流水线题解
- 格式:ppt
- 大小:264.50 KB
- 文档页数:17


流水线作业排序问题/productioncontrol/200908091604.html流水作业排序问题的基本特征是每个工件的加工路线都一致。
在流水生产线上制造不同的零件,遇到的就是流水作业排序问题。
我们说加工路线一致,是指工件的流向一致,并不要求每个工件必须经过加工路线上每台机器加工。
如果某些工件不经某些机器加工,则设相应的加工时间为零。
一般说来,对于流水作业排序问题,工件在不同机器上的加工顺序不尽一致。
但本节要讨论的是一种特殊情况,即所有工件在各台机器上的加工顺序都相同的情况。
这就是排列排序问题。
流水作业排列排序问题常被称作“同顺序”排序问题。
对于一般情形,排列排序问题的最优解不一定是相应的流水作业排序问题的最优解,但一般是比较好的解;对于仅有2台和3台机器的特殊情况,可以证明,排列排序问题下的最优解一定是相应流水作业排序问题的最优解。
这里只讨论排列排序问题。
但对于2台机器的排序问题,实际上不限于排列排序问题。
一、最长流程时间Fmax的计算这里所讨论的是n/m/P /Fmax,问题,其中n为工件数,m为机器数,P表示流水线作业排列排序问题,Fmax为目标函数。
目标函数是使最长流程时间最短,最长流程时间又称作加工周期,它是从第一个工件在第一台机器开始加工时算起,到最后一个工件在最后一台机器上完成加工时为止所经过的时间。
由于假设所有工件的到达时间都为零(ri=0,i= 1,2,…,n),所以Fmax等于排在末位加工的工件在车间的停留时间,也等于一批工件的最长完工时间Cmax。
设n个工件的加工顺序为S=(S1,S2,S3,…,Sn),其中Si为第i位加工的工件的代号。
以表示工件Si在机器M k上的完工时间, 表示工件Si在Mk上的加工时间,k= 1,2,…,m;i=1,2,…,n,则可按以下公式计算:在熟悉以上计算公式之后,可直接在加工时间矩阵上从左向右计算完工时间。
下面以一例说明。
例9.4 有一个6/4/p/F max问题,其加工时间如表9—6所示。

3.12 有一指令流水线如下所示出 50ns 50ns 100ns 200ns(1) 求连续输入10条指令,该流水线的实际吞吐率和效率;(2) 该流水线的“瓶颈”在哪一段?请采取两种不同的措施消除此“瓶颈”。
对于你所给出的两种新的流水线,连续输入10条指令时,其实际吞吐率和效率各是多少? 解:(1)2200(ns)2009200)10050(50t )1n (t T maxm1i i pipeline =⨯++++=∆-+∆=∑= )(ns 2201T nTP 1pipeline-==45.45%1154400TP mtTP E m1i i≈=⋅=∆⋅=∑= (2)瓶颈在3、4段。
⏹ 变成八级流水线(细分)850(ns)509850t 1)(n t T maxm1i i pipeline =⨯+⨯=∆-+∆=∑=)(ns 851T nTP 1pipeline-==58.82%17108400TP mtiTP E m1i ≈=⋅=∆⋅=∑= ⏹ 重复设置部件)(ns 851T nTP 1pipeline-==58.82%1710885010400E ≈=⨯⨯=3.134段组成,3段时,一次,然4段。
如果需要的时间都是t ∆,问:(1) 当在流水线的输入端连续地每t ∆时间输入任务时,该流水线会发生什么情况?(2) 此流水线的最大吞吐率为多少?如果每t ∆2输入一个任务,连续处理10个任务时的实际吞吐率和效率是多少?(3) 当每段时间不变时,如何提高该流水线的吞吐率?仍连续处理10个任务时,其吞吐率提高多少?(2)54.35%925045TP E 2310T nTp 23T 21TP pipelinepipeline max ≈=∆⋅=∆∆==∆=∆=t tt t(3)重复设置部件tt∆⋅=∆⋅==751410T nTP pipeline吞吐率提高倍数=tt ∆∆231075=1.643.14 有一条静态多功能流水线由5段组成,加法用1、3、4、5段,乘法用1、2、5段,第3段的时间为2△t ,其余各段的时间均为△t ,而且流水线的输出可以直接返回输入端或 4段t∆ 14暂存于相应的流水寄存器中。


