数据库系统基础教程第四章答案
- 格式:doc
- 大小:562.00 KB
- 文档页数:43

自考数据库系统原理第四章关系运算课后习题答案2009-09-15 10:454.1 名词解释(1)关系模型:用二维表格结构表示实体集,外键表示实体间联系的数据模型称为关系模型。
(2)关系模式:关系模式实际上就是记录类型。
它的定义包括:模式名,属性名,值域名以及模式的主键。
关系模式不涉及到物理存储方面拿枋觯 鼋鍪嵌允 萏匦缘拿枋觥?(3)关系实例:元组的集合称为关系和实例,一个关系即一张二维表格。
(4)属性:实体的一个特征。
在关系模型中,字段称为属性。
(5)域:在关系中,每一个属性都有一个取值范围,称为属性的值域,简称域。
(6)元组:在关系中,记录称为元组。
元组对应表中的一行;表示一个实体。
(7)超键:在关系中能唯一标识元组的属性集称为关系模式的超键。
(8)候选键:不含有多余属性的超键称为候选键。
(9)主键:用户选作元组标识的一个候选键为主键。
(单独出现,要先解释“候选键”)(10)外键:某个关系的主键相应的属性在另一关系中出现,此时该主键在就是另一关系的外键,如有两个关系S和SC,其中S#是关系S的主键,相应的属性S#在关系SC中也出现,此时S#就是关系SC的外键。
(11)实体完整性规则:这条规则要求关系中元组在组成主键的属性上不能有空值。
如果出现空值,那么主键值就起不了唯一标识元组的作用。
(12)参照完整性规则:这条规则要求“不引用不存在的实体”。
其形式定义如下:如果属性集K是关系模式R1的主键,K也是关系模式R2的外键,那么R2的关系中, K的取值只允许有两种可能,或者为空值,或者等于R1关系中某个主键值。
这条规则在使用时有三点应注意: 1)外键和相应的主键可以不同名,只要定义在相同值域上即可。
2)R1和R2也可以是同一个关系模式,表示了属性之间的联系。
3)外键值是否允许空应视具体问题而定。
(13)过程性语言:在编程时必须给出获得结果的操作步骤,即“干什么”和“怎么干”。
如Pascal和C语言等。

数据库原理教程习题答案全集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#0000000000第1章数据库系统概述习题参考答案税务局使用数据库存储纳税人(个人或公司)信息、纳税人缴纳税款信息等。
典型的数据处理包括纳税、退税处理、统计各类纳税人纳税情况等。
银行使用数据库存储客户基本信息、客户存贷款信息等。
典型的数据处理包括处理客户存取款等。
超市使用数据库存储商品的基本信息、会员客户基本信息、客户每次购物的详细清单。
典型的数据处理包括收银台记录客户每次购物的清单并计算应交货款。
DBMS是数据库管理系统的简称,是一种重要的程序设计系统。
它由一个相互关联的数据集合和一组访问这些数据的程序组成。
数据库是持久储存在计算机中、有组织的、可共享的大量数据的集合。
数据库中的数据按一定的数据模型组织、描述和存储,可以被各种用户共享,具有较小的冗余度、较高的数据独立性,并且易于扩展。
数据库系统由数据库、DBMS(及其开发工具)、应用系统和数据库管理员组成。
数据模型是一种形式机制,用于数据建模,描述数据、数据之间的联系、数据的语义、数据上的操作和数据的完整性约束条件。
数据库模式是数据库中使用数据模型对数据建模所产生设计结果。
对于关系数据库而言,数据库模式由一组关系模式构成。
数据字典是DBMS维护的一系列内部表,用来存放元数据。
所谓元数据是关于数据的数据。
DBMS提供如下功能:(1)数据定义:提供数据定义语言DDL,用于定义数据库中的数据对象和它们的结构。
(2)数据操纵:提供数据操纵语言DML,用于操纵数据,实现对数据库的基本操作(查询、插入、删除和修改)。
(3)事务管理和运行管理:统一管理数据、控制对数据的并发访问,保证数据的安全性、完整性,确保故障时数据库中数据不被破坏,并且能够恢复到一致状态。
(4)数据存储和查询处理:确定数据的物理组织和存取方式,提供数据的持久存储和有效访问;确定查询处理方法,优化查询处理过程。

Database Systems: The Complete BookSolutions for Chapter 2Solutions for Section 2.1Exercise 2.1.1The E/R Diagram.Exercise 2.1.8(a)The E/R DiagramKobvxybzSolutions for Section 2.2Exercise 2.2.1The Addresses entity set is nothing but a single address, so we would prefer to make address an attribute of Customers. Were the bank to record several addresses for a customer, then it might make sense to have an Addresses entity set and make Lives-at a many-many relationship.The Acct-Sets entity set is useless. Each customer has a unique account set containing his or her accounts. However, relating customers directly to their accounts in a many-many relationship conveys the same information and eliminates the account-set concept altogether.Solutions for Section 2.3Exercise 2.3.1(a)Keys ssNo and number are appropriate for Customers and Accounts, respectively. Also, we think it does not make sense for an account to be related to zero customers, so we should round the edge connecting Owns to Customers. It does not seem inappropriate to have a customer with 0 accounts;they might be a borrower, for example, so we put no constraint on the connection from Owns to Accounts. Here is the The E/R Diagram,showing underlined keys andthe numerocity constraint.Exercise 2.3.2(b)If R is many-one from E1 to E2, then two tuples (e1,e2) and (f1,f2) of the relationship set for R must be the same if they agree on the key attributes for E1. To see why, surely e1 and f1 are the same. Because R is many-one from E1 to E2, e2 and f2 must also be the same. Thus, the pairs are the same.Solutions for Section 2.4Exercise 2.4.1Here is the The E/R Diagram.We have omitted attributes other than our choice for the key attributes of Students and Courses. Also omitted are names for the relationships. Attribute grade is not part of the key for Enrollments. The key for Enrollements is studID from Students and dept and number from Courses.Exercise 2.4.4bHere is the The E/R Diagram Again, we have omitted relationship names and attributes other than our choice for the key attributes. The key for Leagues is its own name; this entity set is not weak. The key for Teams is its own name plus the name of the league of which the team is a part, e.g., (Rangers, MLB) or (Rangers, NHL). The key for Players consists of the player's number and the key for the team on which he or she plays. Since the latter key is itself a pair consisting of team and league names, the key for players is the triple (number, teamName, leagueName). e.g., JeffGarcia is (5, 49ers, NFL).Database Systems: The Complete BookSolutions for Chapter 3Solutions for Section 3.1Exercise 3.1.2(a)We can order the three tuples in any of 3! = 6 ways. Also, the columns can be ordered in any of 3! = 6 ways. Thus, the number of presentations is 6*6 = 36.Solutions for Section 3.2Exercise 3.2.1Customers(ssNo, name, address, phone)Flights(number, day, aircraft)Bookings(ssNo, number, day, row, seat)Being a weak entity set, Bookings' relation has the keys for Customers and Flights and Bookings' own attributes.Notice that the relations obtained from the toCust and toFlt relationships are unnecessary. They are:toCust(ssNo, ssNo1, number, day)toFlt(ssNo, number, day, number1, day1)That is, for toCust, the key of Customers is paired with the key for Bookings. Since both include ssNo, this attribute is repeated with two different names, ssNo and ssNo1. A similar situation exists for toFlt.Exercise 3.2.3Ships(name, yearLaunched)SisterOf(name, sisterName)Solutions for Section 3.3Exercise 3.3.1Since Courses is weak, its key is number and the name of its department. We do not have arelation for GivenBy. In part (a), there is a relation for Courses and a relation for LabCourses that has only the key and the computer-allocation attribute. It looks like:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)For part (b), LabCourses gets all the attributes of Courses, as:Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)And for (c), Courses and LabCourses are combined, as:Depts(name, chair)Courses(number, deptName, room, allocation)Exercise 3.3.4(a)There is one relation for each entity set, so the number of relations is e. The relation for the root entity set has a attributes, while the other relations, which must include the key attributes, have a+k attributes.Solutions for Section 3.4Exercise 3.4.2Surely ID is a key by itself. However, we think that the attributes x, y, and z together form another key. The reason is that at no time can two molecules occupy the same point.Exercise 3.4.4The key attributes are indicated by capitalization in the schema below:Customers(SSNO, name, address, phone)Flights(NUMBER, DAY, aircraft)Bookings(SSNO, NUMBER, DAY, row, seat)Exercise 3.4.6(a)The superkeys are any subset that contains A1. Thus, there are 2^{n-1} such subsets, since each of the n-1 attributes A2 through An may independently be chosen in or out.Solutions for Section 3.5Exercise 3.5.1(a)We could try inference rules to deduce new dependencies until we are satisfied we have them all.A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have A+ = A, B+ = B, C+ = ACD, and D+ = AD. Thus, the only new dependency we get with a single attribute on the left is C->A.Now consider pairs of attributes:AB+ = ABCD, so we get new dependency AB->D. AC+ = ACD, and AC->D is nontrivial. AD+ = AD, so nothing new. BC+ = ABCD, so we get BC->A, and BC->D. BD+ = ABCD, giving usBD->A and BD->C. CD+ = ACD, giving CD->A.For the triples of attributes, ACD+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC->D, ABD->C, and BCD->A.Since ABCD+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above is: C->A, AB->D, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.Exercise 3.5.1(b)From the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.5.1(c)The superkeys are all those that contain one of those three keys. That is, a superkey that is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.5.3(a)We must compute the closure of A1A2...AnC. Since A1A2...An->B is a dependency, surely B is in this set, proving A1A2...AnC->B.Exercise 3.5.4(a)Consider