装配的机器语言代码模块考虑的问题包括:每一个语法成分的语义;目标代码中需要哪些信息,怎样截取这些信息。
5、符号表的作用是什么?符号表的查找的整理技术有哪几种?作用:登记源程序中出现的各种名字及其信息,以及编译各阶段的进展状况。
主要技术:线性表,对折查找与二叉树,杂凑技术。
1、实现高级语言程序的途径有哪几种?它们之间的区别?计算机执行用于高级语言编写的程序主要有两种途径:解释和编译。
在解释方式下,翻译程序并不对高级语言进行彻底的翻译,而是读入一条语句,就解释其含义并执行,然后再读入下一条语句,再执行。
在编译方式下,翻译程序先对高级语言进行彻底的翻译并生成目标代码,然后再对目标代码进行优化,即对源程序的处理是先翻译后执行。
从速度上看,编译方式下,源程序的执行比解释方式下快,但在解释方式下,有利于程序的调试。
●对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。
(1) else 没匹配的 if (2)数组下标越界(3)使用的函数没定义(4)在数中出现非数字字符解:●文法 G=({A,B,S},{a,b,c},P,S),其中 P:S → Ac|aB,A → ab,B → bc。
写出 L(G[S]) 的全部元素。
解:L(G[S])={abc}●文法 G[N]:N → D|ND,D → 0|1|2|3|4|5|6|7|8|9。
G[N]的语言是什么。
解:长度至少为 1 的任意的数字串。
● 为只包含数字、加号和减号的表达式,例如 9-2+5 , 3-1 , 7 等构造一个文法。
解:● 已知文法 G[Z]:Z → aZb ,Z → ab 。
写出 L(G[Z]) 的全部元素。
解:L(G[Z]) = { a nb n| n ≥1 }●写一文法,使其语言是偶正整数的集合,分别要求: (1)允许0打头;(2)不允许0打头。
解:(1)文法 G1[S] 为:S → AB , A → ε|D|DA , B → 0|2|4|6|8, D → 0|1|2|3|4|5|6|7|8|9 (2)文法 G2[S] 为:S → C , S → EAB , A → ε|D|DA , B → 0|2|4|6|8, C → 2|4|6|8 D → 0|1|2|3|4|5|6|7|8|9, E → 1|2|3|4|5|6|7|8|9●以下文法是否为二义文法?解:由于对于文法 G[S] 的一个句子abc ,存在以下两个不同的最右推导: 最右推导 1:;最右推导 2:。
所以该文法为二义文法。
●考虑以下的上下文无关文法:(1)说明 aa+a* 的推导过程,并构造相应的语法树。
(2)该文法描述的语言是什么? 解:(1);(2)* 和 + 运算的逆波兰式。
●文法(1)该文法描述的语言是什么? (2)该文法是否为二义文法?说明理由。