一、 问题描述给定n 个作业,每个作业有两道工序,分别在两台机器上处理。
一台机器一次只能处理一道工序,并且一道工序一旦开始就必须进行下去直到完成。
一个作业只有在机器1上的处理完成以后才能由机器2处理。
假设已知作业i 在机器j 上需要的处理时间为t[i,j]。
流水作业调度问题就是要求确定一个作业的处理顺序使得尽快完成这n 个作业。
二、 算法分析n 个作业{1,2,…,n}要在由2台机器1M 和2M 组成的流水线上完成加工。
每个作业加工的顺序都是先在1M 上加工,然后在2M 上加工。
1M 和2M 加工作业i 所需要的时间分别为t[i,1]和t[i,2], n i ≤≤1.流水作业调度问题要求确定这n 个作业的最优加工顺序,使得从第一个作业在机器1M 上开始加工,到最后一个作业在机器2M 上加工完成所需的时间最少。
从直观上我们可以看到,一个最优调度应使机器1M 没有空闲时间,且机器2M 的空闲时间是最少。
在一般情况下,机器2M 上会有机器空闲和作业积压两种情况。
设全部作业的集合为},....,2,1{n N =。
N S ⊆是N 的作业子集。
在一般情况下,机器1M 开始加工S 中作业时,机器2M 还在加工其他作业,要等时间t 后才能利用。
将这种情况下完成S 中作业所需的最短时间计为),(t S T 。
流水作业调度问题的最优解为)0,(N T 。
1. 证明流水作业调度问题具有最优子结构设a 是所给n 个流水作业的一个最优调度,它所需要的加工时间为']1),1([T a t +。
其中,'T 是在机器2M 的等待时间为]2),1([a t 时,安排作业)(),......,3(),2(n a a a 所需的时间。
记)}1({a N S -=,则我们可以得到])2),1([,('a t S T T =。
事实上,有T 的定义可知])2),1([,('a t S T T ≥.若])2),1([,('a t S T T >,设'a 是作业集S 在机器2M 的等待时间为]2),1([a t 情况下的一个最优调度。


计算机组成原理专升本试题解析指令流水线与并行处理计算机组成原理是计算机专业学生必修的一门基础课程,对于理解计算机的组成和工作原理非常重要。
在计算机组成原理的学习中,指令流水线与并行处理是一个重要的概念和技术。
本文将对指令流水线与并行处理进行详细解析。
一、指令流水线指令流水线是一种通过将处理器的执行过程划分为多个子阶段,并行执行这些子阶段来提高处理器性能的技术。
在指令流水线中,每个指令在执行的过程中经过取指令、译码、执行、访存和写回等多个阶段,不同指令在不同阶段同时执行,从而在单位时间内处理更多的指令。
指令流水线的优势在于充分利用了处理器的硬件资源,提高了指令的执行效率。
但是在实际应用中,由于指令间有数据依赖关系等问题,可能会导致流水线的阻塞和冒险,进而影响性能。
为了解决这些问题,人们提出了一系列的技术和策略,比如数据旁路、预测执行和乱序执行等,来提高指令流水线的性能。
二、并行处理并行处理是指通过同时执行多个任务来提高系统的处理能力和性能的技术。
在计算机组成原理中,主要涉及到的并行处理包括指令级并行和线程级并行。
指令级并行是通过在一个指令的执行过程中同时执行多个子指令来提高处理器性能的技术。
一种实现指令级并行的方法是超标量处理器,它能够在一个时钟周期内同时发射多条指令,并行执行这些指令。
