第十四章 输入输出流和缓冲区
- 格式:docx
- 大小:51.36 KB
- 文档页数:15

缓冲区溢出攻击原理与防范1.程序预留了一块内存区域作为缓冲区,用于执行其中一种特定的操作,如字符串拼接、输入输出处理等;2.当输入的数据长度超过了这个缓冲区的大小时,多余的数据会溢出到相邻的内存区域中;3.攻击者利用输入超出缓冲区的长度来对溢出的数据进行控制,修改程序的执行流程;4.修改后的程序执行流程可以导致程序崩溃、系统崩溃、拒绝服务等问题,也可以用于执行任意的恶意代码。
为了防范缓冲区溢出攻击,可以采取以下几种措施:1.对输入进行有效的长度检查:在程序中对输入数据进行有效的长度检查,确保不会超过预定的缓冲区大小。
这样就可以避免发生缓冲区溢出。
2. 使用安全编程语言和工具:选择使用安全编程语言,如Rust、Go 等,这些语言具有安全性的内存管理机制,能够自动检查和防范缓冲区溢出问题。
此外,使用安全编程工具如静态代码分析工具、Fuzzing工具等也可以帮助发现和修复潜在的缓冲区溢出漏洞。
3.使用内存安全检查工具:使用内存安全检查工具,如利用内存隔离技术的地址空间布局随机化(ASLR)、点火检查器、堆栈保护机制等。
这些工具可以帮助检测和防范缓冲区溢出攻击。
4.最小特权原则:在设计软件时,采用最小特权原则,即仅分配程序所需的最小权限。
这样做可以确保即使发生缓冲区溢出攻击,攻击者也只能访问到最小特权内的信息,减少损失。
5.及时修复漏洞和更新软件:及时修复已知的缓冲区溢出漏洞,更新软件以获取最新的安全补丁是非常重要的。
由于缓冲区溢出攻击是一种常见的攻击方式,软件开发商通常会不断更新修复这方面的漏洞。
综上所述,缓冲区溢出攻击是一种常见的安全漏洞利用技术,可以对各种软件和操作系统进行攻击。
为了防范这种攻击,需要采取有效的措施,如对输入进行有效的长度检查、使用安全编程语言和工具、使用内存安全检查工具、采用最小特权原则以及及时修复漏洞和更新软件等。
这样可以有效地减少缓冲区溢出攻击带来的风险。


streambuf用法streambuf是C++标准库提供的一个类,可以用来处理输入和输出流的缓冲区操作。
streambuf类是所有输入输出流的基类,它提供了一套标准接口,使得我们可以定制化输入输出的行为。
streambuf类的主要作用是存储字符序列,并且提供了一些成员函数来进行字符输入输出操作。
在输入流中,streambuf类负责从输入源中读取字符,并存储在自己的缓冲区中;在输出流中,streambuf类负责将自己缓冲区中的字符写入到输出目标中。
streambuf类的成员函数可以分为四个类别:缓冲区管理,字符输入,字符输出,以及其他函数。
一、缓冲区管理streambuf类提供了一些成员函数来管理缓冲区,包括设置缓冲区、获取缓冲区以及刷新缓冲区等操作。
1. setbuf函数原型:char* setbuf (char* s, streamsize n);函数说明:设置缓冲区。
参数s指向用户提供的缓冲区,n表示缓冲区的大小。
当前streambuf类的缓冲区被设置为s,并且缓冲区大小设置为n。
如果参数s为NULL,表示取消缓冲区,并且将n设置为0。
2. pubsetbuf函数原型:char* pubsetbuf (char* s, streamsize n);函数说明:设置缓冲区,与setbuf功能相同。
pubsetbuf是一个virtual函数,可以在派生类中重写。
3. setb函数原型:char* setb (char* s, char* end, int mode = ios_base::in | ios_base::out);函数说明:设置输入输出缓冲区。
参数s为缓冲区的开始位置,参数end为结束位置,mode表示缓冲区的模式。
mode的取值可以为以下之一:- ios_base::in,表示输入缓冲区;- ios_base::out,表示输出缓冲区;- ios_base::in | ios_base::out,表示输入输出缓冲区。

java中基本输入输出流的解释1.网络程序的很大一部分是简单的输入输出,即从一个系统向另一个系统移动字节。
字节就是字节,在很大程度上,读服务器发送的数据与读取文件没什么不同;向客户传送数据与写入一个文件也没有什么区别。
Java中输入和输出组织不同于大多数其他语言。
它是建立在流(stream)上。
不同的基本流类(如java.io.FileInputStream和.TelnetOutputStream)用于读写特定的数据资源。
