统计学第1阶段测试题
- 格式:docx
- 大小:17.35 KB
- 文档页数:5

医院统计学测试题库含答案1、下列属于非概率抽样调查方式的是()A、简单随机抽样B、系统抽样C、分层抽样D、整群抽样E、滚雪球抽样答案:E2、标化后的总死亡率A、仅仅作为比较的基础,它反映了一种相对水平B、它反映了实际水平C、它不随标准选择的变化而变化D、它反映了事物实际发生的强度E、以上都不对答案:A3、下列变量的观测结果属于等级资料的是()A、白细胞计数B、住院天数C、门诊就诊人数D、患者病情分级E、各临床科室的患者数答案:D4、计算乙肝疫苗接种后血清抗体检查的阳转率,分母是()A、乙肝易感人数B、乙肝患病人数C、乙肝疫苗接种抗体阳转人数D、乙肝疫苗接种人数E、乙肝治愈人数答案:D5、下列关于率的标准误的叙述,错误的是A、样本率的标准差称为率的标准误B、率的标准误反映率的抽样误差大小C、率的标准误越小,用样本率估计总体率的可靠性越大D、率的标准误越小,用样本率估计总体率的可靠性越小E、适当增加样本含量可减少率的标准误6、从婴儿死亡率与新生儿死亡率的关系中A、可看出一个国家的卫生水平B、不可看出一个国家的卫生水平C、只能看到婴儿死亡原因的不同D、可以看出新生儿与婴儿死亡率的差别E、以上均不对答案:A7、以下关于非概率抽样的说法不正确的是()A、不需要考虑等概率原则B、依赖研究人员的经验和专业知识C、可以取代概率抽样D、简便易行,节约资源E、结果的稳定性容易受主观性影响答案:C8、下列关于调查设计的叙述,正确的是A、明确调查目的是调查研究最核心的问题B、采用抽样调查还是普查是由该地区的经济水平决定的C、调查设计出现缺陷时,都可以通过相应的统计分析方法弥补D、一旦制定了调查研究计划,在实际操作过程中就不能改变E、调查的质量控制主要在调查问卷设计阶段答案:A9、检测一组病人的血型(A、B、O、AB)是属于A、离散型定量变量B、连续型定量变量C、分类变量D、有序变量E、等级变量答案:C10、红细胞数是A、观察单位B、数值变量C、名义变量D、等级变量E、研究个体11、出院情况的填写只有哪一项是客观的()A、治愈B、好转C、未愈D、死亡E、其他答案:D12、财务科报表反映()A、当月医院应得的业务收入B、当月出院病人费用C、当月门诊病人费用D、当月结算病人费用E、当月病人欠费答案:A13、疾病统计的研究对象视调查目的不同而有不同的规定范围,比如门诊疾病的统计对象应是A、门诊患者B、门诊诊断为患病者C、住院+门诊患者D、以上都对E、以上都不对答案:B14、在病案统计系统数据库中病床使用率是最常用的指标。

练习题一考试科目:《统计学》第1章至第5章(总分100分)一、单项选择题(共20小题,每小题2分,共计40分)1.运用样本数据的统计量来推断总体的特征、变量的关系属于:BA描述统计B推断统计C科学统计D经验统计2.根据无锡市1000个家庭的调查数据,推断无锡市居民家庭订阅《江南晚报》的比例属于:A描述统计B推断统计C科学统计D经验统计B3.根据样本调查数据,制作统计数据分布直方图属于:A描述统计B推断统计C科学统计D经验统计4.一家研究机构从IT从业者中随机抽取500人作为样本进行调查,其中60%的人回答他们的月收入在5000元以上,50%的回答他们的消费支付方式是使用信用卡。
这里的“月收入”是:A 分类变量B 顺序变量C 数值型变量D 离散变量5.要反映我国工业企业的整体业绩水平,总体单位是:A 我国每一家工业企业B 我国所有工业企业C 我国工业企业总数D 我国工业企业的利润总额6.一项调查表明,在所抽取的1000个消费者中,他们每月在网上购物的平均消费是200元,他们选择在网上购物的主要原因是“价格便宜”。
这里的参数是: CA 1000个消费者B 所有在网上购物的消费者C所有在网上购物的消费者的平均消费额D 1000个消费者的平均消费额7.一名统计学专业的学生为了完成其统计作业,在《统计年鉴》中找到的2006年城镇家庭的人均收入数据属于: CA分类数据B顺序数据C截面数据D时间序列数据8.一家公司的人力资源部主管需要研究公司雇员的饮食习惯,改善公司餐厅的现状。
他注意到,雇员要么从家里带饭,要么在公司餐厅就餐,要么在外面的餐馆就餐。
他收集数据的方法属于: DA访问调查B邮寄调查C个别深度访问D观察调查9.下面哪一项属于连续性变量CA学生的籍贯B保险公司雇员数C奶牛24小时的产奶量D某杂货店一天销售的牛奶件数(箱)10.抽样调查与重点调查的主要区别是( D)A作用不同B组织方式不同C灵活程度不同D选取调查单位的方法不同11.调查时限是指( B)A调查资料所属的时间B进行调查工作的期限C调查工作登记的时间D调查资料的报送时间12.统计整理阶段最关键的问题是( B)A对调查资料的审核B统计分组C统计汇总D编制统计表13.调查项目( A )A是依附于调查单位的基本标志B与填报单位是一致的C与调查单位是一致的D是依附于调查对象的基本指标14.为了反映商品价格与需求之间的关系,在统计中应采用(C)A划分经济类型的分组B说明现象结构的分组C分析现象间依存关系的分组D上述都不正确15. 下面的哪一个图形最适合描述结构性问题(B)A条形图B饼图C对比条形图D直方图16.下面的哪一个图形适合比较研究两个或多个总体或结构性问题(A)A环形图B饼图C直方图D折线图17.将全部变量值依次划分为若干个区间,并将这一区间的变量值作为一组,这样的分组方法称为( B)A单变量值分组B组距分组C等距分组D连续分组18.下面的哪一个图形最适合描述大批量数据分布的图形( C)A条形图B茎叶图C直方图D饼图19.由一组数据的最大值最小值中位数和两个四分位数5个特征值绘制而成的,反映原始数据分布的图形,称为( D)A环形图B茎叶图C直方图D箱线图20.有10家公司的月销售额数据(万元)分别为72,63,54,54,29,26,25,23,23,20。

第一章练习题一、单项选择题⒈社会经济统计学是一门()①方法论的社会科学②方法论的自然科学;③实质性的科学④既是方法论又是实质性的科学。
⒉要了解某企业职工的文化水平情况,则总体单位是()①该企业的全部职工②该企业每一个职工的文化程度;③该企业的每一个职工④该企业全部职工的平均文化程度。
⒊总体与总体单位不是固定不变的,是指()①随着客观情况的变化发展,各个总体所包含的总体单位数也是在变动的②随着人们对客观认识的不同,对总体与总体单位的认识也是有着差异的③随着统计研究目的与任务的不同,总体和总体单位可以相互转化④客观上存在的不同总体和总体单位之间,总是存在着差异⒋下列总体中,属于无限总体的是()①全国的人口总数②水塘中所养的鱼;③城市年流动人口数④工业中连续大量生产的产品产量。
⒌下列标志中,属于数量标志的是()①学生性别②学生年龄③学生专业④学生住址⒍下列标志中,属于品质标志的是()①工人性别②工人年龄③工人体重④工人工资⒎下列属于数量指标的有()①劳动生产率②废品量③单位产品成本④资金利润率⒏下列属于质量指标的有()①平均工资②工资总额③销售总量④上交利润额⒐某工人月工资150元,则“工资”是()①数量标志②品质标志③质量指标④数量指标⒑标志与指标的区别之一是()①标志是说明总体特征的,指标说明总体单位的特征②指标是说明总体特征的,标志是说明总体单位的特征③指标是说明有限总体特征的,标志是说明无限总体特征的④指标是说明无限总体特征的,标志是说明有限总体特征的⒒某单位有500名职工,把他们的工资额加起来除以500,则这是()①对500个标志求平均数②对500个变量求平均数③对500个变量值求平均数④对500个指标求平均数⒓变异是指()①标志的具体表现不同②标志和指标各不相同③总体的指标各不相同④总体单位的标志各不相同⒔下列变量中,属于连续变量的是()①大中型企业个数②大中型企业的职工人数③大中型企业的利润额④大中型企业拥有的设备台数⒕统计设计、统计调查、统计整理和统计分析的关系是()①统计设计是基础②统计分析是基础③统计调查是基础④统计整理是基础⒖一个统计总体()①只能有一个标志②只能有一个指标③可以有多个标志④可以有多个指标二、多项选择题⒈对某地区工业生产进行调查,得到如下资料,其中,统计指标有( ) ①某企业亏损20万元②全地区产值3亿元③某企业职工人数2000人④全地区职工6万人⑤全地区拥有各种设备6万台。