the relationThis relation satisfies A->B but does not satisfy B->A.Exercise 3.5.8(a)If all sets of attributes are closed, then there cannot be any nontrivial functional dependenc ies. For suppose A1A2...An->B is a nontrivial dependency. Then A1A2...An+ contains B and thus A1A2...An is not closed.Exercise 3.5.10(a)We need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets: A+ = AB+ = BC+ = ACEAB+ = ABCDEAC+ = ACEBC+ = ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC are: C->A and AB->C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Solutions for Section 3.6Exercise 3.6.1(a)In the solution to Exercise 3.5.1 we found that there are 14 nontrivial dependencies, including the three given ones and 11 derived dependencies. These are: C->A, C->D, D->A, AB->D, AB-> C, AC->D, BC->A, BC->D, BD->A, BD->C, CD->A, ABC->D, ABD->C, and BCD->A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C->A, C->D, D->A, AC->D, and CD->A.One choice is to decompose using C->D. That gives us ABC and CD as decomposed relations. CD is surely in BCNF, since any two-attribute relation is. ABC is not in BCNF, since AB and BC are its only keys, but C->A is a dependency that holds in ABCD and therefore holds in ABC. We must further decompose ABC into AC and BC. Thus, the three relations of the decomposition are AC, BC, and CD.Since all attributes are in at least one key of ABCD, that relation is already in 3NF, and no decomposition is necessary.Exercise 3.6.1(b)(Revised 1/19/02) The only key is AB. Thus, B->C and B->D are both BCNF violations. The derived FD's BD->C and BC->D are also BCNF violations. However, any other nontrivial, derived FD will have A and B on the left, and therefore will contain a key.One possible BCNF decomposition is AB and BCD. It is obtained starting with any of the four violations mentioned above. AB is the only key for AB, and B is the only key for BCD.Since there is only one key for ABCD, the 3NF violations are the same, and so is the decomposition.Solutions for Section 3.7Exercise 3.7.1Since A->->B, and all the tuples have the same value for attribute A, we can pair the B-value from any tuple with the value of the remaining attribute C from any other tuple. Thus, we know that R must have at least the nine tuples of the form (a,b,c), where b is any of b1, b2, or b3, and c is any of c1, c2, or c3. That is, we can derive, using the definition of a multivalued dependency, that each of the tuples (a,b1,c2), (a,b1,c3), (a,b2,c1), (a,b2,c3), (a,b3,c1), and (a,b3,c2) are also in R.Exercise 3.7.2(a)First, people have unique Social Security numbers and unique birthdates. Thus, we expect the functional dependencies ssNo->name and ssNo->birthdate hold. The same applies to children, so we expect childSSNo->childname and childSSNo->childBirthdate. Finally, an automobile has a unique brand, so we expect autoSerialNo->autoMake.There are two multivalued dependencies that do not follow from these functional dependencies. First, the information about one child of a person is independent of other information about that person. That is, if a person with social security number s has a tuple with cn,cs,cb, then if there isany other tuple t for the same person, there will also be another tuple that agrees with t except that it has cn,cs,cb in its components for the child name, Social Security number, and birthdate. That is the multivalued dependencyssNo->->childSSNo childName childBirthdateSimilarly, an automobile serial number and make are independent of any of the other attributes, so we expect the multivalued dependencyssNo->->autoSerialNo autoMakeThe dependencies are summarized below:ssNo -> name birthdatechildSSNo -> childName childBirthdateautoSerialNo -> autoMakessNo ->-> childSSNo childName childBirthdatessNo ->-> autoSerialNo autoMakeExercise 3.7.2(b)We suggest the relation schemas{ssNo, name, birthdate}{ssNo, childSSNo}{childSSNo, childName childBirthdate}{ssNo, autoSerialNo}{autoSerialNo, autoMake}An initial decomposition based on the two multivalued dependencies would give us {ssNo, name, birthDate}{ssNo, childSSNo, childName, childBirthdate}{ssNo, autoSerialNo, autoMake}Functional dependencies force us to decompose the second and third of these.Exercise 3.7.3(a)Since there are no functional dependencies, the only key is all four attributes, ABCD. Thus, each of the nontrvial multivalued dependencies A->->B and A->->C violate 4NF. We must separate out the attributes of these dependencies, first decomposing into AB and ACD, and then decomposing the latter into AC and AD because A->->C is still a 4NF violation for ACD. The final set of relations are AB, AC, and AD.Exercise 3.7.7(a)Let W be the set of attributes not in X, Y, or Z. Consider two tuples xyzw and xy'z'w' in the relation R in question. Because X ->-> Y, we can swap the y's, so xy'zw and xyz'w' are in R. Because X ->-> Z, we can take the pair of tuples xyzw and xyz'w' and swap Z's to get xyz'w and xyzw'. Similarly, we can take the pair xy'z'w' and xy'zw and swap Z's to get xy'zw' and xy'z'w.In conclusion, we started with tuples xyzw and xy'z'w' and showed that xyzw' and xy'z'w must also be in the relation. That is exactly the statement of the MVD X ->-> Y-union-Z. Note that the above statements all make sense even if there are attributes in common among X, Y, and Z.Exercise 3.7.8(a)Consider a relation R with schema ABCD and the instance with four tuples abcd, abcd', ab'c'd, and ab'c'd'. This instance satisfies the MVD A->-> BC. However, it does not satisfy A->-> B. For example, if it did satisfy A->-> B, then because the instance contains the tuples abcd and ab'c'd, we would expect it to contain abc'd and ab'cd, neither of which is in the instance.Database Systems: The Complete BookSolutions for Chapter 4Solutions for Section 4.2Exercise 4.2.1class Customer {attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account {attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Exercise 4.2.4class Person {attribute string name;relationship Person motherOfinverse Person::childrenOfFemalerelationship Person fatherOfinverse Person::childrenOfMalerelationship Set<Person> childreninverse Person::parentsOfrelationship Set<Person> childrenOfFemaleinverse Person::motherOfrelationship Set<Person> childrenOfMaleinverse Person::fatherOfrelationship Set<Person> parentsOfinverse Person::children}Notice that there are six different relationships here. For example, the inverse of the relationship that connects a person to their (unique) mother is a relationship that connects a mother (i.e., a female person) to the set of her children. That relationship, which we call childrenOfFemale, is different from the children relationship, which connects anyone -- male or female -- to their children.Exercise 4.2.7A relationship R is its own inverse if and only if for every pair (a,b) in R, the pair (b,a) is also in R. In the terminology of set theory, the relation R is ``symmetric.''Solutions for Section 4.3Exercise 4.3.1We think that Social Security number should me the key for Customer, and account number should be the key for Account. Here is the ODL solution with key and extent declarations.class Customer(extent Customers key ssNo){attribute string name;attribute string addr;attribute string phone;attribute integer ssNo;relationship Set<Account> ownsAcctsinverse Account::ownedBy;}class Account(extent Accounts key number){attribute integer number;attribute string type;attribute real balance;relationship Set<Customer> ownedByinverse Customer::ownsAccts}Solutions for Section 4.4Exercise 4.4.1(a)Since the relationship between customers and accounts is many-many, we should create a separate relation from that relationship-pair.Customers(ssNo, name, address, phone)Accounts(number, type, balance)CustAcct(ssNo, number)Exercise 4.4.1(d)Ther is only one attribute, but three pairs of relationships