JPEG压缩编码标准
- 格式:doc
- 大小:229.00 KB
- 文档页数:21

jpeg编码标准JPEG,全称为Joint Photographic Experts Group,是一种广泛应用于图像压缩的标准。
其名称包含三个主要部分:“联合”,“图像”,“专家组”。
专家组是一个处理特殊问题的专家团队,而JPEG 就是这些专家的研究成果被采纳并应用于图像处理的结果。
JPEG编码是一种有损压缩方式,它通过去除图像中的冗余数据来减小文件大小,同时尽可能地保留图像的重要信息,使得图像在查看或打印时仍然具有良好的质量。
这种压缩方式被广泛用于数字图像和视频的传输,包括网络传输和存储等。
二、JPEG编码标准的主要组成部分1. 离散余弦变换(DCT):JPEG使用了一种特殊的变换方法,称为离散余弦变换。
这种方法将图像从空间域转换到频率域,从而实现了数据的压缩。
通过离散余弦变换,我们可以将高频率部分(也就是图像中的噪声和细节)移除,只保留低频率部分(也就是图像的主要信息)。
2. 量化:在离散余弦变换之后,我们需要对变换后的系数进行量化。
量化过程是将变换后的系数映射到一个有限的离散值集合中。
这个过程有助于进一步减小文件大小,同时尽可能保留图像的质量。
3. 熵编码:熵编码是一种用于减少文件大小的额外技术。
JPEG 使用了一种称为游程编码的技术来进行熵编码,它能够进一步减少文件中的冗余数据。
4. 霍夫曼编码:在JPEG标准中,霍夫曼编码被用于进一步优化文件大小。
它是一种无损的压缩技术,通过创建短的、重复的符号的平均值来减小文件大小。
三、JPEG编码的应用场景JPEG编码广泛应用于数字图像和视频处理领域,如网络传输、存储、打印和显示等。
它尤其适用于需要大量图像或视频数据的场景,如社交媒体、在线购物、视频会议等。
四、JPEG编码的优缺点优点:1. 高压缩率:JPEG编码能够有效地减小图像和视频的文件大小,而不会显著影响图像的质量。
这使得它成为了一种非常实用的技术,尤其是在需要大量数据传输和存储的场景中。



中国图像网 / 数字图像处理入门—图象的压缩编码,JPEG 压缩编码标准 在介绍图象的压缩编码之前,先考虑一个问题:为什么要压缩?其实这个问题不用我回答,你也能想得到。
因为图象信息的数据量实在是太惊人了。
举一个例子就明白了,一张 A4(210mm*297mm) 幅面的照片,若 用中等分辨率(300dpi)的扫描仪按真彩扫描,其数据量为多少?让我们来计算一下:共有(300*210/25.4)* (300*297/25.4)个像素,每个像素占 3 个字节,其数据量为 26M 字节,其数据量之大可见一斑了。
如今在 Internet 上,传统基于字符界面的应用逐渐被能够浏览图象信息的 WWW(World Wide Web)方式所取 代。
WWW 尽管漂亮,但是也带来了一个问题:图象信息的数据量太大了,本来就已经非常紧张的网络带 宽变得更加不堪重负,使得 World Wide Web 变成了 World Wide Wait。
总之,大数据量的图象信息会给存储器的存储容量,通信干线信道的带宽,以及计算机的处理速度增加极 大的压力。
单纯*增加存储器容量, 提高信道带宽以及计算机的处理速度等方法来解决这个问题是不现实的, 这时就要考虑压缩。
压缩的理论基础是信息论。
从信息论的角度来看,压缩就是去掉信息中的冗余,即保 留不确定的信息,去掉确定的信息(可推知的) ,也就是用一种更接近信息本质的描述来代替原有冗余的描 述。
这个本质的东西就是信息量(即不确定因素) 。
压缩可分为两大类,第一类压缩过程是可逆的,也就是说,从压缩后的图象能够完全恢复出原来的图象, 信息没有任何丢失,称为无损压缩;第二类压缩过程是不可逆的,无法完全恢复出原图象,信息有一定的 丢失,成为有损压缩。
选择哪一类压缩,要折中考虑,尽管我们希望能够无损压缩,但是通常有损压缩的 压缩比(即原图象占的字节数与压缩后图象占的字节数之比,压缩比越大,说明压缩效率越高)比无损压 缩的高。


