GO数据库使用指南
- 格式:pdf
- 大小:1.99 MB
- 文档页数:29
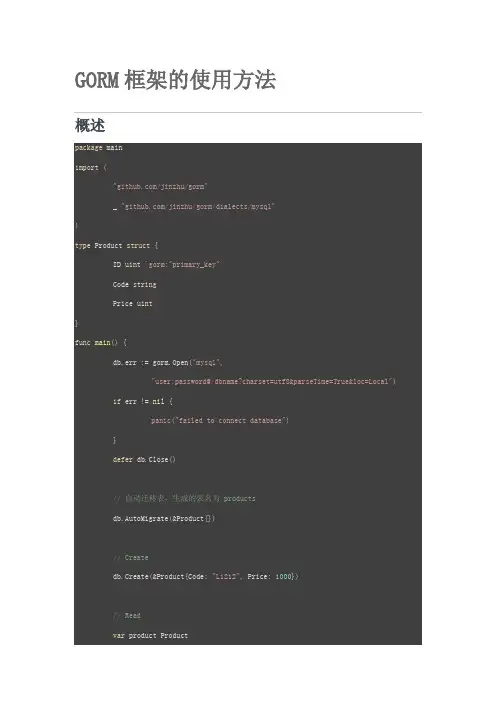
GORM框架的使用方法概述package mainimport ("/jinzhu/gorm"_ "/jinzhu/gorm/dialects/mysql")type Product struct {ID uint`gorm:"primary_key"`Code stringPrice uint}func main() {db,err := gorm.Open("mysql","user:password@/dbname?charset=utf8&parseTime=True&loc=Local") if err != nil {panic("failed to connect database")}defer db.Close()// 自动迁移表,生成的表名为 productsdb.AutoMigrate(&Product{})// Createdb.Create(&Product{Code: "L1212", Price: 1000})// Readvar product Productdb.First(&product, 1) // find product with id 1db.First(&product, "code = ?", "L1212") // find product with code l1212// Updatedb.Model(&product).Update("Price", 2000)//Deletedb.Delete(&product)}模型定义4 个特殊字段。
其中ID 字段默认为主键字段,可以无需加Tag `gorm:"primary_key"`。

go 入门指南pdfGo语言入门指南旨在帮助初学者快速掌握Go语言的基本知识、技能和实践方法。
本文将从Go语言的简介、特点、安装与环境配置,以及基础语法等方面进行讲解,同时分析Go语言在实际项目中的应用和性能优化,最后探讨Go语言的未来发展与趋势。
1.Go语言简介与背景Go语言,又称Golang,是由Google公司开发的一门开源编程语言。
自2007年诞生以来,Go语言凭借其高性能、简洁语法和广泛的应用场景,在全球范围内受到了越来越多开发者的喜爱。
Go语言的的设计理念强调简洁、高效,旨在解决大型软件项目的开发、编译和运行速度问题。
2.Go语言的特点与优势Go语言具有以下几个显著特点:(1)静态类型:Go语言采用静态类型系统,有助于提前发现错误,提高代码质量。
(2)并发支持:Go语言原生支持并发编程,通过goroutine和channel 实现简单高效的多线程。
(3)垃圾回收:Go语言具有自动内存管理功能,降低内存泄漏风险,提高程序稳定性。
(4)高性能:Go语言编译为单一的可执行文件,无需额外依赖库,运行速度快。
(5)跨平台:Go语言支持多种操作系统和处理器架构,可轻松实现跨平台开发。
3.Go语言的安装与环境配置在开始学习Go语言之前,首先需要安装Go语言环境。
请参照官方文档进行安装和环境配置。
需要注意的是,Go语言版本管理严格,不同版本之间存在不兼容性,建议使用最新稳定版进行学习。
4.Go语言基础语法本部分将简要介绍Go语言的基本语法,包括变量、数据类型、控制结构、函数、数组和指针等。
通过学习这些基础知识,可以为后续的编程实践打下坚实基础。
5.Go语言常用库与框架Go语言拥有丰富的第三方库和框架,可以帮助开发者更快地实现各种功能。
本部分将介绍一些常用的库和框架,如:网络编程、数据库操作、Web开发等。
6.Go语言编程实践与案例分析本部分将通过实际案例,讲解如何运用Go语言进行编程实践。
案例可能包括:网络编程、微服务架构、并发编程等。

GO数据库的分类层级说明每次⽤GO分析宝宝就凌乱了,分类关系有传递性吗?怎么推导它们之间的调控关系?语义之间的关系怎么定义?嗯,躺枪的同学默默流泪好了……我们也是操碎了⼼,今天为⼤家科普⼀下GO数据库的规则。
知识拿⾛,不谢~我们都知道GO数据的各个分类间(GO term)是呈现树状层级分类的(图1),那么层级间到底有什么样的关系呢,请看下⾯的图⽂解释:图1 GO term间的有向⽆环图⼀. GO term之间的关系分类之间关系的基本理解分类之间的关系有三种:is a、part of 和 regulates,接下来我们逐⼀来讲解每种情况。
1.Is a · is a → is aIs a具有传递性,即如果A is a B,B is a C,那么A is a C。
形式化表⽰为is a·is a→is a。
例如下图:线粒体(mitochondrion)是⼀种胞内细胞器(intracellular organelle),⽽胞内细胞器是⼀种细胞器官(organelle),从⽽可以推出:线粒体是⼀种细胞器官。
图中的实线表⽰结点之间的关系,虚线表⽰推理⽽并未证明的关系。
2.Part of · part of→part ofPart of具有传递性,如果A is part of B,B is part of C,那么A is part of C。
形式化表⽰为part of·part of→part of。
同样如下图所⽰:线粒体(mitochondrion)是细胞质(cytoplasm)的⼀部分,细胞质⼜是细胞(cell)的⼀部分,从⽽可得出:线粒体是细胞的⼀部分。
3.part of · is a /is a · part of → part of如果关系is a与part of组合,则其关系均为part of 。