但是所有的基本输出流使用同一种基本方法读数据。
过滤器流可以连接到输入流或输出流。
它可以修改已经读出或写人的数据(例如,加密或压缩数据),或者可以简单地提供附加方法将已经读出或写入的数据转化成其他格式。
最后Reader和Writer也可以链接到输入流和输出流,从而允许程序读出和写入文本(即字符)而不是字节。
如果使用正确,Reader和Writer能够处理多种类型的字符编码,包括SJIS和UTF-8等多字节字符集。
一、输出流java的基本输出流是 java.io.OutputStream.public abstract class OutputStreamn public abstract void write(int b) throws IOExceptionn public void write(byte[] data) throws IOExceptionn public void write(byte[] data,int offset,int length) throws IOExceptionn public void flush() throws IOExceptionn public void close() throws IOExceptionOutputStream的子类使用这些方法向指定媒体写入数据。
我始终相信,我们理解了为什么它们存在,就会更好地记住它们,好,现在开始说一下OutputStream类的方法的由来public abstract void write(int b) throws IOExceptionOutputStream的基本方法是write(int b)。


c语言输入输出缓冲区
在C语言中,输入输出缓冲区是用来存储输入数据和输出数据的
临时存储区域。
C语言中的标准输入流和标准输出流都有对应的缓冲区。
标准输
入流的缓冲区称为stdin缓冲区,标准输出流的缓冲区称为stdout
缓冲区。
输入缓冲区用于存储用户输入的数据,当用户输入数据时,数据
首先会被存储在输入缓冲区中,然后才会被读取。
对于标准输入
流(例如键盘输入),如果用户按下回车键,输入缓冲区中的内
容会被读取并处理。
输出缓冲区用于存储要输出到标准输出流的数据。
当程序打印数
据时,数据首先会被存储在输出缓冲区中,然后才会被输出到屏
幕或其他设备上。
输出缓冲区可以提高程序的效率,因为它可以
减少对输出设备的访问次数。
在C语言中,可以使用标准库函数来控制输入输出缓冲区的使用。
例如,使用fflush函数可以清空输出缓冲区,强制将缓冲区中的内容输出到屏幕上。
使用setvbuf函数可以设置缓冲区的大小和类型。
此外,C语言中还有一种特殊的缓冲区称为缓冲区流。
缓冲区流
是通过fopen函数打开的文件流,它使用缓冲区来提高对文件的读取和写入效率。
缓冲区流中的数据首先会被存储在缓冲区中,然
后才会被写入到文件或从文件中读取。
缓冲区流可以使用fflush函数来刷新缓冲区,将缓冲区中的数据写入到文件中。

stream流底层原理Stream流是Java I/O的核心概念之一,它提供了一种用于处理输入输出的机制。
在Java中,流可以理解为一种数据流,它可以从源头输入数据,经过一系列的处理,最终输出到目的地。
Stream流的底层原理主要涉及到数据传输、缓冲区和通道三个方面。
1.数据传输:在Java中,数据的传输是通过输入和输出流来实现的。
具体而言,输入流(InputStream)用于读取数据,输出流(OutputStream)用于写入数据。
Stream流的底层实际上是使用字节流来进行数据传输的,即通过一个字节一个字节地读取和写入数据。
为了提高效率,Java中提供了缓冲流(BufferedInputStream和BufferedOutputStream),它们可以一次读取和写入多个字节,减少与底层输入输出设备的交互次数,从而提高数据传输的速度。
2.缓冲区:缓冲区是Stream流的核心概念之一,它是在内存中开辟一块区域,用于临时存储待读取或待写入的数据。
缓冲区的大小可以根据需要进行调整。
在读取数据时,IO流会首先将数据读取到缓冲区中,然后逐个字节地将数据从缓冲区中读取出来。
类似地,在写入数据时,IO流会将数据写入到缓冲区中,然后逐个字节地将数据从缓冲区写入到目的地。
3.通道:通道是连接输入输出源和缓冲区的一条路径。
它可以将数据从源头输入到缓冲区,也可以将数据从缓冲区输出到目的地。
通道的底层实际上是对底层操作系统的文件系统进行访问和操作。
