华中赛B题获奖
- 格式:xlsx
- 大小:19.42 KB
- 文档页数:6
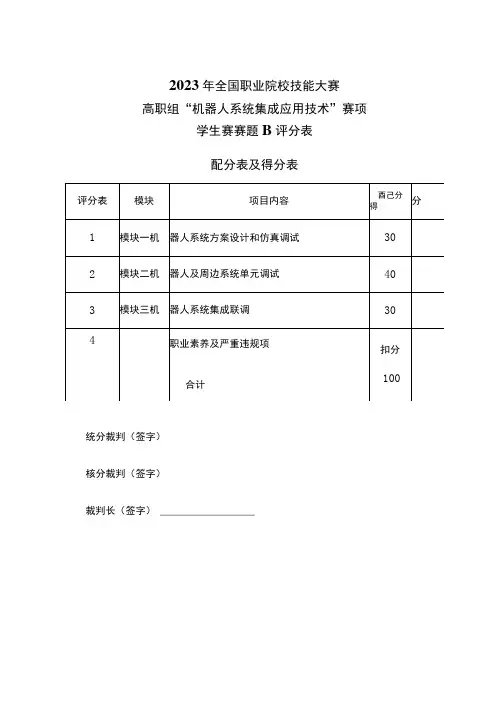
2023年全国职业院校技能大赛高职组“机器人系统集成应用技术”赛项学生赛赛题B评分表配分表及得分表统分裁判(签字)核分裁判(签字)裁判长(签字) ___________________裁判(签名): 选手确认(签赛位号):模块子项评分标准分值得分60-Σ⅛:.小计8完成视觉的安装,得0∙5分,能采集清晰稳定的图像,得0∙5分。
1平1完成视觉的标定,得1分。
(根据4.3任务判,能正确检测出划痕尺寸,此部分正确)评分前准备:1、4号仓位轮毂:视觉检测区域3贴“划痕1”贴纸,视觉检测区域4贴红色标签贴纸2、5号仓位轮毂:正面贴瑕疵贴纸如下图所示位置,并贴“划痕4”任务4视觉单元集成应用8分能正确检测出划痕尺寸,在WINCC显示出来,显示范围误差1.5不超过29mm±0.5mm,得1.5分能正确检测出颜色标签,在WINCC显示出来,显示红色,得1.5L5分能正确检测瑕疵数量,在WlNCC显示数量3,得1分1工业机器人实现使用端面打磨工具,在打磨工位打磨区域2,得2分2小计8一评分前准备:轮毂背面朝上放置到3号仓位中,视觉检测区域3贴划痕3贴纸;视觉检测区域4贴蓝色标签纸在攵,机器人运动状态打到自动运行模式,评分过程任意流程中断或错误,评J梵A分结束,中断后的内容不给分为营商或按下控制面板的绿色“自复位”按钮,流程启动,设备集成三色灯绿灯以IHZ频率闪烁,得1分11.5调或步骤1:3号料仓推出,机器人拾取快换工具,完成24分轮毂抓取,得1.5分模块子项裁判(签名):选手确认(签赛位号):裁判(签选手确认(签赛位号):名):。

2014年美国大学生数学建模大赛落下了帷幕,我们队很幸运地拿到了outstanding(特等奖),还拿到了特别奖Frank Giordano Award,这似乎是中国学校首次拿到这个单项奖。
应数模基地的梅老师之邀,写一篇详细的体会。
我也借这个机会回顾下我的数模之路,从2012年5月的华中赛开始,到2014年的美赛。
希望能给学弟学妹们一些帮助。
一.2012华中赛对于华中科技大学的大多数学子来说,每年5月份的华中赛应该就是与数学建模竞赛的第一次邂逅。
按照学校数模基地的规定,参加华中赛并成功提交论文,是进入暑期培训的必要条件。
因此,尽管华中赛的题目比较简单,比赛规模也不够上档次,但依旧是华科数模人不可磨灭的记忆。
我依稀记得当时的题目是高校硕士研究生招生指标分配问题。
当时我们队三个人都没正式接触过数模,但还是努力地完成了论文,期间主要自学了层次分析法。
当时自己将37页的论文打印出来时,有一种满满的成就感,觉得我们这么认真地做,拿个奖应该没啥问题吧。
可惜结果是残酷的,最后连三等奖都没拿到。
这件事对我打击不小,因为当时的我对自己的数学还是挺自负的,大一几乎所有数学课都是满分,只有一门概率论是98分。
所以当时我尽管没数学建模经验,但仍相信与数学沾边的东西,我肯定不会差。
可第一次参赛就给我浇了一盆冷水。
直到今天,我还保存着当时的论文。
以现在的眼光和水平来看,那篇论文确实漏洞百出,犯了很多大忌,没拿到奖也不算冤枉。
尽管如此,我依旧珍惜这篇论文,我也十分感谢华中赛的失利,它让我知道了数模之路并不容易,切不可因课内的一点成绩就骄傲自大。
二.2012暑期培训每年两个月的暑期培训都是数模基地的重头戏,也是数模基地队员提高实力的黄金时期。
在这里经过高强度的训练,初出茅庐的新手便能在较短的时间内成长为拥有冲击国家一等奖实力的老队员。
这个暑假大概就是三天讲课三天模拟赛的节奏,我们比较系统地学习了数模竞赛中常见的各种模型和算法,而成为正式的国赛队员要经过大概五轮模拟赛的洗礼。

基于任务吸引度的众包平台定价方案优化摘要本文对自助式劳务平台的运营模式及运营效果进行了分析,建立多目标规划模型对定价方案进行了优化,并加入任务打包情况对此方案进行了修改,最终应用在新项口的任务定价中。
对问题一,该项LI任务点分布于四个不同城市。
在分析定价规律时,考虑数据的宏观分布惜况,分别以各任务点与市中心距离、各任务点处会员分布密度为回归变量,以定价为响应变量,通过回归分析研究变量间的定量关系,确定回归系数后,以会员分布密度与定价的回归方程作为定价规律判定。
回归方程表明:定价在宏观上与会员分布密度呈反比例函数关系。
其次,在分析任务未完成原因时,分别定义任务的距离吸引度、标价吸引度来量化距离、标价对任务完成惜况的影响,将任务未完成原因归结为四方面:标价吸引度低、距离吸引度低、会员分布密度低、其它因素。
对问题二,将设计定价方案的过程视为定价方与任务完成方进行博弈的过程,在博弈论的视角下对众包任务定价方案进行了设计。
首先定义了定价基准值的概念,来量化任务本身的价值。
根据问题一的分析结果,任务未完成原因主要是距离吸引度、标价吸引度过低,因此在定价时,从权衡各任务点距离吸引度、标价吸引度入手,分析了任务完成过程中个体的行为规律。
针对任务完成方,分析了会员预定各任务的概率;针对定价方,分析了任务被预定概率、任务被完成概率,其中任务被完成概率与山会员信誉值决定的概率修正因子有关。
以任务被完成概率、定价为H标,建立了无约束多U标规划模型,利用遗传算法确定了每个任务的最优定价。
最后,比较了所设计方案与原方案下任务完成比例和任务标价,很好地表现出了新方案优化效果。
其中新方案的任务完成率为:0.7122,标价总额为:34112.7356。
对问题三,要求修改问题二中定价模型,从而导出适用于含任务包的任务定价方案。
任务打包后,对定价方案造成的影响主要是:任务包中任务个数与会员预定限额之间的矛盾。
首先,在考虑会员预定限额的基础上,确定了任务包的基准价、标价吸引度及距离吸引度。

2023年数学建模国赛B题是关于多波束测线问题。
这是一个非常具有挑战性的题目,需要我们思考和解决。
在本文中,我将从简到繁,从浅入深地探讨这个问题,并提供我个人的观点和理解。
希望通过本文的阅读,你能对这个题目有一个更深入的理解。
一、问题背景多波束测线问题是指在测绘建筑物或场地轮廓时,利用多个发射波束接收返回信号以获取目标轮廓的方法。
而2023年数学建模国赛B题的多波束测线问题则是要求我们通过建立数学模型,从已知点向目标区域内发射波束,测量波束的回波信息,然后根据这些信息计算出目标区域的轮廓。
二、问题分析1. 波束的发射与接收我们需要考虑如何进行波束的发射和接收。
在实际测量中,波束可以由雷达、激光仪等设备发射,然后通过接收设备收集返回的信息。
我们需要建立一套模型来描述波束的发射与接收过程,包括波束的参数、发射源和接收点的位置等。
2. 回波信息的处理接收到的回波信息包含了目标区域内的散射点的位置和强度等信息。
我们需要分析这些信息,找出与目标轮廓有关的数据,并进行数据处理和分析,以便后续的计算和模型建立。
3. 轮廓的计算我们需要根据接收到的回波信息,计算出目标区域的轮廓。
这一部分涉及到数学建模、数据处理和算法设计等内容,需要我们综合运用数学知识和计算机技术来解决。
