数据结构——堆与优先队列共29页
- 格式:ppt
- 大小:2.49 MB
- 文档页数:15


数据结构--栈和队列基础知识⼀概述栈和队列,严格意义上来说,也属于线性表,因为它们也都⽤于存储逻辑关系为 "⼀对⼀" 的数据,但由于它们⽐较特殊,因此将其单独作为⼀篇⽂章,做重点讲解。
既然栈和队列都属于线性表,根据线性表分为顺序表和链表的特点,栈也可分为顺序栈和链表,队列也分为顺序队列和链队列,这些内容都会在本章做详细讲解。
使⽤栈结构存储数据,讲究“先进后出”,即最先进栈的数据,最后出栈;使⽤队列存储数据,讲究 "先进先出",即最先进队列的数据,也最先出队列。
⼆栈2.1 栈的基本概念同顺序表和链表⼀样,栈也是⽤来存储逻辑关系为 "⼀对⼀" 数据的线性存储结构,如下图所⽰。
从上图我们看到,栈存储结构与之前所了解的线性存储结构有所差异,这缘于栈对数据 "存" 和 "取" 的过程有特殊的要求:1. 栈只能从表的⼀端存取数据,另⼀端是封闭的;2. 在栈中,⽆论是存数据还是取数据,都必须遵循"先进后出"的原则,即最先进栈的元素最后出栈。
拿图 1 的栈来说,从图中数据的存储状态可判断出,元素 1 是最先进的栈。
因此,当需要从栈中取出元素 1 时,根据"先进后出"的原则,需提前将元素 3 和元素 2 从栈中取出,然后才能成功取出元素 1。
因此,我们可以给栈下⼀个定义,即栈是⼀种只能从表的⼀端存取数据且遵循 "先进后出" 原则的线性存储结构。
通常,栈的开⼝端被称为栈顶;相应地,封⼝端被称为栈底。
因此,栈顶元素指的就是距离栈顶最近的元素,拿下图中的栈顶元素为元素 4;同理,栈底元素指的是位于栈最底部的元素,下中的栈底元素为元素 1。
2.2 进栈和出栈基于栈结构的特点,在实际应⽤中,通常只会对栈执⾏以下两种操作:向栈中添加元素,此过程被称为"进栈"(⼊栈或压栈);从栈中提取出指定元素,此过程被称为"出栈"(或弹栈);2.3 栈的具体实现栈是⼀种 "特殊" 的线性存储结构,因此栈的具体实现有以下两种⽅式:1. 顺序栈:采⽤顺序存储结构可以模拟栈存储数据的特点,从⽽实现栈存储结构。
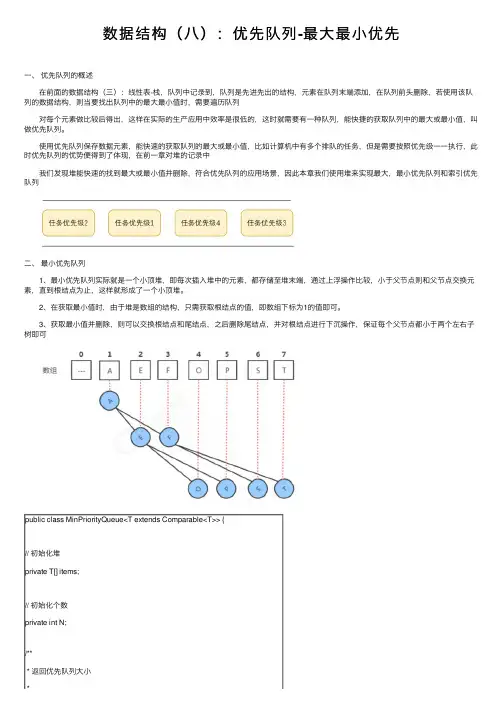
数据结构(⼋):优先队列-最⼤最⼩优先⼀、优先队列的概述 在前⾯的数据结构(三):线性表-栈,队列中记录到,队列是先进先出的结构,元素在队列末端添加,在队列前头删除,若使⽤该队列的数据结构,则当要找出队列中的最⼤最⼩值时,需要遍历队列 对每个元素做⽐较后得出,这样在实际的⽣产应⽤中效率是很低的,这时就需要有⼀种队列,能快捷的获取队列中的最⼤或最⼩值,叫做优先队列。
使⽤优先队列保存数据元素,能快速的获取队列的最⼤或最⼩值,⽐如计算机中有多个排队的任务,但是需要按照优先级⼀⼀执⾏,此时优先队列的优势便得到了体现,在前⼀章对堆的记录中 我们发现堆能快速的找到最⼤或最⼩值并删除,符合优先队列的应⽤场景,因此本章我们使⽤堆来实现最⼤,最⼩优先队列和索引优先队列⼆、最⼩优先队列 1、最⼩优先队列实际就是⼀个⼩顶堆,即每次插⼊堆中的元素,都存储⾄堆末端,通过上浮操作⽐较,⼩于⽗节点则和⽗节点交换元素,直到根结点为⽌,这样就形成了⼀个⼩顶堆。
2、在获取最⼩值时,由于堆是数组的结构,只需获取根结点的值,即数组下标为1的值即可。
3、获取最⼩值并删除,则可以交换根结点和尾结点,之后删除尾结点,并对根结点进⾏下沉操作,保证每个⽗节点都⼩于两个左右⼦树即可public class MinPriorityQueue<T extends Comparable<T>> {// 初始化堆private T[] items;// 初始化个数private int N;/*** 返回优先队列⼤⼩*** @return*/public int size() {return N;}/*** 队列是否为空** @return*/public boolean isEmpty() {return N==0;}/*** 构造⽅法,传⼊堆的初始⼤⼩** @param