在Java NIO(New IO)中,通道是一种双向的、可读写的数据传输路径。
Java中提供了不同类型的通道,例如文件通道(FileChannel)、管道通道(Pipe),它们可以分别用于文件和内存间的数据传输。
Stream流的底层原理可以总结为以下几个步骤:1.打开一个输入或输出流,并与底层设备建立连接,建立通道。
2.创建一个缓冲区,用于存储待读取或待写入的数据。
3.通过通道将数据从输入源读取到缓冲区中,或将数据从缓冲区写入到输出目的地。

* 掌握:输入输出的含意;文件流以及输入/输出的格式控制;标准输出在C++程序中的应用。
* 理解:C++类库中的常用流类。
* 了解:C++的I/O对C的发展。
重点、难点◆输入输出的含意;文件流以及输入/输出的格式控制;标准输出在C++程序中的应用。
一、C++ 输入输出的含义以前所用到的输入和输出,都是以终端为对象的,即从键盘输入数据,运行结果输出到显示器屏幕上。
从操作系统的角度看,每一个与主机相连的输入输出设备都被看作一个文件。
程序的输入指的是从输入文件将数据传送给程序,程序的输出指的是从程序将数据传送给输出文件。
C++的输入与输出包括以下3方面的内容:1、对系统指定的标准设备的输入和输出。
简称标准I/O。
(设备)2、以外存磁盘(或光盘)文件为对象进行输入和输出。
简称文件I/0。
(文件)3、对内存中指定的空间进行输入和输出。
简称串I/O。
(内存)C++采取不同的方法来实现以上3种输人输出。
为了实现数据的有效流动,C++系统提供了庞大的I/O类库,调用不同的类去实现不同的功能。
二、C++的I/O对C的发展—类型安全和可扩展性C语言中I/O存在问题:1、在C语言中,用prinff和scanf进行输入输出,往往不能保证所输入输出的数据是可靠的、安全的。
学过C语言的读者可以分析下面的用法:想用格式符%d输出一个整数,但不小心错用了它输出单精度变量和字符串,会出现什么情况?假定所用的系统int型占两个字节。
printf("%d",i);//i为整型变量,正确,输出i的值printf("%d",f);//f为单精度变量,输出变量中前两个字节的内容printf("%d","C++");//输出字符串"C++”的起始地址编译系统认为以上语句都是合法的,而不对数据类型的合法性进行检查,显然所得到的结果不是人们所期望的。
2、在用scanf输入时,有时出现的问题是很隐蔽的。

字节流常用方法字节流常用方法是指在Java中,处理字节数据(二进制数据)的输入输出流所使用的一些常用方法。
这些方法可以帮助Java程序员有效地处理和操作字节数据。
常见的字节流包括InputStream、OutputStream、DataInputStream和DataOutputStream等。
这些流可以分别用来读取和写入字节数据,并提供了许多有用的方法,如读取字节、写入字节、读取整数、写入整数等等。
本文将详细介绍Java中的字节流常用方法,以及它们的具体用法和含义。
一、InputStream和OutputStreamInputStream和OutputStream是Java中处理字节数据的最基本和最常见的输入输出流。
InputStream可以用于读取从源生成的字节数据,例如文件或网络连接,而OutputStream则可以用于写入字节数据到目标,例如文件或网络连接。
1.1 InputStream的常用方法- read():读取一个字节的数据。
该方法会一直阻塞,直到有可用字节。
- read(byte[] b):读取若干个字节的数据,并存储在字节数组b中。
- read(byte[] b, int off, int len):读取len个字节的数据到字节数组b中,从off位置开始存储。
- skip(long n):跳过n个字节的数据。
- available():返回可读取的字节数。
- close():关闭流并释放相关资源。
1.2 OutputStream的常用方法- write(int b):写入一个字节的数据。
- write(byte[] b):写入字节数组的数据。
- write(byte[] b, int off, int len):写入字节数组中的len个字节,从off 位置开始。
- flush():刷新缓冲区并将数据输出到目标流。
- close():关闭流并释放相关资源。
