常用统计图表的绘制及错误辨析.
- 格式:ppt
- 大小:717.50 KB
- 文档页数:30


统计表的分析与解读统计表在我们日常生活和各个领域都有广泛应用,它通过数据的可视化呈现,能够直观地展示出各种信息和趋势。
然而,要准确理解并分析统计表中的数据,我们需要掌握一定的解读技巧和方法。
本文将从几个方面介绍统计表的分析与解读。
一、统计表的结构和要素统计表通常由标题、表头、表身和表尾四个部分组成。
标题通常位于表格的上方,用于概括表格的主题。
表头包含数据表的主要分类和标签信息。
表身则是统计数据的核心部分,由行和列组成,每个格子内都是具体的数据。
表尾可以用来补充说明表格中数据的来源、计算方法等信息。
二、统计表的分类和特点统计表按照数据的不同分类方式,可以分为横向统计表和纵向统计表。
横向统计表是以时间为主线,按照不同时间段来统计某一指标的变化情况;而纵向统计表则是以不同指标为主线,对同一时间点上的数据进行比较和分析。
在进行统计表的解读时,我们需要根据表格的分类方式,选择合适的分析角度和方法。
三、统计表的数据分析1. 查看数据的趋势:通过观察统计表中的数据,我们可以分析出数据的趋势,比如数据的递增或递减情况。
可以通过计算比例、平均数等指标来进行数据的比较和分析。
2. 比较不同指标:统计表中通常包含多个指标,我们可以通过对比这些指标的数值,来发现它们之间的关联和差异。
可以使用折线图、柱状图等方式来呈现数据的对比情况。
3. 分析数据的变动原因:在分析统计表时,我们还需要考虑数据变动的原因,这有助于我们深入理解数据背后的含义。
比如,某一指标的增长可能是由于政策改变、市场需求增加等因素引起的。
四、统计表的合理解读1. 不断追问为什么:在分析统计表时,我们应该学会不断追问数据背后的原因,不能仅凭表格中的数据就做出结论。
通过深度思考和对比分析,才能得出更准确的结论。
2. 注意数据的可信度:统计表中的数据应该来自可靠的来源,才能保证数据的可信度。
我们应该留意数据是否存在错误或者疏漏,为了确保数据的准确性,也可以参考其他相关数据和资料。
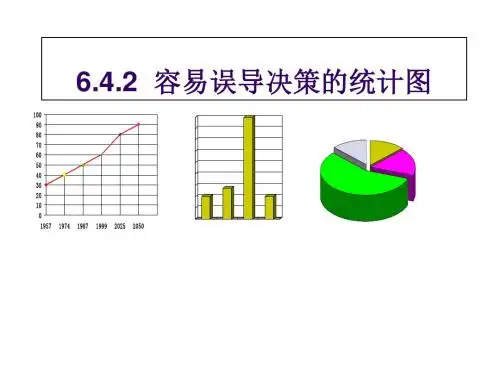

易错点13 统计易错点1.看不懂图,分辨不清数据的表示方法(1)常见的统计图表有柱形图、折线图、扇形图、茎叶图、频数分布直方图、频率分布直方图等. (2)频率分布直方图 ①作频率分布直方图的步骤(ⅰ)找出最值,计算极差:即一组数据中最大值与最小值的差; (ⅱ)合理分组,确定区间:根据数据的多少,一般分5~9组; (ⅲ)整理数据:逐个检查原始数据,统计每个区间内数的个数(称为区间对应的频数),并求出频数与数据个数的比值(称为区间对应的频率),各组均为左闭右开区间,最后一组是闭区间; (ⅳ)作出有关图示:根据上述整理后的数据,可以作出频率分布直方图,如图所示.频率分布直图的纵坐标是频率组距,每一组数对应的矩形高度与频率成正比,而且每个矩形的面积等于这一组数对应的频率,从而可知频率分布直方图中,所有矩形的面积之和为1.②频率分布折线图作图的方法都是:把每个矩形上面一边的中点用线段连接起来.为了方便看图,折线图都画成与横轴相交,所以折线图与横轴的左右两个交点是没有实际意义的.不难看出,虽然作频率分布直方图过程中,原有数据被“压缩”了,从这两种图中也得不到所有原始数据.但是,由这两种图可以清楚地看出数据分布的总体态势,而且也可以得出有关数字特征的大致情况.比如,估计出平均数、中位数、百分位数、方差.当然,利用直方图估计出的这些数字特征与利用原始数据求出的数字特征一般会有差异.易错点2.数据特征的相关概念没有理解 1.