from Person to itself. Since motherOf and fatherOf are many-one, we can store their inverses in the relation for Person. That is, for each person, childrenOfMale and childrenOfFemale will indicate that persons's father and mother. The children relationship is many-many, and requires its own relation. This relation actually turns out to be redundant, in the sense that its tuples can be deduced from the relationships stored with Person. The schema:Persons(name, childrenOfFemale, childrenOfMale)Parent-Child(parent, child)Exercise 4.4.4Y ou get a schema like:Studios(name, address, ownedMovie)Since name -> address is the only FD, the key is {name, ownedMovie}, and the FD has a left side that is not a superkey.Exercise 4.4.5(a,b,c)(a) Struct Card { string rank, string suit };(b) class Hand {attribute Set theHand;};For part (c) we have:Hands(handId, rank, suit)Notice that the class Hand has no key, so we need to create one: handID. Each hand has, in the relation Hands, one tuple for each card in the hand.Exercise 4.4.5(e)Struct PlayerHand { string Player, Hand theHand };class Deal {attribute Set theDeal;}Alternatively, PlayerHand can be defined directly within the declaration of attribute theDeal. Exercise 4.4.5(h)Since keys for Hand and Deal are lacking, a mechanical way to design the database schema is to have one relation connecting deals and player-hand pairs, and another to specify the contents of hands. That is:Deals(dealID, player, handID)Hands(handID, rank, suit)However, if we think about it, we can get rid of handID and connect the deal and the player directly to the player's cards, as:Deals(dealID, player, rank, suit)Exercise 4.4.5(i)First, card is really a pair consisting of a suit and a rank, so we need two attributes in a relation schema to represent cards. However, much more important is the fact that the proposed schema does not distinguish which card is in which hand. Thus, we need another attribute that indicates which hand within the deal a card belongs to, something like:Deals(dealID, handID, rank, suit)Exercise 4.4.6(c)Attribute b is really a bag of (f,g) pairs. Thus, associated with each a-value will be zero or more (f,g) pairs, each of which can occur several times. We shall use an attribute count to indicate the number of occurrences, although if relations allow duplicate tuples we could simply allow duplicate (a,f,g) triples in the relation. The proposed schema is:C(a, f, g, count)Solutions for Section 4.5Exercise 4.5.1(b)Studios(name, address, movies{(title, year, inColor, length,stars{(name, address, birthdate)})})Since the information about a star is repeated once for each of their movies, there is redundancy. To eliminate it, we have to use a separate relation for stars and use pointers from studios. That is: Stars(name, address, birthdate)Studios(name, address, movies{(title, year, inColor, length,stars{*Stars})})Since each movie is owned by one studio, the information about a movie appears in only one tuple of Studios, and there is no redundancy.Exercise 4.5.2Customers(name, address, phone, ssNo, accts{*Accounts})Accounts(number, type, balance, owners{*Customers})Solutions for Section 4.6Exercise 4.6.1(a)We need to add new nodes labeled George Lucas and Gary Kurtz. Then, from the node sw (which represents the movie Star Wars), we add arcs to these two new nodes, labeled direc tedBy and producedBy, respectively.Exercise 4.6.2Create nodes for each account and each customer. From each customer node is an arc to a node representing the attributes of the customer, e.g., an arc labeled name to the customer's name. Likewise, there is an arc from each account node to each attribute of that account, e.g., an arc labeled balance to the value of the balance.To represent ownership of accounts by customers, we place an arc labeled owns from each customer node to the node of each account that customer holds (possibly jointly). Also, we placean arc labeled ownedBy from each account node to the customer node for each owner of that account.Exercise 4.6.5In the semistructured model, nodes represent data elements, i.e., entities rather than entity sets. In the E/R model, nodes of all types represent schema elements, and the data is not represented at all. Solutions for Section 4.7Exercise 4.7.1(a)<STARS-MOVIES><STAR starId = "cf" starredIn = "sw, esb, rj"><NAME>Carrie Fisher</NAME><ADDRESS><STREET>123 Maple St.</STREET><CITY>Hollywood</CITY></ADDRESS><ADDRESS><STREET>5 Locust Ln.</STREET><CITY>Malibu</CITY></ADDRESS></STAR><STAR starId = "mh" starredIn = "sw, esb, rj"><NAME>Mark Hamill</NAME><ADDRESS><STREET>456 Oak Rd.<STREET><CITY>Brentwood</CITY></ADDRESS></STAR><STAR starId = "hf" starredIn = "sw, esb, rj, wit"><NAME>Harrison Ford</NAME><ADDRESS><STREET>whatever</STREET><CITY>whatever</CITY></ADDRESS></STAR><MOVIE movieId = "sw" starsOf = "cf, mh"><TITLE>Star Wars</TITLE><YEAR>1977</YEAR></MOVIE><MOVIE movieId = "esb" starsOf = "cf, mh"><TITLE>Empire Strikes Back</TITLE><YEAR>1980</YEAR></MOVIE><MOVIE movieId = "rj" starsOf = "cf, mh"><TITLE>Return of the Jedi</TITLE><YEAR>1983</YEAR></MOVIE><MOVIE movieID = "wit" starsOf = "hf"><TITLE>Witness</TITLE><YEAR>1985</YEAR></MOVIE></STARS-MOVIES>Exercise 4.7.2<!DOCTYPE Bank [<!ELEMENT BANK (CUSTOMER* ACCOUNT*)><!ELEMENT CUSTOMER (NAME, ADDRESS, PHONE, SSNO)> <!A TTLIST CUSTOMERcustId IDowns IDREFS><!ELEMENT NAME (#PCDA TA)><!ELEMENT ADDRESS (#PCDA TA)><!ELEMENT PHONE (#PCDA TA)><!ELEMENT SSNO (#PCDA TA)><!ELEMENT ACCOUNT (NUMBER, TYPE, BALANCE)><!A TTLIST ACCOUNTacctId IDownedBy IDREFS><!ELEMENT NUMBER (#PCDA TA)><!ELEMENT TYPE (#PCDA TA)><!ELEMENT BALANCE (#PCDA TA)>]>Database Systems: The CompleteBookSolutions for Chapter 5Solutions for Section 5.2Exercise 5.2.1(a)PI_model( SIGMA_{speed >= 1000} ) (PC)Exercise 5.2.1(f)The trick is to theta-join PC with itself on the condition that the hard disk sizes are equal. That gives us tuples that have two PC model numbers with the same value of hd. However, these two PC's could in fact be the same, so we must also require in the theta-join that the model numbers be unequal. Finally, we want the hard disk sizes, so we project onto hd.The expression is easiest to see if we write it using some temporary values. We start by renaming PC twice so we can talk about two occurrences of the same attributes.R1 = RHO_{PC1} (PC)R2 = RHO_{PC2} (PC)R3 = R1 JOIN_{PC1.hd = PC2.hd AND PC1.model <> PC2.model} R2R4 = PI_{PC1.hd} (R3)Exercise 5.2.1(h)First, we find R1, the model-speed pairs from both PC and Laptop. Then, we find from R1 those computers that are ``fast,'' at least 133Mh. At the same time, we join R1 with Product to connect model numbers to their manufacturers and we project out the speed to get R2. Then we join R2 with itself (after renaming) to find pairs of different models by the same maker. Finally, we get our answer, R5, by projecting onto one of the maker attributes. A sequence of steps giving the desired expression is: R1 = PI_{model,speed} (PC) UNION PI_{model,speed} (Laptop)R2 = PI_{maker,model} (SIGMA_{speed>=700} (R1) JOIN Product)R3 = RHO_{T(maker2, model2)} (R2)R4 = R2 JOIN_{maker = maker2 AND model <> model2} (R3)R5 = PI_{maker} (R4)Exercise 5.2.2Here are figures for the expression trees of Exercise 5.2.1 Part (a)Part (f)Part (h). Note that the third figure is not really a tree, since it uses a common subexpression. We could duplicate the nodes to make it a tree, but using common subexpressions is a valuable form of query optimization. One of the benefits one gets from constructing ``trees'' for queries is the ability to combine nodes that represent common subexpressions.Exercise 5.2.7The relation that results from the natural join has only one attribute from each pair of equated attributes. The theta-join has attributes for both, and their columns are identical.Exercise 5.2.9(a)If all the tuples of R and S