SPSS在游程检验中的剖析
- 格式:ppt
- 大小:1.01 MB
- 文档页数:17

市场有效性检验游程检验在金融中主要用于检验市场有效性,比如检验证券市场,外汇市场,黄金期货市场等的有效性。
为什么会用游程检验检验市场有效性呢?下面我就从市场有效性的概念做一下解释。
所谓有效市场,就是市场价格波动服从随机游走趋势,市场价格总是能反映可获得的信息。
如果市场中的价格不能充分反映可获得的信息,投资者则可以利用技术分析的方法获得超额利润。
对市场有效性的检验,就是从统计上检验市场价格波动是否服从随机游走趋势,因此可以用游程检验来检验市场有效性。
下面我就检验股票市场有效性来介绍一下游程检验在金融中的应用。
市场有效性按其强弱程度可分为弱式有效、半强势有效、强势有效三种。
要检验市场有效性,必须先检验市场是否具有弱式有效性市场,若无弱式有效性,那就更谈不上强式有效性。
因此对我国市场有效性检验应从弱式有效性检验入手。
在弱式有效市场的假设下,当前的价格充分反映了全部历史时间序列信息都包括在当前的价格变化之中了。
因此,过去、现在和未来的价格变化之间是没有关系的,价格变化是相互独立的,也就是随机的,技术分析交易规则是无效的。
一.检验方法市场弱式有效性检验的检验方法一般包括两种:一是对随机误差项{}ε序列进行相关性检验,考察是否从在序列自相关;二是进行游t程检验(Runs test),考察股票市场是否通过该检验,并据此判断中国市场是否达到了弱式有效有效性。
游程检验可以避免时间序列相关性检验的两个缺点,一是可能受异常值干扰,但在相关系数中不能反映;二是可能收到有限方差存在与否的影响。
本文只对游程检验方法做一下探讨。
Geary(1970)采用游程检验来检验时间序列中的自相关性,以检验这些序列是否是纯随机的。
如果对时间序列进行游程检验后发现,该序列的游程数显著小于纯随机时间序列游程数的数学期望,则说明该时间序列呈现出持续地随趋势变动的特征,容易发生同方向的持续变化,时间序列具有正的自相关性;反之,如果该序列的游程数显著大于纯随机时间序列游程数的数学期望,则说明该时间序列呈现出反转和均值回复的特征,时间序列具有负的自相关性。

一、统计报告l 在线分析处理报告Analyze→Reports→OLAP Cubesl 个案摘要报告Analyze→Reports→Summarize Casesl 行形式摘要报告Analyze→Reports→Report Summaries in Rowsl 列形式摘要报告Analyze→Reports→Report Summaries in Columns二、描述性统计分析1.频数分析Analyze→Descriptive Statistic→Frequencies(1)频度分布表(2)变量描述统计量的计算(3)显示频度的图形2.基本描述统计量Analyze→Descriptive Statistic→Descriptivesl 集中趋势(Central T endency)的统计量l 离散趋势(Dispersion)的统计量l 分布形态(Distribution)的统计量3.探索性分析Analyze→Descriptive Statistic→Explorel 茎叶图l 箱图l 正态分布检验Q-Q概率图l 方差齐性检验的散点-分层图4.交叉列联表分析Analyze→Descriptive Statistic→Crosstabs三、两总体均值比较l 单样本T检验Analyze→Compare Means→One-Sample T T estl 独立样本T检验Analyze→Compare Means→Independen t-Samples T T est l 配对样本T检验Analyze→Compare Means→Paired-Samples T T est四、方差分析l 单因素方差分析Analyze→Compare Means→One-way ANOV Al 多因素方差分析Analyze→General Linear Model→Univariatel 协方差分析Analyze→General Linear Model→Univariateu 假设检验的步骤1.提出原假设和备择假设对每个假设检验问题,一般可同时提出两个相反的假设:●原假设原假设又称零假设,是正待检验的假设,记为H0●备择假设备择假设是拒绝原假设后可供选择的假设,记为H1 。


SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以p为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Sp处理:第一步:定义变量我们知道在p中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段()以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明.1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value、Miing两项不设置即可.2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在p中的具体操作.比如如下一例:请问您通常获取新闻的方式有哪些()1报纸2杂志3电视4收音机5网络在p中设置变量时可为此题设置五个变量,假如此题为问卷第三题,那么变量名分别为3_1、3_2、3_3、3_4、3_5,然后每一个选项有两个选项选中和不选中,只需在Value一项中为每一个变量设置成1=选中此项、0=不选中此项即可.使用该窗口,我们可以把一个问卷中的所有问题作为变量在这个窗口中一次定义。
第二步:数据录入Sp数据录入有很多方式,大致有一下几种:1.读取SPSS格式的数据2.读取E某cel等格式的数据3.读取文本数据(Fi某ed和Delimiter)4.读取数据库格式数据(分如下两步)(1)配置ODBC(2)在SPSS中通过ODBC和数据库进行但是对于问卷的数据录入其实很简单,只要在p的数据录入窗口中直接输入就可以了,只是在这里有几点注意的事项需要说明一下.1.在数据录入窗口,我们可以看到有一个表格,这个表格中的每一行代表一份问卷,我们也称为一个个案.在数据录入完成后,我们要做的就是我们的关键部分,即问卷的统计分析了,因为这时我们已经把问卷中的数据录入我们的软件中了.第三步:统计分析有了数据,可以利用SPSS的各种分析方法进行分析,但选择何种统计分析方法,即调用哪个统计分析过程,是得到正确分析结果的关键。

如何用SPSS探测及检验异常值一、采用数据探索过程探测异常值SPSS菜单实现程序为: 主菜单–>“Analyze”–>“Descriptive Statistics”–>“Explore……”选项–>“Statistics”按钮–>选中“Outliers”复选框。
输出结果中将列出5个最大值和5个最小值作为异常的嫌疑值。
二、采用箱线图(boxplot)探测异常值箱线图比较直观、形象,易于理解,因此它在统计分析中占有非常重要的地位。
1. 利用上述的数据探测过程,在“Explore”对话框中单击“Plots”,出现如图2所示的对话框,通过“Boxplots”方框可以确定箱线图的生成方式。
“Factor levels together”复选框表示将要为每个因变量创建一个箱线图,“Dependent together”复选框表示将为每个分组变量水平创建箱线图,“None”复选框表示不创建箱线图。
2. 直接利用SPSS中的画图功能实现箱线图,SPSS给出了两种箱线图,一种是基本箱线图,另一种是交互式箱线图。
基本箱线图的SPSS菜单实现为:点击主菜单中的“Graphs”选项,在弹出的一级菜单中选择“Boxplot……”选项。
交互式箱形图的SPSS菜单实现为:点击主菜单中的“Graphs”选项,在弹出的一级菜单中点击“Interactive”选项,在弹出的二级菜单中选择“Boxplot……”选项。
下面仍以A公司雇员分工种的开始工资为例构造基本箱线图(如图3)。
箱线图中的“○”表示可疑的异常值,此处异常值的确定采用的是“五数概括法”,即:变量值超过第75百分位点和25百分位点上变量值之差的1.5倍(箱体上方)或变量值小于第75百分位点和25百分位点上变量值之差的1.5倍(箱体下方)的点对应的值。
三、SPSS 14 后的新功能Data –> Validation:???如何设置。


《统计分析与SPSS的应用》实验报告班级:090911学号:09091141姓名:律江山评分:南昌航空大学经济管理学院南昌航空大学经济管理学院学生实验报告实验课程名称:统计分析与SPSS的应用专业经济学班级学号09091141 姓名律江山成绩实验地点G804 实验性质:演示性 验证性综合性设计性实验项目名称基本统计分析(交叉分组下的频数分析)指导教师周小刚一、实验目的掌握利用SPSS 软件进行基本统计量均值与均值标准误、中位数、众数、全距、方差和标准差、四分位数、十分位数和百分位数、频数、峰度、偏度的计算,进行标准化Z分数及其线形转换,统计表、统计图的显示。
二、实验内容及步骤(包括实验案例及基本操作步骤)(1)实验案例:居民储蓄存款。
(2)基本步骤:1、单击菜单选项analyze→descriptive statistics→crosstabs2、选择行变量到row(s)框中,选择列变量到column(s)框中3、选择dispiay clustered bar charts选项,指定绘制各变量交叉分组下的频数分布棒图。