size*/public MinPriorityQueue(int size) {items = (T[]) new Comparable[size + 1]; N = 0;}/*** 判断堆中索引i处的值是否⼩于j处的值** @param i* @param j* @return*/private boolean bigger(int i, int j) {return items[i].compareTo(items[j]) > 0; }/*** 元素位置的交换** @param col* @param i* @param j*/private void switchPos(int i, int j) {T temp = items[i];items[i] = items[j];items[j] = temp;}/*** 删除堆中最⼤的元素,并且返回这个元素 ** @return*/public T delMin() {// 获取根结点最⼤值T minValue = items[1];// 交换根结点和尾结点switchPos(1, N);// 尾结点置空items[N] = null;// 堆数量减1N--;// 根结点下沉sink(1);return minValue;}/*** 往堆中插⼊⼀个元素t** @param t*/public void insert(T t) {items[++N] = t;swim(N);}/*** 使⽤上浮算法,使堆中索引k处的值能够处于⼀个正确的位置 ** @param k*/private void swim(int k) {while (k > 1) {if (bigger(k / 2, k)) {switchPos(k, k /2);}k = k / 2;}}/*** 使⽤下沉算法,使堆中索引k处的值能够处于⼀个正确的位置 ** @param k*/private void sink(int k) {while (2 * k <= N) {int min;// 存在右⼦结点的情况if (2 * k + 1 <= N) {if (bigger(2 * k, 2 * k + 1)) {min = 2 * k + 1;} else {min = 2 * k;}} else {min = 2 * k;min = 2 * k;}// 当前结点不⽐左右⼦树结点的最⼩值⼩,则退出if (bigger(min, k)) {break;}switchPos(k, min);k = min;}}public static void main(String[] args) {String[] arr = { "S", "O", "R", "T", "E", "X", "A", "M", "P", "L", "E" };MinPriorityQueue<String> minpq = new MinPriorityQueue<>(20);for (String s : arr) {minpq.insert(s);}String del;while (!minpq.isEmpty()) {del = minpq.delMin();System.out.print(minpq.size());System.out.println(del + ",");}}}三、最⼤优先队列 1、最⼤优先队列实际就是⼀个⼤顶堆,即每次插⼊堆中的元素,都存储⾄堆末端,通过上浮操作⽐较,⼤于⽗节点则和⽗节点交换元素,直到根结点为⽌,这样就形成了⼀个⼤顶堆。


堆的特点及典型的应用场景
堆是一种特殊的树形数据结构,它满足堆属性:每个节点的值大于或等于(大顶堆)或小于或等于(小顶堆)其子节点的值。
堆的特点:
1.堆是完全二叉树,这使得在内存中它可以更有效地存储,节省空间。
2.堆中的父节点和子节点之间的比较关系决定了堆的性质:大顶堆或小顶堆。
3.堆通常用于实现优先级队列,其中元素按照一定的优先级顺序进行插入和删除。
