❖ 因此连锁分析的基本原理是通过分析两个遗传位点在家系中 的共分离性来确定控制疾病表型变异的的基因位点 .
❖ 连锁分析方法一般是以有关遗传标志为“路 标”,以被定位基因与其连锁基因的重组率 为“遗传学距离”,进行基因定位。
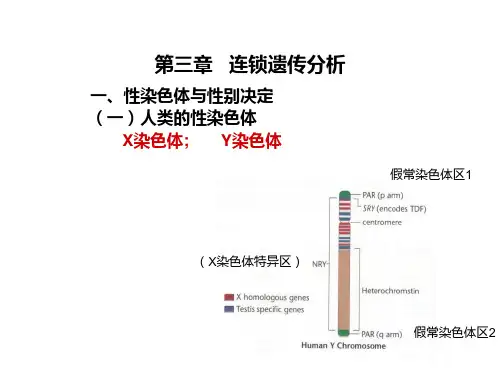
11
2.3:连锁分析的作用
❖ 连锁分析是用来确定人类基因组上疾病易感基因位 置的一种方法。人们认为,已知的标记系统和待推 定的疾病基因座之间的连锁证据是此疾病由一种遗 传机制造成的最有力的统计证据。
❖ 他们的实验如下: ❖ 一对是花的颜色,紫花对红花为显性,一对是
花粉形状,长形对圆形为显性。
3
试验一:
结果表明F2:
1). 同样出现四种表现型;
2). 不符合9:3:3:1;
4
3). 亲本组合数偏多,重新组合数偏少(与理论数相比)。
试验二:
结果与第一个试验情况相同。
5
第二个试验的表现与第一个试验基本相同,同9:3:3:1的 独立遗传比例相比较,在F2四种表现型中仍然是亲本组合性 状(紫、圆和红、长)的实际数多于理论数,重新组合性状的 实际数少于理论数,同样不能用独立分配规律来解释。
❖ 连锁分析仅涉及到基因座的位置,用位置来定位基 因,而不考虑此基因的生化功能。这种方法称为 “定位克隆”(positional cloning)。
12
2.4:连锁分析分类
❖ 分类标准一:按照是否基于模型,可以分为一种是基于模型的 参数分析法,另一种是与模型无关的非参数分析。
❖ 参数方法需要假定性状的遗传模式以及有关的参数值,例如, 致病等位基因的频率,外显率,野生型等位基因的频率和突 变型等位基因的频率,和重组率等等.
❖ 不完全连锁:连锁基因之间发生非姐妹染色 单体间的交换,不仅形成两种亲型配子,同 时形成两种重组型配子。