三、实验结论(包括SPSS输出结果及分析解释)实验结论:较大部分储户认为在未来收入会基本不变,收入会增加的比例高于会减少的比例;城镇储户中认为收入会增加的比例高于会减少的比例,但农村储户恰恰相反;可见城镇和农村储户在对该问题的看法上存在分歧。
城镇户口较内存户口收入有明显的增加,但未来收入减少的比例差距不大。
其中二者未来收入大部分基本保持不变。
实验课程名称:统计分析与SPSS的应用专业经济学班级学号09091141 姓名律江山成绩实验地点G804 实验性质:演示性 验证性综合性设计性实验项目名称参数检验(两独立样本T检验)指导教师周小刚一、实验目的掌握利用 SPSS 进行单样本 T 检验、两独立样本 T 检验和两配对样本 T 检验的基本方法,并能够解释软件运行结果。
利用来自两个总体的独立样本,推断两个总体的均值是否存在显着差异。


SPSS分析调查问卷数据的方法(2012-05-29 21:45:13)分类:学习标签:杂谈当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Spss处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类). 我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段( )?A:20—29 B:30—39 C:40—49 D:50--59那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width 宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。
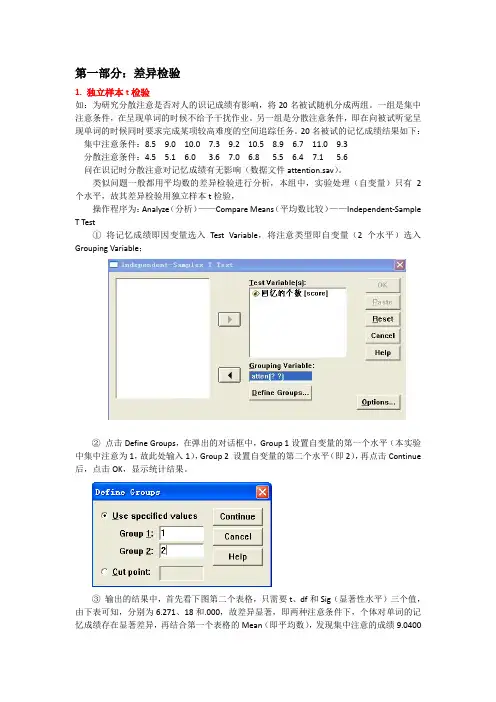
第一部分:差异检验1. 独立样本t检验如:为研究分散注意是否对人的识记成绩有影响,将20名被试随机分成两组。
一组是集中注意条件,在呈现单词的时候不给予干扰作业。
另一组是分散注意条件,即在向被试听觉呈现单词的时候同时要求完成某项较高难度的空间追踪任务。
20名被试的记忆成绩结果如下:集中注意条件:8.5 9.0 10.0 7.3 9.2 10.5 8.9 6.7 11.0 9.3分散注意条件:4.5 5.1 6.0 3.6 7.0 6.8 5.5 6.4 7.1 5.6问在识记时分散注意对记忆成绩有无影响(数据文件attention.sav)。
类似问题一般都用平均数的差异检验进行分析,本组中,实验处理(自变量)只有2个水平,故其差异检验用独立样本t检验,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Independent-Sample T Test①将记忆成绩即因变量选入Test Variable,将注意类型即自变量(2个水平)选入Grouping Variable;②点击Define Groups,在弹出的对话框中,Group 1设置自变量的第一个水平(本实验中集中注意为1,故此处输入1),Group 2 设置自变量的第二个水平(即2),再点击Continue 后,点击OK,显示统计结果。
③输出的结果中,首先看下图第二个表格,只需要t、df和Sig(显著性水平)三个值,由下表可知,分别为6.271、18和.000,故差异显著,即两种注意条件下,个体对单词的记忆成绩存在显著差异,再结合第一个表格的Mean(即平均数),发现集中注意的成绩9.0400大于分散注意的成绩5.4600,故集中注意的记忆效果显著高于分散注意。
2. 相关样本t检验基本过程与独立样本t检验类似,操作程序为:Analyze(分析)——Compare Means(平均数比较)——Paired-Sample T Test例题:从某小学三年级随机抽取20名儿童做样本,分别在学期初和学期末进行了推理测验,结果如下(数据文件:Test.sav):学生编号 1 2 3 4 5 6 7 8 9 10学期初 12 13 12 11 10 13 14 15 15 11学期末 14 14 11 15 11 14 14 17 15 14学生编号 11 12 13 14 15 16 17 18 19 20学期初 13 12 11 10 13 14 15 15 11 12学期末 14 14 11 15 14 14 16 18 15 14①分两次分别点击“学期初成绩”和“学期末成绩”两个变量,如下图所示,Current Selections 显示两个变量后,点击中间的小三角选入Paired Variables后点击OK,显示结果;②输出结果的理解和分析与独立样本t检验相同。

SPSS分析调查问卷数据的方法当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍.Spss处理:第一步:定义变量大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。
