实验六 MySql存储过程
- 格式:doc
- 大小:277.00 KB
- 文档页数:7
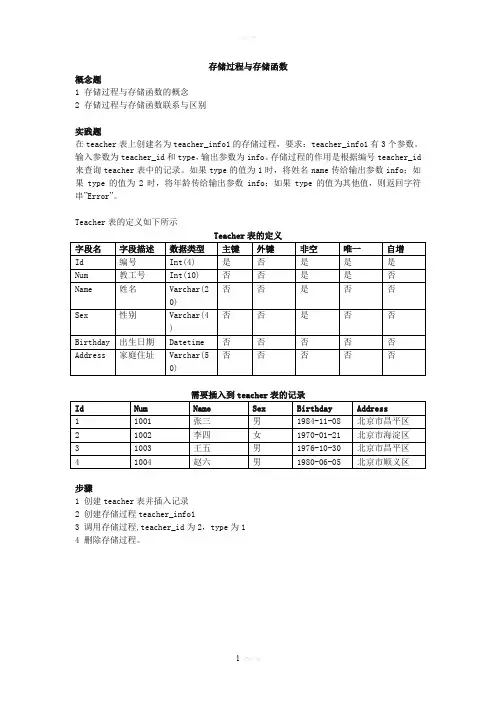
存储过程与存储函数概念题1 存储过程与存储函数的概念2 存储过程与存储函数联系与区别实践题在teacher表上创建名为teacher_info1的存储过程,要求:teacher_info1有3个参数。
输入参数为teacher_id和type,输出参数为info。
存储过程的作用是根据编号teacher_id 来查询teacher表中的记录。
如果type的值为1时,将姓名name传给输出参数info;如果type的值为2时,将年龄传给输出参数info;如果type的值为其他值,则返回字符串”Error”。
Teacher表的定义如下所示Teacher表的定义需要插入到teacher表的记录步骤1 创建teacher表并插入记录2 创建存储过程teacher_info13 调用存储过程,teacher_id为2,type为14 删除存储过程。
概念题1 存储过程和函数是在数据库中定义一些SQL语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的SQL语句。
存储过程和函数可以避免开发人员重复的编写相同的SQL 语句。
而且,存储过程和函数是在MySQL服务器中存储和执行的,可以减少客户端和服务器端的数据传输。
2 存储过程与存储函数一样,都是由sql语句和过程式语句所组成的代码片段,并且可以被应用程序和其他sql语句调用。
区别:存储函数不能拥有输出参数,因为存储函数自身就是输出参数;而存储过程可以拥有输出参数。
存储函数可以直接对存储函数进行调用,而不需要使用call语句;而对存储过程的调用,需要使用call语句。
存储函数中必须包含一条return语句,而这条特殊的sql语句不允许包含于存储过程中。
实践题1 CREATE TABLE teacher(id INT(4) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT,num INT(10) NOT NULL UNIQUE ,name VARCHAR(20) NOT NULL ,sex VARCHAR(4) NOT NULL ,birthday DATETIME ,address VARCHAR(50));INSERT INTO teacher VALUES(1, 1001, '张三','男' ,'1984-11-08' ,'北京市昌平区');INSERT INTO teacher VALUES(2, 1002, '李四','女' ,'1970-01-21' ,'北京市海淀区') ,(NULL, 1003, '王五','男' ,'1976-10-30' ,'北京市昌平区') ,(NULL, 1004, '赵六','男' ,'1980-06-05' ,'北京市顺义区') ;2 DELIMITER &&CREATE PROCEDUREteacher_info1(IN teacher_id INT, IN type INT,OUT info VARCHAR(20))READS SQL DATABEGINCASE typeWHEN 1 THENSELECT name INTO info FROM teacher WHERE id=teacher_id;WHEN 2 THENSELECT YEAR(NOW())-YEAR(birthday) INTO infoFROM teacher WHERE id=teacher_id;ELSESELECT ‘ERROR’ INTO info;END CASE;END &&DELIMITER ;3 CALL teacher_info1(2,1,@info);SELECT @info;4 DROP PROCEDURE teacher_info1;欢迎您的下载,资料仅供参考!致力为企业和个人提供合同协议,策划案计划书,学习资料等等打造全网一站式需求。

mysql存储过程MySQL存储过程1. 存储过程简介我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(StoredProcedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
一个存储过程是一个可编程的函数,它在数据库中创建并保存。
它可以有SQL 语句和一些特殊的控制结构组成。
当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。
数据库中的存储过程可以看做是对编程中面向对象方法的模拟。
它允许控制数据的访问方式。
存储过程通常有以下优点:(1).存储过程增强了SQL语言的功能和灵活性。
存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).存储过程允许标准组件是编程。
存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。
而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).存储过程能实现较快的执行速度。
如果某一操作包含大量的Transaction-SQL 代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。
因为存储过程是预编译的。
在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。