统计学1.总体与总体单位之间的关系是( B )A.在同一研究目的下,两者可以相互变换B.在不同研究目的下,两者可以相互变换C.两者都可以随时变换D.总体可变换成总体单位,而总体单位不能变换成总体2. 下列标志哪一个是品质标志( C )A. 产品成本B. 企业增加值C. 企业经济类型D. 企业职工人数3. 构成统计总体的总体单位( D )A. 只能有一个指标B. 只能有一个标志C. 可以有多个指标D. 可以有多个标志4. 某连续变量数列,其末组为开口组,下限有500,相邻组的组中值为480,则末组的组中值为( A )A.520B.510C.500D.5405. 社会经济现象构成统计总体的必要条件是总体单位之间必须存在( B )A. 差异性B. 同质性C. 社会性D. 综合性6. 研究某市工业企业生产设备的使用情况,则总体单位是( C )A. 该市全部工业企业B. 该市每一个工业企业C. 该市工业企业的每一台生产设备D. 该市工业企业的全部生产设备7.对某市占成交额比重大的7个大型集市贸易市场的成交额进行调查,这种调查的组织方式是( C )A.普查 B.抽样调查C.重点调查 D.典型调查8.某一学生的统计学成绩为85分,则85分是( D )A. 品质标志B. 数量标志C. 数量指标D. 标志值9.下列变量中属于连续变量的是( C )A. 职工人数B. 设备台数C. 学生体重D. 工业企业数10. 某企业1994年计划规定劳动生产率提高8%,实际提高6%,则计划完成程度为( B )A.75%B.98.15%C.133.33%D.101.89%11. 假设计划任务数是五年计划中规定最后一年应达到的水平,计算计划完成程度相对指标可采用( B )累计法 B.水平法 C.简单平均法 D.加权平均法12.“平均每个人占有钢产量”这个指标是( D )A.总量指标 B.平均指标C.比较相对指标 D.强度相对指标13. 对于不同水平的总体不能直接用标准差比较其标志变动度,这时需要分别计算其( A )来比较A.标准差系数 B.平均差C.极差 D.均方差14.产品单位成本、产品合格率、劳动生产率、利润总额这四个指标中有几个属于质量指标?( C )A. 一个B. 两个C. 三个D. 四个15.在校学生数和毕业生人数这两个指标( A )A. 前者为时点指标,后者为时期指标B. 均为时期指标C. 前者为时期指标,后者为时点指标D. 均为时点指标1、构成统计总体的个别事物称为( D )A、调查单位B、标志值C、品质标志D、总体单位2、对一批商品进行质量检验,最适宜采用的方法是( B ) 。

第一章测试1【判断题】(5分)总体分为有限总体与无限总体A.对B.错2【判断题】(5分)统计分析包括统计描述和统计推断A.对B.错3【多选题】(5分)指出下列资料的类型中属于计量资料的是()A.20例患者的血型构成B.20例患者的粪便潜血试验-、+、++C.20例患者的白细胞计数( 109/L)分别为9.8,11.6,12.3…D.20名学生的考试分数20名学生的考试分数20名学生的考试分数4【单选题】(5分)指出下列资料的类型中属于计数资料的()A.20名学生的考试分数B.20例患者的粪便潜血试验-、+、++C.20例患者的白细胞计数(⨯109/L)分别为9.8,11.6,12.3…D.20例患者的血型构成5【单选题】(5分)指出下列资料的类型中属于等级资料的是()。
A.20例患者的粪便潜血试验-、+、++B.20名学生的考试分数C.20例患者的血型构成D.20例患者的白细胞计数(⨯109/L)分别为9.8,11.6,12.3…6【判断题】(5分)统计中所说的样本是指从总体中抽出的典型部分。
A.错B.对7【判断题】(5分)变异是指同质基础上,各观察单位之间的差异。
A.错B.对8【判断题】(5分)样本量选择的原则是越多越好。
A.错B.对9【判断题】(5分)小概率事件一般是指发生概率≤0.05或者0.01的随机事件。
A.错B.对。

1.判断数据类型,三者的层次关系。
①分类数据(=、≠):只能分类。
EG.性别(男为0,女为1)、水果种类。
②顺序数据(>、<):可进行类别排序,但是类别间尺度不定。
顺序数据虽然有类别,但是这些类别是有序的。
EG.文化程度(小学、初中、高中、大学)、获奖(一等奖、二等奖、三等奖),身高(160—170、170—180、180—190)。
③数值型数据(+、-):按数字尺度测量的观察值,计算两个测度之间的差值。
类别排序是根据一定的尺度来进行的。
EG.身高(168、170、178、189)、年龄、收入。
①—③是从低层次数据(包含的信息量少)到高层次数据(包含的信息量多)。
定类数据与定序数据是品质数据(定性数据),定距数据是数量数据(定量数据)。
定类数据包含了定序数据,定序数据包含了定距数据。
所以定距数据涵盖的信息量最多。
2.总体分布、样本分布、抽样(样本统计量)分布总体:是包含所研究的全部个体(数据)的集合。
总体中的每一个个体都是总体单位。
有限总体(抽样中每次抽取后不放回)、无限总体(抽取后放回)样本:从总体中抽取的一部分元素的集合。
构成样本元素的数目叫样本量(样本中有几个元素)。
3.参数、统计量参数:描述总体特征的概括性数字度量。
EG.总体平均数、总体标准差、总体比例。
统计量:描述样本特征的概括性数字度量。
EG.样本平均数、样本标准差。
4.变量、变量值、指标指标:反映统计总体数量特征的概念和数值。
(指标值是由变量值综合计算得到的。
)变量:总体单位普遍具有的属性和特征。
(分类变量、顺序变量、数值型变量『离散型变量EG.自然数,可以一一列举;连续型变量EG.实数,不能一一列举』)变量值:变量的具体取值就是变量值。
5.各特点、辨别应使用的抽样方式概率抽样(随机抽样):1) 简单随机抽样:从总体N的样本框中随机、一个个地抽取n个单位作为样本,每个单位的入样概率是相等的。
(简单直观,计算估计量误差方便;N较大时,构建抽样框不易且抽取过程繁琐,实施调查有困难。

统计学原理考试题一、选择题。
1. 下列哪个不是统计学的基本概念?A. 总体。
B. 样本。
C. 参数。
D. 统计量。
2. 在统计学中,描述总体特征的数字指标称为什么?A. 参数。
B. 样本。
C. 统计量。
D. 方差。
3. 下列哪个不是描述数据集中心位置的统计量?A. 均值。
B. 中位数。
C. 众数。
D. 标准差。
4. 如果一个数据集的标准差很大,表示什么?A. 数据集的离散程度大。
B. 数据集的离散程度小。
C. 数据集的中心位置偏移。
D. 数据集的分布形状不规则。
5. 在统计学中,概率分布的形状是由哪个参数控制的?A. 均值。
B. 标准差。
C. 方差。
D. 自由度。
二、填空题。
1. 样本容量为100,样本均值为30,总体标准差为5,样本标准误差为?答,0.5。
2. 一组数据的中位数为35,下四分位数为30,上四分位数为40,该组数据的四分位差为?答,10。
3. 某随机变量X的期望为20,方差为16,标准差为?答,4。
4. 在正态分布曲线上,距离均值两个标准差之外的数据占比约为?答,95.44%。
5. 在t分布中,自由度为10时,t分布的峰度为?答,3。
三、简答题。
1. 请解释参数和统计量的区别。
答,参数是用来描述总体特征的数字指标,如总体均值、总体标准差等;统计量是用来描述样本特征的数字指标,如样本均值、样本标准差等。
参数是对总体进行推断的依据,而统计量是对样本进行推断的依据。
2. 请解释正态分布曲线的特点。
答,正态分布曲线是一个钟形曲线,以均值为中心对称,曲线两侧尾部逐渐下降。
正态分布曲线的均值、中位数、众数重合,曲线的标准差决定了曲线的宽窄。
在正态分布曲线上,距离均值一个标准差之外的数据占比约为68%,距离均值两个标准差之外的数据占比约为95.44%,距离均值三个标准差之外的数据占比约为99.73%。
3. 请解释t分布与正态分布的区别。
答,t分布与正态分布的区别在于t分布是以样本容量为自由度的分布,而正态分布是以总体为基础的分布。

统计学测试题(附答案)一、单选题(共50题,每题1分,共50分)1、在双侧检验中,原假设与备择假设应选为()。
A、H0:M ≠M0,H1:M = M0B、H0:M= M0 ,H1:M<M0C、H0:M= M0 ,H1:M ≠M0D、H0:M = M0 ,H1:M ≥M0正确答案:C2、由变量y倚变量x回归和由变量x倚变量y回归所得到的回归方程是不同的,这表现在()。
A、一个是直线方程,另一个是曲线方程B、与方程对应的两条直线只有一条经过点C、方程中参数不同,意义也不同D、参数估计的方法不同正确答案:C3、连续调查与不连续调查的划分依据是()。
A、调查的组织形式B、调查单位包括的范围是否全面C、调查登记的时间是否连续D、调查资料的来源正确答案:C4、重点调查中重点单位是指()。
A、能用以推算总体标志总量的单位B、具有典型意义或代表性的单位C、标志总量在总体中占有很大比重的单位D、那些具有反映事物属性差异的品质标志的单位正确答案:C5、统计整理是()。
A、统计调查的前提,统计分析的继续B、统计研究的最终阶段C、统计分析的前提,统计调查的继续D、统计研究的初始阶段正确答案:C6、标志的具体表现是指()。
A、标志名称之后所列示的属性B、标志名称之后所列示的数值C、标志名称之后所列示的属性或数值D、如性别正确答案:C7、按水平法计算的平均发展速度推算可以使()。
A、推算的各期水平之和等于各期实际水平之和B、推算的各期增长量等于实际的逐期增长量C、推算的各期定基发展速度等于实际的各期定基发展速度D、推算的期末水平等于实际期末水平正确答案:D8、现有一数列:3,9,27,81,243,729,2 187,反映其平均水平最好用()。
A、算术平均数B、调和平均数C、几何平均数D、中位数正确答案:C9、某质量管理部门对某企业准备出厂的180件产品进行抽样调查,发现有170件为合格品,为证明该企业的全部产品的合格率是否达到95%,应采用哪一种假设检验()。
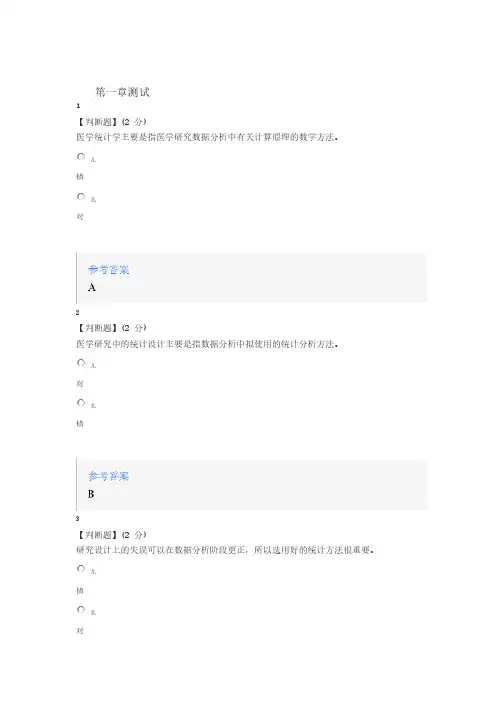
第一章测试1【判断题】(2 分)医学统计学主要是指医学研究数据分析中有关计算原理的数学方法。