数据的数字特征 (1)最值一组数据的最值指的是其中的最大值与最小值,最值反映的是这组数最极端的情况. (2)平均数①定义:如果给定的一组数是x 1,x 2,…,x n ,则这组数的平均数为x -=1n (x 1+x 2+…+x n ).这一公式在数学中常简记为x -=1n ∑n i =1x i , ②性质:一般地,利用平均数的计算公式可知,如果x 1,x 2,…,x n 的平均数为x ,且a ,b 为常数,则ax 1+b ,ax 2+b ,…,ax n +b 的平均数为a x -+b . (3)中位数有奇数个数,且按照从小到大排列后为x 1,x 2,…,x 2n +1,则称x n +1为这组数的中位数;如果一组数有偶数个数,且按照从小到大排列后为x 1,x 2,…,x 2n ,则称x n +x n +12为这组数的中位数. (4)百分位数①定义:一组数的p %(p ∈(0,100))分位数指的是满足下列条件的一个数值:至少有p %的数据不大于该值,且至少有(100-p )%的数据不小于该值.②确定方法:设一组数按照从小到大排列后为x 1,x 2,…,x n ,计算i =np %的值,如果i 不是整数,设i 0为大于i 的最小整数,取xi 0为p %分位数;如果i 是整数,取x i +x i +12为p %分位数. (5)众数一组数据中,出现次数最多的数据称为这组数据的众数.(6)极差、方差与标准差①极差:一组数的极差指的是这组数的最大值减去最小值所得的差,描述了这组数的离散程度. ②方差定义:如果x 1,x 2,…,x n 的平均数为x ,则方差可用求和符号表示为s 2=1n ∑n i =1(x i-x -)2=1n ∑n i =1x 2i-x -2. 性质:如果a ,b 为常数,则ax 1+b ,ax 2+b ,…,ax n +b 的方差为a 2s 2. ③标准差定义:方差的算术平方根称为标准差.一般用s 表示,即样本数据x 1,x 2,…,x n 的标准差为s =1n ∑n i =1(x i -x )2. 性质:如果a ,b 为常数,则ax 1+b ,ax 2+b ,…,ax n +b 的标准差为|a |s . 2.用样本的数字特征估计总体的数字特征一般情况下,如果样本容量恰当,抽样方法合理,在估计总体的数字特征时,只需直接算出样本对应的数字特征即可. 易错点3.两个统计模型理解错误 1.变量的相关关系(1)相关关系:两个变量有关系,但又没有确切到可由其中的一个去精确地决定另一个的程度,这种关系称为相关关系. (2)相关关系的分类:正相关和负相关.(3)线性相关:如果变量x 与变量y 之间的关系可以近似地用一次函数来刻画,则称x 与y 线性相关. 2.相关系数(1)r =∑ni =1(x i -x -)(y i -y -)∑n i =1(x i -x -)2∑n i =1(y i -y -)2=∑ni =1x i y i -n x -y-(∑ni =1x 2i -n x -2)(∑n i =1y 2i -ny 2).(2)当r >0时,成对样本数据正相关;当r <0时,成对样本数据负相关.(3)|r |≤1;当|r |越接近1时,成对样本数据的线性相关程度越强;当|r |越接近0时,成对样本数据的线性相关程度越弱. 3.一元线性回归模型(1)我们将y ^=b^x +a ^称为y 关于x 的回归直线方程,其中⎩⎪⎨⎪⎧b ^=∑ni =1(x i -x -)(y i -y -)∑n i =1(x i -x -)2=∑n i =1x i y i -n x -y -∑n i =1x 2i -n x-2,a ^=y ^-b ^x -.(2)残差:观测值减去预测值,称为残差. 4.2×2列联表和χ2如果随机事件A 与B 的样本数据的2×2列联表如下.记n =a +b +χ2=n (ad -bc )2(a +b )(c +d )(a +c )(b +d ).5.