算法导论(第二版)勘误表
- 格式:pdf
- 大小:260.34 KB
- 文档页数:27

《编译原理》(第2版)勘误表2008-8-311、第2页倒数第2行改成:分隔单词的空格通常在词法分析时被删去。
2、第3页图1.2改成:3、第16页倒数第9行开始的那段改成:上一节提到,字符串集合由叫做模式的规则来描述。
正规式是表示这些规则的一种重要方法,因此本节围绕正规式来介绍记号的描述与识别。
在介绍正规式前,先给“语言”一个形式定义。
4、第18页表2.3的第4行第4列改成:ε肯定出现在一个闭包中5、第26页图2.10上面的那段改成:ε-closure(T)的计算是从给定的结点集合出发,在图上搜索可达结点的典型过程。
该图只包含NFA的含ε标记的边,T是给定的结点集合。
计算ε-closure(T)的简单算法是用栈来保存那些边还没有完成ε转换检查的状态。
图2.11描述了这样的过程。
6、第43页倒数第5行第一句改成:正规式可以描述的语言都能用上下文无关文法来描述。
7、第61页5行开始的那段改成:(2)仅使用FOLLOW(A)作为A的同步集合是不够的。
例如,分号在C语言中作为语句的结束符,那么作为语句开始符号的关键字没有出现在表达式非终结符的FOLLOW集合中。
这样,仅按上面(1)来设定同步记号集合的话,作为赋值结束的分号的遗漏会引起下一语句的开始关键字被跳过。
8、第74页图3.15第2行改成:C = {closure ({[S'→ · S ]})};9、第80页图3.19倒数第7行改成:置C 的初值为{closure ({[S ' → · S , $]})};10、第111页倒数第4行开始的那段改成: 语法树作为一种中间表示,允许把翻译从分析中分离出来,形成先分析后翻译的方式,即先分析生成语法树,然后再基于语法树进行翻译。
即使是边分析边翻译,语法树作为一种概念上的中间表示,也是有用的。
C 和Java 的编译器通常显式构造语法树。
11、第119页图4.9下第1行第1句改成: 图4.10给出了图4.9的动作是怎样为a *5*b 构造语法树的。

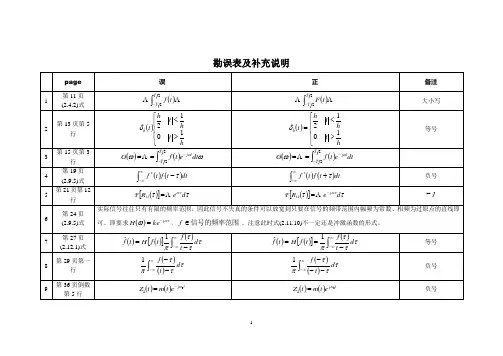
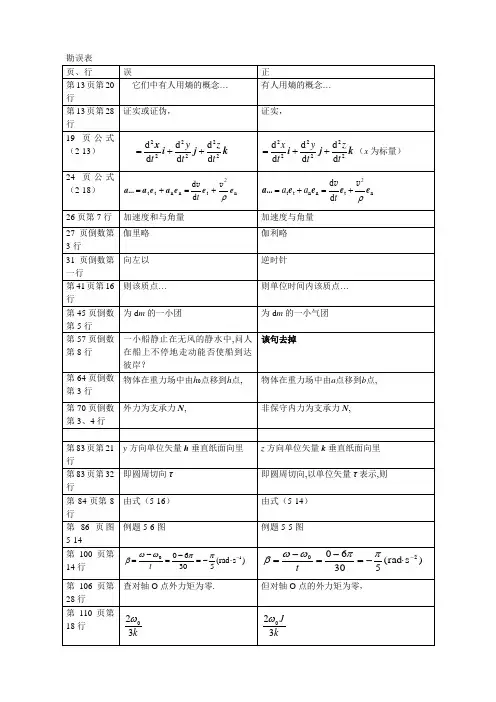
前言P7第4段:经济学解释的是节约(economizing)和交换的逻辑P8第2段:强调市场过程的动态性和企业家创业(entrepreneurial)性质第四章P68第3段:从他人身上获得什么东西,而这又取决于用这些资源能为他人创造出多大的价值。
P73第1段:图中的柱形表示史密斯种植玉米的边际机会成本,以市场价值衡量。
(给定大豆的价格为每单位1美元)。
P77第3段:从供给曲线顶端征来的人越多,换句话说,从供给曲线底端征来的人越少,强制兵役的成本就越高。
第五章P87:斯密认为,当一个社会的成员有效地掌握了专业化能力,P92倒数第1段:,这说明生产更多的吉他意味着更高的边际机会成本。
P975.7 变化的市场条件第4段:一般认为,电吉他和原声吉他是很好的替代品。
P102倒数第1段:一般来说,你向商业银行借钱跟一个大型企业向银行借钱相比,成本会高一些。
第六章P122:尼德尔纠正他:"22000除以1000是21,不对,是22块钱。
"第七章P139倒数第2段:在市场经济中,工资、租金和利息是获取收入的三种重要形式。
P146:7.10 Entrepreneurship and the Market Process(企业家职能与市场过程)P149第2段:对于评估一项新事业(无论是新开…技术革新)使用稀缺资源的方式是不是比以前更有效率、更有利可图这项任务来讲,市场价格是关键。
倒数第1段:企业家实现的利润或亏损则能进一步提供有关其商业眼光正确与否的信息。
P151:7.14 企业家投机的结果P159第2段:这些问题的答案取决于游戏规则及其创造的产权制度。
第八章P175第1段:我们的选择越少,我们的地位就越不利,我们就越可能被“剥削”。
P179:8.6 竞争作为一个过程倒数第2段:完全竞争会导致假想的资源最优配置以及零利润。
P180第3段:我们已经在第五章中讨论过这一点。
经济活动之间往往有一种内在的关联,对经济系统的拙劣描述常常忽略这一点。

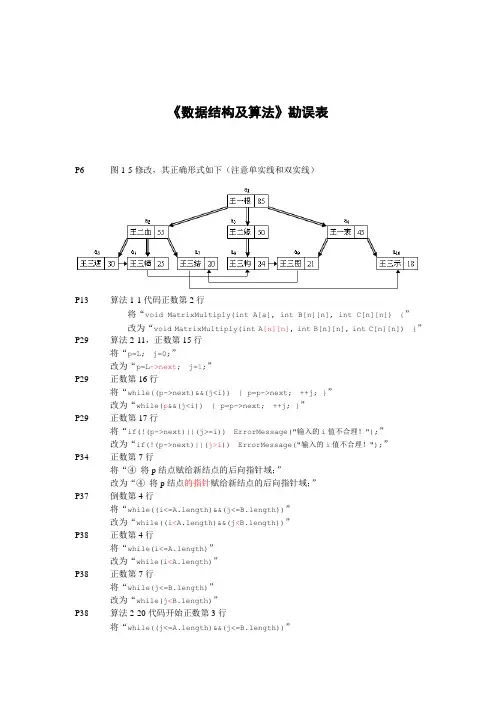