三、可能的解决方案针对2023年数学建模国赛B题的多波束测线问题,可能的解决方案包括但不限于以下几个方面:1. 建立数学模型,描述波束的发射与接收过程,包括波束的参数、发射源和接收点的位置等。
2. 开发数据处理和分析的方法,提取目标轮廓相关的信息,并对数据进行处理和筛选。
3. 设计计算和模拟算法,根据接收到的回波信息计算出目标区域的轮廓,得出最终的结果。
四、个人观点和理解从我个人的角度来看,2023年数学建模国赛B题的多波束测线问题需要综合运用数学、物理、计算机等各方面的知识和技能来解决。
这是一个非常有挑战性的题目,但同时也是一个很有趣的问题,可以锻炼我们的综合能力和创新思维。

2019年第十二届华中地区数学建模邀请赛
B题库存补单及销量预测
商家原来已有订单,在此基础上,买家又增加新的需求量,追加订单,就是补单。
有时补单也特指因品质异常不能满足客户要求而导致的补单。
但是补单对于许多电商来说也是一个十分烦恼的问题,其问题主要表现在以下两个方面。
补单的第一个问题是对现金流的占用。
在每年双11时的货物成本对于许多电商来说那就是几千万的货值,一但补单没预测好,几千万的资金占用,对于大多数的电商而言都是不小的压力,所以合理的补单预测,尽量减少流动资金的占用对于体量大的公司尤为重要
补单的第二大问题就是库存问题。
一个商品能卖多少实际在你的店铺里面是有个上限的,根据单个商品的价格,点击,流量,转化率,活动表现等,最终体现在销售数据上,而过于乐观的补单将造成大量的库存,库存的积压带来的不仅是仓储成本的增加,更为严重的是要考虑清仓问题,清库存的方式无非是加大营销力度,以更低的成本清理货物,这时候不仅资金的流转变慢,而且低价的清仓对于品牌而已也会拉低品牌溢价,而过于悲观的补单则会导致货不够卖而造成资源的浪费和利润的流失,这又是企业不愿意看到的,所以科学合理的补单预测尤为重要。
请建立相应的数学模型和算法,解决以下问题:
(1)请根据附件一中的销量数据建立一个销量预测的数学模型,要求至少能够比较精确地预测未来五天的货物销量大小;
(2)请根据附件二分析货物的上新量和延期比的分布情况,并给出分布范围及置信区间;
(3)请根据附件二中的数据进一步分析各个季度货物的上新量和延期比的分布情况,并给出分布范围及置信区间;
(4)请根据上述分析结果,制定合理的补单策略,写出具体操作流程。

2021年全国数学建模国赛b题题目一、题目概述及分析2021年全国数学建模国赛b题题目,是一道让学生发挥数学建模能力的典型题目。
题目要求学生运用概率统计、数学建模等知识,分析并解决实际问题,展现自己的数学建模能力和创新思维。
二、题目背景与问题本次题目涉及到城市停车场的管理问题,这是一个与现代城市生活息息相关的实际问题。
题目要求选手利用数学建模的方法,有效地优化车位分配方案,从而提高停车场的利用率和管理效率。
该题目涉及到的问题主要包括:如何确定最佳的车位分配方案?如何优化停车场的管理策略?如何提高车位的利用率?三、解题思路讨论在解题过程中,学生需要运用概率统计、数学建模等知识,结合实际情况对题目进行分析,并提出合理的解决方案。
他们需要考虑停车场的实际情况,包括停车需求的高峰期和低谷期、不同车型的停车需求、停车时间的分布规律等因素,进行合理的模型假设和参数设定,并运用数学工具进行建模和求解。
四、个人观点和理解对于这道题目,我认为学生不仅需要具备扎实的数学功底,还需要具备较强的实际问题分析能力和创新思维。
他们需要学会运用数学建模的方法,将抽象的数学理论与实际问题相结合,找到最佳的解决方案。
还需要具备团队合作和沟通能力,与队友共同分析问题、制定解决方案,以及有效地呈现研究成果。
五、总结与展望2021年全国数学建模国赛b题题目,对学生的综合能力提出了较高的要求。
通过解决这类实际问题,学生将深化对数学建模方法的理解,培养创新思维和实际问题解决能力。
希望学生能够通过这样的比赛,不断提升自己的数学建模能力,为未来的学术研究和工程技术实践打下坚实的基础。
这篇文章着重分析了2021年全国数学建模国赛b题题目的背景、问题、解题思路,结合个人观点和思考。
希望能够帮助您更深入地理解此题目,增加对数学建模能力和创新思维的认识。
题目中提到的城市停车场管理问题是一个与现代城市生活息息相关的实际问题。
随着城市化进程的不断加快,车辆数量的增加导致停车难成为了城市交通管理的一大难题。

第八届华中地区大学生数学建模邀请赛承诺书我们仔细阅读了第八届华中地区大学生数学建模邀请赛的竞赛细则。
我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们的参赛报名号为:参赛队员(签名) :队员1:队员2:队员3:武汉工业与应用数学学会第八届华中地区大学生数学建模邀请赛组委会第八届华中地区大学生数学建模邀请赛编号专用页选择的题号: B参赛的编号:(以下内容参赛队伍不需要填写)竞赛评阅编号:第八届华中地区大学生数学建模邀请赛题目:基因调控网络的重构及病毒感染的致病机制【摘要】一个基因的表达受其他基因的影响,而这个基因又影响其他基因的表达,这种相互影响相互制约的关系构成了复杂的基因调控网络。
基因调控网络的研究是从基因之间相互作用的角度揭示复杂的生命现象,是当前生物信息学研究的前沿。
疾病的发病因素和原理,对于医疗领域有着十分重要的作用。
这不仅仅能够让更多的患者免受病痛的困扰,还能促进人类医学史的进步。
所以根据基因数据谱来重构基因调控网络,以及某个疾病症状产生的原因的研究具有很大的意义。
本文对基因调控网络的重构以及导致严重临床症状的蛋白质进行了研究和推测。
由于所给的基因数据谱(附录一)十分庞大,所以首先要对数据进行降维处理。
本题基于时间序列给出了272组基因数据,为了减小噪声以及缺失值对实验精度的干扰,在实验前对四组噪声较大或有缺失的数据进行剔除。
具体的降维方式采用了多元统计法中的主成分分析和聚类分析:先对这一万多个数据做主成分分析,从这一万多个数据中,通过线性变化选出了1000个左右的重要变量来组成新的样本。

2007年全国研究生数学建模竞赛获奖名单
自11月30日全国研究生数学建模竞赛拟获奖名单公示以来我们收到部分参赛研究生对拟获奖名单中学校名称、研究生姓名的输入错误要求进行改正的邮件,现在已经全部纠正。
在公示期间我们还组织力量对部分获奖论文进行复查并要求所有拟获一等奖的研究生队对自己的论文进行复核,在复核中发现与论文不一致的地方要做出可以接受的解释。
现在这项工作也已经完成,我们据此对获奖情况做了极个别的调整。
现将2007年全国研究生数学建模竞赛获奖名单正式公布。
全国研究生数学建模竞赛评审委员会
2007.12.16
A题获奖名单
B题获奖名单
C题获奖名单
D题获奖名单。

第十四届华中杯数学建模b题代码摘要:一、华中杯数学建模简介1.比赛背景与目的2.比赛分类与难度二、第十四届华中杯数学建模B题解析1.题目概述与要求2.解题思路与方法3.代码实现与关键步骤三、代码展示与解读1.数据处理与分析2.模型构建与优化3.结果展示与分析四、建模心得与建议1.建模过程中的经验总结2.对于参赛者的建议和鼓励正文:一、华中杯数学建模简介华中杯数学建模竞赛是我国面向全国大学生的数学建模竞赛,旨在培养学生的创新能力和团队合作精神,提高学生运用数学方法和计算机技术解决实际问题的能力。
