《计量经济学》第三版例题stata解答
- 格式:docx
- 大小:1.10 MB
- 文档页数:22

实验一P42第二章第6题=+GDP+Dependent Variable: YMethod: Least SquaresDate: 01/11/08 Time: 09:03Sample: 1985 1998Included observations: 14Variable Coefficient Std.Errort-Statistic Prob.C12596.271244.56710.121010.0000GDP26.954154.1203006.5417920.0000 R-squared0.781002 Meandependent var20168.57Adjusted R-squared 0.762752 S.D. dependentvar3512.487S.E. of regression 1710.865 Akaike infocriterion17.85895Sum squared resid 35124719 Schwarzcriterion17.95024Log likelihood-123.0126 F-statistic42.79505Durbin-Watsonstat0.859998 Prob(F-statistic)0.000028(10.1) ( 6.5), =0.78 =0.76(一)对回归方程的结构分析:是这个样本回归方程的斜率,它表示GDP每增加1亿元,某市将增加26.95的货物运输量;是样本回归方程的截距,它表示不受GDP影响的某市的货物运输量。
(二)统计检验=0.78,说明总离差平方和的78%被样本回归直线解释,有22%未被解释,因此,样本回归直线的拟合优度是可以的。
给出显著水平,查自由度v=14-2=12的t分布表,得临界值,,,固回归系数均显著不为零,回归模型中应包含常数项,GDP对Y有显著影响。
(三)预测2000年的某市货物运输量假如2000年某市以1980年不变价的国内生产总值为620亿元,得到2000年货物运输量的预测值29307.84万吨。


第一章 绪论(一)基本知识类题型1-1. 什么是计量经济学?1-2. 简述当代计量经济学发展的动向。
1-3. 计量经济学方法与一般经济数学方法有什么区别?1-4.为什么说计量经济学是经济理论、数学和经济统计学的结合?试述三者之关系。
1-5.为什么说计量经济学是一门经济学科?它在经济学科体系中的作用和地位是什么? 1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-8.建立计量经济学模型的基本思想是什么?1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么?1-10.试分别举出五个时间序列数据和横截面数据,并说明时间序列数据和横截面数据有和异同?1-11.试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1-12.模型的检验包括几个方面?其具体含义是什么?1-13.常用的样本数据有哪些?1-14.计量经济模型中为何要包括随机误差项?简述随机误差项形成的原因。
1-15.估计量和估计值有何区别?哪些类型的关系式不存在估计问题?1-16.经济数据在计量经济分析中的作用是什么?1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ S R t t =+1120012.. 其中S t 为第t 年农村居民储蓄增加额(亿元)、R t 为第t 年城镇居民可支配收入总额(亿元)。
⑵ S R t t -=+144320030.. 其中S t -1为第(1-t )年底农村居民储蓄余额(亿元)、R t 为第t 年农村居民纯收入总额(亿元)。
1-18.指出下列假想模型中的错误,并说明理由:(1)RS RI IV t t t =-+83000024112...其中,RS t 为第t 年社会消费品零售总额(亿元),RI t 为第t 年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t 为第t 年全社会固定资产投资总额(亿元)。

计量经济学第三版版课后答案全第⼆章(1)①对于浙江省预算收⼊与全省⽣产总值的模型,⽤Eviews分析结果如下:Dependent Variable: YMethod: Least SquaresDate: 12/03/14 Time: 17:00Sample (adjusted): 1 33Included observations: 33 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.??XCR-squaredMean dependent var Adjusted R-squared. dependent var. of regression Akaike info criterionSum squared residSchwarz criterionLog likelihood Hannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)②由上可知,模型的参数:斜率系数,截距为—③关于浙江省财政预算收⼊与全省⽣产总值的模型,检验模型的显着性:1)可决系数为,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t检验:t(β2)=>(31)=,对斜率系数的显着性检验表明,全省⽣产总值对财政预算总收⼊有显着影响。
④⽤规范形式写出检验结果如下:Y=—t= ()R2= F= n=33⑤经济意义是:全省⽣产总值每增加1亿元,财政预算总收⼊增加亿元。
(2)当x=32000时,①进⾏点预测,由上可知Y=—,代⼊可得:Y= Y=*32000—=②进⾏区间预测:∑x 2=∑(X i —X )2=δ2x (n —1)= ? x (33—1)= (X f —X)2=(32000—?2当Xf=32000时,将相关数据代⼊计算得到:即Yf 的置信区间为(—, +)(3) 对于浙江省预算收⼊对数与全省⽣产总值对数的模型,由Eviews 分析结果如下:Dependent Variable: LNYMethod: Least SquaresDate: 12/03/14 Time: 18:00Sample (adjusted): 1 33Included observations: 33 after adjustmentsVariable Coefficien t Std. Error t-Statistic Prob.?? LNXCR-squared Mean dependent var Adjusted R-squared . dependent var. of regression Akaike infocriterion Sum squared resid Schwarz criterionLog likelihood Hannan-Quinncriter. F-statistic Durbin-Watson statProb(F-statistic)①模型⽅程为:lnY=由上可知,模型的参数:斜率系数为,截距为③关于浙江省财政预算收⼊与全省⽣产总值的模型,检验其显着性: 1)可决系数为,说明所建模型整体上对样本数据拟合较好。
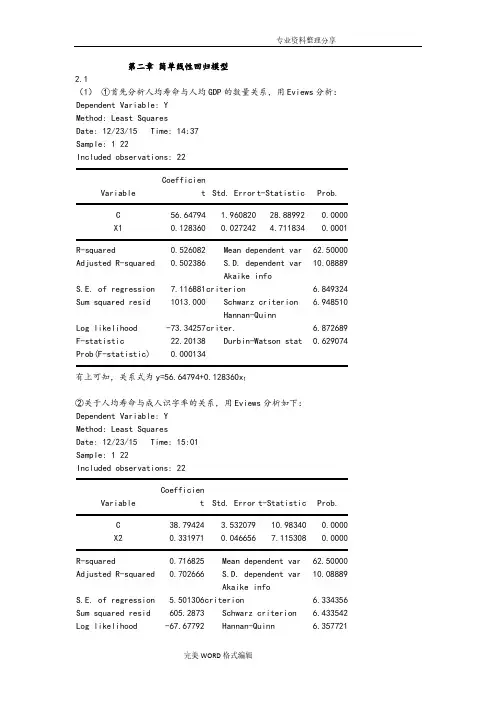
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 14:37Sample: 1 22Included observations: 22Variable Coefficient Std. Errort-Statistic Prob.C56.64794 1.96082028.889920.0000X10.1283600.027242 4.7118340.0001R-squared0.526082 Mean dependent var62.50000 Adjusted R-squared0.502386 S.D. dependent var10.08889S.E. of regression7.116881 Akaike infocriterion 6.849324Sum squared resid1013.000 Schwarz criterion 6.948510Log likelihood-73.34257 Hannan-Quinncriter. 6.872689F-statistic22.20138 Durbin-Watson stat0.629074 Prob(F-statistic)0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 15:01Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C38.79424 3.53207910.983400.0000X20.3319710.0466567.1153080.0000R-squared0.716825 Mean dependent var62.50000 Adjusted R-squared0.702666 S.D. dependent var10.08889S.E. of regression 5.501306 Akaike infocriterion 6.334356Sum squared resid605.2873 Schwarz criterion 6.433542 Log likelihood-67.67792 Hannan-Quinn 6.357721criter.F-statistic50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic)0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/14 Time: 15:20Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C31.79956 6.536434 4.8649710.0001X30.3872760.080260 4.8252850.0001R-squared0.537929 Mean dependent var62.50000 Adjusted R-squared0.514825 S.D. dependent var10.08889S.E. of regression7.027364 Akaike infocriterion 6.824009Sum squared resid987.6770 Schwarz criterion 6.923194Log likelihood-73.06409 Hannan-Quinncriter. 6.847374F-statistic23.28338 Durbin-Watson stat0.952555Prob(F-statistic)0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