二、DataInputStream和DataOutputStreamDataInputStream和DataOutputStream是在InputStream和OutputStream的基础上封装而成,提供了一些额外的方法,可以更加方便地读取和写入各种数据类型的字节数据。
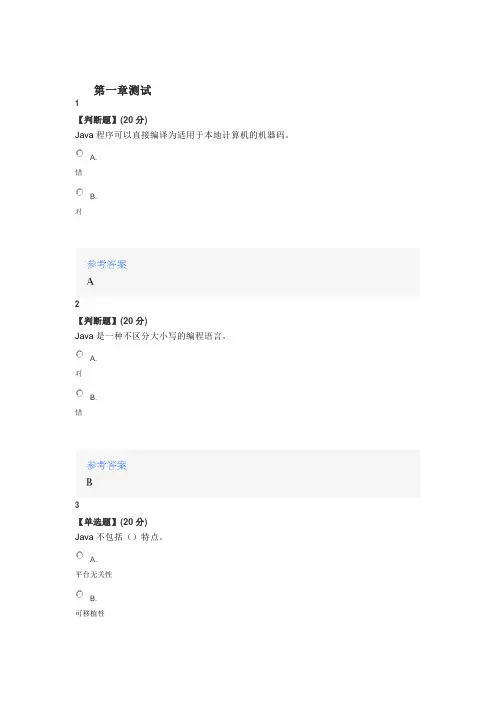
第一章测试1【判断题】(20分)Java程序可以直接编译为适用于本地计算机的机器码。
A.错B.对2【判断题】(20分)Java是一种不区分大小写的编程语言。
A.对B.错3【单选题】(20分)Java不包括()特点。
A.平台无关性B.可移植性C.分布性D.面向过程4【单选题】(20分)Java源程序的扩展名为()A..classB..jsC..javaD..jav5【单选题】(20分)Java编译成功后生成文件的扩展名为()A..javaB..jsC..classD..jav第二章测试1【单选题】(20分)下列标识符名称不合法是()A.trueB.$mainC.squareD._1232【单选题】(20分)下列选择中,不属于Java语言的简单数据类型的是()A.数组B.浮点型C.字符型D.整数型3【单选题】(20分)下列名称不是Java语言中的关键字的是()A.privateB.sizeofC.if4【判断题】(20分)在Java程序中要使用一个变量,必须先对其进行声明()A.错B.对5【判断题】(20分)以0x或0X开头的整数(如0x45)代表八进制整型常量()A.错B.对第三章测试1【判断题】(20分)简单if结构是顺序程序结构A.对B.错2【判断题】(20分)多重if-else分支结构中的大括号不能省略A.对B.错3【判断题】(20分)switchcase结构中的default为必选参数,必须得写上,否则程序会出错A.对B.错4【单选题】(20分)在流程图中,下面说法正确的是()A.“跑道形”表示判断分支B.“平行四边形”表示输入/输出指令(或数据)C.”菱形”表示计算步骤/处理过程符号D.“长方形'表示程序开始/结束5【单选题】(20分)下列关于if选择结构和switch选择结构的说法正确的是()A.多重if-else选择结构中的else语句是必须的B.嵌套if-else选择结构中不能包含else语句C.switch选择结构中的default可选第四章测试1【判断题】(20分)continue语句用在循环结构中跳过当次continue下面的语句继续执行下一次循环A.对B.错2【判断题】(20分)嵌套循环的次数为外循环的次数加上内循环的执行次数A.对B.错3【单选题】(20分)运行下面的程序将输出()次“我爱中国”publicclassChina{ publicstaticvoidmain(String[]args){ inti=1;do{System.out.println(“我爱中国”);}while(i<5);}}A.4B.死循环C.5D.4【单选题】(20分)阅读下面的程序片断,输出结果是()inta=0;while(a<5){switch(a){case0:case3:a=a+2;case1:case2:a=a+3;default:a=a+5;}}System.out.println(a);A.10B.其他C.D.55【单选题】(20分)阅读下列代码,如果输入的数字是6,正确的运行结果是() importjava.util.*;publicclassTest{publicstaticvoidmain(String[]args){Scannerinput=newScanner(System.in);System.out.print(“请输入1个1-10之间的数”);intnumber=input.nextInt();for(inti=1;i<=10;i++){if((i+number)>10){break;}System.out.print(i+””);}}}A.123456B.78910C.1234D.5678第五章测试1【判断题】(20分)int[][]x=newint[3][5];所定义的二维数组对象含有15个int型元素。

C++中输⼊输出流及⽂件流操作总结本⽂实例为⼤家分享了C++中输⼊输出流及⽂件流操作笔记,供⼤家参考,具体内容如下1、流的控制iomanip 在使⽤格式化I/O时应包含此头⽂件。