are different, then the union has n+m tuples, and this number is the maximum possible.The minimum number of tuples that can appear in the result occurs if every tuple of one relation also appears in the other. Surely the union has at least as many tuples as the larger of R and that is, max(n,m) tuples. However, it is possible for every tuple of the smaller to appear in the other, so it is possible that there are as few as max(n,m) tuples in the union.Exercise 5.2.10In the following we use the name of a relation both as its instance (set of tuples) and as its schema (set of attributes). The context determines uniquely which is meant.PI_R(R JOIN S) Note, however, that this expression works only for sets; it does not preserve the multipicity of tuples in R. The next two expressions work for bags.R JOIN DELTA(PI_{R INTERSECT S}(S)) In this expression, each projection of a tuple from S onto the attributes that are also in R appears exactly once in the second argument of the join, so it preserves multiplicity of tuples in R, except for those thatdo not join with S, which disappear. The DELTA operator removes duplicates, as described in Section 5.4.R - [R - PI_R(R JOIN S)] Here, the strategy is to find the dangling tuples of R and remove them.Solutions for Section 5.3Exercise 5.3.1As a bag, the value is {700, 1500, 866, 866, 1000, 1300, 1400, 700, 1200, 750, 1100, 350, 733}. The order is unimportant, of course. The average is 959.As a set, the value is {700, 1500, 866, 1000, 1300, 1400, 1200, 750, 1100, 350, 733}, and the average is 967. H3>Exercise 5.3.4(a)As sets, an element x is in the left-side expression(R UNION S) UNION Tif and only if it is in at least one of R, S, and T. Likewise, it is in the right-side expressionR UNION (S UNION T)under exactly the same conditions. Thus, the two expressions have exactly the same members, and the sets are equal.As bags, an element x is in the left-side expression as many times as the sum of the number of times it is in R, S, and T. The same holds for the right side. Thus, as bags the expressions also have the same value.Exercise 5.3.4(h)As sets, element x is in the left sideR UNION (S INTERSECT T)if and only if x is either in R or in both S and T. Element x is in the right side(R UNION S) INTERSECT (R UNION T)if and only if it is in both R UNION S and R UNION T. If x is in R, then it is in both unions. If x is in both S and T, then it is in both union. However, if x is neither in R nor in both of S and T, then it cannot be in both unions. For example, suppose x is not in R and not in S. Then x is not in R UNION S. Thus, the statement of when x is in the right side is exactly the same as when it is in the left side: x is either in R or in both of S and T.Now, consider the expression for bags. Element x is in the left side the sum of the number of times it is in R plus the smaller of the number of times x is in S and the number of times x is in T. Likewise, the number of times x is in the right side is the smaller ofThe sum of the number of times x is in R and in S.The sum of the number of times x is in R and in T.A moment's reflection tells us that this minimum is the sum of the number of times x is in R plus the smaller of the number of times x is in S and in T, exactly as for the left side.Exercise 5.3.5(a)For sets, we observe that element x is in the left side(R INTERSECT S) - T。

第4章数据库安全性1 .什么是数据库的安全性?答:数据库的安全性是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏。
2 .数据库安全性和计算机系统的安全性有什么关系?答:安全性问题不是数据库系统所独有的,所有计算机系统都有这个问题。
只是在数据库系统中大量数据集中存放,而且为许多最终用户直接共享,从而使安全性问题更为突出。
系统安全保护措施是否有效是数据库系统的主要指标之一。
数据库的安全性和计算机系统的安全性,包括操作系统、网络系统的安全性是紧密联系、相互支持的,3 .试述可信计算机系统评测标准的情况,试述TDI / TCSEC 标准的基本内容。
答:各个国家在计算机安全技术方面都建立了一套可信标准。
目前各国引用或制定的一系列安全标准中,最重要的是美国国防部(DoD )正式颁布的《DoD 可信计算机系统评估标准》(伽sted Co 哪uter system Evaluation criteria ,简称TcsEc ,又称桔皮书)。
(TDI / TCSEC 标准是将TcsEc 扩展到数据库管理系统,即《可信计算机系统评估标准关于可信数据库系统的解释》(Tmsted Database Interpretation 简称TDI , 又称紫皮书)。
在TDI 中定义了数据库管理系统的设计与实现中需满足和用以进行安全性级别评估的标准。
TDI 与TcsEc 一样,从安全策略、责任、保证和文档四个方面来描述安全性级别划分的指标。
每个方面又细分为若干项。
4 .试述T csEC ( TDI )将系统安全级别划分为4 组7 个等级的基本内容。
答:根据计算机系统对安全性各项指标的支持情况,TCSEC ( TDI )将系统划分为四组(division ) 7 个等级,依次是D 、C ( CI , CZ )、B ( BI , BZ , B3 )、A ( AI ) ,按系统可靠或可信程度逐渐增高。
这些安全级别之间具有一种偏序向下兼容的关系,即较高安全性级别提供的安全保护包含较低级别的所有保护要求,同时提供更多或更完善的保护能力。

数据库系统教程课后答案数据库系统是一种用于管理和组织大量数据的软件系统,它通过数据模型、数据结构和数据操作等方式来实现数据的存储、访问、更新和管理等功能。
数据库系统广泛应用于各个领域,如企业管理、电子商务、科学研究等。
在数据库系统的学习过程中,会出现一些练习题目和问题,需要我们进行思考和解答。
下面我将结合一些常见的课后答案,对数据库系统进行详细的解析。
首先,我们需要了解数据库的基本概念和组成部分。
数据库是按照一定的数据模型组织、存储和管理数据的集合,它由数据库管理系统(DBMS)、数据库、数据库模式(或称为数据库结构)、数据库实例(或称为数据系统)等组成。
其中,数据库管理系统是进行数据库管理的软件系统,它负责数据库的创建、维护和管理等操作。
接着,我们需要了解数据库的设计和规范化。
数据库设计是指根据用户的需求和系统的要求,将现实世界的数据和关系转化为数据库模式的过程。
在设计数据库时,要符合一定的规范化原则,如第一范式、第二范式和第三范式等。
规范化可以提高数据库的性能、减少数据冗余,同时也方便数据库的操作和维护。
然后,我们需要了解数据库的查询和操作。
数据库查询是指根据用户的需求,从数据库中检索出符合条件的数据的过程。
查询语言是进行数据库查询的工具,如结构化查询语言(SQL)。
SQL语言包括数据定义语言(DDL)、数据操纵语言(DML)和数据控制语言(DCL)等。
DDL用于定义和管理数据库的结构,如创建表、定义键等;DML用于对数据库中的数据进行操作,如插入、更新和删除等;DCL用于控制数据库的安全性和权限,如授权和回收权限。
此外,我们还需要了解数据库的事务和并发控制。
事务是指一组对数据库的操作,要么全部执行成功,要么全部放弃。
事务具备ACID特性,即原子性、一致性、隔离性和持久性。
并发控制是指多个事务同时对数据库进行操作时,保证数据库的一致性和完整性的措施。
并发控制可以通过加锁、多版本并发控制(MVCC)、时间戳等方式来实现。
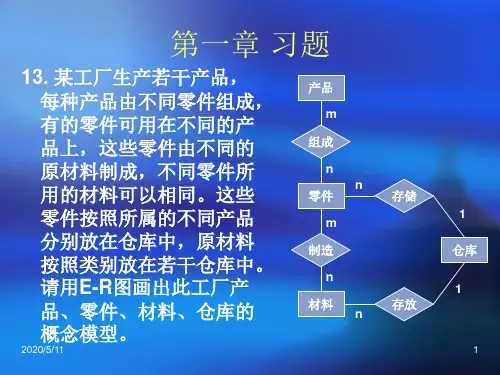


第四章作业1.数据仓库的需求分析的任务是什么?P67需求分析的任务是通过详细调查现实世界要处理的对象(企业、部门用户等),充分了解源系统工作概况,明确用户的各种需求,为设计数据仓库服务。
概括地说,需求分析要明确用那些数据经过分析来实现用户的决策支持需求。
2.数据仓库系统需要确定的问题有哪些?P67、、(1)确定主题域a)明确对于决策分析最有价值的主题领域有哪些b)每个主题域的商业维度是那些?每个维度的粒度层次有哪些?c)制定决策的商业分区是什么?d)不同地区需要哪些信息来制定决策?e)对那个区域提供特定的商品和服务?(2)支持决策的数据来源a)那些源数据与商品的主题有关?b)在已有的报表和在线查询(OLTP)中得到什么样的信息?c)提供决策支持的细节程度是怎么样的?(3)数据仓库的成功标准和关键性指标a)衡量数据仓库成功的标准是什么?b)有哪些关键的性能指标?如何监控?c)对数据仓库的期望是什么?d)对数据仓库的预期用途有哪些?e)对计划中的数据仓库的考虑要点是什么?(4)数据量与更新频率a)数据仓库的总数据量有多少?b)决策支持所需的数据更新频率是多少?时间间隔是多长?c)每种决策分析与不同时间的标准对比如何?d)数据仓库中的信息需求的时间界限是什么?3.实现决策支持所需要的数据包括哪些内容?P68(1)源数据(2)数据转换(3)数据存储(4)决策分析4.概念:将需求分析过程中得到的用户需求抽象为计算机表示的信息结构,叫做概念模型。
特点:(1)能真实反映现实世界,能满足用户对数据的分析,达到决策支持的要求,它是现实世界的一个真实模型。
(2)易于理解,便利和用户交换意见,在用户的参与下,能有效地完成对数据仓库的成功设计。
(3)易于更改,当用户需求发生变化时,容易对概念模型修改和扩充。
(4)易于向数据仓库的数据模型(星型模型)转换。
5.用长方形表示实体,在数据仓库中就表示主题,椭圆形表示主题的属性,并用无向边把主题与其属性连接起来;用菱形表示主题之间的联系,用无向边把菱形分别与有关的主题连接;若主题之间的联系也具有属性,则把属性和菱形也用无向边连接上。

免责声明:私人学习之余整理,如有错漏,概不负责1.查询学生选课表中的全部数据SELECT *FROM SC2.查询计算机系的学生的姓名、年龄SELECT Sname,SageFROM StudentWHERE Sdept = '计算机系'3.查询成绩在70到80分之间的学生的学号课程号和成绩SELECT *FROM SCWHERE Grade BETWEEN 70 AND 804.查询计算机系年龄在18-20岁之间且性别为男的学生的姓名和年龄SELECT Sname,SageFROM StudentWHERE Sage BETWEEN 18 AND 20AND Sdept = '计算机系'AND Ssex = '男'5.查询课程号为‘c001’的课程的最高的分数SELECT MAX(Grade)FROM SCWHERE Cno = 'c001'6.查询计算机系学生的最大年龄和最小年龄SELECT MAX(Sage),MIN(Sage)FROM StudentWHERE Sdept = '计算机系'7.统计每个系的学生人数SELECT Sdept,COUNT(*) AS 学生人数FROM StudentGROUP BY Sdept8.统计每门课程的选课人数和考试最高分SELECT Cno,COUNT(*) AS 选课人数,MAX(Grade)FROM SCGROUP BY Cno9.统计每个学生的选课门数和考试总成绩,并按照选课门数升序显示结果SELECT Sno,COUNT(*) AS 选课门数,SUM(Grade) AS 总成绩FROM SCGROUP BY SnoORDER BY COUNT(*) ASC10.查询总成绩超过200分的学生的学号和总成绩SELECT Sno,SUM(Grade) AS 总成绩FROM SCGROUP BY SnoHAVING SUM(Grade) >20011.查询选修了'c002'号课程的学生的姓名和所在系SELECT Sname,SdeptFROM Student INNER JOIN SC ON Student.Sno = SC.SnoWHERE Cno = 'C002'12.查询成绩80分以上的学生的姓名、课程号和成绩,按成绩降序排列SELECT Sname,Cno,GradeFROM Student INNER JOIN SC ON Student.Sno = SC.SnoWHERE Grade > 80ORDER BY Grade DESC13.查询那些学生没有选修课,列出学号、姓名和所在系SELECT Student.Sno,Sname,Sdept,CnoFROM Student LEFT OUTER JOIN SC ON Student.Sno = SC.SnoWHERE Cno IS NULL14.查询与java在同一学期开设的课程的课程名和开课学期SELECT ame,c2.SemesterFROM Course c1 JOIN Course c2 ON c1.Semester = c2.SemesterWHERE ame = 'Java'-- 注意select的列与where的列应该不同15.查询与李勇年龄相同的学生的姓名、所在系和年龄SELECT s1.Sname,s1.Sdept,s1.SageFROM Student s1 JOIN Student s2 ON s1.Sage = S2.SageWHERE s2.Sname = '李勇'16.