而批处理的Transaction-SQL 语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).存储过程能过减少网络流量。
针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
(5).存储过程可被作为一种安全机制来充分利用。
系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。

实验项目列表实验一:数据库的定义实验一、实验目的:1、理解MySQL Server 6.0 服务器的安装过程和方法;2、要求学生熟练掌握和使用SQL、T-SQL、SQL Server Enterpriser Manager Server 创建数据库、表、索引和修改表结构,并学会使用SQL Server Query Analyzer,接收T-SQL语句和进行结果分析。
二、实验环境:硬件:PC机软件:Windows操作系统、 MySQL Server 6.0 和Navicat for MySQL 9.0三、实验内容和原理:1、安装MySQL以及相应的GUI工具2、用SQL命令,建立学生-课程数据库基本表:学生Student(学号Sno,姓名Sname,年龄Sage,性别Ssex,所在系Sdept);课程Course(课程号Cno,课程名Cname,先行课Cpno,学分Ccredit);选课SC(学号Sno,课程号Cno,成绩Grade);要求:1) 用SQL命令建库、建表和建立表间联系。
2) 选择合适的数据类型。
3) 定义必要的索引、列级约束和表级约束.四、实验步骤:1、运行Navicat for MySQL,然后进行数据库连接,进入到GUI界面;2、利用图形界面建立基础表:student表的信息:Sage smallint 6Sdept varchar 20course表的信息:字段名类型长度约束条件Cno varchar 4 非空、主键Cname varchar 40Cpno varchar 4 与course表中Cno关联Ccredit smallint 6sc表的信息:字段名类型长度约束条件Sno varchar 9 非空、主键、与student表中Sno外键关联,级联删除Cno varchar 4 非空、主键、与course表中Cno外键关联Grade smallint 6(1)、连接数据库,在localhost中点击鼠标右键(如图1所示),点击“新建数据库”,在弹出的窗口中输入数据库名称(如图2所示),然后单击“确定”,就完成了数据库的建立。

MYSQL存储过程注释详解⽬录1.使⽤说明2.准备3.语法3.1 变量及赋值3.2 ⼊参出参3.3 流程控制-判断3.4 流程控制-循环3.5 流程控制-退出、继续循环3.6 游标3.7 存储过程中的handler4.练习4.1 利⽤存储过程更新数据4.3 其他场景:5.其他5.1 characteristic5.2 死循环处理5.3 可以在select语句中写case5.4 临时表0.环境说明:软件版本mysql8.0navicat1.使⽤说明存储过程时数据库的⼀个重要的对象,可以封装SQL语句集,可以⽤来完成⼀些较复杂的业务逻辑,并且可以⼊参出参(类似于java中的⽅法的书写)。
创建时会预先编译后保存,⽤户后续的调⽤都不需要再次编译。
// 把editUser类⽐成⼀个存储过程public void editUser(User user,String username){String a = "nihao";user.setUsername(username);}main(){User user = new User();editUser(user,"张三");user.getUseranme(); //java基础}⼤家可能会思考,⽤sql处理业务逻辑还要重新学,我⽤java来处理逻辑(⽐如循环判断、循环查询等)不⾏吗?那么,为什么还要⽤存储过程处理业务逻辑呢?优点:在⽣产环境下,可以通过直接修改存储过程的⽅式修改业务逻辑(或bug),⽽不⽤重启服务器。
执⾏速度快,存储过程经过编译之后会⽐单独⼀条⼀条执⾏要快。
减少⽹络传输流量。
⽅便优化。
缺点:过程化编程,复杂业务处理的维护成本⾼。
调试不便不同数据库之间可移植性差。
-- 不同数据库语法不⼀致!2.准备数据库参阅资料中的sql脚本:delimiter $$ --声明结束符3.语法官⽅参考⽹址:#### 3.0 语法结构```sql-- 存储过程结构CREATE[DEFINER = user]PROCEDURE sp_name ([proc_parameter[,...]])[characteristic ...] routine_body-- 1. proc_parameter参数部分,可以如下书写:[ IN | OUT | INOUT ] param_name type-- type类型可以是MySQL⽀持的所有类型-- 2. routine_body(程序体)部分,可以书写合法的SQL语句 BEGIN ... END简单演⽰:-- 声明结束符。

mysql存储过程返回结果集的方法使用MySQL存储过程返回结果集的方法MySQL是一种常用的关系型数据库管理系统,提供了存储过程的功能,可以帮助我们更好地组织和管理数据库操作。
在某些情况下,我们需要从存储过程中返回结果集,本文将介绍如何使用MySQL存储过程返回结果集。
一、什么是存储过程存储过程是一组预先编译好的SQL语句集合,类似于程序中的函数。
存储过程通常由一系列的SQL语句和控制结构组成,可以接受参数并返回结果。
存储过程可以提高数据库操作的效率,减少网络传输的开销,并且可以重复使用。
二、存储过程返回结果集的方法1. 使用游标游标是一种用于遍历结果集的数据结构。