A.错B.对2【判断题】(2 分)医学研究中的统计设计主要是指数据分析中拟使用的统计分析方法。
A.对B.错3【判断题】(2 分)研究设计上的失误可以在数据分析阶段更正,所以选用好的统计方法很重要。
A.错B.对4【判断题】(2 分)统计设计包括统计描述与统计推断。
A.对B.错5【判断题】(2 分)统计工作基本步骤中数据分析是最为重要的步骤。
A.错B.对6【判断题】(2 分)医学研究中第一手数据的价值大于二手数据。
A.错B.对7【判断题】(2 分)来自大样本的指标称为参数,来自小样本的指标称为统计量。
A.对B.错8【判断题】(2 分)定量数据是指连续型变量的取值。
A.错B.对9【判断题】(2 分)某社区各家庭成员数属于分类计数资料。
A.对B.错10【判断题】(2 分)分布是一种对应关系,可以用图、表、函数来描述。
A.错B.对第二章测试1【判断题】(2 分)实验研究是根据研究目的将同质的研究对象随机分组,分别给予不同的干预或处理,在合理控制非处理因素条件下,比较不同干预或处理的实验效应的一种研究方法。
属于研究对象随机分组的被动性研究。
A.对B.错2【判断题】(2 分)以人作为受试对象的试验研究,要求有伦理委员会的批准,但不一定全部需要受试对象签署知情同意书。
A.错B.对3【判断题】(2 分)实验研究中要抓住所有的非处理因素才能保证研究结果的科学性。
A.对B.错4【判断题】(2 分)临床试验中我们常以单、双日就诊的患者进行随机化化分组,因为患者哪天就诊是随机的。
A.对B.错5【判断题】(2 分)一般而言,完全随机设计就可以达到组间均衡的目的。
A.对B.错6【判断题】(2 分)随机区组设计要求区组内受试对象个数与处理因素的水平数相同,若同一区组内有数据缺失,该区组的其它数据就无法利用,因此需要重新补做该缺失数据的实验。

(一) 单选题1. 对中国大学教育状况进行调查,调查单位是( )。
(A) 中国的所有大学(B) 中国的每一所大学(C) 中国的每个大学生(D) 中国教育部参考答案:(B)2. 具有时效快,费用低等特点调查方法是( )。
(A) 电话调查(B) 邮寄调查(C) 网上调查(D) 短信调查参考答案:(A)3. 统计学通常把指标分为数量指标和( )。
(A) 时期指标(B) 品质指标(C) 质量指标(D) 总量指标参考答案:(C)4. ( )是根据统计设计的要求搜集统计数据的阶段,是定量认识的起点。
(A) 统计设计(B) 统计调查(C) 统计整理(D) 统计分析参考答案:(B)5. 质问题答案由表示不同等级的形容词组成,并按照一定的程度排序,由被调查者依次选择的方法是( )。
(A) 配对比较法(B) 赋值评价法(C) 评定尺度法(D) 双向列联法参考答案:(C)6. 温度可以运用( )来测度。
(A) 定类尺度(B) 定序尺度(C) 定距尺度(D) 定比尺度参考答案:(C)7. 统计设计的基本任务是制定( )。
(A) 统计指标体系(B) 统计调查方案(C) 统计分析方案(D) 各种统计工作方案参考答案:(D)8. 按调查误差产生原因,统计调查误差分为工作误差和( )。
(A) 代表性误差(B) 人为误差(C) 方法误差(D) 源头误差参考答案:(A)9. 采用组距分组时,一定要遵循的原则( )。
(A) 不重不漏(B) 组距相等(C) 组数从少(D) 操作简单参考答案:(A)10.英国的戈塞特( ,1876~1937)用笔名发表了关于分布的论文。
该事件发生在( )。
(A) “城邦政情”阶段(B) “政治算术”阶段(C) “统计分析科学”阶段(D) “统计学帝国主义”阶段参考答案:(C)11. 用直方形的宽度和高度来表示频数分布的图形是( )。
(A) 条形图(B) 直方图(C) 箱线图(D) 平面图参考答案:(B)12. “一母生九子,九子各不同”说明总体中个体具有( )。

《统计学基础》理论训练题第一章概论一、填空题1.统计一词有().().()三种涵义。
2.统计工作过程分为().().().()四个阶段。
3.标志是说明()具有的特征。
4.统计指标值用()表示。
5.质量指标值用()和()形式表示。
6.统计总体具有().().()三个基本特点。
7.()标志表示总体单位的性质和属性特征,要用()来表示。
8.标志是说明总体单位的名称,它有()和()两种。
9.要了解某银行全部金融产品的情况,总体单位是()。
10.当我们研究某银行职工的工资水平时,该银行全部职工构成(),每一职工是()。
11.当我们研究某市居民户的生活水平时,该市全部居民户便构成(),每一居民是()。
12.统计研究的基本方法是().().综合指标法.统计模型法和归纳推断法13.银行职员的年龄.银行设备的价值属于()标志,而职员的性别.设备的种类是()标志。
二、单项选择题1.研究某高校教师的工资,总体单位是()。
A.该校全体教师B.该校每一名教师C.该校的教师人数D.该校的工资总额2.某校在校本科生为2500人,这里的“在校本科生为2500人”是()。
A.指标B. 变量C. 标志 D . 标志值3.工人的年龄.工厂设备的价值,属于()标志,而工人的性别.设备的种类是()标志。
4.下列变量属于连续变量的是()。
A. 学生人数B. 年龄C.身高D.所学课程数5.有三名工人,他们的日产量分别为20件.21件.18件,这三个数值是()。
A. 指标B. 标志C. 变量D. 标志值6.下列标志属于品质标志的是()A.年龄B.工种C.及格率D. 平均成绩E.日产量7.对某地区所有工业企业的职工情况进行研究,总体单位是()A.每一个企业B.每一个职工C.全部工业企业D.每个企业的职工8.社会经济统计的研究对象是()。
A.抽象的数量关系B.社会经济现象的规律性C.社会经济现象的数量特征和数量关系D.社会经济统计认识过程的规律和方法9.指标是说明总体特征的,标志是说明总体单位特征的,所以()。
大学统计学考试练习题及答案111.[单选题]时间序列中各逐期环比值的几何平均数减1后的结果称为( )A)环比增长率B)定基增长率C)平均增长率D)年度化增长率答案:C解析:2.[单选题]假设检验差别有统计学意义时,P越小,说明A)样本均数差别越大B)总体均数差别越大C)认为样本之间有差别的统计学证据越充分D)认为总体之间有差别的统计学证据越充分答案:D解析:3.[单选题]综合指数包括()A)个体指数和总指数B)数量和质量指标指数C)定基指数和环比指数D)平均指数和平均指标指数答案:B解析:4.[单选题]从某地区中随机抽出20家企业,得到20位企业总经理的年平均收入为25,964.7元,标准差位42,807.8元。
则年平均收入的95%置信区间为( )A)25,964.7±20,034.3B)25,964.7±21,034,3C)25,964.7±25,034.3D)25,964.7±30,034.3答案:A解析:5.[单选题]在抽样调查中( )A)全及总体是唯一确定的B)样本是唯一确定的C)全及指标只能有一个6.[单选题]某病患者5人的潜伏期(天)分别为:6、8、5、12、>15,则平均潜伏期为A)8天B)5天C)11天D)不低于10天E无法计算答案:A解析:7.[单选题]下列不受极端值影响的平均数是( )A)算术平均数B)调和平均数C)众数D)上述三种都不对答案:C解析:8.[单选题]制定统计调查方案的首要问题是()。
A)确定调查组织工作B)调查任务和目的的明确C)调查时间和地点的明确D)调查经费的确定答案:B解析:9.[单选题]有两个数列,甲数列平均数为100,标准差为12.8;乙数列平均数为14.5,标准差为3.7。
据此资料可知( )。
A)甲平均数代表性高于乙B)乙平均数代表性高于甲C)甲乙平均数代表性相同D)无法直接比较甲乙平均数代表性大小答案:A解析:10.[单选题]对某单位职工的文化程度进行抽样调查,得知其中80%的人是高中毕业,抽样平均误差为2%,当概率为95.45%(Z=2)时,该单位职工中具有高中文化程度的比重是( )A)等于78%B)大于84%11.[单选题]圆的周长和半径之间存在着 ( )A)比较关系B)相关关系C)因果关系D)函数关系答案:D解析:12.[单选题]用简单随机重复抽样方法抽取样本时,如果要使抽样平均误差比原来减少一半,则样本单位数需要扩大到原来的( )。