独立性检验统计学中,常用的显著性水平α以及对应的分位数k 如下表所示.要推断“(1)作2×2列联表.(2)根据2×2列联表计算χ2的值.(3)查对分位数k,作出判断.如果根据样本数据算出χ2的值后,发现χ2≥k成立,就称在犯错误的概率不超过α的前提下,可以认为A与B不独立(也称为A与B 有关);或说有1-α的把握认为A与B有关.若χ2<k成立,就称不能得到前述结论.这一过程通常称为独立性检验.1.从某中学甲、乙两班各随机抽取10名同学,测量他们的身高(单位:cm),所得数据用茎叶图表示如下,由此可估计甲、乙两班同学的身高情况,则下列结论正确的是()A.甲乙两班同学身高的极差不相等B.甲班同学身高的平均值较大C.甲班同学身高的中位数较大D.甲班同学身高在175cm以上的人数较多对于D ,甲班同学身高在175cm 以上的有3人,乙班同学身高在175cm 以上的有4人,所以甲班同学身高在175cm 以上的人数较少,故D 错误. 故选:A .2.2021年某省高考体育百米测试中,成绩全部介于12秒与18秒之间,抽取其中100个样本,将测试结果按如下方式分成六组:第一组[)1213,,第二组[)1314,,⋯,第六组[]1718,,得到如下频率分布直方图.则该100名考生的成绩的平均数和中位数(保留一位小数)分别是( )A .15.2 15.3B .15.1 15.4C .15.1 15.3D .15.2 15.3【答案】C【详解】100名考生成绩的平均数12.50.1013.50.1514.50.1515.50.3016.50.2517.50.0515.1x =⨯+⨯+⨯+⨯+⨯+⨯=,因为前三组频率直方图面积和为0.100.150.150.4++=,前四组频率直方图面积和为0.100.150.150.300.7+++=,所以中位数位于第四组内,设中位数为a ,则()150.300.1a -⨯=, 解得:15.3a ≈, 故选:C .3.某地区今年夏天迎来近50年来罕见的高温极端天气,当地气象部门统计了八月份每天的最高气温和最低气温,得到如下图表: 某地区2022年8月份每天最高气温与最低气温根据图表判断,以下结论正确的是( )A .8月每天最高气温的平均数低于35℃B .8月每天最高气温的中位数高于40℃C .8月前半月每天最高气温的方差大于后半月最高气温的方差D .8月每天最高气温的方差大于每天最低气温的方差 【答案】D【详解】由某地区2022年8月份每天最高气温与最低气温的折线图知,对于A ,8月1日至9日的每天最高气温的平均数大于35℃,25日至28日的每天最高气温的平均数大于35℃,29日至31日每天最高气温大于20℃小于25℃,与35℃相差总和小于45℃,而每天最高气温不低于40℃的有7天,大于37℃小于40℃的有8天,它们与35℃相差总和超过45℃,因此8月每天最高气温的平均数不低于35℃,A 不正确;对于B ,8月每天最高气温不低于40℃的数据有7个,其它都低于40℃,把31个数据由小到大排列,中位数必小于40,因此8月每天最高气温的中位数低于40℃,B 不正确;对于C ,8月前半月每天最高气温的数据极差小,波动较小,后半月每天最高气温的极差大,数据波动很大,因此8月前半月每天最高气温的方差小于后半月最高气温的方差,C 不正确; 对于D ,8月每天最高气温的数据极差大,每天最低气温的数据极差较小,每天最高气温的数据波动也比每天最低气温的数据波动大,因此8月每天最高气温的方差大于每天最低气温的方差,D 正确. 故选:D4.两个具有线性相关关系的变量的一组数据()()1122x y x y ,,,,()n n x y ,,下列说法错误的是( )A .落在回归直线方程上的样本点越多,回归直线方程拟合效果越好B .