4.堆排序是一种高效的排序算法,它利用堆的特性实现排序,时间复杂度为O(nlogn)。
5.中位数查询可以利用最大堆和最小堆,在O(logn)的时间内查询一组数据的中位数。
6.在一些贪心算法中,需要根据一定的规则选取优先级最高的元素,堆可以用于快速查询优先级最
高的元素。
7.对于一个数据流,需要在其中找到前K大或前K小的元素,可以使用堆来实现。
典型的应用场景:
1.优先级队列:堆可以用于实现优先级队列,其中元素按照一定的优先级顺序进行插入和删除,常
用于任务调度、网络路由和事件处理等场景。
2.堆排序:这是一种高效的排序算法,利用堆的特性实现排序,时间复杂度为O(nlogn)。
3.中位数查询:利用最大堆和最小堆,可以在O(logn)的时间内查询一组数据的中位数。
4.贪心算法:在一些贪心算法中,需要根据一定的规则选取优先级最高的元素,堆可以用于快速查
询优先级最高的元素。
5.数据流中的TopK问题:对于一个数据流,需要在其中找到前K大或前K小的元素,可以使用
堆来实现。



C语言中堆的名词解释堆(Heap)是C语言中的一种动态内存分配方式,它相对于栈(Stack)来说,拥有更大的内存空间并且能够存储具有更长生命周期的数据。
在本文中,我们将解释堆的概念、特性以及在C语言中的应用。
一、堆的概念和特性堆是C语言中一块动态分配的内存区域,用于存储程序运行期间需要长时间保留的数据。
与栈不同,堆的内存分配和释放并不自动管理,而是需要通过程序员手动控制。
堆的主要特性可以概括为以下几点:1. 大小可变:堆的大小取决于操作系统的内存限制,可以动态地增加或缩小。
2. 不连续性:堆内存中的数据块可以被随意分配和释放,它们的位置通常是不连续的。
3. 长生命周期:堆中分配的内存空间在程序运行期间一直存在,直到显式地释放。
4. 存储动态数据:堆用于存储运行时动态创建的数据,例如对象、数组、链表等。
二、堆的内存分配在C语言中,使用malloc函数来动态分配堆内存。
malloc的完整形式是memory allocation(内存分配),其原型如下:```cvoid* malloc(size_t size);malloc函数接受一个size_t类型的参数,表示需要分配的内存空间大小,返回一个void指针,指向分配的内存起始地址。
若分配失败,则返回一个空指针NULL。
以下是一个使用malloc分配堆内存的示例:```cint* ptr = (int*) malloc(sizeof(int));```在上述示例中,我们使用malloc函数分配了一个int类型的内存空间并将其地址赋值给了ptr指针。
这样,我们就可以通过访问ptr来操作这个堆内存空间。
需要注意的是,使用malloc函数分配的堆内存必须在使用完毕后通过调用free 函数来显式地释放,以避免内存泄漏。
free函数的原型如下:```cvoid free(void* ptr);```free函数接受一个void指针作为参数,指向需要释放的堆内存的起始地址。

优先队列的实现(⼤根堆,⼩根堆) 本博客不讲解具体的原理,仅仅给出⼀种优先队列较为⼀般化的,可重⽤性更⾼的⼀种实现⽅法。
我所希望的是能过带来⼀种与使⽤STL相同的使⽤体验,因为学习了STL源码之后深受STL代码的影响,对每个ADT都希望能过给出⼀种⾼效,可重⽤,更⼀般的实现⽅法,即使我的代码在STL的priority_queue⾯前仅仅只是三流⽔平,但也⾜够吧⼆叉堆这种数据结构演绎好了。
为了更⼀般化,我抛弃C语⾔的函数指针,改⽤STL相同的仿函数来实现更加⽅便的⾃定义优先级⽐较函数,于此同时我也兼容了已有类型的原有优先级⽐较仿函数。
⾸先给出maxPriorityQueue的ADT以及默认的优先级⽐较仿函数,默认为⼤根堆,⼩根堆重载优先级⽐较仿函数即可。