该比赛自举办以来,吸引了大量优秀的学生参加,已经成为国内最具影响力的数学建模竞赛之一。
比赛的题目分为A、B、C三组,其中A组题目难度较低,B组题目难度适中,C组题目难度较高。
参赛者可以根据自己的能力选择相应的题目进行解答。
二、第十四届华中杯数学建模B题解析1.题目概述与要求第十四届华中杯数学建模B题涉及到一个生产调度问题。
题目给出了一个工厂生产某种产品的生产流程,以及各种生产约束条件,要求参赛者建立数学模型,求解在满足所有约束条件的前提下,如何安排生产计划,使得产品的生产成本最低。
2.解题思路与方法对于这个问题,首先需要将题目中的实际问题抽象为一个数学模型。
考虑到生产调度问题是一个优化问题,我们可以将其建模为一个线性规划问题。
然后,利用线性规划的求解方法,求解出满足所有约束条件的最优生产计划。
3.代码实现与关键步骤我们可以使用Python编程语言,结合常用的线性规划求解库(如`scipy.optimize.linprog`),来实现上述模型。
以下是代码实现的关键步骤:- 定义目标函数和约束条件- 初始化线性规划对象- 设置线性规划的参数- 求解线性规划问题- 输出最优解三、代码展示与解读以下是一个简化的代码示例,展示了如何使用Python求解线性规划问题:```pythonfrom scipy.optimize import linprog# 定义目标函数和约束条件c = [1, 1, 1]A = [[1, 1, 0], [0, 1, 1], [0, 0, 1]]b = [10, 5, 15]bounds = [(0, None), (0, None), (0, None)]# 初始化线性规划对象lp = linprog.Linprog(c, A_ub=A, b_ub=b, bounds=bounds)# 设置线性规划的参数lp.method = "interior-point"# 求解线性规划问题res = lp.solve()# 输出最优解print("最优解:", res)```四、建模心得与建议参加数学建模竞赛,不仅需要具备扎实的数学基础和编程能力,还需要学会如何将实际问题抽象为数学模型,并找到合适的求解方法。
B题:智能并联电表的通信协议及其应用2020年电赛B题要求参赛者实现基于QT的智能并联电表通信协议,并应用该协议实现远程控制电表、数据查询等功能。
以下是详细的解释和讲解:一、技术要求1. 硬件要求:参赛者需要准备一只并联电表(可以是普通家庭电表或工业用表),一台可以连接到并联电表的智能手机或平板电脑,以及一个充电底座。
2. 软件要求:参赛者需要使用QT开发环境,并实现以下功能:(1)实现并联电表与智能手机或平板电脑的通信协议,包括数据传输协议、控制协议等;(2)实现远程控制电表的功能,包括远程查询电表数据、远程控制电表开关等;(3)实现数据查询功能,包括查询并联电表的用电量、查询并联电表的当前电量、查询并联电表的运行状态等。
3. 环境要求:参赛者需要在一个稳定的网络环境下进行测试,确保网络连接稳定、流畅。
二、解决方案并联电表的通信协议通常采用IEC 61850标准,该标准定义了电表与保护装置之间的通信协议。
参赛者需要遵循该标准来实现并联电表的通信协议。
1. 数据传输协议并联电表与智能手机或平板电脑之间的数据传输采用Modbus TCP/IP协议。
该协议是一种用于工业控制和自动化领域的通信协议,具有传输速度快、可靠性高、协议简单等特点。
2. 控制协议并联电表的控制协议采用通用的HTTP协议实现。
参赛者需要实现一个HTTP 服务器,用于接收并解析来自智能手机或平板电脑的请求,并发送命令给并联电表。
3. 远程控制电表的功能参赛者需要实现远程查询并联电表的用电量、当前电量、运行状态等功能。
这可以通过智能手机或平板电脑上的APP实现,APP向并联电表发送请求,并接收并联电表的响应。
4. 数据查询功能参赛者需要实现查询并联电表的用电量、当前电量、运行状态等功能。
这可以通过智能手机或平板电脑上的APP实现,APP向并联电表发送请求,并接收并联电表的响应。
三、实现方法1. 硬件连接参赛者需要将智能手机或平板电脑连接到并联电表的充电底座上,然后将并联电表连接到充电底座上。
(由由由由由由)第十届华为杯全国研究生数学建模竞参学校南京师范大学参参队号103190031.佟德宇队员姓名2.顾燕3.贾泽慧(由由由由由由)第十届华为杯全国研究生数学建模竞参题 目 功率放大器非线性特性及预失真建模摘 要针对问题一中求解输入输出信号之间的非线性功放特性函数问题, 采用了不同的多项式函数, 运用最小二乘法或正则化后的最小二乘法进行拟合求解. 并用参数NMSE 来评价所建模型的准确度. 结果发现在逼近函数选为函数基的情况下, 采用正则化后的最小二乘法得出的模型准确度最好, 其对应的参数NMSE=-68.6294.同时考虑计算量和模型准确度, 在由多项式变形函数逼近功放的模型基础上, 来进行预失真模型的建立. 根据题中给出的原则和约束, 可知预失真模型的表达式与功放模型的表达式是类似的, 从而可建立相应的预失真模型.:-11()()()K k k k z t h x t x t ==∑K=4时, 整体模型的放大倍数g=1.8693, 参数NMSE=-32.5819, EVM=2.3491; K=5时, g=1.8473, 参数NMSE=-37.1398, EVM=1.3900; K=7时, g=1.8326, 参数NMSE=-46.0624, EVM=0.4976.针对问题二, 直接将功放的输入输出与题目中所提的“和记忆多项式”模型进行拟合, 运用正则化后的最小二乘法进行求解, 这很好的保证了模型的可解性. 本题只考虑功放模型次数为5的情形. 当记忆深度为7时, 得NMSE=-45.8394; 当记忆深度为3时, 得NMSE=-44.5315. 预失真模型的建立与问题一类似, 文中以框图的方式建立了预失真处理的模型实现示意图, 并对次数为5、记忆深度为3的情形, 求解出整体模型的放大倍数g=9.4908, 参数NMSE=-37.8368, EVM=0.0128.针对问题三, 将所给的离散的、有限的输入输出数据作为随机过程的样本函数,通过其傅立叶变换得到功率谱参度函数. 文中分别给出了输入信号、无预失真补偿的功率放大器输出信号、采用预失真补偿的功率放大器输出信号的功率谱参度图形. 可解出它们的ACPR 分别为-155.6610、-74.3340、-104.4904, 最后对结果进行分析评价, 得出采用预失真补偿的功率放大器的输出信号效果比无预失真补偿的效果好. 关键字:最小二乘法、Tikhonov正则化、Fourier变换一、问题重述信号的功率放大是电子通信系统的关键功能之一, 其实现模块称为功率放大器( PA, Power Amplifier), 简称功放. 功放的输出信号相对于输入信号可能产生非线性变形, 这将带来无益的干扰信号, 影响信信息的正确传递和接收, 此现象称为非线性失真.功放非线性属于有源电子器件的固有特性, 研究其机理并采取措施改善, 具有重要意义. 