第05讲第九章统计与成对数据的统计分析(综合测试)第05讲第九章统计与成对数据的统计分析(综合测试)一、单选题(本题共8小题,每小题5分,共40分.在每小题给出的四个选项中,只有一项是符合题目要求的.)(2022·全国·高一课时练习)1.“中国天眼”为500米口径球面射电望远镜,是具有我国自主知识产权、世界最大单口径、最灵敏的射电望远镜.建造“中国天眼”的目的是()A .通过调查获取数据B .通过试验获取数据C .通过观察获取数据D .通过查询获得数据(2022·黑龙江·大庆市东风中学高一期末)2.嫦娥五号的成功发射,实现了中国航天史上的五个“首次”,某中学为此举行了“讲好航天故事”演讲比赛.若将报名的30位同学编号为01,02,…,30,利用下面的随机数表来决定他们的出场顺序,选取方法是从随机数表第1行的第3列和第4列数字开始由左到右依次选取两个数字,重复的跳过,则选出来的第5个个体的编号为()4567321212310201045215200112512932049234493582003623486969387481A .23B .20C .15D .12(2022·全国·高一单元测试)3.电影《长津湖之水门桥》于2022年2月1日上映.某新闻机构想了解市民对《长津湖之水门桥》的评价,决定从某市3个区按人口数用分层随机抽样的方法抽取一个样本.若3个区人口数之比为2:3:5,且人口最多的一个区抽出了100人,则这个样本的容量为().A .100B .160C .200D .240(2022·重庆·高二阶段练习)4.下表是某饮料专卖店一天卖出奶茶的杯数y 与当天气温x (单位:C )的对比表,已知表中数据计算得到y 关于x 的线性回归方程为ˆˆ27ybx =+,则据此模型预计35C 时卖出奶茶的杯数为()气温/Cx 510152025杯数y2620161414A .4B .5C .6D .7(2022·福建·莆田一中高二期末)5.某高中调查学生对2022年冬奥会的关注是否与性别有关,随机抽样调查150人,进行独立性检验,经计算得()()()()()22 5.879n ad bc a b c d a c b d χ-=≈++++,临界值表如下:α0.150.100.050.0250.010x α2.0722.0763.8415.0246.635则下列说法中正确的是:()A .有97.5%的把握认为“学生对2022年冬奥会的关注与性别无关”B .有99%的把握认为“学生对2022年冬奥会的关注与性别有关”C .在犯错误的概率不超过2.5%的前提下可认为“学生对2022年冬奥会的关注与性别有关”D .在犯错误的概率不超过2.5%的前提下可认为“学生对2022年冬奥会的关注与性别无关”(2022·广西河池·高二期末(文))6.一只红铃虫的产卵数y 和温度x 有关,现收集了6组观测数据,y (单位:个)与温度x (单位:℃)得到样本数据(),i i x y (1i =,2,3,4,5,6),令ln i i z y =,并将(),i i x z 绘制成如图所示的散点图.若用方程e bx y a =对y 与x 的关系进行拟合,则()A .1a >,0b >B .1a >,0b <C .01a <<,0b >D .01a <<,0b <(2022·全国·高一单元测试)7.2022年国务院《政府工作报告》中指出,有序推进碳达峰碳中和工作,落实碳达峰行动方案.汽车行业是碳排放量比较大的行业之一,某检测单位对甲、乙两类MI 型品牌的新车各抽取了5辆进行2CO 排放量检测,记录如下(单位:g/km ),则甲、乙两品牌汽车2CO 的排放量稳定性更好的是()甲80110120140150乙100120100120160A .甲B .乙C .甲、乙相同D .无法确定(2022·全国·高一单元测试)8.期末考试后,高二某班50名学生物理成绩的平均分为85,方差为8.2,则下列四个数中不可能是该班物理成绩的是()A .60B .78C .85D .100二、多选题(本题共4小题,每小题5分,共20分.在每小题给出的选项中,有多项符合题目要求.全部选对的得5分,部分选对的得2分,有选错的得0分.)(2022·福建南平·高一期末)9.关于用统计方法获取数据,分析数据,下列结论正确的是()A .某食品加工企业为了解生产的产品是否合格,合理的调查方式为抽样调查B .为了解高一学生的视力情况,现有高一男生480人,女生420人,按性别进行分层抽样,样本量按比例分配,若从女生中抽取的样本量为63,则样本容量为135C .若甲、乙两组数据的标准差满足<甲乙s s ,则可以估计乙比甲更稳定D .若数据123,,,,n x x x x ⋅⋅⋅的平均数为x ,则数据(1,2,3,,)i i y ax b i n =-=⋅⋅⋅的平均数为ax b-(2022·全国·高一单元测试)10.下图是甲、乙两个工厂的轮胎宽度的雷达图(虚线代表甲,实线代表乙).根据图中的信息,下列说法正确的是()A .甲厂轮胎宽度的平均数大于乙厂轮胎宽度的平均数B .甲厂轮胎宽度的众数大于乙厂轮胎宽度的众数C .甲厂轮胎宽度的中位数与乙厂轮胎宽度的中位数相同D .甲厂轮胎宽度的极差小于乙厂轮胎宽度的极差(2022·云南省下关第一中学高三开学考试)11.自2020年初,新型冠状病毒引起的肺炎疫情爆发以来,各地医疗机构采取了各种有针对性的治疗方法,取得了不错的成效,某地开始使用中西医结合方法后,每周治愈的患者人数如表所示,由表格可得y 关于x 的二次回归方程为2ˆ6yx a =+,则下列说法正确的是()周数(x )12345治愈人数(y )2173693142A .4a =B .8a =-C .此回归模型第4周的残差(实际值与预报值之差)为5D .估计第6周治愈人数为220(2022·广东汕头·高二期末)12.已知由样本数据()(),1,2,3,,10i i x y i = 组成的一个样本,得到回归直线方程为20.4y x =-,且2x =,去除两个歧义点()2,1-和()2,1-后,得到新的回归直线的斜率为3.则下列说法正确的是()A .相关变量x ,y 具有正相关关系B .去除两个歧义点后的回归直线方程为 33y x =-C .去除两个歧义点后,样本(4,8.9)的残差为0.1-D .去除两个歧义点后,随x 值增加相关变量y 值增加速度变小三、填空题:(本题共4小题,每小题5分,共20分,其中第16题第一空2分,第二空3分.)(2022·陕西渭南·高一期末)13.已知某种商品的广告费支出x (单位:万元)与销售额y (单位:万元)之间有如下对应数据:x 24568y3040506070根据上表可得线性回归方程ˆ7ˆyx a =+,据此估计,当投入15万元广告费时,销售额为_______万元.(2022·重庆十八中高二期末)14.某篮球联赛期间,某一电视台对年龄高于30岁和不高于30岁的人是否喜欢甲队进行调查,对高于30岁的调查了45人,不高于30岁的调查了55人,所得数据绘制成如下列联表:年龄是否喜欢甲队合计不喜欢甲队喜欢甲队高于30岁pq45不高于30岁154055合计15p +40q +100若工作人员从调查的所有人中任取一人,取到喜欢甲队的人的概率为35,依据小概率值0.005α=的独立性检验,推断年龄与是否喜欢甲队______(填“有”“无”)关联.附:()()()()()22n ad bc K a b c d a c b d -=++++,n a b c d =+++.α0.0500.0100.0050.0012K 3.8416.6357.87910.828(2022·福建厦门·高一期末)15.某电池厂有A ,B 两条生产线制造同一型号可充电电池.现采用样本量比例分配的分层随机抽样,从某天两条生产线上的成品中随机抽取样本,并测量产品可充电次数的均值及方差,结果如下:项目抽取成品数样本均值样本方差A 生产线产品82104B 生产线产品122004则20个产品组成的总样本的方差为_____.(2022·天津津衡高级中学有限公司高三阶段练习)16.对正在横行全球的“新冠病毒”,某科研团队研发了一款新药用于治疗,为检验药效,该团队从“新冠”感染者中随机抽取若干名患者,检测发现其中感染了“普通型毒株”、“奥密克戎型毒株”、“其他型毒株”的人数占比为5:3:2.对他们进行治疗后,统计出该药对“普通型毒株”、“奥密克戎毒株”、“其他型毒株”的有效率分别为78%、60%、75%,那么你预估这款新药对“新冠病毒”的总体有效率是________;若已知这款新药对“新冠病毒”有效,求该药对“奥密克戎毒株”的有效率是________.四、解答题(本题共6小题,共70分,其中第17题10分,其它每题12分,解答应写出文字说明、证明过程或演算步骤.)(2022·全国·高一课时练习)17.某工厂对200个电子元件的使用寿命进行检查,按照使用寿命(单位:h )可以把这批电子元件分成六组.由于工作中不慎将部分数据丢失,现有以下部分图表:分组[)100,200[)200,300[)300,400[)400,500[)500,600[]600,700频数3020频率0.20.4(1)求图2中A 的值;(2)补全图2频率分布直方图,并求图2中阴影部分的面积;(3)为了某次展销会,用分层抽样的方法在寿命位于[)400,600内的产品中抽取5个作为样本,那么在[)400,500内应抽取多少个?(2022·全国·高一单元测试)18.在①样本容量为190,②抽取的高一学生人数为36这两个条件中任选一个,补充在下面问题中,并解答问题.某校为了解学生课外阅读情况,将每周阅读时间超过10小时的学生称为“阅读者”,在“阅读者”中按年级用分层随机抽样的方法抽取部分学生进行问卷调查.已知该校高一、高二、高三的学生人数和“阅读者”情况分别如图(1)和图(2)所示,且______.(1)求抽取的“阅读者”中高三学生的人数;(2)为了深入了解高三学生阅读情况,利用随机数表法抽取样本时,先对被抽取的高三“阅读者”按01,02,03,…进行编号,然后从随机数表第8行第5列的数字开始从左向右读,依次抽取5个编号,写出被选出的5个学生的编号.