《数据结构及算法》勘误表P6 图1-5修改,其正确形式如下(注意单实线和双实线)P13 算法1-1代码正数第2行将“void MatrixMultiply(int A[a], int B[n][n], int C[n][n]) {”改为“void MatrixMultiply(int A[n][n], int B[n][n], int C[n][n]) {”P29 算法2-11,正数第15行将“p=L; j=0;”改为“p=L->next; j=1;”P29 正数第16行将“while((p->next)&&(j<i)) { p=p->next; ++j; }”改为“while(p&&(j<i)) { p=p->next; ++j; }”P29 正数第17行将“if(!(p->next)||(j>=i)) ErrorMessage("输入的i值不合理!");”改为“if(!(p->next)||(j>i)) ErrorMessage("输入的i值不合理!");”P34 正数第7行将“④将p结点赋给新结点的后向指针域;”改为“④将p结点的指针赋给新结点的后向指针域;”P37 倒数第4行将“while((i<=A.length)&&(j<=B.length))”改为“while((i<A.length)&&(j<B.length))”P38 正数第4行将“while(i<=A.length)”改为“while(i<A.length)”P38 正数第7行将“while(j<=B.length)”改为“while(j<B.length)”P38 算法2-20代码开始正数第3行将“while((j<=A.length)&&(j<=B.length))”改为“j=0;while((j<A.length)&&(j<B.length))”P52 算法3-7代码开始正数第3行将“S=new LNode;”改为“S=new S Node;”P53 算法3-10代码开始正数第3行将“if(S->next) EmptyMessage("链栈S空!");”改为“if(!(S->next)) EmptyMessage("链栈S空!");”P54 算法3-12代码开始正数第3行将“if(S->next) EmptyMessage("链栈S空!");”改为“if(!(S->next)) EmptyMessage("链栈S空!");”P61 算法3-22代码开始正数第3行将“if(Q.front->next) EmptyMessage("链队列Q空!");”改为“if(!(Q.front->next)) EmptyMessage("链队列Q空!");”P61 算法3-24代码开始正数第3行将“if(Q.front==Q.rear) EmptyMessage("链队列Q空!");”改为“if(!(Q.front->next)) EmptyMessage("链队列Q空!");”P63 算法3-26代码开始正数第16行将“if(k=1) return 1;”改为“if(k==1) return 1;”P76 正数22行将“(2) 确定两个串的最大相等前缀子串,"s1 s1 … s k "="t1 t1 … t k"(其中1≤k≤m,1≤k≤n)。



《C语言与程序设计方法(第二版)》勘误表请大家将发现的错误补充进来(请用不同颜色表示你的增加),谢谢!P19例2.1整型常量的表示。
#include <stdio.h>void main() {int a, b, c;a=50; // a为十进制整数50b=-032; // b为八进制整数-32c=0x5b; // c为十六进制整数5bprintf("a=%d, b=%d, c=%d\n", a, b, c); //以十进制整数形式输出a,b,c的值}运行结果如下:a=50, b=-26, c=91P31例2.7整型数据的格式输出。
# include <stdio.h>void main() {int a=-2, b=25;unsigned u=65534, v=28;short c=45;char d='A';printf("a:%d, %u, %o, %x\n", a, a, a, a);printf("u:%d, %u, %o, %x\n", u, u, u, u);printf("b:%d, %u v:%d, %u\n", b, b, v, v);printf("c=%d, d=%d\n", c, d);}运行结果如下:a:-2, 65534, 177776, fffeu:-2, 65534, 177776, fffeb:25, 25 v:28, 28c=45, d=65P33(4) 指定输出宽度。
指定输出宽度和对齐方式需用到附加格式字符m、.n和-。