目前已经提出了各种技术来克服功放的非线性失真, 其中预失真技术是被研究的较多的一项技术, 其最新的研究成果已经被运用于实际的产品中, 但在新算法、实现复杂度、计算速度、效果精度等方面仍有相当的研究价值.预失真的基本原理是:在功放前设置一个预失真处理模块, 这两个模块的合成总效果使整体输入-输出特性线性化, 输出功率得到充分利用.文中给出了NMSE 、EVM 等参数评价所建模型其准确度, 以及ACPR 表示信道的带外失真的参数.根据数据文件中给出的某功放无记忆效应、有记忆效应的复输入输出测试数据:(1)我们建立此功放的非线性数学模型()G ⋅, 并用NMSE 来评价所建模型的准确度.(2)根据线性化原则以及“输出幅度限制”和“功率最大化”约束, 计算线性化后最大可能的幅度放大倍数, 建立预失真模型. 并运用评价指标参数NMSE/EVM 评价预失真补偿的计算结果.(3)应用问题二中所给的数据, 计算功放预失真补偿前后的功率谱参度(输入信号、无预失真补偿的功率放大器输出信号、采用预失真补偿的功率放大器输出信号), 并用图形的方式表示了这三类信号的功率谱参度. 最后用相邻信道功率比ACPR 对结果进行分析.二、模型假设1、假设题中所给的功放输入输出数据采样误差为0.2、假设题中所给的功放输入输出数据具有代表性、一般性.3、假设存在这样的预失真处理器, 能够做到将输入数据变为模型求解所得的预失真 处理输出结果.三、基本知识§3.1 最小二乘方法最小二乘方法[][]12产生于数据拟合问题, 它是一种基于观测数据与模型数据之间的差的平方和最小来估计数学模型中参数的方法. 输入数据t 与输出数据y 之间大致服从如下函数关系(,)y x t φ=,式中n x R ∈为待定参数. 为估计参数x 的值, 要先经过多次试验取得观测数据1122(,),(,),,(,)m m t y t y t y , 然后基于模型输出值和实际观测值的误差平方和21((,))m i ii y x t φ=−∑最小来求参数x 的值, 这就是最小二乘问题. 一般地, m n .引入函数()(,), 1,2,,i i i r x y x t i m φ=−= ,并记12()((), (), , ())m r x r x r x r x = ,则最小二乘问题即为n min ()()T x Rr x r x ∈. 如果最小二乘问题中的模型函数估计准确, 那么最小二乘问题的最优值是很靠近零的. 因此()r x 常称作残量函数.对于线性最小二乘问题, 残量函数可以表示为()r x b Ax =−,从而线性最小二乘问题可以表示为2min n x R b Ax ∈−. (3.1.1) 若A 是列满秩的, 且考虑到二次凸函数的稳定点即为最小值点, 可以直接得到x 的求解公式, 即()1T T x A A A b −=. (3.1.2) 而对于复数域上的线性最小二乘问题n 2min x C b Ax ∈−, 也可以直接得到x 的求解公式, 即为()-1T x A A A b =, (3.1.3) 其中, T A 表示A 的共轭转置.§3.2 Tikhonov 正则化在使用最小二乘方法进行参数估计的时候, 由于A 不一定是列满秩的, 故T A A 不一定是可逆的, 此时就不能够用上面所推得的公式进行直接的求解了. 为了克服这个困难,考虑Tikhonov 正则化[]3方法, 即给目标函数加上一个正则项(即一个邻近项)2k k x x λ−.此时, 最小二乘问题转化为n 221min +k k k x C x b Ax x x λ+∈=−−.其中k x 是第k 步迭代得到的解, k λ可以选为一个常数或一个单调下降趋于0的数列. 迭代的终止准则为1k k x x ε+−≤,其中ε是一个给定的误差上界.考虑到二次凸函数的稳定点即为最小值点, 这时问题22min n k k x C b Ax x x λ∈−+− 是可以直接求解的, 给出x 的求解公式为()()1T k k k x A A I A b x λλ−=++.显然, 此时即使A 非列满秩, 问题也是可以求解的.四、问题分析问题一题中已给出了某功放无记忆效应的复输入输出测试数据, 现需要建立此功放的非线性特性数学模型, 拟合出功放的特性函数()G⋅. 根据函数逼近理论, 功放的特性函数可以用多项式来表示, 也可以用空间中的一由正交函数基来表示. 然后采用最小二乘法或正则化后的最小二乘法, 将这些情况都进行求解, 得出功放的特性函数()G⋅. 并在最后用参数NMSE(归一化均方误差)来评价所建模型的准确度.接着, 在前面所建模型的基础上, 选择一个计算量适当, 且准确度较好的()G⋅的一个拟合模型. 然后根据线性化原则以及“输出幅度限制”和“功率最大化”约束, 建立预失真模型, 使得整体模型线性化后放大倍数尽可能的大. 通过对优化模型的分析可知, 对预失真特性函数()F⋅的求解可以转化为对1Gg−⎛⎞⎜⎟⎝⎠的求解, 且预失真模型的表达式与功放模型的表达式是类似的. 在求解1Gg−⎛⎞⎜⎟⎝⎠时, 可以对求解所用模型的次数进行不同的选取,分别得出整体模型的g和NMSE、EVM的值, 用来评价预失真补偿的结果.问题二题中已给出了某功放有记忆效应的复输入输出测试数据, 现需要建立此功放的非线性特性数学模型, 拟合出功放的特性函数()G⋅. 根据函数逼近理论, 本文直接将功放的输入输出与题目中所提的“和记忆多项式”模型来进行拟合, 在使用最小二乘方法求解时, 我们对目标函数加了一个正则项, 以保证求解的可实现性.预失真处理器模型的建立与问题一类似, 且给出了以框图的方式建立的预失真处理的模型实现示意图.问题三问题二中所给的输入输出数据是离散的、有限的, 在这种情况下计算功率谱参度的函数可以用自相关函数法或对随机过程{}()x t的样本函数作傅立叶变换得到, 文中采取第二种方法来求解.五、模型建立与求解§5.1 问题一的模型与求解§5.1.1 无记忆功放的特性函数()G⋅模型建立文章中已给出某功放无记忆效应的复输入输出测试数据, 这些数据是对功放输入)(tx/输出)(t z进行离散采样后得到的, 它们的值为分别为()x n/()z n(采样过程符合Nyquist采样定理要求).对于问题一, 根据文章中所给的某功放无记忆效应的复输入输出测试数据, 首先需要建立此功放的非线性特性数学模型, 拟合出功放的特性函数()G⋅. 根据函数逼近理论,可以采用1、多项式的形式2、多项式的变形的形式3、空间中的一由正交函数基的线性由合来表示4、正则化下, 空间中的一由正交函数基的线性由合来表示下面将这些情况都进行建模, 来拟合功放的特性函数()G ⋅, 并在最后进行比较选择优者.所求得的模型的数值计算结果业界常用NMSE 、EVM 等参数评价其准确度, NMSE 的具体定义如下. 采用归一化均方误差 (Normalized Mean Square Error, NMSE) 来表征计算精度, 其表达式为211021ˆ|()()|NMSE 10log |()|N n N n z n z n z n ==−=∑∑ . (5.1.1) 如果用z 表示实际信号值, ˆz表示通过模型计算的信号值, NMSE 就反映了模型与实际模块的接近程度. 显然NMSE 的值越小, 模型的数值计算结果就越准确.