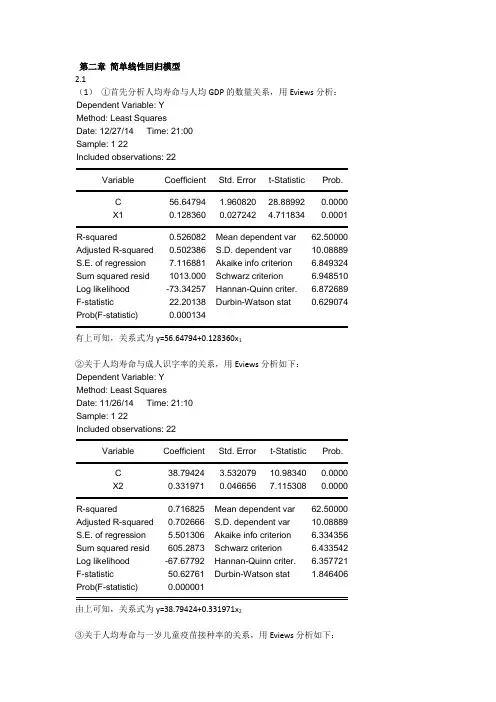
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。

第二章例2.1.1(p24)(1)表2.1.2中E(Y|X=800)即条件均值的求法,将数据直接复制到stata 中。
程序: sum y if x==800程序:程序:(2)图2.1.1的做法:程序:twoway(scatter y x )(lfit y x ),title("不同可支配收入水平组家庭消费支出的条件分布图")xtitle("每月可支配收入(元)")ytitle("每月消费支出(元)")xtick(500(500)4000)ytick(0(500)3500)例2.3.1(p37)将数据直接复制到stata 中程序:(1)total xiyireturn listscalars:r(skip) = 0r(first) = 1r(k_term) = 0r(k_operator) = 0r(k) = 0r(k_level) = 0r(output) = 1r(b) = 4974750r(se) = 1507820.761894463g a=r(b) in 1 total xi2 xiyi 4974750 1507821 1563822 8385678Total Std. Err. [95% Conf. Interval]Scatter 表示散点图选项,lfit 表示回归线,title 表示题目,xtick 表示刻度,(500(500)4000)分别表示起始刻度,中间数表示以单位刻度,4000表示最后的刻度。
要注意的是命令中的符号都要用英文字符,否则命令无效。
这个图可以直接复制的,但是由于我的软件出问题,只能直接剪切,所以影响清晰度。
return listg b=r(b) in 1di a/b.67(2)mean Yigen m=r(b) in 1mean Xig n=r(b) in 1di m-n*0.67142.4由此得到回归方程:Y=142.4+0.67Xi例2.6.2(p53)程序:(1)回归reg y x(2)求X的样本均值和样本方差:mean xMean estimation Number of obs = 31 Mean Std. Err. [95% Conf. Interval] x 11363.69 591.7041 10155.27 12572.11sum x ,d(d表示detail的省略,这个命令会产生更多的信息)xPercentiles Smallest1% 8871.27 8871.275% 8920.59 8920.5910% 9000.35 8941.08 Obs 3125% 9267.7 9000.35 Sum of Wgt. 3150% 9898.75 Mean 11363.69Largest Std. Dev. 3294.46975% 12192.24 16015.5890% 16015.58 18265.1 Variance 1.09e+0795% 19977.52 19977.52 Skewness 1.69197399% 20667.91 20667.91 Kurtosis 4.739267di r(Var)(特别注意Var的大小写)10853528例2.6.2(P56)(1)reg Y XSource SS df MS Number of obs = 29F( 1, 27) = 2214.60Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000Residual 30259023.9 27 1120704.59 R-squared = 0.9880Adj R-squared = 0.9875 Total2.5122e*************.8RootMSE=1058.6Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033_cons 2091.295 334.987 6.24 0.000 1403.959 2778.632(2)图2.6.1的绘制:twoway (line Y X year),title("中国居民可支配总收入X与消费总支出Y 的变动图")第三章例3.2.2(p72)reg Y X1 X2Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383例3.5.1(p85)g lnP1=ln(P1)g lnP0=ln(P0)g lnQ=ln(Q)g lnX=ln(X)Source SS df MS Number of obs = 22 F( 3, 18) = 258.84 Model .765670868 3 .255223623 Prob > F = 0.0000 Residual .017748183 18 .00098601 R-squared = 0.9773 Adj R-squared = 0.9736 Total .783419051 21 .037305669 Root MSE = .0314 lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .5399167 .0365299 14.78 0.000 .4631703 .6166631 lnP1 -.2580119 .1781856 -1.45 0.165 -.632366 .1163422 lnP0 -.2885609 .2051844 -1.41 0.177 -.7196373 .1425155 _cons 5.53195 .0931071 59.41 0.000 5.336339 5.727561 drop lnX lnP1 lnP0g lnXP0=ln(X/P0)g lnP1P0=ln(P1/P0)reg lnQ lnXP0 lnP1P0Source SS df MS Number of obs = 22F( 2, 19) = 408.93Model .765632331 2 .382816165 Prob > F = 0.0000Residual .01778672 19 .000936143 R-squared = 0.9773Adj R-squared = 0.9749Total .783419051 21 .037305669 Root MSE = .0306lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnXP0 .5344394 .0231984 23.04 0.000 .4858846 .5829942lnP1P0 -.2753473 .1511432 -1.82 0.084 -.5916936 .040999_cons 5.524569 .0831077 66.47 0.000 5.350622 5.698515练习题13(p105)g lnY=ln(Y)g lnK=ln(K)g lnL=ln(L)reg lnY lnK lnLSource SS df MS Number of obs = 31 F( 2, 28) = 59.66 Model 21.6049266 2 10.8024633 Prob > F = 0.0000 Residual 5.07030244 28 .18108223 R-squared = 0.8099 Adj R-squared = 0.7963 Total 26.6752291 30 .889174303 Root MSE = .42554 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnK .6092356 .1763779 3.45 0.002 .2479419 .9705293 lnL .3607965 .2015915 1.79 0.084 -.0521449 .7737378 _cons 1.153994 .7276114 1.59 0.124 -.33645 2.644439第二问:test b_[lnk]+b_[lnl]==1第四章例4.1.4 (P116)(1)回归g lnY=ln(Y)g lnX1=ln(X1)g lnX2=ln(X2)reg lnY lnX1 lnX2Source SS df MS Number of obs = 31 F( 2, 28) = 49.60 Model 2.9609923 2 1.48049615 Prob > F = 0.0000 Residual .835744123 28 .029848004 R-squared = 0.7799 Adj R-squared = 0.7642 Total 3.79673642 30 .126557881 Root MSE = .17277 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .1502137 .1085379 1.38 0.177 -.072116 .3725435 lnX2 .4774534 .0515951 9.25 0.000 .3717657 .5831412 _cons 3.266068 1.041591 3.14 0.004 1.132465 5.39967于是得到方程:lnY=3.266+0.1502lnX1+0.4775lnX2(2)绘制参差图:predict e, residg ei2=e^2scatter ei2 lnX2,title("图4.1.3 异方差性检验图")xtick(6(0.4)9.2)ytick(0(0.04)0.24)predict在回归结束后,需要对拟合值以及残差进行分析,需要使用此命令。

第2章 一元线性回归模型习 题3.简答题、分析与计算题(12)表1数据是从某个行业的5个不同的工厂收集的,请回答以下问题:①估计这个行业的线性总成本函数: tt x b b y 10ˆˆˆ+= ②0ˆb 和1ˆb 的经济含义是什么? ③估计产量为10时的总成本。
表1 某行业成本与产量数据(13)有10户家庭的收入(x ,百元)与消费(y ,百元)的资料如表2。
表2 家庭的收入与消费的资料要求:①建立消费(y )对收入(x )的回归直线。
②说明回归直线的代表性及解释能力。
③在95%的置信度下检验参数的显著性。
④在95%的置信度下,预测当x =45(百元)时,消费(y )的可能区间 (14)假设某国的货币供给量(y )与国民收入(x )的历史数据如表3所示:表3 货币供给量(y )与国民收入(x )数据请回答以下问题:①作出散点图,然后估计货币供给量y 对国民收入x 的回归方程,并把加归直线画在散点图上。
②如何解释回归系数的含义?③如果希望1997年国民收入达到15.0,那么应该把货币供应量定在什么水平上? (15)我国1978-2011年的财政收入y 和国内生产总值x 的数据资料如表4所示。
《计量经济学》(第3版)习题数据表4 我国1978-2011年中国财政收入和国内生产总值数据试根据资料完成下列问题:①建立财政收入对国内生产总值的一元线性回归方程,并解释回归系数的经济意义;②求置信度为95%的回归系数的置信区间;③对所建立的回归方程进行检验(包括经济意义检验、估计标准误差评价、拟合优度检验、参数的显著性检验);④若2012年国内生产总值为117253.52亿元,求2002年财政收入预测值及预测区间(05.0=α)。