在存储过程中,可以使用游标来获取结果集,并返回给调用者。
以下是一个示例的存储过程,使用游标返回结果集:```DELIMITER $$CREATE PROCEDURE get_employee()BEGINDECLARE done INT DEFAULT FALSE;DECLARE emp_name VARCHAR(255);DECLARE emp_salary INT;DECLARE cur CURSOR FOR SELECT name, salary FROM employee;DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; OPEN cur;FETCH cur INTO emp_name, emp_salary;WHILE NOT done DO-- 处理结果集的逻辑-- 这里可以将结果集保存到一个临时表中或者直接返回给调用者FETCH cur INTO emp_name, emp_salary;END WHILE;CLOSE cur;END $$DELIMITER ;```2. 使用临时表另一种常用的方法是使用临时表来保存需要返回的结果集。
存储过程可以先将结果集插入到临时表中,然后将临时表返回给调用者。

mysql 存储过程语法MySQL一款流行的关系型数据库管理系统,它拥有丰富的数据库管理功能,同时支持 SQL存储过程,存储过程语法给 MySQL供了一种新的强大的编程能力,可以实现有效的数据操作。
存储过程是一种基于计算机的系统软件,用于处理数据库的程序模块,其提供的一组功能和程序,用户可以使用它来完成所需的数据库操作。
MySQL持存储过程,使用它们可以使用更加灵活的方式来处理数据库。
MySQL存储过程语法主要由以下几个关键部分组成:定义语句、参数、处理结构和处理流程。
定义语句是定义存储过程的基础,它可以定义一个新的存储过程,也可以定义一个已存在的存储过程。
参数是用来传递参数的变量,可以被用在存储过程中,这些参数可以是输入参数、输出参数或双向参数。
处理结构是 SQL句的集合,它们可以用来控制存储过程的执行流程和行为,这些处理结构可以通过类似IF WHILE句来实现。
处理流程是由处理结构组成的,它们可以用来控制存储过程的执行,处理流程可以利用处理结构,声明变量、调用函数、执行 SQL句、控制程序流程等。
MySQL存储过程语法可以用来实现更加灵活的数据库应用程序,它们能够有效地控制程序的执行流程,提高程序的效率,减少编程的工作量。
MySQL还支持触发器,它们是存储过程的一部分,当某个事件发生时,就会自动触发执行指定的存储过程,这样可以使用者更加便捷地处理一些重复性工作。
MySQL存储过程语法非常有用,但它们也有一定的局限性。
由于MySQL存储过程语法只能支持基本的 SQL句,因此不能支持复杂的数据操作,也不能支持复杂的函数调用,而且由于 MySQL存储过程语法受限,也无法实现一些高级的数据库技术。
总结,MySQL储过程语法是一种非常有效的数据库编程方式,它可以为数据库应用程序带来更加灵活的处理程序,但也有一定的局限性,不能实现一些复杂的数据操作。

MySQL存储过程实例教程MySQL 5.0以后的版本开始支持存储过程,存储过程具有一致性、高效性、安全性和体系结构等特点,本节将通过具体的实例讲解PHP是如何操纵MySQL存储过程的。
1:存储过程的创建这是一个创建存储过程的实例实例说明为了保证数据的完整性、一致性,提高应用的性能,常采用存储过程技术。
MySQL 5.0之前的版本并不支持存储过程,随着MySQL技术的日趋完善,存储过程将在以后的项目中得到广泛的应用。
本实例将介绍在MySQL 5.0以后的版本中创建存储过程。
技术要点一个存储过程包括名字、参数列表,以及可以包括很多SQL语句的SQL语句集。
下面为一个存储过程的定义过程: create procedure proc_name (in parameterinteger)begindeclare variable varchar(20);if parameter=1 thensetvariable='MySQL';elseset variable='PHP';end if;insert into tb (name) values (variable);end;MySQL中存储过程的建立以关键字create procedure开始,后面紧跟存储过程的名称和参数。
MySQL的存储过程名称不区分大小写,例如PROCE1()和proce1()代表同一个存储过程名。
存储过程名不能与MySQL数据库中的内建函数重名。
存储过程的参数一般由3部分组成。
第一部分可以是in、out或inout。
in表示向存储过程中传入参数;out表示向外传出参数;inout表示定义的参数可传入存储过程,并可以被存储过程修改后传出存储过程,存储过程默认为传入参数,所以参数in可以省略。
第二部分为参数名。
第三部分为参数的类型,该类型为MySQL数据库中所有可用的字段类型,如果有多个参数,参数之间可以用逗号进行分割。

一、实验模块数据库原理与应用二、实验标题存储过程操作实验三、实验内容1. 实验目的(1)掌握存储过程的概念和作用。
(2)学会创建和使用存储过程。
(3)了解存储过程与触发器的区别。
2. 实验原理存储过程是一组为了完成特定功能的SQL语句集,存储在数据库中供应用程序调用。
它可以提高数据库性能,简化代码编写,提高安全性。