(注:如下为随机数表的第8行至第11行)630163785916955947199850717512867358332112342978645607825207443815510013注:如果选择多个条件分别解答,按第一个解答计分.(2022·河南信阳·高二期末(文))19.随着人们生活水平的提高,国家倡导绿色安全消费,菜篮子工程从数量保障型转向质量效益型.为了测试甲、乙两种不同有机肥料的使用效果,某科研单位用西红柿做了对比实验,分别在两片实验区各摘取100个,对其质量的某项指标值进行检测,质量指数值达到35及以上的为“质量优等”,由测量结果绘成如下频率分布直方图,其中质量指数值分组区间是:[)20,25,[)25,30,[)30,35,[)35,40,[]40,45.(1)分别求甲片实验区西红柿的质量指数的平均值和中位数,并从统计学的角度说明平均值、中位数哪一个更能代表甲片实验区西红柿的质量指数;(2)请根据题中信息完成下面的列联表,并判断是否有99.9%的把握认为“质量优等”与使用不同的肥料有关;甲有机肥料乙有机肥料合计质量优等质量非优等合计()()()()()22n ad bc x a b c d a c b d -=++++.()20P x x ≥0.1000.0500.0100.0050.0010x 2.7063.8416.6357.87910.828(2022·陕西·宝鸡市金台区教育体育局教研室高二期末(理))20.如图是某采矿厂的污水排放量(y 单位:吨)与矿产品年产量(x 单位:吨)的折线图:(1)依据折线图计算相关系数(r 精确到0.01),并据此判断是否可用线性回归模型拟合y 与x 的关系?(若||0.75r >,则线性相关程度很高,可用线性回归模型拟合)(2)若可用线性回归模型拟合y 与x 的关系,请建立y 关于x 的线性回归方程,并预测年产量为10吨时的污水排放量.相关公式:()(niix x yy r --∑0.95≈≈.回归方程ˆˆˆybx a =+中,121()()ˆˆˆ,.()niii nii x x y y b a y bxx x ==--==--∑∑(2022·全国·高一单元测试)21.2022年“中国航天日”线上启动仪式在4月24日上午举行,为普及航天知识,某校开展了“航天知识竞赛”活动,现从参加该竞赛的学生中随机抽取了60名,统计他们的成绩(满分100分),其中成绩不低于80分的学生被评为“航天达人”,将数据整理后绘制成如图所示的频率分布直方图.(1)若该中学参加这次竞赛的共有2000名学生,试估计全校这次竞赛中“航天达人”的人数;(2)估计参加这次竞赛的学生成绩的80%分位数;(3)若在抽取的60名学生中,利用分层随机抽样的方法从成绩不低于70分的学生中随机抽取6人,则从成绩在[70,80),[80,90),[90,100]内的学生中分别抽取了多少人?(2022·宁夏·石嘴山市第三中学模拟预测(文))22.新型冠状病毒肺炎COVID-19疫情发生以来,在世界各地逐渐蔓延.在全国人民的共同努力和各级部门的严格管控下,我国的疫情已经得到了很好的控制.然而,小王同学发现,每个国家在疫情发生的初期,由于认识不足和措施不到位,感染人数都会出现快速的增长.下表是小王同学记录的某国连续8天每日新型冠状病毒感染确诊的累计人数.日期代码x 12345678累计确诊人数y481631517197122为了分析该国累计感染人数的变化趋势,小王同学分别用两杆模型:①2ˆybx a =+,②ˆydx c =+对变量x 和y 的关系进行拟合,得到相应的回归方程并进行残差分析,残差图如下(注:残差e ˆi ii y y =- ):经过计算得81()()728i i i x x y y =--=∑,821()42i i x x =-=∑,81()()6868i i i z z y y =--=∑,821(3570i i z z =-=∑,其中2i iz x =,8118i i z z ==∑.(1)根据残差图,比较模型①,②的拟合效果,应该选择哪个模型?并简要说明理由;(2)根据(1)问选定的模型求出相应的回归方程(系数均保留两位小数);(3)由于时差,该国截止第9天新型冠状病毒感染确诊的累计人数尚未公布.小王同学认为,如果防疫形势没有得到明显改善,在数据公布之前可以根据他在(2)问求出的回归方程来对感染人数做出预测,那么估计该地区第9天新型冠状病毒感染确诊的累计人数是多少?(结果保留整数)附:回归直线的斜率和截距的最小二乘估计公式分别为:()()()81821ˆiii ii x x y y bx x ==--=-∑∑,ˆˆay bx =-.参考答案:1.C【分析】直接由获取数据的途径求解即可.【详解】“中国天眼”主要是通过观察获取数据.故选:C .2.C【分析】根据随机数表法的概念直接得解.【详解】根据随机数表法可得选出的个体编号依次为:12,02,01,04,15,第5个个体编号为15,故选:C.3.C【分析】根据分层抽样的抽取比例相同求解即可.【详解】解:由3个区人口数之比为2:3:5,得第三个区所抽取的人数最多,所占比例为50%.又因为此区抽取了100人,所以3个区所抽取的总人数为100÷50%=200,即这个样本的容量为200.故选:C .4.C【分析】先求得ˆb的值,再据此模型计算出35C 时卖出奶茶的杯数.【详解】由题可知1(510152025)155x =++++=,1(2620161414)185y =++++=,由ˆ181527b=+,可得3ˆ5b =-,则3ˆ352765y=-⨯+=则据此模型预计35C 时卖出奶茶的杯数为6.故选:C 5.C【分析】根据独立性检验的方法即可求解.【详解】由题意可知,()()()()()22 5.879 5.024n ad bc a b c d a c b d χ-=≈>++++,所以在犯错误的概率不超过2.5%的前提下可认为“学生对2022年冬奥会的关注与性别有关”.故选:C.6.A【分析】令ln z y =,可得z 与x 的回归方程为ln z bx a =+,根据散点图,可得z 与x 正相关,所以0b >,根据纵截距大于0,可得a 的范围,即可得答案.【详解】因为e bx y a =,令ln z y =,则z 与x 的回归方程为ln z bx a =+.根据散点图可知z 与x 正相关,所以0b >.由回归直线图象可知:回归直线的纵截距大于0,即ln 0a >,所以1a >,故选:A.7.B【分析】分别计算甲类、乙类品牌汽车的2CO 排放量的平均值和方差即可求出答案.【详解】甲类品牌汽车的2CO 排放量的平均值80110120140150120(g/km)5x ++++==甲,甲类品牌汽车的2CO ,排放量的方差2222221[(80120)(110120)(120120)(140120)(150120)]6005s =⨯-+-+-+-+-=甲.乙类品牌汽车的2CO 排放量的平均值100120100120160120(g/km)5x ++++==乙,乙类品牌汽车的2CO 排放量的方差22221[(100120)(120120)(100120)5s =⨯-+-+-+乙22(120120)(160120)]480-+-=,所以22乙甲<s s .故选:B.8.A【分析】利用方差的定义、计算公式进行判断.【详解】根据题意,平均数85x =,方差()502211858.250i i s x ==-=∑,所以()5021858.250410ii x =-=⨯=∑,若存在60x =,则()26085625410-=>,则方差必然大于8.2,不符合题意,所以60不可能是所有成绩中的一个数据.又()2788549410-=<,()285850410-=<,()210085225410-=<.故B ,C ,D 错误.故选:A .9.ABD【分析】根据普查的适用情形即可判断A,根据分层抽样的抽样比即可求解B,根据标准差的含义即可判断C ,根据平均数的性质即可判断D.【详解】对于A:了解生产的产品是否合格,合理的调查方式为抽样调查,故A 正确;对于B,根据分层抽样的抽样比可知样本容量为()63480420=135420⨯+,故B 对对于C:因为<甲乙s s ,所以甲的数据更稳定,故C 错误,对于D:根据平均数的性质:(1,2,3,,)i i y ax b i n =-=⋅⋅⋅的平均数为ax b -,故D 对故选:ABD 10.ACD【分析】根据雷达图逐项判断可得答案.【详解】甲厂轮胎宽度分别为194,194,194,195,196,197,乙厂轮胎宽度分别为191,193,194,195,195,196,甲厂轮胎宽度平均数为19431951961971956⨯+++=,乙厂轮胎宽度平均数为19521911931941961946⨯++++=,195194>,故A 正确;甲厂轮胎宽度的众数是194,乙厂轮胎宽度的众数是195,195194>,故B 错误;甲厂轮胎宽度的中位数为195194194.52+=,乙厂轮胎宽度的中位数为195194194.52+=,故C 正确;甲厂轮胎宽度的极差为1971943-=,乙厂轮胎宽度极差为1961915-=,53>,故D 正确.故选:ACD .11.BC【分析】设2t x =,则ˆ6yt a =+,求出样本中心点即可判断选项A,B ;利用残差公式计算判断选项C ;令6x =,计算即可判断选项D.