JPEG压缩编码标准是国际标准化组织(ISO)和CCITT联合制定的静态图像的压缩编码标准。
它主要采用预测编码、离散余弦变换以及熵编码的联合编码方式,以去除冗余的图像和彩色数据,属于有损压缩格式。
JPEG压缩编码标准是面向连续色调静止图像的压缩编码标准,具有较高的压缩比,是目前静态图像中压缩比最高的。
它能够将图像压缩在很小的储存空间,一定程度上会造成图像数据的损伤。
JPEG压缩编码标准有多种类型,包括标准JPEG格式、渐进式JPEG格式和JPEG2000格式。
其中,标准JPEG格式在网页下载时只能由上而下依序显示图像,直到图像资料全部下载完毕,才能看到图像全貌;渐进式JPEG格式在网页下载时,先呈现出图像的粗略外观后,再慢慢地呈现出完整的内容;JPEG2000格式是新一代的影像压缩法,压缩品质更高,并可改善在无线传输时,常因信号不稳造成马赛克现象及位置错乱的情况,改善传输的品质。
总之,JPEG压缩编码标准是一种广泛应用于图像处理领域的压缩编码标准,具有较高的压缩比和多种类型,能够满足不同应用场景的需求。
余信息。
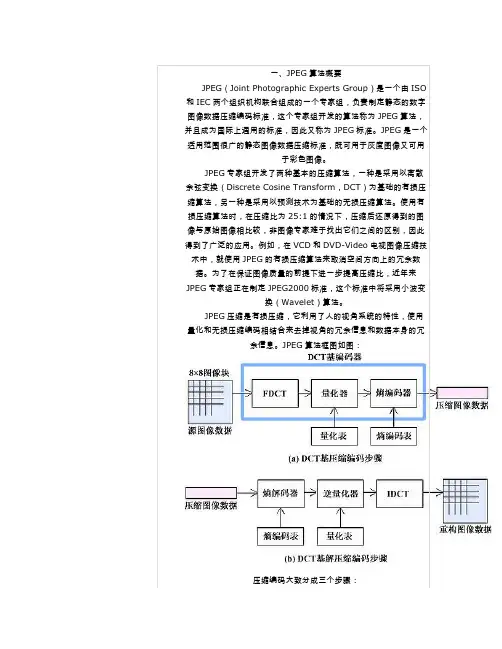
JPEG算法框图如图:1、使用正向离散余弦变换(Forward Discrete Cosine Transform,FDCT)把空间域表示的图变换成频率域表示的图。
2、使用加权函数对DCT系数进行量化,这个加权函数对于人的视觉系统是最佳的。
3、使用霍夫曼可变字长编码器对量化系数进行编码。
译码或者叫做解压缩的过程与压缩编码过程正好相反。
JPEG算法与彩色空间无关,因此“RGB到YUV变换”和“YUV 到RGB变换”不包含在JPEG算法中。
JPEG算法处理的彩色图像是单独的彩色分量图像,因此它可以压缩来自不同彩色空间的数据,如RGB, YCbCr和CMYK。
二、JPEG算法的主要计算步骤JPEG压缩编码算法的主要计算步骤如下:(1)正向离散余弦变换(FDCT)。
(2)量化(Quantization)。
(3)Z字形编码(Zigzag Scan)。
(4)使用差分脉冲编码调制(Differential Pulse CodeModulation,DPCM)对直流系数(DC)进行编码。
(5)使用行程长度编码(Run-Length Encoding,RLE)对交流系数(AC)进行编码。
(6)熵编码(Entropy Eoding)。
1、正向离散余弦变换下面对正向离散余弦变换(FDCT)变换作几点说明。
(1)对每个单独的彩色图像分量,把整个分量图像分成若干个8×8的图像块,如图所示,并作为两维离散余弦变换DCT的输入。
通过DCT变换,把能量集中在少数几个系数上。
(2)DCT变换使用下式计算:它的逆变换使用下式计算:上面两式中,C(u),C(v) = (2)-1/2,当u, v = 0;C(u),C(v) = 1,其他。
f(i, j)经DCT变换之后,F(0,0)是直流系数,其他为交流系数。
(3)在计算两维的DCT变换时,可使用下面的计算式把两维的DCT变换变成一维的DCT变换:2、量化量化是对经过FDCT变换后的频率系数进行量化。

JPEG是图像压缩编码标准JPEG(Joint Photographic Experts Group)是一种常见的图像压缩编码标准,它是一种无损压缩技术,可以有效地减小图像文件的大小,同时保持图像的高质量。
JPEG压缩技术广泛应用于数字摄影、网页设计、打印和传真等领域,成为了图像处理中不可或缺的一部分。
JPEG压缩编码标准的原理是基于人眼对图像细节的感知特性,通过去除图像中的冗余信息和不可见细节,从而实现图像的压缩。
在JPEG压缩中,图像被分割成8x8像素的块,然后对每个块进行离散余弦变换(DCT),将图像从空间域转换到频域。
接着,对DCT系数进行量化和编码,最后使用熵编码对图像进行压缩。
这样的压缩方式可以显著减小图像文件的大小,同时保持图像的视觉质量。
