安德森-商务与经济统计公式汇总
- 格式:pdf
- 大小:172.62 KB
- 文档页数:3

本文系作者原创,如需转载或引用请注明作者为lukesran,其中转载还需事后发邮箱*****************(按上述方式即不视为侵权)经典统计学中的样本规模确定尽管现在是大数据时代,动辄数个G的数据。
因为根本不需要样本,都是对总体或接近总体进行分析,于是乎经典的抽样统计似乎已经老掉牙、不中用了。
但今天这里还是要总结一下经典统计学(频率学派)关于样本规模确定的一些说法。
虽然大数据的方法没怎么学,但无论如何,要理解大数据方法,显然要知道经典统计学是怎么考虑的。
而经典统计学都是建立在样本规模有限基础上的,故样本规模的讨论很重要。
只有样本规模不够,才需要大数据!还是那句话,本文即是学习小结,也供需要的人参考。
一、什么时候要确定样本规模这句话简直就是废话,肯定是在调查之前。
但如果细读有关统计学的教材,会发现在多个章节出现确定样本规模的方法,而且还不一样。
有些教材甚至没讲全,这样就更加云里雾里。
因此究竟在什么时候确定就需要详细分析下了。
其实,样本规模的确定并不是一次成型的,多数情况下要分好几个阶段分别确定,然后选择最大的必要样本规模。
二、究竟哪些阶段需要确定样本规模经典统计大致就是估计及假设检验两大基础方法。
回归、结构方程、因子分析等,估计是上述两方面为基础的(除回归外,其它具体还没考证,哈哈)。
上述两大基础方法,都是以正态分布的总体为前提,这样均值等统计量的分布就为正态分布。
若总体并非正态分布,这时候就需要开始考虑样本规模了。
因为按中心极限定理,只要样本规模足够大,非正态分布总体的样本的统计量(如均值)的分布为正态分布,统计量与样本方差S2的分布为t分布。
一旦样本的统计量为正态分布或t分布,那上述基础方法就可以使用了。
但问题就来了,究竟多少样本规模算是足够大?由于此必要样本规模与具体的统计方法有关,故以下一并介绍。
(一)估计1.总体正态分布情形1.1点估计以正态分布总体为前提,估计中的点估计根本就不需要确定样本规模,因为它主要强调无偏、有效、一致即可。

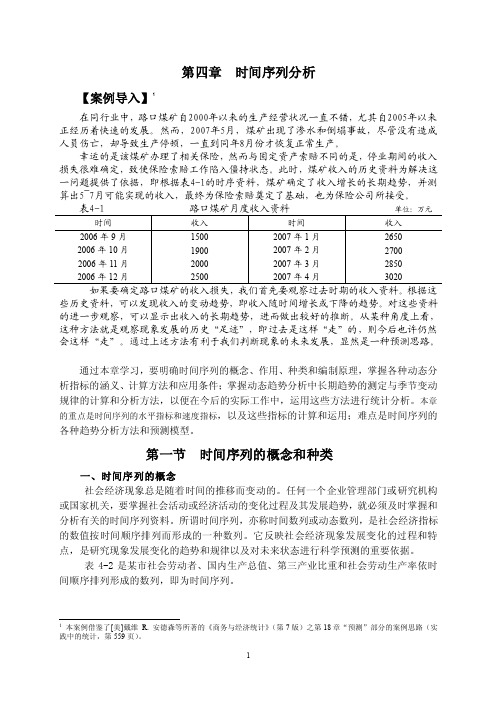
第四章时间序列分析【案例导入】1在同行业中,路口煤矿自2000年以来的生产经营状况一直不错,尤其自2005年以来正经历着快速的发展。
然而,2007年5月,煤矿出现了渗水和倒塌事故,尽管没有造成人员伤亡,却导致生产停顿,一直到同年8月份才恢复正常生产。
幸运的是该煤矿办理了相关保险,然而与固定资产索赔不同的是,停业期间的收入损失很难确定,致使保险索赔工作陷入僵持状态。
此时,煤矿收入的历史资料为解决这一问题提供了依据,即根据表4-1的时序资料,煤矿确定了收入增长的长期趋势,并测算出5~7月可能实现的收入,最终为保险索赔奠定了基础,也为保险公司所接受。
单位:万元些历史资料,可以发现收入的变动趋势,即收入随时间增长或下降的趋势。
对这些资料的进一步观察,可以显示出收入的长期趋势,进而做出较好的推断。
从某种角度上看,这种方法就是观察现象发展的历史“足迹”,即过去是这样“走”的,则今后也许仍然会这样“走”。
通过上述方法有利于我们判断现象的未来发展,显然是一种预测思路。
通过本章学习,要明确时间序列的概念、作用、种类和编制原理,掌握各种动态分析指标的涵义、计算方法和应用条件;掌握动态趋势分析中长期趋势的测定与季节变动规律的计算和分析方法,以便在今后的实际工作中,运用这些方法进行统计分析。
本章的重点是时间序列的水平指标和速度指标,以及这些指标的计算和运用;难点是时间序列的各种趋势分析方法和预测模型。
第一节时间序列的概念和种类一、时间序列的概念社会经济现象总是随着时间的推移而变动的。
任何一个企业管理部门或研究机构或国家机关,要掌握社会活动或经济活动的变化过程及其发展趋势,就必须及时掌握和分析有关的时间序列资料。
所谓时间序列,亦称时间数列或动态数列,是社会经济指标的数值按时间顺序排列而形成的一种数列。
它反映社会经济现象发展变化的过程和特点,是研究现象发展变化的趋势和规律以及对未来状态进行科学预测的重要依据。