3. 实验步骤(1)创建数据库```sqlCREATE DATABASE IF NOT EXISTS experiment;USE experiment;```(2)创建表```sqlCREATE TABLE IF NOT EXISTS employee (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50),age INT,department_id INT);CREATE TABLE IF NOT EXISTS department (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50));```(3)插入数据```sqlINSERT INTO employee (name, age, department_id) VALUES ('张三', 25, 1),('李四', 30, 2),('王五', 28, 3);INSERT INTO department (name) VALUES ('技术部'),('业务部'),('售后部');```(4)创建存储过程```sqlDELIMITER //CREATE PROCEDURE get_department_name(IN emp_id INT, OUT dept_name VARCHAR(50))BEGINSELECT INTO dept_name FROM employee e INNER JOIN department d ON e.department_id = d.id WHERE e.id = emp_id;END //DELIMITER ;```(5)调用存储过程```sqlCALL get_department_name(1, @dept_name);SELECT @dept_name AS department_name;```(6)创建触发器```sqlDELIMITER //CREATE TRIGGER before_employee_insertBEFORE INSERT ON employeeFOR EACH ROWBEGINIF NEW.age < 20 THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = '年龄不能小于20岁'; END IF;END //DELIMITER ;```(7)尝试插入年龄小于20岁的数据```sqlINSERT INTO employee (name, age, department_id) VALUES ('赵六', 18, 1);```4. 实验结果与分析(1)成功创建存储过程和触发器。

mysql实验报告《MySQL实验报告》摘要:本实验报告旨在对MySQL数据库进行实验,通过实验过程和结果分析,深入了解MySQL数据库的基本操作和特性。
实验内容包括数据库的创建、表的设计与管理、数据的插入与查询等,通过实验验证了MySQL数据库的稳定性和高效性。
通过本实验报告,读者将能够对MySQL数据库有更深入的了解,并且掌握基本的数据库操作技能。
一、实验目的本次实验的目的是通过对MySQL数据库的实验,掌握MySQL数据库的基本操作和特性,包括数据库的创建、表的设计与管理、数据的插入与查询等。
二、实验环境本次实验使用的环境为Windows操作系统,MySQL数据库管理系统。
三、实验内容1. 数据库的创建:通过命令行或者图形化界面创建一个新的数据库。
2. 表的设计与管理:设计一个包含多个字段的表,并进行表的管理操作,如添加、删除、修改字段等。
3. 数据的插入与查询:向表中插入数据,并进行简单的查询操作,包括条件查询、排序等。
四、实验步骤1. 数据库的创建:使用CREATE DATABASE命令创建一个名为“test”的数据库。
2. 表的设计与管理:使用CREATE TABLE命令创建一个名为“student”的表,并添加、删除、修改表的字段。
3. 数据的插入与查询:使用INSERT INTO命令向表中插入数据,并使用SELECT 命令进行简单的查询操作。
五、实验结果与分析通过实验,我们成功创建了一个名为“test”的数据库,并在其中创建了一个名为“student”的表。
我们成功向表中插入了数据,并且能够通过查询操作获取到所需的数据。
实验结果表明,MySQL数据库具有稳定性和高效性,能够满足基本的数据库操作需求。
六、实验总结通过本次实验,我们对MySQL数据库有了更深入的了解,掌握了基本的数据库操作技能。
通过实验过程和结果分析,我们认识到MySQL数据库具有稳定性和高效性,适用于各种规模的应用场景。

mysql的存储过程和函数MySQL的存储过程和函数是数据库中非常重要的两个概念,它们可以帮助我们更加高效地管理和操作数据库。
在本文中,我们将详细介绍MySQL的存储过程和函数,包括它们的定义、使用方法以及优缺点等方面。
一、MySQL的存储过程1. 定义MySQL的存储过程是一组预编译的SQL语句,它们被存储在数据库中,并可以被多次调用。
存储过程可以接受参数,并且可以返回结果集或者输出参数。
2. 使用方法创建存储过程的语法如下:CREATE PROCEDURE procedure_name ([IN|OUT|INOUT] parameter_name data_type [, ...])BEGIN-- 存储过程的SQL语句END;其中,procedure_name是存储过程的名称,parameter_name是存储过程的参数名称,data_type是参数的数据类型。
IN表示输入参数,OUT表示输出参数,INOUT表示既是输入参数又是输出参数。
调用存储过程的语法如下:CALL procedure_name ([parameter_value, ...]);其中,procedure_name是存储过程的名称,parameter_value是存储过程的参数值。
3. 优缺点存储过程的优点在于:(1)提高了数据库的性能,因为存储过程是预编译的,可以减少SQL语句的解析和编译时间。
(2)提高了数据库的安全性,因为存储过程可以控制对数据库的访问权限。