相关系数r 越接近1,变量x ,y 相关性越强C .相关指数2R 越小,残差平方和越大,即模型的拟合效果越差D .若x 表示女大学生的身高,y 表示体重,则20.65R ≈表示女大学生的身高解释了65%的体重变化对于C :相关指数2R 越小,残差平方和越大,效果越差,故正确;对于D :根据2R 的实际意义可得,20.65R ≈表示女大学生的身高解释了65%的体重变化,故正确; 故选:A .5.下列说法正确的序号是( )℃在回归直线方程ˆ0.812y x =-中,当解释变量x 每增加一个单位时,预报变量ˆy 平均增加0.8个单位;℃利用最小二乘法求回归直线方程,就是使得12()i i i n y bx a =--∑最小的原理;℃已知X ,Y 是两个分类变量,若它们的随机变量2K 的观测值k 越大,则“X 与Y 有关系”的把握程度越小;℃在一组样本数据()11,x y ,()22,x y ,…,(),n n x y (2n ≥,1x ,2x ,…,n x 不全相等)的散点图中,若所有样本(),(1,2,)i i x y i n =都在直线112y x =-+上,则这组样本数据的线性相关系数为12-.A .℃℃B .℃℃C .℃℃D .℃℃【答案】B【详解】对于℃,在回归直线方程 ˆ0.812y x =- 中, 当解释变量 x 每增加一个单位时, 预报变量ˆy平均增加 0.8个单位,故℃正确; 对于℃,用离差的平方和,即:()()2211ˆnni i i i i i Q y yy a bx ===-=--∑∑作为总离差, 并使之达到最小;这样回归直线就是所有直线中Q 取最小值的那一条。

论文统计图表常见的那些错,附大量实例!1、“率”与“构成比”的混用【原文1】600 例烧伤患儿中,210 例早期有休克症状,其中3岁以下者110例,占52%;3岁以上者100例,占48%,年龄越小,休克发生率越高,随着年龄逐渐增长,机体调节机能及其对体液丧失的耐受性会逐步改善。
(《中华烧伤杂志》2000年发表)【原文2】表1. 101例术后病人对探视时机、探视时段的需求(《中华护理杂志》2001年发表)【分析】“率”是指某现象实际发生数与某时间点或某时间段可能发生该现象的观察单位总数之比,用以说明该现象发生的频率或强度。
“构成比”即比例,是指事物内部某一组成部分观察单位数与同一事物各组成部分的观察单位总数之比,用以说明事物内部各组成部分所占的的比重。
二者都是相对指标,计算公式相似,但是存在本质区别。
原文1中,210例发生早期休克患儿中,3岁以下的占52%,3岁以上占48%,实际上是构成比,而文中却将其误认为“发病率”,得出了“年龄越小,休克发生率越高”的结论,明显是错误的。
如果要计算不同年龄段的休克发生率,则计算公式应为(某年龄段发生休克的患儿数/该年龄段可能发生休克的患儿总数)×100%。
原文2表格中的相对数实际上也是“构成比”,“百分率”的表述方式并不准确,应该改为“构成比”。
2、分母太小不适合计算比例【原文】环丙沙星治疗实验感染动物鼠疫疗效观察:表2结果表明治疗组30只动物全部存活,治愈率为100%。
(《中国地方病学杂志》2005年发表)表2. 环丙沙星治疗实验感染动物鼠疫疗效观察【分析】原文中统计表的主要问题在于计算相对数的分母太小。
分母太小,会使结果显得过分夸张,易失真,不能正确反映事实情况,给人造成错觉。
一般来说,只有当观察的研究对象数量足够多的时候,计算相对数才比较稳定,才能反映真实的情况。
研究中对照组的动物数仅有3只,“治愈率为0”的表达显然是不合适的。
此外,表2要表达的是两组治疗疗效的差异,“攻击剂量”是对实验动物进行感染的剂量,文中也明确说明了两组动物的攻击剂量是一样的,因此攻击剂量没有必要出现在表格中。

绘制统计图和统计表要注意什么?