分别如下图所⽰:调节控制关系及其推导GO term中,如果某⼀过程直接影响另⼀过程或参数值(quality)的表现形式,我们称前者调节控制(regulates)后者。

goland 数据库连接方法在GoLand中,连接数据库有几种常见的方法,下面是其中一些常用的方法:1. 使用原生的database/sql包连接数据库:```goimport ("database/sql"_ "数据库驱动包")func main() {// 打开数据库连接db, err := sql.Open("数据库驱动名", "连接信息")if err != nil {log.Fatal(err)}defer db.Close()// 测试连接err = db.Ping()if err != nil {log.Fatal(err)}}```2. 使用ORM框架连接数据库,比如GORM:```goimport ("gorm.io/gorm""gorm.io/driver/数据库驱动包")func main() {// 打开数据库连接db, err := gorm.Open(数据库驱动名.Open("连接信息"),&gorm.Config{})if err != nil {log.Fatal(err)}defer db.Close()// 迁移数据库err = db.AutoMigrate(&User{})if err != nil {log.Fatal(err)}// 在这里可以进行更多的数据库操作}```上述代码中的"数据库驱动名"可以根据你实际使用的数据库来选择,比如"mysql"、"postgres"、"sqlite"等。
具体的连接信息也需要根据你的数据库配置来设置,比如数据库地址、用户名、密码等。
这里只是列举了两种常见的连接方法,实际情况可能会根据具体的数据库驱动和框架有所不同。

go-sqlite3用法gosqlite3用法详解引言:gosqlite3是一个Go语言的SQLite3驱动程序。
它提供了一组简单易用的函数和方法,使得在Go语言中使用SQLite3数据库变得异常方便。
本文将一步一步引导您使用gosqlite3,从安装到基本用法,帮助您快速上手。
第一步:安装gosqlite3在开始使用gosqlite3之前,我们需要先安装它。
可以使用如下命令进行安装:go get github/mattn/go-sqlite3第二步:导入gosqlite3包安装完成之后,我们需要在Go代码中导入gosqlite3包。
在代码的开头添加如下代码:import ("database/sql"_ "github/mattn/go-sqlite3")第三步:打开数据库连接在使用gosqlite3之前,我们需要先建立与SQLite3数据库的连接。
可以使用Open函数打开数据库连接。
下面是一个例子:db, err := sql.Open("sqlite3", "test.db")if err != nil {log.Fatal(err)}defer db.Close()第四步:创建表格打开数据库连接之后,我们可以创建表格。
可以使用Execute函数执行SQL语句。
下面是一个例子:_, err = db.Exec("CREATE TABLE IF NOT EXISTS users (id INTEGERNOT NULL PRIMARY KEY, name TEXT, age INTEGER)")if err != nil {log.Fatal(err)}第五步:插入数据创建表格之后,我们可以插入数据。
可以使用Exec函数执行SQL语句。
下面是一个例子:_, err = db.Exec("INSERT INTO users (name, age) VALUES (?, ?)", "John Doe", 30)if err != nil {log.Fatal(err)}第六步:查询数据插入数据之后,我们可以通过查询语句检索数据。

Go语⾔中使⽤SQLite数据库Go语⾔中使⽤SQLite数据库1、驱动Go⽀持sqlite的驱动也⽐较多,但是好多都是不⽀持database/sql接⼝的⽀持database/sql接⼝,基于cgo(关于cgo的知识请参看官⽅⽂档或者本书后⾯的章节)写的不⽀持database/sql接⼝,基于cgo写的不⽀持database/sql接⼝,基于cgo写的⽬前⽀持database/sql的SQLite数据库驱动只有第⼀个,我⽬前也是采⽤它来开发项⽬的。
采⽤标准接⼝有利于以后出现更好的驱动的时候做迁移。
2、实例代码⽰例的数据库表结构如下所⽰,相应的建表SQL:CREATE TABLE `userinfo` (`uid` INTEGER PRIMARY KEY AUTOINCREMENT,`username` VARCHAR(64) NULL,`departname` VARCHAR(64) NULL,`created` DATE NULL);CREATE TABLE `userdeatail` (`uid` INT(10) NULL,`intro` TEXT NULL,`profile` TEXT NULL,PRIMARY KEY (`uid`));看下⾯Go程序是如何操作数据库表数据:增删改查package mainimport ("database/sql""fmt"_ "/mattn/go-sqlite3")func main() {db, err := sql.Open("sqlite3", "./foo.db")checkErr(err)//插⼊数据stmt, err := db.Prepare("INSERT INTO