(3)提高了代码的可维护性,因为存储过程可以被多次调用,可以减少代码的重复性。
存储过程的缺点在于:(1)需要学习存储过程的语法和使用方法。
(2)存储过程的调试和测试比较困难。
二、MySQL的函数1. 定义MySQL的函数是一段预编译的代码,它们可以接受参数,并且可以返回一个值。
函数可以被多次调用,并且可以嵌套使用。
2. 使用方法创建函数的语法如下:CREATE FUNCTION function_name ([parameter_name data_type [, ...]])RETURNS return_typeBEGIN-- 函数的SQL语句END;其中,function_name是函数的名称,parameter_name是函数的参数名称,data_type是参数的数据类型,return_type是函数的返回值类型。

在MySQL中使用存储过程进行数据分析和统计数据分析和统计在今天的信息时代变得越来越重要。
对于企业和组织来说,能够准确地了解和分析数据是决策制定的关键。
MySQL作为一种常用的关系型数据库管理系统,不仅提供了强大的数据存储和查询功能,还提供了存储过程的机制,可以用来进行更复杂的数据分析和统计。
一、存储过程简介存储过程是一组预编译的SQL语句集合,可以在数据库服务器上存储和执行。
它的优势在于可以减少网络开销,提高查询性能,同时也方便了维护和管理。
在MySQL中,通过CREATE PROCEDURE语句创建存储过程,然后通过CALL语句来执行。
为了演示存储过程在数据分析和统计中的应用,我们假设我们有一个包含大量销售数据的表,其中包含了销售日期、销售数量、产品价格等信息。
二、使用存储过程进行数据分析首先,我们可以使用存储过程来计算总销售额。
我们可以创建一个名为calculate_total_sales的存储过程,使用SUM函数来计算所有产品的销售额,并将结果返回。
```DELIMITER //CREATE PROCEDURE calculate_total_sales(OUT total DECIMAL(10, 2))BEGINSELECT SUM(quantity * price) INTO total FROM sales;END//DELIMITER ;```可以通过以下语句来执行该存储过程并获取结果:```CALL calculate_total_sales(@total);SELECT @total;```在上面的代码中,我们使用OUT参数将计算结果返回到变量total中,并在存储过程结束后使用SELECT语句将结果打印出来。
除了计算总销售额,我们还可以使用存储过程来进行更复杂的数据分析,比如计算每个月的平均销售额。
```DELIMITER //CREATE PROCEDURE calculate_average_sales_per_month()BEGINDECLARE month INT;DECLARE total_sales DECIMAL(10, 2);DECLARE total_count INT;DECLARE average_sales DECIMAL(10, 2);SET month = 1;SET total_sales = 0;SET total_count = 0;WHILE month <= 12 DOSELECT SUM(quantity * price), COUNT(*) INTO total_sales, total_count FROM salesWHERE MONTH(sale_date) = month;SET average_sales = total_sales / total_count;SELECT CONCAT('Month ', month, ': ', average_sales) AS result;SET month = month + 1;END WHILE;END//DELIMITER ;```上面的代码中,我们使用了一个循环来计算每个月的平均销售额。
一.实验内容1)创建并执行不带参数的存储过程①针对项目表创建名为“P1_存储过程”的存储过程,要求显示所有记录。
②执行“P1_存储过程”存储过程进行数据浏览。
2)创建并执行带输入参数的存储过程①部门人数应该等于员工表中对应部门实际员工数,由于有员工调入调出,可能存在不等的情况。
编写存储过程“P2_存储过程”,检查指定部门人数的正确性,如果不正确,则进行修改。
②显示部门表和员工表数据;然后执行存储过程;再显示部门表和员工表数据,比较数据是否变化。
3)创建带OUTPUT输出参数的存储过程①设计存储过程“P3_存储过程”,从员工表计算某部门人员平均工资。
要求输入参数为部门号,输出参数是该部门的平均工资。
②编写主程序,调用存储过程,在主程序中显示指定部门的平均工资。
4)创建并执行带输入参数和返回状态的存储过程①设计存储过程“P4_存储过程”,完成对员工表的元组插入工作。
要求使用输入参数。
插入操作成功返出状态值0,失败返出状态值-1。
②执行存储过程,如果返回状态值为0,输出“数据插入成功”,否则输出“数据插入失败”。
5)修改和删除存储过程①修改“P1_存储过程”存储过程,要求指定项目编号作为输入参数,并增加WITH ENCRYPTION 选项。
②查看修改后的“P1_存储过程”存储过程文本。
③执行“P1_存储过程”存储过程④删除“P1_存储过程”存储过程。