根据需要绘制的统计图、统计表通常要放在外面公布或张贴出来,所以同学们在绘制统计图时要注意以下几点:1、绘制统计图和统计表都要根据材料的内容和统计的要求确定统计图、统计表的项目和格式。
2、根据规定的项目和格式进行规划,可先用铅笔勾画出草图或草表。
3、绘制统计表要注意清楚明了;绘制统计图要注意鲜明美观。
二者都要突出统计的要求,又要强调客观的真实性。
4、绘制统计图和统计表都要写出标题、制作日期、图例或说明等。
5、统计图和统计表中的各种数量一定得填写的准确无误,要认真地进行核对。
6、要做到字迹工整。
7、制图的线条要均匀、美观;有着色的地方色彩要鲜明,给人以美感。
总之,同学们在绘制统计图和统计表时应做到准确无误,认真细致。
1。

统计报表易错点汇总
1. 数据源错误:如果数据源不准确或过时,那么基于这些数据生成的统计报表也会存在问题。
2. 数据理解错误:统计人员可能对数据的理解有误,导致在处理或分析数据时出错。
3. 数据录入错误:在将数据录入计算机系统时,可能会发生输入错误,如键入错误、格式错误等。
4. 数据处理错误:在进行数据清洗、转换和分析时,可能会发生错误。
例如,不正确的公式、计算错误或逻辑错误。
5. 数据可视化错误:在创建图表、图形或其他可视化表示时,可能会发生错误。
例如,错误的图表类型、标签或轴的错误解释等。
6. 数据报告错误:在编写报告时,可能会发生描述性错误、解释性错误或结论性错误。
7. 合规性问题:在某些情况下,统计报表可能违反了某些规定或标准,例如数据保密问题、伦理问题等。
8. 时间限制问题:由于时间压力,可能没有足够的时间来处理和核实所有的数据和细节,导致报表存在缺陷。
9. 技术问题:使用软件或工具时的技术问题,例如软件故障、兼容性问题或系统崩溃等。
10. 沟通问题:与其他团队或部门沟通不足,可能导致报表内容无法满足他们的需求或期望。
为了确保统计报表的准确性和可靠性,应定期进行质量检查和审计,并采取措施纠正和预防上述问题。


统计分析中常见的错误与注意事项统计分析是一种重要的数据处理方法,它帮助我们从大量的数据中提取有用的信息,作出科学的决策。
然而,在进行统计分析时常常会出现一些常见的错误和需要注意的事项。
本文将介绍一些统计分析中常见的错误并提供相应的注意事项,以帮助读者避免这些问题,并在实践中获得准确可靠的统计结果。
首先,让我们来看一些统计分析中常见的错误。
首要的错误是样本选择偏差。
在进行统计分析时,我们通常通过从总体中随机选择样本来代表整个总体。
然而,如果样本选择出现偏差,即样本与总体之间存在系统性的差异,那么从样本中得到的统计结果将无法准确反映总体的情况。
为避免样本选择偏差,应采用随机抽样的方法,并确保样本的构成与总体的分布一致。
第二个常见的错误是数据缺失处理不当。
在现实中,很少会出现完整的、没有任何缺失值的数据集。
当我们处理数据缺失时,常见的错误是直接删除缺失值或者简单地进行插补。
然而,这种方法可能导致结果的偏差和不准确性。
正确的处理数据缺失的方法是使用合适的缺失值处理技术,如多重插补等,来进行数据修复,以保证结果的可靠性。
另一个常见的错误是在进行假设检验时,错误地解释显著性水平。
显著性水平是研究者设定的一个判断标准,用于确定某个差异是否具有统计学意义。
在进行假设检验时,如果显著性水平设置得过低,会增加犯第一类错误(即错误地拒绝了真实的无效假设)的概率;而如果显著性水平设置得过高,会增加犯第二类错误(即错误地接受了错误的无效假设)的概率。
因此,为了准确地解释显著性水平,我们应该充分理解犯两类错误的概率,并根据具体问题来设定合适的显著性水平。
此外,一些重要的注意事项也需要我们特别关注。
首先,我们应该在进行统计分析前对数据进行合适的预处理。
这包括数据清洗、数据变换、异常值处理等。
对数据进行预处理可以消除不必要的误差,并确保得到的统计结果更加准确可靠。
其次,我们需要选择合适的统计方法。
不同的统计问题可能需要使用不同的方法进行处理。


