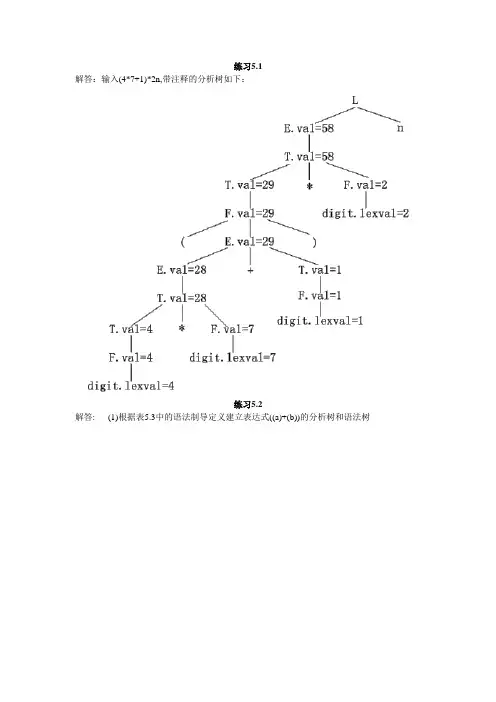
编译原理 作业标准答案
- 格式:docx
- 大小:462.46 KB
- 文档页数:11
《编译原理》第一次作业参考答案一、下列正则表达式定义了什么语言(用尽可能简短的自然语言描述)?1.b*(ab*ab*)*所有含有偶数个a的由a和b组成的字符串.2.c*a(a|c)*b(a|b|c)* | c*b(b|c)*a(a|b|c)*答案一:所有至少含有1个a和1个b的由a,b和c组成的字符串.答案二:所有含有子序列ab或子序列ba的由a,b和c组成的字符串.说明:答案一要比答案二更好,因为用自然语言描述是为了便于和非专业的人员交流,而非专业人员很可能不知道什么是“子序列”,所以相比较而言,答案一要更“自然”.二、设字母表∑={a,b},用正则表达式(只使用a,b, ,|,*,+,?)描述下列语言:1.不包含子串ab的所有字符串.b*a*2.不包含子串abb的所有字符串.b*(ab?)*3.不包含子序列abb的所有字符串.b*a*b?a*注意:关于子串(substring)和子序列(subsequence)的区别可以参考课本第119页方框中的内容.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第二次作业参考答案一、考虑以下NFA:1.这一NFA接受什么语言(用自然语言描述)?所有只含有字母a和b,并且a出现偶数次或b出现偶数次的字符串.2.构造接受同一语言的DFA.答案一(直接构造通常得到这一答案):答案二(由NFA构造DFA得到这一答案):二、正则语言补运算3.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串.1.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串.规律:构造语言L的补语言L’的DFA,可以先构造出接受L的DFA,再把这一DFA的接受状态改为非接受状态,非接受状态改为接受状态,就可以得到识别L’的DFA.说明:在上述两题中的D状态,无论输入什么符号,都不可能再到达接受状态,这样的状态称为“死状态”.在画DFA时,有时为了简明起见,“死状态”及其相应的弧(上图中的绿色部分)也可不画出.2.再证明:对任一正则表达式R,一定存在另一正则表达式R',使得L(R')是L(R)的补集.证明:根据正则表达式与DFA的等价性,一定存在识别语言L(R)的DFA. 设这一DFA为M,则将M的所有接受状态改为非接受状态,所有非接受状态改为接受状态,得到新的DFA M’. 易知M’识别语言L(R)的补集. 再由正则表达式与DFA的等价性知必存在正则表达式R’,使得L(R’)是L(R)的补集.三、设有一门小小语言仅含z、o、/(斜杠)3个符号,该语言中的一个注释由/o开始、以o/结束,并且注释禁止嵌套.1.请给出单个正则表达式,它仅与一个完整的注释匹配,除此之外不匹配任何其他串. 书写正则表达式时,要求仅使用最基本的正则表达式算子( ,|,*,+,?).参考答案一:/o(o*z|/)*o+/思路:基本思路是除了最后一个o/,在注释中不能出现o后面紧跟着/的情况;还有需要考虑的是最后一个o/之前也可以出现若干个o.参考答案二(梁晓聪、梁劲、梁伟斌等人提供):/o/*(z/*|o)*o/2.给出识别上述正则表达式所定义语言的确定有限自动机(DFA). 你可根据问题直接构造DFA,不必运用机械的算法从上一小题的正则表达式转换得到DFA.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第三次作业参考答案一、考虑以下DFA的状态迁移表,其中0,1为输入符号,A~H代表状态:其中A为初始状态,D为接受状态,请画出与此DFA等价的最小DFA,并在新的DFA状态中标明它对应的原DFA状态的子集.说明:有些同学没有画出状态H,因为无法从初始状态到达状态H. 从实用上讲,这是没有问题的. 不过,如果根据算法的步骤执行,最后是应该有状态H的.二、考虑所有含有3个状态(设为p,q,r)的DFA. 设只有r是接受状态. 至于哪一个状态是初始状态与本问题无关. 输入符号只有0和1. 这样的DFA总共有729种不同的状态迁移函数,因为对于每一状态和每一输入符号,可能迁移到3个状态中的一个,所以总共有3^6=729种可能. 在这729个DFA中,有多少个p和q是不可区分的(indistinguishable)?解释你的答案.解:考虑对于p和q,在输入符号为0时的情况,在这种情况下有5种可能使p和q无法区分:p和q在输入0时同时迁移到r(1种可能),或者p和q在输入0时,都迁移到p或q(4种可能).类似地,在输入符号为1时,也有5种可能使p和q无法区分.如果再考虑r的迁移,r的任何迁移对问题没有影响. 于是r在输入0和输入1时各有3种可能的迁移,总共有3*3=9种迁移.因此,总共有5*5*9=225个DFA,其中p和q是不可区分的.三、证明:所有仅含有字符a,且长度为素数的字符串组成的集合不是正则语言.证明:用反证法.假设含有素数个a的字符串组成的集合是正则语言,则必存在一个DFA接受这一语言,设此DFA为D. 由于D 的状态数有限,而素数有无限多个,所以必存在两个不同的素数p和q(设p<q),使得从D的初始状态出发,经过p个a和q个a后到达同一状态s,且s为接受状态. 