二.测试数据与实验结果1、创建并执行不带参数的存储过程a、针对项目表创建名为“P1_存储过程”的存储过程,显示所有记录,代码如下:create procedure P1_存储过程asselect*from项目表b、执行“P1_存储过程”存储过程进行数据浏览,结果如下:2、创建并执行带输入参数的存储过程a、编写存储过程“P2_存储过程”,其中利用游标逐行检查部门人数是否和在员工表中的数据相符合,如果不符合,则利用游标进行定位修改,代码如下:create procedure P2_存储过程asdeclare@部门号char(6),@部门人数intdeclare@n intdeclare部门表_cursor cursor forselect部门号,部门人数from部门表for update of部门人数open部门表_cursorfetch next from部门表_cursor into@部门号,@部门人数while@@FETCH_STATUS=0beginselect@部门号,@部门人数select@n=COUNT(员工号)from员工表where所在部门号=@部门号update部门表set部门人数=@nwhere current of部门表_cursorfetch next from部门表_cursor into@部门号,@部门人数endclose部门表_cursordeallocate部门表_cursor执行存储过程,代码如下:exec P2_存储过程b、显示部门表和员工表数据,然后执行存储过程,可以看出,在执行存储过程之前,“办公室”的人数和员工表中的人数是不相符的,在执行存储过程之后,部门人数成功更新,如下图所示:图1 员工表中的数据图2执行“P2_存储过程”之前的部门表数据图3 执行“P2_存储过程”之后的部门表数据3、创建带OUTPUT输出参数的存储过程a、设计存储过程“P3_存储过程”,从员工表计算某部门人员平均工资,输入参数为部门号,输出参数是该部门的平均工资,创建的过程如下:create procedure P3_存储过程(@部门号char(10),@部门平均工资float output)asselect@部门平均工资=AVG(工资)from员工表where所在部门号=@部门号c、执行的代码和运行结果如下:declare@部门平均工资floatexec P3_存储过程'1011',@部门平均工资outputselect'部门平均工资'=@部门平均工资4、创建并执行带输入参数和返回状态的存储过程a、设计存储过程“P4_存储过程”,完成对员工表的元组插入工作,存储过程的创建代码如下:create procedure P4_存储过程(@员工号char(4),@姓名varchar(20),@性别char(2),@出生年月varchar(60),@技术职称char(10),@工资int,@所在部门号char(6),@参加的项目总数int)asbegin transactioninsert into员工表values(@员工号,@姓名,@性别,cast(@出生年月as datetime),@技术职称,@工资,@所在部门号,@参加的项目总数)if@@error<>0beginrollback transactionreturn-1endelsebegincommit transactionreturn 0endb、执行存储过程,代码如下:此存储过程的返回值是-1或者0,所以可以将返回值赋给变量@statusdeclare@status intexec@status=P4_存储过程'2015','钱六','男','1988-03-15','工程师',2700,'10101','1'if@status=0print'插入成功'elseprint'插入失败'c、执行结果如下:图1 显示插入成功图2 在“员工表”中查看5、修改和删除存储过程a、修改“P1_存储过程”存储过程,要求指定项目编号作为输入参数,并增加WITH ENCRYPTION:alter procedure P1_存储过程(@项目编号char(5))with encryptionasselect*from项目表b、执行存储过程如下:exec P1_存储过程'J1111'c、查看存储过程如下:d、删除存储过程成功,如下图:drop proc P1_存储过程三.实验总结本实验使我学会了在SQL Server 2008中创建存储过程和执行存储过程,现在还不熟悉,希望以后可以通过练习掌握的更好。
第1篇一、实验背景随着数据库技术的不断发展,存储过程在数据库管理中的应用越来越广泛。
存储过程是一组为了完成特定功能的SQL语句集合,它具有提高数据库性能、增强安全性、简化应用开发等优点。
为了更好地掌握存储过程的应用,我们进行了本次实验。
二、实验目的1. 理解存储过程的概念、特点和应用场景。
2. 掌握存储过程的创建、执行、修改和删除方法。
3. 学习使用存储过程实现常见的数据库操作,如数据插入、查询、更新和删除。
4. 熟悉存储过程中的流程控制语句、循环语句和游标操作。
三、实验环境1. 操作系统:Windows 102. 数据库:MySQL 5.73. 开发工具:MySQL Workbench四、实验内容1. 创建存储过程2. 执行存储过程3. 修改存储过程4. 删除存储过程5. 存储过程中的流程控制语句6. 存储过程中的循环语句7. 存储过程中的游标操作五、实验步骤1. 创建存储过程首先,我们创建一个简单的存储过程,用于查询特定部门的所有员工信息。
```sqlCREATE PROCEDURE GetEmployeeInfo(IN dept_id INT)BEGINSELECT FROM employees WHERE department_id = dept_id;END;```在此过程中,我们使用了`IN`参数,表示该参数在调用存储过程时传入。
2. 执行存储过程创建存储过程后,我们可以通过以下命令执行它:```sqlCALL GetEmployeeInfo(10);```这将查询部门ID为10的所有员工信息。
3. 修改存储过程如果需要修改存储过程,可以使用`ALTER PROCEDURE`语句。