误差矢量幅度 (Error Vector Magnitude, EVM)定义为误差矢量信号平均功率的均方根和参照信号平均功率的均方根的比值, 以百分数形式表示. 如果用X 表示理想的信号输出值, e 表示理想输出与整体模型输出信号的误差, 可用EVM 衡量整体模型对信号的幅度失真程度:EVM 100%= . (5.1.2)模型一 多项式的形式首先根据函数逼近的Weierstrass 定理, 对解析函数采用简单的多项式来表示, 可表示为∑==Kk k k t x h t z 1)()(. (5.1.3)因为此时是要将观测数据与形式已经固定的函数(5.1.3)进行拟合, 而目的是求解该函数的各项系数, 所以该问题其实就是最简单的线性最小二乘问题.模型建立()n 211min ()N K k k h C n k z n h x n ∈==−∑∑, (5.1.4) 其中, ()x n 和()z n 为文章中所给的输入和输出测试数据, 这些数据是对功放输入()x t 、输出()z t 进行离散采样后得到的(采样过程符合Nyquist 采样定理要求),N 为功放输入输出数据的总个数.将问题(5.1.4)与( 3.1.1)进行对应, 由( 3.1.3)可以直接得到系数的表达式为()-1T h A A A z = 其中232323 (1) (1) (1) (1) (2) (2) (2) (2) () () () ()K K K x x x x x x x x A x N x N x N x N ⎡⎤…⎢⎥…⎢⎥=⎢⎥⎢⎥⎢…⎥⎣⎦, ()12,,,TK h h h h =…, ()()()()1,2,,Tz z z z N =….结果当3K =时, (见附录2.1.1)该表达式中的系数为123 2.908532278399690.060653883258900.213775998314930.43417026083854 0.198185637666730.27826757408010h ih i h i=−=−=+.根据模型一以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE 13.4414169873254 3k =−=.当5k =时, (见附录2.1.2 )表达式中的系数为12345 2.908037719327826 - 0.063527494375989i0.343519806629302 - 0.388942747664566i0.541211413428411 - 0.144422960285135i -0.399744749427209 - 0.558463329513045i-0.271952185146638 + 0.1205591h h h h h =====40060622i根据模型一以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE -21.544782705381238 5k ==.模型二 多项式的变形同时我们也考虑了多项式变形[]4的情形来对其进行表示, 其表示式为-11()()()K k k k z t h x t x t ==∑. (5.1.5)因为此时是要将观测数据与形式已经固定的函数(5.1.5)进行拟合, 而目的是求解该函数的各项系数, 所以该问题其实就是最简单的线性最小二乘问题.模型建立()n 2-111min ()()N K k k h C n k z n h x n x n ∈==−∑∑ (5.1.6)其中N 为所给功放输入输出数据的总个数, K 为表达式的次数. 将问题(5.1.6)与(3.1.1)进行对应, 由(3.1.3)可以直接得到系数的表达式为()-1T h A A A z = 其中212121(1) (1)(1) (1)(1) (1)(1)(2) (2)(2) (2)(2) (2)(2) () ()() ()() ()()K K K x x x x x x x x x x x x x x A x N x N x N x N x N x N x N −−−⎡⎤…⎢⎥⎢⎥…=⎢⎥⎢⎥⎢⎥…⎢⎥⎣⎦,()123,,,,TK h h h h h =…, ()()()()()1,2,3,,Tz z z z z N =…. 分别考虑当3k =, 5k =时, 该表达式的具体形式(即确定表达式的系数).结果当3k =时, (见附录2.1.3 )表达式中的系数为123 3.051183005392040.00000000000001 0.006071903393980.00000000000005 1.170159412626470.00000000000004h ih i h i=−=+=−−.根据上面所建立的模型以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE 29.7446547565428 3k =−=.当5k =时, (见附录2.1.4 )表达式中的系数为12345 2.967983597251020.00000000000080 0.309931644197600.00000000000873 0.153664636905190.00000000002804 3.424500445954250.00000000003458 2.208212395486470.00000000001446h ih ih i h ih i=−=+=−−=−+=−.根据上面所建立的模型以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE 45.379717608769994 5k =−=模型三 空间中的一由正交函数基的线性由合最后根据函数逼近理论, 可采用空间中的一由正交函数基[]4的线性由合来表示该特性函数(参考文献3中的方法), 其表达式为()z t h =Ψ, (5.1.7)其中正交矩阵12[() () ()]k x x x ψψψΨ= ,11()!()(1)(1)!(1)!()!kl l k k l k l x x x l l k l ψ−+=+=−−+−∑. 因为此时是要将观测数据与形式已经固定的函数(5.1.7)进行拟合, 而目的是求解该函数的各项系数, 所以该问题其实就是最简单的线性最小二乘问题.模型建立 n 2min h C z h ∈−Ψ (5.1.8) 其中()123,,,,TK h h h h h =…, ()()()()()1,2,3,,T z z z z z N =…, ()()()12[() ()()]k x n x n x n ψψψΨ= ,()()()11()!()(1)(1)!(1)!()!k l l kk l k l x n x n x n l l k l ψ−+=+=−−+−∑, N 为功放的输入输出数据的总个数. 将问题(5.1.8)与(3.1.1)进行对应, 由(3.1.3)可以直接得到系数的表达式为 ()-1T T h z =ΨΨΨ. 由于计算量较大, 我们选取7=k 来进行拟合, 得出表达式中的系数.