表4-2是某市社会劳动者、国内生产总值、第三产业比重和社会劳动生产率依时间顺序排列形成的数列,即为时间序列。


第四章--微分Rules of Differentiation1.基本求导公式(1)(C)'=0 p252(2)(x n)’=nx n-1 p245(3)P333 与复合函数求导结合(e x)’=e x(e mx)=e mx*mlnmx=1/mx*m(4)(lnx)'=1/x p334(5)h(x)=cf(x) then h’(x)=cf’(x) p2512.导数的四则运算加法和减法法则h(x)=f(x)+g(x) then h’(x)=f’(x)+g’(x) P252乘法法则(uv)’=u’v+uv' P278(u、v为可导函数)商法则(u/v)'=(u'v-uv')/v2 △ P2813.The chain rule链式法则p276(复合函数求导)如果y是一个关于u的函数,u本身是关于x的函数,则:dy/dx=dy/du * du/dx4.反函数求导法则设函数y=f(x)在某一区间单调、连续,又在该区间内一点x处导数f'(x)存在且不为零,则反函数x=u(y)在对应点y处存在导数u'(x),且有u'(x)=1/f'(x)4.1和4.2高中学过导数的跳过~4.3边际函数Marginal Functions主要任务:三个领域中的应用1.收益和成本--计算边际收益MR(marginal revenue)和边际成本MC(marginal cost)主用公式:2.2:p129/p131/p132*P与Q的关系式(题目中会给出)若P(price价格)为常数,P与Q(quantity 数量)无关,则为完全竞争市场;若P为关于Q的表达式,则为垄断市场,P 随Q的增加而下降。
1*TR=PQ(TR总收益-total revenue,P-price,Q-sales of Q goods)2*π=TR-TC(π利润profit,因以用p表示price,所以此处用π表示profit)3*TC=FC+(VC)Q(TC总成本-total cost,FC固定成本-fixed cost,VC可变成本-variable cost)4*AC=TR/Q(AC平均成本-average cost)4.3公式1* MR=TR'边际收益是总收益对需求量的导数 p262同理,MC=TC'边际成本是总成本对产出的微分p267(一定将TR、TC写成关于Q的表达式而非关于P的表达式,求导后才是MR、MC)2*Δ(TR)≈MR×ΔQ p264 ΔTR的近似计算公式2. 生产--计算劳动边际产出MP L(marginal product of labour);证明边际产出递减规律MP L=dQ/dL边际产出是产出对劳动的微分(Q关于L的函数)(Q产量-output,L劳动力-labour)若证明边际产出递减规律,则再对MP L求导,证明其恒<0)3. 消费和储蓄--计算边际消费倾向MPC(marginal propensity to consume)和边际储蓄倾向MPS(marginal propensity to save)用到1.6内容Y国民收入-national income,C消费-consumption,S储蓄-savingsC=aY+b(0<a<1,a为边际消费倾向即MPC)Y=C+SMPC+MPS=1MPC=C'(Y) MPS=1-MPC4.5弹性Elasticity主要任务:1.计算弧弹性和点弹性;需求函数的价格弹性Price elasticity of Demand(经济学中一般用来衡量需求的数量随商品的价格的变动而变动的情况)☆因需求函数中P上升(价格)时,Q(需求数量)下降,即ΔP>0时,ΔQ<0,为使E符号位正,求时需加负号E= -需求变化的百分数/价格变化的百分数☆弧弹性Elasticity averaged along an arc(题目给出两点,两点平均,不用求导)E=-ΔQ/ΔP * P/QΔQ=Q2-Q1,ΔP=P2-P1 , P=(P1+P2)/2 ,Q=(Q1+Q2)/2☆点弹性Elasticity at a point(在一点的弹性,需求此点的导数)E=-Q’P *P/QQ’P=1/P’Q供给函数的价格弹性Price Elasticity of Supply除了应去掉负号外与需求函数价格弹性公式都相同因供给中P(价格)上升时,Q(企业产出数量)上升,即ΔP>0时,ΔQ>0,E为正,故前不用加负号△此节特别注意正负号问题,不能漏加,也不能少加,Demand有负号,Supply 没有(供给与需求中,P、Q关系,涉及1.3内容p53)2.