(16)表5是1960-1981年间新加坡每千人电话数y 与按要素成本x 计算的新加坡元人均国内生产总值。
这两个变量之间有何关系?你怎样得出这样的结论?表5 1960-1981年新加坡每千人电话数与人均国内生产总值《计量经济学》(第3版)习题数据第3章 多元线性回归模型习 题3.简答题、分析与计算题(12)表1给出某地区职工平均消费水平t y ,职工平均收入t x 1和生活费用价格指数t x 2,试根据模型:t t t t u x b x b b y +++=22110作回归分析。

ÿÿÿÿÿ************************************************************************* *****************************************************************************ÿÿÿÿÿÿÿÿÿÿÿÿ第一章绪论(一)基本知识类题型1-1.什么是计量经济学1-3.计量经济学方法与一般经济数学方法有什么区别它在经济学科体系中的作用和地位是什么1-6.计量经济学的研究的对象和内容是什么计量经济学模型研究的经济关系有哪两个基本特征1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-9.计量经济学模型主要有哪些应用领域各自的原理是什么1-12.模型的检验包括几个方面其具体含义是什么1-17.下列假想模型是否属于揭示因果关系的计量经济学模型为什么⑴ S t其中S t为第t年农村居民储蓄增加额(亿元)、R t为第t年城镇居民可支配收入总额(亿元)。
⑵ S t1其中S t1为第(t1)年底农村居民储蓄余额(亿元)、R t为第t年农村居民纯收入总额(亿元)。
1-18.指出下列假想模型中的错误,并说明理由:(1)RS t RI t其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t 年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额1(亿元)。
(2)C t 180其中,C、Y分别是城镇居民消费支出和可支配收入。
(3) ln Y t ln K t L t其中,Y、K、L分别是工业总产值、工业生产资金和职工人数。
1-19.下列假想的计量经济模型是否合理,为什么(1) GDP i GDP i其中, GDP i (i 1,2,3) 是第i产业的国内生产总值。

第一章绪论参考重点:计量经济学的一般建模过程第一章课后题〔1.4.5〕1.什么是计量经济学计量经济学方法与一般经济数学方法有什么区别答:计量经济学是经济学的一个分支学科,是以提醒经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的穿插学科。
计量经济学方法提醒经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法提醒经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。
4.建设与应用计量经济学模型的主要步骤有哪些答:建设与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
5.模型的检验包括几个方面其具体含义是什么答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。
在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经历和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建设的模型是否可以用于样本观测值以外的范围。
第二章经典单方程计量经济学模型:一元线性回归模型参考重点:1.相关分析与回归分析的概念、联系以及区别2.总体随机项与样本随机项的区别与联系3.为什么需要进展拟合优度检验4.如何缩小置信区间〔P46〕由上式可以看出〔1〕.增大样本容量。
样本容量变大,可使样本参数估计量的标准差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。
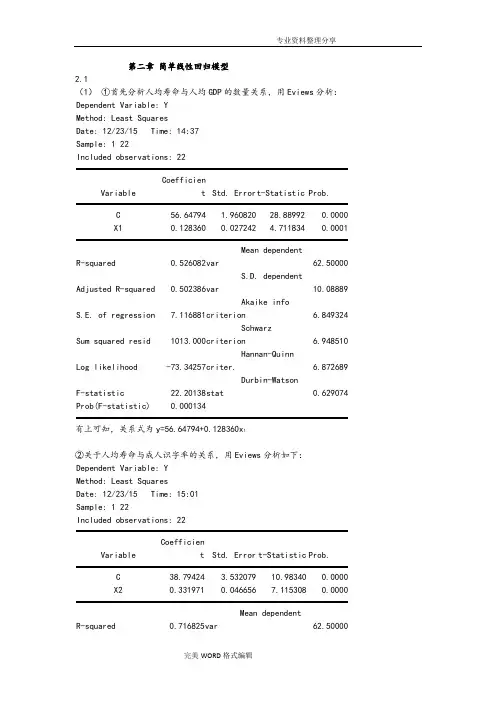
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 14:37Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependentvar 62.50000Adjusted R-squared 0.502386 S.D. dependentvar 10.08889S.E. of regression 7.116881 Akaike infocriterion 6.849324Sum squared resid 1013.000 Schwarzcriterion 6.948510Log likelihood -73.34257 Hannan-Quinncriter. 6.872689F-statistic 22.20138 Durbin-Watsonstat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/15 Time: 15:01Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependentvar 62.50000Adjusted R-squared 0.702666 S.D. dependentvar 10.08889S.E. of regression 5.501306 Akaike infocriterion 6.334356Sum squared resid 605.2873 Schwarzcriterion 6.433542Log likelihood -67.67792 Hannan-Quinncriter. 6.357721F-statistic 50.62761 Durbin-Watsonstat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 12/23/14 Time: 15:20Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001 X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependentvar 62.50000Adjusted R-squared 0.514825 S.D. dependentvar 10.08889S.E. of regression 7.027364 Akaike infocriterion 6.824009Sum squared resid 987.6770 Schwarzcriterion 6.923194Log likelihood -73.06409 Hannan-Quinncriter. 6.847374F-statistic 23.28338 Durbin-Watsonstat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
第六章1、答:给定显著水平α,依据样本容量n 和解释变量个数k’,查D.W.表得d 统计量的上界du 和下界dL ,当0<d<dL 时,表明存在一阶正自相关,而且正自相关的程度随d 向0的靠近而增强。
当dL<d<du 时,表明为不能确定存在自相关。
当du<d<4-du 时,表明不存在一阶自相关。
当4-du<d<4-dL 时,表明不能确定存在自相关。
当4-dL<d<4时,表明存在一阶负自相关,而且负自相关的程度随d 向4的靠近而增强。
前提条件:DW 检验的前提条件:(1)回归模型中含有截距项;(2)解释变量是非随机的(因此与随机扰动项不相关)(3)随机扰动项是一阶线性自相关。
;(4)回归模型中不把滞后内生变量(前定内生变量)做为解释变量。
(5)没有缺失数据,样本比较大。
DW 检验的局限性:(1)DW 检验有两个不能确定的区域,一旦DW 值落在这两个区域,就无法判断。
这时,只有增大样本容量或选取其他方法(2)DW 统计量的上、下界表要求n ≥15, 这是因为样本如果再小,利用残差就很难对自相关的存在性做出比较正确的诊断(3) DW 检验不适应随机误差项具有高阶序列相关的检验.(4) 只适用于有常数项的回归模型并且解释变量中不能含滞后的被解释变量2、答:(1)当回归模型随机误差项有自相关时,普通最小二乘估计量是有偏误的和非有效的。
判断:错误。
当回归模型随机误差项有自相关时,普通最小二乘估计量是无偏误的和非有效的。
(2)DW 检验假定随机误差项u i 的方差是同方差。
判断:错误。
DW 统计量的构造中并没有要求误差项的方差是同方差 。
(3)用一阶差分法消除自相关是假定自相关系数为-1。
判断:错误。
用一阶差分法消除自相关是假定自相关系数为1,即原原模型存在完全一阶正自相关。
(4)当回归模型随机误差项有自相关时,普通最小二乘估计的预测值的方差和标准误差不再是有效的。
第二章例.1(p24)(1)表中E(Y|X=800)即条件均值的求法,将数据直接复制到stata中。
程序:sum y if x==800程序:sum y if x==1100程序:sum y if x==1400(2)图的做法:程序:twoway(scatter y x )(lfit y x ),title("不同可支配收入水平组家庭消费支出的条件散布图")xtitle("每一个月可支配收入(元)")ytitle("每一个月消费支出(元)")xtick(500(500)4000)ytick(0(500)3500)例.1(p37)将数据直接复制到stata 中程序:(1)total xiyireturn listscalars:r(skip) = 0 xiyi 4974750 1507821 1563822 8385678Total Std. Err. [95% Conf. Interval]Scatter 表示散点图选项,lfit 表示回归线,title表示题目,xtick 表示刻度,(500(500)4000)分别表示起始刻度,中间数表示以单位刻度,4000表示最后的刻度。