其中m 为一正整数,用来指定输出宽度(对于f格式符,输出宽度包括整数位、小数点和小数位;对于e 格式符,输出宽度包括尾数部分和指数部分),如果数据的实际宽度比指定输出宽度大,则按实际宽度输出;附加格式符“.n ”的作用是指定输出n 位小数,对于e 格式小数点后仅输出n -1位;附加格式符“-”是用来说明采用左对齐方式,没有“-”时默认是右对齐方式。

《程序设计基础——C语言》教材勘误表【注意】勘误表中红色标识部分是修改后的正确内容。
1.P24页第9行426110改为:4261102.P35页第11行\'"abcefdabcd efd改为:\'"abcefdabcd efd3.P48页表3-3中第二个表达式res=i--改为:res=i--;4.P65页表3-12序号20的输出结果:123.456000e+002改为:1.234560e+0025.P106页图4-16改为:直到“i <=100”为假sum=sum+ii++sum=0 i=1输出sum 的值6. P120页第15行输出九九乘法表中的每一项语句 “printf("%d*%d=%2d",i,j,i*j);” 改为:输出九九乘法表中的每一项语句 “printf("%d*%d=%2d ",i,j,i*j);”7. P135页最后一行要求:x 的值由键盘输入(代码弧度)改为:要求:x 的值由键盘输入(弧度)8. P172页(4) 不可能控制精度。
改为:(4) 不可能控制进度。
9. P173页please enter radius:4 please enter radius:5 圆环面积=28.26改为:please enter radius:4↙ please enter radius:5↙ 圆环面积=28.2610.P206页第4行程序6-16 改为:程序6-1811.P238页int main(){int array[5] ={2,4,6,8,10};;…func(array,5); /*实参为数组名array*/…}改为:int main(){int array[5] ={2,4,6,8,10};…func(array,5); /*实参为数组名array*/…}12.P244页最后一行Int (*pRow)[4];改为:int (*pRow)[4];13.P250页int main(){char string1[N1],string2[N2],string[N];puts("请输入第一个字符串:\n");gets(string1);puts("请输入第二个字符串:\n");gets(string2);link(string1,string2,string);puts("合并后的字符串:");puts(string);return 0;}改为:int main(){char string1[N1],string2[N2],string[N];puts("请输入第一个字符串:");gets(string1);puts("请输入第二个字符串:");gets(string2);link(string1,string2,string);puts("合并后的字符串:");puts(string);return 0;}14.P250页请输入第一个字符串:My请输入第二个字符串:Program改为:请输入第一个字符串:My↙请输入第二个字符串:Program↙15.P251页合并后的字符串:My Program改为:合并后的字符串:MyProgram16.P251页int main(){char string1[N1],string2[N2],string[N];puts("请输入第一个字符串:\n");gets(string1);puts("请输入第二个字符串:\n");gets(string2);link(string1,string2,string);puts("合并后的字符串:");puts(string);return 0;}改为:int main(){char string1[N1],string2[N2],string[N];puts("请输入第一个字符串:");gets(string1);puts("请输入第二个字符串:");gets(string2);link(string1,string2,string);puts("合并后的字符串:");puts(string);return 