ARM Cortex-M3 学习笔记(1)
- 格式:docx
- 大小:9.10 KB
- 文档页数:1

Cortex-M3寄存器等基础知识1.寄存器 CM3拥有R0~R15通⽤寄存器和⼀些特殊功能寄存器 R0~R12这些通⽤寄存器,复位初始值都是不可预料的2.CM3有R0到R15的通⽤寄存器组注:绝⼤部分的16位thumb只能访问R0到R7,⽽32位thumb-2可以访问全部寄存器3.特殊功能寄存器3.1程序状态寄存器组(应⽤程序PSR+中断号PSR+执⾏PSR)3.2中断屏蔽寄存器组:⽤于控制异常的除能和使能3.3控制寄存器:⽤于定义特权级别和当前使⽤哪个堆栈指针4.操作模式和特权级别:两种操作模式(处理器模式):Handler模式和线程模式(⽤于区分异常服务例程的代码和普通程序的代码)两种特权等级:特权级和⽤户级(是指在硬件层⾯上对存储器访问权限的设置)注:CM3在运⾏主程序(即线程模式)可以使⽤特权级别和⽤户级别;但是异常服务例程(即handler模式)只能使⽤特权级别。
当处于线程+⽤户模式时⼀些访问权限将被禁⽌将代码区分成⽤户级和特权级,有利于程序架构的稳定,如某⼀个⽤户代码出问题,不会使其成为害群之狗,因为⽤户级别的代码是禁⽌对⼀些要害寄存器操作的。
5.异常处理5.1CONTROL[0]=0;5.2CONTROL[0]=1;CONTROL[0]只有在特权级别下可以访问,若在⽤户级别想访问先通过"系统服务呼叫指令(SVC)"来触发SVC异常,然后在该异常的服务例程中可以修改CONTROL[0]。
6.下⾯是各操作模式的转换7.异常和中断可以有11个系统异常和最多240个外部中断(IRQ),具体芯⽚使⽤了多少要看芯⽚制造⼚商。
作为中断功能的强化,NVIC 还有⼀条NMI输⼊信号线,具体做什么由芯⽚制造商决定,NMI(not masked interrupted)8.向量表:当⼀个异常被CM3内核接受。
对应的异常Handler就会执⾏,向量表⽤来决定Handler的⼊⼝地址。



ARMCortex-M3处理器学习总结ARMCortex-M3处理器学习总结在学习了《嵌入式Linux系统》这门课后,本人简单学习了ARMCortex-M3处理器,有了一点粗略的认识,下面将从性能,特性,用途这三方面来介绍ARMCortex-M3处理器。
1性能参数Cortex‐M3是一个32位处理器内核。
内部的数据路径是32位的,寄存器是32位的,存储器接口也是32位的。
CM3采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行不悖。
这样一来数据访问不再占用指令总线,从而提升了性能。
为实现这个特性,CM3内部含有好几条总线接口,每条都为自己的应用场合优化过,并且它们可以并行工作。
但是另一方面,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统)。
比较复杂的应用可能需要更多的存储系统功能,为此CM3提供一个可选的MPU,而且在需要的情况下也可以使用外部的cache。
另外在CM3中,Both小端模式和大端模式都是支持的。
CM3内部还附赠了好多调试组件,用于在硬件水平上支持调试操作,如指令断点,数据观察点等。
另外,为支持更高级的调试,还有其它可选组件,包括指令跟踪和多种类型的调试接口。
2特性ARMCortex-M3的特性总结为以下几方面:●功耗低。
延长了电池的寿命——这简直就是便携式设备的命门(如无线网络应用)。
●实时性好。
采用了很前卫甚至革命性的设计理念,使它能极速地响应中断,而且响应中断所需的周期数是确定的。
●代码密度得到很大改善。
一方面力挺大型应用程序,另一方面为低成本设计而省吃俭用。
●使用更方便。
