基于核双子空间线性判别分析人脸识别方法
- 格式:pdf
- 大小:273.13 KB
- 文档页数:4

基于核主成分分析特征提取及支持向量机的人脸识别应用研究一、综述近年来,随着计算机技术的发展和人类对信息安全需求的日益增长,人脸识别作为一种具有广泛应用前景的技术,得到了广泛关注。
传统的面部识别方法面临着诸多挑战,例如在复杂环境下的人脸捕捉、处理以及识别准确性等问题。
为了克服这些问题,研究者们将目光投向了更为高效的特征提取算法和支持向量机(SVM)的分类器。
核主成分分析(Kernel PCA, KDE)是一种重要的非线性特征提取方法。
它通过对原始高维数据映射到低维空间,并在此空间中求取主成分,从而有效地减少数据的维度,同时保留数据中的主要信息。
KDE 在人脸识别领域展现出了良好的性能,为解决非线性问题提供了新的思路。
支持向量机(SVM)作为另一种重要的监督学习算法,在模式分类和回归分析等领域取得了显著的成果。
相较于传统方法,SVM 通过最大化间隔原则,有效地提高了分类器的泛化能力。
在人脸识别领域,SVM 可以克服特征维度高、分类困难等问题,从而进一步提高识别的准确率和鲁棒性。
将核主成分分析和支持向量机相结合用于人脸识别的研究逐渐受到关注。
这种结合充分利用了两者的优势,提高了特征提取与分类的效率。
本文将对相关研究进行综述,介绍 KPCA 和 SVM 在人脸识别中的应用进展,分析其在实际场景中的优缺点,为后续的研究提供参考。
1. 人脸识别的研究背景和意义在信息时代的浪潮下,人脸识别技术以其捕捉便捷、操作简便的特点,逐渐成为了网络安全领域中具有重要价值的身份验证手段。
随着人们生活节奏的不断加快,对安全和便捷性的需求也日益提升,人脸识别技术在金融、医疗、教育等多个行业的应用越来越广泛。
在此背景下,研究如何通过精确的身份识别技术来维护网络空间安全,已成为当前亟待解决的问题。
人脸识别技术的研究背景源于图像处理与模式识别领域的深层次理论——主成分分析(PCA)。
作为一种广泛应用的特征提取方法,PCA能有效减少数据集中的冗余信息,并将高维数据映射至低维空间,从而简化数据结构,提升数据分析的效率与准确性。

基于核函的LDA人脸图像识别摘要对于人脸识别,大家似乎认为它离我们很远,其实人脸识别与我们的生活也是息息相关的。
人脸识别是生物特征识别的一个主要研究方向,与其它生物特征识别技术相比较,人脸识别具有能动性,用户界面友好等许多特点。
同时,在所有的生物特征方向,人脸特征也是最普遍和最比较容易获取的。
因此,在模式识别和图像处理领域,人脸识别一直都是比较热门的研究课题之一。
特征提取是模式识别学科研究的最基本问题之一。
对于人脸识别而言,抽取有效的人脸特征是完成人脸识别任务的关键。
从最初的基于几何的方法到基于统计等复杂特征的方法,人脸识别已经发展了很多算法。
目前,基于统计特征的线性方法在人脸识别中以发展的比较成热,但是由于人脸识别涉及光照、表情、姿态等诸多因素,线性方法在实际也应用中表现得还远远不够。
因此,将线性方法拓展到非线性领域以提高识别率是个有待解决的问题。
基于核函数的特征提取方法是最近提出的一种很有效的非线性特征提取方法。
本文就基于核的特征提取方法在人脸识别方面的应用进行了较深入的研究,所提出的算法在ORL人脸数据库上的试验取得了比较好的识别效率。
关键词:人脸识别;特征提取;核方法Kernel Function-Based LDA Face Image RecognitionAbstractFor face recognition, everyone seems to think it is very far away from us, in fact, face recognition and our lives are also closely related. Face recognition is the biometric identification of a major research direction, compared with other biometric identification technology, face recognition book mobility, friendly user interface and many other features. Meanwhile, In the direction of all the biometric facial feature is the most common and most relatively easy to obtain. Therefore,In the field of pattern recognition and image processing, face recognition has always been a popular research topic. Feature extraction is one of the most fundamental problems of pattern recognition disciplines. For face recognition, the extraction of effective facial feature is the key to complete the recognition task. From the initial geometry-based approach to the methods based on statistical and other complex features, face recognition has been the development of many algorithms. At