【详解】解:设2t x =,则ˆ6yt a =+,由已知得11(1491625)11,(2173693142)5855t y =++++==++++=所以586118a =-⨯=-,故选项A 错误,选项B 正确;在2ˆ68yx =-中,令4x =,得24ˆ64888y =⨯-=,所以此回归模型第4周的残差44ˆ93885y y=-=-=.故选项C 正确;在2ˆ68yx =-中,令6x =,得26ˆ668208y =⨯-=,故选项D 错误.故选:BC .12.ABC【分析】回归直线方程的斜率大小可以判断A 和D ;残差为真实值与估计值之差,进而判断C ;根据题意算出新的相关变量的平均值,进一步求出 a,进而判断B.【详解】对A ,因为回归直线的斜率大于0,即相关变量x ,y 具有正相关关系,故A 正确;对B ,将2x =代入 20.4y x =-得 3.6y =,则去掉两个歧义点后,得到新的相关变量的平均值分别为2105 3.6109,Y 8282X ⨯⨯====, 953322a=-⨯=-,此时的回归直线方程为 33y x =-,故B 正确;对C ,x =4时, 343=9y =⨯-,残差为8.9-9=-0.1,故C 正确;对D ,斜率3>1,此时随x 值增加相关变量y 值增加速度变大,D 错误.故选:ABC.13.120【分析】根据表中数据求得样本中心(),x y ,代入回归方程y bx a =+$$$后求得 a,然后再求当15x =的函数值即可.【详解】由上表可知:2456830405060705,5055x y ++++++++====.得样本点的中心为()5,50,代入回归方程y bx a =+$$$,得507515a =-⨯=$.所以回归方程为 715y x =+,将15x =代入可得:120y =$.故答案为:12014.有【分析】先根据条件列方程组求出p 、q ,然后计算2K 查表可知.【详解】由题知403100545q p q +⎧=⎪⎨⎪+=⎩,解得20,25q p ==所以()221002540152024508.2497.87940604555297K ⨯-⨯==>⨯⨯⨯所以有99.5%的把握认为年龄与是否喜欢甲队有关.故答案为:有15.28【分析】利用均值公式计算出总样本的均值,再利用方差的公式:22211n ii S x x n ==-∑,求出21nii x=∑,进一步求出总样本的方差即可.【详解】依题意得,82221121048Ai i S x ==-=∑,1222211200412B i i S x ==-=∑,解得:()822184210i i x ==⨯+∑,()12221124200ii x==⨯+∑,又8128210122002042020A B x x x +⨯+⨯=== ,()()20812222221112221120420201842101242002042028.i i i i i i S x x x x ===⎛⎫∴=-=⨯+- ⎪⎝⎭⎡⎤=⨯⨯++⨯+-⎣⎦=∑∑∑∴20个产品组成的总样本的方差为28.故答案为:28.16.72%##182525%##14【分析】依据统计数据的平均数求法即可求得这款新药对“新冠病毒”的总体有效率;依据条件概率即可求得已知这款新药对“新冠病毒”有效条件下该药对“奥密克戎毒株”的有效率.【详解】(1)53278%60%75%72%101010⨯+⨯+⨯=(2)360%1025%72%⨯=故答案为:72%;25%17.(1)0.001A =(2)频率分布直方图见解析,阴影部分的面积为0.5(3)4个【分析】(1)根据频率除以组距等于A ,结合图中的数据求解即可,(2)根据频率分布表中的数据可补全频率分布上直方图,阴影部分的面积等于第4组和第5组的频率和,(3)利用分层抽样的定义求解.(1)由题意可知0.1100A =⨯,所以0.001A =.(2)补全后的频率分布直方图如图所示,阴影部分的面积为0.0041000.0011000.5⨯+⨯=.(3)由分层抽样的性质,知在[)400,500内应抽取0.4540.40.1⨯=+(个).18.(1)条件选择见解析,高三学生的人数为90(2)依次选出的编号是63,78,59,16,47【分析】(1)首先确定分层随机抽样的抽样比,再利用“阅读者”中高三学生的人数乘以抽样比即可.(2)利用随机数表法的规则依次取数即可.【详解】(1)由题图知,该校“阅读者”中,高一、高二、高三学生人数分别为180010%180⨯=,160020%320⨯=,150030%450⨯=.选①,因为样本容量为190,所以抽取的“阅读者”中高三学生的人数为45019090180320450⨯=++.选②,因为抽取的高一学生人数为36,所以抽取的“阅读者”中高三学生的人数为3645090180⨯=.(2)根据题意,从随机数表第8行第5列的数字开始从左向右读,依次选出的编号是63,78,59,16,47.19.(1)平均值为34.5,中位数为35.91,中位数更能代表甲片实验区西红柿的质量指数;(2)表格见解析,有99.9%的把握认为,“质量优等”与使用不同的肥料有关【分析】(1)根据频率分布直方图计算平均数即可,中位数是通过排序得到的,不受极端值的影响,故从统计学的角度中位数更能代表甲片实验区西红柿的质量指数.(2)根据频率分布直方图,补全列联表,计算2x ,即可得出结论.(1)解:甲片实验区西红柿的质量指数的平均值为22.50.0527.50.1532.50.237.50.5542.50.0534.5⨯+⨯+⨯+⨯+⨯=,设甲片实验区西红柿的质量指数的中位数为x ,则0.050.150.2(35)0.110.5x +++-⨯=,所以35.91x ≈,故甲片实验区西红柿的质量指数的中位数为35.91,从统计学的角度中位数更能代表甲片实验区西红柿的质量指数.(2)由题意可得22⨯列联表为甲有机肥料乙有机肥料合计质量优等603090质量非优等4070110合计100100200,()()()()()222200(42001200)18.18210010011090x a b n ad c d a c b d bc -⨯-=++=≈⨯⨯⨯++,因为()210.8280.001P x ≥≈,所以有99.9%的把握认为,“质量优等”与使用不同的肥料有关.20.(1)相关系数0.95,可用线性回归模型拟合y 与x 的关系(2)ˆ0.3 2.5yx =+,5.5吨【分析】(1)代入数据,算出相关系数r ,将其绝对值与0.75比较,即可判断可用线性回归模型拟合y 与x 的关系.(2)先求出回归方程,求出当10x =时的值,即为预测值.【详解】(1)由折线图得如下数据计算得:5x =,4y =,51()()6i i i x x y y =--=∑,552211()20,()2i i i i x x y y ==-=-=∑∑所以相关系数0.95r =≈,因为||0.75r >,所以可用线性回归模型拟合y 与x 的关系(2)6ˆ0.3,20b==40.352ˆˆ.5ay bx =-=-⨯=,所以回归方程为ˆ0.3 2.5yx =+,当10x =时,ˆ 5.5y=,所以预测年产量为10吨时的污水排放量为5.5吨21.(1)600人;(2)85;(3)3人,2人,1人.【分析】(1)根据频率分布直方图可求成绩在[80,100]内的频率,从而可求“航天达人”的人数.(2)根据频率和可确定成绩的80%分位数在[80,90)内,根据公式可求80%分位数;(3)根据成绩在[70,80),[80,90),[90,100]的频率比值可求各自抽取人数.【详解】(1)由频率分布直方图可知,成绩在[80,100]内的频率为0.020×10+0.010×10=0.3,则估计全校这次竞赛中“航天达人”的人数约为2000×0.3=600人.(2)由频率分布直方图可知,成绩在[40,50)内的频率为0.005×10=0.05,成绩在[50,60)内的频率为0.015×10=0.15,成绩在[60,70)内的频率为0.020×10=0.2,成绩在[70,80)内的频率为0.030×10=0.3,成绩在[80,90)内的频率为0.020×10=0.2,所以成绩在80分以下的学生所占的比例为70%,成绩在90分以下的学生所占的比例为90%,所以成绩的80%分位数一定在[80,90)内,而0.80.78010805850.90.7-+⨯=+=-,因此估计参加这次竞赛的学生成绩的80%分位数约为85.(3)因为0.3630.30.20.1⨯=++,0.2620.30.20.1⨯=++,0.1610.30.20.1⨯=++,所以从成绩在[70,80),[80,90),[90,100]内的学生中分别抽取了3人,2人,1人.22.(1)选择模型①,理由见解析(2)2ˆ 1.92 1.04yx =+(3)157【分析】(1)选择模型①.根据残差的意义直接判断;(2)套公式求出系数,即可得到y 关于x 的回归方程;(3)将9x =代入,即可求得.【详解】(1)选择模型①.理由如下:根据残差图可以看出,模型①的估计值和真实值相对比较接近,模型②的残差相对较大一些,所以模型①的拟合效果相对较好(2)由(1),知y 关于x 的回归方程为2ˆybx a =+,令2z x =,则ˆy bz a =+.由所给数据得:1(1491625364964)25.58z =+++++++=,1(481631517197122)508y =+++++++=,8121()()6868ˆ 1.923570()iii nii z z y y b z z ==--==≈-∑∑.ˆˆ50 1.9225.5 1.04ay bz =-≈-⨯=,∴y 关于x 的回归方程为2ˆ 1.92 1.04y x =+,(3)将9x =代入上式,得2ˆ 1.929 1.04156.56157y=⨯+=≈(人),所以预测该地区第9天新型冠状病毒感染确诊的累计人数为157人.。