#ifndef MAXPRIORITYQUEUE_H#define MAXPRIORITYQUEUE_H#include <cstring>template<class T>struct Compare {bool operator () (const T& a, const T& b) {return a < b;}};template<>struct Compare<char*> {bool operator () (char* s1, char* s2) {return strcmp(s1, s2) < 0;}};template<class T>class maxPriorityQueue {public:~maxPriorityQueue() {}virtual bool empty() const = 0;virtual int size() const = 0;virtual T& top() = 0;virtual void pop() = 0;virtual void push(const T& theElement) = 0;};#endif 对于ADT的设计与实现,在C++中,相应ADT的纯虚类是必不可少的,它是ADT的逻辑定义,是设计数据结构的基础,上述代码给出了maxPriorityQueue的定义以及默认优先级⽐较仿函数,对于仿函数的使⽤⽅法,可在下⾯的maxHeap类中找到。

堆、栈、BSS、Data、code区、静态存储区、⽂字常量区在计算机领域,堆栈是⼀个不容忽视的概念,但是很多⼈甚⾄是计算机专业的⼈也没有明确堆栈其实是两种数据结构。
要点:堆:顺序随意栈:先进后出堆和栈的区别⼀、预备知识—程序的内存分配⼀个由c/C++编译的程序占⽤的内存分为以下⼏个部分1、栈区(stack)— 由编译器⾃动分配释放,存放函数的参数值,局部变量的值等。
其操作⽅式类似于数据结构中的栈。
2、堆区(heap) — ⼀般由程序员分配释放,若程序员不释放(就会造成内存泄漏的问题),程序结束时可能由OS回收。
注意它与数据结构中的堆是两回事,分配⽅式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在⼀块的,初始化的全局变量和静态变量在⼀块区域(data),未初始化的全局变量和未初始化的静态变量在相邻的另⼀块区域(BSS,Block Started by Symbol)。
- 程序结束后有系统释放(在整个程序的执⾏过程中都是有效的)4、⽂字常量区 —常量字符串就是放在这⾥的。
程序结束后由系统释放 (⽂字常量区内的数据可以修改吗?)5、程序代码区(code)—存放函数体的⼆进制代码。
⼆、例⼦程序这是⼀个前辈写的,⾮常详细//main.cppint a = 0; 全局初始化区char *p1; 全局未初始化区main(){int b; 栈char s[] = "abc"; 栈 //abc是在栈⾥⾯,⽽下⾯的123456/0却在在常量区内,要注意这两种情况的区别char *p2; 栈char *p3 = "123456"; 123456/0在常量区,p3在栈上。
static int c =0;全局(静态)初始化区p1 = (char *)malloc(10);p2 = (char *)malloc(20);分配得来得10和20字节的区域就在堆区。

数据结构14:队列(Queue),“先进先出”的数据结构队列是线性表的⼀种,在操作数据元素时,和栈⼀样,有⾃⼰的规则:使⽤队列存取数据元素时,数据元素只能从表的⼀端进⼊队列,另⼀端出队列,如图1。
图1 队列⽰意图称进⼊队列的⼀端为“队尾”;出队列的⼀端为“队头”。
数据元素全部由队尾陆续进队列,由队头陆续出队列。
队列的先进先出原则队列从⼀端存⼊数据,另⼀端调取数据的原则称为“先进先出”原则。
(first in first out,简称“FIFO”)图1中,根据队列的先进先出原则,(a1,a2,a3,…,a n)中,由于 a1 最先从队尾进⼊队列,所以可以最先从队头出队列,对于 a2来说,只有a1出队之后,a2才能出队。
类似于⽇常⽣活中排队买票,先排队(⼊队列),等⾃⼰前⾯的⼈逐个买完票,逐个出队列之后,才轮到你买票。
买完之后,你也出队列。
先进⼊队列的⼈先买票并先出队列(不存在插队)。