userinfo(username, departname, created) values(?,?,?)")checkErr(err)res, err := stmt.Exec("astaxie", "研发部门", "2012-12-09")checkErr(err)id, err := stInsertId()checkErr(err)fmt.Println(id)//更新数据stmt, err = db.Prepare("update userinfo set username=? where uid=?")checkErr(err)res, err = stmt.Exec("astaxieupdate", id)checkErr(err)affect, err := res.RowsAffected()checkErr(err)fmt.Println(affect)//查询数据rows, err := db.Query("SELECT * FROM userinfo")checkErr(err)for rows.Next() {var uid intvar username stringvar department stringvar created stringerr = rows.Scan(&uid, &username, &department, &created)checkErr(err)fmt.Println(uid)fmt.Println(username)fmt.Println(department)fmt.Println(created)}//删除数据stmt, err = db.Prepare("delete from userinfo where uid=?")checkErr(err)res, err = stmt.Exec(id)checkErr(err)affect, err = res.RowsAffected()checkErr(err)fmt.Println(affect)db.Close()}func checkErr(err error) {if err != nil {panic(err)}}我们可以看到上⾯的代码和MySQL例⼦⾥⾯的代码⼏乎是⼀模⼀样的,唯⼀改变的就是导⼊的驱动改变了,然后调⽤sql.Open是采⽤了SQLite的⽅式打开。


golang数据库开发神器sqlx使⽤指南qlx使⽤指南这边⽂章主要基于翻译⽽成。
sqlx是⼀个go语⾔包,在内置database/sql包之上增加了很多扩展,简化数据库操作代码的书写。
资源如果对于go语⾔的sql⽤法不熟悉,可以到下⾯⽹站学习:如果对于golang语⾔不熟悉,可以到下⾯⽹站学习:由于database/sql接⼝是sqlx的⼦集,当前⽂档中所有关于database/sql的⽤法同样⽤于sqlx开始安装sqlx 驱动$ go get /jmoiron/sqlx本⽂访问sqlite数据库$ go get /mattn/go-sqlite3Handle Typessqlx设计和database/sql使⽤⽅法是⼀样的。
包含有4中主要的handle types:- sqlx.DB - 和sql.DB相似,表⽰数据库。
- sqlx.Tx - 和sql.Tx相似,表⽰transacion。
- sqlx.Stmt - 和sql.Stmt相似,表⽰prepared statement。
- dStmt - 表⽰prepared statement(⽀持named parameters)所有的handler types都提供了对database/sql的兼容,意味着当你调⽤sqlx.DB.Query时,可以直接替换为sql.DB.Query.这就使得sqlx可以很容易的加⼊到已有的数据库项⽬中。
此外,sqlx还有两个cursor类型:- sqlx.Rows - 和sql.Rows类似,Queryx返回。
- sqlx.Row - 和sql.Row类似,QueryRowx返回。
连级到数据库⼀个DB实例并不是⼀个链接,但是抽象表⽰了⼀个数据库。
这就是为什么创建⼀个DB时并不会返回错误和panic。
它内部维护了⼀个连接池,当需要进⾏连接的时候尝试连接。
你可以通过Open创建⼀个sqlx.DB或通过NewDb从已存在的sql.DB中创建⼀个新的sqlx.DBvar db *sqlx.DB// exactly the same as the built-indb = sqlx.Open("sqlite3", ":memory:")// from a pre-existing sql.DB; note the required driverNamedb = sqlx.NewDb(sql.Open("sqlite3", ":memory:"), "sqlite3")// force a connection and test that it workederr = db.Ping()在⼀些环境下,你可能需要同时打开⼀个DB并链接。

GolangORM类库:GORM的使⽤总结Golang ORM类库:GORM的使⽤总结技术概述ORM(Object Relation Mapping 关系对象映射),就是把对象模型表⽰的对象映射到基于SQL的关系模型数据库结构中,在具体的操作实体对象的时候,不需要直接与复杂的 SQL语句打交道,只需简单的操作实体对象的属性和⽅法。
⽽GORM就是基于Go语⾔实现的ORM库。
在使⽤Go语⾔开发项⽬的时候,我们可以利⽤GORM来实现对数据库的操作,进⾏简单的CRUD操作。
