非监督分类实验报告
- 格式:doc
- 大小:677.00 KB
- 文档页数:6
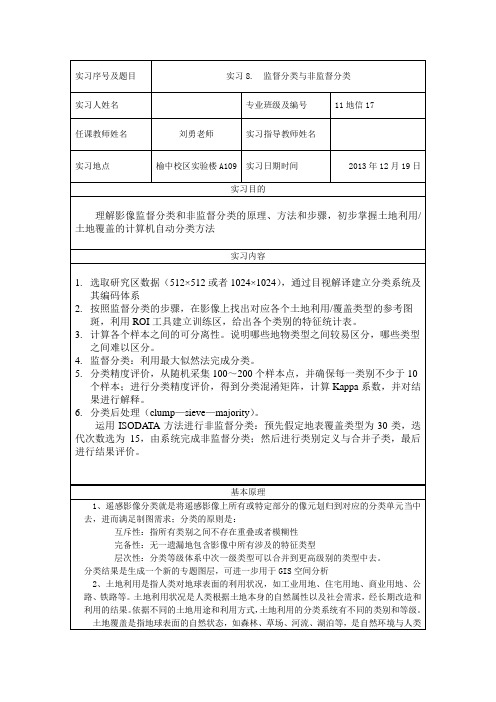
选择classification/unsupervised/Isodata,选择子区为输入文件,,点击OK,设置参数如下图所示。
对照原影像将30种类型进行编号并改名字,改变颜色;进行相同类别的合并:选择Classification中的分类后处理post classification,选择合并同类别Combine Classes,选择之前的非监督分类影像,在输入的文件中依次选择要合并的类,在输出的文件中选择相同的类别,点击Add Combination,所有的类别合并完后点击确定即可。
原影像最大似然法进行监督分类结果监督分类的最大似然法分类结果中,主要的地物都可以被区分出来,地物分布也很清楚的展现出来,只是生成的结果又很严重的椒盐现象,分析可能是选取训练区时认为造成了误差。
缺点就是没有将结果中的颜色按照真实地物的颜色进行修改,下次在聚类统计的结果上很容易看出原本监督分类的生成结果中严重的椒盐现象消失但有些细节已经被消除看不清楚,3*3窗口与5*5窗口生成的5*5窗口的更加清楚具体, 5*5窗口将周边的面积较对影像的过滤分析生成的结果显得椒盐现象更加严重Number of Neighbors的值设置的越小,小黑点越密集象都已经消失.主要成分分析得到的结果较好,椒盐现象得到避免邻地物之间的合并,分析窗口越小,地物信息更加具体次要分析(kernal size为3*3):利用次要成分分析的影像不但没有减轻椒盐现象,反而椒盐现象更加严重,未定义的黑点更密集,并且变得更大,效果很不好.7、非监督分类结果:在进行非监督分类的时候首先将地物分成了30类,然后人工进行识别分类后最终与监督分类结果一样合并成了8类,但是最后的效果并不是很好,在非监督分类一开始就将水稻田与林地分类到一起,最后生成的结果只能区分大致的地物分布,与监督分类结果相比,非监督分类结果更粗糙.。

1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigated land 水库reservoir裸地barren land 工业区industrial area滩地shoaly land 林地forest草地grassland 河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色5. 分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进行解释。
1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigated land 水库reservoir裸地barren land 工业区industrial area滩地shoaly land 林地forest草地grassland 河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色5. 分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进行解释。