JPEG压缩标准的优点之一是可以根据需要选择不同的压缩比,从而在图像质量和文件大小之间取得平衡。
在数字摄影中,用户可以根据拍摄场景和要求选择不同的压缩比,以满足对图像质量和文件大小的需求。
此外,JPEG格式的图像可以在不同的设备和平台上进行广泛的应用和共享,具有很好的兼容性。
然而,JPEG压缩也存在一些缺点。
由于JPEG是一种有损压缩技术,因此在高压缩比下会出现明显的失真和伪影。
特别是在连续的编辑和保存过程中,图像的质量会逐渐下降,出现“JPEG失真”。
因此,在图像处理中需要注意选择合适的压缩比,避免过度压缩导致图像质量下降。
另外,JPEG格式不支持透明度和动画等高级特性,对于一些特殊的图像处理需求可能不够灵活。
在这种情况下,可以考虑使用其他图像格式,如PNG和GIF,来满足特定的需求。
总的来说,JPEG作为一种图像压缩编码标准,具有广泛的应用和重要的意义。
它在数字摄影、网页设计、打印和传真等领域发挥着重要作用,为图像处理和传输提供了有效的解决方案。
然而,在使用JPEG格式进行图像处理时,需要注意选择合适的压缩比,避免过度压缩导致图像质量下降。
同时,也需要根据具体的需求考虑使用其他图像格式来满足特定的需求。

jpeg编码重要参数
JPEG编码是一种常用的图像压缩标准,它通过一些关键参数来控制压缩质量和文件大小。
以下是几个重要的JPEG编码参数:
1. 质量因子(Quality Factor):质量因子是一个介于1到100之间的整数,它控制了压缩的程度。
较高的质量因子值表示较少的压缩,从而产生更高质量的图像,但文件大小也更大。
相反,较低的质量因子值会导致更多的压缩,从而减小文件大小,但图像质量会下降。
2. 色彩空间(Color Space):JPEG编码支持多种色彩空间,包括RGB、CMYK 和YCbCr等。
不同的色彩空间适用于不同的应用场景,例如RGB适用于显示器显示,CMYK适用于印刷品。
3. 分辨率(Resolution):JPEG编码支持不同的分辨率设置,通常以dpi(每英寸点数)表示。
较高的分辨率会产生更高质量的图像,但文件大小也更大。
4. 压缩级别(Compression Level):JPEG编码支持不同的压缩级别,从1到9,其中1级压缩最不失真,但文件大小也最大,而9级压缩文件大小最小,但失真程度也最高。
5. 插值算法(Interpolation Algorithm):JPEG编码使用不同的插值算法来重建图像。
常见的插值算法包括最近邻插值、双线性插值和双三次插值等。
不同的插值算法对图像质量的影响不同。
这些参数可以根据需要进行调整,以实现不同的压缩质量和文件大小。
在选择JPEG编码参数时,应根据具体的应用场景和需求进行权衡。


JPEG文件编/解码详解(1)2.初步了解图像数据流的结构1)理论说明分析图像数据流的结构,笔者准备以一个从宏观到微观的顺序为读者详细剖析,即:数据流→最小编码单元→数据单元与颜色分量。
a)在图片像素数据流中,信息可以被分为一段接一段的最小编码单元(Minimum Coded Unit,MCU)数据流。
所谓MCU,是图像中一个正方矩阵像素的数据。
矩阵的大小是这样确定的:查阅标记SOF0,可以得到图像不同颜色分量的采样因子,即Y、Cr、Cb三个分量各自的水平采样因子和垂直采样因子。
大多图片的采样因子为4:1:1或1:1:1。
其中,4:1:1即(2*2):(1*1):(1*1));1:1:1即(1*1):(1*1):(1*1)。
记三个分量中水平采样因子最大值为Hmax,垂直采样因子最大值为Vmax,那么单个MCU矩阵的宽就是Hmax*8像素,高就是Vmax*8像素。
如果,整幅图像的宽度和高度不是MCU宽度和高度的整数倍,那么编码时会用某些数值填充进去,保证解码过程中MCU的完整性(解码完成后,可直接忽视图像宽度和高度外的数据)。
在数据流中,MCU的排列方法是从左到右,从上到下。
b)每个MCU又分为若干个数据单元。