求出E后,判断供给和需求函数是缺乏弹性、单位弹性还是富有弹性E<1 inelasricE=1unit elasticE>1 elastic3.公式变形,求出E后,由价格变化ΔP/P*100%求需求或供给ΔQ/Q*100%,或P、Q反过来求也一样4.6经济函数的最优化1.求驻点stationary pointf '(x)=02.求局部最大maximumf ''(x)<03.求局部最小minimumf ''(x)>04.拐点f ''(x)=o5.计算并证明在劳动平均产出的最大点处MP L=AP L6.计算并证明在利润π最大点处MR=MC(π'=0,π'=MR-MC , π''=MR'-MC'<0,MR'<MC')(p312的例题,和第一章的收税问题结合,比较好~很值得一看!参考1.2 p55例题用到公式市场均衡时,Q S=Q D=Q*对企业单位商品征税t:需求函数不变,供给函数由P=cQ s+d,变为P=cQ s+d+t △重要,注意t加在等式的右边政府总税收T=tQ*)求极值就求导,一阶导数为0,→stationary point,然后再求二阶导数,证明其是max或min4.7经济函数的进一步优化主要任务:1.没有价格歧视price discrimination时,函数都用Q表示,用已证明的在利润π最大点处MR=MC,且MR'<MC'解题,计算利益最大时,两种商品的价格2.有价格歧视时,为了方便,可以TR、TC、π都用P表示,用π'=0,计算两种商品的价格(黄万阳老师就这么做的,跟课本上不同,但其实原理都一样)4.8AP L=Q/LAP L’=0AP L’’<0,max,AP L’’>0,min仍为求极值问题,只不过求导用了乘法、除法和链式法则而已,若考了,知道怎么求导,注意一下求导的时候仔细点就ok,此节不做重点,看p338例题第三章--金融数学Mathematics of Finance3.1百分数percentages主要任务:1.使用百分数表示各种东西,初中内容而已,果断跳过2.求指数时,被选择的基期年份的值为100,指数=相对基期的比例因子*100,求出然后进行各年间的比较index number=scale factor form base year*100(P187也有个小公式,不写了,不一定能出大题,有兴趣的童鞋看一下)3.Inflation通货膨胀△annual rate of inflation年通货膨胀率(上一年所选定的商品和劳务价格在本年度平均变化的百分比)nominal data名义值(最初的原始数据)real data真值(又叫实际值,是考虑到通货膨胀后调整过的数据)比较名义价格与实际价格的上涨p189例题3.2 Compound interest 复利公式1.S=P(1+r/100)nP-本金principal,S-终值future value,r-年复利,t-时间△注意题目所给interest一般就是以年为单位的年复利r%,一般r%<0.有一年复利,半年复利,季度复利,每月复利,每周复利,即根据年利率将其分成2份、4份、12份、52份。

商务与经济统计学习笔记整理安德森第13版2018/12/11开始阅读,2019/1⽉14⽇完成
正常页3min/per_page,有难度页5min/per_page
正常每天1-1.5⼩时阅读。
共计耗时36⼩时。
同期开始学习Python(⽬前⾄递归函数)
学习笔记⼤纲:
第20章指数
第19章质量管理的统计⽅法
第18章⾮参数⽅法
第17章时间序列分析及预测
第16章回归分析:建⽴模型
第15章多元回归
第14章简单线性回归
第13章实验设计与⽅差分析