统计基础知识章节练习题(总19页)-CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除第一章概述测试题一、单选题:(每题1分,共计20分)l、统计学是一门( )A、方法论的社会科学B、方法论的自然科学C、实质性科学D、方法论的工具性科学2、调查某大学2000名学生学习情况,则总体单位是( ) 。
A、2000名学生B、2000名学生的学习成绩C、每一名学生D、每一名学生的学习成绩3、要了解某市国有工业企业生产设备情况,则统计总体是( )A、该市国有的全部工业企业B、该市国有的每一个工业企业c、该市国有的某一台设备 D、该市国有制工业企业的全部生产设备4、变量是( )A、可变的质量指标B、可变的数量标志和指标C、可变的品质标志D、可变的数量标志5、构成统计总体的个别事物称为( )A、标志B、总体单位 c、指标 D、总体6、统计总体的基本特征是( )A、同质性、大量性、差异性B、数量性、大量性、差异性、C、数量性、综合性、具体性D、同质性、大量性、可比性7、下列属于品质标志的是( )A、工人年龄B、工人性别C、工人体重D、工人工资等级8、标志是说明( )A、总体单位特征的名称B、总体单位量的特征的名称’C、总体单位质的特征的名称D、总体特征的名称9、在职工生活状况的研究中,“职工的收入”是( )A、连续变量B、离散变量C、随机变量值D、连续变量值lO、下列属于连续变量的是( )A、中等学校数B、国营企业数C、国民生产总值D、学生人数ll、下列属于无限总体的是( )A、全国的人口总数B、水塘中所养的鱼C、城市流动人口数D、工业连续大量生产的产品产量12、某人月工资500元,则“工资”是( )A、数量标志B、品质标志 c、质量指标 D、数量指标13、某单位有500名工人,把他们的工资额加起来除以500,则这是( )A、对500个标志求平均数B、对500个变量求平均数c、对500个变量值求平均数 D、对500个指标求平均数14、要了解全国人口情况,总体单位是( )A、每个省的人口B、每一户C、每个人D、全国总人口15、已知某种商品每件的价格是25元,这里的“商品价格”是( )A、指标B、变量 c、品质标志 D、数量标志16、某地区四个工业企业的总产值分别为20万元、50万元、65万元和100万元,这里的“工业总产值”是( )A、变量B、变量值C、数量标志D、品质标志17、有四名工人的月工资额分别为125元、140元、165元、200元,这四个数字是( )A、数量指标B、变量C、变量值D、品质标志18、某企业职工人数为1200人,这里的“职工人数1200人”是( )A、标志B、变量 c、指标 D、标志值19、下列说法正确的是( )A、标志值有两大类:品质标志值和数量标志值B、品质标志才有标志值C、数量标志才有标志值D、品质标志和数量标志都有标志值20、对某地区某日的气温进行测量得到的测量值,使用的计量方式是( ) ,A、测量值数据B、计数值数据 c、排序数据 D、分类数据二、多选题(每题2分,共计20分)l、变量按其是否连续可分为( )A、确定性变量 B、随机变量 C、连续变量 D、离散变量2、某企业是总体单位,则数量标志有( )A、所有制B、职工人数C、月平均工资D、产品合格率3、下列说法正确的有( )A、数量标志可以用数值表示B、品质标志可以用数值表示C、数量标志不可以用数值表示D、品质标志不可以用数值表示4、下列属于品质标志的是( ) 。
测试题一、判断题(题数:40,共 100.0 分)1数量指标根据数量标志计算而来,质量指标根据品质标志计算而来。
(2.5分)正确答案:×我的答案:×答案解析:2由各种偶然因素造成的个体差异,使得统计学研究具有实际意义。
(2.5分)正确答案:√我的答案:×答案解析:3由样本推断总体,从逻辑上看属于完全的归纳推理。
(2.5分)正确答案:×我的答案:×答案解析:4按照现代统计学的定义,国势学派有统计学之名而无统计学之实。
(2.5分)正确答案:×我的答案:√答案解析:5描述统计与推断统计的区别在于前者简单,后者复杂。
(2.5分)正确答案:×我的答案:×答案解析:6分层抽样的样本代表性取决于层内差异,所以要尽量通过分层把总体差异转化为层内差异。
(2.5分)正确答案:×我的答案:×答案解析:7在细制组所式数师时,最大组的上限应低于总体的最大变量值,最小组的下限应高于总体的最小变量值。
((2.5分)正确答案:×我的答案:×答案解析:8无论是概率抽样还是非概率抽样,误差都是可以计算的。
(2.5分)正确答案:×我的答案:×答案解析:9凡是离散型变量都适合编制单向式数列。
(2.5分)正确答案:×我的答案:×答案解析:10多阶段抽样可以理解为分层抽样与整群抽样的结合作式。
(2.5分)正确答案:√我的答案:√答案解析:11各组的频数或频率都是可以直接比较的。
(2.5分)正确答案:×我的答案:×答案解析:12偶然性误差只存在于抽样调查,观测性误差则可能存在于任何统计调查。
(2.5分)正确答案:√我的答案:×答案解析:13整群抽样的样本代表性取决于群内差异,所以要尽量把总体差异转化为群间差异。
(2.5分)正确答案:×我的答案:×答案解析:14若某一变量的所有变量值都增加10%,则平均数也增加10%。
统计学考试试题一、选择题1. 下列哪个不是描述统计学的方法?A. 均值B. 方差C. 标准差D. 回归分析2. 假设总体服从正态分布,样本容量增大时,样本均值的分布将更接近于:A. 正态分布B. 泊松分布C. 偏态分布D. 均匀分布3. 在统计学中,用来描述数据集合的集中趋势的指标是:A. 方差B. 标准差C. 中位数D. 众数4. 描述数据的分散程度使用的指标是:A. 方差B. 标准差C. 中位数D. 均值5. 在回归分析中,被预测的变量称为:A. 因变量B. 自变量C. 中介变量D. 控制变量二、简答题1. 请简要说明什么是统计学,以及统计学在现实生活中的应用。
2. 请解释什么是标准差,如何计算标准差并解释其意义。
3. 请解释什么是回归分析,以及回归分析在实际研究中的作用。
三、计算题1. 计算以下数据的方差:5, 8, 10, 12, 152. 计算以下数据集的相关系数:X: 2, 4, 6, 8, 10Y: 1, 3, 5, 7, 93. 根据以下数据,进行一元线性回归分析:X: 1, 2, 3, 4, 5Y: 3, 5, 7, 9, 11四、解答题1. 请说明在实际调查研究中,样本容量的大小对统计分析结果的影响。
2. 请解释什么是假设检验,以及假设检验在研究中的作用。
3. 请列举一个实际案例,说明如何运用统计学方法进行数据分析和得出结论。
以上是统计学考试的试题,希望你能认真作答,祝你顺利通过考试!。
2018年度病案统计科专业能力测试题2018年度面向信息科岗位(招聘)专业能力测试题(满分100)(建议用时90分钟)第一部分:统计基础知识应用一.最佳选择题(共40分,每题2分)1.描述一组偏态分布资料的变异度,以( )指标较好A.全距B.标准差C.变异系数D.四分位数间距E.方差2.比较某地1-2岁和5-5.5岁儿童身高的变异程度,宜用( )A.极差B.四分位数间距C.方差D.变异系数E.标准差3.某地2016年随机抽取100名健康女性,算得其血清总蛋白含量的均数为74g/L,标准差为4g/L,则其95%的参考值范围为( )A.74±4×4B.74±1.96×4C.74±2.58×4D.74±2.58×4÷10E.74±1.96×4÷104.两样本均数比较t检验时,分别取以下检验水准,犯第二类错误概率最小的是( )A.α=0.01B.α=0.05C.α=0.10D.α=0.20E.α=0.305.正态性检验,按α=0.10 水准,认为总体分布服从正态分布,此时若推断有错,其错误的概率( )A.大于0.10B.小于0.10C.等于0.10D.等于β,而β未知E.等于1-β,而β未知6.当组数等于2时,对于同一资料,方差分析结果与t检验结果( )A.完全等价且F=tB.方差分析结果更准确C.t检验结果更准确D.完全等价且t=FE.理论上不一致7.k个组方差齐性检验有统计学意义,可认为( )A.σ12、σ22、...σk2 不全相等 B.μ1、μ2、..μk不全相等C.S1、S2、...Sk不全相等 D.X1、X2、 (X)k不全相等E.σ12、σ22、...σk2 全不相等8.医院日门诊各科疾病分类资料,可作为计算( )指标的基础A.死亡率B.构成比C.发病率D.病死率E.患病率9.χ2分布的形状( )A.同正态分布B.同t分布C.为对成分布D.与自由度ν有关E.与样本量n有关10.