r(first) = 1r(k_term) = 0r(k_operator) = 0r(k) = 0r(k_level) = 0r(output) = 1r(b) = 4974750r(se) =g a=r(b) in 1total xi2return listg b=r(b) in 1di a/b.67(2)mean Yigen m=r(b) in 1mean Xig n=r(b) in 1di m-n*由此取得回归方程:Y=+例.2(p53)程序:(1)回归reg y x(2)求X的样本均值和样本方差:mean xMean estimation Number of obs = 31 Mean Std. Err. [95% Conf. Interval] x 11363.69 591.7041 10155.27 12572.11 sum x ,d(d表示detail的省略,那个命令会产生更多的信息)xPercentiles Smallest1% 8871.27 8871.275% 8920.59 8920.5910% 9000.35 8941.08 Obs 3125% 9267.7 9000.35 Sum of Wgt. 3150% 9898.75 Mean 11363.69Largest Std. Dev. 3294.46975% 12192.24 16015.5890% 16015.58 18265.1 Variance 1.09e+0795% 19977.52 19977.52 Skewness 1.69197399% 20667.91 20667.91 Kurtosis 4.739267di r(Var)(专门注意Var的大小写)例(P56)(1)reg Y XSource SS df MS Number of obs = 29 F( 1, 27) = 2214.60 Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000 Residual 30259023.9 27 1120704.59 R-squared = 0.9880 Adj R-squared = 0.9875 Total 2.5122e+09 28 89720219.8 Root MSE = 1058.6 Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033 _cons 2091.295 334.987 6.24 0.000 1403.959 2778.632(2)图的绘制:twoway (line Y X year),title("中国居民可支配总收入X与消费总支出Y 的变更图")第三章例(p72)reg Y X1 X2Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383例.1(p85)g lnP1=ln(P1)g lnP0=ln(P0)g lnQ=ln(Q)g lnX=ln(X)Source SS df MS Number of obs = 22 F( 3, 18) = 258.84 Model .765670868 3 .255223623 Prob > F = 0.0000 Residual .017748183 18 .00098601 R-squared = 0.9773 Adj R-squared = 0.9736 Total .783419051 21 .037305669 Root MSE = .0314 lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .5399167 .0365299 14.78 0.000 .4631703 .6166631 lnP1 -.2580119 .1781856 -1.45 0.165 -.632366 .1163422 lnP0 -.2885609 .2051844 -1.41 0.177 -.7196373 .1425155 _cons 5.53195 .0931071 59.41 0.000 5.336339 5.727561 drop lnX lnP1 lnP0g lnXP0=ln(X/P0)g lnP1P0=ln(P1/P0)reg lnQ lnXP0 lnP1P0Source SS df MS Number of obs = 22F( 2, 19) = 408.93Model .765632331 2 .382816165 Prob > F = 0.0000Residual .01778672 19 .000936143 R-squared = 0.9773Adj R-squared = 0.9749Total .783419051 21 .037305669 Root MSE = .0306lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnXP0 .5344394 .0231984 23.04 0.000 .4858846 .5829942lnP1P0 -.2753473 .1511432 -1.82 0.084 -.5916936 .040999_cons 5.524569 .0831077 66.47 0.000 5.350622 5.698515练习题13(p105)g lnY=ln(Y)g lnK=ln(K)g lnL=ln(L)reg lnY lnK lnLSource SS df MS Number of obs = 31 F( 2, 28) = 59.66 Model 21.6049266 2 10.8024633 Prob > F = 0.0000 Residual 5.07030244 28 .18108223 R-squared = 0.8099 Adj R-squared = 0.7963 Total 26.6752291 30 .889174303 Root MSE = .42554 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnK .6092356 .1763779 3.45 0.002 .2479419 .9705293 lnL .3607965 .2015915 1.79 0.084 -.0521449 .7737378 _cons 1.153994 .7276114 1.59 0.124 -.33645 2.644439第二问:test b_[lnk]+b_[lnl]==1第四章例.4 (P116)(1)回归g lnY=ln(Y)g lnX1=ln(X1)g lnX2=ln(X2)reg lnY lnX1 lnX2Source SS df MS Number of obs = 31 F( 2, 28) = 49.60 Model 2.9609923 2 1.48049615 Prob > F = 0.0000 Residual .835744123 28 .029848004 R-squared = 0.7799 Adj R-squared = 0.7642 Total 3.79673642 30 .126557881 Root MSE = .17277 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .1502137 .1085379 1.38 0.177 -.072116 .3725435 lnX2 .4774534 .0515951 9.25 0.000 .3717657 .5831412 _cons 3.266068 1.041591 3.14 0.004 1.132465 5.39967于是取得方程:lnY=++(2)绘制参差图:predict e, residg ei2=e^2scatter ei2 lnX2,title("图异方差性查验图")xtick(6ytick(0predict在回归结束后,需要对拟合值以及残差进行分析,需要使用(3)G-Q查验sort X2drop in 13 /19reg lnY lnX1 lnX2 in 1/12Source SS df MS Number of obs = 12F( 2, 9) = 12.79Model .19947228 2 .09973614 Prob > F = 0.0023Residual .070196863 9 .007799651 R-squared = 0.7397Adj R-squared = 0.6818Total .269669142 11 .024515377 Root MSE = .08832lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .3983847 .0787908 5.06 0.001 .2201475 .5766219lnX2 .2347508 .1097475 2.14 0.061 -.0135153 .4830169_cons 3.141209 1.122358 2.80 0.021 .6022575 5.68016reg lnY lnX1 lnX2 in 13/24Source SS df MS Number of obs = 12 F( 2, 9) = 32.06 Model 1.36238223 2 .681191114 Prob > F = 0.0001 Residual .191197445 9 .021244161 R-squared = 0.8769 Adj R-squared = 0.8496 Total 1.55357967 11 .141234516 Root MSE = .14575 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 -.113766 .1599622 -0.71 0.495 -.4756257 .2480937 lnX2 .6201685 .1116539 5.55 0.000 .3675898 .8727472 _cons 3.993643 1.884053 2.12 0.063 -.2683811 8.255668 di F=(能够用字母替代)2..7222222(4)怀特查验(从头把原始数据出入)reg lnY lnX1 lnX2predict e ,residg e2=e^2g lnX12=(lnX1)^2g lnX22=(lnX2)^2g lnX1X2=lnX1*lnX2reg e2 lnX1 lnX2 lnX12 lnX22 lnX1X2Source SS df MS Number of obs = 31F( 5, 25) = 9.83Model .035298411 5 .007059682 Prob > F = 0.0000Residual .017947599 25 .000717904 R-squared = 0.6629Adj R-squared = 0.5955Total .05324601 30 .001774867 Root MSE = .02679e2 Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 -2.32907 1.116442 -2.09 0.047 -4.628426 -.0297138lnX2 -.4573069 .4540203 -1.01 0.323 -1.392379 .4777655lnX12 .1491144 .0581072 2.57 0.017 .0294404 .2687884lnX22 .0211007 .0133574 1.58 0.127 -.0064095 .0486109lnX1X2 .0193327 .0412645 0.47 0.643 -.0656532 .1043186_cons 10.24328 5.474522 1.87 0.073 -1.031707 21.51827reg e2 