用子查询实现如下查询1)查询选修了'c001'号课程的学生的姓名和所在系SELECT Sname,SdeptFROM StudentWHERE Sno IN (SELECT Sno FROM SC WHERE Cno = 'c001')2)查询数学系成绩在80分以上的学生的学号、姓名、课程号和成绩SELECT s.Sno,Sname,Cno,GradeFROM Student s INNER JOIN SC ON s.Sno = SC.SnoWHERE Grade > 80 ANDs.Sno IN (SELECT Sno FROM SC WHERE Sdept = '数学系')3)查询计算机系考试成绩最高的学生的姓名SELECT SnameFROM Student s INNER JOIN SC ON s.Sno = SC.SnoWHERE Sdept = '计算机系' ANDgrade = (SELECT MAX(Grade) FROM SC INNER JOIN Student ON SC.Sno = Student.Sno)-- 不用子查询SELECT SnameFROM Student s INNER JOIN SC ON s.Sno = SC.SnoWHERE Sdept = '计算机系'GROUP BY Grade DESC LIMIT 1-- mysql没有top n 可以用limit替代4)查询数据结构考试成绩最高的学生的姓名、所在系、性别和成绩SELECT Sname,Sdept,Ssex,GradeFROM SC INNER JOIN Student s ON SC.Sno = s.SnoWHERE Grade = (SELECT MAX(Grade) FROM SC INNER JOIN Course c ON o = o WHERE Cname = '数据结构')AND Cno = (SELECT Cno FROM Course WHERE Cname = '数据结构')-- 使用排序SELECT Sname,Sdept,Ssex,GradeFROM Student s INNER JOIN SC ON s.Sno = SC.SnoWHERE Cno = (SELECT Cno FROM Course WHERE Cname = '数据结构')GROUP BY Grade DESC LIMIT 1-- mysql没有top n 可以用limit替代17.查询没有选修java课程的学生的姓名和所在系-- 子查询SELECT Sname,SdeptFROM StudentWHERE Sno NOT IN (SELECT Sno FROM SCWHERE Cno = (SELECT Cno FROM Course WHERE Cname = 'Java'))18.查询计算机系没有选课的学生的姓名和性别SELECT Sname,SsexFROM StudentWHERE Sno NOT IN (SELECT Sno FROM SC)19.创建一个新表,表明test_t........CREATE TABLE test_t(COL1 INT,COL2 CHAR(10) NOT NULL,COL3 CHAR(10))INSERT INTO test_t VALUE(NULL,'B1',NULL),(1,'B2','C2'),(2,'B3',NULL)20.删除考试成绩低于50分的学生的选课记录DELETE FROM SCWHERE Grade < 5021.删除没有人选的课程记录DELETE FROM CourseWHERE Cno NOT IN (SELECT Cno FROM SC)22.删除计算机系java成绩不及格学生的java课程选课记录DELETE FROM SCWHERE Sno IN (SELECT Sno FROM Student WHERE Sdept = '计算机系')AND Cno = (SELECT Cno FROM Course WHERE Cname = 'Java')AND Grade < 6023.将第二学期开设的所有课程的学分增加2分UPDATE Course SET Credit = Credit + 2WHERE Semester = 224.将java课程的学分改为3分UPDATE Course SET Credit = 3WHERE Cname = 'Java'25.将计算机系的学生的年龄增加一岁UPDATE Student SET Sage = Sage + 1WHERE Sdept = '计算机系'26.将信息系学生的计算机文化学课程的考试成绩加5分UPDATE SC SET Grade = Grade + 5WHERE Sno IN (SELECT Sno FROM Student WHERE Sdept = '信息系')AND Cno = (SELECT Cno FROM Course WHERE Cname = '计算机文化学')27.查询每个系年龄大于等于20的学生人数,并将结果保存到一个新永久标Dept_ageCREATE TABLE Dept_age (SELECT b.Sdept,IFNULL(人数,0) AS 人数FROM(SELECT Sdept,COUNT(*) AS 人数FROM Student WHERE Sage >= 20 GROUP BY Sdept) a RIGHT OUTER JOIN (SELECT DISTINCT Sdept FROM Student) b ON a.Sdept = b.Sdept)SELECT * FROM Dept_age-- mysql不支持select into from28.查询计算机系每个学生的java考试情况,列出学号、姓名、成绩和成绩情况>=90(好)80-89(较好)70-79(一般)60-69(较差)<60(差)SELECT s.Sno,Sname,Grade,CASEWHEN Grade >= 90 THEN '优'WHEN Grade BETWEEN 80 AND 89 THEN '较好'WHEN Grade BETWEEN 70 AND 79 THEN '一般'WHEN Grade BETWEEN 60 AND 69 THEN '较差'WHEN Grade < 60 THEN '差'END AS 成绩情况FROM Student s INNER JOIN SC ON s.Sno = SC.SnoWHERE Cno = (SELECT Cno FROM Course WHERE Cname = 'Java')29.统计每个学生的选课门数(包括没有选课的人),列出学号、选课门数和选课情况>=6(多)3-5(一般)1-2(偏少)0(未选课)SELECT s.Sno,IFNULL(COUNT(*),0) AS 选课门数,CASEWHEN COUNT(*) >= 6 THEN '多'WHEN COUNT(*) BETWEEN 3 AND 5 THEN '一般'WHEN COUNT(*) BETWEEN 1 AND 2 THEN '偏少'WHEN COUNT(*) IS NULL THEN '未选课'END AS 选课情况FROM Student s LEFT OUTER JOIN SC ON s.Sno = SC.SnoGROUP BY Sno30.修改全部课程的学分,修改规则如下:1-2学期开设的课程加5分3-4学期开设的课程加3分5-6学期开设的课程加1分其余不变UPDATE Course SET Credit = Credit +CASEWHEN Semester BETWEEN 1 AND 2 THEN 5WHEN Semester BETWEEN 3 AND 4 THEN 3WHEN Semester BETWEEN 5 AND 6 THEN 5ELSE 0END31.查询李勇和王大力所选的全部课程,列出课程名、开课学期和学分,不包括重复结果SELECT Cname,Semester,CreditFROM CourseWHERE Cno IN (SELECT Cno FROM SC WHERE Sno IN (SELECT Sno FROM Student WHERE Sname = '李勇' OR Sname = '王大力'))-- 并运算SELECT Cname,Semester,Credit FROM CourseWHERE Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '李勇'))UNIONSELECT Cname,Semester,Credit FROM CourseWHERE Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '王大力'))32.查询第3学期开设的课程中,李勇选了但王大力没选的课程,列出课程名和学分SELECT Cname,CreditFROM CourseWHERE Semester = 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '李勇'))AND Cno NOT IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '王大力'))-- 差运算mysql不支持EXCEPTSELECT Cname,CreditFROM CourseWHERE Semester = 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '李勇'))EXCEPTSELECT Cname,CreditFROM CourseWHERE Semester = 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '王大力'))33.查询学分大于3分的课程中,李勇和王大力所选的相同课程,列出课程名和学分SELECT Cname,CreditFROM CourseWHERE Credit > 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '李勇'))AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '王大力'))-- 交运算mysql不支持INTERSECTSELECT Cname,CreditFROM CourseWHERE Credit > 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '李勇'))INTERSECTSELECT Cname,CreditFROM CourseWHERE Credit > 3AND Cno IN (SELECT Cno FROM SC WHERE Sno = (SELECT Sno FROM Student WHERE Sname = '王大力'))。

第一部分基础理论第1章数据库概述1.试说明数据、数据库、数据库管理系统和数据库系统的概念。
数据:描述事务的符号记录数据库:存储数据的仓库数据库管理系统:用于管理和维护数据的系统软件数据库系统:计算机中引入数据库后的系统,包括数据库,数据库管理系统,应用程序,数据库管理员2.数据管理技术的发展主要经历了哪几个阶段?两个阶段,文件管理和数据库管理9.数据独立性指的是什么?应用程序不因数据的物理表示方式和访问技术改变而改变,分为逻辑独立性和物理独立性。
物理独立性是指当数据的存储结构或存储位置发生变化时,不影响应用程序的特性;逻辑独立性是指当表达现实世界的信息内容发生变化时,不影响应用程序的特性。
10.数据库系统由哪几部分组成?由数据库、数据库管理系统、应用程序、数据库管理员组成。
第2章数据模型与数据库系统的结构4.说明实体一联系模型中的实体、属性和联系的概念。
实体是具有公共性质的并可相互区分的现实世界对象的集合。
属性是实体所具有的特征或性质。
联系是实体之间的关联关系。
6.数据库系统包含哪三级模式?试分别说明每一级模式的作用。
外模式、模式和内模式。
外模式:是对现实系统中用户感兴趣的整体数据结构的局部描述,用于满足不同用户对数据的需求,保证数据安全。
模式:是数据库中全体数据的逻辑结构和特征的描述,它满足所有用户对数据的需求。
内模式:是对整个数据库的底层表示,它描述了数据的存储结构。
7.数据库管理系统提供的两级映像的作用是什么?它带来了哪些功能?两级映像是外模式/模式映像和模式/内模式映像。
外模式/模式映像保证了当模式发生变化时可以保证外模式不变,从而使用户的应用程序不需要修改,保证了程序与数据的逻辑独立性。
模式/内模式映像保证了当内模式发生变化,比如存储位置或存储文件名改变,可以保持模式不变,保证了程序与数据的物理独立性。
两级印象保证了应用程序的稳定性。
第3章关系数据库1.试述关系模型的三个组成部分。
数据结构、关系操作集合、关系完整性约束2.解释下列术语的含义:(3)候选码当一个属性或属性集的值能够唯一标识一个关系的元组,而又不包含多余的元素,则称该属性或属性集为候选码。
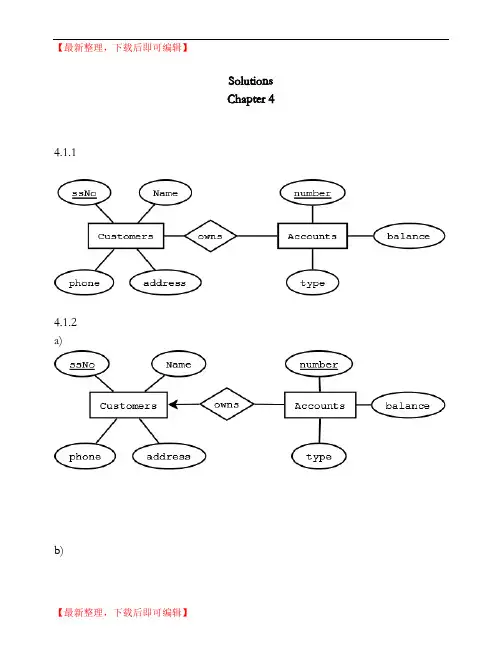
【最新整理,下载后即可编辑】SolutionsChapter 4 4.1.14.1.2a)b)c)In c we assume that a phone and address can only belong to a single customer (1-m relationship represented by arrow into customer).d)In d we assume that an address can only belong to one customer and a phone can exist at only one address.If the multiplicity of above relationships were m-to-n, the entity set becomes weak and the key ssNo of customers will be needed as part of the composite key of the entity set.In c&d, we convert attributes phones and addresses to entity sets. Since entity sets often become relations in relational design,we must consider more efficient alternatives.Instead of querying multiple tables where key values are duplicated, we can also modify attributes:(i) Phones attribute can be converted into HomePhone, OfficePhone and CellPhone.(ii) A multivalued attribute such as alias can be kept as an attribute where a single column can be used in relational design i.e. concatenate all values. SQL allows a query "like '%Junius%'" to search the multiple values in a column alias.4.1.34.1.4a)b)c)The relationship "played" between Teams and Players is similar to relationship "plays" between Teams and Players.4.1.54.1.6 The information about children can be ascertained from motherOf and fatherOf relationships. Attribute ssNo is required since names are not unique.4.1.74.1.8a)(b)4.1.9AssumptionsA Professor only works in at most one department.A course has at most one TA.A course is only taught by one professor and offered by one department. Students and professors have been assigned unique email ids.A course is uniquely identified by the course no, section no, and semester (e.g. cs157-3 spring 09).4.1.10Given that for each movie, a unique studio exists that produces the movie. Each star is contracted to at most one studio.But stars could be unemployed at a given time. Thus the four-way relationship in fig 4.6 can be easily into converted equivalent relationships.4.2.1Redundancy: The owner address is repeated in AccSets and Addresses entity sets. Simplicity: AccSets does not serve any useful purpose and the design can be more simply represented by creating many-to-many relationship between Customers and Accounts.Right kind of element: The entity set Addresses has a single attribute address. A customer cannot have more than one address.Hence address should be an attribute of entity set Customers. Faithfulness: Customers cannot be uniquely identified by their names. In real world Customers would have a unique attribute