另一种实现指令级并行的方法是超流水线处理器,它将处理器的执行流程进一步细分为多个较短的子阶段,以便更多地重叠执行。
线程级并行是通过同时处理多个线程来提高系统性能的技术。
在多核处理器和多线程处理器中,可以同时执行多个线程,从而实现线程级并行。
通过合理的线程调度和资源分配,可以充分利用处理器的硬件资源,提高系统的吞吐量和响应速度。
指令流水线和并行处理是计算机组成原理中的两个重要概念和技术,它们可以相互结合,共同提高计算机系统的性能。
指令流水线通过划分指令执行过程为多个子阶段并行执行,提高了指令的执行效率;而并行处理通过同时处理多个任务或线程,提高了系统的处理能力和性能。

系统架构设计师真题解析(计算题)第一章计算机组成与体系结构流水线吞吐率、加速比2017年下半年1.某计算机系统采用5级流水线结构执行指令,设每条指令的执行由取指令(2t ∆)、分析指令(1t ∆)、取操作数(3t ∆)、运算(1t ∆)和写回结果(2t ∆)组成,并分别用5个子部件完成,该流水线的最大吞吐率为();若连续向流水线输入10条指令,则该流水线的加速比为()。
【解析】理论流水线执行时间=(2t ∆+1t ∆+3t ∆+1t ∆+2t ∆)+max(2t ∆,1t ∆,3t ∆,1t ∆,2t ∆)*(n-1)=9t ∆+(n-1)*3t ∆;第一问:最大吞吐率:Δt 31Δt 6t nΔ3n Δt31)(n-Δt+9n n =+=⨯∞→lim 第二问:10条指令使用流水线的执行时间=9t ∆+(10-1)*3t ∆=36t ∆。
10条指令不用流水线的执行时间=9t ∆*10=90t ∆。
加速比=使用流水线的执行时间/不使用流水线的执行时间=90t ∆/36t ∆=5:2。
2.例:某计算机系统,一条指令的执行需要经历取指(2ms )、分析(4ms )、执行(1ms )三个阶段,现要执行100条指令,利用流水线技术需要多长时间?(教材1.3.1)理论上来说,1条指令的执行时间为:2ms+4ms+1ms=7ms 。
所以:理论流水线执行时间=2ms+4ms+1ms+(100-1)*4=403ms 。
而实际上,真正做流水线处理时,考虑到处理的复杂性,会将指令的每个执行阶段的时间都统一为流水线周期,即1条指令的执行时间为:4ms+4ms+4ms=12ms 。
所以:实际流水线执行时间=4ms+4ms+4ms+(100-1)*4=408ms扩展:上述题目中,如果采用3级操作,2级流水,等价于将3级操作变成2级操作。
最合理的划分是由取指(2ms )、分析(4ms )、执行(1ms )相连划分为指(2ms )、分析(4ms )+执行(1ms )={2,5}。
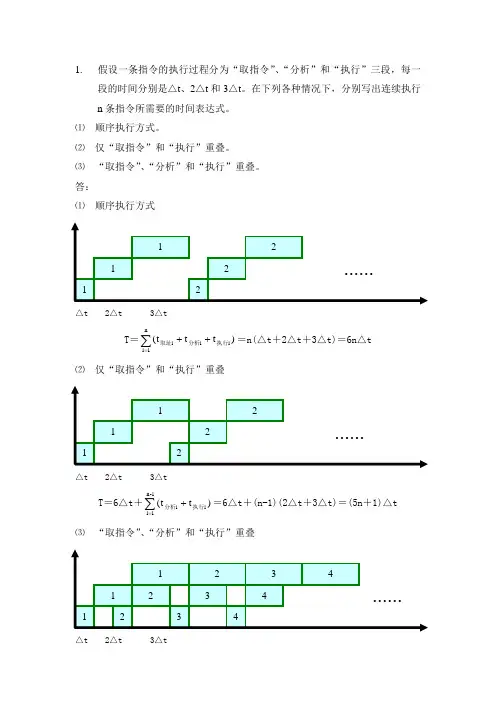
1. 假设一条指令的执行过程分为“取指令”、“分析”和“执行”三段,每一段的时间分别是△t 、2△t 和3△t 。
在下列各种情况下,分别写出连续执行n 条指令所需要的时间表达式。
⑴ 顺序执行方式。
⑵ 仅“取指令”和“执行”重叠。
⑶ “取指令”、“分析”和“执行”重叠。
答:⑴ 顺序执行方式12 ......1 2 12T =∑=++n1i i i i )t t t (执行分析取址=n(△t +2△t +3△t)=6n △t⑵ 仅“取指令”和“执行”重叠12 ......1 212T =6△t +∑=+1-n 1i i i )t t (执行分析=6△t +(n-1)(2△t +3△t)=(5n +1)△t⑶ “取指令”、“分析”和“执行”重叠12 34 ......1 2 3 41234△t2△t3△t△t2△t3△t△t2△t3△tT =6△t +∑=1-n 1i i )t (执行=6△t +(n-1)(3△t)=(3n +3)△t2. 一条线性流水线有4个功能段组成,每个功能段的延迟时间都相等,都为△t 。