lnX1 lnX2 lnX12 lnX22Source SS df MS Number of obs = 31 F( 4, 26) = 12.62 Model .035140831 4 .008785208 Prob > F = 0.0000 Residual .018105178 26 .000696353 R-squared = 0.6600 Adj R-squared = 0.6077 Total .05324601 30 .001774867 Root MSE = .02639 e2 Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 -1.851123 .4467273 -4.14 0.000 -2.769384 -.932862 lnX2 -.2581661 .1571598 -1.64 0.112 -.5812127 .0648806 lnX12 .1261597 .0307668 4.10 0.000 .0629176 .1894018 lnX22 .0172142 .0103109 1.67 0.107 -.0039802 .0384085 _cons 7.763275 1.375323 5.64 0.000 4.936257 10.59029 g lne2= ln(e2)reg lne2 lnX2 lnX22Source SS df MS Number of obs = 31F( 2, 28) = 3.55Model 29.2575216 2 14.6287608 Prob > F = 0.0423Residual 115.374726 28 4.12052593 R-squared = 0.2023Adj R-squared = 0.1453Total 144.632248 30 4.82107492 Root MSE = 2.0299lne2 Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX2 -25.97629 9.860002 -2.63 0.014 -46.17359 -5.778992lnX22 1.701071 .6414051 2.65 0.013 .3872121 3.01493_cons 93.19585 37.65529 2.47 0.020 16.06249 170.3292. predict m ,xb(和书上直接以差残作为权数是有区别的,理论上不能能以残差直接作为权数). predictnl n=exp(xb()). g wi=sqrt(n). vwls lnX1 lnX2,sd(wi)Variance-weighted least-squares regression Number of obs = 31 Goodness-of-fit chi2(28) = 73.28 Model chi2(2) = 263.97 Prob > chi2 = 0.0000 Prob > chi2 = 0.0000lnY Coef. Std. Err. z P>|z| [95% Conf. Interval]lnX1 .3177322 .0514579 6.17 0.000 .2168765 .4185879 lnX2 .428669 .0275805 15.54 0.000 .3746122 .4827257 _cons 2.338164 .4472981 5.23 0.000 1.461476 3.214852例(教师有标准答案)reg Y XSource SS df MS Number of obs = 29F( 1, 27) = 2214.60Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000Residual 30259023.9 27 1120704.59 R-squared = 0.9880Adj R-squared = 0.9875Total 2.5122e+09 28 89720219.8 Root MSE = 1058.6Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033_cons 2091.295 334.987 6.24 0.000 1403.959 2778.632predict e,residtsset yeartime variable: year, 1978 to 2006delta: 1 unitline e year,title("残差相关图")xtick(1978(5)2006)ytick(-3000(1000)3000)scatter e e1,title("残差相关图")xtick(-2000(1000)3000)ytick(-3000(1000)3000)g T=_ng T2=T^2Source SS df MS Number of obs = 29 F( 2, 26) = 5380.77 Model 2.5061e+09 2 1.2531e+09 Prob > F = 0.0000 Residual 6054792.7 26 232876.642 R-squared = 0.9976 Adj R-squared = 0.9974 Total 2.5122e+09 28 89720219.8 Root MSE = 482.57 Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .1761519 .0259858 6.78 0.000 .1227374 .2295664 T2 21.65582 2.124183 10.19 0.000 17.2895 26.02215 _cons 3328.191 195.0326 17.06 0.000 2927.296 3729.086 reg Y X T2reg e X T2 e1Source SS df MS Number of obs = 28 F( 3, 24) = 64.94 Model 25597419.6 3 8532473.19 Prob > F = 0.0000 Residual 3153351.72 24 131389.655 R-squared = 0.8903 Adj R-squared = 0.8766 Total 28750771.3 27 1064843.38 Root MSE = 362.48 e Coef. Std. Err. t P>|t| [95% Conf. Interval]X -.1435191 .0335797 -4.27 0.000 -.2128242 -.074214 T2 11.04582 2.915754 3.79 0.001 5.028004 17.06365 e1 .6186482 .1467037 4.22 0.000 .3158666 .9214297 _cons 910.3409 172.739 5.27 0.000 553.8251 1266.857 g e2=e[_n-1]reg e X T2 e1 e2Source SS df MS Number of obs = 28F( 4, 23) = 46.69Model 25598535.3 4 6399633.84 Prob > F = 0.0000Residual 3152235.94 23 137053.737 R-squared = 0.8904Adj R-squared = 0.8713Total 28750771.3 27 1064843.38 Root MSE = 370.21e Coef. Std. Err. t P>|t| [95% Conf. Interval]X -.1421776 .0373799 -3.80 0.001 -.2195039 -.0648513T2 10.80845 3.973581 2.72 0.012 2.58847 19.02843e1 .6192203 .1499666 4.13 0.000 .3089908 .9294498e2 4.183503 46.36562 0.09 0.929 -91.73108 100.0981_cons 886.1107 321.3096 2.76 0.011 221.4311 1550.79prais Y X T2,rhotype(orrc)Prais-Winsten AR(1) regression -- iterated estimatesSource SS df MS Number of obs = 29F( 2, 26) = 1153.30Model 215943215 2 107971607 Prob > F = 0.0000Residual 2434113.93 26 93619.7664 R-squared = 0.9889Adj R-squared = 0.9880Total 218377329 28 7799190.31 Root MSE = 305.97Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .1896298 .0292979 6.47 0.000 .1294071 .2498524T2 20.79527 2.693162 7.72 0.000 15.25939 26.33114_cons 3118.169 329.4324 9.47 0.000 2441.011 3795.327rho .764553Durbin-Watson statistic (original) 0.442033Durbin-Watson statistic (transformed) 1.361658newey lnY lnX, lag(2)例(P140)g lnX1=ln(X1)g lnX2=ln(X2)g lnX3=ln(X3)g lnX4=ln(X4)g lnX5=ln(X5)g lnY=ln(Y)reg lnY lnX1 lnX2 lnX3 lnX4 lnX5Source SS df MS Number of obs = 25 F( 5, 19) = 202.68 Model .205495866 5 .041099173 Prob > F = 0.0000 Residual .003852744 19 .000202776 R-squared = 0.9816 Adj R-squared = 0.9768 Total .209348611 24 .008722859 Root MSE = .01424 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .3811446 .050242 7.59 0.000 .275987 .4863022 lnX2 1.222289 .1351786 9.04 0.000 .9393566 1.505221 lnX3 -.0811099 .0153037 -5.30 0.000 -.1131409 -.0490789 lnX4 -.0472287 .0447674 -1.05 0.305 -.1409279 .0464705 lnX5 -.1011737 .0576866 -1.75 0.096 -.2219131 .0195656 _cons -4.173174 1.923624 -2.17 0.043 -8.199365 -.1469838 corr lnX1 lnX2 lnX3 lnX4 lnX5lnX1 lnX2 lnX3 lnX4 lnX5lnX1 1.0000lnX2 -0.5687 1.0000lnX3 0.4517 -0.2141 1.0000lnX4 0.9644 -0.6976 0.3988 1.0000lnX5 0.4402 -0.0733 0.4113 0.2795 1.0000 stepwise, pr : reg Y X1 X2 X3 X4 X5或stepwise, pe : reg Y X1 X2 X3 X4 X5(慢慢向前回归和慢慢向后回归)reg lnY lnX1 lnX2 lnX3Source SS df MS Number of obs = 25 F( 3, 21) = 320.34 Model .204871849 3 .068290616 Prob > F = 0.0000 Residual .004476761 21 .000213179 R-squared = 0.9786 Adj R-squared = 0.9756 Total .209348611 24 .008722859 Root MSE = .0146 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .3233849 .0108608 29.78 0.000 .3007987 .3459711 lnX2 1.290729 .0961534 13.42 0.000 1.090767 1.490691 lnX3 -.0867539 .0151549 -5.72 0.000 -.1182702 -.0552376 _cons -5.999638 1.162078 -5.16 0.000 -8.416312 -3.582964例.1(P151)reg X1 X2 ZSource SS df MS Number of obs = 31 F( 2, 28) = 1947.55 Model 323280649 2 161640324 Prob > F = 0.0000 Residual 2323912.12 28 82996.8616 R-squared = 0.9929 Adj R-squared = 0.9924 Total 325604561 30 10853485.4 Root MSE = 288.09 X1 Coef. Std. Err. t P>|t| [95% Conf. Interval]X2 -.470904 .1154633 -4.08 0.000 -.7074199 -.2343881 Z 1.460539 .0860022 16.98 0.000 1.284372 1.636707 _cons 132.7416 194.2843 0.68 0.500 -265.2317 530.7149 predict v,residreg Y X1 X2 vSource SS df MS Number of obs = 31F( 3, 27) = 1313.48Model 169977392 3 56659130.6 Prob > F = 0.0000Residual 1164688.99 27 43136.6292 R-squared = 0.9932Adj R-squared = 0.9924Total 171142081 30 5704736.02 Root MSE = 207.69Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .4502363 .042451 10.61 0.000 .3631339 .5373386X2 .4025897 .0638268 6.31 0.000 .2716278 .5335515v 1.191137 .1427031 8.35 0.000 .8983341 1.483939_cons 155.6975 140.1522 1.11 0.276 -131.871 443.266ivreg Y X2 (X1=Z)Instrumental variables (2SLS) regressionSource SS df MS Number of obs = 31F( 2, 28) = 513.69Model 166680210 2 83340105 Prob > F = 0.0000Residual 4461870.66 28 159352.524 R-squared = 0.9739Adj R-squared = 0.9721Total 171142081 30 5704736.02 Root MSE = 399.19Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .4502363 .0815915 5.52 0.000 .2831037 .6173688X2 .4025897 .122676 3.28 0.003 .1512992 .6538801_cons 155.6975 269.3743 0.58 0.568 -396.0907 707.4858reg Y X1 X2Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383第4章练习8(P154)(1)回归rename var1 Xrename var2 Yreg Y XSource SS df MS Number of obs = 20 F( 1, 18) = 1048.91 Model 49342144 1 49342144 Prob > F = 0.0000 Residual 846742.352 18 47041.2418 R-squared = 0.9831 Adj R-squared = 0.9822 Total 50188886.4 19 2641520.34 Root MSE = 216.89 Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .755125 .0233157 32.39 0.000 .7061404 .8041095 _cons 272.3635 159.6772 1.71 0.105 -63.1059 607.8329(2)异方差判定(4种方式)predict e,residg e2=e^2scatter e2 Xi通过观测散点图可知残差有明显的扩大趋势ii 通过怀特检验,原假设为同方imtest,whiteWhite's test for Ho: homoskedasticityagainst Ha: unrestricted heteroskedasticitychi2(2) = 12.65Prob > chi2 = 0.0018Cameron & Trivedi's decomposition of IM-testSource chi2 df pHeteroskedasticity 12.65 2 0.0018Skewness 5.16 1 0.0232Kurtosis 1.85 1 0.1733Total 19.66 4 0.0006(3)解决异方差predict e,residualsg e2=e^2reg le2 XSource SS df MS Number of obs = 20F( 1, 18) = 7.80Model 18.3174302 1 18.3174302 Prob > F = 0.0120Residual 42.2889689 18 2.34938716 R-squared = 0.3022Adj R-squared = 0.2635Total 60.6063991 19 3.18981048 Root MSE = 1.5328le2 Coef. Std. Err. t P>|t| [95% Conf. Interval]X .0004601 .0001648 2.79 0.012 .0001139 .0008063_cons 6.825132 1.128446 6.05 0.000 4.454355 9.19591predict m,xbpredictnl h=exp(xb())reg Y X [w=1/h]Source SS df MS Number of obs = 20F( 1, 18) = 428.83Model 11254461.3 1 11254461.3 Prob > F = 0.0000Residual 472402.755 18 26244.5975 R-squared = 0.9597Adj R-squared = 0.9575Total 11726864.1 19 617203.372 Root MSE = 162Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .7399551 .0357325 20.71 0.000 .664884 .8150263_cons 359.3844 197.876 1.82 0.086 -56.33756 775.1064练习题9(p155)g lnX=ln(X)g lnY=ln(Y)reg lnY lnXSource SS df MS Number of obs = 28 F( 1, 26) = 3610.88 Model 45.5793477 1 45.5793477 Prob > F = 0.0000 Residual .328192471 26 .012622787 R-squared = 0.9929 Adj R-squared = 0.9926 Total 45.9075401 27 1.70027926 Root MSE = .11235 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .8544154 .0142188 60.09 0.000 .8251883 .8836426 _cons 1.588478 .1342196 11.83 0.000 1.312586 1.86437判定相关性:(通过e-t或DW值)predict e ,residline e yearscatter etsset yeartime variable: year, 1980 to 2007delta: 1 unitestat dwatsonDurbin-Watson d-statistic( 2, 28) = .3793231说明有正自相关性。
2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