such as ssNo or customerNo 4.2.2Studios and Presidents can be combined into one entity set Studios with Presidents becoming an attribute of Studios under following circumstances:1. The Presidents entity set only contains a simple attribute viz. presidentName. Additional attributes specific to Presidents might justify making Presidents into an entity set.4.2.34.2.4 The entity sets should have single attribute.a) Stars: starNameb) Movies: movieNamec) Studios: studioName. However there exists a many-to-many relationship between Studios and Contracts. Hence, in addition, we need more informationabout studios involved. If a contract always involves two studios, two attributes such as producingStudio and starStudio can replace theStudios entity set. If a contact can be associated with at most five studios, it may be possible to replace the Studios entity set by five attributes viz. studio1, studio2, studio3, studio4, and studio5. Alternately, a composite attribute containing concatenation of all studio names in a contact can be considered. A separator character such as "$" can be used. SQL allows searching of such an attribute using query like '%keyword%'4.2.5From Augmentation rule of Functional Dependency,givenB -> M (B=Baby, M=Mother)thenBND -> M (N=Nurse, D=Doctor)Hence we can just put an arrow entering mother.a) Put an arrow entering entity set Mothers for the simplest solution (As in fig. 4.4, where a multi-way relationship was allowed, even though Movies alone could identify the Studio). However, we can display more accurate information with below figure.b)c)Again from Augmentation rule of Functional Dependency, givenBM -> DthenBMN -> DThus we can just add an arrow entering Doctors to fig 4.15. Below figure represents more accurate information however.4.2.6a)b) Transitivity and Augmentation rules of Functional Dependency allow arrow entering Mothers from Births. However, a new relationship in below figure represents more accurate information.c)Design flaws in abc above 1. As suggested above, using Transitivity and Augmentation rules of Functional Dependency, much simpler design is possible.4.2.7In below figure there exists a many-to-one relationship between Babies and Births and another many-to-one relationship between Births and Mothers. From transitivity of relationships, there is a many-to-one relationship between Babiesand Mothers. Hence a baby has a unique mother while a birth can allow more than one baby.4.3.1a)b)A captain cannot exist without a team. However a player can (free agent). A recently formed (or defunct) team can exist without players or colors.c)Children can exist without mother and father (unknown).4.3.2a)The keys of both E1 and E2 are required for uniquely identifying tuples in R b)The key of E1c)The key of E2d)The key of either E1 or E24.3.3Special Case: All entity sets have arrows going into them i.e. all relationships are 1-to-1Any KiOtherwise: Combination of all Ki's where there does not exist an arrow going from R to Ei.4.4.1No, grade is not part of the key for enrollments. The keys of Students and Courses become keys of the weak entity set Enrollments.4.4.2It is possible to make assignment number a weak key of Enrollments but this is not good design (redundancy since multiple assignments correspond to a course).A new entity set Assignment is created and it is also a weak entity set. Hence the key attributes of Assignment will come from the strong entity sets to which Enrollments is connected i.e. studentID, dept, and CourseNo.4.4.3a)b)c)4.4.4a)b)4.5.1Customers(SSNo,name,addr,phone)Flights(number,day,aircraft)Bookings(custSSNo,flightNo,flightDay,row,seat)Relations for toCust and toFlt relationships are not required since the weak entity set Bookings already contains the keys of Customers and Flights.4.5.2(a)(b)Schema is changed. Since toCust is no longer an identifying relationship, SSNo is no longer a part of Bookings relation.Bookings(flightNo,flightDay,row,seat)ToCust(custSSNO,flightNo,flightDay,row,seat)The above relations are merged intoBookings(flightNo,flightDay,row,seat,custSSNo)However custSSNo is no longer a key of Bookings relation. It becomes a foreign key instead.4.5.3Ships(name, yearLaunched)SisterOf(name, sisterName)4.5.4(a)Stars(name,addr)Studios(name,addr)Movies(title,year,length,genre)Contracts(starName,movieTitle,movieYear,studioName,salary)Depending on other relationships not shown in ER diagram, studioName may not be required as a key of Contracts (or not even required as an attribute of Contracts).(b)Students(studentID)Courses(dept,courseNo)Enrollments(studentID,dept,courseNo,grade)(c)Departments(name)Courses(deptName,number)(d)Leagues(name)Teams(leagueName,teamName)Players(leagueName,teamName,playerName)4.6.1The weak relation Courses has the key from Depts along with number. Hence there is no relation for GivenBy relationship.(a)Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)(b) LabCourses has all the attributes of Courses.Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)(c) Courses and LabCourses are combined into one relation.Depts(name, chair)Courses(number, deptName, room, allocation)4.6.2(a)Person(name,address)ChildOf(personName,personAddress,childName,childAddress)Child(name,address,fatherName,fatherAddress,motherName,motherAddresss) Father(name,address,wifeName,wifeAddresss)Mother(name,address)Since FatherOf and MotherOf are many-one relationships from Child, there is no need for a separate relation for them. Similarly the one-one relationship Married can be included in Father (or Mother). ChildOf is a many-many relationship and needs a separate relation.However the ChildOf relation is not required since the relationship can be deduced from FatherOf and MotherOf relationships contained in Child relation.(b)A person cannot be both Mother and Father.Person(name,address)PersonChild(name,address)PersonChildFather(name,address)PersonChildMother(name,address)PersonFather(name,address)PersonMother(name,address)ChildOf(personName,personAddress,childName,childAddress)FatherOf(childName,childAddress,fatherName,fatherAddress)MotherOf(childName,childAddress,motherName,motherAddress)Married(husbandName,husbandAddress,wifeName,wifeAddress)The many-many ChildOf relationship again requires a relation.An entity belongs to one and only one class when using object-oriented approach. Hence, the many-one relations MotherOf and FatherOf could be added as attributes to PersonChild,PersonChildFather, and PersonChildMother relations.Similarly the Married relation can be added as attributes to PersonChildMother and PersonMother (or the corresponding father relations).(c) For the Person relation at least one of husband and wife attributes will be null. Person(personName,personAddress,fatherName,fatherAddress,motherName,mot herAddresss,wifeName,wifeAddresss,husbandName,husbandAddress) ChildOf(personName,personAddress,childName,childAddress)4.6.3(a)People(name,fatherName,motherName)Males(name)Females(name)Fathers(name)Mothers(name)ChildOf(personName,childName)(b)People(name)PeopleMale(name)PeopleMaleFathers(name)PeopleFemale(name)PeopleFemaleMothers(name)ChildOf(personName,childName)FatherOf(childName,fatherName)MotherOf(childName,motherName)People cannot belong to both male and female branch of the ER diagram. Moreover since an entity belongs to one and only one class when using object-oriented approach, no entity belongs to People relation.Again we could replace MotherOf and FatherOf relations by adding as attributes to PeopleMale,PeopleMaleFathers,PeopleFemale, and PeopleFemaleMothers relations.(c)People(name,fatherName,motherName)ChildOf(personName,childName)4.6.4(a)Each entity set results in one relation. Thus both the minimum and maximum number of relations is e.The root relation has a attributes including k keys. Thus the minimum number of attributes is a. All other relations include the k keys from root along with their a attributes. Thus the maximum number of attributes is a+k.