开始5个任务,每间隔一个△t 向流水线输入一个任务,然后停顿2个△t ,如此重复。
求流水线的实际吞吐率、加速比和效率。
答:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15...1 2 3 4 5 6 7 8 9 10 11 12 13 14 151 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 2 3 4 56 7 8 9 10 11 12 13 14 151 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23我们可以看出,在(7n+1)Δt 的时间内,可以输出5n 个结果,如果指令的序列足够长(n →∞),并且指令间不存在相关,那么,吞吐率可以认为满足:)n (t75t )n /17(5t )1n 7(n 5TP ∞→∆=∆+=∆+=加速比为:)n (720n /17201n 7n 20t )1n 7(t 4n 5S ∞→=+=+=∆+∆⨯=从上面的时空图很容易看出,效率为:)n (75n /1751n 7n 5t )1n 7(4t 4n 5E ∞→=+=+=∆+⨯∆⨯=3. 用一条5个功能段的浮点加法器流水线计算∑==101i i A F 。


试题25(2007年11月试题4~5)若每一条指令都可以分解为取指、分析和执行三步。
已知取指时间t取指=4,分析时间t分析=3 ,执行时间t执行=5 .如果按串行方式执行完100条指令需要(4) .如果按照流水线方式执行,执行完100条指令需要(5) .(4)A. 1190 B.119 5C. 1200 D.1205(5)A. 504 B. 507 C. 508 D. 510试题25分析按顺序方式执行指令,每条指令从取指到执行共耗时12?t,所以100条指令共耗时: .有关流水线连续执行指令所需时间,请参考试题3的分析。
在本题中,采用流水线的耗时为:试题25答案(4)C(5)B试题26(2007年11月试题6)若内存地址区间为4000H~43FFH,每个存储单元可存储16位二进制数,该内存区域由4片存储器芯片构成,则构成该内存所用的存储器芯片的容量是(6) .(6)A. 512×16bit B. 256×8bit C. 256×16bit D. 1024×8bit 试题26分析内存从4000H到43FFH的内存有43FFH-4000H+1=1024 个字节,由于每个存储单元可存储16位二进制数,内存区域用4片存储器芯片构成,因此每片的容量为1024/4×16bit=256×16 bit.试题26答案(6)C试题27(2008年5月试题1)在计算机体系结构中,CPU 内部包括程序计数器PC、存储器数据寄存器MDR、指令寄存器IR 和存储器地址寄存器MAR 等。
若CPU 要执行的指令为:MOV R0, #100(即将数值100传送到寄存器R0中),则CPU 首先要完成的操作是(1) .(1)A.100→R0 B. 100→MDR C. PC→MAR D. PC→IR试题27分析指令的执行过程一般为:到内存读取指令,控制器分析指令,控制器按指令要求的具体操作功能,用一到几个执行步骤,驱动计算机相关部件完成指令的运算、操作功能,并在这期间准备好下一条指令的地址到程序计数器PC中,至此,本条指令的功能算是完成了,接下来检查有无中断请求,若无中断请求,则进入下一条指令的执行过程。
算法设计与分析——流⽔作业调度(动态规划)⼀、问题描述N个作业{1,2,………,n}要在由两台机器M1和M2组成的流⽔线上完成加⼯。
每个作业加⼯的顺序都是先在M1上加⼯,然后在M2上加⼯。
M1和M2加⼯作业i所需的时间分别为ai和bi,1≤i≤n。
流⽔作业⾼度问题要求确定这n个作业的最优加⼯顺序,使得从第⼀个作业在机器M1上开始加⼯,到最后⼀个作业在机器M2上加⼯完成所需的时间最少。