实验四遥感影像分类——非监督分类非监督分类:是在没有先验类别(训练场地)作为样本的条件下,即事先不知道类别特征,主要根据像元间相似度的大小进行归类合并(即相似度的像元归为一类)的方法。
1、K—均值分类算法K -Means非监督分类计算数据空间上均匀分布的初始类别均值,然后用最短距离技术对像元进行叠代,把它们聚集到最近的类中。
每次迭代重新计算了类别均值,且用这一新的均值对像元进行再分类。
除非限定了标准差和距离的阈值(这时,如果一些像元不满足选择的标准,他们就不参与分类),所有像元都被归并到与其最临近的类别中。
这一过程持续到每一类的变化像元数少于所选的像元变化阈值或已经到了迭代的最多次数。
步骤:1)打开待分类的遥感影像数据——彼格哈恩.img2)依次打开:ENVI主菜单栏—>Classification—>Unsupervised—>K—Means即进入K均值分类数据文件选择对话框3)选择待分类的数据文件4)选好数据以后,点击OK键,进入K-Means参数设置对话框,进行有关参数的设置,包括分类的类数、分类终止的条件、迭代次数(Maximum Iteration)、类均值左右允许误差、最大距离误差以及文件的输出等参数的设置。
这里主要设置类别数目(Number of Classes)为6、迭代次数为10。
其他选项按照默认设置,输出文件。
5)建立光谱类和地物类之间的联系:在新窗口中显示分类结果图:然后,打开显示窗口菜单栏Tools菜单—>Color Mapping—>Class Color Mapping…进入分类结果的属性设置对话框,在这里,可以进行类别的名称、显示的颜色等修改,建立光谱类和地物类之间的联系。
更改类别颜色设置完成以后,点击菜单栏Options—>Save Changes 即完成光谱类与地物类联系的确立。
6)类的合并问题:如果分出的类中,有一些需要进行合并,可按以下步骤进行:选择ENVI 主菜单Classfaction—>Post Classfiction—>Combine Classes,进入待合并分类结果数据的选择对话框点击OK键,进入合并参数设置对话框,在左边选择要合并的类,在右边选择合并后的类,点击Add Combination键即完成一组合并的设置,如此反复,对其他需合并的类进行此项操作,点击OK,出现输出文件对话框,选择输出方式,即完成了类的合并的操作。

实习七非监督分类一、实习目的通过实习,掌握在软件中实现非监督分类、分类精度评价及分类后处理的操作流程、步骤。
二、实习内容1.非监督分类2.分类后处理3.分类精度的评价三、实习步骤1、获取初始分类结果1)启动非监督分类步骤:raster → unsupervised()→ unsupervised classification非监督分类对话框:2)进行非监督分类初步分类结果:2、分类方案调整(p106-107)1)显示原图像与分类图像批阅意见:装订线步骤:→ editor →进行编辑2)定义类别颜色3)设置不透明度4)确定类别意义及精度5)标注类别名称和颜色3、分类后处()1)聚类分析步骤:raster → thematic → clump 聚类结果:2)去除分析步骤:raster → thematic → eliminate 去除对比:3)重编码步骤:raster → thematic → recode重编码结果:4、评价分类精度1)分类叠加2)精度评估步骤:分别加载重编码后图像和专题图Inlandc.img图像 raster → supervised → accuracy assessment①加载cbm图像②关联专题图③点击edit :create/add random points点击OK点击edit → show class values;点击view → show all;专题图会随机出现(point#)查看class与reference是否一致并填入reference一栏;最后点击Report 生成报告:................。



遥感图像的非监督分类实验报告姓名:李全意专业班级:地科二班学号:2010214310指导教师:段艳日期:2012年6月3日1. 实验目的通过本实验加强对遥感非监督分类处理理论部分的理解,熟练掌握图像非监督分类的处理方法,并将处理前后数据进行比较。
2. 实验准备工作(1)准备遥感数据(本实验使用的是老师提供的遥感数据);(2)熟悉遥感图像非监督分类的理论部分3.实验步骤4. 实验数据分析与结论(1)通过分类前后图像的比较,发现非监督分类后的图像容易区分不同地物;(2)分类过程中存在较多错分漏分现象,同种类别中有多种地物;(3)非监督分类根据地物的光谱统计特性进行分类,客观真实且方法简单,而且具有一定的精度。
5. 实验收获及需要解决的问题(1)对非监督分类处理遥感图像方法有了总体上的认识,基本上掌握该方法的具体操作步骤,会用该方法处理一些遥感图图像。
(2)如何减少错分漏分现象,使分类后的图像更加精确?3. 实验步骤(1) 在ERDAS工具条中点击Classifier Classification Unsupervised Classification, 在Unsupervised Classification对话框中,将参数设计设计如下:Number of classes:30,一般将分类数取为最终分类数的2倍以上;Maximum Iterations:18;点击Color Scheme Options决定输出的分类图像为黑白的;Convergence Threshold:0.95。
点击OK即可。
打开完成后图像与原图像对比:原图:完成后:(2)打开原图像,在视窗中点击File/Open/Raster Layer,选择分类监督后的图像classification1.img,在Raster Options中,取消Clear Display如下:得到下图:打开分类图像属性并调整字段显示顺序在视窗工具条中,点击图标打开Raster工具面板,点击Raster工具面板的图标,得到Raster Attribute Editor对话框,如下图:可在Raster Attribute Editor对话框中点击Edit/Columns Properties,通过Up、Down调节Columns中字段的顺序,最好将Histogram、Color、Opacity、Class-Names四个调到最前列。