数据单元的大小必定为8*8,所以每个MCU的数据单元个数为Hmax*Vmax。
另外JPEG的压缩方法与BMP文件有所不同,它不是把每个像素的颜色分量连续存储在一起的,而是把图片分成Y,Cr,Cb三张子图,然后分别压缩。
而三个颜色分量的采样密度(即采样因子)可能一样(例如1:1:1)也可能不一样(例如4:1:1)。
每个MCU内部,数据的顺序是Y、Cr、Cb。
如果一个颜色分量有多个数据单元,则顺序是从左到右,从上到下。
2)举例说明下面通过一幅32*35的图像,对上面两个问题列出两种采样因子的具体说明。
图1 整张完整的图像(4:1:1)图2 将图像的MCU1放大图1及图3中灰色部分为实际图像大小(32px*35px);粗虚线表示各个MCU的分界;细虚线表示MCU内部数据单元的分界。
JPEG是图像压缩编码标准JPEG是一种图像压缩编码标准,它是一种广泛应用的图像压缩格式,可以在保持图像质量的同时减小图像文件的大小,使得图像在存储和传输过程中更加高效。
JPEG的全称是Joint Photographic Experts Group,它是一种有损压缩的图像格式,也是目前应用最为广泛的图像格式之一。
JPEG图像压缩编码标准的出现,使得图像在存储和传输过程中占用更小的空间,这对于网络传输和存储设备的容量都是非常有利的。
JPEG图像压缩编码标准的核心思想是通过舍弃一些人眼不易察觉的细节来减小图像的大小,从而达到压缩图像的目的。
在保证图像质量的前提下,JPEG可以将图像文件的大小减小到原来的很小一部分,这对于存储和传输来说都是非常有益的。
在JPEG图像压缩编码标准中,压缩的过程分为两个阶段,分别是亮度和色度的压缩。
在亮度的压缩中,采用的是离散余弦变换(DCT)的方法,它将图像分成8x8的小块,然后对每个小块进行DCT变换,得到频域的系数。
而在色度的压缩中,采用的是色度子采样的方法,将色度分量的分辨率降低,从而减小了色度分量的数据量。
这两种压缩方法结合在一起,就实现了对图像的高效压缩。
值得一提的是,JPEG是一种有损压缩的格式,这意味着在压缩过程中会丢失一些图像的细节信息,从而导致图像质量的损失。
因此,在进行JPEG压缩时,需要根据实际需求来选择合适的压缩比例,以在图像质量和文件大小之间取得平衡。
通常情况下,对于要求较高图像质量的场景,可以选择较小的压缩比例,而对于一些网络传输和存储空间有限的场景,可以选择较大的压缩比例。
除了JPEG之外,还有一些其他的图像压缩编码标准,例如PNG、GIF等,它们各有特点,适用于不同的场景。
在实际应用中,需要根据实际需求来选择合适的图像格式和压缩方法,以达到最佳的效果。
总的来说,JPEG作为一种图像压缩编码标准,具有高效压缩、广泛应用的特点,可以在保证图像质量的前提下减小图像文件的大小,使得图像在存储和传输过程中更加高效。
JPEG图像压缩算法及其实现⼀、JEPG压缩算法(标准)(⼀)JPEG压缩标准JPEG(Joint Photographic Experts Group)是⼀个由ISO/IEC JTC1/SC2/WG8和CCITT VIII/NIC于1986年底联合组成的⼀个专家组,负责制定静态的数字图像数据压缩编码标准。
迄今为⽌,该组织已经指定了3个静⽌图像编码标准,分别为JPEG、JPEG-LS和JPEG2000。
这个专家组于1991年前后指定完毕第⼀个静⽌图像压缩标准JPEG标准,并且成为国际上通⽤的标准。
JPEG标准是⼀个适⽤范围很⼴的静态图像数据压缩标准,既可⽤于灰度图像⼜可⽤于彩⾊图像。
JPEG专家组开发了两种基本的静⽌图像压缩算法,⼀种是采⽤以离散余弦变换(Discrete Cosine Transform, DCT)为基础的有损压缩算法,另⼀种是采⽤以预测技术为基础的⽆损压缩算法。
使⽤⽆损压缩算法时,其压缩⽐⽐较低,但可保证图像不失真。
使⽤有损压缩算法时,其算法实现较为复杂,但其压缩⽐⼤,按25:1压缩后还原得到的图像与原始图像相⽐较,⾮图像专家难于找出它们之间的区别,因此得到了⼴泛的应⽤。