0;}17.P252页请输入第一个字符串:My请输入第二个字符串:Program合并后的字符串:My Program改为:请输入第一个字符串:My↙请输入第二个字符串:Program↙合并后的字符串:MyProgram18.P276页第4行void sort(char *num[],int n);改为:void sort(char *name[],int n);19.P276页第5行void print(char *nmu[],int n);改为:void print(char *name[],int n);20.P281页struct 结构体名{类型名成员名1;类型名成员名2;……}变量名表列;改为:struct 结构体名{类型名成员名1;类型名成员名2;……}变量名表列;21.P308页输出结果为:98.000000改为:输出结果为:98.00000022.P316页void destroy(struct node *head){struct node *p=head,*pTmp=NULL;while(p!=NULL) /*若不是表尾,则释放节点占用的内存*/{pTmp=p; /*打印节点的数据*/p=p->next; /*让p指向下一个节点*/free(pTmp); /*释放pTmp指向的当前节点占用的内存*/ }}改为:void destroy(struct node *head){struct node *p=head,*pTmp=NULL;while(p!=NULL) /*若不是表尾,则释放节点占用的内存*/{pTmp=p; /*保存当前节点指针到pTmp中*/p=p->next; /*让p指向下一个节点*/free(pTmp); /*释放pTmp指向的当前节点占用的内存*/ }}23.P341页请输入字符串,以#结束:Hello World!↙输出字符串:Hello World!改为:请输入字符串,以#结束:Hello World!#↙输出字符串:Hello World!24.P363页图10-2改为:。
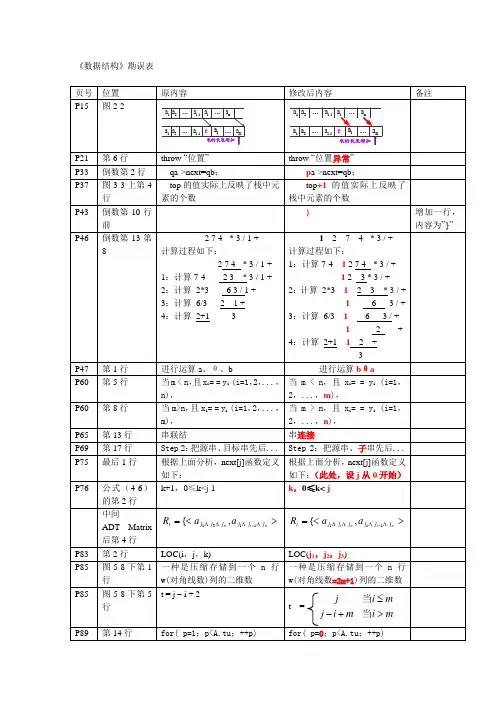
数据结构(c语言版)清华大学出版社秦锋主编勘误(红色字体为修改后的内容)1.教材30页算法描述如下(假定顺序表A和B的存储空间足够):void Inter_sec (PSeqList A, PSeqList B ){ /*求集合A和B的交集,入口参数:指向顺序表的指针,返回值:无,结果存放在顺序表A中*/ int i=0;while(i<A->length){if(!Location_Seqlist(B,A->data[i]))/*B中无A->data[i]*/Delete_SeqList(A,i+1);else i++;/*考察下一个元素*/}}2.教材43页算法如下:(考虑m=1的特殊情况)int josephus_ LinkList (LinkList josephus_Link, int s, int m){ /*求约瑟夫问题的出列元素序列,入口参数:已经存放数据的链表头指针,起始位置s,从1报数到m,出口参数:1表示成功,0表示表中没有元素*/LinkList p,pre;/*p指向当前结点,pre指向其前驱结点*/int count;if ( ! josephus_Link){ printf(“表中无元素”);return (0);}/*找第s个元素*/p= josephus_Link;for(count=1;count<s;count++) /*查找第s个结点,用p作为第s个结点的指针*/ p=p->next;printf(“输出约瑟夫序列:”);while ( p!=p->next) /*输出n-1个结点*/{ pre=p->next;while(pre->next!=p)pre=pre->next;/*pre指针初始化,pre是p的前驱指针*/ for(count=1;count<m;count++){ pre=p;p=p->next;} /*for*/printf(“%d\t”, p->data);pre->next=p->next;free(p);p=pre->next;}/*while*/printf(“%d\t”,p->data); /*输出最后一个结点*/free(p);return 1;}算法2.17该算法时间复杂度是O(n*m)。