(b)The relation for root will have a attributes. The relation representing the whole tree will have e*a attributes.The number of relations will depend on the shape of the tree. A tree of e entities where only one child exists(say left child only) would have the minimum number of relations. Thus below figure will only contain 4 subtrees that contain rootE1,E1E2,E1E2E3, and E1E2E3E4. With e entity sets, minimum e relations are possible.The maximum number of subtrees result when all the entities(except root) are at depth 1. Thus below figure will contain 8 subtrees that contain rootE1,E1E2,E1E3,E1E4,E1E2E3,E1E3E4,E1E2E4,and E1E2E3E4. With e entity sets, maximum 2^(e-1) relations are possible.The nulls method always results in one relation and contains attributes from all e entities i.e. e*a attributes.Summarizing for a,b, and c above;#Components #RelationsMin Max Min MaxMethodstraight-E/R a a e eobject-oriented a e*a e 2^(e-1)nulls e*a e*a 1 14.7.14.7.2a)b)c)d)4.7.34.7.44.7.5Males and Females subclasses are complete. Mothers and Fathers are partial. All subclasses are disjoint.4.7.6。
第1章绪论1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据(Data ) :描述事物的符号记录称为数据。
数据的种类有数字、文字、图形、图像、声音、正文等。
数据与其语义是不可分的。
解析在现代计算机系统中数据的概念是广义的。
早期的计算机系统主要用于科学计算,处理的数据是整数、实数、浮点数等传统数学中的数据。
现代计算机能存储和处理的对象十分广泛,表示这些对象的数据也越来越复杂。
数据与其语义是不可分的。
500 这个数字可以表示一件物品的价格是500 元,也可以表示一个学术会议参加的人数有500 人,还可以表示一袋奶粉重500 克。
( 2 )数据库(DataBase ,简称DB ) :数据库是长期储存在计算机内的、有组织的、可共享的数据集合。
数据库中的数据按一定的数据模型组织、描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。
( 3 )数据库系统(DataBase System ,简称DBS ) :数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。
解析数据库系统和数据库是两个概念。
数据库系统是一个人一机系统,数据库是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统简称为数据库。
希望读者能够从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引起混淆。
( 4 )数据库管理系统(DataBase Management system ,简称DBMS ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包括数据定义功能、数据操纵功能、数据库的运行管理功能、数据库的建立和维护功能。
解析DBMS 是一个大型的复杂的软件系统,是计算机中的基础软件。
目前,专门研制DBMS 的厂商及其研制的DBMS 产品很多。
数据库实用教程课后习题参考答案(1-4章)第1、2章1.1 名词解释:◆ DB:数据库(Database),DB是统一管理的相关数据的集合。
DB能为各种用户共享,具有最小冗余度,数据间联系密切,而又有较高的数据独立性。
◆ DBMS:数据库管理系统(Database Management System),DBMS是位于用户与操作系统之间的一层数据管理软件,为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更新及各种数据控制。
DBMS总是基于某种数据模型,可以分为层次型、网状型、关系型、面向对象型DBMS。
◆ DBS:数据库系统(Database System),DBS是实现有组织地、动态地存储大量关联数据,方便多用户访问的计算机软件、硬件和数据资源组成的系统,即采用了数据库技术的计算机系统。
◆ 1:1联系:如果实体集E1中的每个实体最多只能和实体集E2中的一个实体有联系,反之亦然,好么实体集E1对E2的联系称为“一对一联系”,记为“1:1”。
◆ 1:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中的一个实体有联系,那么E1对E2的联系是“一对多联系”,记为“1:N”。
◆ M:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1对E2的联系是“多对多联系”,记为“M:N”。
◆ 数据模型:表示实体类型及实体类型间联系的模型称为“数据模型”。
它可分为两种类型:概念数据模型和结构数据模型。
◆ 概念数据模型:它是独门于计算机系统的模型,完全不涉及信息在系统中的表示,只是用来描述某个特定组织所关心的信息结构。
◆ 结构数据模型:它是直接面向数据库的逻辑结构,是现实世界的第二层抽象。
这类模型涉及到计算机系统和数据库管理系统,所以称为“结构数据模型”。
结构数据模型应包含:数据结构、数据操作、数据完整性约束三部分。
习题11、简述数据库系统的特点。
答:数据库系统的特点有:1)数据结构化在数据库系统中,采用统一的数据模型,将整个组织的数据组织为一个整体;数据不再仅面向特定应用,而是面向全组织的;不仅数据内部是结构化的,而且整体是结构化的,能较好地反映现实世界中各实体间的联系。
这种整体结构化有利于实现数据共享,保证数据和应用程序之间的独立性。
2)数据共享性高、冗余度低、易于扩充数据库中的数据能够被多个用户、多个应用程序共享。
数据库中相同的数据不会多次重复出现,数据冗余度降低,并可避免由于数据冗余度大而带来的数据冲突问题。
同时,当应用需求发生改变或增加时,只需重新选择不同的子集,或增加数据即可满足。
3)数据独立性高数据独立性是由DBMS 的二级映像功能来保证的。
数据独立于应用程序,降低了应用程序的维护成本。
4)数据统一管理与控制数据库中的数据由数据库管理系统(DBMS )统一管理与控制,应用程序对数据的访问均经由DBMS 。
DBMS 提供四个方面的数据控制功能:并发访问控制、数据完整性、数据安全性保护、数据库恢复。
2、什么是数据库系统?答:在计算机系统上引入数据库技术就构成一个数据库系统(DataBase System ,DBS )。
数据库系统是指带有数据库并利用数据库技术进行数据管理的计算机系统。
DBS 有两个基本要素:一是DBS 首先是一个计算机系统;二是该系统的目标是存储数据并支持用户查询和更新所需要的数据。
3、简述数据库系统的组成。
答:数据库系统一般由数据库、数据库管理系统(及其开发工具)、数据库管理员(DataBase Administrator ,DBA )和用户组成。
4、试述数据库系统的三级模式结构。
这种结构的优点是什么?答:数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三级构成,同时包含了二级映像,即外模式/模式映像、模式/内模式映像,如下图所示。
数据库应用1……外模式A 外模式B 模式应用2应用3应用4应用5……模式外模式/模式映像模式/内模式映像数据库系统的这种结构具有以下优点:(1)保证数据独立性。
第1章数据库概论1.1 基本内容分析1.1.1 本章的重要概念(1)DB、DBMS和DBS的定义(2)数据管理技术的发展阶段人工管理阶段、文件系统阶段、数据库系统阶段和高级数据库技术阶段等各阶段的特点。
(3)数据描述概念设计、逻辑设计和物理设计等各阶段中数据描述的术语,概念设计中实体间二元联系的描述(1:1,1:N,M:N)。
(4)数据模型数据模型的定义,两类数据模型,逻辑模型的形式定义,ER模型,层次模型、网状模型、关系模型和面向对象模型的数据结构以及联系的实现方式。
(5)DB的体系结构三级结构,两级映像,两级数据独立性,体系结构各个层次中记录的联系。
(6)DBMSDBMS的工作模式、主要功能和模块组成。
(7)DBSDBS的组成,DBA,DBS的全局结构,DBS结构的分类。
1.1.2本章的重点篇幅(1)教材P23的图1.24(四种逻辑数据模型的比较)。
(2)教材P25的图1.27(DB的体系结构)。
(3)教材P28的图1.29(DBMS的工作模式)。
(4)教材P33的图1.31(DBS的全局结构)。
1.2 教材中习题1的解答1.1 名词解释·逻辑数据:指程序员或用户用以操作的数据形式。
·物理数据:指存储设备上存储的数据。
·联系的元数:与一个联系有关的实体集个数,称为联系的元数。
·1:1联系:如果实体集E1中每个实体至多和实体集E2中的一个实体有联系,反之亦然,那么E1和E2的联系称为“1:1联系”。
·1:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中一个实体有联系,那么E1和E2的联系是“1:N联系”。
·M:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1和E2的联系称为“M:N联系”。
·数据模型:能表示实体类型及实体间联系的模型称为“数据模型”。
!SolutionsChapter 4c we assume that a phone and address can only belong to a single customer (1-m relationship represented by arrow into customer).;……( # d) }In d we assume that an address can only belong to one customer and a phone can exist at only one address.If the multiplicity of above relationships were m-to-n, the entity set becomes weak and the key ssNo of customers will be needed as part of the composite key of the entity set.In c&d, we convert attributes phones and addresses to entity sets. Since entity sets often become relations in relational design,we must consider more efficient alternatives.Instead of querying multiple tables where key values are duplicated, we can also modify attributes:(i) Phones attribute can be converted into HomePhone, OfficePhone and CellPhone.(ii) A multivalued attribute such as alias can be kept as an attribute where a single column can be used in relational design . concatenate all values. SQL allows a query "like '%Junius%'" to search the multiple values in a column alias.:…《a)—b)c)、The relationship "played" between Teams and Players is similar to relationship "plays" between Teams and Players.、The information about children can be ascertained from motherOf and fatherOf relationships. Attribute ssNo is required since names are not unique.,%~Professor only works in at most one department.…A course has at most one TA.A course is only taught by one professor and offered by one department.Students and professors have been assigned unique email ids.A course is uniquely identified by the course no, section no, and semester . cs157-3 spring 09).$、(`that for each movie, a unique studio exists that produces the movie. Each star is contracted to at most one studio.But stars could be unemployed at a given time. Thus the four-way relationship in fig can be easily into converted equivalent relationships.(The owner address is repeated in AccSets and Addresses entity sets.Simplicity: AccSets does not serve any useful purpose and the design can be more simply represented by creating many-to-many relationship between Customers and Accounts.(Right kind of element: The entity set Addresses has a single attribute address. A customer cannot have more than one address.Hence address should be an attribute of entity set Customers.Faithfulness: Customers cannot be uniquely identified by their names. In real world Customers would have a unique attribute such as ssNo or customerNoand Presidents can be combined into one entity set Studios with Presidents becoming anattribute of Studios under following circumstances:1. The Presidents entity set only contains a simple attribute viz. presidentName. Additional attributes specific to Presidents might justify making Presidents into an entity set.