JPEG有4种⼯作模式,分别为顺序编码,渐近编码,⽆失真编码和分层编码,他们有各⾃的应⽤场合,其中基于顺序编码⼯作模式的JPEG压缩系统也称为基本系统,该系统采⽤单遍扫描完成⼀个图像分量的编码,扫描次序从左到右、从上到下,基本系统要求图像像素的各个⾊彩分量都是8bit,并可通过量化线性地改变DCT系统的量化结果来调整图像质量和压缩⽐。
下⾯介绍图像压缩采⽤基于DCT的顺序模式有损压缩算法,该算法下的JPEG压缩为基本系统。
(⼆)JPEG压缩基本系统编码器JPEG压缩是有损压缩,它利⽤了⼈的视觉系统的特性,将量化和⽆损压缩编码相结合来去掉视觉的冗余信息和数据本⾝的冗余信息。
基于基本系统的JPEG压缩编码器框图如图1所⽰,该编码器是对单个图像分量的处理,对于多个分量的图像,则⾸先应将图像多分量按照⼀定顺序和⽐例组成若⼲个最⼩压缩单元(MCU),然后同样按该编码器对每个MCU各个分量进⾏独⽴编码处理,最终图像压缩数据将由多个MCU压缩数据组成。
JPEG图像压缩算法流程详解(转)JPEG是Joint Photographic Exports Group的英⽂缩写,中⽂称之为联合图像专家⼩组。
该⼩组⾪属于ISO国际标准化组织,主要负责定制静态数字图像的编码⽅法,即所谓的JPEG算法。
JPEG专家组开发了两种基本的压缩算法、两种熵编码⽅法、四种编码模式。
如下所⽰:压缩算法:(1)有损的离散余弦变换DCT(Discrete Cosine Transform)(2)⽆损的预测压缩技术;熵编码⽅法:(1)Huffman编码;(2)算术编码;编码模式:(1)基于DCT的顺序模式:编码、解码通过⼀次扫描完成;(2)基于DCT的渐进模式:编码、解码需要多次扫描完成,扫描效果由粗到精,逐级递增;(3)⽆损模式:基于DPCM,保证解码后完全精确恢复到原图像采样值;(4)层次模式:图像在多个空间分辨率中进⾏编码,可以根据需要只对低分辨率数据做解码,放弃⾼分辨率信息;在实际应⽤中,JPEG图像编码算法使⽤的⼤多是离散余弦变换、Huffman编码、顺序编码模式。
这样的⽅式,被⼈们称为JPEG的基本系统。
这⾥介绍的JPEG编码算法的流程,也是针对基本系统⽽⾔。
基本系统的JPEG压缩编码算法⼀共分为11个步骤:颜⾊模式转换、采样、分块、离散余弦变换(DCT)、Zigzag 扫描排序、量化、DC系数的差分脉冲调制编码、DC系数的中间格式计算、AC系数的游程长度编码、AC系数的中间格式计算、熵编码。
下⾯,将⼀⼀介绍这11个步骤的详细原理和计算过程。
(1)颜⾊模式转换JPEG采⽤的是YCrCb颜⾊空间,⽽BMP采⽤的是RGB颜⾊空间,要想对BMP图⽚进⾏压缩,⾸先需要进⾏颜⾊空间的转换。
YCrCb 颜⾊空间中,Y代表亮度,Cr,Cb则代表⾊度和饱和度(也有⼈将Cb,Cr两者统称为⾊度),三者通常以Y,U,V来表⽰,即⽤U代表Cb,⽤V代表Cr。
RGB和YCrCb之间的转换关系如下所⽰:Y = 0.299R+0.587G+0.114BCb = -0.1687R-0.3313G+0.5B+128Cr = 0.5R=0.418G-0.0813B+128⼀般来说,C 值 (包括 Cb Cr) 应该是⼀个有符号的数字, 但这⾥通过加上128,使其变为8位的⽆符号整数,从⽽⽅便数据的存储和计算。
JPEG压缩编码标准JPEG压缩编码标准JPEG是联合图象专家组(Joint Picture Expert Group)的英⽂缩写,是国际标准化组织(ISO)和CCITT联合制定的静态图象的压缩编码标准。
和相同图象质量的其它常⽤⽂件格式(如GIF,TIFF,PCX)相⽐,JPEG是⽬前静态图象中压缩⽐最⾼的。
我们给出具体的数据来对⽐⼀下。
例图采⽤Windows95⽬录下的,原图⼤⼩为640*480,256⾊。
⽤⼯具SEA将其分别转成24位⾊BMP、24位⾊JPEG、GIF(只能转成256⾊)压缩格式、24位⾊TIFF压缩格式、24位⾊TGA压缩格式。