第12章多个⽐率的⽐较、独⽴性及拟合优度检验
第11章总体⽅差的统计推断
第10章两总体均值和⽐例的推断
第9章假设检验
第8章区间估计
第7章抽样和抽样分布
第6章连续型概率分布
第5章离散型概率分布。
商业统计学公式大全1.中心趋势测量-平均值公式:平均值=总和/观测数量-中位数公式:将所有观测值按顺序排列,取中间的值作为中位数-众数公式:出现频率最高的观测值-加权平均值公式:加权平均值=∑(观测值×权重)/∑权重2.离散程度测量-方差公式:方差=(∑(观测值-平均值)^2)/观测数量-标准差公式:标准差=√方差-平均绝对离差公式:平均绝对离差=(∑,观测值-平均值,)/观测数量-变异系数公式:变异系数=(标准差/平均值)×100%3.概率与概率分布-概率公式:概率=事件发生次数/总次数-累计概率公式:累计概率=当前事件之前所有事件的概率之和-正态分布公式:Z=(观测值-平均值)/标准差4.假设检验-单样本t检验公式:t=(样本均值-总体均值)/(标准差/√样本数量)-双样本t检验公式:t=(样本均值差-总体均值差)/(标准差/√((样本1数量-1)+(样本2数量-1)))5.回归分析- 简单线性回归方程公式:y = a + bx- 多元线性回归方程公式:y = a + b1x1 + b2x2 + ... + bnxn- 线性相关系数公式:r = (n∑xy - (∑x)(∑y)) / √((n∑x^2 - (∑x)^2)(n∑y^2 - (∑y)^2))-判定系数公式:判定系数=相关系数^26.预测与趋势分析-移动平均法公式:移动平均=(∑数据点)/观测数量-指数平滑法公式:本期预测值=上期预测值+α(本期观测值-上期预测值)7.抽样与抽样误差-简单随机抽样公式:每个个体被选中的概率相等-抽样误差公式:抽样误差=总体标准差/√样本数量这些公式是商业统计学中的基础,可以用于描述、分析和预测商业数据,从而帮助企业做出合理的决策。
在实际应用中,还需要根据具体情况选择适合的公式和方法,并结合实际数据进行计算和分析。
关键术语统计学(Statistics)收收集、分析、表述和解释数据的艺术和科学。
数据( Data)收被收集、分析和解释的事实与数字。
数据集(Data set)一特定研究中所有收集的数据。
个体( Elements )从中收集数据的实体。
变量( Variable)个体的某种令人感兴趣的属性。
观测值( Observation )为单个个体获取的度量集。
品质数据(Qualitative data)为一个体的性质提供标记或名称的数据。
品质数据可能是非数值或数值型的。
品质变量(Qualitative variable)有关品质数据的变量。
数量数据(Quantitative data)表明某事多少的数据。
数量数据总是数值型的。
数量变量(Quantitative variable)有关数量数据的变量。
截面数据(Cross-sectional data)在同时或近似相同时点收集的数据。
时间序列数据( Time series data)在几个连续期间收集的数据。
描述统计学(Descriptive statistics)用于汇总数据的表、图和数值方法。
总体(Population )一特定研究中所有感兴趣个体的集合。
样本( Sample )总体的一个子集。
统计推断(Statistical inference)利用从一个样本获得的数据对总体性质进行估计或假设检验的过程。
频数分布(Frequency distribution) 对一数据集的表格汇总法,显示若干无重叠组别中每一组的项目频数(或个数)。
相对频数分布(Relative frequency distribution) 一数据集的表格汇总法,显示在若干无重叠组别中每一组的项目总数的相对频数,即分数或比例。
百分数频数分布(Percent frequency distribution) 一数据集的表格汇总法,显示几个无重叠组别中每一组的项目总数的百分率。
条形图(Bar graph) 一种图形方法,描述在品质数据的频数分布、相对频数据分布或百分数频数分布中表示的信息。