{The entity sets should have single attribute.a) Stars: starNameb) Movies: movieNamec) Studios: studioName. However there exists a many-to-many relationship between Studios and Contracts. Hence, in addition, we need more information about studios involved. If a contract always involves two studios, two attributes such as producingStudio and starStudio can replace theStudios entity set. If a contact can be associated with at most five studios, it may be possible to replace the Studios entity set by five attributes viz. studio1, studio2, studio3, studio4, and studio5. Alternately, a composite attribute containing concatenation of all studio names in a contact can be considered. A separator character such as "$" can be used. SQL allows searching of such an attribute using query like '%keyword%'|)Augmentation rule of Functional Dependency,given$B -> M (B=Baby, M=Mother)thenBND -> M (N=Nurse, D=Doctor)Hence we can just put an arrow entering mother.a) Put an arrow entering entity set Mothers for the simplest solution (As in fig. , where amulti-way relationship was allowed, even though Movies alone could identify the Studio). However, we can display more accurate information with below figure.》》?b).{ 【~; c)Again from Augmentation rule of Functional Dependency,givenBM -> DthenBMN -> DThus we can just add an arrow entering Doctors to fig . Below figure represents more accurate information however.】Transitivity and Augmentation rules of Functional Dependency allow arrow entering Mothers from Births. However, a new relationship in below figure represents more accurate information.【c)Design flaws in abc above 1. As suggested above, using Transitivity and Augmentation rules of Functional Dependency, much simpler design is possible.[…In below figure there exists a many-to-one relationship between Babies and Births and another many-to-one relationship between Births and Mothers. From transitivity of relationships, thereis a many-to-one relationship between Babies and Mothers. Hence a baby has a unique mother while a birth can allow more than one baby./captain cannot exist without a team. However a player can (free agent). A recently formed (or defunct) team can exist without players or colors.c)Children can exist without mother and father (unknown).'keys of both E1 and E2 are required for uniquely identifying tuples in R (b)The key of E1c)The key of E2d)~The key of either E1 or E2Case: All entity sets have arrows going into them . all relationships are 1-to-1Any KiOtherwise: Combination of all Ki's where there does not exist an arrow going from R to Ei.)grade is not part of the key for enrollments. The keys of Students and Courses become keys of the weak entity set Enrollments.}It is possible to make assignment number a weak key of Enrollments but this is not good design (redundancy since multiple assignments correspond to a course). A new entity set Assignment iscreated and it is also a weak entity set. Hence the key attributes of Assignment will come from the strong entity sets to which Enrollments is connected . studentID, dept, and CourseNo.,,~for toCust and toFlt relationships are not required since the weak entity set Bookings already contains the keys of Customers and Flights.is changed. Since toCust is no longer an identifying relationship, SSNo is no longer a part of Bookings relation.Bookings(flightNo,flightDay,row,seat)ToCust(custSSNO,flightNo,flightDay,row,seat)The above relations are merged intoBookings(flightNo,flightDay,row,seat,custSSNo)<However custSSNo is no longer a key of Bookings relation. It becomes a foreign key instead.Ships(name, yearLaunched)SisterOf(name, sisterName)%…on other relationships not shown in ER diagram, studioName may not be required as a key of Contracts (or not even required as an attribute of Contracts).*(b)Students(studentID)Courses(dept,courseNo)Enrollments(studentID,dept,courseNo,grade)(c)Departments(name)Courses(deptName,number){(d)Leagues(name)Teams(leagueName,teamName)Players(leagueName,teamName,playerName)weak relation Courses has the key from Depts along with number. Hence there is no relation for GivenBy relationship.(a)^Depts(name, chair)Courses(number, deptName, room)LabCourses(number, deptName, allocation)(b) LabCourses has all the attributes of Courses.Depts(name, chair)·Courses(number, deptName, room)LabCourses(number, deptName, room, allocation)(c) Courses and LabCourses are combined into one relation.Depts(name, chair)Courses(number, deptName, room, allocation)?、FatherOf and MotherOf are many-one relationships from Child, there is no need for a separate relation for them. Similarly the one-one relationship Married can be included in Father (or Mother). ChildOf is a many-many relationship and needs a separate relation.!However the ChildOf relation is not required since the relationship can be deduced from FatherOf and MotherOf relationships contained in Child relation.(b)A person cannot be both Mother and Father.Person(name,address)PersonChild(name,address)PersonChildFather(name,address);PersonChildMother(name,address)PersonFather(name,address)PersonMother(name,address)ChildOf(personName,personAddress,childName,childAddress)FatherOf(childName,childAddress,fatherName,fatherAddress)MotherOf(childName,childAddress,motherName,motherAddress)Married(husbandName,husbandAddress,wifeName,wifeAddress)》The many-many ChildOf relationship again requires a relation.An entity belongs to one and only one class when using object-oriented approach. Hence, the many-one relations MotherOf and FatherOf could be added as attributes toPersonChild,PersonChildFather, and PersonChildMother relations.Similarly the Married relation can be added as attributes to PersonChildMother and PersonMother (or the corresponding father relations).(c) For the Person relation at least one of husband and wife attributes will be null.^Person(personName,personAddress,fatherName,fatherAddress,motherName,motherAddresss,wifeName,wife Addresss,husbandName,husbandAddress)ChildOf(personName,personAddress,childName,childAddress):—cannot belong to both male and female branch of the ER diagram.Moreover since an entity belongs to one and only one class when using object-oriented approach, no entity belongs to People relation.Again we could replace MotherOf and FatherOf relations by adding as attributes toPeopleMale,PeopleMaleFathers,PeopleFemale, and PeopleFemaleMothers relations.(c)People(name,fatherName,motherName)ChildOf(personName,childName))entity set results in one relation. Thus both the minimum and maximum number of relations is e. The root relation has a attributes including k keys. Thus the minimum number of attributes is a. All other relations include the k keys from root along with their a attributes. Thus the maximum number of attributes is a+k.:、—(b)The relation for root will have a attributes. The relation representing the whole tree will have e*a attributes.The number of relations will depend on the shape of the tree. A tree of e entities where only one child exists(say left child only) would have the minimum number of relations. Thus below figure will only contain 4 subtrees that contain root E1,E1E2,E1E2E3, and E1E2E3E4. With eentity sets, minimum e relations are possible.The maximum number of subtrees result when all the entities(except root) are at depth 1. Thus below figure will contain 8 subtrees that contain rootE1,E1E2,E1E3,E1E4,E1E2E3,E1E3E4,E1E2E4,and E1E2E3E4. With e entity sets, maximum 2^(e-1) relations are possible.](c)The nulls method always results in one relation and contains attributes from all e entities . e*a attributes.Summarizing for a,b, and c above;,#Components #RelationsMin Max Min Max Methodstraight-E/R a a e e object-oriented a e*a e 2^(e-1) nulls e*a e*a 1 1?'):{}and Females subclasses arecomplete. Mothers and Fathers are partial. All subclasses are disjoint.、}convert the ternary relationship Contracts into three binary relationships between a new entity set Contracts and existing entity sets.self-association ParentOf for entity set people has multiplicity 0..2 at parent role end.In a Library database, if a patron can loan at most 12 books, them multiplicity is 0..12.For a FullTimeStudents entity set, a relationship of multiplicity 5..* must exist with Courses (A student must take at least。