得到的⽂件⼤⼩(以字节为单位)分别为:921,654,17,707,177,152,923,044,768,136。
可见JPEG⽐其它⼏种压缩⽐要⾼得多,⽽图象质量都差不多(JPEG处理的颜⾊只有真彩和灰度图)。
正是由于JPEG的⾼压缩⽐,使得它⼴泛地应⽤于多媒体和⽹络程序中,例如HTML语法中选⽤的图象格式之⼀就是JPEG(另⼀种是GIF)。
这是显然的,因为⽹络的带宽⾮常宝贵,选⽤⼀种⾼压缩⽐的⽂件格式是⼗分必要的。
JPEG有⼏种模式,其中最常⽤的是基于DCT变换的顺序型模式,⼜称为基线系统(Baseline),以下将针对这种格式进⾏讨论。
的压缩原理JPEG的压缩原理其实上⾯介绍的那些原理的综合,博采众家之长,这也正是JPEG有⾼压缩⽐的原因。
其编码器的流程为:图 JPEG编码器流程解码器基本上为上述过程的逆过程:图解码器流程8×8的图象经过DCT变换后,其低频分量都集中在左上⾓,⾼频分量分布在右下⾓(DCT变换实际上是空间域的低通滤波器)。
由于该低频分量包含了图象的主要信息(如亮度),⽽⾼频与之相⽐,就不那么重要了,所以我们可以忽略⾼频分量,从⽽达到压缩的⽬的。
如何将⾼频分量去掉,这就要⽤到量化,它是产⽣信息损失的根源。
这⾥的量化操作,就是将某⼀个值除以量化表中对应的值。
第9章图象的压缩编码,JPEG压缩编码标准在介绍图象的压缩编码之前,先考虑一个问题:为什么要压缩?其实这个问题不用我回答,你也能想得到。
因为图象信息的数据量实在是太惊人了。
举一个例子就明白:一张A4(210mm×297mm) 幅面的照片,若用中等分辨率(300dpi)的扫描仪按真彩色扫描,其数据量为多少?让我们来计算一下:共有(300×210/25.4) ×(300×297/25.4)个象素,每个象素占3个字节,其数据量为26M字节,其数据量之大可见一斑了。
如今在Internet上,传统基于字符界面的应用逐渐被能够浏览图象信息的WWW(World Wide Web)方式所取代。
WWW尽管漂亮,但是也带来了一个问题:图象信息的数据量太大了,本来就已经非常紧张的网络带宽变得更加不堪重负,使得World Wide Web变成了World Wide Wait。
总之,大数据量的图象信息会给存储器的存储容量,通信干线信道的带宽,以及计算机的处理速度增加极大的压力。
单纯靠增加存储器容量,提高信道带宽以及计算机的处理速度等方法来解决这个问题是不现实的,这时就要考虑压缩。
压缩的理论基础是信息论。
从信息论的角度来看,压缩就是去掉信息中的冗余,即保留不确定的信息,去掉确定的信息(可推知的),也就是用一种更接近信息本质的描述来代替原有冗余的描述。
这个本质的东西就是信息量(即不确定因素)。
压缩可分为两大类:第一类压缩过程是可逆的,也就是说,从压缩后的图象能够完全恢复出原来的图象,信息没有任何丢失,称为无损压缩;第二类压缩过程是不可逆的,无法完全恢复出原图象,信息有一定的丢失,称为有损压缩。
选择哪一类压缩,要折衷考虑,尽管我们希望能够无损压缩,但是通常有损压缩的压缩比(即原图象占的字节数与压缩后图象占的字节数之比,压缩比越大,说明压缩效率越高)比无损压缩的高。
图象压缩一般通过改变图象的表示方式来达到,因此压缩和编码是分不开的。
图象压缩的主要应用是图象信息的传输和存储,可广泛地应用于广播电视、电视会议、计算机通讯、传真、多媒体系统、医学图象、卫星图象等领域。
压缩编码的方法有很多,主要分成以下四大类:(1)象素编码;(2)预测编码;(3)变换编码;(4)其它方法。
所谓象素编码是指,编码时对每个象素单独处理,不考虑象素之间的相关性。
在象素编码中常用的几种方法有:(1)脉冲编码调制(Pulse Code Modulation,简称PCM);(2)熵编码(Entropy Coding);(3)行程编码(Run Length Coding);(4)位平面编码(Bit Plane Coding)。