结果(见附录2.1.5)当7=k 时, 表达式中的系数为12345 3.287412936081622-7.322701472967097-015-0.091488124421954-2.16460963736731-015-0.066219774105875 5.035305939565804-0160.038056322596937 2.726632938529483-0160.01014165858755-1.2h e ih e ih e ih e i h ===+=+=6758894247527231-016-0.005283612035716-2.653720342429833-016-0.001265433154276-1.923256069376669-016e ih e ih e i==.根据上面所建立的模型以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE -60.5675309366592 7k ==模型四 模型三正则化模型建立对于模型三, 由于所给的数据较多, 很难避免本文3.2节中所提到的T ΨΨ奇异的情况, 故对(5.1.8)再进行一个Tikhonov 正则化. 即对(5.1.8)加一个正则项2k k h h λ−.问题转变为()1221min K M k k k h C h z h h h λ⋅×+∈=−Ψ+−. (5.1.9) 其中k h 是第k 步迭代得到的解(计算机运行求解时是要给其赋一个初始值的), 而k λ可以选为一个常数或一个单调下降趋于0的数列. 而迭代的终止准则为1k k h h ε+−≤,其中ε是一个给定的误差上界.考虑到二次凸函数的稳定点即为最小值点, 问题(5.1.9)是可以直接求解的, 得到h 的求解公式为()()()1T Tk k k h I z n h λλ−=ΨΨ+Ψ+. (5.1.10)此处, 我们仍选取7=k 来进行拟合, 其中一些参数选取为800111, 1, 0.8, 10k k h i λλλε−+=+===.则可得出表达式(5.1.7)中的系数.结果(见附录2.1.6)123456 3.2873994140515280.000008426827987-0.0914922453118830.000002568107767-0.066218825186175-0.000000591359660.038056824724197-0.0000003129219510.010141412616440.000000153287355-0h ih ih ih i h ih =+=+===+=7.0052839775157310.000000227764411-0.0012655686759970.000000084456122ih i+=+根据上面所建立的模型以及(5.1.1)式, 可以求出NMSE 的值如下:()NMSE -68.6293523598994 7k ==模型一~模型四的总评价对四种模型下参数NMSE 的大小进行比较发现, 当选用一由正交函数基, 并运用正则化后的最小二乘方法来对功放特性函数进行拟合时(即模型四), NMSE 的值是最小的. 也就是说2121ˆ|()()||()|Nn Nn z n zn z n ==−∑∑在模型四下是最靠近0的, 故模型四是逼近效果最好的.但模型四的计算复杂度是很大, 由所得的NMSE 参数可发现模型二的计算精度也是不错的, 但其计算的复杂度比模型四要小很多, 故选择模型二来求解功放特性函数. 且在下面的无记忆功放模型的预失真处理建模中, 功放特性函数是由模型二得出的.§5.1.2四种模型的输入输出幅度比较图与评价下面将实际的与拟合的复输入输出幅度值进行作图, 以便更直观的看出模型的逼近效果.图5.1 模型一k=3实际与拟合功放输入/输出幅度散点图 图5.1模型一k=5实际与拟合功放输入/输出幅度散点图图5.3模型二k=3实际与拟合功放输入/输出幅度散点图 图5.4 模型二k=5实际与拟合功放输入/输出幅度散点图图5.5 模型三实际与拟合的功放输入/输出幅度散点图图5.6模型四实际与拟合的功放输入/输出幅度散点图根据观察比较发现, 当用正交的函数基或对其实行一个正则化(即模型三和模型四), 来对功放特性函数进行拟合的时候, 拟合情形的输入输出幅度散点图与实际的输入输出幅度散点图的逼近效果是最佳的.k=时, 其散点图的逼近效果也是很好的.同时可观察到但模型二中的次数5§5.1.3 预失真处理模型建立选定-11():()()()Kk k k G z n b x n x n =⋅=∑的阶数5K =, 通过上面的算法可以得到当F 取不同阶数的情况下, g, NMSE, EVM 的结果及图像表5.1 F 取不同阶数情况下g, NMSE, EVM 的结果F 的阶数Kg NMSE EVM 4 1.86932497973065-32.5819077399852 2.34911681195961% 5 1.84730161996524-37.1398119663279 1.38998272147897% 7 1.83264461869445-46.06241433950440.497598752653887%由表5.1的结果可以看出当F 的阶数越高时, 得到的g 的值越小(说明线性化后的幅度放大倍数越小), NMSE 、EVM 的值越小(说明模型的计算精度越高, 整体模型对信号的幅度失真程度越小).图5.7理想信号与所建模型得到的输出信号对比(K=4) 图5.8理想信号与所建模型得到的输出信号对比(K=5)图5.9理想信号与所建模型得到的输出信号对比(K=7)根据观察发现, 当K 的取值越大时, 所建模型的输入输出幅度散点图与理想的输入输出幅度散点图的逼近效果越好.§5.2 问题二的模型与求解§5.2.1 有记忆功放的特性函数()G ⋅模型建立对于问题二, 根据文章中所给的某功放有记忆效应的复输入输出测试数据, 首先需要建立此功放的非线性特性数学模型, 拟合出功放的特性函数()G ⋅. 此时功放不仅与此时刻输入有关, 而且与此前某一时间段的输入有关, 其可以由为101111022220212()()()(1)()()(1)()K Mk km M k m M z n h x n m h x n h x n h x n M h x n h x n h x n M ===−=+−++−++−++−+∑∑ 01 ()(1)()K K K K K KM h x n h x n h x n M ++−++− , 0,1,2,,n N = .式中M 表示记忆深度, km h 为系数. 具有记忆效应的功放模型也可以用更一般的V olterra级数[][]56表示, 由于V olterra 级数太复杂, 简化模型有Wiener 、Hammersteint 等[][]47. 由于常用复值输入-输出信号, 上式也可表示为便于计算的“和记忆多项式”模型-110()(-)|(-)|K Mk km k m z n h x n m x n m ===∑∑ 0,1,2,,n N = (5.2.1)模型建立本文采用“和记忆多项式”模型(5.2.1)式来进行拟合. 我们用最小二乘法来求解, 由于本问中所给的输入输出的数据个数非常大, 故现在选取其中的一部分来进行拟合, 求得功放过程的模型. 