由于DFA每一步的迁移都是确定的,所以从状态s 出发,经过(q-p)个a,只能到达状态s.考虑仅含有字母a,长度为p+p(q-p)的字符串T. T从初始状态出发,经过p个a到达状态s,再经过(q-p)个a仍然到达s;同样,经过p(q-p)个a后仍然到达s. 因此,从初始状态出发,经过p+p(q-p)个a后必然到达状态s. 由于p+p(q-p)=p(q-p+1)是合数,而s为接受状态,因而得出矛盾. 原命题得证.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第四次作业参考答案一、用上下文无关文法描述下列语言:1.定义在字母表∑={a, b}上,所有首字符和尾字符相同的非空字符串.S → aTa | bTb | a | bT → aT | bT | є说明:1. 用T来产生定义在字母表∑={a, b}上的任意字符串;2. 注意不要漏了单个a和单个b的情况.2.L={0i1j|i≤j≤2i且i≥0}.S → 0S1 | 0S11 | є3.定义在字母表∑={0, 1}上,所有含有相同个数的0和1的字符串(包括空串).S → 0S1 | 1S0 | SS | є思路:分两种情况考虑.1)如果首尾字母不同,那么这一字符串去掉首尾字母仍应该属于我们要定义的语言,因此有S → 0S1 | 1S0;2)如果首尾字母相同,那么这一字符串必定可以分成两部分,每一部分都属于我们要定义的语言,因此有S → SS.二、考虑以下文法:S → aABeA → Abc|bB → d1.用最左推导(leftmost derivation)推导出句子abbcde.S ==> aABe ==> aAbcBe ==> abbcBe ==> abbcde2.用最右推导(rightmost derivation)推导出句子abbcde.S ==> aABe ==> aAde ==> aAbcde ==> abbcde3.画出句子abbcde对应的分析树(parse tree).三、考虑以下文法:S → aSbS → aSS →1.这一文法产生什么语言(用自然语言描述)?所有n个a后紧接m个b,且n>=m的字符串.2.证明这一文法是二义的.对于输入串aab,有如下两棵不同的分析树3.写出一个新的文法,要求新文法无二义且和上述文法产生相同的语言.答案一:S → aSb | TT → aT | ε答案二:S → TS’T → aT | εS’→ aS’b | ε~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第五次作业参考答案一、考虑以下文法:S → aTUV | bVT → U | UUU →ε | bVV →ε | cV写出每个非终端符号的FIRST集和FOLLOW集.FIRST(S)={a, b} FIRST(T)={є, b} FIRST(U)={ є, b} FIRST(V)={є, c}FOLLOW(S)={$} FOLLOW(T)={ b, c, $} FOLLOW(U)={ b, c, $} FOLLOW(V)={b, c , $}二、考虑以下文法:S → (L) | aL → L, S | S1.消除文法的左递归.S → (L) | aL → SL’L’→ ,SL’ | ε2.构造文法的LL(1)分析表.FIRST(S) = {‘(‘, ‘a’} FIRST(L) = {‘(‘, ‘a’} FIRST(L’) = {‘,’, ε}FOLLOW(S) = {‘$’, ‘,’, ‘)’} FOLLOW(L) = {‘)’ } FOLLOW(L’) = {‘)’}3.三、考虑以下文法:S → aSbS | bSaS | ε这一文法是否是LL(1)文法?给出理由.这一文法不是LL(1)文法,因为S有产生式S →ε,但FIRST(S) = {a, b, ε},FOLLOW(S) = {a, b},因而FIRST(S)∩FOLLOW(S)≠∅. 根据LL(1)文法的定义知这一文法不是LL(1)文法.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第六次作业参考答案一、考虑以下文法:(0) E’→ E(1) E → E+T(2) E → T(3) T → TF(4) T → F(5) F → F*(6) F → a(7) F → b1. 写出每个非终端符号的FIRST集和FOLLOW集.FIRST(E’)= FIRST(E)= FIRST(T)= FIRST(F)={a, b}FOLLOW(E’)={$} FOLLOW(E)={+, $} FOLLOW(T)={+, $, a, b} FOLLOW(F)= {+, *, $, a, b}2. 构造识别这一文法所有活前缀(viable prefixes)的LR(0) 自动机(参照课本4.6.2节图4.31).~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第八次作业参考答案一、考虑以下语法制导定义(Syntax Directed Definition):对于输入串gbbabbccd构造带注释的分析树(annotated parse tree).最终答案:34二、以下文法定义了二进制浮点数常量的语法规则:S → L.L | LL → LB | BB → 0 | 1试给出一个S属性的语法制导定义,其作用是求出该二进制浮点数的十进制值,并存放在开始符号S相关联的一个综合属性value中。