一、实习背景随着人工智能技术的飞速发展,机器学习在各个领域得到了广泛的应用。
非监督学习作为机器学习的一个重要分支,旨在通过算法自动将数据集划分为若干个类别,而不需要预先定义类别。
为了深入了解非监督学习在分类任务中的应用,我参加了为期一个月的非监督分类实习项目。
二、实习目标1. 掌握非监督学习的基本概念和原理;2. 熟悉常用的非监督学习算法,如K-means、层次聚类、DBSCAN等;3. 学会使用Python等编程语言进行非监督学习实践;4. 分析非监督学习在分类任务中的应用效果,并针对实际问题提出改进措施。
三、实习过程1. 非监督学习基础知识学习在实习初期,我学习了非监督学习的基本概念和原理,包括聚类、降维、异常检测等。
通过阅读相关文献和在线课程,我对非监督学习有了初步的了解。
2. 非监督学习算法实践在掌握了非监督学习基础知识后,我开始进行算法实践。
以下是我对几种常用非监督学习算法的实践过程:(1)K-means聚类K-means聚类是一种基于距离的聚类算法,它将数据集划分为K个簇,使得每个簇内的数据点距离聚类中心最近。
我使用Python的sklearn库实现了K-means聚类,并针对一组模拟数据进行了实验。
(2)层次聚类层次聚类是一种基于层次结构的聚类算法,它将数据集逐步合并为一个大簇,并记录合并过程中的信息。
我使用Python的scipy库实现了层次聚类,并针对一组模拟数据进行了实验。
(3)DBSCAN聚类DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它将数据集划分为若干个簇,并识别出噪声点。
我使用Python的sklearn库实现了DBSCAN聚类,并针对一组模拟数据进行了实验。
3. 非监督学习在分类任务中的应用在实习过程中,我尝试将非监督学习应用于分类任务。
以下是我对两种应用场景的实践:(1)数据降维降维是将高维数据转换为低维数据的过程,有助于提高后续分类算法的效率和准确性。

实验三遥感图像的监督分类与非监督分类[实验目的]1.理解遥感图像的监督分的含义;2.会使用ENVI软件对遥感图像进行监督分类。
[实验原理]在遥感图像分类中,按照是否有已知训练样本的分类依据,分类方法又分为两大类:监督分类与非监督分类。
遥感图像的监督分类是在已知类别的训练场地上提取各类别训练样本,通过选择特征变量、确定判别函数或判别式(判别规则),进而把图像中的各个像元点划归到各个给定类的分类。
遥感图像的非监督分类是在没有先验知识(训练场地)的情况下,根据图像本身的统计特征及自然点群的分布情况来划分地物类别的分类处理,事后再对已分出的各类的地物属性进行确认,也称作“边学习边分类法”。
两者的最大区别在于,监督分类首先给定类别,而非监督分类则由图像数据本身的统计特征来决定。
[实验步骤]一监督分类(数据采用njtmcorrected)监督分类技术需要在执行以前事先定义训练分类器(training classes), 训练分类器也可以用ENVI 感兴趣区(ROI)函数限定。
ENVI的监督分类技术包括平行六面体(平行管道)、最小距离、马氏距离、最大似然、波谱角度制图仪以及二进制编码方法1. “开始”->“程序”->RSI ENVI4.0->ENVI,打开ENVI4.0界面;2. 选择File > Open Image File.3. 当出现Enter Data Filename 对话框,选择要打开的文件名,再点击“OK”,在Available Bands List框里点击Load Band ,图像显示在图像显示窗口。
4. 选择“基本工具”->感兴趣区->ROI工具,弹出ROI Tool对话框。
5. 在ROI_Type菜单里选择建立感兴趣区的类型,可以选择Polygon、Polyline、point、Rectangle、Ellipse等类型。
6. 在Window栏里选择要建立感兴趣区的窗口,可以选择Image、Scroll、Zoom窗口。