stdiostream ⽤于混合使⽤C和C + +的I/O机制时,例如想将C程序转变为C++程序2、类继承关系ios是抽象基类,由它派⽣出istream类和ostream类, iostream类⽀持输⼊输出操作,iostream类是从istream类和ostream类通过多重继承⽽派⽣的类类ifstream继承了类istream,类ofstream继承了类ostream,类fstream继承了类iostreamiostream头⽂件中4种流对象cout补充1、⽤“cout<<”输出基本类型的数据时,可以不必考虑数据是什么类型,系统会判断数据的类型并根据其类型选择调⽤与之匹配的运算符重载函数。
这个过程都是⾃动的,⽤户不必⼲预。
如果在C语⾔中⽤prinf函数输出不同类型的数据,必须分别指定相应的输出格式符,⼗分⿇烦,⽽且容易出错2、cout流在内存中对应开辟了⼀个缓冲区,⽤来存放流中的数据,当向cout流插⼈⼀个endl时,不论缓冲区是否已满,都⽴即输出流中所有数据,然后插⼊⼀个换⾏符,并刷新流(清空缓冲区)。
注意如果插⼈⼀个换⾏符”\n“(如cout<<a<<"\n"),则只输出和换⾏,⽽不刷新cout 流(但并不是所有编译系统都体现出这⼀区别)。
3、在iostream中只对"<<"和">>"运算符⽤于标准类型数据的输⼊输出进⾏了重载,但未对⽤户声明的类型数据的输⼊输出进⾏重载。
如果⽤户声明了新的类型,并希望⽤"<<"和">>"运算符对其进⾏输⼊输出,按照重运算符重载来做。
C语⾔的标准输⼊输出欢迎探讨,如有错误敬请指正如需转载,请注明出处 /nullzx/1. 标准输⼊输出标准输⼊、输出主要由缓冲区和操作⽅法两部分组。
缓冲区实际上可以看做内存中的字符串数组,⽽操作⽅法主要是指printf、scanf、puts、gets,getcha、putcahr等操作缓冲区的⽅法。
在C++以及Java等⾯向对象的编程语⾔中,将缓冲区以及操作缓冲区的⽅法封装成⼀类对象,这类对象就称为流。
缓冲区最⼤的特点主要体现在数据的⼀次性,即数据被printf、scanf从缓冲区中取出后就被使⽤了,或者说消耗了。
可以把缓冲区⽐喻成管道,缓冲区中的数据⽐喻成⽔流,printf、scanf等⽅法⽐喻成开关,当打开开关,⽔就会慢慢流逝,⽽流出去的⽔就再也收不回来了。
由于不同系统,不的硬件底层实现输⼊输出的具体⽅法可能不⼀样,C语⾔要求系统为每个程序提供两个指针,这两个指针分别指向两个结构体,这两个结构体分别表⽰了键盘和屏幕在内存中的抽象表⽰(缓冲区的地址值被记录在这个结构体中),并将指向这两个结构体的指针命名为stdin和 stdout.这两个指针就是所谓的标准输⼊和标准输出。
还有⼀点应该始终铭记,标准输⼊和输出缓冲区中存储的是字符的ASCII码值。
⽐如你想从键盘上输⼊了123给⼀个变量,那么在缓冲区中存储是三个字节,分别是字符‘1’的ASCII码值,字符‘2’的ASCII码值,字符‘3’的ASCII码值,然后将这个这三个ASCII值序列转换为⼀个数值给这个变量。
同理,从屏幕输出“123”,计算机并不认为它输出的是⼀个数值,计算机实际上仅仅是描绘了⼀个‘1’的ASCII码值对应的图形,‘2’的ASCII的值对应的图形,‘3’的ASCII码值对应的图形。
2. getchar、putcharputchar的作⽤主要是向输出缓冲区中写⼊⼀个字符。
getchar的作⽤主要是向输⼊缓冲区中读取⼀个字符。
如果碰到⽂件结尾,返回-1getchar源代码int getchar(void){static char buf[BUFSIZ];static char* bb = buf;static int n = 0;if (n == 0) {n = read(0, buf, BUFSIZ);bb = buf;}return(--n >= 0) ? (unsigned char)*bb++ : EOF;}OEF是⼀个宏,表⽰-1。
今天发现了清空缓冲区的问题,上网搜寻,发现如下方法。
1.输入输出缓冲区的概念(C++用的多一些)我想以一个例子说明,比如我想把一篇文章以字符序列的方式输出到计算机显示器屏幕上,那么我的程序内存作为数据源而显示器驱动程序作为数据目标,如果数据源直接对数据目标发送数据的话。
数据目标获得第一个字符,便将它显示。
然后从端口读取下一个字符,可是这时就不能保证数据源向端口发送的恰好是第二个字符(也许是第三个,而第二个已经在数据目标显示时发送过了)。
这样的话就不能保证输出的数据能完整的被数据目标所接受并处理。
为了解决这个问题,我们需要在数据源与数据目标中间放置一个保存完整数据内容的区域,那就是“缓冲区”。