技术详述使⽤流程使⽤GORM1.导⼊GROM和数据库驱动可以使⽤⼀下命令安装GROM和数据库驱动go get -u gorm.io/gormgo get -u gorm.io/driver/mysql但是这是⼀种⽐较传统的⽅法。
我们还可以在项⽬中使⽤go.mod⽂件设置项⽬需要添加的依赖包:go 1.15require (gorm.io/driver/mysql v1.0.5gorm.io/gorm v1.21.8)像上⾯这样定义好需要添加的依赖包之后,就可以直接执⾏下⾯这⼀条指令让go.mod⽂件⾃动引⼊所有依赖包:go mod download执⾏完上述指令若没有任何反应则说明已经成功将GORM和数据库驱动的依赖包导⼊了2.定义数据库连接信息在项⽬中的.env⽂件中编写数据库连接的信息,可以⼤致按照如下格式编写,但需要根据具体项⽬要求修改具体信息,⽐如这⾥使⽤的数据库是MySQL的,如果使⽤的是其他数据库(PostgreSQL等),则需要修改MYSQL_DSN的内容:MYSQL_DSN="root:12345678@tcp(localhost:3306)/pingleme?charset=utf8&parseTime=True&loc=Local"REDIS_ADDR="pingleme.top:6379"REDIS_PW="Test1234"REDIS_DB=""SESSION_SECRET="setOnProducation"GIN_MODE="debug"LOG_LEVEL="debug"LOG_PATH="./.log/system.log"LOG_MAX_SIZE="50"LOG_MAX_AGE="30"LOG_MAX_BACKUP="0"LOG_COMPRESS="false"LOG_JSON_FORMAT="false"LOG_SHOW_LINES="true"LOG_SHOW_IN_CONSOLE="true"DB_LOG_LEVEL="info"在这⾥可能会遇到⼀些连接问题,会在之后的“遇到的问题和解决过程”模块解释3.获取数据库连接完成以上准备⼯作后,需要先获取数据库的连接:package mainimport ("gorm.io/gorm""gorm.io/driver/mysql")func main() {db, err := gorm.Open("mysql", &gorm.Config{})if err != nil {panic("failed to connect database")}defer db.Close()db.SingularTable(true)}4.定义数据库模型GORM 倾向于约定,⽽不是配置。

go的用法归纳总结Go是一种强类型的编程语言,它支持并发编程和垃圾回收机制等特性。
它的设计初衷是为了提高程序员的开发效率和提供更好的性能。
其中,常用的go命令包括:1. go build:用于编译Go程序。
2. go run:用于编译并运行Go程序。
3. go test:用于运行Go程序的单元测试。
4. go install:用于将编译后的程序安装到本地的bin目录中。
5. go fmt:用于格式化Go代码。
另外,Go还支持多种语言特性,如:1.函数:Go中的函数可以返回多个值,也可以作为参数传递给其他函数。
2. 包(package):Go中的包是一种组织结构,用于封装共享的代码和数据,并且可以被其他程序引用和重用。
3.接口:Go中的接口是一种抽象类型,用于描述对象的行为和能力,可以在不关心具体实现的情况下编写代码。
4. 并发:Go中的并发编程模型类似于协程,可以通过go关键字创建并发执行的子进程(goroutine)。
5. 错误处理:Go中的错误处理采用panic和recover机制,可以在程序运行中捕获并处理错误。
在使用Go进行编程时,还需要注意一些最佳实践:1.熟悉Go的基础特性,如语法和数据类型。
2. 使用相关的工具和库,如Go Doc文档和第三方的库。
3.避免使用全局变量和共享状态,尽量考虑使用函数和闭包等方式来管理状态。
4.注意并发编程中的线程安全问题,如使用锁、信号量等机制保证数据的原子性。
5.编写简洁、可读性高的代码,遵循Go语言的命名和格式化规范。
总之,Go是一门新兴的编程语言,它的特性和社区资源都在不断发展和完善中。
对于程序员来说,需要不断学习和实践,才能体会到Go带来的种种好处。

如何使用Go语言进行实时数据处理和流式计算的实现指南Go语言是一种开发高性能实时数据处理和流式计算的理想编程语言。
它的简洁性、并发性和快速编译特性使其成为处理大数据和实时事件的流行选择。
本文将介绍如何使用Go语言进行实时数据处理和流式计算的实现指南。
首先,让我们了解一下Go语言的一些特性,这些特性使其成为一个强大的工具,用于构建实时数据处理和流式计算应用程序。
Go语言拥有一种轻量级的线程模型,称为goroutine。
它可以在单个线程上并发运行成千上万个goroutine。
这种并发模型使得Go语言非常适合处理大量的实时数据和事件。
此外,Go语言还提供了通道(channel)机制,用于在goroutine之间安全地传输数据。
通道可以在goroutine之间进行同步和通信,这对于构建实时数据处理和流式计算应用程序至关重要。
接下来,让我们探讨一些实时数据处理和流式计算的常见应用场景,并看看如何使用Go语言来实现这些应用。
1. 实时日志分析实时日志分析是一个常见的需求,尤其是在大规模分布式系统和云环境中。
使用Go语言,你可以编写一个能够实时收集、解析和分析日志的应用程序。
通过使用goroutine和通道,你可以并发处理大量的日志事件,并可以实时地提取有价值的信息。