⼆、算法思路直观上,⼀个最优调度应使机器M1没有空闲时间,且机器M2的空闲时间最少。
在⼀般情况下,机器M2上会有机器空闲和作业积压2种情况。
最优调度应该是:1. 使M1上的加⼯是⽆间断的。
即M1上的加⼯时间是所有ai之和,但M2上不⼀定是bi之和。
2. 使作业在两台机器上的加⼯次序是完全相同的。
则得结论:仅需考虑在两台机上加⼯次序完全相同的调度。
设全部作业的集合为N={1,2,…,n}。
S是N的作业⼦集。
在⼀般情况下,机器M1开始加⼯S中作业时,机器M2还在加⼯其他作业,要等时间t后才可利⽤。
将这种情况下完成S中作业所需的最短时间记为T(S,t)。
流⽔作业调度问题的最优值为T(N,0)。
这个T(S,t)该如何理解?举个例⼦就好搞了(⽤ipad pencil写的...没贴类纸膜,太滑,凑合看吧)1、最优⼦结构T(N,0)=min{ai + T(N-{i}, bi)}, i∈N。
ai:选⼀个作业i先加⼯,在M1的加⼯时间。
T(N-{i},bi}:剩下的作业要等bi时间后才能在M2上加⼯。
注意这⾥函数的定义,因为⼀开始⼯作i是随机取的,M1加⼯完了ai之后,要开始加⼯bi了,这⾥M1是空闲的可以开始加⼯剩下的N-i个作业了,但此时M2开始加⼯bi,所以要等bi时间之后才能重新利⽤,对应到上⾯函数T(s,t)的定义的话,这⾥就应该表⽰成T(N-{i},bi), 所以最优解可表⽰为T(N,0)=min{ai + T(N-{i}, bi)}, i∈N,即我们要枚举所有的⼯作i,使这个式⼦取到最⼩值。
流水线作业调度问题Time Limit: 1000 ms Case Time Limit: 1000 ms Memory Limit: 64 MBDescriptionN个作业{1,2,………,n}要在由两台机器M1和M2组成的流水线上完成加工。
每个作业加工的顺序都是先在M1上加工,然后在M2上加工。
M1和M2加工作业i所需的时间分别为ai和bi,1≤i≤n。
流水作业高度问题要求确定这n个作业的最优加工顺序,使得从第一个作业在机器M1上开始加工,到最后一个作业在机器M2上加工完成所需的时间最少。
Input输入包括若干测试用例,每个用例输入格式为:第1行一个整数代表任务数n,当为0时表示结束,或者输入到文件结束(EOF)第2行至第n+1行每行2个整数,代表任务在M1,M2上所需要的时间Output输出一个整数,代表执行n个任务的最短时间Sample InputOriginal Transformed11 2Sample OutputOriginal Transformed3思路:这一题的难度还是相当不小的。
首先是一个两道工序的流水线排序问题(“同顺序”排序问题)。
用Johnson算法来解决两道工序的流水线排序相对比较简单易懂,而且可以得到最优解。
Johnson算法的大致内容如下:(1)从加工时间矩阵中找出最短的加工时间。
(2)若最短的加工时间出现在M1上,则对应的工件尽可能往前排;若最短加工时间出现在M2上,则对应工件尽可能往后排。
然后,从加工时间矩阵中划去已排序工件的加工时间。
若最短加工时间有多个,则任挑一个。
(3)若所有工件都已排序,停止。
否则,转步骤(1)。
加工时间矩阵即为所有工件分别在两道工序上加工所需时间。
M1为工序1,M2为工序2(进入工序2之前,工序1必须完工)。
Johnson算法之所以能求出最优解,是因为:1.所有工件没开始加工时,只能加工工序1,工序2不得不空着。
2.我们只能利用工序2的加工过程尽量省去工序1的时间。