西北师范大学学生实验报告(2)在unsupervised classification对话框中定义参数:对聚类选项clustering options选择initialize from statistics的统计值产生自由聚类,分出类别的数目由用户自己决定;定的模版文件进行非监督分类,类别的数目由板文件决定)初始分类类别数:10(一般取最终分类数的2倍以上)最大循环次数maximum iterations:24(是指重新聚类的最多次数,是为了避免程序运行时间太长或由于没有达到聚类指标而导致的死循环,一般都取convergence threshold:0.95(两次分类结果相比保持不变的像元占最2.分类评价在获得一个初步的分类结果以后,可以应用分类叠加方法来评价检查分类精度。
1)显示原图像与分类图像在视窗中同时显示isodata分类前后的两幅图像,两幅图像的叠加顺序为分类前在下,分类后在上,分类前图像显示方式为R4,G5,B32)打开分类图像属性表并调整字段显示顺序(1)在视窗菜单中点击raster(2)点击attributes,打开raster attribute editor(3)属性表中的11个记录分别对应产生的10的字段。
如果想要看到所有字段,需要用鼠标拖动浏览条。
为了方便看到关心的重要字段,需要调整字段显示序列。
(4)在raster attribute editor对话框菜单中点击5)确定类别专题意义及其准确程度(1)在视窗菜单中点击utility(2)点击flicker,打开viewer flicker对话框(3)在viewer flicker对话框中,选择auto mode察它与背景图像的关系从而断定该类别的专题意义,并分析准确与否)2.打开模版编辑器并调整显示字段(1)在ERDAS工具面板上点击Classifier,打开Classification (2)点击Signature Editor打开对话框。

遥感图像的分类实验报告一、实验名称遥感图像的监督分类与非监督分类二、实验目的理解遥感图像监督分类及非监督分类的原理;掌握用ENVI对影像进行监督分类和非监督分类的方法,初步掌握图像分类后的相关操作;了解整个实验的过程以及实验过程中要注意的事项。
三、实验原理监督分类:又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。
它是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
四、数据来源本次实验所用数据来自于国际数据服务平台;landsat4-5波段30米分辨率TM第三波段影像,投影为WGS-84,影像主要为山西省大同市恒山地区,中心纬度:38.90407 中心经度:113.11840。
鉴于实验内容及图像大小等问题,故从一景TM影像中裁取一个含有较丰富地物信息区域作为待分类影像。
五、实验过程1.监督分类1.1打开并显示影像文件,选择合适的波段组合加载影像打开并显示TM影像文件,从ENVI 主菜单中,选择File →Open Image File选择影像,为了更好地区分不同地物以及方便训练样本的选取,选择5、4、3波段进行相关操作,点击Load Band 在主窗口加载影像。
1.2使用感兴趣区(ROI)工具来选择训练样区1)主影像窗口菜单栏中,选择Overlay >Region of Interest。

一、实验背景随着遥感技术的飞速发展,遥感数据在资源调查、环境监测、灾害评估等领域发挥着越来越重要的作用。
遥感图像的分类是遥感应用中的一项基础性工作,它将遥感图像中的像素根据其光谱特性划分为不同的类别,从而实现对地表地物的识别和提取。
非监督分类作为遥感图像分类的一种重要方法,因其无需预先设定分类类别,能够自动将相似像素归为一类,在遥感图像处理中具有广泛的应用。
二、实验目的1. 理解非监督分类的原理和方法;2. 掌握利用ENVI软件进行非监督分类的步骤;3. 分析不同非监督分类方法的效果,比较其优缺点;4. 将非监督分类应用于实际遥感图像处理,提取地表地物信息。
三、实验原理非监督分类,也称为聚类分析或无监督分类,是一种基于像素光谱特征自动将像素归为不同类别的分类方法。
其主要原理是:将像素按照其光谱特征相似性进行聚类,使得同一类别的像素之间的距离尽可能小,而不同类别的像素之间的距离尽可能大。
常用的非监督分类方法包括:1. K-Means聚类算法:将像素按照其光谱特征分为K个类别,使得每个类别内部的像素距离最小,不同类别之间的像素距离最大。
2. ISODATA聚类算法:在K-Means聚类算法的基础上,引入了噪声点和边界点的概念,使得聚类结果更加合理。
3. 密度聚类算法:基于像素空间分布密度进行聚类,适用于地表地物分布不均匀的情况。
四、实验步骤1. 数据准备:选择合适的遥感图像作为实验数据,并进行预处理,如辐射校正、几何校正等。
2. 选择分类方法:根据实验需求和图像特点,选择合适的非监督分类方法。
3. 参数设置:设置聚类数量、迭代次数等参数,以影响聚类结果。
4. 分类执行:利用ENVI软件进行非监督分类,生成分类结果图。
5. 分类结果分析:分析分类结果,评估分类效果,并根据需要调整参数。
五、实验结果与分析以某地区Landsat 8遥感图像为例,采用K-Means聚类算法进行非监督分类,将图像分为5个类别。