队列的实现⽅式队列的实现同样有两种⽅式:顺序存储和链式存储。
两者的区别同样在于数据元素在物理存储结构上的不同。
队列的顺序表⽰和实现使⽤顺序存储结构表⽰队列时,⾸先申请⾜够⼤的内存空间建⽴⼀个数组,除此之外,为了满⾜队列从队尾存⼊数据元素,从队头删除数据元素,还需要定义两个指针分别作为头指针和尾指针。
当有数据元素进⼊队列时,将数据元素存放到队尾指针指向的位置,然后队尾指针增加 1;当删除对头元素(即使想删除的是队列中的元素,也必须从队头开始⼀个个的删除)时,只需要移动头指针的位置就可以了。
顺序表⽰是在数组中操作数据元素,由于数组本⾝有下标,所以队列的头指针和尾指针可以⽤数组下标来代替,既实现了⽬的,⼜简化了程序。
例如,将队列(1,2,3,4)依次⼊队,然后依次出队并输出。
代码实现:#include <stdio.h>int enQueue(int *a, int rear, int data){a[rear] = data;rear++;return rear;}void deQueue(int *a, int front, int rear){//如果 front==rear,表⽰队列为空while (front != rear) {printf("%d", a[front]);front++;}}int main(){int a[100];int front, rear;//设置队头指针和队尾指针,当队列中没有元素时,队头和队尾指向同⼀块地址front = rear = 0;rear = enQueue(a, rear, 1);rear = enQueue(a, rear, 2);rear = enQueue(a, rear, 3);rear = enQueue(a, rear, 4);//出队deQueue(a, front, rear);return0;}顺序存储存在的问题当使⽤线性表的顺序表⽰实现队列时,由于按照先进先出的原则,队列的队尾⼀直不断的添加数据元素,队头不断的删除数据元素。
Fibonacci堆数据结构中的高效堆实现方式Fibonacci堆是一种常用于实现优先队列的数据结构,它具有较好的时间复杂度表现,特别适用于一些需要频繁插入、删除和更新操作的场景。
在Fibonacci堆中,节点之间以树的形式进行组织,通过一系列巧妙的操作来维护堆的性质。
本文将介绍Fibonacci堆的基本原理以及高效的堆实现方式。
### Fibonacci堆的基本原理Fibonacci堆是由一组树构成的森林,每棵树都满足最小堆性质:即每个节点的键值都不大于其子节点的键值。
与二叉堆不同,Fibonacci堆中的树可以是任意形状,而不仅仅是二叉树。
每个节点除了指向其子节点外,还有指向其兄弟节点、父节点以及一个标记字段。
Fibonacci堆的主要操作包括插入节点、合并堆、提取最小节点、减小节点关键字值等。
其中,最重要的操作是合并两个堆和提取最小节点。
合并操作将两个Fibonacci堆合并成一个新的Fibonacci堆,而提取最小节点操作则会删除并返回堆中具有最小关键字值的节点。
### 高效的堆实现方式在实际应用中,为了提高Fibonacci堆的效率,可以采用一些优化策略来实现高效的堆操作。
以下是一些常用的高效实现方式:1. **懒惰删除**:在删除节点时,并不立即删除该节点,而是将其标记为已删除,并延迟删除操作。
这样可以减少删除操作的开销,提高效率。
2. **级联剪切**:在减小节点关键字值的操作中,可能会导致某些节点违反最小堆性质。
为了恢复堆的性质,可以采用级联剪切的方式,将违反性质的节点剪切到根节点位置,直到满足最小堆性质。
3. **摊还分析**:通过摊还分析可以证明,Fibonacci堆的插入、删除、合并等操作的平均时间复杂度为O(1),这意味着在大多数情况下,这些操作的时间开销是非常低的。
4. **路径压缩**:在查找最小节点的过程中,可以采用路径压缩的方式,将访问过的节点路径进行压缩,减少后续操作的时间复杂度。