一.判断题1.一个指令周期由若干个机器周期组成.解:答案为正确.2.非访内指令不需从内存中取操作数,也不需将目的操作数存放到内存,因此这类指令的执行不需地址寄存器参与.解:答案为错误.3.组合逻辑控制器比微程序控制器的速度快.解:答案为正确.4.流水线中的相关问题是指在一段程序的相邻指令之间存在某种信赖关系,这种关系影响指令的执行.解:答案为正确.5.微程序控制控制方式与硬布线控制方式相比,最大的优点是提高了指令的执行速度.解:答案为正确.6.微程序控制器中的控制存储器可用PROM,EPROM或闪存实现.解:答案为正确.7.指令周期是指人CPU从主存取出一条指令开始到执行这条指令完成所需的时间.解:答案为正确.8.控制存储器是用来存放微程序的存储器,它比主存储器速度快.解:答案为正确.9.机器的主频最快,机器的速度就最快.解:答案为正确.10.80X86的数据传送指令MOV,不能实现两个内存操作数的传送.解:答案为正确.二.选择题1.指令系统中采用不同寻址方式的目的主要是.A. 实现程序控制和快速查找存储器地址B. 可以直接访问主存和外存C. 缩短指令长度,扩大寻址空间,提高编程灵活性D. 降低指令译码难度解:答案为C.2.CPU组成中不包括.A.指令寄存器B.地址寄存器C.指令译码器D.地址译码器解:答案为D.3.程序计数器PC在中.A.运算器B.控制器C.存储器D.I/O接口解:答案为B.4.计算机主频的周期是指.A.指令周期B.时钟周期C.CPU周期D.存取周期解:答案为B.5.CPU内通用寄存器的位数取决于.A.存储器容量B.机器字长C.指令的长度D.CPU的管脚数解:答案为B.6.以硬布线方式构成的控制器也叫.A.组合逻辑型控制器B.微程序控制器C.存储逻辑型控制器D.运算器解:答案为A.7.一个节拍脉冲持续的时间长短是.A.指令周期B.机器周期C.时钟周期D.以上都不是解:答案为C.8.直接转移指令的功能是将指令中的地址代码送入.A.累加器B.地址寄存器C.PCD.存储器解:答案为C.9.状态寄存器用来存放.A.算术运算结果B.逻辑运算结果C.运算类型D.算术,逻辑运算及测试指令的结果状态解:答案为D.10.微程序放在中.A.指令寄存器B.RAMC.控制存储器D.内存解:答案为C.11.某寄存器中的值有时是地址,这只有计算机的才能识别它.A.译码器B.判断程序C.指令D.时序信号解:答案为C.12.微程序控制器中,机器指令与微指令的关系是________.A. 每一条机器指令由一条微指令执行B. 每一条机器指令由一段用微指令编成的微程序来解释执行C. 一段机器指令组成的程序可由一条微指令来执行D. 一条微指令由若干条机器指令组成解:答案为C.13.在高速计算机中,广泛采用流水线技术.例如,可以将指令执行分成取指令,分析指令和执行指令3个阶段,不同指令的不同阶段可以①执行;各阶段的执行时间最好②;否则在流水线运行时,每个阶段的执行时间应取③.可供选择的答案:①A.顺序B.重叠C.循环D.并行②A.为0 B.为1个周期C.相等 D.不等③A. 3个阶段执行时间之和 B. 3个阶段执行时间的平均值C. 3个阶段执行时间的最小值D. 3个阶段执行时间的最大值解:答案为①D,②C,③D.14.微指令格式分成水平型和垂直型,前者的位数,用它编写的微程序.A.较少B.较多C.较长D.较短解:答案为B,D.15.异步控制常作为的主要控制方式.A. 单总线计算机结构计算机中访问主存和外部设备时B. 微型机的CPU控制中C.组合逻辑的CPU控制中D. 微程序控制器中解:答案为A.16.与微指令的执行周期对应的是.A.指令周期B.机器周期C.节拍周期D.时钟周期解:答案为B.三.填空题1.目前的CPU包括, 和CACHE(一级).答:运算器,控制器.2.CPU中保存当前正在执行的指令的寄存器为,保存下一条指令地址的寄存器为.答:指令寄存器IR,程序计数器PC.3.CPU从主存取出一条指令并执行该指令的时间叫,它常用若干个来表示,而后者又包含若干个.答:指令周期,机器周期,时钟周期.4.在程序执行过程中,控制器控制计算机的运行总是处于,分析指令和的循环之中.