2. 实时流媒体处理随着在线视频和音频的流行,实时流媒体处理变得越来越重要。
Go语言提供了强大的库和工具,可以帮助你构建高性能的实时流媒体处理应用程序。
你可以使用goroutine和通道来处理流式数据,并通过使用其他开源库(如FFmpeg)来实现音视频处理功能。
3. 实时监控和警报实时监控和警报是保持系统运行稳定和高可用性的关键部分。
使用Go语言,你可以编写一个实时监控和警报系统,该系统可以实时监测关键指标和事件,并在达到预定的阈值时触发警报。
通过使用goroutine和通道,你可以实现高效的事件处理和警报功能。
在实现这些实时数据处理和流式计算应用程序时,还有一些实用的Go语言库可供选择。
使用Go语言进行实时数据处理与分析的方法与工具推荐在当今信息爆炸的时代,实时数据处理与分析变得越来越重要。
Go语言作为一种高效、可靠且易于编程的语言,备受开发者青睐。
本文将介绍如何使用Go语言进行实时数据处理与分析,并推荐一些常用的工具和方法。
一、Go语言的优势1. 并发处理能力:Go语言内置了轻量级的协程(goroutine)和通道(channel),可以方便地进行并发编程。
这使得Go语言非常适合处理和分析大量实时数据。
2. 高性能:Go语言使用了一种称为垃圾回收器(garbage collector)的机制,能够自动管理内存,避免了手动释放内存的繁琐过程。
同时,Go语言的编译器和运行时环境均经过优化,可以提供出色的性能。
3. 丰富的标准库:Go语言提供了丰富的标准库,其中包括了许多用于处理数据的模块。
这些模块可以大大简化实时数据处理与分析的过程。
二、实时数据处理与分析的方法1. 数据收集:实时数据处理与分析的第一步是收集数据。
Go语言可以使用标准库中的net包或第三方库来实现数据的网络收集。
例如,可以使用net/http包来构建HTTP服务器,接收客户端的数据推送。
还可以使用第三方库如Gorilla WebSocket来实现WebSocket数据的收集。
2. 数据存储:收集到的实时数据需要进行存储,以便后续的处理和分析。
Go 语言提供了许多数据库驱动,可以方便地与各种数据库进行交互。
例如,可以使用Golang的官方驱动程序来连接MySQL或PostgreSQL数据库,也可以使用第三方库如MongoDB驱动程序来连接MongoDB数据库。
3. 数据处理:一旦数据被存储,就可以使用Go语言进行数据处理。
可以使用Go语言的标准库中的文本处理模块,如strings包和regexp包,对实时数据进行处理。
此外,还可以利用第三方库如Golang实现的并发任务调度工具goroutinepool,对大规模数据进行高效并发处理。
go数据库使用方法1.安装Go数据库Go 数据库是一款轻量级的 SQL 数据库,它可以用来储存和管理小型结构化数据。
首先,需要安装 Go 数据库,可以到官网下载最新的安装包。
安装之后,启动它的服务,然后就可以开始使用了。
2.创建数据库使用 Go 语言操作 Go 数据库,首先需要创建一个数据库,可以使用 create database <dbname> 命令来创建一个新的数据库。
这条命令会在当前目录下创建一个新的文件夹,并且把新数据库的数据文件存放在其中。
3.添加表在 Go 数据库中,每个数据库中都有多个表,每个表代表一组特定的数据,可以用 create table <tablename> 命令来创建表。
4.添加字段在 Go 数据库中,每张表都有多个字段,可以使用 add column <columnname> <type> 命令来添加字段。
5.插入数据使用 insert into <tablename> (column1,column2…)values(value1,value2…); 命令可以把数据插入到 Go 数据库中。
6.更新数据使用 update <tablename> set <columnname>=<newvalue>; 命令可以更新 Go 数据库中的数据。
7.查询数据使用 select * from <tablename> 命令可以从 Go 数据库中查询所有数据,也可以使用 select <columnname> from <tablename> 命令来查询指定的数据。
Go语言作为一种开发高效、性能优越的编程语言,其在Web开发、后端服务以及大数据处理等领域都有广泛的应用。
在实际开发中,经常需要将程序与数据库进行交互,其中数据库表结构的初始化是非常关键的一步。
本文将对如何在Go程序中初始化数据库表结构进行介绍,希望能够帮助到需要的读者。
一、使用ORM框架进行数据库表结构初始化在Go语言中,有许多优秀的ORM框架可以使用,比如GORM、Xorm等。
这些ORM框架提供了一种方便快捷的方式来定义数据库表结构,并且可以自动创建相应的表格。
使用ORM框架进行数据库表结构初始化,主要包括以下几个步骤:1. 定义数据模型我们需要定义相应的数据模型,即Go语言中的结构体。
通过结构体的字段来表示数据库表中的字段,在字段上可以使用标签来定义字段的名称、类型、约束等信息。
例如:```gotype User struct {ID intName string `gorm:"size:255"`Age int}```2. 连接数据库在使用ORM框架进行数据库表结构初始化之前,首先需要连接数据库。
通常情况下,我们会在程序的初始化阶段进行数据库的连接,并且在程序退出时关闭连接。
连接数据库的代码如下:```godb, err := gorm.Open("mysql","user:password/dbname?charset=utf8parseTime=Trueloc=Local ")if err != nil {panic("failed to connect database")}defer db.Close()```3. 创建表格一旦定义了数据模型并且成功连接了数据库,就可以通过ORM框架提供的自动迁移功能来创建相应的表格。