现在从8位/16位处理器转到32位处理器之风刮得越来越猛,更简单的编程模型和更透彻的调试系统,为与时俱进的人们大大减负。
●低成本的整体解决方案。
让32位系统比和8位/16位的还便宜,低端的Cortex‐M3单片机甚至还卖不到1美元。
●遍地开花的优秀开发工具。
免费的,便宜的,全能的,要什么有什么。

读后感:ARM Cortex-M3处理器简介ARM, 读后感, 处理器, 简介首先谈谈我对这个系列先入为主的感觉。
Cortex-M3是ARM7的升级版本。
个人认为:ARM7本身并不是完全针对MCU来设计的,但是众多芯片厂家以ARM7为内核做了很多32位MCU芯片。
例如Atmel和NXP的ARM7系列。
Cortex-M3是真正针对MCU应用来设计的,这一点在功能取舍和性能偏向上得到反映。
那么与ARM7相比较,Cortex-M3有哪些区别和特点呢?加速设计:哈佛结构替代ARM7的冯.诺伊曼结构。
哈佛结构就是指令和数据总线分开。
这样取指令和取数据可以同时进行。
很适合将指令放在片内FLASH,将数据放在片内SRAM的MCU结构。
在ARM7的3级流水线之上增加了分支预测。
减少了程序跳转时流水线被打断的时间消耗。
ALU支持硬件乘法和硬件除法。
数学计算能力增强。
单周期32位乘法。
Bit-Band技术:简单地说,就是增强了位操作性能。
SRAM中有专门的Bit-Band区域,可以按位进行寻址(使用别名地址)。
而且,这样的位操作是原子操作。
这在实现互斥功能时有用。
一些DSP运算专用的位操作指令,比如bit翻转。
节省存储器使用量的技术:位寻址是可以节省bool型变量的存储器使用的。
ARM7的short变量要16位对齐、int变量要32位对齐。
Cortex-M3不用对齐。
这个问题,一般看法是,对齐可以简化设计。
个人认为这个好处有限。
指令集的优化。
现在叫Thumb-2了。
ARM7有两种指令集:ARM和Thumb,两种指令模式可以切换。
个人感觉比较怪。
处理器模式的简化:我们知道ARM7有很多种处理器模式,目的主要应该是支持复杂的操作系统。
Cortex-M3的处理器模式现在有两个:Thread模式和handler模式。
Thread模式相当于用户模式了,有两种访问方式:有特权方式和无特权方式。
结构区别:ARM7是个纯内核,中断控制器和存储器接口是芯片厂家扩展的。
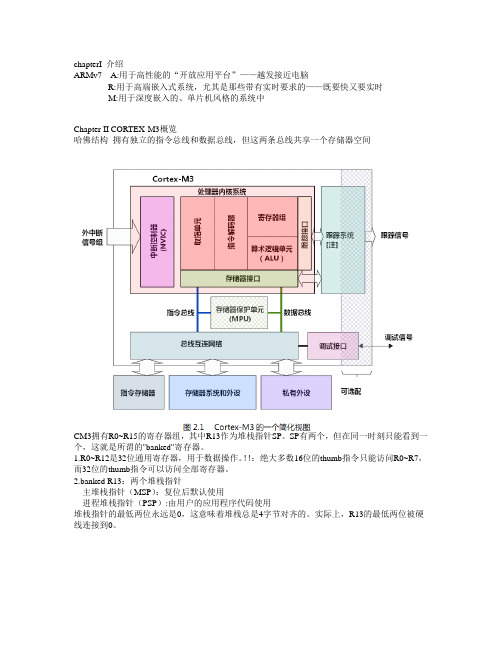
chapterI 介绍ARMv7 A:用于高性能的“开放应用平台”——越发接近电脑R:用于高端嵌入式系统,尤其是那些带有实时要求的——既要快又要实时M:用于深度嵌入的、单片机风格的系统中Chapter II CORTEX-M3概览哈佛结构拥有独立的指令总线和数据总线,但这两条总线共享一个存储器空间CM3拥有R0~R15的寄存器组,其中R13作为堆栈指针SP。
SP有两个,但在同一时刻只能看到一个,这就是所谓的"banked"寄存器。
1.R0~R12是32位通用寄存器,用于数据操作。
!!:绝大多数16位的thumb指令只能访问R0~R7,而32位的thumb指令可以访问全部寄存器。
2.banked R13:两个堆栈指针主堆栈指针(MSP):复位后默认使用进程堆栈指针(PSP):由用户的应用程序代码使用堆栈指针的最低两位永远是0,这意味着堆栈总是4字节对齐的。
实际上,R13的最低两位被硬线连接到0。
3.R14:连接寄存器:当调用一个子程序时,由R14存储返回地址4.R15:程序计数寄存器:只向当前程序地址5.特殊功能寄存器:程序状态子寄存器组(PSR)中断屏蔽寄存器组(primask,faultmask,besepri)控制寄存器(control)还支持两级特权操作:特权级和用户级在CM3运行主应用程序时(thread mode),既可以使用用户特权级,也可以使用用户级;但是异常服务例程必须在特权级下执行。