其中我们要介绍的是熵编码中的哈夫曼(Huffman)编码和行程编码(以读取.PCX文件为例)。
所谓预测编码是指,去除相邻象素之间的相关性和冗余性,只对新的信息进行编码。
举个简单的例子,因为象素的灰度是连续的,所以在一片区域中,相邻象素之间灰度值的差别可能很小。
如果我们只记录第一个象素的灰度,其它象素的灰度都用它与前一个象素灰度之差来表示,就能起到压缩的目的。
如248,2,1,0,1,3,实际上这6个象素的灰度是248,250,251,251,252,255。
表示250需要8个比特,而表示2只需要两个比特,这样就实现了压缩。
常用的预测编码有Δ调制(Delta Modulation,简称DM);微分预测编码(Differential Pulse Code Modulation,DPCM),具体的细节在此就不详述了。
所谓变换编码是指,将给定的图象变换到另一个数据域(如频域)上,使得大量的信息能用较少的数据来表示,从而达到压缩的目的。
变换编码有很多,如(1)离散傅立叶变换(Discrete Fourier Transform,简称DFT);(2)离散余弦变换(Discrete Cosine Transform,简称DCT);(3)离散哈达玛变换(Discrete Hadamard Transform,简称DHT)。
其它的编码方法也有很多,如混合编码(Hybird Coding)、矢量量化(Vector Quantize,VQ) 、LZW算法。
在这里,我们只介绍LZW算法的大体思想。
值得注意的是,近些年来出现了很多新的压缩编码方法,如使用人工神经元网络(Artificial Neural Network,简称ANN)的压缩编码算法、分形(Fractl)、小波(Wavelet) 、基于对象(Object Based)的压缩编码算法、基于模型(Model –Based)的压缩编码算法(应用在MPEG4及未来的视频压缩编码标准中)。
这些都超出了本书的范围。
本章的最后,我们将以JPEG压缩编码标准为例,看看上面的几种编码方法在实际的压缩编码中是怎样应用的。
9.1 哈夫曼编码哈夫曼(Huffman)编码是一种常用的压缩编码方法,是Huffman于1952年为压缩文本文件建立的。
它的基本原理是频繁使用的数据用较短的代码代替,较少使用的数据用较长的代码代替,每个数据的代码各不相同。
这些代码都是二进制码,且码的长度是可变的。
举个例子:假设一个文件中出现了8种符号S0,S1,S2,S3,S4,S5,S6,S7,那么每种符号要编码,至少需要3比特。
假设编码成000,001,010,011,100,101,110,111(称做码字)。
那么符号序列S0S1S7S0S1S6S2S2S3S4S5S0S0S1编码后变成000 001 111 000 001 110 010 010 011 100 101 000 000 001,共用了42比特。
我们发现S0,S1,S2这三个符号出现的频率比较大,其它符号出现的频率比较小,如果我们采用一种编码方案使得S0,S1,S2的码字短,其它符号的码字长,这样就能够减少占用的比特数。
例如,我们采用这样的编码方案:S0到S7的码字分别01,11,101,0000,0001,0010,0011,100,那么上述符号序列变成011110001110011101101000000010010010111,共用了39比特,尽管有些码字如S3,S4,S5,S6变长了(由3位变成4位),但使用频繁的几个码字如S0,S1变短了,所以实现了压缩。
上述的编码是如何得到的呢?随意乱写是不行的。
编码必须保证不能出现一个码字和另一个的前几位相同的情况,比如说,如果S0的码字为01,S2的码字为011,那么当序列中出现011时,你不知道是S0的码字后面跟了个1,还是完整的一个S2的码字。
我们给出的编码能够保证这一点。
下面给出具体的Huffman编码算法。