自动迁移会自动创建表格,并根据定义的数据模型来创建字段。
创建表格的代码如下:```godb.AutoMigrate(User{})```通过以上步骤,我们就可以使用ORM框架来进行数据库表结构的初始化了。
go crypto库用法Go语言是一种广泛使用的编程语言,它提供了丰富的库和工具,用于开发高性能的分布式应用程序。
在Go语言中,crypto库提供了一组功能强大的加密和解密工具,用于保护数据的机密性和完整性。
在本篇文章中,我们将介绍gocrypto库的基本用法和常见操作。
一、安装crypto库在使用crypto库之前,您需要先将其添加到您的Go项目。
您可以使用以下命令来安装crypto库:```shellgoget-ucrypto/...```这将更新crypto库及其依赖项,并将其添加到您的项目目录。
二、使用crypto库crypto库提供了多种加密算法和功能,如哈希算法、公钥加密、私钥解密等。
下面是一些常用的操作和用法:1.创建加密密钥crypto库提供了一种简单的方法来创建加密密钥。
您可以使用crypto.GenerateKey()函数生成一个随机的加密密钥。
例如:```goimport"crypto/rand"import"crypto/cipher"key,err:=crypto.GenerateKey()iferr!=nil{//处理错误```这将生成一个长度为32字节的加密密钥,并将其存储在key变量中。
2.使用AES加密算法加密数据crypto库支持多种加密算法,其中AES是一种常用的对称加密算法。
您可以使用crypto.NewCipher()函数创建一个AES加密器,并使用其Encrypt()方法对数据进行加密。
例如:```goimport"crypto/aes"import"crypto/cipher"import"crypto/rand"import"encoding/base64"//生成一个随机的AES密钥对key,err:=crypto.GenerateKey()iferr!=nil{//处理错误}ciphertext,err:=crypto.Encrypt(key,[]byte("Hello,world!")) iferr!=nil{//处理错误}base64String:=base64.StdEncoding.EncodeToString(ciphertex t)这将使用AES加密算法对字符串"Hello,world!"进行加密,并将结果存储在base64String变量中。
go gorm 用法go gorm 用法Gorm 是一个强大的 Go 语言 ORM 框架,用于数据库操作。
它提供了简洁、灵活的 API,使得开发者可以轻松地进行数据库操作。
以下是一些常用的 go gorm 用法,以及对每个用法的详细讲解:连接数据库Gorm 支持多种数据库的连接,包括 MySQL、SQLite、PostgreSQL 等。
连接数据库的方法如下:import ("/driver/mysql""/gorm")func main() {dsn := "user:password@tcp(:3306)/dbname?charset=utf8mb 4&parseTime=True&loc=Local"db, err := ((dsn), &{})if err != nil {panic("连接数据库失败:" + ())}defer ()}这里使用的是 MySQL 数据库的连接方式。
可以根据实际情况选择其他数据库。
创建数据表使用 Gorm 创建数据表非常方便,只需定义一个结构体即可。
例如,创建一个名为 User 的数据表:type User struct {ID uintName stringAge uint}func main() {// ...(&User{})}在上述代码中,AutoMigrate方法会根据结构体的定义自动生成相应的数据表。
插入数据可以使用 Gorm 提供的Create方法来插入数据。
例如,往User 表中插入一条记录:user := User{Name: "Alice", Age: 20}(&user)上述代码中,Create方法会将user结构体中的数据插入到User 表中。
查询数据Gorm 提供了多种查询数据的方法,可以根据各种条件进行查询。
go-migrate用法Go-Migrate 是一个用于数据库迁移的Go语言库,它支持多种类型的数据库,并且提供了一种简单、易于使用的方式来管理数据库模式的变化。
在使用 Go-Migrate 之前,需要先进行一些准备工作。
首先,需要将Go-Migrate 库导入到项目中,可以通过以下命令在项目中引入 Go-Migrate:``````一旦导入了 Go-Migrate 库,就可以使用其提供的命令行工具和库功能来进行数据库迁移。
Go-Migrate 命令行工具使用方法如下:``````接下来,我们将详细介绍一些常用的 Go-Migrate 命令和库方法:1.初始化迁移目录```migrate create -ext sql -dir <dir> <name>```这个命令用于在指定的目录 `<dir>` 中创建一个新的迁移文件,文件名为 `<name>`。
生成的迁移文件中包含了两个空操作函数 `Up(` 和`Down(`,分别用于执行和回滚迁移操作。
2.执行迁移``````这个命令用于执行迁移操作。