present, To develop linear methods based on statistical features in face recognition more into the hot face recognition involves illumination, facial expression, posture and many other factors, the linear method in practical applications, performance is still far from enough. Therefore, that the linear method is extended to the nonlinear field in order to improve the recognition rate is a problem to be solved. Based on multiple nuclear functions combination of feature extraction methods recently proposed a very effective non-linear feature extraction method. In this paper, based on the core feature extraction method in face recognition more in-depth study, the test of the proposed algorithm in the YALE face database and obtain good recognition efficiency. First understand the LDA (linear discriminant analysis) as the principles and methods of feature extraction tools; and then to understand the basic idea of the definition of the kernel function, principles, characteristics and Kernel space. And then to understand the basic idea of the definition of the kernel function, principles, characteristics and Kernel space; Understand existing use "LDA" and "KLDA method for face image recognition rate; MATLAB code written in "the LDA" and "KLDA (a kernel function) method for face recognition; Writing based on the "KLDA for face image recognitionMATLAB code with the combination of multiple kernels; Finally, the advantages and disadvantages of a single kernel function KLDA for human face recognition and scope of application of the multiple Kernel functions combination.Keyword: Face recognition; feature extraction; Kernel function目录1绪论 (1)1.1人脸识别发展介绍 (1)1.2人脸识别研究意义 (3)1.3本文人脸识别研究方法 (3)1.4人脸识别技术的应用 (3)2线性判别分析LDA (5)2.1Fisher算法理论基础 (5)2.2欧氏距离 (7)2.3研究LDA的方法步骤 (9)2.3实现过程 (10)2.4实现结果 (10)2.5结果分析 (15)3核函数 (16)3.1理论基础 (16)3.1.1传统方法 (16)3.1.2核技巧 (17)3.2常用的几种核函数形式 (19)3.3核函数的特点 (20)3.4核函数处理非线性问题 (21)4研究成果 (23)4.1人脸库的选取 (23)4.2随机数模拟LDA成果 (23)4.3LDA在ORL库中的识别成果 (26)4.4核函数在ORL库中的识别成果 (28)4.4.1核函数方法实施步骤 (28)4.4.2在ORL库中的识别过程 (28)4.4.3部分实验结果 (32)4.4.4单个核函数结果分析 (33)5总结 (34)5.1对于LDA的总结 (34)5.2对核函数的总结 (34)5.3相对比较 (34)致谢 (35)参考文献 (36)1绪论1.1人脸识别发展介绍第一阶段(1964~1990)这一阶段人脸识别通常只是作为一个一般性的模式识别问题来研究,所采用的主要技术方案是基于人脸几何结构特征的方法。

人脸识别主要算法原理人脸识别主要算法原理主流的人脸识别技术基本上可以归结为三类,即:基于几何特征的方法、基于模板的方法和基于模型的方法。
1. 基于几何特征的方法是最早、最传统的方法,通常需要和其他算法结合才能有比较好的效果;2. 基于模板的方法可以分为基于相关匹配的方法、特征脸方法、线性判别分析方法、奇异值分解方法、神经网络方法、动态连接匹配方法等。
3. 基于模型的方法则有基于隐马尔柯夫模型,主动形状模型和主动外观模型的方法等。