复位后,默认进入thread mode,特权级访问。
在特权级下,程序可以访问所有范围的存储器(如果有MPU,则必须在MPU规定范围之外),并且可以执行所有指令。
一旦进入用户级,想要进入特权级必须:执行一条系统调用指令(SVC),这会出发SVC异常,然后由异常服务例程接管,如果批准进入,则异常服务例程修改control寄存器,才能在用户级的thread mode 下重新进入特权级。
ARM Cortex-M3 学习笔记(5)最近在学ARM Cortex-M3,找了本号称很经典的书An Definitive Guide to The ARM Cortex-M3 在看。
这个系列学习笔记其实就是在学习这本书的过程中做的读书笔记。
第五章存储器系统地址空间分配对比更早版本的ARM 内核,Cortex-M3 的地址空间分配相对来说是固定的。
尤其是内部的私有外设,地址分配是固定不变的。
这为软件移植提供很大的方便。
图1 Cortex-M3 地址空间分配片内SRAM 地址空间和片内外设地址空间中各有1MB 是所谓的位带区。
这个区数据可以按位访问。
外部SRAM 和外部外设地址空间中没有位带区。
RAM 地址空间与外设地址空间最大的区别是RAM 地址空间中的存储的数据是可以作为程序代码运行的,而外设地址空间中的数据却不能运行。
当然,程序最好还是放到片内的代码区,因为对这个区域的访问有专用的总线,因此读取程序代码与读取RAM 区的数据可以同时进行,效率最高。
Bit-Band 操作在0x20000000 和0x40000000 地址处开始的1MB 空间被称为bit-band region。
这个区域内的数据的每一位都被映射了到了一个32 位宽的word 的最低一位,被映射到的地址空间称为bit-band alias address range。
比如说,0x20000000 对应字节第0 位映射到了0x22000000 的第0 位。
0x20000000 的第1 位映射到了0x22000004 的第0 位,其他的以此类推。
这样,读取0x22000004 就相当于读取0x20000000 的第1 位。
写0x22000004 的第0 位就相当于写0x20000000 的第1 位。
对bit-band aliasaddress range 中数据的读写都是原子操作。
ARM Cortex-M3 学习笔记(1)
最近在学ARM Cortex-M3,找了本号称很经典的书An Definitive Guide to The ARM Cortex-M3 在看。
这个系列学习笔记其实就是在学习这本书的过程中做的读书笔记。
第一章简介这一章的内容主要是介绍Cortex-M3 内核是如何的
强悍。
还顺带着介绍了ARM 系列的发展历史和路线。
ARM 公司成立于1990 年,ARM 公司是Advanced RISC Machines Ltd.的缩写,当然ARM 就是Advanced RISC Machines 的缩写了,ARM 公司是由Apple,Acorn 和VLSI 三家共同出资创建的。
ARM 处理器内核的发展可以用一张图来说明:
图1 ARM 处理器内核的发展从上图中可以看到,ARM 7 系列是基于v4 内核的,ARM9 系列是基于v5 内核的,ARM11 是基于v6 内核的,而Cortex 系列则是基于v7 内核的。
指令集的演化可以用下图来描述:
图2 指令集演进图Cortex-M3 采用Thumb-2 指令集,不支持ARM 指令集,对Thumb-2 指令集其实也只是部分的支持,有很少一部分Thumb-2 指令是不
支持的。
由于不支持ARM 指令集,也就没有了处理器状态在Thumb 和ARM
之间来回的切换,省去了很多麻烦。
tips:感谢大家的阅读,本文由我司收集整编。
仅供参阅!。