`-database` 参数指定了数据库连接的相关信息,`-path` 参数指定了迁移文件所在的目录。
`up` 命令表示执行所有尚未执行的迁移文件。
3.回滚迁移``````这个命令用于回滚迁移操作。
`<steps>` 参数指定要回滚的迁移步数,默认为 1,表示回滚最近的一个迁移操作。
4.创建和删除数据库``````这两个命令分别用于创建和删除数据库。
`create` 命令用于创建数据库,`drop -f` 命令用于删除数据库(`-f` 参数表示强制删除)。
Go-Migrate 还提供了一些其他的命令和库方法,用于管理和查询数据库迁移的状态。
以下是一些常用的命令和方法:- `version`:显示当前数据库的迁移版本。
- `goto <version>`:将数据库迁移到指定的版本。
GO数据库使用指南Version No.2010.09.03(内部资料仅供参考)目录目录第一部分GO是什么? (2)1.1基因本体论(gene ontology)的建立 (2)1.2本体论(The ontologies)简介 (3)1.3本体论语义之间的关系及其组织结构 (4)1.3.1语义之间关系的基本理解 (4)1.3.2关系之间的推导 (5)1.3.3调节控制关系(the regulates relation)及其推导 (6)1.3.4本体论的组织结构 (7)1.4GO的注释(Annotation) (8)第二部分GO怎么用? (10)2.1下载本体论文件和注释文件 (10)2.2GO语义及其相关注释的浏览与搜索 (17)2.2.1AmiGO的基本使用说明 (17)2.2.2语义关系的图形化描述 (20)2.2.3根据语义检索 (22)2.2.4根据基因产物检索 (25)第一部分GO是什么?GO(gene ontology)是基因本体联合会(Gene Onotology Consortium)所建立的数据库,旨在建立一个适用于各种物种的,对基因和蛋白质功能进行限定和描述的,并能随着研究不断深入而更新的语义词汇标准。
GO是多种生物本体语言中的一种,提供了三层结构的系统定义方式,用于描述基因产物的功能.ontology))的建立1.1基因本体论(gene ontology现今的生物学家们浪费了太多的时间和精力在搜寻生物信息上。
这种情况归结为生物学上定义混乱的原因,不同的生物学数据库可能会使用不同的术语,好比是一些方言一样。
不光是精确的计算机难以搜寻到这些随时间和人为多重因素而随机改变的定义,即使是完全由人手动处理也无法完成。
举个例子来说,如果需要找到一个用于制抗生素的药物靶点,你可能想找到所有的和细菌蛋白质合成相关的基因产物,特别是那些和人体中蛋白质合成组分显著不同的。
但如果一个数据库描述这些基因产物为“翻译类”,而另一个数据库描述其为“蛋白质合成类”,那么这无疑对于计算机来说是难以区分这两个在字面上相差甚远却在功能上相一致的定义。
Gene Ontology就是为了解决上述问题,使各种数据库中基因产物功能描述相一致而发起的一个项目。
这个项目最初是由1988年对三个模式生物数据库的整合开始:the FlyBase(果蝇数据库Drosophila),the Saccharomyces Genome Database(酵母基因组数据库SGD)和the Mouse Genome Informatics(小鼠基因组数据库MGI)。
从那开始,GO不断发展扩大,现在已是包含数十个动物、植物、微生物的数据库(详见GO Consortium Page)。
GO开发了具有三级结构的语义词汇标准(Ontologies),根据基因产物的相关生物学途径、细胞学组件以及分子功能而分别给予定义,与具体物种无关。
GO的工作大致可分为三个部分:第一,给予并维持语义(terms);第二,将位于数据库当中的基因、基因产物与GO 本体论语言当中的语义(terms)进行关联,形成网络;第三,开发相关工具,使本体论标准语言的产生和维持更为便捷。
GO的定义法则已经在多个合作的数据库中使用,这使在这些数据库中的查询具有极高的一致性。
这种定义语言具有多重结构,因此在各种程度上都能进行查询。
举例来说,GO 可以被用来在小鼠基因组中查询和信号转导相关的基因产物,也可以进一步找到各种生物的受体酪氨酸激酶。
这种结构允许在各种水平添加对此基因产物特性的认识。
1.2本体论(The ontologiesontologies))简介GO提供了一系列的语义(terms)用来描述基因、基因产物的特性。
这些语义分为三种不同的种类:细胞学组件,用于描述亚细胞结构、位置和大分子复合物,如核仁、端粒和识别起始的复合物等;分子功能,用于描述基因、基因产物个体的功能,如与碳水化合物结合或ATP水解酶活性等;生物学途径,指分子功能的有序组合,达成更广的生物功能,如有丝分裂或嘌呤代谢等。
基因产物可能分别具有分子生物学上的功能、生物学途径和在细胞中的组件作用。
当然,它们也可能在某一个方面有多种性质。
如细胞色素C,在分子功能上体现为电子传递活性,在生物学途径中与氧化磷酸化和细胞凋亡有关,在细胞中存在于线粒体质中和线粒体内膜上。
注:基因产物和其生物功能常常被我们混淆。
例如,“乙醇脱氢酶”既可以指放在Eppendorf试管里的基因产物,也表明了它的功能。
但是这之间其实是存在差别的:一个基因产物可以拥有多种分子功能,多种基因产物也可以行使同一种分子功能。
比如还是“乙醇脱氢酶”,其实多种基因产物都具有这种功能,而并不是所有的这些酶都是由乙醇脱氢酶基因编码的。
一个基因产物可以同时具有“乙醇脱氢酶”和“乙醛歧化酶”两种功能,甚至更多。
所以,在GO中,很重要的一点在于,当使用“乙醇脱氢酶活性”这种术语时,所指的是功能,并不是基因产物。