1. 基于几何特征的方法人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。
几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。
Jia 等由正面灰度图中线附近的积分投影模拟侧面轮廓图是一种很有新意的方法。
采用几何特征进行正面人脸识别一般是通过提取人眼、口、鼻等重要特征点的位置和眼睛等重要器官的几何形状作为分类特征,但Roder对几何特征提取的精确性进行了实验性的研究,结果不容乐观。
可变形模板法可以视为几何特征方法的一种改进,其基本思想是:设计一个参数可调的器官模型(即可变形模板),定义一个能量函数,通过调整模型参数使能量函数最小化,此时的模型参数即做为该器官的几何特征。
这种方法思想很好,但是存在两个问题,一是能量函数中各种代价的加权系数只能由经验确定,难以推广,二是能量函数优化过程十分耗时,难以实际应用。
基于参数的人脸表示可以实现对人脸显著特征的一个高效描述,但它需要大量的前处理和精细的参数选择。
同时,采用一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求,计算量也较大。

人脸识别主要算法原理主流的人脸识别技术基本上可以归结为三类,即:基于几何特征的方法、基于模板的方法和基于模型的方法。
1.基于几何特征的方法是最早、最传统的方法,通常需要和其他算法结合才能有比较好的效果;2.基于模板的方法可以分为基于相关匹配的方法、特征脸方法、线性判别分析方法、奇异值分解方法、神经网络方法、动态连接匹配方法等。
3.基于模型的方法则有基于隐马尔柯夫模型,主动形状模型和主动外观模型的方法等。
1.基于几何特征的方法人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。
几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。
Jia等由正面灰度图中线附近的积分投影模拟侧面轮廓图是一种很有新意的方法。
采用几何特征进行正面人脸识别一般是通过提取人眼、口、鼻等重要特征点的位置和眼睛等重要器官的几何形状作为分类特征,但Roder对几何特征提取的精确性进行了实验性的研究,结果不容乐观。
可变形模板法可以视为几何特征方法的一种改进,其基本思想是:设计一个参数可调的器官模型(即可变形模板),定义一个能量函数,通过调整模型参数使能量函数最小化,此时的模型参数即做为该器官的几何特征。
这种方法思想很好,但是存在两个问题,一是能量函数中各种代价的加权系数只能由经验确定,难以推广,二是能量函数优化过程十分耗时,难以实际应用。
基于参数的人脸表示可以实现对人脸显著特征的一个高效描述,但它需要大量的前处理和精细的参数选择。
同时,采用一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求,计算量也较大。
2.局部特征分析方法(Local Face Analysis)主元子空间的表示是紧凑的,特征维数大大降低,但它是非局部化的,其核函数的支集扩展在整个坐标空间中,同时它是非拓扑的,某个轴投影后临近的点与原图像空间中点的临近性没有任何关系,而局部性和拓扑性对模式分析和分割是理想的特性,似乎这更符合神经信息处理的机制,因此寻找具有这种特性的表达十分重要。
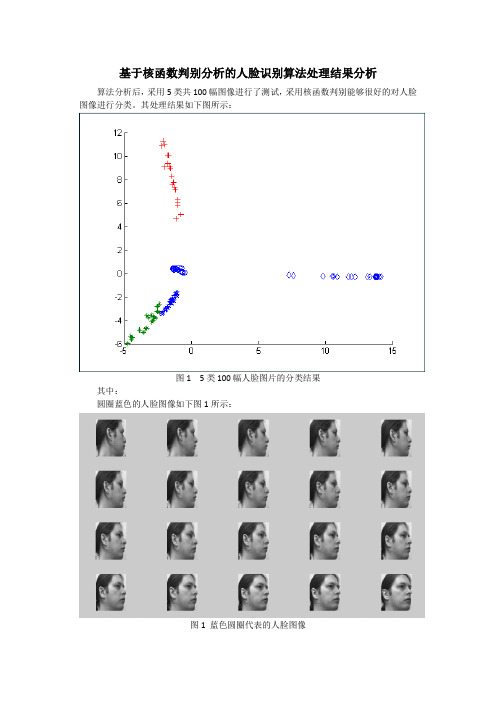
基于核函数判别分析的人脸识别算法处理结果分析算法分析后,采用5类共100幅图像进行了测试,采用核函数判别能够很好的对人脸图像进行分类。
其处理结果如下图所示:图1 5类100幅人脸图片的分类结果其中:圆圈蓝色的人脸图像如下图1所示:图1 蓝色圆圈代表的人脸图像绿色*所对应的图像如下图2所示图 2 绿色*所对应的人脸图像红色+所对应的图像如下图3所示:图 3 红色+所对应的人脸图像蓝色☆所对应的人脸图像如下图4所示:蓝色◇所对应的人脸图像如下图5所示:图 5 所示蓝色◇所对应的人脸图像上述,结果虽然能够正确的将人脸的图像进行分类,但是在局部细节的噪声干扰上任然不能对其进行很好的分类。
例如:处理结果的绿色*和蓝色☆所对应的人脸图像就不能够很好的进行分类。
两者的人脸图像的分布集中在一起,直观情况下,两者都是带眼镜,现在排除眼镜的干扰,选取没有或只有一类图像戴眼镜的进行分析。
在没有上述蓝色☆所对应的人脸图像中,实验结果的分布如下图6所示:图6 没有图4所对应的人脸图像的处理结果在没有上述图2所对应的人脸图像的,实验结果如下图7所示:图7 没有图2的人脸图像对应的实验结果上述两种处理结果,在没有戴眼镜的情况下,实验结果能够很好的将人脸图像进行分类。
由上述结果分析,可得戴眼镜的人脸图像在进行判别分析的时候降低了特征空间的特征系数分布,是两者之间的判别分类的区别性增大,不易进行分类。
由于进行了很判别分析的特征提取后,样本间具有了很高的可分性,采用最邻近分类器进行分类。
当一幅图像经过特征提取后为:m,另一幅图像经过特征提取后为:n,当的值最小或达到一个阈值的时候,m所代表的类别就可以划分到n的两者之间的m n类别中。
有实验结果图1所示图 1 5类人脸图像的分布纵横坐标分表代表了各个图像的特征系数,也就是这里所说的特征数值,绿色*所代表的人脸特征和蓝色☆所代表的人脸特征有部分重叠。
不能够很好的进行判别分类。
由于处理的结果,外界因素(这里指戴眼镜)对人脸分类产生很大的影响,8图是在没有眼镜的情况下的实验结果:图8 不含戴眼镜人脸图像的实验结果由上述分析,可得当人脸图像在带上眼镜的时候,训练集就把这一特征作为人脸的一个分类标准,它们可以很好的被分类出来,但是,当遇到两个或两个以上戴眼镜的时候,分类处理就把这两个具有戴眼镜的一起作为一个新的特征被分类到了一起。