在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、l abel(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类).我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为:1.请问你的年龄属于下面哪一个年龄段( )?A:20—29 B:30—39 C:40—49 D:50--59那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, wi dth宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。
Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40—49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colo mns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。
SPSS统计分析与应用课程报告城市旅游业与星级酒店相关分析姓名:学号:2013 年 6 月30 日城市旅游业与星级酒店相关分析摘要酒店是城市旅游产业客源的主要承载部门,酒店的客源市场取决于城市的旅游客源市场。
随着城市面貌的巨大变化,旅游业也飞速发展,一个城市拥有高档次星级酒店的多少,反映了一个地方旅游接待能力水平的高低,长期以来,中国城市旅游业以入境观光为龙头而超常发展。
然而进入二十世纪九十年代中期以后,我国旅游市场环境发生了根本性的变化,酒店业进入了买房市场需求约束性状态1。
各城市酒店业在入境客人、国内客人等主要客源市场上表现出不同的特点。
豪华酒店的热潮可以说席卷了全国,从一线到二三线城市,从CBD到风景区,大量的五星级酒店或者是含五星级酒店的高端城市综合项目在进行,高星级酒店的热度超乎想象。
关键词星级酒店城市级别单因素方差分析 f检验聚类分析回归分析一、利用单因素方差分析1.建立数据文件。
定义变量名:市别、宾馆总数、五星级酒店、四星级酒店、三星级酒店、二星级酒店、一星级酒店、客房、床位、客房出租。
并将城市按照中国城市等级榜1将其分等。
图12. 选择菜单“分析(Analyze)→比较均值→单因素”,弹出“单因素方差分析”对话框。
在对话框左侧的变量列表中选择变量“宾馆酒店”、“五星级酒店”、“四星级酒店”、“三星级酒店”“二星级酒店”、“一星级酒店”进入“因变量列表”框,选择“城市级别”进入“因子”框。
图23.设置均值多重比较类型。
单击“两两比较(Post Hoc)”按钮,弹出“单因素:两两比较”对话框。
在“假定方差齐性(Equal Variances Assumed)”复选框组中,选择LSD法进行方差齐时两两均值的比较。
图34.方差齐性检验,单击“选项”按钮,弹出“单因素:选项”对话框。
在“统计量”复选框组中,选择“描述性”输出观测变量的基本描述统计量,选择“方差同质性检验”表示进行方差齐性检验。
《非参数统计》SPSS实验指导书非参数统计分析―Nonparametric Tests菜单详解平时我们使用的统计推断方法大多为参数统计方法,它们都是在已知总体分布的条件下,对相应分布的总体参数进行估计和检验。
比如单样本u检验就是假定该样本所在总体服从正态分布,然后推断总体的均数是否和已知的总体均数相同。
本节要讨论的统计方法着眼点不是总体参数,而是总体分布情况,即研究目标总体的分布是否与已知理论分布相同,或者各样本所在的分布位置/形状是否相同。
由于这一类方法不涉及总体参数,因而称为非参数统计方法。
SPSS的的Nonparametric Tests菜单中一共提供了8种非参数分析方法,它们可以被分为两大类:1、分布类型检验方法:亦称拟合优度检验方法。
即检验样本所在总体是否服从已知的理论分布。
具体包括:Chi-square test:用卡方检验来检验二项/多项分类变量的几个取值所占百分比是否和我们期望的比例有没有统计学差异。
Binomial Test:用于检测所给的变量是否符合二项分布,变量可以是两分类的,也可以使连续性变量,然后按你给出的分界点一分为二。
Runs Test:用于检验样本序列随机性。
观察某变量的取值是否是围绕着某个数值随机地上下波动,该数值可以是均数、中位数、众数或人为制定。
一般来说,如果该检验P值有统计学意义,则提示有其他变量对该变量的取值有影响,或该变量存在自相关。