非监视分类实验报告1 实验目的通过本实验加强对遥感非监视分类处理理论局部的理解,熟练掌握图像非监视分类的处理方法,并将处理前后数据进展比拟。
2 实验内容利用Envy软件进展非监视分类,主要是应用IsoData和K-Means对实验数据进展处理,并进展比拟。
3 实验步骤和过程分类过程1.翻开envi软件,添加影像,并对数据进展裁切。
2.选择Classification→Unsupervised→isodata,选择数据Stack-b1-6167.img,出现下面的对话框,选择适宜的分类值,迭代值,3.翻开影像。
选择RGB翻开,设置为5,4,3波段4.Overlay→Classification,根据经历判断具体的地物类型5.将一样地物合并Classification→Post Classification→Combine Classess6.翻开合并后的影像,并进展颜色处理〔Classification→Post classification→Assign class colors)7.分类后处理Classification→Post classification→Majority/Minority Analysis分类过程1.K-means分类方法与isodata分类方法根本类似,不同的是是在第二步过程选择Classification→Unsupervised→k-means,选择数据Stack-b1-6167.img,出现下面的对话框,选择适宜的分类值,迭代值,2.我们设置了10次迭代,而系统只进展了6次,说明对我们设置的分类数只进展6次迭代就可以了3.此后与isodata步骤一样,得到合并后的以及颜色处理后的图像如图4.进展分类后处理5.结果如图比照IsoData和K-Means分类1.在Envy中,比拟IsoData和K-Means分类,可以将最终的结果影像放在一起,如下列图。
IsodataK-means将二者连接,比照红色矩形框的图像我们发现,K-means处理容易将一些细节局部弱化掉,使分类效果不如isodata好,因此人们常使用isodata进展非监视分类。

图像分类一、实验目的1、理解遥感图像分类的基本原理和方法。
2、掌握在ERDAS IMAGINE 软件中进行非监督分类、监督分类的操作流程以及两种分类方法的区别。
3、 了解分类后处理及精度评价原理及过程。
二、 实验设备1、ERDAS IMAGINE 遥感影像处理软件。
三、 实验过程及要求1、 非监督分类ERDAS IMAGINE 使用ISODATA 算法(基于最小光谱距离公式)来进行非监督分类。
聚类过程始于任意聚类平均值或一个已有分类模板的平均值:聚类每重复一次,聚类的平均值就更新一次,新聚类的均值再用于下次聚类循环。
ISODATA 实用程序不断重复,直到最大的循环次数已达到设定阈值或者两次聚类结果相比有达到要求百分比的像元类别已经不再发生变化。
1.1 分类流程图1.2 分类过程1)调出非监督分类对话框在菜单栏中单击Raster → Unsupervised Classification →选择Unsupervised Classification 项,打开Unsupervised Classification 对话框。
影像分析结果验证分类后处理类别定义/类别合并影像分类分类器选择ISODATAK MENA 其它2)进行非监督分类在 Unsupervised Classification 对话框中→Input Raster File (确定输入文件):待分类的图像(此处为经过主成分分析后的图像)。
→Output Cluster Layer (确定输出文件)。
→勾选Output signature Set (选择生成分类模板文件)→ (确定分类模板文件) 。
→Cluster Options:选择 Initiate from Statistics.→分类方法:选择isodata.→Number of Classes(确定初始分类数):7→对于 Initializing Options 和 Color Scheme Options 两项均取缺省值。


非监督分类实验报告
一、非监督分类的初分类图
1、在ERDAS图标面板工具条下点击Classifier图标,选择Unsupervised
classification,弹出了Unsupervised classification对话框,进行如下图的设置(图像材料是实例图像中的germtm.img):
图一
2、分类评价:
1)在同一个视窗中显示分类后的图像和原图像,点击视窗菜单栏的下的Attributes,打开分类图像属性表对话框,调整字段显示顺序,并调出视窗菜单栏Utility下的Swipe窗口,使可以方便对分类后的图像的各个类别分别赋予相应的颜色,分类好的分类属性表如下图:
图二2)经过赋色后的图像如下:
图三
二、经过过滤分析后的图像:
1、在ERDAS图标面板工具条下的Interpreter图标下选择下的
(聚类统计)对话框,将刚才分类都得图像导入,输出图像为:clump.img。
2、选择下的(去除)对话框,设置如下图:
图四
然后导入经过去除分析后的图像,把各个类别的颜色设置与初步分类后
的图像设置的颜色一样,如下图:
图五经去除分析后的图像如下:
图六
三、分类重编码
1、在ERDAS图标面板工具条下的Interpreter图标下选择下
的,调出分类重编码对话框,输入的图像是经过去除分析后的
图像,点击设置重分类的编码(如图七),但也可以在视窗
窗口的菜单栏下的Recode对话框中进行设置,定义输出文件名为
recode.img:
图七
2、打开重编码后的图像,如下图:
图八。