詹姆斯·斯托克,马克·沃森计量经济学第三章实证练习stata答案⼀、Two-sample t test with equal variancesGroup Obs Mean Std.Err. Std.Dev. 95% Conf. Interval1992 7,612 11.62 0.0644 5.619 11.49 11.742012 7,440 19.80 0.124 10.69 19.56 20.04combined 15,052 15.66 0.0770 9.442 15.51 15.81diff -8,183 0.139 -8.455 -7.911 diff = mean(1992) - mean(2012) t = -58.9871Ho: diff = 0 degrees of freedom = 15050Ha: diff < 0 Ha: diff != 0 Ha: diff > 0Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000⼆、Two-sample t test with equal variancesGroup Obs Mean Std.Err. Std.Dev. 95% Conf. Interval 1992 7,612 15.64 0.0867 7.564 15.47 15.81 2012 7,440 19.80 0.124 10.69 19.56 20.04 combined 15,052 17.69 0.0772 9.471 17.54 17.85 diff -4.164 0.151 -4.459 -3.869diff = mean(1992) - mean(2012) t = -27.6423Ho: diff = 0 degrees of freedom = 15050Ha: diff < 0 Ha: diff != 0 Ha: diff > 0Pr(T < t) = 0.0000 Pr(|T| > |t|) = 0.0000 Pr(T > t) = 1.0000三、第⼆题根据通货膨胀率进⾏了调整,反映了购买⼒的变化,所以可⽤利⽤第⼆题的结果进⾏分析。
第二章例2.1.1(p24)(1)表2.1.2中E(Y|X=800)即条件均值的求法,将数据直接复制到stata 中。
程序: sum y if x==800程序:程序:(2)图2.1.1的做法:程序:twoway(scatter y x )(lfit y x ),title("不同可支配收入水平组家庭消费支出的条件分布图")xtitle("每月可支配收入(元)")ytitle("每月消费支出(元)")xtick(500(500)4000)ytick(0(500)3500)例2.3.1(p37)将数据直接复制到stata 中程序:(1)total xiyireturn listscalars:r(skip) = 0r(first) = 1r(k_term) = 0r(k_operator) = 0r(k) = 0r(k_level) = 0r(output) = 1r(b) = 4974750r(se) = 1507820.761894463g a=r(b) in 1 total xi2 xiyi 4974750 1507821 1563822 8385678Total Std. Err. [95% Conf. Interval]Scatter 表示散点图选项,lfit 表示回归线,title 表示题目,xtick 表示刻度,(500(500)4000)分别表示起始刻度,中间数表示以单位刻度,4000表示最后的刻度。
要注意的是命令中的符号都要用英文字符,否则命令无效。
return listg b=r(b) in 1di a/b.67(2)mean Yigen m=r(b) in 1mean Xig n=r(b) in 1di m-n*0.67142.4由此得到回归方程:Y=142.4+0.67Xi例2.6.2(p53)程序:(1)回归reg y x(2)求X的样本均值和样本方差:mean xMean estimation Number of obs = 31 Mean Std. Err. [95% Conf. Interval] x 11363.69 591.7041 10155.27 12572.11sum x ,d(d表示detail的省略,这个命令会产生更多的信息)xPercentiles Smallest1% 8871.27 8871.275% 8920.59 8920.5910% 9000.35 8941.08 Obs 3125% 9267.7 9000.35 Sum of Wgt. 3150% 9898.75 Mean 11363.69Largest Std. Dev. 3294.46975% 12192.24 16015.5890% 16015.58 18265.1 Variance 1.09e+0795% 19977.52 19977.52 Skewness 1.69197399% 20667.91 20667.91 Kurtosis 4.739267di r(Var)(特别注意Var的大小写)10853528例2.6.2(P56)(1)reg Y XSource SS df MS Number of obs = 29F( 1, 27) = 2214.60Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000Residual 30259023.9 27 1120704.59 R-squared = 0.9880Adj R-squared = 0.9875 Total2.5122e*************.8RootMSE=1058.6Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033_cons 2091.295 334.987 6.24 0.000 1403.959 2778.632(2)图2.6.1的绘制:twoway (line Y X year),title("中国居民可支配总收入X与消费总支出Y 的变动图")第三章例3.2.2(p72)reg Y X1 X2Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383例3.5.1(p85)g lnP1=ln(P1)g lnP0=ln(P0)g lnQ=ln(Q)g lnX=ln(X)Source SS df MS Number of obs = 22 F( 3, 18) = 258.84 Model .765670868 3 .255223623 Prob > F = 0.0000 Residual .017748183 18 .00098601 R-squared = 0.9773 Adj R-squared = 0.9736 Total .783419051 21 .037305669 Root MSE = .0314 lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .5399167 .0365299 14.78 0.000 .4631703 .6166631 lnP1 -.2580119 .1781856 -1.45 0.165 -.632366 .1163422 lnP0 -.2885609 .2051844 -1.41 0.177 -.7196373 .1425155 _cons 5.53195 .0931071 59.41 0.000 5.336339 5.727561 drop lnX lnP1 lnP0g lnXP0=ln(X/P0)g lnP1P0=ln(P1/P0)reg lnQ lnXP0 lnP1P0Source SS df MS Number of obs = 22F( 2, 19) = 408.93Model .765632331 2 .382816165 Prob > F = 0.0000Residual .01778672 19 .000936143 R-squared = 0.9773Adj R-squared = 0.9749Total .783419051 21 .037305669 Root MSE = .0306lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnXP0 .5344394 .0231984 23.04 0.000 .4858846 .5829942lnP1P0 -.2753473 .1511432 -1.82 0.084 -.5916936 .040999_cons 5.524569 .0831077 66.47 0.000 5.350622 5.698515练习题13(p105)g lnY=ln(Y)g lnK=ln(K)g lnL=ln(L)reg lnY lnK lnLSource SS df MS Number of obs = 31 F( 2, 28) = 59.66 Model 21.6049266 2 10.8024633 Prob > F = 0.0000 Residual 5.07030244 28 .18108223 R-squared = 0.8099 Adj R-squared = 0.7963 Total 26.6752291 30 .889174303 Root MSE = .42554 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnK .6092356 .1763779 3.45 0.002 .2479419 .9705293 lnL .3607965 .2015915 1.79 0.084 -.0521449 .7737378 _cons 1.153994 .7276114 1.59 0.124 -.33645 2.644439第四章例4.1.4 (P116)(1)回归g lnY=ln(Y)g lnX1=ln(X1)g lnX2=ln(X2)reg lnY lnX1 lnX2Source SS df MS Number of obs = 31 F( 2, 28) = 49.60 Model 2.9609923 2 1.48049615 Prob > F = 0.0000 Residual .835744123 28 .029848004 R-squared = 0.7799 Adj R-squared = 0.7642 Total 3.79673642 30 .126557881 Root MSE = .17277 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .1502137 .1085379 1.38 0.177 -.072116 .3725435 lnX2 .4774534 .0515951 9.25 0.000 .3717657 .5831412 _cons 3.266068 1.041591 3.14 0.004 1.132465 5.39967于是得到方程:lnY=3.266+0.1502lnX1+0.4775lnX2(2)绘制参差图:predict e, residg ei2=e^2scatter ei2 lnX2,title("图4.1.3 异方差性检验图")xtick(6(0.4)9.2)ytick(0(0.04)0.24)predict在回归结束后,需要对拟合值以及残差进行分析,需要使用此命令。
第2章 一元线性回归模型习 题3.简答题、分析与计算题(12)表1数据是从某个行业的5个不同的工厂收集的,请回答以下问题:①估计这个行业的线性总成本函数: tt x b b y 10ˆˆˆ+= ②0ˆb 和1ˆb 的经济含义是什么? ③估计产量为10时的总成本。