下面,将进一步的分别说明GO的具体定义情况。
细胞组件即细胞中的位置,指基因产物位于何种细胞器或基因产物组中(如糙面内质网,核或核糖体,蛋白酶体等)。
分子功能分子功能描述在分子生物学上的活性,如催化活性或结合活性。
GO分子功能用来定义功能而不是整体分子,而且不特异性地指出这些功能具体的时空信息。
分子功能大部分指的是单个基因产物的功能,还有一小部分是此基因产物形成的复合物的功能。
定义功能的义项包括催化活性、转运活性、结合活性等,更为狭窄的定义包括腺苷酸环化酶活性或钟形受体结合活性等。
生物学途径生物学途径是由分子功能有序地组成的,具有多个步骤的一个过程。
举例来说,较为宽泛的是细胞生长和维持、信号传导。
一些更为具体的例子包括嘧啶代谢或α-配糖基的运输等。
一个生物学途径并不是完全和一条生物学通路相等。
因此,GO并不涉及到通路中复杂的机制和所依赖的因素。
1.3本体论语义之间的关系及其组织结构1.3.1语义之间关系的基本理解基因本体论组织类似于图,语义作为图的结点,语义之间的关系为图中的边。
因此,一旦产生新的语义,其与其它语义之间的关系也会同时被定义。
语义之间的关系有四种:is a、part of和regulates。
关系表示的几点约定1.“语义”用图论的术语“结点”表示2.我们习惯于用父子结点来表示语义之间的关系,其中父结点离根结点较近,表示相对宽泛的语义,而子结点离叶子结点较近,相对父结点其语义所代表的内容更为具体。
3.图中的实线表示结点之间的关系4.虚线表示推理而并未证明的关系上述可以用下图表示:A is a B;B is part of C从而可以得出:A is part of C,其形式化表示为:is a·part of→part ofGO图具有树的性质,但与其不同的是,GO图中结点不但可能具有多个孩子结点,而且可能具有多个父亲结点,且与不同的父结点具有不同的关系,如下图所示:线粒体(mitochondrion)便有两个父亲结点,因为线粒体既是一种细胞器(organelle),又是细胞质(cytoplasm)的一部分。
同样,细胞器(organelle)也有两个孩子结点,因为线粒体是一种细胞器(organelle),细胞器膜(organelle membrane)是细胞器的一部分。
1.3.2关系之间的推导is a·is a→is ais a具有传递性,即如果A is a B,B is a C,那么A is a C。
形式化表示为is a·is a→is a。
如下图:线粒体(mitochondrion)是一种胞内细胞器(intracellular organelle),而胞内细胞器是一种细胞器官(organelle),从而可以推出:线粒体是一种细胞器官。
part of·part of→part ofpart of具有传递性,如果A is part of B,B is part of C,那么A is part of C。
形式化表示为part of·part of→part of。
同样如下图所示:线粒体(mitochondrion)是细胞质(cytoplasm)的一部分,细胞质又是细胞(cell)的一部分,从而可得出:线粒体是细胞的一部分。
part of ·is a →part of 与is a ·part of →part of如果关系is a 与part of 组合,则其关系均为part of 。
分别如下图所示:1.3.3调节控制关系(the regulates relation)及其推导基因本体论语义中,如果某一过程直接影响另一过程或参数值(quality)的表现形式,我们称前者调节控制(regulates)后者。
被调节的对象可以是一个过程,如生物通路、酶促反应等,也可以是一个参数值,如细胞大小,pH 值等。
与part of 类似,调节控制关系也是充分非必要的,即:B 能且仅能调节控制A ,而A 并非只受B 的调节控制。
如下图所示:例如:一旦cell cycle checkpoint(细胞周期检查点)出现时,它总是调节控制cell cycle(细胞周期),然而细胞周期并不单独受细胞周期检查点调节控制,还受其它过程的调节控制。
线粒体膜线粒体胞内细胞器线粒体胞内细胞器细胞regulates·is a→regulates、is a·regulates→regulates以及regulates·part of→regulates均为正确的推导关系,其示意图分别如下:截至目前,尚不能确定part of·regulates→???、regulates·regulates→???为何种关系。
1.3.4本体论的组织结构GO委员会除了要定义语义(term)以外,还要定义该语义与其它语义之间的关系,使语义总体构成有一定结构的语义词汇表。
本体论的图形化表示本体论的结构可以用图表示,其中语义表示为结点,其间的关系表示为结点之间的边。
当然GO语义之间的关系是单向的,例如:线粒体(mitochondrion)是一个细胞器(organelle),可以表示为a mitochondrion is an organelle,但反过来不成立,细胞器不是一个线粒体!在这种意义上说,本体论的结构更像是有向非循环树,其中离根结点越近的结点越概括,离叶子结点越近的结点越具体,但与有向非循环树不同的是,本体论结构图中的结点可以有两个及其以上的父结点。
例如:生物过程当中的语义已糖合成(hexose biosynthetic process)就有两个父结点,已糖代谢(hexose metabolic process)和单糖合成(monosaccharide biosynthetic process)。