我们选取输入输出数据的次数n 为1M +的倍数的数据来进行拟合, 最小二乘公式即为()()12-1(1)|10min (-)|(-)|K M K Mk km h CM nk m n Nz n h x n m x n m ××∈+==≤−∑∑∑ (5.2.2) 其中N 是指所有的功放的输入数据总个数, K 表示所选模型的最高次数, M 表示记忆深度(本文在求解模型时是事先给定的), ()x n 是第n 个复输入值, ()z n 是第n 个复输出值, km h 为系数, ()102001222212,,,,,,,, ,,,,TK K M M KM h h h h h h h h h h =…………….由于所给的数据较多, 即便是选取了部分数据进行拟合,但仍很难避免3.2节中所提到的A A 奇异的情况, 故对(5.2.2)再进行一个Tikhonov 正则化. 即对(5.2.2)加一个正则项2k k h h λ−,则问题转变为()()122-11(1)|10min (-)|(-)|K M K Mk k km k k h CM nk m n Nh z n h x n m x n m h h λ××+∈+==≤=−+−∑∑∑ (5.2.3) 其中k h 是第k 步迭代得到的解, 而k λ可以选为一个常数或一个单调下降趋于0的数列. 而迭代的终止准则为1k k h h ε+−≤,其中ε是一个给定的误差上界.当给定一个记忆深度M 后, 我们可以将问题(5.2.3)化成如下形式的问题, 即()22min nk k h Cz n Ah h h λ∈−+− (5.2.4) 其中A 是一个()()()()/11N M K M +×⋅+的复矩阵, 即1111(1) (1)(1) (1)(1) (1) (1)(1) (22) (22)(22) (22)(22) (2) (1)(1) K K K K x M x M x M x M x M x x x x M x M x M x M x M x M x x A −−−−+++++++++++=……………… ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦而()102001121112,,,,,,,, ,,,,TK K M M KM h h h h h h h h h h =…………….考虑到二次凸函数的稳定点即为最小值点, 问题(5.2.4)是可以直接求解的, h 的求解公式为()()()1Tk kk h A A I A z n h λλ−=++. (5.2.5)本题中已给出有记忆功放输入输出数据的总个数为73920N =, 并分别取 87, 5, 10M K ε−===和 83, 5, 10M K ε−===这两种情况. 这样就可以根据(5.2.5)求得h .结果(见附录2.2.1、2.2.2)当7,5M K ==时, 由于系数共有40个, 即h 是一个401×的大向量, 故将该结果放到附录中. 再根据上面所建立的模型及(5.1.1)式, 求出该模型的NMSE 值如下:NMSE -45.839408840847 7,5M K ===.当3,5M K ==时, 由于系数共有20个, 即h 是一个201×的大向量, 故将该结果放到附录中. 再根据上面所建立的模型及(5.1.1)式, 求出该模型的NMSE 值如下:NMSE 44.5315001961471 3,5M K =−==.§5.2.2有记忆功放模型的输入输出幅度图下面将实际与拟合的复输入输出幅度进行作图, 以便更直观的看出模型的逼近效果.图5.10 M=7实际与拟合功放输入/输出幅度散点图 图5.11 M=3实际与拟合功放输入/输出幅度散点图总评价根据观察比较发现, 尽管在用“和记忆多项式”模型进行拟合时, 我们只选取了一部分输入输出测量数据进行模型的建构. 但通过对上面两图的观察, 当对所有的输入测量数据进行作图时, 可发现拟合得到的输入输出幅度散点图与实际的输入输出幅度散点图的逼近效果还是很好的.§5.2.3 预失真处理模型建立上面已求得功放特性函数()G ⋅的模型, 采用“和记忆多项式”模型-110()(-)|(-)|K Mk kmk m z n hx n m x n m ===∑∑建立的功放模型. 下面建模的总体原则是使预失真和功放的联合模型呈线性后误差最小. 在此模型中, 有两个约束需要考虑:(1)输出幅度限制:即模型中的预失真处理的输出幅度不大于给出的功放输入幅度最大值.(2)功率最大化:即模型的建立必需考虑尽可能使功放的信号平均输出功率最大, 因此预失真处理后的输出幅度需尽可能提高.0≤下面我们将给出解决该优化问题的算法: 给定判断容限step1选定-110(): ()(-)|(-)|KMk km k m G z n h x n m x n m ==⋅=∑∑的阶数为5K =. 因数据量很大且算法较复杂, 本文对F 进行多次计算, 发现当阶数为5K =的时候与更高阶相比, 效果就已经很好了, 故下面只给出阶数为5K =时g, NMSE, EVM 的结果.本文取定记忆深度为 3M =, 现根据算法5.2可求得9.490829228013789g =,由于系数一共有20个, 即h 是一个201×的向量, 故将此结果放到附录中.根据上面所建模型以及(5.1.1)、(5.1.2)式, 可求出该模型的NMSE 、EVM 值如下:.NMSE -37.836849855461956EVM 0.012827957346961== 3,5M K ==由所得数据, 可以发现在该算法下, 得到的g 的值比较大(说明线性化后的幅度放大倍数大), NMSE 、EVM 的值较小(说明模型的计算精度越高, 整体模型对信号的幅度失真程度越小).图5.13 M=3, K=5实际与拟合功放输入/输出幅度散点图观察图5.13发现, 该情况下所建模型的输入输出幅度散点图与理想的输入输出幅度散点图逼近效果还是较好的. 故该模型是可行的.§5.3 问题三的模型与求解 §5.3.1背景知识功率谱的概念是针对功率有限信号的, 所表现的是单位频带内信号功率随频率的变化情况. 保留了频谱的幅度信息, 但是丢掉了相位信息, 所以频谱不同的信号其功率谱是可能相同的. 功率谱是随机过程的统计平均概念, 平稳随机过程的功率谱是一个确定函数;而频谱是随机过程样本的Fourier 变换, 对于一个随机过程而言, 频谱也是一个“随机过程”(随机的频域序列).功率谱参度(PSD), 它定义了信号或者时间序列的功率如何随频率分布. 这里功率可能是实际物理上的功率, 或者更经常便于表示抽象的信号, 被定义为信号数值的平方, 也就是当信号的负载为1欧姆(ohm)时的实际功率.由于平均值不为零的信号不是平方可积的, 所以在这种情况下就没有傅立叶变换. 维纳-辛钦定理(Wiener-Khinchin theorem)提供了一个简单的替换方法. 如果信号可以看作是平稳随机过程, 那么功率谱参度就是信号自相关函数的傅立叶变换. 信号的功率谱参度当且仅当信号是广义的平稳过程的时候才存在; 如果信号不是平稳过程, 那么自相关函数一定是两个变量的函数, 这样就不存在功率谱参度, 但是可以使用类似的技术估计时变谱参度. 