正则表达式 教学25页PPT
- 格式:ppt
- 大小:3.48 MB
- 文档页数:13

中文符号正则表达式一、校验数字的表达式数字:^[0-9]*$n位的数字:^\d{n}$至少n位的数字:^\d{n,}$m-n位的数字:^\d{m,n}$零和非零开头的数字:^(0|[1-9][0-9]*)$非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$有两位小数的正实数:^[0-9]+(.[0-9]{2})?$有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$非零的正整数:^[1-9]\d*$ 或^([1-9][0-9]*){1,3}$ 或^\+?[1-9][0-9]*$非零的负整数:^\-[1-9][]0-9"*$ 或^-[1-9]\d*$非负整数:^\d+$ 或^[1-9]\d*|0$非正整数:^-[1-9]\d*|0$ 或^((-\d+)|(0+))$非负浮点数:^\d+(\.\d+)?$ 或^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[ 1-9][0-9]*))$负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9] *[1-9][0-9]*)))$浮点数:^(-?\d+)(\.\d+)?$ 或^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$二、校验字符的表达式汉字:^[\u4e00-\u9fa5]{0,}$英文和数字:^[A-Za-z0-9]+$ 或^[A-Za-z0-9]{4,40}$长度为3-20的所有字符:^.{3,20}$由26个英文字母组成的字符串:^[A-Za-z]+$由26个大写英文字母组成的字符串:^[A-Z]+$由26个小写英文字母组成的字符串:^[a-z]+$由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或^\w{3,20}中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+禁止输入含有~的字符[^~\x22]+其它:.*匹配除 \n 以外的任何字符。




正则表达式30分钟⼊门教程——堪称⽹上能找到的最好的正则式⼊门教程本教程堪称⽹上能找到的最好正则表达式⼊门教程本⽂⽬标30分钟内让你明⽩正则表达式是什么,并对它有⼀些基本的了解,让你可以在⾃⼰的程序或⽹页⾥使⽤它。
如何使⽤本教程最重要的是——请给我30分钟,如果你没有使⽤正则表达式的经验,请不要试图在30秒内⼊门——除⾮你是超⼈ :)别被下⾯那些复杂的表达式吓倒,只要跟着我⼀步⼀步来,你会发现正则表达式其实并没有想像中的那么困难。
当然,如果你看完了这篇教程之后,发现⾃⼰明⽩了很多,却⼜⼏乎什么都记不得,那也是很正常的——我认为,没接触过正则表达式的⼈在看完这篇教程后,能把提到过的语法记住80%以上的可能性为零。
这⾥只是让你明⽩基本的原理,以后你还需要多练习,多使⽤,才能熟练掌握正则表达式。
除了作为⼊门教程之外,本⽂还试图成为可以在⽇常⼯作中使⽤的正则表达式语法参考⼿册。
就作者本⼈的经历来说,这个⽬标还是完成得不错的——你看,我⾃⼰也没能把所有的东西记下来,不是吗?⽂本格式约定:专业术语元字符/语法格式正则表达式正则表达式中的⼀部分(⽤于分析) 对其进⾏匹配的源字符串对正则表达式或其中⼀部分的说明本⽂右边有⼀些注释,主要是⽤来提供⼀些相关信息,或者给没有程序员背景的读者解释⼀些基本概念,通常可以忽略。
正则表达式到底是什么东西?字符是计算机软件处理⽂字时最基本的单位,可能是字母,数字,标点符号,空格,换⾏符,汉字等等。
字符串是0个或更多个字符的序列。
⽂本也就是⽂字,字符串。
说某个字符串匹配某个正则表达式,通常是指这个字符串⾥有⼀部分(或⼏部分分别)能满⾜表达式给出的条件。
在编写处理字符串的程序或⽹页时,经常会有查找符合某些复杂规则的字符串的需要。
正则表达式就是⽤于描述这些规则的⼯具。
换句话说,正则表达式就是记录⽂本规则的代码。
很可能你使⽤过Windows/Dos下⽤于⽂件查找的通配符(wildcard),也就是*和?。


正则表达式入门教程以下内容经正则表达式学习网授权≈正则表达式是什么?≈在使用电脑进行各种文字处理的时候,我们有时需要查找和匹配一些特殊的字符串,如邮箱地址、验证用户输入的密码是否包含了大小写字母和数字,查找HTML源文档中的所有web地址等等,这时我们就可以使用到正则表达式。
正则表达式本身是一个“字符串”,通过这个“字符串”去描述字符组成规则。
如abbb、abbbb、abbbbb这三个字符串包都是以a字母开头a后面有一个b字母,而且b字母重复了3到5次。
用正则表达式来描述就是ab{3,5},b{3,5}表示b字符重复3到5次。
如果我们想匹配ababab这样的字符串,ab重复了3次,用正则表达式表示就是(ab){3},圆括号()是正则表达式中的分组。
大家如果想亲自感受正则表达式的使用效果,可以打开正则表达式测试系统。
如以上实例所展示的,正则表达式为人们提供了一种简单易用的字符处理工具。
它在目前主流的文字处理软件中都提供了良好的支持(不仅是编程软件,还有文字处理软件Uedit32、EditPlus,网页采集软件火车头等等),它具有很强的通用性,学好它,我们可以达一变应万变的效果。
≈正则表达式详解≈像{},()这种在正则表达式中,具有特殊含义的字符称为元字符(metacharacter)。
元字符是组成正则表达式的基本元素,在正则表达式经常使用的元字符不是很多,概念容易理解。
大家只要花30来分钟学完我们的教程基本上就可以完全掌握。
为了您能更快速的掌握正则表达式,我们为您推荐一款方便的正则表达式在线测试工具“RegExr”,(RegExr由免费提供)。
保留字符匹配字符本身匹配字符数量匹配字符位置分组匹配表达式选项保留字符(返回目录)在正则表达式中,有一些字符在正则表达式中具有特殊含义被称保留字符,如*表示前一个元素可以重复零次或多次,要匹配“*”字符本身使用\*,半角句号.匹配除了换行符外的所有字符,要匹配“.”使用\.。