欲比较两地20年来冠心病和恶性肿瘤死亡率是上升速度,最好选用( )A.普通线图B.半对数线图C.条图D.直方图E.圆图11.比较某地在两个年份几种传染病的发病率可用( )A.构成比条图B.复式条图C.线图D.直方图E.圆图12.定基比和环比属于( )指标A.平均数B.构成比C.频率D.相对比E.发展速度13.统计学中所指的总体是( )A.按行政区域划分的研究对象的全体B.按自然人群划分的研究对象的全体C.按研究目的确定的研究对象的全体D.按时间范围划分的研究对象的全体E.按空间范围划分的研究对象的全体14.标准化死亡比SMR是( )A.期望死亡数/实际死亡数B.实际死亡数/期望死亡数C.一种比例,分子是分母的一部分D.一种率,表示事物发展的速度E.反映了实际死亡水平15.欲分析某人群体重指数和血脂之间相关的方向和相关程度,可选用的统计学方法是( )A.t检验B.F检验C.χ2检验D.相关性分析E.秩和检验16.四格表资料的χ2检验,其校正公式的应用条件是( )A.n≥40且T≤5B.n<40且T>5C.n≥40且1<T≤5D.n<40且1<T≤5E.n≥40且T<117.在医学研究中,采用多变量回归分析的主要目的是( )A.节约样本B.提高检验精度C.克服共线问题D.减少异常值的影响E.控制混杂因素的影响18.估计样本含量时,所定Ⅰ型误差愈小,则( )A.所要的样本含量愈大B.所要的样本含量愈小C.不影响样本含量D.所定的样本含量愈精确E.所定的样本含量愈粗糙19.实验设计的基本原则是( )A.随机化、盲法、设置对照B.重复、随机化、配对C.随机化、盲法、配对D.齐同、均衡、随机化E.随机化、重复、设置对照20.若某非遗传性疾病在家族成员间没有传染性,则n个家族成员中出现X个成员患病的概率分布为( )A.二项分布B.负二项分布C.χ2分布D.正态分布E.Poisson分布第二部分:病案首页与国际疾病分类基础知识应用一.判断题(共20分,每题2分)1.国际疾病分类要求,妊娠/分娩和产褥期、起源于围生期若干情况,以及损伤/中毒的临床表现应当优先于其他疾病编码。
江南大学现代远程教育013年上半年第一阶段测试卷
考试科目:《统计学》第0章至第4章(总分100分)时间:90分钟
_______________ 习中心(教学点)批次:___________ 层次:__________
专业:_______________ 学号: _________________ 身份证号:___________________ 姓名:______________________ 得分:____________________________________________
一、简答题(每题5分,共40分)
1、简述统计一词有几种的含义。
统计有三种理解:统计工作,统计资料,统计学,
三者关系:统计工作与统计资料是统计过程与活动成果的关系,统计工作与统计学是统计实践与统计理论的关系,统计工作先于统计学。
统计学研究的对象是统计研究所要认识的客体。
2、简述什么是描述统计和推断统计,并说明两者的关系。
描述统计学研究如何取得反映客观现象的数据,并通过图表形式对所收集的数据进行加工
处理和显示,进而通过综合概括与分析得出反映客观现象的规律性数量特征。
推断统计学则是研究如何根据样本数据去推断总体数量特征的方法,它是在对样本数据进行描
述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。
描述统计和推断统计是统计方法的两个组成部分。
描述统计是整个统计学的基础,推断统计则
是现代统计学的主要内容。
由于在对现实问题的研究中,所获得的数据主要是样本数据,因此, 推断统计在现代统计学中的地位和作用越来越重要,已成为统计学的核心内容。
当然,这并不等于说描述统计不重要,如果没有描述统计收集可靠的统计数据并提供有效的样本信息,即使再科学的统计推断方法也难以得出切合实际的结论。
从描述统计学发展到推断统计学,既反映了统计学发展的巨大成就,也是统计学发展成熟的重要标志。
3、什么是参数,什么是统计量?
参数:描述总体特征的概括性数字度量,它是研究者想要了解的总体的某种特征值。
统计量:统计量是统计理论中用来对数据进行分析、检验的变量。
4、什么是统计规律?
统计规律:对大量偶然事件整体起作用的规律,表现这些事物整体的本质和必然的联系
而个别事件的特征和偶然联系退居次要地位。
统计规律是自然科学和人类社会生活中的普遍规
律之一。
5、统计数据有哪几种计量类型。
在统计学中,统计数据主要可分为四种类型,分别是定类数据,定序数据,定距数据,定比变量。
1. 定类数据(Nominal ):名义级数据,数据的最低级,表示个体在属性上的特征或类别上的不同变量,仅仅是一种标志,没有序次关系。
2. 定序数据(Ordinal ): 数据的中间级,用数字表示个体在某个有序状态中所处的位置,不能做四则运算。
3. 定距数据(Interval ): 具有间距特征的变量,有单位,没有绝对零点,可以做加减运算,不能做乘除运算。
例如,温度。
4. 定比变量(Ratio ): 数据的最高级,既有测量单位,也有绝对零点,例如职工人数,身高。
一般来说,数据的等级越高,应用范围越广泛,等级越低,应用范围越受限。
不同测度级别的数据,应用范围不同。
等级高的数据,可以兼有等级低的数据的功能,而等级低的数据,不能兼有等级高的数据的功
6、简述统计调查方案的内容。
统计调查方案是统计调查前所制订的实施计划,是全部调查过程的指导性文件。
是调查工作有计划、有组织、有系统进行的保证。
统计调查方案应确定的内容有:调查目的与任务、调查对象与调查单位、调查项目与调查表、调查时间和调查时限、调查的组织实施计划。
7、什么叫离散系数,它有什么特征和作用。
离散系数,离散系数又称变异系数,是统计学当中的常用统计指标,主要用于比较不同水平的变量数列的离散程度及平均数的代表性。
变异系数是衡量资料中各观测值变异程度的一个统计量。
当进行两个或多个资料变异程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。
如果单位和(或)平均数不同时,比较其变异程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。
8、简述统计描述数据分布特征的统计图有哪些?
(1)条图:又称直条图,表示独立指标在不同阶段的情况,有两维或多维,图例位于右上方。
(2)百分条图和圆图:描述百分比(构成比)的大小,用颜色或各种图形将不同比例表达出来。
(3)线图:用线条的升降表示事物的发展变化趋势,主要用于计量资料,描述两个变量间关系。
(4 )半对数线图:纵轴用对数尺度,描述一组连续性资料的变化速度及趋势。
(5 )直方图:描述计量资料的频数分布。
(6 )散点图:描述两种现象的相关关系。
(7)统计地图:描述某种现象的地域分布。
二、计算与操作题(每题15分,共60分)
1、以下是某地区收入数据的分组资料
要求:(1)填上上表中的累积频率;
(2 )画出频率分布的直方图、累积频率折线图;
(3)计算收入的平均数、中位数和众数。
2、下面是某班50名同学数学和外语的考试成绩,要求计算:
(1)50名数学成绩平均数、中位数和标准差;
(2)50名外语成绩平均数、中位数和标准差;
(3)分别计算数学和外语的标准差系数,并说明那门课程程及分布的离散程度大。
解答:
1) 平均数:x= (35*3+45*5+55*8+65*14+75*10+85*6+95*4)/(3+5+8+14+10+6+4)=66.4
中位数:3+5+8+14+10+6+4=50 为偶数中间两位是65, 65 所以中位数是(65+65)/2=65
标准差: d =V{[3* ( 35-66.4 )
人2+5*(45-66.4)人2+8*(55-66.4)人2+14*(65-66.4)人2+10*(75-66.4)人2+6*(85-66.4 ) A2+4*(95-66.4)A2]/(50-1)}=16
2 )和1)类似只要把数据换一下 1
3 6 15 22 2 1
3 )数学标准差系数V c = d / x =16/66.4=0.2
4 根据 2 )求出外语的标准差系数比较哪个
离0远,哪个的离散度就大
2、对10名成年人和10名儿童的身高(cm)进行抽样,结果如下: 要求(1)要比较成年组和儿童组的身高差异,应该选择什么指标;
(2)比较分析哪一组的身高差异大。
解:)可以采用全距,平均差,方差2,标准差,离散系数s来描述成年组和幼儿组的身高差异。
(2)从以上结果来看,全距 R ,平均差MAD
,方差S 2,标准差S 所体现的都是成年组的身高 差异较大,但是比较均值不相同两组数据的相对离散程度时,
,采用离散系数更为准确一些,
因
此,从本例中可以看出,儿童组的离散系数较大,也就是说儿童组的身高差异较大。
3、对某地区90
要求:(1)计算90家企业销售额的众数、中位数、平均数。
(2)计算标准差和标准差系数。
解:
兰-E
9
45-30
胚=£+ ------ xd = 1D004- ------------- x500
凡 35
H- I
(3 5- 2C&
(35-20) + (35- 15)^ 500。