(1) 首先统计出每个符号出现的频率,上例S0到S7的出现频率分别为4/14,3/14,2/14,1/14,1/14,1/14,1/14,1/14。
(2) 从左到右把上述频率按从小到大的顺序排列。
(3) 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,这两个叶子节点不再参与比较,新的根节点参与比较。
(4) 重复(3),直到最后得到和为1的根节点。
(5) 将形成的二叉树的左节点标0,右节点标1。
把从最上面的根节点到最下面的叶子节点途中遇到的0,1序列串起来,就得到了各个符号的编码。
上面的例子用Huffman编码的过程如图9.1所示,其中圆圈中的数字是新节点产生的顺序。
可见,我们上面给出的编码就是这么得到的。
图9.1 Huffman编码的示意图产生Huffman编码需要对原始数据扫描两遍。
第一遍扫描要精确地统计出原始数据中,每个值出现的频率,第二遍是建立Huffman树并进行编码。
由于需要建立二叉树并遍历二叉树生成编码,因此数据压缩和还原速度都较慢,但简单有效,因而得到广泛的应用。
源程序就不给出了,有兴趣的读者可以自己实现。
9.2 行程编码行程编码(Run Length Coding)的原理也很简单:将一行中颜色值相同的相邻象素用一个计数值和该颜色值来代替。
例如aaabccccccddeee可以表示为3a1b6c2d3e。
如果一幅图象是由很多块颜色相同的大面积区域组成,那么采用行程编码的压缩效率是惊人的。
然而,该算法也导致了一个致命弱点,如果图象中每两个相邻点的颜色都不同,用这种算法不但不能压缩,反而数据量增加一倍。
所以现在单纯采用行程编码的压缩算法用得并不多,PCX文件算是其中的一种。
PCX文件最早是PC Paintbrush软件所采用的一种文件格式,由于压缩比不高,现在用的并不是很多了。
它也是由头信息、调色板、实际的图象数据三个部分组成。
其中头信息的结构为:typedef struct{char manufacturer;char version;char encoding;char bits_per_pixel;WORD xmin,ymin;WORD xmax,ymax;WORD hres;WORD vres;char palette[48];char reserved;char colour_planes;WORD bytes_per_line;WORD palette_type;char filler[58];} PCXHEAD;其中值得注意的是以下几个数据:manufacturer为PCX文件的标识,必须为0x0a;xmin为最小的x 坐标,xmax最大的x坐标,所以图象的宽度为xmax-xmin+1,同样图象的高度为ymax-yin+1;bytes_per_line 为每个编码行所占的字节数,下面将详细介绍。
PCX的调色板在文件的最后。
以256色PCX文件为例,倒数第769个字节为颜色数的标识,256时该字节必须为12,剩下的768(256×3)为调色板的RGB值。
为了叙述方便,我们针对256色PCX文件,介绍一下它的解码过程。
编码是解码的逆过程,有兴趣的读者可以试着自己来完成。
解码是以行为单位的,该行所占的字节数由bytes_per_line给定。
为此,我们开一个大小为bytes_per_line 的解码缓冲区。
一开始,将缓冲区的所有内容清零。
从文件中读出一个字节C,若C>0xc0,说明是行程(RunLength)信息,即C的低6位表示后面连续的字节个数(所以最多63个连续颜色相同的象素,若还有颜色相同的象素,将在下一个行程处理),文件的下一个字节就是实际的图象数据(即该颜色在调色板中的索引值)。
若C<0xc0,则表示C是实际的图象数据。
如此反复,直到这bytes_per_line个字节处理完,这一行的解码完成。
PCX就是有若干个这样的解码行组成。
下面是实现256色PCX文件解码的源程序,其中第二个函数对一行进行解码,应该把阅读的重点放在这个函数上。