快速认知是我们在非常短暂的时间中进行挖掘和衡量的重要能力,所以人类大脑能够以更快的速度处理图像,出于本能,我们更热衷于使用图像表达而非文本。
尽管我们被告知不要试图“以貌取人”,但我们每天都在频繁地使用这种快速认知的能力,通过它快速解析海量信息,发现哪些是最为重要的,而非更多采取较慢的、理性的思维方式。
心理学家将这种现象称为“薄片”:在几秒钟内感知细节或信息,大脑的理性部分可能花费数月甚至数年的时间。
薄片是人类的重要组成部分。
每当遇到一个陌生人或必须快速理解的某件事时,我们就会触发薄片现象。
如今,我们非常依赖这种能力,因为在很多情况下,即使不超过一秒钟,我们也能分辨出很多信息。
当然,在现实中,你可以通过某些方法来改变或反驳他人对你的不良的第一印象,让他们可以更加深入的了解你,但在网络中要困难的多。
所以,绝不能让你的数据可视化给人留下不好的第一印象。
为了防止这种情况发生,下面我将着重讲解5个数据可视化过程中常见的错误类型。
数据过载问题许多数据可视化和BI仪表盘都成为数据过载的牺牲品——主要原因在于可视化内容过于拥挤,很多不必要的内容可能会让数据更加难以理解。
例如,三维图表虽然看起来令人印象深刻,但它们往往会使数据的解释更加困难。
同样,对于带有超过5个数据图表和众多标签的BI仪表盘来说,确实能够展现出大量信息,但如果读者们无法区分哪些是有用的、哪些是无用的,展现再多的信息也毫无价值。
不必要的插图、阴影、字体和其他装饰会让数据看上去更加分散,数据分析师应该少用。
对于数据可视化来说,大多数情况下,少即是多。
访问轴数值设置不当在处理定量数据时,条形图或折线图是两种最佳的可视化方法。
但是,很多数据分析爱好者都会出现一个与图表轴相关的错误:对于较大的Y轴值来说,如果初始值设定到大于零,那么很可能会截断某些条形值,影响数值的准确性数值比例不清晰我们在分析数据时,通常需要以整体到部分的形式进行展现,这时我们就需要用到饼图或环图。
简单图表的分析在我们的日常生活和工作中,图表无处不在。
从财务报表到市场调研报告,从科学研究的数据展示到新闻报道中的信息呈现,图表以其直观、简洁的特点帮助我们快速理解和把握大量复杂的数据和信息。
然而,要真正从图表中获取有价值的见解,需要我们掌握一定的分析方法和技巧。
首先,让我们来了解一下常见的图表类型。
柱状图是一种非常直观的图表,它通过柱子的高度或长度来比较不同类别之间的数据差异。
比如,我们可以用柱状图来比较不同月份的销售额、不同产品的销量等。
折线图则更适合展示数据的变化趋势,像股票价格的波动、气温的变化等。
饼图主要用于显示各部分在总体中所占的比例关系,比如公司各部门的预算占比。
还有箱线图,它能有效地反映数据的分布情况,包括中位数、四分位数等。
当我们面对一个图表时,第一步是要明确图表的主题和目的。
这就好比我们在阅读一篇文章之前,要先知道文章的主旨一样。
比如,如果是一个关于公司销售业绩的图表,那么它可能是为了展示销售额的增长情况,或者是不同地区销售业绩的对比。
只有明确了主题和目的,我们才能有针对性地进行分析。
接下来,要仔细观察图表的坐标轴和刻度。
坐标轴的标签和刻度决定了数据的范围和精度。
比如,如果一个柱状图的纵轴刻度从0 开始,而另一个从 100 开始,那么给人的直观感受可能会完全不同。
同时,还要注意坐标轴的单位是否合理,是否能够准确反映数据的实际情况。
在观察数据点的时候,要关注数据的极值和异常值。
极值往往能够反映出数据的上限和下限,帮助我们了解数据的最大和最小可能情况。
而异常值则可能是由于数据录入错误或者特殊情况导致的,需要进一步核实和分析。
比如,在一个销售数据图表中,如果某个月的销售额远远高于或低于其他月份,就需要探究其原因,是因为促销活动还是市场环境的变化。
除了观察单个数据点,还要注意数据之间的关系。
比如,在折线图中,我们要观察线条的走向是上升、下降还是平稳,以及相邻数据点之间的变化幅度。
如果线条呈现出持续上升的趋势,说明相关指标在不断改善;如果是波动的,就要分析波动的原因和规律。