随机信号是时域无限信号, 不具备可积分条件, 因此不能直接进行傅氏变换. 一般用具有统计特性的功率谱来作为谱分析的依据. 功率谱与自相关函数是一个傅氏变换对.一般的功率谱参度都是针对平稳随机过程的, 由于平稳随机过程的样本函数一般不是绝对可积的, 因此不能直接对它进行傅立叶分析. 可以有三种办法来重新定义谱参度,来克服上述困难.1. 用相关函数的傅立叶变换来定义谱参度;2. 用随机过程的有限时间傅立叶变换来定义谱参度;3. 用平稳随机过程的谱分解来定义谱参度.§5.3.2 模型建立计算功率谱参度函数通常有两种方法[]8. 一种叫做标准的自相关函数法, 其表达式为:(1)0()4()cos 2d x x G f R f τπττ∞=∫ (5.3.1)其中()x R τ表示某个各态历经的随机过程{}()x t 的自相关函数;另一种叫做直接法, 即是直接对随机过程{}()x t 的样本函数作傅立叶变换得到功率谱参度函数, 其表达式为:2(2)202()lim ()d T j ftx T G f x t e t Tπ−→∞=∫ (5.3.2)在计算机上计算功率谱参度函数时, 要求输入的数据必须是离散数值, 所以要对连续观测的数据记录必须做离散化处理. 这叫做数据采样. 离散化的数据值叫做采样数据. 实际计算时, 要求参加运算的采样数据的个数是有限的(即是说, 在有限的时间区段0-T 上进行计算). 在记录是离散的、有限的情况下, 计算功率谱参度函数的公式可以分别近似地表示为:1(1)01()22cos 2cos 2M x r M r G f t R R fr t R fM t ππ−=⎡⎤=Δ+Δ+Δ⎢⎥⎣⎦∑ (5.3.3)和21(2)202()N j fi t x i i G f t x e N t π−−Δ==ΔΔ∑ (5.3.4)这里, 将(5.3.4)式整理为()()21P f X f N=(5.3.5) 其中()X f 是()x n 的傅里叶变换, 在计算过程中可以直接调用FFT 函数.另外由题意可设出, per F 表示每个点上的频率, 其表达式为sper F F N=. M 表示每个信道所含的点的个数, 其表达式为0perF M F =.其中0F 表示每个传输信道上的频率. 故传输信道就只包含M 个点, 相邻信道也只包含M 个点.由于非线性效应产生的新频率分量由对邻道信号有一定的影响, 现用相邻信道功率比(Adjacent Channel Power Ratio, ACPR)表示信道的带外失真的参数, 衡量由于非线性效应所产生的新频率分量对邻道信号的影响程度. 其定义为。
2023华中杯b题范文摘要:1.介绍华中杯B题背景及重要性2.分析题目要求及考查点3.解题思路与步骤4.具体实例解析5.总结与展望正文:华中杯B题是每年备受关注的赛事之一,其题目设置具有现实意义和实用性,旨在考查参赛者的综合素质和实际操作能力。
本文将从题目背景、考查点、解题思路、具体实例解析以及总结与展望五个方面,全面剖析华中杯B 题,以期为广大考生提供有益的参考。
首先,华中杯B题的背景和重要性不容忽视。
随着科技的飞速发展,相关领域的知识和技能也日新月异。
华中杯B题以实际问题为切入点,紧紧围绕当前社会发展需求,旨在激发参赛者创新精神和实践能力,为我国科技事业培养更多优秀人才。
其次,分析题目要求及考查点。
华中杯B题通常涉及多个知识点,既有理论性,又有实践性。
题目要求参赛者具备扎实的基本功、创新思维、团队协作和沟通能力。
考查点包括:对相关领域知识的掌握程度、分析问题的能力、解决问题的方法、时间管理和组织协调能力等。
接下来,详细介绍解题思路与步骤。
参赛者应首先充分了解题目背景,明确考查要求。
在此基础上,通过分析题目所给信息,提炼关键点,找到解决问题的切入点。
具体步骤如下:1.仔细阅读题目,梳理信息,确定解题方向。
2.归纳总结相关知识点,为解题奠定基础。
3.针对题目要求,逐步推导,确立解题思路。
4.验证解题方案,确保答案正确性。
5.对照评分标准,优化解题过程和结果。
在此过程中,实例解析尤为重要。
以某届华中杯B题为例,题目要求解决一个复杂的实际问题。
解题团队首先从理论知识入手,分析问题背景和现状,然后通过实际操作,不断尝试和优化,最终成功找到解决方案。
以下是具体解题过程:1.确定题目背景和考查要求。
2.梳理相关知识点,包括理论知识和技术方法。
3.分析题目给出的条件,找到关键信息。
4.运用所学知识,逐步推导解题思路。
5.结合实际操作,验证解题方案。
6.对照评分标准,完善解题过程和结果。
最后,总结与展望。
华中杯B题旨在培养参赛者的综合素质和实践能力,通过现实问题的解决,提升参赛选手的竞争力。
第十三届“华中杯”大学生数学建模挑战赛题目A题马赛克瓷砖选色问题马赛克瓷砖是一种尺寸较小(常见规格为边长不超过5cm)的正方形瓷砖,便于在非平整的表面铺设,并且容易拼接组合出各种文字或图案。
但是受工艺和成本的限制,瓷砖的颜色只能是有限的几种。
用户在拼接图案时,首先要根据原图中的颜色,选出颜色相近的瓷砖,才能进行拼接。
某马赛克瓷砖生产厂只能生产22种颜色(见附件1)的马赛克瓷砖。
该厂要开发一个软件,能够根据原始图片的颜色,自动找出颜色最接近的瓷砖,以减少客户人工选色的工作量。
该厂希望你们团队提供确定原始颜色与瓷砖颜色对应关系的算法。
假设原始图像为24 位真彩色格式,即R、G、B 三个颜色分量均为8 位,共有2 8 ×2 8 ×2 8 = 16777216种颜色,对于任何一种指定的颜色,算法输出颜色最相近的瓷砖的颜色编号。
请完成以下任务。
1)附件2是图像1 中的216种颜色,附件3是图像2中的200 种颜色,请找出与每种颜色最接近的瓷砖颜色,将选出的瓷砖颜色的编号按照附件4 的要求输出至结果文件。
2)如果该厂技术革新,计划研发新颜色的瓷砖。
那么,不考虑研发难度,只考虑到拼接图像的表现力,应该优先增加哪些颜色的瓷砖?当同时增加1种颜色、同时增加 2 种颜色、……、同时增加10 种颜色时,分别给出对应颜色的RGB编码值。
3)如果研发一种新颜色瓷砖的成本是相同的,与颜色本身无关,那么,综合考虑成本和表现效果,你们建议新增哪几种颜色,说明理由并给出对应的RGB编码值。
附数据说明附件1:现有瓷砖颜色编号RGB 编号RGB 编号RGB 编号RGB 编号RGB1 0,0,0 6 27,115,186 11 92,59,144 16 17,168,226 21 249,225,2142 255,255,255 7 53,118,84 12 11,222,222 17 255,110,0 22 186,149,1953 255,0,0 8 244,181,208 13 228,0,130 18 201,202,2024 246,232,9 9 255,145,0 14 255,218,32 19 255,249,1775 72,176,64 10 177,125,85 15 118,238,0 20 179,226,242附件2:图像1颜色列表附件3:图像2颜色列表附件4:选色结果文件格式1. 附件2的选色结果保存在result1.txt 中。