答:取指令,执行指令.5.控制器发出的控制信号是因素和因素的函数,前者是指出操作在什么条件下进行,后者是指操作在什么时刻进行.答:空间,时间.6.微程序入口地址是根据指令的产生的.答:译码器,操作码.7.微程序控制器的核心部件是,它一般用构成.答:控制存储器,只读存储器.8.微指令执行时,产生后继微地址的方法主要有, 等.答:计数器方式,断定方式.9.任何指令的第一个周期一定是.答:取指令.10.一条机器指令的执行可与一段微指令构成的相对应,微指令可由一系列组成.答:微程序,微命令.11.微程序设计技术是利用方法设计的一门技术.答:软件,控制器.12.在同一微周期中的微命令叫互斥的微命令;在同一微周期中的微命令叫相容的微命令.显然, 不能放在一起译码.答:不可能同时出现,可以同时出现,相容的微命令.13.在微程序控制器中,时序信号比较简单,一般采用.答:同步控制.14.保存当前栈顶地址的寄存器叫.答:栈顶指针SP.15.实现下面各功能有用哪些寄存器⑴表示运算结果是零的是.⑵表示运算结果溢出的是.⑶表示循环计数的是.⑷做8位乘除法时用来保存被乘数和被除数的是.⑸暂时存放参加ALU中运算的操作数和结果的是.答:⑴状态寄存器中的ZF.⑵状态寄存器中的OF.⑶CX.⑷AL/AX.⑸累加器.四.综合题1.在8086中,对于物理地址2014CH来说,如果段起始地址为20000H,则偏移量应为多少解:14CH.2.在8086中SP的初值为2000H,AX=3000H,BX=5000H.试问:(1) 执行指令PUSH AX后,SP=(2) 再执行指令PUSH BX及POP AX后,SP= ,BX= 请画出堆栈变化示意图.解:⑴SP=2000H-2=1FFEH⑵执行PUSH BX和POP AX后,SP=1FFEH-2+2=IFFEH,BX=5000H,指针变化图略.3.指出下列8086指令中,源操作数和目的操作的寻址方式.(1) PUSH AX (2) XCHG BX,[BP+SI](3) MOV CX,03F5H (4) LDS SI,[BX](5)LEA BX,[BX+SI] (6) MOV AX,[BX+SI+0123H](7) MOV CX,ES:[BX][SI] (8) MOV [SI],AX(9)XCHG AX,[2000H]解:⑴源是寄存器直接寻址.目的是寄存器间接寻址.⑵源是变址/基址寻址,目的是寄存器直接寻址.⑶源是立即数寻址,目的是寄存器直接寻址.⑷源是寄存器间接寻址.目的是寄存器直接寻址.⑸源是变址/基址寻址,目的是寄存器直接寻址.⑹源是变址/基址加偏移量寻址,目的是寄存器直接寻址.⑺源是跨段的变址/基址寻址,目的是寄存器直接寻址.⑻源是寄存器直接寻址.目的是寄存器间接寻址.⑼源是存储器直接寻址.目的是寄存器直接寻址.4.请按下面的要求写出相应的8086汇编指令序列.(1) 将1234H送入DS中(2) 将5678H与AX中的数相加,结果放在AX中.(3) 将DATAX和DATAY相加,其和放在DATAY中.(4) 将AX中的高4位变为全0.(5) 将AX中的低2位变为全1.解:⑴MOV AX,1234H ;MOV DS,AX⑵ADD AX,5678H⑶MOV AX,DATAXADD DATAY,AX⑷AND AX,0FFFH⑸OR AX,0003H5.若BX=0379H,下面8086指令执行后,BX=(1) XOR BX,0FF00H(2) AND BX,0FF00H(3) OR BX,0FF00H解:⑴根据"异或"操作的特点,与"0"做"异或"操作,操作数不变;与"1"做"异或"操作,即使操作数变反,此题仅使BH变反,所以结果为BX=1111110001111001=FC79H.⑵根据"与"操作的特点,对"0"做"与"操作,操作数为0;对"1"做"与"操作,即操作数不变.