这样的话,数据源可以不考虑数据目标正在处理哪部分数据,只要把数据输出到缓冲区就可以了,数据目标也可以不考虑数据源的发送频率,只是从缓冲区中依次取出下一个数据。
从而保证了数据发送的完整性,同时也提高了程序的效率。
当然getch(),getche()没有用到缓冲区。
2.几个函数的区别首先不要忘了,要用getch()必须引入头文件conio.h,以前学C语言的时候,我们总喜欢用在程序的末尾加上它,利用它来实现程序运行完了暂停不退出的效果。
如果不加这句话,在TC2.0的环境中我们用Ctrl+F9编译并运行后,程序一运行完了就退回到TC环境中,我们根本来不及看到结果,这时要看结果,我们就要按Alt+F5回到DOS环境中去看结果,这很麻烦。
而如果在程序的结尾加上一行getch();语句,我们就可以省掉会DOS看结果这个步骤,因为程序运行完了并不退出,而是在程序最后把屏幕停住了,按任意键才退回到TC环境中去。
那我们来看看getch()到底起的什么作用,getch()实际是一个输入命令,作用是从键盘接收一个字符,而且并不把这个字符显示出来,就是说,你按了一个键后它并不在屏幕上显示你按的什么,而继续运行后面的代码,所以我们在C++中可以用它来实现“按任意键继续”的效果,即程序中遇到getch();这行语句,它就会把程序暂停下来,等你按任意键,它接收了这个字符键后再继续执行后面的代码。
fastlio公式推导要推导fastlio公式,我首先需要解释fastlio的概念和原理。
fastlio的核心思想是使用两个缓冲区:输入缓冲区和输出缓冲区。
输入缓冲区用于从输入流中读取数据,输出缓冲区用于将数据写入输出流。
通过将数据缓冲到内存中,可以减少对磁盘或网络的访问次数,从而提高程序的执行效率。
步骤1:定义输入缓冲区和输出缓冲区的大小。
通常情况下,缓冲区的大小应根据输入和输出数据的预估大小来确定。
步骤2:使用数组或指针来实现输入缓冲区和输出缓冲区。
可以使用char数组、int数组或其他适当的数据结构来存储缓冲区中的数据。
步骤3:定义指针或索引来追踪缓冲区中的数据位置。
通常情况下,输入缓冲区和输出缓冲区都有一个指针或索引,用于记录当前读取或写入的位置。
步骤4:使用循环结构从输入流中读取数据并写入输入缓冲区。
可以使用标准输入函数(如scanf)或文件输入函数(如fread)来读取输入数据,并将数据存储到输入缓冲区中。
步骤5:使用循环结构从输出缓冲区中读取数据并写入输出流。
可以使用标准输出函数(如printf)或文件输出函数(如fwrite)将输出缓冲区中的数据写入输出流。
步骤6:在读取或写入完整个缓冲区后,将指针或索引重置为缓冲区的起始位置。
这样可以循环使用缓冲区,使程序可以继续读取或写入数据。
步骤7:在程序执行完毕后,确保将缓冲区中的剩余数据写入输出流。
可以使用fflush函数或类似的方法来强制刷新输出缓冲区,并将缓冲区中的数据写入输出流。
通过以上步骤1. 定义输入缓冲区和输出缓冲区的大小,通常使用char数组或其他适当的数据结构。
2.定义指针或索引来追踪缓冲区中的数据位置。
3.使用循环结构从输入流中读取数据并写入输入缓冲区。
4.使用循环结构从输出缓冲区中读取数据并写入输出流。
5.在读取或写入完整个缓冲区后,将指针或索引重置为缓冲区的起始位置。
6.在程序执行完毕后,将缓冲区中的剩余数据写入输出流。
streambuf用法streambuf是C++标准库中的一个类,它用于管理输入输出流的缓冲区。
它是一个抽象基类,提供了一些接口供派生类实现,用于处理底层的字符流。
streambuf类通常被用作iostream类(如iostream、ifstream、ofstream等)的基类,它定义了输入输出缓冲区的行为。
streambuf 类负责管理输入输出缓冲区,并定义了一些基本的读写方法,如从流中读取字符、写入字符到流中等。
派生类可以根据不同的具体需求重写这些方法。
使用streambuf的一般步骤如下:1.创建一个派生自streambuf的自定义类,例如MyStreambuf。
2.重写需要定制的方法,如overflow()、underflow()、xsputn()和xsgetn()等,以满足特定的缓冲区行为。
3.创建一个iostream对象,如ostringstream。
4.将自定义的streambuf对象传递给iostream对象,使用iostream的rdbuf()方法进行设置,例如`ostringstream obj; obj.rdbuf(myStreambufObject);`5.使用iostream对象进行输入输出操作。