One-Sample Kolmogorov-Smirnov T est:采用柯尔莫哥诺夫-斯米尔诺夫检验来分析变量是否符合某种分布,可以检验的分布有正态分布、均匀分布、Poission分布和指数分布。
2、分布位置检验方法:用于检验样本所在总体的分布位置/形状是否相同。
具体包括:Two-Independent-Samples Tests:即成组设计的两独立样本的秩和检验。
Tests for Several Independent Samples:成组设计的多个独立样本的秩和检验,此处不提供两两比较方法。
关于度假的分析报告目录○1.频数分析 (3)○2.描述性析 (3)○3.探索性析 (12)○4.交叉表析 (15)数据介绍这张数据表包含九个变量,分别是:选择休闲度假地点的原因、娱乐项目、最近两年到北京郊区休闲度假的次数、性别、年龄、教育程度、单位性质、职业、收入水平。
通过对这些变量进行频率分析、描述性分析、探索性分析、交叉表分析,从而得出了以下结论。
○1频数分析基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量取值的状况,对把握数据的分布特征是非常有用的。
此次分析利用的是度假数据表,在性别、年龄和教育程度等不同的情况下的频数分析,从而了解变量的取值状况。
统计量性别年龄教育程度N 有效52 52 52缺失0 0 0百分位数25 1.00 2.00 1.0050 1.00 3.00 1.0075 2.00 3.00 2.00表一表二其中男性比例为63.5%比女性36.5%高27%,在饼状图中所占面积如下所示:接下来,对原有数据中的年龄进行频数分析,结果如下:年龄频率百分比有效百分比累积百分比有效20岁以下2 3.8 3.8 3.820_29岁15 28.8 28.8 32.7 30_39岁25 48.1 48.1 80.8 40_49岁10 19.2 19.2 100.0 合计52 100.0 100.0表三其中30-39年龄断的人数比例最大,其次为20-29年龄段,所占比例最小的是20岁以下,他们分别在饼状图中的比例如下:图二以上两张表是对年龄变量的分析说明:被调查者中有年龄为30-39的人数占48.1%,是个组中频数最高的的;其次是年龄为20-29的占28.8%;而最低的为年龄为20岁以下的,占全体的3.8%。
从条形图来看,年龄分布存在一定的右偏。
其均值为2.83,标准偏差为0.785。
图三表四由图可得,被调查的人中学历在大学或本科以上的占主要成分,比例为55.8%,其他学历比例为44.2%如下图所示:○2描述统计分析在通过频数分析把握了数据的总体分布状况后,我们通常还需要对数据的分布特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
【下载本文档,可以自由复制内容或自由编辑修改内容,更多精彩文章,期待你的好评和关注,我将一如既往为您服务】SPSS数据分析的主要步骤利用SPSS进行数据分析的关键在于遵循数据分析的一般步骤,但涉及的方面会相对较少。
主要集中在以下几个阶段。
1.SPSS数据的准备阶段在该阶段应按照SPSS的要求,利用SPSS提供的功能准备SPSS数据文件。
其中包括在数据编辑窗口中定义SPSS数据的结构、录入和修改SPSS 数据等。
2.SPSS数据的加工整理阶段该阶段主要对数据编辑窗口中的数据进行必要的预处理。
3.SPSS数据的分析阶段选择正确的统计分析方法对数据编辑窗口中的数据进行分析建模是该阶段的核心任务。
由于SPSS能够自动完成建模过程中的数学计算并能自动给出计算结果,因而有效屏蔽了许多对一般应用者来说非常晦涩的数学公式,分析人员无需记忆数学公式,这无疑给统计分析方法和SPSS 的广泛应用铺平了道路。
4.SPSS分析结果的阅读和解释该阶段的主要任务是读懂SPSS输出编辑窗口中的分析结果,明确其统计含义,并结合应用背景知识做出切合实际的合理解释。
数据分析必须掌握的分析术语1、增长:增长就是指连续发生的经济事实的变动,其意义就是考查对象数量的增多或减少。
2、百分点:百分点是指不同时期以百分数的形式表示的相对指标的变动幅度。
3、倍数与番数:倍数:两个数字做商,得到两个数间的倍数。
番数:翻几番,就是变成2的几次方倍。
4、指数:指数是指将被比较数视为100,比较数相当于被比较数的多少得到的数。
5、比重:比重是指总体中某部分占总体的百分比6、拉动。
增长。
:即总体中某部分的增加值造成的总体增长的百分比。
例子:某业务增量除以上年度的整体基数=某业务增量贡献度乘以整体业务的增长率。
例如:去年收入为23(其中增值业务3),今年收入为34(其中增值业务5),则增值业务拉动收入增长计算公式就为:(5-2)/23=(5-2)/(34-23)×(34-23)/23,解释3/(34-23)为数据业务增量的贡献,后面的(34-23)/23为增长率。