此题仅使BL清0,BH不变,所以结果为BX=0000001100000000=0300H.⑶根据"或"操作的特点,对"0"做"或"操作,操作数不变;对"1"做"或"操作,即操作数为 1.此题仅使BH(即高8位)置1,BL(低8位)不变,所以结果为BX=0000001110000110=0386H.6.若(BX)=5555H,试写出执行完下面的指令序列后BX中的内容.MOV CL,5SHR BX,CL解:第一条指令把数5传送到CL(CL是指定用于存放移位或循环次数的寄存器)中,第2条是逻辑右移指令,使BX逻辑右移5次(由CL给出移位次数),结果BX=02AAH.7.试用8086移位和加法指令完成将AX中的内容乘以10的操作.解:算法为AX×10=AX×2+AX×8,指令序列如下:SHL AX,1 ;AX×2MOV BX,AX ;AX×2保存到BXSHL AX,1 ;AX×4SHL AX,1 ;AX×8ADD AX,BX ;AX×108.根据以下要求写出相应的8086汇编语言指令.(1) 把BX寄存器和DX寄存器的内容相加,结果存入DX寄存器中.(2) 用寄存器BX和SI的基址变址寻址方式把存储器中的一个字节与AL寄存器的内容相加,并把结果送到AL寄存器中.(3) 用寄存器BX和偏移量0BD2H的寄存器相对寻址方式把存储器中的一个字和CX相加并把结果送回存储器中.(4) 用偏移量为0524H的直接寻址方式把存储器中的一个字与数2A59H相加,并把结果送回该存储单元中.(5) 把数0B5H与AL相加,并把结果送回AL中.解:⑴ADD DX,BX⑵ADD AL,[BX+SI]⑶ADD [BX+0BD2H],CX⑷ADD [0524H],2A59H⑸ADD AL,0B5H9.已知8086汇编程序段如下:MOV AX,1234HMOV CL,4ROL AX,CLDEC AXMOV CX,4MUL CXINT 20H试问:(1) 每条指令执行完后,AX寄存器的内容是什么(2) 每条指令执行完后,进位,溢出和零标志的值是什么(3) 程序结束时,AX和DX的内容是什么解:⑴MOV AX,1234H AX=1234HMOV CL,4 AX=1234HROL AX,CL AX=2341HDEC AX AX=2340HMOV CX,4 AX=2340HMUL CX AX=8D00HINT 20H第2,5,7条指令对AX没有操作,故不影响AX的值.第1条指令把立即数1234H送到AX中,AX 的值就是1234H,第3条指令把AX的内容循环移位4次,AX值为2341H,第4条指令把AX减1,AX的值为2340H,第6条指令把AX的值乘以4,AX的值变为8D00H.⑵传送指令不影响标志位,第3条指令影响进位(CF),溢出(OF)标志,CF=0,OF=0;第4条指令不影响CF标志,该指令执行后,CF维持原状,OF=0,零标志(ZF)也为0;第6条指令影响各标志位,由于DX=0,因此CF=0,OF=0,ZF=0.⑶程序结束时,AX的值为8D00H,DX的值为0000H.10.有一主频为25 MHz的微处理器,平均每条指令的执行时间为两个机器周期,每个机器周期由两个时钟脉冲组成.(1)假定存储器为"0等待",请计算机器速度(每秒钟执行的机器指令条数).(2)假如存储器速度较慢,每两个机器周期中有一个是访问存储器周期,需插入两个时钟的等待时间,请计算机器速度.解:⑴存储器"0等待"是假设在访问存储器时,存储周期=机器周期,此时机器周期=主频周期×2(一个机器周期由两个时钟脉冲组成)=2/25MHz=0.08μS指令周期=2×机器周期=0.16μS机器平均速度=1/0.16=6.25MIPS(百万条指令/秒)⑵若每两个机器周期中有一个是访问存储器周期,则需插入两个时钟的等待时间.指令周期=0.16μS+0.08μS=0.24μS机器平均速度=1/0.24≈4.2MIPS(百万条指令/秒)。