除了重写方法以外,还可以对streambuf进行一些拓展。
例如,可以重写seekoff()、seekpos()和setbuf()等方法,以自定义缓冲区的读写位置和大小,或者添加其他自定义的方法来处理特定需求。
此外,还可以在streambuf类的基础上创建新的派生类,以提供更加特定的功能,例如对网络流、加密流等的处理。
总结来说,streambuf是C++标准库中用于管理底层输入输出缓冲区的抽象基类,通过重写其中的方法,可以实现自定义的读写行为。
并且可以根据具体需求进行拓展和派生,以满足不同的功能要求。
C语⾔缓冲区(缓存)详解1.概念缓冲区⼜称为缓存,它是内存空间的⼀部分。
也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。
缓冲区根据其对应的是输⼊设备还是输出设备,分为输⼊缓冲区和输出缓冲区。
2.为什么要引⼊缓冲区⽐如我们从磁盘⾥取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。
现在您基本明⽩了吧,缓冲区就是⼀块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。
它使得低速的输⼊输出设备和⾼速的CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
缓冲区的类型缓冲区 分为三种类型:全缓冲、⾏缓冲和不带缓冲。
1) 全缓冲在这种情况下,当填满标准I/O缓存后才进⾏实际I/O操作。
全缓冲的典型代表是对磁盘⽂件的读写。
2) ⾏缓冲在这种情况下,当在输⼊和输出中遇到换⾏符时,执⾏真正的I/O操作。
这时,我们输⼊的字符先存放在缓冲区,等按下回车键换⾏时才进⾏实际的I/O操作。
典型代表是标准输⼊(stdin)和标准输出(stdout)。
3) 不带缓冲也就是不进⾏缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显⽰出来。
ANSI C( C89 )要求缓存具有下列特征:当且仅当标准输⼊和标准输出并不涉及交互设备时,它们才是全缓存的。
标准出错决不会是全缓存的。
但是,这并没有告诉我们如果标准输⼊和输出涉及交互作⽤设备时,它们是不带缓存的还是⾏缓存的,以及标准输出是不带缓存的,还是⾏缓存的。
缓冲区(缓存)缓冲区(Buffer)⼜称为缓存(Cache),是内存空间的⼀部分。
也就是说,计算机在内存中预留了⼀定的存储空间,⽤来暂时保存输⼊或输出的数据,这部分预留的空间就叫做缓冲区(缓存)。
有时候,从键盘输⼊的内容,或者将要输出到显⽰器上的内容,会暂时进⼊缓冲区,待时机成熟,再⼀股脑将缓冲区中的所有内容“倒出”,我们才能看到变量的值被刷新,或者屏幕产⽣变化。
1.为什么要引⼊缓冲区(缓存)缓冲区是为了让低速的输⼊输出设备和⾼速的⽤户程序能够协调⼯作,并降低输⼊输出设备的读写次数。
例如,我们都知道硬盘的速度要远低于 CPU,它们之间有好⼏个数量级的差距,当向硬盘写⼊数据时,程序需要等待,不能做任何事情,就好像卡顿了⼀样,⽤户体验⾮常差。
计算机上绝⼤多数应⽤程序都需要和硬件打交道,例如读写硬盘、向显⽰器输出、从键盘输⼊等,如果每个程序都等待硬件,那么整台计算机也将变得卡顿。
但是有了缓冲区,就可以将数据先放⼊缓冲区中(内存的读写速度也远⾼于硬盘),然后程序可以继续往下执⾏,等所有的数据都准备好了,再将缓冲区中的所有数据⼀次性地写⼊硬盘,这样程序就减少了等待的次数,变得流畅起来。
缓冲区的另外⼀个好处是可以减少硬件设备的读写次数。
其实我们的程序并不能直接读写硬件,它必须告诉操作系统,让操作系统内核(Kernel)去调⽤驱动程序,只有驱动程序才能真正的操作硬件。
从⽤户程序到硬件设备要经过好⼏层的转换,每⼀层的转换都有时间和空间的开销,⽽且开销不⼀定⼩;⼀旦⽤户程序需要密集的输⼊输出操作,这种开销将变得⾮常⼤,会成为制约程序性能的瓶颈。
这个时候,分配缓冲区就是必不可少的。
每次调⽤读写函数,先将数据放⼊缓冲区,等数据都准备好了再进⾏真正的读写操作,这就⼤⼤减少了转换的次数。
实践证明,合理的缓冲区设置能成倍提⾼程序性能。
现在你基本明⽩了吧,缓冲区其实就是⼀块内存空间,它⽤在硬件设备和⽤户程序之间,⽤来缓存数据,⽬的是让快速的 CPU 不必等待慢速的输⼊输出设备,同时减少操作硬件的次数。
第十四章对C语言输入输出流和缓冲区的深入理解
14.1对C语言输入输出流的深入理解