表1 某行业成本与产量数据(13)有10户家庭的收入(x ,百元)与消费(y ,百元)的资料如表2。
表2 家庭的收入与消费的资料要求:①建立消费(y )对收入(x )的回归直线。
②说明回归直线的代表性及解释能力。
③在95%的置信度下检验参数的显著性。
④在95%的置信度下,预测当x =45(百元)时,消费(y )的可能区间 (14)假设某国的货币供给量(y )与国民收入(x )的历史数据如表3所示:表3 货币供给量(y )与国民收入(x )数据请回答以下问题:①作出散点图,然后估计货币供给量y 对国民收入x 的回归方程,并把加归直线画在散点图上。
②如何解释回归系数的含义?③如果希望1997年国民收入达到15.0,那么应该把货币供应量定在什么水平上? (15)我国1978-2011年的财政收入y 和国内生产总值x 的数据资料如表4所示。
表4 我国1978-2011年中国财政收入和国内生产总值数据试根据资料完成下列问题:①建立财政收入对国内生产总值的一元线性回归方程,并解释回归系数的经济意义;②求置信度为95%的回归系数的置信区间;③对所建立的回归方程进行检验(包括经济意义检验、估计标准误差评价、拟合优度检验、参数的显著性检验);④若2012年国内生产总值为117253.52亿元,求2002年财政收入预测值及预测区间(05.0=α)。
(16)表5是1960-1981年间新加坡每千人电话数y 与按要素成本x 计算的新加坡元人均国内生产总值。
这两个变量之间有何关系?你怎样得出这样的结论?表5 1960-1981年新加坡每千人电话数与人均国内生产总值第3章 多元线性回归模型习 题3.简答题、分析与计算题(12)表1给出某地区职工平均消费水平t y ,职工平均收入t x 1和生活费用价格指数t x 2,试根据模型:t t t t u x b x b b y +++=22110作回归分析。
第二章例2.1.1(p24)(1)表2.1.2中E(Y|X=800)即条件均值的求法,将数据直接复制到stata 中。
程序: sum y if x==800程序:程序:(2)图2.1.1的做法:程序:twoway(scatter y x )(lfit y x ),title("不同可支配收入水平组家庭消费支出的条件分布图")xtitle("每月可支配收入(元)")ytitle("每月消费支出(元)")xtick(500(500)4000)ytick(0(500)3500)例2.3.1(p37)将数据直接复制到stata 中程序:(1)total xiyireturn listscalars:r(skip) = 0r(first) = 1r(k_term) = 0r(k_operator) = 0r(k) = 0r(k_level) = 0r(output) = 1r(b) = 4974750r(se) = 1507820.761894463g a=r(b) in 1 total xi2 xiyi 4974750 1507821 1563822 8385678Total Std. Err. [95% Conf. Interval]Scatter 表示散点图选项,lfit 表示回归线,title 表示题目,xtick 表示刻度,(500(500)4000)分别表示起始刻度,中间数表示以单位刻度,4000表示最后的刻度。
要注意的是命令中的符号都要用英文字符,否则命令无效。
return listg b=r(b) in 1di a/b.67(2)mean Yigen m=r(b) in 1mean Xig n=r(b) in 1di m-n*0.67142.4由此得到回归方程:Y=142.4+0.67Xi例2.6.2(p53)程序:(1)回归reg y x(2)求X的样本均值和样本方差:mean xMean estimation Number of obs = 31 Mean Std. Err. [95% Conf. Interval] x 11363.69 591.7041 10155.27 12572.11sum x ,d(d表示detail的省略,这个命令会产生更多的信息)xPercentiles Smallest1% 8871.27 8871.275% 8920.59 8920.5910% 9000.35 8941.08 Obs 3125% 9267.7 9000.35 Sum of Wgt. 3150% 9898.75 Mean 11363.69Largest Std. Dev. 3294.46975% 12192.24 16015.5890% 16015.58 18265.1 Variance 1.09e+0795% 19977.52 19977.52 Skewness 1.69197399% 20667.91 20667.91 Kurtosis 4.739267di r(Var)(特别注意Var的大小写)10853528例2.6.2(P56)(1)reg Y XSource SS df MS Number of obs = 29F( 1, 27) = 2214.60Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000Residual 30259023.9 27 1120704.59 R-squared = 0.9880Adj R-squared = 0.9875 Total2.5122e*************.8RootMSE=1058.6Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033_cons 2091.295 334.987 6.24 0.000 1403.959 2778.632(2)图2.6.1的绘制:twoway (line Y X year),title("中国居民可支配总收入X与消费总支出Y 的变动图")第三章例3.2.2(p72)reg Y X1 X2Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383例3.5.1(p85)g lnP1=ln(P1)g lnP0=ln(P0)g lnQ=ln(Q)g lnX=ln(X)Source SS df MS Number of obs = 22 F( 3, 18) = 258.84 Model .765670868 3 .255223623 Prob > F = 0.0000 Residual .017748183 18 .00098601 R-squared = 0.9773 Adj R-squared = 0.9736 Total .783419051 21 .037305669 Root MSE = .0314 lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .5399167 .0365299 14.78 0.000 .4631703 .6166631 lnP1 -.2580119 .1781856 -1.45 0.165 -.632366 .1163422 lnP0 -.2885609 .2051844 -1.41 0.177 -.7196373 .1425155 _cons 5.53195 .0931071 59.41 0.000 5.336339 5.727561 drop lnX lnP1 lnP0g lnXP0=ln(X/P0)g lnP1P0=ln(P1/P0)reg lnQ lnXP0 lnP1P0Source SS df MS Number of obs = 22F( 2, 19) = 408.93Model .765632331 2 .382816165 Prob > F = 0.0000Residual .01778672 19 .000936143 R-squared = 0.9773Adj R-squared = 0.9749Total .783419051 21 .037305669 Root MSE = .0306lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnXP0 .5344394 .0231984 23.04 0.000 .4858846 .5829942lnP1P0 -.2753473 .1511432 -1.82 0.084 -.5916936 .040999_cons 5.524569 .0831077 66.47 0.000 5.350622 5.698515练习题13(p105)g lnY=ln(Y)g lnK=ln(K)g lnL=ln(L)reg lnY lnK lnLSource SS df MS Number of obs = 31 F( 2, 28) = 59.66 Model 21.6049266 2 10.8024633 Prob > F = 0.0000 Residual 5.07030244 28 .18108223 R-squared = 0.8099 Adj R-squared = 0.7963 Total 26.6752291 30 .889174303 Root MSE = .42554 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnK .6092356 .1763779 3.45 0.002 .2479419 .9705293 lnL .3607965 .2015915 1.79 0.084 -.0521449 .7737378 _cons 1.153994 .7276114 1.59 0.124 -.33645 2.644439第四章例4.1.4 (P116)(1)回归g lnY=ln(Y)g lnX1=ln(X1)g lnX2=ln(X2)reg lnY lnX1 lnX2Source SS df MS Number of obs = 31 F( 2, 28) = 49.60 Model 2.9609923 2 1.48049615 Prob > F = 0.0000 Residual .835744123 28 .029848004 R-squared = 0.7799 Adj R-squared = 0.7642 Total 3.79673642 30 .126557881 Root MSE = .17277 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .1502137 .1085379 1.38 0.177 -.072116 .3725435 lnX2 .4774534 .0515951 9.25 0.000 .3717657 .5831412 _cons 3.266068 1.041591 3.14 0.004 1.132465 5.39967于是得到方程:lnY=3.266+0.1502lnX1+0.4775lnX2(2)绘制参差图:predict e, residg ei2=e^2scatter ei2 lnX2,title("图4.1.3 异方差性检验图")xtick(6(0.4)9.2)ytick(0(0.04)0.24)predict在回归结束后,需要对拟合值以及残差进行分析,需要使用此命令。