例如,将查询条件修改为按姓名查询:```sqlALTER PROCEDURE GetEmployeeInfo(IN emp_name VARCHAR(50))BEGINSELECT FROM employees WHERE name = emp_name;END;```4. 删除存储过程删除存储过程可以使用`DROP PROCEDURE`语句。
实验6 存储过程和触发器一、实验目的1、加深和巩固对存储过程和触发器概念的理解。
2、掌握触发器的简单应用。
3、掌握存储过程的简单应用。
二、实验容一)存储过程:1. 创建一存储过程,求l+2+3+…+n,并打印结果。
CREATE PROCEDURE addresultASDECLARE n int=10,/*最后一个数*/i int=0,result int=0 /*结果*/BEGINWHILE(i<=n)BEGINSET result=result+iSET i=i+1ENDPRINT'1+2+3+...+n的结果是:'PRINT resultRETURN(result)ENDGO2.调用上面的addresult存储过程,打印l十2+3+…+10的结果。
EXEC addresult3. 修改上述存储过程为addresult1,使得n为输入参数,其具体值由用户调用此存储过程时指定。
CREATE PROCEDURE addresult1n int=10 /*最后一个数*/ASDECLARE i int=0,result int=0 /*结果*/BEGINWHILE(i<=n)BEGINSET result=result+iSET i=i+1ENDPRINT'1+2+3+...+n的结果是:'PRINT resultRETURN(result)ENDGO4. 调用上面修改后的addresult1存储过程,打印l+2+3+…+100的结果。
EXEC addresult1 1005.修改上述存储过程为addresult2,将n参数设定默认值为10,并改设sum为输出参数,让主程序能够接收计算结果。
CREATE PROCEDURE addresult2n int=10,/*最后一个数*/sum int out/*结果*/ASDECLARE i int=0BEGINset sum=0WHILE(i<=n)BEGINSET sum=sum+iSET i=i+1ENDENDGO6.调用上面修改后的addresult2存储过程,设置变量s接收计算l+2+3+…+10的结果。
mysql存储过程sql语句存储过程是一组预编译的SQL语句,可以在MySQL数据库中进行存储和重复调用。
下面是一个简单的存储过程示例,用于在数据库中创建一个新的表:sql.DELIMITER //。
CREATE PROCEDURE create_new_table()。
BEGIN.CREATE TABLE new_table (。
id INT AUTO_INCREMENT PRIMARY KEY,。
name VARCHAR(50)。
);END //。
DELIMITER ;在这个示例中,我们首先使用`DELIMITER`语句将语句结束符号改为`//`,然后使用`CREATE PROCEDURE`语句定义了一个名为`create_new_table`的存储过程。
在`BEGIN`和`END`之间是存储过程的主体,其中包含了要执行的SQL语句。
在这个例子中,我们使用`CREATE TABLE`语句创建了一个名为`new_table`的新表,该表包含一个自增的id列和一个名为name的列。
最后,我们使用`DELIMITER ;`将语句结束符号改回分号。
除了创建表,存储过程还可以执行各种其他操作,包括插入、更新、删除数据,以及执行复杂的查询和逻辑处理。
存储过程可以接受参数,并根据参数的不同执行不同的逻辑。
存储过程的灵活性和可重用性使其成为管理和执行复杂数据库操作的有力工具。
需要注意的是,存储过程的语法和用法可能会因不同的数据库系统而有所不同,上面的示例是针对MySQL数据库的存储过程语法。
mysql存储过程sql语句摘要:1.存储过程简介2.创建存储过程3.调用存储过程4.存储过程示例5.存储过程参数6.存储过程返回值7.存储过程错误处理8.总结正文:一、存储过程简介MySQL存储过程是一组预编译的SQL语句,它们在一起执行完成特定任务。
存储过程允许你封装复杂的逻辑、重复执行相同的操作,以及改善应用程序的性能。
在本文中,我们将介绍如何创建和使用存储过程。
二、创建存储过程创建存储过程的语法如下:```DELIMITER //CREATE PROCEDURE 存储过程名称(参数1 数据类型, 参数2 数据类型, ...)BEGIN// 编写SQL语句END //DELIMITER ;```例如,创建一个简单的存储过程,如下:```DELIMITER //CREATE PROCEDURE example_procedure(IN p1 INT, IN p2 VARCHAR(255))BEGINSELECT "Hello, World! " || p1 || " " || p2 AS result;END //DELIMITER ;```三、调用存储过程调用存储过程的语法如下:```CALL 存储过程名称(参数1, 参数2, ...);```例如,调用上面创建的存储过程:```CALL example_procedure(10, "World");```四、存储过程示例以下是一个完整的存储过程示例,用于查询用户信息并分页显示:```DELIMITER //CREATE PROCEDURE paginate_users(IN page_number INT)BEGINSET @start_row = (page_number - 1) * 10;SELECT * FROM users ORDER BY id LIMIT 10 OFFSET @start_row;END //DELIMITER ;```五、存储过程参数存储过程可以接受参数,这些参数在调用存储过程时传递。