正则表达式及应⽤正则表达式及应⽤⼀、正则表达式(⼀)、概念:正则表达式(regular expression)就是由普通字符(例如a 到z)以及特殊字符(称为元字符)组成的⼀种字符串匹配的模式,可以⽤来检查⼀个串是否含有某种⼦串、将匹配的⼦串做替换或者从某个串中取出符合某个条件的⼦串等。
(⼆)、正则表达式中主要元字符:【其中常⽤的元字符⽤红⾊标出,红⾊的元字符必须掌握。
难点⽤蓝⾊标出,难点在⼀般的应⽤中并不常⽤】1.\将下⼀个字符标记为⼀个特殊字符、或⼀个原义字符、或⼀个向后引⽤、或⼀个⼋进制转义符。
例如,'n' 匹配字符"n"。
'\n' (newline)匹配⼀个换⾏符。
序列 '\\' 匹配 "\" ⽽"\(" 则匹配 "("。
…\r? (return)2.^匹配输⼊字符串的开始位置。
如果设置了 RegExp 对象的Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。
3.$匹配输⼊字符串的结束位置。
如果设置了RegExp 对象的Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。
4.*匹配前⾯的⼦表达式零次或多次。
例如,zo* 能匹配 "z" 以及 "zoo"。
* 等价于{0,}。
5.+匹配前⾯的⼦表达式⼀次或多次。
例如,'zo+' 能匹配 "zo"以及 "zoo",但不能匹配 "z"。
+ 等价于 {1,}。
6.?匹配前⾯的⼦表达式零次或⼀次。
例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。
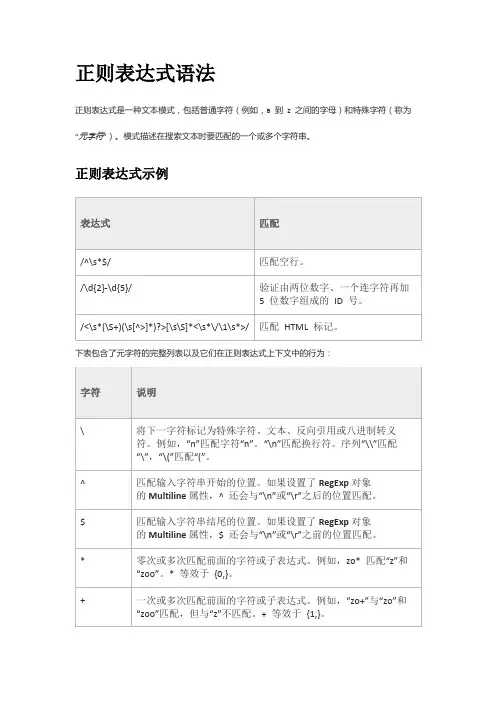
正则表达式语法正则表达式是一种文本模式,包括普通字符(例如,a 到z 之间的字母)和特殊字符(称为“元字符”)。
模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式示例下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:优先级顺序正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
运算符下表从最高到最低说明了各种正则表达式运算符的优先级顺序:字符具有高于替换运算符的优先级,使得“m|food”匹配“m”或“food”。
若要匹配“mood”或“food”,请使用括号创建子表达式,从而产生“(m|f)ood”。
特殊字符许多元字符要求在试图匹配它们时特别对待。
若要匹配这些特殊字符,必须首先使字符“转义”,即,将反斜杠字符(\) 放在它们前面。
下表列出了特殊字符以及它们的含义:特殊字符表不可打印字符非打印字符也可以是正则表达式的组成部分。
下表列出了表示非打印字符的转义序列:转义序列字符匹配句点(.) 匹配字符串中的各种打印或非打印字符,只有一个字符例外。
这个例外就是换行符(\n)。
下面的正则表达式匹配aac、abc、acc、adc等等,以及a1c、a2c、a-c 和a#c:/a.c/若要匹配包含文件名的字符串,而句点(.) 是输入字符串的组成部分,请在正则表达式中的句点前面加反斜扛(\) 字符。
举例来说明,下面的正则表达式匹配filename.ext:/filename\.ext/这些表达式只让您匹配“任何”单个字符。
可能需要匹配列表中的特定字符组。
例如,可能需要查找用数字表示的章节标题(Chapter 1、Chapter 2 等等)。
中括号表达式若要创建匹配字符组的一个列表,请在方括号([ 和])内放置一个或更多单个字符。
当字符括在中括号内时,该列表称为“中括号表达式”。
与在任何别的位置一样,普通字符在中括号内表示其本身,即,它在输入文本中匹配一次其本身。
大多数特殊字符在中括号表达式内出现时失去它们的意义。