2023年408数据结构选择题一、树与二叉树1. 什么是树结构?- 答案:树结构是由n(n>=1)个结点组成。
- 解析:树结构是一种非线性的数据结构,其中的结点通过边连接在一起,形成层级关系。
树结构由根结点、子结点和边组成。
2. 什么是二叉树?- 答案:每个结点最多有两个子结点的树称为二叉树。
- 解析:二叉树是一种特殊的树结构,每个结点最多有两个子结点,分别称为左子结点和右子结点。
二叉树的结构简单,易于实现和操作。
3. 二叉树的性质有哪些?- 答案:1)第i层最多有2^(i-1)个结点;2)深度为h的二叉树最多有2^h - 1个结点;3)在任意一棵二叉树中,度为0的叶结点数等于度为2的结点数加1。
二、图与搜索1. 什么是图?- 答案:图是由结点和边组成的一种数据结构。
- 解析:图是一种抽象的数据结构,由若干个顶点和边组成,用于描述事物之间的关系。
图可以分为有向图和无向图。
2. 什么是DFS(深度优先搜索)?- 答案:DFS是一种用于遍历或搜索图和树的算法。
- 解析:DFS通过递归或栈实现,首先访问初始结点,然后访问其邻接结点,直到所有结点都被访问过为止。
DFS具有简单、易于实现的特点。
3. 什么是BFS(广度优先搜索)?- 答案:BFS是一种用于遍历或搜索图和树的算法。
- 解析:BFS通过队列实现,首先访问初始结点,然后访问与初始结点相邻的所有结点,直到所有结点都被访问过为止。
BFS具有高效、逐层搜索的特点。
三、排序与查找1. 什么是排序算法?- 答案:排序算法是一种用于对数据进行排序的算法。
- 解析:常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序等。
不同的排序算法具有不同的时间复杂度和空间复杂度。
2. 什么是查找算法?- 答案:查找算法是一种用于在数据集中查找特定元素的算法。
- 解析:常见的查找算法包括顺序查找、二分查找、哈希查找等。
不同的查找算法适用于不同类型的数据集和查找需求。
C语言中的堆与优先队列堆和优先队列是C语言中常用的数据结构,它们在很多算法和程序中发挥着重要的作用。
本文将介绍C语言中的堆和优先队列,包括其定义、操作和应用。
一、堆堆是一种特殊的二叉树结构,常用于实现优先级队列。
在C语言中,我们通常使用数组来表示堆。
堆可以分为最大堆和最小堆两种类型,根据具体的需求选择使用。
1. 定义最大堆:父节点的值大于等于其子节点的值。
最小堆:父节点的值小于等于其子节点的值。
2. 操作堆的常见操作包括:a. 插入元素:将元素插入到堆的最后一个位置,然后进行堆化操作,确保满足堆的性质。
b. 删除堆顶元素:将堆顶元素与最后一个元素交换,然后删除最后一个元素,再进行堆化操作,确保满足堆的性质。
c. 堆化操作:将一个无序的数组调整为一个堆。
可以通过从最后一个非叶子节点开始,依次向前进行比较和交换操作,直到根节点。
堆在C语言中常用于实现优先级队列、排序算法等。
优先级队列:通过堆来实现,可以方便地找到具有最高优先级的元素。
堆排序:使用堆来实现的一种排序算法,具有稳定性和不稳定性两种实现方式。
二、优先队列优先队列是一种特殊的队列数据结构,其中的元素按照优先级进行排序。
C语言中可以使用堆来实现优先队列。
1. 定义优先队列中的元素按照优先级排序,越高优先级的元素越先被处理。
2. 操作优先队列的主要操作包括:a. 插入元素:将元素按照优先级插入到队列中的适当位置。
b. 删除最高优先级元素:删除队列中优先级最高的元素,并返回该元素。
3. 应用优先队列在C语言中常用于任务调度、模拟系统等场景,需要按照特定的优先级进行处理。
堆和优先队列是C语言中常用的数据结构,通过堆可以实现优先队列功能。
堆具有最大堆和最小堆两种类型,可以用于实现排序算法和优先级队列。
优先队列是一种特殊的队列,按照优先级对元素进行排序,常用于任务调度等场景。
通过学习和掌握堆和优先队列的概念、操作和应用,我们能够更加灵活地处理不同场景下的数据和算法问题,提高程序的效率和优化性能。