实验六MySql存储过程
一、实验目的
1、熟悉MySql的存储过程
二、实验内容
1、建立一张学生表,属性有学号、姓名、年龄三个字段。
2、建立一个存储过程,实现学生的全查询
3、分别用IN 和OUT实现姓名的调用
4、声明一个变量,把变量加1,再把变量加入到学生表的学号字段中。
5、建立一个存储过程,外部调用这个存储过程,当外部传入的值是0时,则在学生表中插入一个学号是17的学生,如果是1时,则在学生表中插入一个学号是18的学生,如果都不是,则在学生表中插入一个学号是19的学生.
6、建立一个存储过程,做一个循环语句,循环插入5个学生。
(至少用三种循环的存储过程方法)
三、试验结果截图
1.建立一张学生表,属性有学号、姓名、年龄三个字段。
2.建立一个存储过程,实现学生的全查询
3.分别用IN 和OUT实现姓名的调用
4.声明一个变量,把变量加1,再把变量加入到学生表的学号字段中。
5.建立一个存储过程,外部调用这个存储过程,当外部传入的值是0时,则在学生表中插入一个学号是17的学生,如果是1时,则在学生表中插入一个学号是18的学生,如果都不是,则在学生表中插入一个学号是19的学生.
6建立一个存储过程,做一个循环语句,循环插入5个学生。
(至少用三种循环的存储过程方法)
所有代码:
1.
create table stu(
stuno int,
stuna varchar(20),
stuage int
);
insert into stu values(001,'zhangsan',22);
insert into stu values(002,'lisi',23);
insert into stu values(003,'wangwu',23);
insert into stu values(004,'maliu',24);
insert into stu values(005,'zhaoqi',25);
insert into stu values(006,'gaoba',23);
insert into stu values(007,'ddddd',22);
insert into stu values(008,'ttttt',21);
2.
create procedure select_all()
select * from stu;
3.
delimiter //
create procedure searchno(
in no int,
out na varchar(20),
out age int
)
begin
select stuna from stu where stuno=no into na;
select stuage from stu where stuno=no into age; end //
delimiter ;
call searchno(n,@na,@age);
select @na,@age;
4.
delimiter //
create procedure noupdate(
in n int)
begin
update stu set stuno=stuno+n;
end //
delimiter ;
5.
delimiter //
create procedure addstu(
in sno int
)
begin
case sno
when 0 then insert into stu values(17,'no17',20); when 1 then insert into stu values(18,'no18',20); else insert into stu values(19,'no19',20);
end case;
end //
delimiter ;
6.
(1).
delimiter //
create procedure add5stu1()
begin
declare num1 int;
set num1=0;
loop_label:loop
insert into stu values (111,'111',20);
set num1=num1+1;
if num1>=5 then leave loop_label;
end if;
end loop;
end //
delimiter ;
(2).
delimiter //
create procedure add5stu2()
begin
declare num2 int;
set num2=0;
while num2<5 do
insert into stu values (222,'222',20);
set num2=num2+1;
end while;
end //
delimiter ;
(3).
delimiter //
create procedure add5stu3()
begin
declare num3 int;
set num3=0;
repeat
insert into stu values (333,'333',20);
set num3=num3+1;
until num3>=5
end repeat;
end //
delimiter ;
四、实验小结
本次试验让我好好补习了下前段时间落下的课程,让我对数据库有了新的体会和认识,
试验中碰到了一些问题,但都已解决和理解。
谢谢老师的细心指导。
五、评阅成绩
实验预习20% 实验过程20% 实验结果30% 实验报告30% 总成绩。