程序开始执行时,默认会打开 stdin、stdout和stderr三个文件,所以我们使用 scanf()、printf() 等函数时就不需要再使用 fopen() 显式打开这些文件。
C语言打开文件时,先将文件内容载入缓冲区(缓存),并返回一个指向FILE结构体的指针,接下来对文件的操作,都映射成对缓冲区的操作,只有当强制刷新缓冲区、关闭文件或程序运行结束时,才将缓冲区中的内容更新到文件。
就像编辑word文档,并不是立刻将编辑好的内容写入到磁盘上的文件,而是对缓存中的副本进行操作,只有当保存文件时,才将副本同步到磁盘上的文件。
缓冲区有很多类型,我们这里指的缓冲区是主存(内存条)上的一块特殊区域,专门用来缓存数据,供程序读写。
而由于硬件不同,将缓冲区的内容同步到文件的过程可能比较繁杂,不易操作,这些都由操作系统完成,对编程人员不可见,编程人员只要能操作接口简单的缓冲区即可。
14.2 C语言缓冲区(缓存)详解
深入理解缓冲区请查看:结合缓冲区谈谈C语言getchar()、getche()、getch()的区别
14.3结合缓冲区谈谈C语言getchar()、getche()、
getch()的区别
三个函数的对比
程序运行后,首先停下来,等待输入一个字符串,输入完毕后,它会把你输入的整个字符串都输出来了。
这是为什么?getchar()不是只返回第一个字符么,这里为什么全部输出了?
因为我们输入的字符串并不是取了第一个字符就把剩下的字符串丢掉了,它还在我们的缓冲区中,就好像开闸放水,你把水放到闸里去以后,开一次闸就放掉一点,开一次就放掉一点,直到放光了为止,这里开闸动作就相当于调用一次getchar()。
我们输入的字符串也是这么一回事,首先我们输入的字符串是放在内存的缓冲区中的,我们调用一次getchar()就把缓
冲区中里出口最近的一个字符输出,也就是最前面的一个字符输出,输出后,就把它释放掉了,但后面还有字符串,所以我们就用循环把最前面的一个字符一个个的在内存中释放掉,直到不满足循环条件退出为止。
例子中循环条件里的'\n'实际上就是你输入字符串后的回车符,所以意思就是说,直到遇到回车符才结束循环,而getchar()函数就是等待输入(或缓冲区中的数据)直到按回车才结束,所以实现了整个字符串的输出。
当然,我们也可以把循环条件改一下,比如while ((c=getchar())!='a'),就是遇到字符'a'就停止循环,当然意思是如果你输入
“12345a213123/n”那么只会输出到a,结果是12345a。
base // 缓冲区基地址
在上面我们向缓冲区中放入了10个字节大小的数据,FILE结构体中的 cnt 变为了10 ,说明此时缓冲区中有10个字节大小的数据可以读,同时我们假设缓冲区的基地址也就是 base 是0x00428e60 ,它是不变的,而此时 ptr 的值也为0x00428e60 ,表示从0x00428e60
这个位置开始读取数据,当我们从缓冲区中读取5个数据的时候,cnt 变为了5 ,表示缓冲区还有5个数据可以读,ptr 则变为了0x0042e865表示下次应该从这个位置开始读取缓冲区中的数据,如果接下来我们再读取5个数据的时候,cnt 则变为了0 ,表示缓冲区中已经没有任何数据了,ptr 变为了0x0042869表示下次应该从这个位置开始从缓冲区中读取数据,但是此时缓冲区中已经没有任何数据了,所以要将输入流中的剩下的那10个数据放进来,这样缓冲区中又有了10个数据,此时 cnt 变为了10 ,注意了刚才我们讲到 ptr 的
值是0x00428e69 ,而当缓冲区中重新放进来数据的时候这个 ptr 的值变为了
0x00428e60 ,这是因为当缓冲区中没有任何数据的时候要将 ptr 这个值进行一下刷新,使其指向缓冲区的基地址也就是0x0042e860这个值!因为下次要从这个位置开始读取数据!在这里有点需要说明:当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键(\r)会被转换为一个换行符\n,这个换行符\n 也会被存储在缓冲区中并且被当成一个字符来计算!比如我们在键盘上敲下了123456这个字符串,然后敲一下回车键(\r)将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是7 ,而不是6。
缓冲区的刷新就是将指针 ptr 变为缓冲区的基地址,同时 cnt 的值变为0 ,因为缓冲区刷新后里面是没有数据的!
针也并不为NULL。